SegmentFault 马蜂窝技术最新的文章
2020-02-18T11:47:23+08:00
https://segmentfault.com/feeds/blogs
https://creativecommons.org/licenses/by-nc-nd/4.0/
基于 Google-S2 的地理相册服务实现及应用
https://segmentfault.com/a/1190000021774912
2020-02-18T11:47:23+08:00
2020-02-18T11:47:23+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
2
<blockquote><em>马蜂窝技术原创内容,更多干货请关注公众号:mfwtech</em></blockquote>
<p>随着智能手机存储容量的增大,以及相册备份技术的普及,我们可以随时随地用手机影像记录生活,在手机中存储几千张甚至上万张照片已经是很常见的事情。但另一方面,当我们想从这么多张照片中去找到一张,也是一件麻烦事。</p>
<p>马蜂窝作为旅行玩乐平台,希望实现「会玩的人」与「好玩的事」之间的连接。众多旅行爱好者在这里记录和分享他们的旅行记忆,使马蜂窝在旅游 UGC 领域累积了大量内容。因此,不断优化用户在发布内容时的体验是我们一直努力的主向。</p>
<p>用照片、视频记录旅行是最直接的方式。本文将介绍马蜂窝如何通过 App 地理相册空间索引的应用,为用户提供直观、好用的图片分享服务。</p>
<h2>Part.1 应用场景和需求</h2>
<p>要想让用户快速地找到想要分享的照片/视频,我们需要一个有效且合理的筛选手段,对用户的相册进行聚合、排序,提升用户依托相册去分享和记录生活时易用性和便捷性。</p>
<p>首先要确定聚合排序的筛选维度。照片的地理位置就是最直观的分类维度;同时,记录最近发生的事情符合用户的发布行为习惯。因此我们方案要满足的需求是:</p>
<ol>
<li>根据目的地和时间,对用户相册进行聚合、排序;</li>
<li>基于某个地理位置信息和给定范围,在用户相册中搜索给定范围的照片/视频。</li>
</ol>
<p>本文提及的地理相册服务在马蜂窝 App 内主要有两个落地场景。</p>
<h3>1.1 笔记</h3>
<p>「笔记」是以图片、视频为主要呈现形式的旅行短内容分享。用户发布笔记的第一个环节就是从相册中选择需要发布的照片/视频,在新版 App 中,基于地理相册服务结合马蜂窝自有目的地数据,对用户相册进行按照地点维度的聚合分类,并且按照片/视频的创建时间由近及远的排序,提升用户选择发布效率。</p>
<p><img src="/img/remote/1460000021774915" alt="" title=""></p>
<h3>1.2 足迹</h3>
<p>「足迹」这一产品的功能,旨在帮助马蜂窝用户以自动同步或手动点选去过的国家和地区这种更简易的方式记录旅行。在「我的足迹」中有一个场景,会鼓励用户对去过的但还没有发布笔记的地点发布笔记。此时地理相册服务可以帮助用户发布相册中以指定地点为圆心,给定半径范围内的所有照片。</p>
<p><img src="/img/remote/1460000021774916" alt="" title=""></p>
<h2>Part.2 方案设计与算法选型</h2>
<h3>2.1 初期方案</h3>
<p>初期我们想到的方案比较直观,也比较粗暴,就是对相册进行遍历后由服务端计算结果。具体来说,首先取出用户所有携带地理信息的照片/视频,然后将地理信息(经纬度)上传服务端,由服务端进行聚合和筛选,返回给客户端结果,但是这个方案有很多缺点。</p>
<p>文章开始我们已经描述了目前用户手机设备中的照片数量是成千上万的,如果遍历所有图片,这上传的数据体量是巨大的;同时,一般用户照片的地理位置会有很多呈现出成簇聚集的状态,因为一般我们会在一个地点范围内拍摄许多照片,这就导致了大量的重复聚类的计算。</p>
<p>如果要优化这个方案,针对第一个需求我们可以采用缓存+增量请求的方式,因为用户分类数据是稳定的。但是针对给定范围查询的需求,我们无法做缓存,这就需要每次都请求服务端做大量的计算,对于时间的消耗是不能容忍的。</p>
<p>可以看到,上述方案的挑战主要在于用户相册中地理信息的数据量和重复度、依赖服务端计算搜索结果导致的性能问题和用户体验。经过调研我们发现,基于地理空间点(经纬度)索引算法可以很好地解决这些问题。</p>
<h3>2.2 基于地理空间点索引算法的实践</h3>
<p>结合我们的实际需求来理解地理空间点索引算法,即找到合适的方法来对地理空间中海量的坐标点添加索引,从而对空间点进行快速查询和排序的一种算法。</p>
<p>我们对一些比较通用的地理空间点索引算法进行了选型比较,下面主要介绍 GeoHash 算法和 Google-S2 算法。</p>
<h4><strong>2.2.1 算法选型</strong></h4>
<h5><strong>(1)GeoHash</strong></h5>
<p>GeoHash 算法即地理位置距离排序算法。Geohash 是一种地理编码,由 Gustavo Niemeyer 发明。它利用一种分级的数据结构,把空间划分为网格。</p>
<p>GeoHash 属于空间填充曲线中的 Z 阶曲线的实际应用。GeoHash 有一个和 Z 阶曲线相关的性质,那就是一个点附近的地方 Hash 字符串总是有公共前缀,并且公共前缀的长度越长,这两个点距离越近。由于这个特性,GeoHash 就常常被用来作为唯一标识符,比如在数据库里面可用 GeoHash 来唯一表示一个点。</p>
<p><img src="/img/remote/1460000021774917" alt="" title=""></p>
<p>GeoHash 这个公共前缀的特性就可以用来快速的进行邻近点的搜索。越接近的点通常和目标点的 GeoHash 字符串公共前缀越长。但是 Z 阶曲线有一个比较严重的问题,就是它的突变性。在每个 Z 字母的拐角,都有可能出现顺序的突变,导致搜索临近点的精确度较差,不能满足我们的业务场景对精确度的要求。</p>
<h5><strong>(2)S2 算法</strong></h5>
<p>S2 其实是来自几何数学中的一个数学符号 S²,它表示的是单位球。</p>
<p>S2 算法采用正方体投影的方式将地球展开,然后利用希尔伯特分形曲线将展开后的二维地球进行填充,完成了对三位地球的降维和分形,从而得到空间坐标点与希尔伯特分形曲线的函数关系,即将球面经纬度坐标转换成球面 xyz 坐标,再转换成正方体投影面上的坐标,最后变换成修正后的坐标在坐标系变换,映射到 [0,2^30^-1] 区间,最后一步就是把坐标系上的点都映射到希尔伯特曲线上。最终,映射到希尔伯特曲线上的点成为 Cell ID,即是空间坐标点的索引。</p>
<p><img src="/img/remote/1460000021774919" alt="" title=""></p>
<p>S2 的最大的优势在于精度高。Geohash 有 12 级,从 5000km 到 3.7cm,中间每一级的变化比较大。有时候可能选择上一级会大很多,选择下一级又会小一些。而 S2 有 30 级,从 0.7cm² 到 85,000,000km²,中间每一级的变化都比较平缓,接近于 4 次方的曲线。所以选择精度时不会出现 Geohash 选择困难的问题。</p>
<p>综上,S2 算法能够满足我们对于功能和精度上的要求,因此最终选择 S2 算法作为空间点索引算法的实现方案。</p>
<h2>Part.3 功能实现与性能优化</h2>
<h3>3.1 模块设计</h3>
<p>本文中的 App 地理相册服务主要基于<strong>相册索引数据操作、用户相册扫描、相册索引服务和相册地点分类计算</strong>四大模块实现:</p>
<p><img src="/img/remote/1460000021774920" alt="" title=""></p>
<p>以下分别介绍。</p>
<h4><strong>3.1.1 相册索引数据操作模块</strong></h4>
<p>相册位置信息的索引采用数据库作为存储介质,将用户照片信息以及通过 S2 算法计算出来的 Cell ID 存储到数据库当中。其中,考量存储的数量和对搜索和聚合经度的要求,存储了从 Level4~Level16 经度级别的 Cell ID。</p>
<p>相册索引数据操作模块,由数据库(DB)和数据库操作层(DAO)组成。数据表的设计见下图:</p>
<p><img src="/img/remote/1460000021774918" alt="" title=""></p>
<p>数据库操作层(DAO)封装了数据插入、删除、查询等基本操作的 API。</p>
<h4><strong>3.1.2 用户相册扫描模块</strong></h4>
<p>用户相册扫描模块基于 iOS 原生提供的相册查询的 API,将用户相册的数据与本地数据库中存储的照片数据进行对比,提取出新增照片数据和用户已经删除的照片。</p>
<h4><strong>3.1.3 相册索引服务模块</strong></h4>
<p>相册索引服务模块,是基于 S2 算法的相册服务的核心模块。模块功能如下:</p>
<ul>
<li>直接与数据模块交互,向使用者屏蔽数据层的数据操作细节,提供满足查询、搜索等需求的 API</li>
<li>查询指定 Cell ID 下的照片资源</li>
<li>查询指定 Level 下,相册照片索引后的 Cell ID</li>
<li>查询以指定坐标点为圆心、指定半径范围内的照片</li>
<li>与用户相册扫描模块交互,获取新增照片和已经删除照片的数据,更新数据库内容,同时支持查询和通知更新状态</li>
</ul>
<h4><strong>3.1.4 相册地点分类计算模块</strong></h4>
<p>相册地点分类计算模块是计算用户相册的地点分类结果的核心模块。该模块的主体功能如下:</p>
<ul>
<li>获取 S2 相册索引服务中的照片 Cell ID,作为参数上传至服务端,服务端根据地图服务提供的聚合接口,将 Cell ID 的聚合结果返回给服务端</li>
<li>综合考量精确度和 Cell ID 的数据量,选取 Level12 的 Cell ID 作为请求服务端的 Cell ID 等级</li>
<li>调用相册索引服务模块根据指定 Level 获取 Cell ID 的方法得到去重后的 Cell ID</li>
<li>服务端返回的数据结构是 mdd_id(目的地 ID) 与 Cell ID 的一对多的映射关系</li>
<li>利用本地 S2 相册索引服务中的照片 Cell ID,根据上一步服务端返回的分类数据进行分类</li>
<li>缓存每次地点分类的计算结果</li>
</ul>
<h3>3.2 整体流程</h3>
<p><img src="/img/remote/1460000021774922" alt="" title=""></p>
<p>相册索引服务模块会在 App 启动时更新服务,将本地数据与相册数据同步。当用户触发地点相册功能时,相册地点分类计算模块会先取出缓存在本地相册地点分类计算结果展现给用户,同时驱动相册索引服务更新。</p>
<p>在收到更新服务更新完毕的通知后,首先向相册请求 12Level 的全量去重的 Cell ID,然后将 Cell ID 上传服务端由服务端计算分类,最后结合相册索引服务的全量照片数据,计算照片的地点分类结果,缓存结果并渲染展现给用户。</p>
<h3>3.3 性能优化</h3>
<h4><strong>3.3.1 获取相册增量照片</strong></h4>
<p>相册索引服务模块需要同步服务和用户相册的照片资源数据,找到新增数据,加入到服务数据库中。最初设计的获取新增数据方案如下:</p>
<p><strong>Step.1</strong> 获取全量的用户相册的数据</p>
<p><strong>Step.2</strong> 遍历用户照片,查询是否存在本地服务数据库中</p>
<p>但是这个方案应用到照片量较大的手机上时,获取新增照片的时延很高。排查后我们发现原因在于全量遍历用户相册时延很高,同时在遍历中频繁查询数据库也比较耗时。经过调研发现,iOS 的用户相册有「最近项目」的相册分类,该相册分类下的资源只按照添加顺序的倒序排列,即越新的照片越靠前。故将方案优化如下:</p>
<p><strong>Step.1</strong>:从列表头部截取 100 条</p>
<p><strong>Step.2</strong>:将该 100 条追加为新增照片</p>
<p><strong>Step.3</strong>:判断该 100 条中的最后一条,即新增时间最晚的一条,查询是否存在于服务数据库中</p>
<ul>
<li>若不存在,继续 Step.1</li>
<li>若存在,停止截取,从而得到新增照片</li>
</ul>
<h4><strong>3.3.2 渐进计算相册照片的地点分类</strong></h4>
<p>相册地点分类计算模块在获得服务端返回的分类结果(mdd_id 与 Cell ID 列表的映射关系)后,根据结果对本地服务数据库中的照片进行分类。最初的方案如下:</p>
<p><strong>Step.1</strong>:遍历结果列表,获得每个 mdd_id 映射的 Cell ID 列表</p>
<ul>
<li>A. 遍历 Cell ID 列表,通过 Cell ID 向相册索引服务模块查询属于该 Cell ID 索引下的照片资源,从而获得该 mdd_id 对应的照片资源</li>
<li>B. 对该目的地下的照片按照创建时间倒序排序</li>
</ul>
<p><strong>Step.2</strong>:将所有目的地维度照片分类结果,按照每个结果集中照片最晚创建时间,即第一个照片的创建时间,进行倒序排序,获得按照地点维度和创建时间维度排序的地点相册的最终计算结果。</p>
<p>这样的方案导致在地点相册首次计算的时候,用户需要等待所有目的地下的结果计算完毕后才能展现给用户,同时需要多次按照创建时间排序,导致时延很高,冷启动下用户体验很差。</p>
<p>为此,我们做出了方案优化,减少排序次数,同时通过渐进加载的方式优化用户体验。主要思路是相册索引服务模块的数据库中,存储照片的创建时间可以通过 SQL 查询,按照创建时间倒序排列的所有照片资源,获取倒序排列的照片资源集合:</p>
<p><strong>Step.1</strong>:每次从照片资源集合头部取 1000 条照片</p>
<ul>
<li>遍历每一张照片,根据照片的 Cell ID,从 mdd_id-Cell ID 映射表中查询所属的目的地, 判断照片目的地分类结果集中是否存在该目的地的照片资源分类集合</li>
<li>存在,追加该照片</li>
<li>创建该目的地的结果集,追加到照片目的地分类结果集中,并追加该照片</li>
</ul>
<p><strong>Step.2</strong>:将该 1000 张照片的分类结果渲染展现给用户</p>
<p><strong>Step.3</strong>:计算完所有照片的分类,通知结束渲染,计算完毕。</p>
<p>以上方案,将全量的本地照片资源以 1000 张为一批次,进行渐进计算,同时渐进渲染,缩短了用户的等待时间;同时,依托关系型数据库的排序能力,减少排序次数,优化了性能。</p>
<h2>Part.4 未来规划和总结</h2>
<p>目前,本文介绍的基于 Google-S2 算法实现的地点相册在马蜂窝 APP iOS 客户端已经上线一段时间,并且为笔记发布量带来了正向增长。但是这套方案在数据库数据处理中已经对于 Google-S2 算法的使用上仍然有很大的优化和探索空间,后续我们团队也会对其不断优化和深挖。</p>
<p>Google-S2 算法服务在马蜂窝 App iOS 客户端中的实现和落地,成果不仅仅是满足了笔记发布场景的探索,更使得客户端具备了对于用户相册照片百米级精确度的索引和搜索的能力,可以为后续更多、更复杂的业务场景服务,相信在不远的未来能为用户提供更便捷、更有趣的旅行记录产品。</p>
<p><strong>本文作者</strong>:王岩、王明友,马蜂窝内容业务研发工程师。</p>
<p><img src="/img/remote/1460000021774921" alt="" title=""></p>
机器学习在马蜂窝酒店聚合中的应用初探
https://segmentfault.com/a/1190000021610126
2020-01-17T15:52:42+08:00
2020-01-17T15:52:42+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
17
<p>出门旅行,订酒店是必不可少的一个环节。住得干净、舒心对于每个出门在外的人来说都非常重要。</p>
<p>在线预订酒店让这件事更加方便。当用户在马蜂窝打开一家选中的酒店时,不同供应商提供的预订信息会形成一个聚合列表准确地展示给用户。这样做首先避免同样的信息多次展示给用户影响体验,更重要的是帮助用户进行全网酒店实时比价,快速找到性价比最高的供应商,完成消费决策。</p>
<p>酒店聚合能力的强弱,决定着用户预订酒店时可选价格的「厚度」,进而影响用户个性化、多元化的预订体验。为了使酒店聚合更加实时、准确、高效,现在马蜂窝酒店业务中近 80% 的聚合任务都是由机器自动完成。本文将详细阐述酒店聚合是什么,以及时下热门的机器学习技术在酒店聚合中是如何应用的。</p>
<h2>Part.1 应用场景和挑战</h2>
<h3>1.酒店聚合的应用场景</h3>
<p>马蜂窝酒旅平台接入了大量的供应商,不同供应商会提供很多相同的酒店,但对同一酒店的描述可能会存在差异,比如:</p>
<p><img src="/img/remote/1460000021610137" alt="" title=""></p>
<p>酒店聚合要做的,就是将这些来自不同供应商的酒店信息聚合在一起集中展示给用户,为用户提供一站式实时比价预订服务:</p>
<p><img src="/img/remote/1460000021610129" alt="" title=""></p>
<p>下图为马蜂窝对不同供应商的酒店进行聚合后的展示,不同供应商的报价一目了然,用户进行消费决策更加高效、便捷。</p>
<p><img src="/img/remote/1460000021610135" alt="" title=""></p>
<p>2.挑战</p>
<p><strong>(1) 准确性</strong></p>
<p>上文说过,不同供应商对于同一酒店的描述可能存在偏差。如果聚合出现错误,就会导致用户在 App 中看到的酒店不是实际想要预订的:</p>
<p><img src="/img/remote/1460000021610130" alt="" title=""><img src="/img/remote/1460000021610133" alt="" title=""></p>
<p>在上图中,用户在 App 中希望打开的是「精途酒店」,但系统可能为用户订到了供应商 E 提供的「精品酒店」,对于这类聚合错误的酒店我们称之为 「AB 店」。可以想象,当到店后却发现没有订单,这无疑会给用户体验造成灾难性的影响。</p>
<p><strong>(2) 实时性</strong></p>
<p>解决上述问题,最直接的方式就是全部采取人工聚合。人工聚合可以保证高准确率,在供应商和酒店数据量还不是那么大的时候是可行的。</p>
<p>但马蜂窝对接的是全网供应商的酒店资源。采用人工的方式聚合处理得会非常慢,一来会造成一些酒店资源没有聚合,无法为用户展示丰富的预订信息;二是如果价格出现波动,无法为用户及时提供当前报价。而且还会耗费大量的人力资源。</p>
<p>酒店聚合的重要性显而易见。但随着业务的发展,接入的酒店数据快速增长,越来越多的技术难点和挑战接踵而来。</p>
<h2>Part.2 初期方案:余弦相似度算法</h2>
<p>初期我们基于余弦相似度算法进行酒店聚合处理,以期降低人工成本,提高聚合效率。</p>
<p>通常情况下,有了名称、地址、坐标这些信息,我们就能对一家酒店进行唯一确定。当然,最容易想到的技术方案就是通过比对两家酒店的名称、地址、距离来判断是否相同。</p>
<p>基于以上分析,我们初版技术方案的聚合流程为:</p>
<ol>
<li>输入待聚合酒店 A;</li>
<li>ES 搜索与 A 酒店相距 5km 范围内相似度最高的 N 家线上酒店;</li>
<li>N 家酒店与 A 酒店分别开始进行两两比对;</li>
<li>酒店两两计算整体名称余弦相似度、整体地址余弦相似度、距离;</li>
<li>通过人工制定相似度、距离的阈值来得出酒店是否相同的结论。</li>
</ol>
<p>整体流程示意图如下:</p>
<p><img src="/img/remote/1460000021610132" alt="" title=""></p>
<p>「酒店聚合流程 V1」上线后,我们验证了这个方案是可行的。它最大的优点就是简单,技术实现、维护成本很低,同时机器也能自动处理部分酒店聚合任务,相比完全人工处理更加高效及时。</p>
<p>但也正是因为这个方案太简单了,问题也同样明显,我们来看下面的例子 (图中数据虚构,仅为方便举例):</p>
<p><img src="/img/remote/1460000021610134" alt="" title=""><img src="/img/remote/1460000021610131" alt="" title=""></p>
<p>相信我们每个人都可以很快判断出这是两家不同的酒店。但是当机器进行整体的相似度计算时,得到的数值并不低:<img src="/img/remote/1460000021610139" alt="" title=""></p>
<p><img src="/img/remote/1460000021610138" alt="" title=""></p>
<p>为了降低误差率,我们需要将相似度比对的阈值提升至一个较高的指标范围内,因此大量的相似酒店都不会自动聚合,仍需要人工处理。</p>
<p>最后,此版方案机器能自动处理的部分只占到约 30%,剩余 70% 仍需要人工处理;且机器自动聚合准确率约为 95%,也就是有 5% 的概率会产生 AB 店,用户到店无单,入住体验非常不好。</p>
<p>于是,伴随着机器学习的兴起,我们开始了将机器学习技术应用于酒店聚合中的探索之旅,来解决实时性和准确性这对矛盾。</p>
<h2>Part.3 机器学习在酒店聚合中的应用</h2>
<p>下面我将结合酒店聚合业务场景,分别从机器学习中的分词处理、特征构建、算法选择、模型训练迭代、模型效果来一一介绍。</p>
<h3>3.1 分词处理</h3>
<p>之前的方案通过比对「整体名称、地址」获取相似度,粒度太粗。</p>
<p>分词是指对酒店名称、地址等进行文本切割,将整体的字符串分为结构化的数据,目的是解决名称、地址整体比对粒度太粗的问题,同时也为后面构建特征向量做准备。</p>
<h4><strong>3.1.1 分词词典</strong></h4>
<p>在聊具体的名称、地址分词之前,我们先来聊一下分词词典的构建。现有分词技术一般都基于词典进行分词,词典是否丰富、准确,往往决定了分词结果的好坏。</p>
<p>在对酒店的名称分词时,我们需要使用到酒店品牌、酒店类型词典,如果纯靠人工维护的话,需要耗费大量的人力,且效率较低,很难维护出一套丰富的词典。</p>
<p>在这里我们使用统计的思想,采用机器+人工的方式来快速维护分词词典:</p>
<ol>
<li>随机选取 100000+酒店,获取其名称数据;</li>
<li>对名称从后往前、从前往后依次逐级切割;</li>
<li>每一次切割获取切割词且切割词的出现频率+1;</li>
<li>出现频率较高的词,往往就是酒店品牌词或类型词。</li>
</ol>
<p><img src="/img/remote/1460000021610141" alt="" title=""></p>
<p>上表中示意的是出现频率较高的词,得到这些词后再经过人工简单筛查,很快就能构建出酒店品牌、酒店类型的分词词典。</p>
<h4><strong>3.1.2 名称分词</strong></h4>
<p>想象一下人是如何比对两家酒店名称的?比如:</p>
<ul>
<li>A:7 天酒店 (酒仙桥店)</li>
<li>B:如家酒店 (望京店)</li>
</ul>
<p>首先,因为经验知识的存在,人会不自觉地进行「先分词后对比」的判断过程,即:</p>
<ul>
<li>7 天--->如家 </li>
<li>酒店--->酒店 </li>
<li>酒仙桥店--->望京店</li>
</ul>
<p>所以要想对比准确,我们得按照人的思维进行分词。经过对大量酒店名称进行人工模拟分词,我们对酒店名称分为如下结构化字段:</p>
<p><img src="/img/remote/1460000021610140" alt="" title=""></p>
<p>着重说下「<strong>类型前 2 字</strong>」这个字段。假如我们需要对如下 2 家酒店名称进行分词:</p>
<ul>
<li>酒店 1:龙门南昆山碧桂园紫来龙庭温泉度假别墅</li>
<li>酒店 2:龙门南昆山碧桂园瀚名居温泉度假别墅</li>
</ul>
<p>分词效果如下:<img src="/img/remote/1460000021610146" alt="" title=""></p>
<p><img src="/img/remote/1460000021610136" alt="" title=""></p>
<p>我们看到分词后各个字段相似度都很高。但类型前 2 字分别为:</p>
<ul>
<li>酒店 1 类型前 2 字:龙庭 </li>
<li>酒店 2 类型前 2 字:名居 </li>
</ul>
<p>这种情况下此字段 (类型前 2 字) 具有极高的区分度,因此可以作为一个很高效的对比特征。</p>
<h4><strong>3.1.3 地址分词</strong></h4>
<p>同样,模拟人的思维进行地址分词,使之地址的比对粒度更细更具体。具体分词方式见下图:</p>
<p><img src="/img/remote/1460000021610147" alt="" title=""></p>
<p>下面是具体的分词效果展示如下: </p>
<p><img src="/img/remote/1460000021610148" alt="" title=""></p>
<h4><strong>小结</strong></h4>
<p>分词解决了对比粒度太粗的缺点,现在我们大约有了 20 个对比维度。但对比规则、阈值怎么确定呢?</p>
<p>人工制定规则、阈值存在很多缺点,比如:</p>
<ol>
<li>规则多变。20 个对比维度进行组合会出现 N 个规则,人工不可能全部覆盖这些规则;</li>
<li>人工制定阈值容易受「经验主义」先导,容易出现误判。</li>
</ol>
<p>所以,对比维度虽然丰富了,但规则制定的难度相对来说提升了 N 个数量级。机器学习的出现,正好可以弥补这个缺点。机器学习通过大量训练数据,从而学习到多变的规则,有效解决人基本无法完成的任务。</p>
<p>下面我们来详细看下特征构建以及机器学习的过程。</p>
<h3>3.2 特征构建</h3>
<p>我们花了很大的力气来模拟人的思维进行分词,其实也是为构建特征向量做准备。</p>
<p>特征构建的过程其实也是模拟人思维的一个过程,目的是针对分词的结构化数据进行两两比对,将比对结果数字化以构造特征向量,为机器学习做准备。</p>
<p>对于不同供应商,我们确定能拿到的数据主要包括酒店名称、地址、坐标经纬度,可能获得的数据还包括电话和邮箱。</p>
<p>经过一系列数据调研,最终确定可用的数据为名称、地址、电话,主要是:因为</p>
<ol>
<li>部分供应商经纬度坐标系有问题,精准度不高,因此我们暂不使用,但待聚合酒店距离限制在 5km 范围内;</li>
<li>邮箱覆盖率较低,暂不使用。</li>
</ol>
<p>要注意的是,名称、地址拓展对比维度主要基于其分词结果,但电话数据加入对比的话首先要进行电话数据格式的清洗。</p>
<p>最终确定的特征向量大致如下,因为相似度算法比较简单,这里不再赘述:</p>
<p><img src="/img/remote/1460000021610142" alt="" title=""></p>
<h3>3.3 算法选择:决策树</h3>
<p>判断酒店是否相同,很明显这是有监督的二分类问题,判断标准为:</p>
<ul>
<li>有人工标注的训练集、验证集、测试集; </li>
<li>输入两家酒店,模型返回的结果只分为「相同」或「不同」两类情况。</li>
</ul>
<p>经过对多个现有成熟算法的对比,我们最终选择了决策树,核心思想是根据在不同 Feature 上的划分,最终得到决策树。每一次划分都向减小信息熵的方向进行,从而做到每一次划分都减少一次不确定性。这里摘录一张图片,方便大家理解:</p>
<p><img src="/img/remote/1460000021610149" alt="" title=""></p>
<p><em>(图源:__《机器学习西瓜书》)</em></p>
<h4><strong>3.3.1 Ada Boosting OR Gradient Boosting</strong></h4>
<p>具体的算法我们选择的是 Boosting。「三个臭皮匠,顶过诸葛亮」这句话是对 Boosting 很好的描述。Boosting 类似于专家会诊,一个人决策可能会有不确定性,可能会失误,但一群人最终决策产生的误差通常就会非常小。</p>
<p>Boosting 一般以树模型作为基础,其分类目前主要为 Ada Boosting、Gradient Boosting。Ada Boosting初次得出来一个模型,存在无法拟合的点,然后对无法拟合的点提高权重,依次得到多个模型。得出来的多个模型,在预测的时候进行投票选择。如下图所示:</p>
<p><img src="/img/remote/1460000021610143" alt="" title=""></p>
<p>Gradient Boosting 则是通过对前一个模型产生的错误由后一个模型去拟合,对于后一个模型产生的错误再由后面一个模型去拟合…然后依次叠加这些模型:</p>
<p><img src="/img/remote/1460000021610144" alt="" title=""></p>
<p>一般来说,Gradient Boosting 在工业界使用的更广泛,我们也以 Gradient Boosting 作为基础。</p>
<h4><strong>3.3.2 XGBoost OR LightGBM</strong></h4>
<p>XGBoost、LightGBM 都是 Gradient Boosting 的一种高效系统实现。</p>
<p>我们分别从内存占用、准确率、训练耗时方面进行了对比,LightGBM 内存占用降低了很多,准确率方面两者基本一致,但训练耗时却也降低了很多。</p>
<p>内存占用对比:</p>
<p><img src="/img/remote/1460000021610145" alt="" title=""></p>
<p>准确率对比:</p>
<p><img src="/img/remote/1460000021610153" alt="" title=""></p>
<p>训练耗时对比:</p>
<p><img src="/img/remote/1460000021610154" alt="" title=""></p>
<p><em>(图源:微软亚洲研究院)</em></p>
<p>基于以上对比数据参考,为了模型快速迭代训练,我们最终选择了 LightGBM。</p>
<h3>3.4 模型训练迭代</h3>
<p>由于使用 LightGBM,训练耗时大大缩小,所以我们可以进行快速的迭代。</p>
<p>模型训练主要关注两方面内容: </p>
<ul>
<li>训练结果分析</li>
<li>模型超参调节</li>
</ul>
<h4><strong>3.4.1 训练结果分析</strong></h4>
<p>训练结果可能一开始差强人意,没有达到理想的效果,这时需要我们仔细分析什么原因导致的这个结果,是特征向量的问题?还是相似度计算的问题?还是算法的问题?具体原因具体分析,但总归会慢慢达到理想的结果。</p>
<h4><strong>3.4.2 模型超参调节</strong></h4>
<p>这里主要介绍一些超参数调节的经验。首先大致说一下比较重要的参数:</p>
<p>(1) maxdepth 与 numleaves</p>
<p>maxdepth 与 numleaves是提高精度以及防止过拟合的重要参数:</p>
<ul>
<li>maxdepth: 顾名思义为「树的深度」,过大可能导致过拟合</li>
<li>numleaves 一棵树的叶子数。LightGBM 使用的是 leaf-wise 算法,此参数是控制树模型复杂度的主要参数</li>
</ul>
<p>(2) feature_fraction 与 bagging_fraction</p>
<p> feature_fraction与 bagging_fraction可以防止过拟合以及提高训练速度:</p>
<ul>
<li>feature_fraction:随机选择部分特征 (0<feature_fraction<1)</li>
<li>bagging_fraction随机选择部分数据 (0<bagging_fraction<1)</li>
</ul>
<p>(3) lambda_l1 与 lambda_l2 </p>
<p> lambda_l1与 lambda_l2 都是正则化项,可以有效防止过拟合。</p>
<ul>
<li>lambda_l1:L1 正则化项</li>
<li>lambda_l2 :L2 正则化项</li>
</ul>
<h3>3.5 模型效果</h3>
<p>经过多轮迭代、优化、验证,目前我们的酒店聚合模型已趋于稳定。</p>
<p>对方案效果的评估通常是凭借「准确率」与「召回率」两个指标。但酒店聚合业务场景下,需要首先保证绝对高的准确率(聚合错误产生 AB 店影响用户入住),然后才是较高的召回率。</p>
<p>经过多轮验证,目前模型的准确率可以达到 99.92% 以上,召回率也达到了 85.62% 以上:</p>
<p><img src="/img/remote/1460000021610150" alt="" title=""></p>
<p>可以看到准确率已经达到一个比较高的水准。但为保险起见,聚合完成后我们还会根据酒店名称、地址、坐标、设施、类型等不同维度建立一套二次校验的规则;同时对于部分当天预订当天入住的订单,我们还会介入人工进行实时的校验,来进一步控制 AB 店出现的风险。</p>
<p>3.6 方案总结</p>
<p>整体方案介绍完后,我们将基于机器学习的酒店聚合流程大致示意为下图:</p>
<p><img src="/img/remote/1460000021610151" alt="" title=""></p>
<p>经过上面的探索,我们大致理解了:</p>
<ol>
<li>解决方案都是一个慢慢演进的过程,当发现满足不了需求的时候就会进行迭代;</li>
<li>分词解决了对比粒度太粗的缺点,模拟人的思维进行断句分词;</li>
<li>机器学习可以得到复杂的规则,通过大量训练数据解决人无法完成的任务。</li>
</ol>
<h2>Part 4 写在最后</h2>
<p>新技术的探索充满挑战也很有意义。未来我们会进一步迭代优化,高效完成酒店的聚合,保证信息的准确性和及时性,提升用户的预订体验,比如:</p>
<ol>
<li>进行不同供应商国内酒店资源的坐标系统一。坐标对于酒店聚合是很重要的 Feature,相信坐标系统一后,酒店聚合的准确率、召回率会进一步提高。</li>
<li>打通风控与聚合的闭环。风控与聚合建立实时双向数据通道,从而进一步提高两个服务的基础能力。</li>
</ol>
<p>上述主要讲的是国内酒店聚合的演进方案,对于「国外酒店」数据的机器聚合,方法其实又很不同,比如国外酒店名称、地址如何分词,词形还原与词干提取怎么做等,我们在这方面有相应的探索和实战,总体效果甚至优于国内酒店的聚合,后续我们也会通过文章和大家分享,希望感兴趣的同学持续关注。</p>
<p><strong>本文作者:</strong>刘书超,交易中心-酒店搜索研发工程师;贺夏龙、康文云,智能中台-内容挖掘工程师。</p>
<p><img src="/img/remote/1460000021610152" alt="" title=""></p>
多环境多需求并行下的代码测试覆盖率统计工具实现
https://segmentfault.com/a/1190000021568729
2020-01-13T15:39:07+08:00
2020-01-13T15:39:07+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
2
<blockquote><em>马蜂窝技术原创内容,更多干货请关注公众号:mfwtech</em></blockquote>
<p>测试覆盖率常被用来衡量测试的充分性和完整性,也是测试有效性的一个度量。「敏捷开发」的大潮之下,如何在快速迭代的同时保证对被测代码的覆盖度和产品质量,是一个非常有挑战性的话题。</p>
<p>在马蜂窝大交通、酒店等交易相关业务中,项目的开发和测试实践同样遵循敏捷的原则,迭代周期短、速度快。因此,如何依据测试覆盖率数据帮助我们有效判断项目质量、了解测试状态、提升迭代效率,是我们一直很重视的工作。</p>
<h2>Part.1 测试覆盖率统计中的挑战</h2>
<p>对于功能测试而言,通常可以通过充分了解需求、完善的测试用例、接口测试、Review 技术方案等来保证测试充分性。但随着业务规模快速发展,业务逻辑越来越复杂,系统级别交互越来越多,这些方法都不能保证所有的代码一定被全部测试过,也给测试人员带来极大挑战。</p>
<p>说到这儿和大家分享一个因为测试覆盖不充分,影响到线上业务的真实案例。事件起因是项目提测阶段一个微服务 Sonar 扫描没通过,开发同学为了修复 Sonar 发现的问题而重构了一部分历史代码,却导致一个原有发券需求的错误。当天下午运营触发发券后 Bug 出现直接导致生单不可用,并且持续了将近一个小时。这里的问题就是发券功能与此次需求无关,开发人员修改代码后测试人员不知道,也没有经过测试,但跟随本次需求一起上线了,测试用例无法覆盖到。</p>
<p>通过这个例子可以明显地看到正确统计被测代码覆盖率的重要性。当前市面上统计覆盖率的工具很多,但应用到我们的实际场景中通常存在以下问题:</p>
<ol>
<li>大部分第三方工具都是以支持提测前单元测试的覆盖率统计为主,而<strong>支持提测后测试覆盖率的工具则比较缺乏</strong>;</li>
<li>第三方工具提供的覆盖率基本都是展示全量的,但大部分情况下,<strong>测试人员重点关注的应该是本次新增和修改的部分</strong>,而不是耗费过多精力在未修改的部分上;</li>
<li>为了支持多需求并行测试,大交通后端服务采用 QA 隔离环境,而<strong>市面上还没有支持多需求隔离环境并行测试的测试覆盖率统计工具</strong>。</li>
</ol>
<p>因此,大交通测试组决定自研工具进行被测代码的覆盖率统计,用代码覆盖结果反向地检查测试人员测试用例的覆盖度和开发人员代码的冗余度,更精准地定位和分析问题,保证产品质量。</p>
<h2>Part.2 覆盖率统计工具设计</h2>
<p>结合我们的实际场景,覆盖率统计工具的实现目标如下:</p>
<ol>
<li>大交通业务后端代码使用 Java 语言开发,主要的业务处理逻辑都在后端,所以工具要优先支持 Java 代码覆盖率统计</li>
<li>可以统计提测后测试过程中不同类型测试的覆盖率,包括:手工测试、回归测试、接口测试、UI 自动化测试等等</li>
<li>支持全量、增量覆盖率统计</li>
<li>支持多需求多环境并行测试,同时统计覆盖率</li>
<li>用户不局限于测试人员,而是所有有测试需求的人员,包括开发和测试等</li>
<li>支持自动化统计,简化操作步骤,无需学习成本,报告简单易懂</li>
</ol>
<p>我们将覆盖率统计工具命名为 jCover,并将其引入 CI/CD 体系,与内部 Java 平台项目管理及持续集成系统 MONE 打通。工具设计如下图所示:</p>
<p><img src="/img/remote/1460000021568733" alt="" title=""></p>
<p>图 1:覆盖率工具整体架构图</p>
<p>覆盖率统计的大致流程为首先通过获取多环境服务的配置信息,生成指定环境服务的测试覆盖率文件,然后根据需要生成全量覆盖率报告和增量覆盖率报告,最后,存储测试覆盖率报告到指定环境目录下。</p>
<h2>Part.3 主要功能及实现方式</h2>
<p>jCover 的主要功能包括:</p>
<ul>
<li>支持多需求多环境并行测试下,同时统计覆盖率</li>
<li>支持全量覆盖率统计</li>
<li>支持增量覆盖率统计</li>
<li>支持自动/手动统计覆盖率</li>
<li>覆盖率报告统一管理</li>
</ul>
<p>下面围绕以上功能点,为大家介绍 jCover 的作用、特点和具体实现方式。</p>
<h4>1. 覆盖率工具平台化</h4>
<p>为了简化操作步骤降低学习成本、报告简单易懂,jCover 支持界面化操作,可以手动生成测试覆盖率报告和查询测试覆盖率报告;查询测试覆盖率报告入口统一,代码测试覆盖率数据清晰,方便数据统计和量化。</p>
<p><img src="/img/remote/1460000021568739" alt="" title=""></p>
<p>图 2:覆盖率报告查询页面</p>
<h4>2. 支持多需求多环境下的并行测试</h4>
<p>由于使用敏捷迭代,项目多、并行率高,大交通所有微服务均引入测试环境隔离插件,同时支持多项目并行测试。因此,jCover 需要支持多环境并行的测试覆盖率统计。</p>
<p>具体来说,每个测试项目都会有一个单独的环境标识,以隔离环境标识+环境类型+服务名称唯一确定一个覆盖率统计单元;每一个覆盖率统计单元都会生成对应的测试覆盖率统计报告,测试覆盖率统计报告被存储到 jCover 部署的服务器中,存储位置是环境标识对应的服务目录下;同一个服务的不同提测分支同时在多项目中测试时相互间的覆盖率报告不会被覆盖。</p>
<p>多环境并行流程图见下图(目前只支持 QA 环境覆盖率统计):</p>
<p><img src="/img/remote/1460000021568734" alt="" title=""></p>
<p>图 3:多环境并行流程图</p>
<p>例如:隔离环境 gjssqz 和隔离环境 supplyrefund 可以同时进行测试覆盖率统计,隔离环境标识+环境类型+服务名称指定了每个环境下的单个服务测试覆盖率统计结果。</p>
<p>覆盖率工具 UI 展示如下图:</p>
<p><img src="/img/remote/1460000021568732" alt="" title=""></p>
<p>图 4:用「隔离环境标识+环境类型+服务名称」来标识和统计覆盖率</p>
<h4>3. 全量覆盖率统计</h4>
<p>在测试时有时候需要关注全量代码的测试覆盖率,代码全量覆盖率统计过程如下:</p>
<p><strong>(1)查询服务信息</strong></p>
<p>jCover 通过内部 Java 平台项目管理及持续集成系统 MONE 来查询被测微服务的信息:</p>
<ul>
<li>为了减轻对 MONE 系统的压力,设定每日一次定时拉取全量服务信息,将隔离环境标识、服务名称、容器 IP、监听端口、环境类型和状态存储到数据库。</li>
<li>生成覆盖率报告时根据隔离环境标识和服务名称从 MONE 单服务信息拉取接口查询最新的容器 IP。如果数据库没有就新增服务信息,如果数据库有就更新服务对应 IP。</li>
</ul>
<p><strong>(2)收集覆盖率数据</strong></p>
<p>为了做覆盖率统计,需要从微服务部署的容器中下载测试覆盖率 Dump 文件。我们采用的解决方案是使用 JavaAgent 代理,首先对微服务部署的容器进行了改造,使得容器支持 JavaAgent 功能;其次为了动态插桩记录被测代码的运行结果,在被测微服务的 JVM 启动脚本中增加 JavaAgent 参数。</p>
<p>覆盖率工具根据 IP 和监听端口通过 JavaAgent 代理从容器中下载 Dump 文件,以环境和服务标识唯一 Dump 文件,并存储到 jCover 所在的服务器。在下载覆盖率数据时采用追加方式,如果该 Dump 覆盖率文件已存在,那么该轮的覆盖率数据会直接在文本末尾进行追加,便于统计整个测试过程的代码覆盖结果。</p>
<p><strong>(3)根据全量覆盖率文件生成全量覆盖率报告</strong></p>
<ol>
<li>MONE 从微服务容器中拷贝 Class 文件到 jCover 所在服务器指定目录</li>
<li>jCover 通过 Class 文件和 Dump 文件生成全量覆盖率文件</li>
<li>根据全量覆盖率文件生成全量的测试覆盖率报告,把全量的测试覆盖率报告以「隔离环境标识+服务名称+顺序 ID」的维度存储到 jCover 所在服务器的指定目录</li>
<li>最后配置静态资源映射规则生成测试覆盖率报告 URL 并把测试覆盖率报告 URL 存储到数据库中</li>
</ol>
<p>用户打开测试覆盖率工具前端界面就可以在浏览器中查看步骤 D 生成的覆盖率报告了,绿色表示被覆盖,红色表示未被覆盖,黄色表示部分覆盖:</p>
<p><img src="/img/remote/1460000021568735" alt="" title=""></p>
<p>图 5:全量测试覆盖率报告展示</p>
<h4>4. 增量覆盖率统计</h4>
<p>业务发展到一定阶段后,代码量级很大。主干代码我们默认是正确的代码。当一个新需求提测后,测试人员更关注的其实是针对本次需求更改的代码的覆盖率而不是全部代码的覆盖率,想从全量覆盖率报告中找出本次更改的增量代码的覆盖率是非常困难的。基于此问题我们开发了增量覆盖率统计功能。</p>
<p>增量覆盖率统计和全量覆盖率统计有三个相同的步骤:查询服务信息、收集覆盖率数据、生成全量覆盖率文件。生成全量覆盖率文件后,增量覆盖率统计的不同点是增加了以下处理:增量代码获取、生成增量覆盖率报告,具体实现如下:</p>
<p><strong>(1)Diff 增量代码</strong></p>
<ol>
<li>分别获取每个微服务的 master 主干和测试分支内容,Diff 测试分支对象和 Master 分支对象,得到增量代码</li>
<li>滤除增量代码中的非.java 文件</li>
<li>循环遍历增量代码得到变化行,标识行变化类型包括:新增、更新</li>
</ol>
<p><strong>(2)生成增量覆盖率报告</strong></p>
<ul>
<li>根据增量代码变化行标识无变化的方法</li>
<li>在改变的代码行(改变包括增加和更新)行首加上对应的标识:「增加」的代码以「+++」标识,「更新」的代码以「U」标识,同时删除无变化的方法,生成增量代码覆盖率报告</li>
</ul>
<p><img src="/img/remote/1460000021568740" alt="" title=""></p>
<p>图 6:增量覆盖率流程</p>
<p>下图是交易服务增量覆盖率报告的截图示例,从图中清晰看出增量行和更新行的测试覆盖率情况。</p>
<p><img src="/img/remote/1460000021568737" alt="" title=""></p>
<p>图 7:增量覆盖率报告展示</p>
<h4>5. 支持手动/自动统计覆盖率</h4>
<p>当测试人员需要查看最新的测试覆盖率时,可以通过「jCover - 生成测试覆盖率报告」的入口手动触发生成测试覆盖率报告。</p>
<p><img src="/img/remote/1460000021568736" alt="" title=""></p>
<p>图 8:手动统计覆盖率图形化界面</p>
<p>在一个需求的实际测试中被测的微服务通常有多个。因为修改 Bug 等原因,被测微服务经常需要重启,重启后容器销毁,JavaAgent 插桩后的文件也会被删除导致重启前覆盖的代码无法被统计。</p>
<p>如果每次重启每个被测微服务前都需要测试人员手动生成覆盖率报告的话,是个很大的工作量也会经常被遗忘。因此 jCover 通过和发布系统结合实现了覆盖率自动统计功能。具体实现方法为 jCover 提供了自动生成覆盖率文件接口,在服务重启部署时后端发布系统调用此接口,实现自动统计覆盖率,不管服务重启多少次都可以把每次测试时覆盖的代码全部统计到。</p>
<p>之前大交通的后端服务发布系统为 Jenkins,后续升级为了 MONE,两种发布系统下均支持服务部署时自动统计覆盖率。</p>
<h2>Part.4 工具效果</h2>
<p>经过一段时间推广使用和优化,现在大交通所有的需求提测后均使用 jCover,主要体现出以下几点优势:</p>
<ul>
<li>
<strong>可以支撑不同类型的覆盖率测试</strong>。jCover 可以统计手工测试、接口测试、回归测试、UI 自动化测试等各种类型测试的全部覆盖率,展示为一份覆盖率报告。</li>
<li>
<strong>及时发现漏测代码</strong>。通过使用测试覆盖率工具可以发现测试用例未覆盖的代码,反推测试用例缺失。例如在「虚舱管理」项目中国际交易支付前校验失败发送 MQ 消息没有覆盖,测试人员补充了支付前校验失败发消息的测试用例;在「国际搜索坑位供应商及价格优先级设置」项目中发现由于 Mock 数据的局限性, 带有辅营的加价代码未覆盖,补充了机票+辅营的测试用例,提高测试覆盖度。</li>
<li>
<strong>发现开发的冗余代码</strong>。例如:在「国际机票重复预订优化项目」中发现冗余代码,getBaseOrderDetail 方法无调用方,开发进行了删除。</li>
<li>
<strong>及时发现测试中的问题并改进,提高测试效率</strong>。在「国内供应商资源统一化」项目中测试人员执行了很多测试用例后,使用 jCover 查看覆盖率报告发现应该覆盖的代码未被覆盖,与开发沟通后发现控制这部分代码逻辑的开关是「关闭」状态,此开关应该是在「打开」状态进行测试</li>
<li>
<strong>为上线代码审批提供数据参考</strong>。当团队成员申请代码上线时,开发 TL 可以重点关注未覆盖部分代码,减少线上问题发生。</li>
<li><strong>辅助提升测试人员对被测代码的熟悉度。</strong></li>
</ul>
<h2>Part.5 近期规划</h2>
<p>目前 jCover 只支持查看每一个类覆盖行和未覆盖行是什么,但是对于一个微服务整体行覆盖率是多少没有统计,我们正在开发<strong>增量覆盖率百分比</strong>,帮助开发和测试做出准确的判断。目前也在调研前端的覆盖率统计,下一步将实现前端的覆盖率统计工具 jCover。</p>
<p>在日常需求测试中可以采用测试(手工测试、接口测试、回归测试等)+jCover 覆盖分析的测试方法来完善测试场景,减少测试遗漏,确保测试的充分性,但需要注意的是 jCover 统计只能展示哪些代码被覆盖了,代码的正确性还是需要用例的执行结果正确来保障;还有时候开发会漏开发某部分需求,此时依靠 jCover 是无法发现这部分遗漏代码的,因此除了 jCover 之外可以通过参与技术评审、编写用例时参考产品功能矩阵图等多种手段发现问题,全方位保障被测代码的质量。</p>
<p>以上就是对马蜂窝大交通测试覆盖率统计工具 jCover 的分享。当然,统计代码覆盖率仅仅是一种手段,覆盖率高不一定代表质量好,但覆盖率不高的代码质量风险肯定很高。只有清楚在覆盖率统计数据背后反映出的问题,才能从根本上保证软件整体的质量。</p>
<p><strong>本文作者</strong>:代春美,马蜂窝测试部-交易测试工程师;孙海燕,马蜂窝测试部-交易测试团队负责人。</p>
<p><img src="/img/remote/1460000021568738" alt="" title=""></p>
Kafka 集群在马蜂窝大数据平台的优化与应用扩展
https://segmentfault.com/a/1190000021478249
2020-01-03T14:26:40+08:00
2020-01-03T14:26:40+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
4
<blockquote><em>马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech</em></blockquote>
<p>Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐、低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数据的交流和传递问题。</p>
<p>Kafka 在马蜂窝也有非常广泛的应用,为很多核心的业务提供支撑。本文将围绕 Kafka 在马蜂窝大数据平台的应用实践,介绍相关业务场景、在 Kafka 应用的不同阶段我们遇到了哪些问题以及如何解决、之后还有哪些计划等。</p>
<h2>Part.1 应用场景</h2>
<p>从 Kafka 在大数据平台的应用场景来看,主要分为以下三类:</p>
<p><strong>第一类是将 Kafka 作为数据库</strong>,提供大数据平台对实时数据的存储服务。从来源和用途两个维度来说,可以将实时数据分为业务端 DB 数据、监控类型日志、基于埋点的客户端日志 (H5、WEB、APP、小程序) 和服务端日志。</p>
<p><strong>第二类是为数据分析提供数据源</strong>,各埋点日志会作为数据源,支持并对接公司离线数据、实时数据仓库及分析系统,包括多维查询、实时 Druid OLAP、日志明细等。</p>
<p><strong>第三类是为业务方提供数据订阅</strong>。除了在大数据平台内部的应用之外,我们还使用 Kafka 为推荐搜索、大交通、酒店、内容中心等核心业务提供数据订阅服务,如用户实时特征计算、用户实时画像训练及实时推荐、反作弊、业务监控报警等。</p>
<p>主要应用如下图所示:</p>
<p><img src="/img/remote/1460000021478254" alt="" title=""></p>
<h2>Part.2 演进之路</h2>
<h3>四个阶段</h3>
<p>早期大数据平台之所以引入 Kafka 作为业务日志的收集处理系统,主要是考虑到它高吞吐低延迟、多重订阅、数据回溯等特点,可以更好地满足大数据场景的需求。但随着业务量的迅速增加,以及在业务使用和系统维护中遇到的问题,例如注册机制、监控机制等的不完善,导致出现问题无法快速定位,以及一些线上实时任务发生故障后没有快速恢复导致消息积压等, 使 Kafka 集群的稳定性和可用性得受到挑战,经历了几次严重的故障。</p>
<p>解决以上问题对我们来说迫切而棘手。针对大数据平台在使用 Kafka 上存在的一些痛点,我们从集群使用到应用层扩展做了一系列的实践,整体来说包括四个阶段:</p>
<p><strong>第一阶段:版本升级</strong>。围绕平台数据生产和消费方面存在的一些瓶颈和问题,我们针对目前的 Kafka 版本进行技术选型,最终确定使用 1.1.1 版本。</p>
<p><strong>第二阶段:资源隔离</strong>。为了支持业务的快速发展,我们完善了多集群建设以及集群内 Topic 间的资源隔离。</p>
<p><strong>第三阶段:</strong><strong>权限控制和监控告警。</strong></p>
<p>首先在安全方面,早期的 Kafka 集群处于裸跑状态。由于多产品线共用 Kafka,很容易由于误读其他业务的 Topic 导致数据安全问题。因此我们基于 SASL/ SCRAM + ACL 增加了鉴权的功能。</p>
<p>在监控告警方面,Kafka 目前已然成为实时计算中输入数据源的标配,那么其中 Lag 积压情况、吞吐情况就成为实时任务是否健康的重要指标。因此,大数据平台构建了统一的 Kafka 监控告警平台并命名「雷达」,多维度监控 Kafka 集群及使用方情况。</p>
<p><strong>第四阶段:应用扩展</strong>。早期 Kafka 在对公司各业务线开放的过程中,由于缺乏统一的使用规范,导致了一些业务方的不正确使用。为解决该痛点,我们构建了实时订阅平台,通过应用服务的形式赋能给业务方,实现数据生产和消费申请、平台的用户授权、使用方监控告警等众多环节流程化自动化,打造从需求方使用到资源全方位管控的整体闭环。</p>
<p>下面围绕几个关键点为大家展开介绍。</p>
<h3>核心实践</h3>
<h4>1. 版本升级</h4>
<p>之前大数据平台一直使用的是 0.8.3 这一 Kafka 早期版本,而截止到当前,Kafka 官方最新的 Release 版本已经到了 2.3,于是长期使用 0.8 版本过程中渐渐遇到的很多瓶颈和问题,我们是能够通过版本升级来解决的。</p>
<p>举例来说,以下是一些之前使用旧版时常见的问题:</p>
<ul>
<li>缺少对 Security 的支持:存在数据安全性问题及无法通过认证授权对资源使用细粒度管理</li>
<li>broker under replicated:发现 broker 处于 under replicated 状态,但不确定问题的产生原因,难以解决。</li>
<li>新的 feature 无法使用:如事务消息、幂等消息、消息时间戳、消息查询等。</li>
<li>客户端的对 offset 的管理依赖 zookeeper, 对 zookeeper 的使用过重, 增加运维的复杂度</li>
<li>监控指标不完善:如 topic、partition、broker 的数据 size 指标, 同时 kafka manager 等监控工具对低版本 kafka 支持不好</li>
</ul>
<p>同时对一些目标版本的特性进行了选型调研,如:</p>
<ul>
<li>0.9 版本, 增加了配额和安全性, 其中安全认证和授权是我们最关注的功能</li>
<li>0.10 版本,更细粒度的时间戳. 可以基于偏移量进行快速的数据查找,找到所要的时间戳。这在实时数据处理中基于 Kafka 数据源的数据重播是极其重要的</li>
<li>0.11 版本, 幂等性和 Transactions 的支持及副本数据丢失/数据不一致的解决。</li>
<li>1.1 版本,运维性的提升。比如当 Controller Shut Down,想要关闭一个 Broker 的时候,之前需要一个很长很复杂的过程在 1.0 版本得到很大的改善。</li>
</ul>
<p>最终选择 1.1 版本, 则是因为出于 Camus 与 Kafka 版本的兼容性及 1.1 版本已经满足了使用场景中重要新特性的支持的综合考量。这里再简单说一下 Camus 组件,同样是由 Linkedin 开源,在我们的大数据平台中主要作为 Kafka 数据 Dump 到 HDFS 的重要方式。</p>
<h4>2. 资源隔离</h4>
<p>之前由于业务的复杂性和规模不大,大数据平台对于 Kafka 集群的划分比较简单。于是,一段时间以后导致公司业务数据混杂在一起,某一个业务主题存在的不合理使用都有可能导致某些 Broker 负载过重,影响到其他正常的业务,甚至某些 Broker 的故障会出现影响整个集群,导致全公司业务不可用的风险。</p>
<p>针对以上的问题,在集群改造上做了两方面实践:</p>
<ul>
<li>按功能属性拆分独立的集群</li>
<li>集群内部 Topic 粒度的资源隔离</li>
</ul>
<p><strong>(1) 集群拆分</strong></p>
<p>按照功能维度拆分多个 Kafka 物理集群,进行业务隔离,降低运维复杂度。</p>
<p>以目前最重要的埋点数据使用来说, 目前拆分为三类集群,各类集群的功能定义如下:</p>
<ul>
<li>
<strong>Log 集群</strong>:各端的埋点数据采集后会优先落地到该集群, 所以这个过程不能出现由于 Kafka 问题导致采集中断,这对 Kafka 可用性要求很高。因此该集群不会对外提供订阅,保证消费方可控;同时该集群业务也作为离线采集的源头,数据会通过 Camus 组件按小时时间粒度 dump 到 HDFS 中,这部分数据参与后续的离线计算。</li>
<li>全量订阅集群:该集群 Topic 中的绝大部分数据是从 Log 集群实时同步过来的。上面我们提到了 Log 集群的数据是不对外的,因此全量集群就承担了消费订阅的职责。目前主要是用于平台内部的实时任务中,来对多个业务线的数据分析并提供分析服务。</li>
<li>
<strong>个性定制集群</strong>:之前提到过,我们可以根据业务方需求来拆分、合并数据日志源,同时我们还支持定制化 Topic,该集群只需要提供分流后 Topic 的落地存储。</li>
</ul>
<p>集群整体架构划分如下图:</p>
<p><img src="/img/remote/1460000021478253" alt="" title=""></p>
<p><strong>(2) 资源隔离</strong></p>
<p>Topic 的流量大小是集群内部进行资源隔离的重要依据。例如,我们在业务中埋点日志量较大的两个数据源分别是后端埋点数据源 server-event 和端上的埋点 mobile-event 数据源,我们要避免存储两个数据的主题分区分配到集群中同一个 Broker 上的节点。通过在不同 Topic 进行物理隔离,就可以避免 Broker 上的流量发生倾斜。</p>
<h4>3. 权限控制和监控告警</h4>
<p><strong>(1) 权限控制</strong></p>
<p>开始介绍时我们说过,早期 Kafka 集群没有设置安全验证处于裸跑状态,因此只要知道 Broker 的连接地址即可生产消费,存在严重的数据安全性问题。</p>
<p>一般来说, 使用 SASL 的用户多会选择 Kerberos,但就平台 Kafka 集群的使用场景来说,用户系统并不复杂,使用 Kerberos 就有些大材小用, 同时 Kerberos 相对复杂,存在引发其他问题的风险。另外,在 Encryption 方面, 由于都是运行在内网环境,所以并没有使用 SSL 加密。</p>
<p>最终平台 Kafka 集群使用 SASL 作为鉴权方式, 基于 SASL/ SCRAM + ACL 的轻量级组合方式,实现动态创建用户,保障数据安全。</p>
<p><strong>(2) 监控告警</strong></p>
<p>之前在集群的使用中我们经常发现,消费应用的性能无缘无故变差了。分析问题的原因, 通常是滞后 Consumer 读取的数据大概率没有命中 Page- cache,导致 Broker 端机器的内核要首先从磁盘读取数据加载到 Page- cache 中后,才能将结果返还给 Consumer,相当于本来可以服务于写操作的磁盘现在要读取数据了, 影响了使用方读写同时降低的集群的性能。</p>
<p>这时就需要找出滞后 Consumer 的应用进行事前的干预从而减少问题发生,因此监控告警无论对平台还是用户都有着重大的意义。下面介绍一下我们的实践思路。</p>
<p><strong>整体方案:</strong></p>
<p>整体方案主要是基于开源组件 Kafka JMX Metrics+OpenFalcon+Grafana:</p>
<ul>
<li>Kafka JMX Metrics:Kafka broker 的内部指标都以 JMX Metrics 的形式暴露给外部。1.1.1 版本 提供了丰富的监控指标,满足监控需要</li>
<li>OpenFalcon:小米开源的一款企业级、高可用、可扩展的开源监控系统</li>
<li>Grafana:Metrics 可视化系统,大家比较熟悉,可对接多种 Metrics 数据源。</li>
</ul>
<p><strong>关于监控:</strong></p>
<ul>
<li>Falcon-agent:部署到每台 Broker 上, 解析 Kafka JMX 指标上报数据</li>
<li>Grafana:用来可视化 Falcon Kafka Metrics 数据,对 Cluster、Broker、Topic、Consumer 4 个角色制作监控大盘。</li>
<li>Eagle:获取消费组 Active 状态、消费组 Lag 积压情况,同时提供 API,为监控告警系统「雷达」提供监控数据。</li>
</ul>
<p><strong>关于告警:</strong></p>
<p><strong>雷达系统</strong>: 自研监控系统,通过 Falcon 及 Eagle 获取 Kafka 指标,结合设定阈值进行告警。以消费方式举例,Lag 是衡量消费情况是否正常的一个重要指标,如果 Lag 一直增加,必须要对它进行处理。</p>
<p>发生问题的时候,不仅 Consumer 管理员要知道,它的用户也要知道,所以报警系统也需要通知到用户。具体方式是通过企业微信告警机器人自动提醒对应消费组的负责人或使用者及 Kafka 集群的管理者。</p>
<p><strong>监控示例:</strong></p>
<p><img src="/img/remote/1460000021478252" alt="" title=""></p>
<p><img src="/img/remote/1460000021478256" alt="" title=""></p>
<p><img src="/img/remote/1460000021478255" alt="" title=""></p>
<p><img src="/img/remote/1460000021478257" alt="" title=""></p>
<p><img src="/img/remote/1460000021478260" alt="" title=""></p>
<p><img src="/img/remote/1460000021478258" alt="" title=""></p>
<p><img src="/img/remote/1460000021478259" alt="" title=""></p>
<p><img src="/img/remote/1460000021478261" alt="" title=""></p>
<h4>4. 应用扩展</h4>
<p><strong>(1) 实时数据订阅平台 </strong></p>
<p>实时数据订阅平台是一个提供 Kafka 使用全流程管理的系统应用,以工单审批的方式将数据生产和消费申请、平台用户授权、使用方监控告警等众多环节流程化自动化, 并提供统一管控。</p>
<p>核心思想是基于 Kafka 数据源的身份认证和权限控制,增加数据安全性的同时对 Kafka 下游应用进行管理。</p>
<p><strong>(2) 标准化的申请流程</strong></p>
<p>无论生产者还是消费者的需求,使用方首先会以工单的方式提出订阅申请。申请信息包括业务线、Topic、订阅方式等信息;工单最终会流转到平台等待审批;如果审批通过,使用方会分配到授权账号及 Broker 地址。至此,使用方就可以进行正常的生产消费了。</p>
<p><img src="/img/remote/1460000021478265" alt="" title=""></p>
<p><img src="/img/remote/1460000021478267" alt="" title=""></p>
<p><strong>(3) 监控告警</strong></p>
<p>对于平台来说,权限与资源是绑定的,资源可以是用于生产的 Topic 或消费使用的 GroupTopic。一旦权限分配后,对于该部分资源的使用就会自动在我们的雷达监控系统进行注册,用于资源整个生命的周期的监控。 </p>
<p><strong>(4) 数据重播</strong></p>
<p>出于对数据完整性和准确性的考量,目前 Lamda 架构已经是大数据的一种常用架构方式。但从另一方面来说,Lamda 架构也存在资源的过多使用和开发难度高等问题。</p>
<p>实时订阅平台可以为消费组提供任意位点的重置,支持对实时数据按时间、位点等多种方式的数据重播, 并提供对 Kappa 架构场景的支持,来解决以上痛点。</p>
<p><img src="/img/remote/1460000021478263" alt="" title=""></p>
<p><strong>(5) 主题管理</strong></p>
<p>为什么提供主题管理?举一些很简单的例子,比如当我们想让一个用户在集群上创建他自己的 Kafka Topic,这时显然是不希望让他直接到一个节点上操作的。因此刚才所讲的服务,不管是对用户来讲,还是管理员来讲,我们都需要有一个界面操作它,因为不可能所有人都通过 SSH 去连服务器。</p>
<p>因此需要一个提供管理功能的服务,创建统一的入口并引入主题管理的服务,包括主题的创建、资源隔离指定、主题元数据管理等。</p>
<p><img src="/img/remote/1460000021478266" alt="" title=""></p>
<p><strong>(6) 数据分流</strong></p>
<p>在之前的架构中, 使用方消费 Kafka 数据的粒度都是每个 Kafka Topic 保存 LogSource 的全量数据,但在使用中很多消费方只需要消费各 LogSource 的部分数据,可能也就是某一个应用下几个埋点事件的数据。如果需要下游应用自己写过滤规则,肯定存在资源的浪费及使用便捷性的问题;另外还有一部分场景是需要多个数据源 Merge 在一起来使用的。</p>
<p>基于上面的两种情况, 我人实现了按业务方需求拆分、合并并定制化 Topic 支持跨数据源的数据合并及 appcode 和 event code 的任意组个条件的过滤规则。</p>
<p><img src="/img/remote/1460000021478262" alt="" title=""></p>
<h2>Part.3 后续计划</h2>
<ul>
<li>
<strong>解决数据重复问题</strong>。为了解决目前平台实时流处理中因故障恢复等因素导致数据重复的问题,我们正在尝试用 Kafka 的事务机制结合 Flink 的两段提交协议实现端到端的仅一次语义。目前已经在平台上小范围试用, 如果通过测试,将会在生产环境下推广。</li>
<li>
<strong>Consumer 限流</strong>。在一写多读场景中, 如果某一个 Consumer 操作大量读磁盘, 会影响 Produce 级其他消费者操作的延迟。l 因此,通过 Kafka Quota 机制对 Consume 限流及支持动态调整阈值也是我们后续的方向</li>
<li>
<strong>场景扩展</strong>。基于 Kafka 扩展 SDK、HTTP 等多种消息订阅及生产方式,满足不同语言环境及场景的使用需求。</li>
</ul>
<p>以上就是关于 Kafka 在马蜂窝大数据平台应用实践的分享,如果大家有什么建议或者问题,欢迎在马蜂窝技术公众号后台留言。</p>
<p><strong>本文作者:毕博,马蜂窝大数据平台研发工程师。</strong></p>
<p><img src="/img/remote/1460000021478264" alt="" title=""></p>
OpenResty 在马蜂窝广告监测中的应用
https://segmentfault.com/a/1190000021417557
2019-12-27T10:58:27+08:00
2019-12-27T10:58:27+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
10
<blockquote><em>马蜂窝技术原创内容,更多干货请订阅公众号:mfwtech</em></blockquote>
<p>广告是互联网变现的重要手段之一。</p>
<p>以马蜂窝旅游 App 为例,当用户打开我们的应用时,有可能会在首屏或是信息流、商品列表中看到推送的广告。如果刚好对广告内容感兴趣,用户就可能会点击广告了解更多信息,进而完成这条广告希望完成的后续操作,如下载广告推荐的 App 等。</p>
<p>广告监测平台的任务就是持续、准确地收集用户在浏览和点击广告这些事件中携带的信息,包括来源、时间、设备、位置信息等,并进行处理和分析,来为广告主提供付费结算以及评估广告投放效果的依据。</p>
<p>因此,一个可靠、准确的监测服务非常重要。为了更好地保障平台和广告主双方的权益,以及为提升马蜂窝旅游网的广告服务效果提供支撑,我们也在不断地探索适合的解决方案,加强广告监测服务的能力。</p>
<h2>Part.1 初期形态</h2>
<p>初期我们的广告监测并没有形成完整的服务对外开放,因此实现方式及提供的能力也比较简单,主要分为两部分:一是基于客户端打点,针对事件进行上报;另一部分是针对曝光、点击链接做转码存档,当请求到来后解析跳转。</p>
<p>但是很快,这种方式的弊端就暴露出来,主要体现在以下几个方面:</p>
<ul>
<li>
<strong>收数的准确性</strong>:数据转发需要访问中间件才能完成,增加了多段丢包的机率。在和第三方监测服务进行对比验证时,Gap 差异较大;</li>
<li>
<strong>数据的处理能力</strong>:收集的数据来自于各个业务系统,缺乏统一的数据标准,数据的多种属性导致解析起来很复杂,增加了综合数据二次利用的难度;</li>
<li>
<strong>突发流量:</strong>当流量瞬时升高,就会遇到 Redis 内存消耗高、服务掉线频繁的问题;</li>
<li>
<strong>部署复杂</strong>:随着不同设备、不同广告位的变更,打点趋于复杂,甚至可能会覆盖不到;</li>
<li>
<strong>开发效率</strong>:初期的广告监测功能单一,例如对实时性条件的计算查询等都需要额外开发,非常影响效率。</li>
</ul>
<h2>Part.2 基于 OpenResty 的架构实现</h2>
<p>在这样的背景下,我们打造了马蜂窝广告数据监测平台 ADMonitor,希望逐步将其实现成一个稳定、可靠、高可用的广告监测服务。</p>
<h3>2.1 设计思路</h3>
<p>为了解决老系统中的各种问题,我们引入了新的监测流程。主体流程设计为:</p>
<ol>
<li>在新的监测服务 (ADMonitor) 上生成关于每种广告独有的监测链接,同时附在原有的客户链接上;</li>
<li>所有从服务端下发的曝光链接和点击链接并行依赖 ADMonitor 提供的服务;</li>
<li>客户端针对曝光行为进行并行请求,点击行为会优先跳转到 ADMonitor,由 ADMonitor 来做二段跳转。</li>
</ol>
<p><img src="/img/bVbB1N1" alt="流程.png" title="流程.png"></p>
<p>通过以上方式,使监测服务完全依赖 ADMonitor,极大地增加了监测部署的灵活性及整体服务的性能;同时为了进一步验证数据的准确性,我们保留了打点的方式进行对比。</p>
<h3>2.2 技术选型</h3>
<p>为了使上述流程落地,广告监测的流量入口必须要具备高可用、高并发的能力,尽量减少非必要的网络请求。考虑到内部多个系统都需要流量,为了降低系统对接的人力成本,以及避免由于系统迭代对线上服务造成干扰,我们首先要做的就是把流量网关独立出来。</p>
<p>关于 C10K 编程相关的技术业内有很多解决方案,比如 OpenResty、JavaNetty、Golang、NodeJS 等。它们共同的特点是使用一个进程或线程可以同时处理多个请求,基于线程池、基于多协程、基于事件驱动+回调、实现 I/O 非阻塞。</p>
<p>我们最终选择基于 OpenResty 构建广告监测平台,主要是对以下方面的考虑:</p>
<p><strong>第一</strong>,OpenResty 工作在网络的 7 层之上,依托于比 HAProxy 更为强大和灵活的正则规则,可以针对 HTTP 应用的域名、目录结构做一些分流、转发的策略,既能做负载又能做反向代理;</p>
<p><strong>第二</strong>,OpenResty 具有 Lua协程+Nginx 事件驱动的「事件循环回调机制」,也就是 Openresty 的核心 Cosoket,对远程后端诸如 MySQL、Memcached、Redis 等都可以实现同步写代码的方式实现非阻塞 I/O;</p>
<p><strong>第三</strong>,依托于 LuaJit,即时编译器会将频繁执行的代码编译成机器码缓存起来,当下次调用时将直接执行机器码,相比原生逐条执行虚拟机指令效率更高,而对于那些只执行一次的代码仍然可以逐条执行。</p>
<h3>2.3 架构实现</h3>
<p>整体方案依托于 OpenResty 的处理机制,在服务器内部进行定制开发,主要划分为<strong>数据收集、数据处理与数据归档</strong>三大部分,实现异步拆分请求与 I/O 通信。整体结构示意图如下:</p>
<p><img src="/img/bVbB1O5" alt="架构.png" title="架构.png"></p>
<p>我们将多 Woker 日志信息以双端队列的方式存入 Master 共享内存,开启 Worker 的 Timer 毫秒级定时器,离线解析流量。</p>
<h4><strong>2.3.1 数据收集</strong></h4>
<p>收集部分也是主体承受流量压力最大的部分。我们使用 Lua 来做整体检参、过滤与推送。由于在我们的场景中,数据收集部分不需要考虑时序或对数据进行聚合处理,因此核心的推送介质选择 Lua 共享内存即可,以 I/O 请求来代替访问其他中间件所需要的网络服务,从而减少网络请求,满足即时性的要求,如下所示:</p>
<p><img src="/img/bVbB1O7" alt="企业微信截图_1ad8c6b4-39b2-4107-957b-5d0e1a6ed2b1.png" title="企业微信截图_1ad8c6b4-39b2-4107-957b-5d0e1a6ed2b1.png"></p>
<p>下面结合 OpenResty 配置,介绍一些我们对服务器节点进行的优化:</p>
<ol>
<li>设置 lua 缓存-lua_code_cache:<p>(1)开启后会将 Lua 文件缓存到内存中,加速访问,但修改 Lua 代码需要 reload</p>
<p>(2)尽量避免全局变量的产生</p>
<p>(3)关闭后会依赖 Woker 进程中生成自己新的 LVM</p>
</li>
<li>设置 Resolver 对于网络请求、好的 DNS 节点或者自建的 DNS 节点在网络请求很高的情况下会很有帮助:<p>(1)增加公司的 DNS 服务节点与补偿的公网节点</p>
<p>(2)使用 shared 来减少 Worker 查询次数</p>
</li>
<li>设置 epoll (multi_accept/accept_mutex/worker_connections):<p>(1)设置 I/O 模型、防止惊群</p>
<p>(2)避免服务节点浪费资源做无用处理而影响整体流转等</p>
</li>
<li>设置 keepalive:<p>(1)包含链接时长与请求上限等</p>
</li>
</ol>
<p>配置优化一方面是要符合当前请求场景,另一方面要配合 Lua 发挥更好的性能。设置 Nginx 服务器参数基础是根据不同操作系统环境进行调优,比如 Linux 中一切皆文件、调整文件打开数、设置 TCP Buckets、设置 TIME_WAIT 等。</p>
<h4><strong>2.3.2 数据处理</strong></h4>
<p>这部分流程是将收集到的数据先通过 ETL,之后创建内部的日志 location,结合 Lua 自定义 log_format,利用 Nginx 子请求特性离线完成数据落盘,同时保证数据延迟时长在毫秒级。</p>
<p>对被解析的数据处理要进行两部分工作,一部分是 ETL,另一部分是 Count。</p>
<p><strong>(1)ETL</strong></p>
<p><img src="/img/bVbB1Pf" alt="WX20191226-170748.png" title="WX20191226-170748.png"></p>
<p>主要流程:</p>
<ol>
<li>日志经过统一格式化之后,抽取包含实际意义参数部分进行数据解析</li>
<li>将抽取后的数据进行过滤,针对整体字符集、IP、设备、UA、相关标签信息等进行处理</li>
<li>将转化后的数据进行重加载与日志重定向</li>
</ol>
<p>【例】Lua 利用 FFI 通过 IP 库解析 "ip!"用 C 把 IP 库拷贝到内存中,Lua 进行毫秒级查询:</p>
<p><img src="/img/bVbB1Pg" alt="举个例子.png" title="举个例子.png"></p>
<p><strong>(2)Count</strong></p>
<p>对于广告数据来说,绝大部分业务需求都来自于数据统计,这里直接使用 Redis+FluxDB 存储数据,以有下几个关键的技术点:</p>
<ul>
<li>RDS 结合 Lua 设置链接时间,配置链接池来增加链接复用</li>
<li>RDS 集群服务实现去中心化,分散节点压力,增加 AOF与延时入库保证可靠</li>
<li>FluxDB 保证数据日志时序性可查,聚合统计与实时报表表现较优</li>
</ul>
<h4><strong>2.3.3 数据归档</strong></h4>
<p>数据归档需要对全量数据入表,这个过程中会涉及到对一些无效数据进行过滤处理。这里整体接入了公司的大数据体系,流程上分为在线处理和离线处理两部分,能够对数据回溯。使用的解决方案是在线 Flink、离线 Hive,其中需要关注: </p>
<ul>
<li>ES 的索引与数据定期维护</li>
<li>Kafka 的消费情况</li>
<li>对于发生故障的机器使用自动脚本重启与报警等</li>
</ul>
<p><img src="/img/bVbB1Pj" alt="企业微信截图_421b3443-7c1f-4b9b-9948-49ee29a8e734(1).png" title="企业微信截图_421b3443-7c1f-4b9b-9948-49ee29a8e734(1).png"></p>
<p>实时数据源:数据采集服务→ Filebeat → Kafka → Flink → ES</p>
<p>离线数据源:HDFS → Spark → Hive → ES</p>
<p><strong>数据解析后的再利用:</strong></p>
<p>解析后的数据已经拥有了重复利用的价值。我们的主要应用场景有两大块。</p>
<p>一是 <strong>OLAP</strong>,针对业务场景与数据表现分析访问广告的人群属性标签变化情况,包含地域,设备,人群分布占比与增长情况等;同时,针对未来人群库存占比进行预测,最后影响到实际投放上。</p>
<p>另一部分是在 <strong>OLTP</strong>,主要场景为:</p>
<ul>
<li>判定用户是否属于广告受众区域</li>
<li>解析 UA 信息,获取终端信息,判断是否属于为低级爬虫流量</li>
<li>设备号打标,从 Redis 获取实时用户画像,进行实时标记等</li>
</ul>
<h3>2.4 OpenResty 其他应用场景</h3>
<p>OpenResty 在我们的广告数据监测服务全流程中均发挥着重要作用:</p>
<ul>
<li>init_worker_by_lua阶段:负责服务配置业务</li>
<li>access_by_lua阶段:负责CC防护、权限准入、流量时序监控等业务</li>
<li>content_by_lua阶段:负责实现限速器、分流器、WebAPI、流量采集等业务</li>
<li>log_by_lua阶段:负责日志落盘等业务</li>
</ul>
<p>重点解读以下两个应用的实现方式。</p>
<h4><strong>2.4.1 分流器业务</strong></h4>
<p>NodeJS 服务向 OpenResty 网关上报当前服务器 CPU 和内存使用情况;Lua 脚本调用 RedisCluster 获取时间窗口内 NodeJS 集群使用情况后,计算出负载较高的 NodeJS 机器;OpenResty 对 NodeJS 集群流量进行熔断、降级、限流等逻辑处理;将监控数据同步 InfluxDB,进行时序监测。</p>
<h4><strong>2.4.2 小型 WEB 防火墙</strong></h4>
<p>使用第三方开源 lua_resty_waf 类库实现,支持 IP 白名单和黑名单、URL 白名单、UA 过滤、CC 攻击防护功能。我们在此基础上增加了 WAF 对 InfluxDB 的支持,进行时序监控和服务预警。</p>
<h3>2.5 小结</h3>
<p>总结来看,基于 OpenResty 实现的广告监测服务 ADMonitor 具备以下特点:</p>
<ul>
<li>
<strong>高可用</strong>:依赖 OpenResty 做 Gateway,多节点做 HA</li>
<li>
<strong>立即返回</strong>:解析数据后利用 I/O 请求做数据异步处理,避免非必要的网络通信</li>
<li>
<strong>解耦功能模块</strong>:对请求、数据处理和转发实现解耦,缩减单请求串行处理耗时</li>
<li>
<strong>服务保障</strong>:针对重要的数据结果利用第三方组件单独存储</li>
</ul>
<p>完整的技术方案示意如下:</p>
<p><img src="/img/bVbB1Po" alt="WX20191226-174735.png" title="WX20191226-174735.png"></p>
<h2>Part.3 总结</h2>
<p>目前,ADMonitor 已经接入公司的广告服务体系,总体运行情况比较理想:</p>
<h4><strong>1. 性能效果</strong></h4>
<ul>
<li>达到了高吞吐、低延迟的标准</li>
<li>转发成功率高,曝光计数成功率>99.9%,点击成功率>99.8%</li>
</ul>
<h4><strong>2. 业务效果</strong></h4>
<ul>
<li>与主流第三方监测机构进行数据对比:曝光数据 GAP < 1%,点击数据GAP < 3%</li>
<li>可提供实时检索与聚合服务</li>
</ul>
<p>未来我们将结合业务发展和服务场景不断完善,期待和大家多多交流。</p>
<p><strong>本文作者:江明辉,马蜂窝旅游网品牌广告数据服务端组研发工程师。</strong></p>
<p><img src="/img/bVbvnxq" alt="微信公众号引导关注图.png" title="微信公众号引导关注图.png"></p>
Golang 在电商即时通讯服务建设中的实践
https://segmentfault.com/a/1190000021297135
2019-12-16T11:27:32+08:00
2019-12-16T11:27:32+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
45
<blockquote><em>马蜂窝技术原创文章,更多干货请搜索公众号:mfwtech</em></blockquote>
<p>即时通讯(IM)功能对于电商平台来说非常重要,特别是旅游电商。</p>
<p>从商品复杂性来看,一个旅游商品可能会包括用户在未来一段时间的衣、食、住、行等方方面面;从消费金额来看,往往单次消费额度较大;对目的地的陌生、在行程中可能的问题,这些因素使用户在购买前、中、后都存在和商家沟通的强烈需求。可以说,一个好用的 IM 可以在一定程度上对企业电商业务的 GMV 起到促进作用。</p>
<p>本文我们将结合马蜂窝旅游电商 IM 服务的发展历程,重点介绍基于 Go 的 IM 重构,希望可以给有相似问题的朋友一些借鉴。</p>
<h2>Part.1 技术背景和问题</h2>
<p>与广义上的即时通讯不同,电商各业务线有其特有业务逻辑,如客服聊天系统的客人分配逻辑、敏感词检测逻辑等,这些往往要耦合进通信流程中。随着接入业务线越来越多,即时通讯服务冗余度会越来越高。同时整个消息链路追溯复杂,服务稳定性很受业务逻辑的影响。</p>
<p>之前我们 IM 应用中的消息推送主要基于轮询技术,消息轮询模块的长连接请求是通过 php-fpm 挂载在阻塞队列上实现。当请求量较大时,如果不能及时释放 php-fpm 进程,对服务器的性能消耗很大。</p>
<p>为了解决这个问题,我们曾用 OpenResty+Lua 的方式进行改造,利用 Lua 协程的方式将整体的 polling 的能力从 PHP 转交到 Lua 处理,释放一部 PHP 的压力。这种方式虽然能提升一部分性能,但 PHP-Lua 的混合异构模式,使系统在使用、升级、调试和维护上都很麻烦,通用性也较差,很多业务场景下还是要依赖 PHP 接口,优化效果并不明显。</p>
<p>为了解决以上问题,我们决定结合电商 IM 的特定背景对 IM 服务进行重构,核心是实现业务逻辑和即时通讯服务的分离。</p>
<h2>Part.2 基于Go的双层分布式IM架构</h2>
<h3>2.1 实现目标</h3>
<h5><strong>1. 业务解耦</strong></h5>
<p>将业务逻辑与通信流程剥离,使 IM 服务架构更加清晰,实现与电商 IM 业务逻辑的完全分离,保证服务稳定性。</p>
<h5><strong>2. 接入方式灵活</strong></h5>
<p>之前新业务接入时,需要在业务服务器上配置 OpenResty 环境及 Lua 协程代码,非常不便,IM 服务的通用性也很差。考虑到现有业务的实际情况,我们希望 IM 系统可以提供 HTTP 和 WebSocket 两种接入方式,供业务方根据不同的场景来灵活使用。</p>
<p>比如已经接入且运行良好的电商定制化团队的待办系统、定制游抢单系统、投诉系统等下行相关的系统等,这些业务没有明显的高并发需求,可以通过 HTTP 方式迅速接入,不需要熟悉稍显复杂的 WebSocket 协议,进而降低不必要的研发成本。</p>
<h5><strong>3. 架可扩展</strong></h5>
<p>为了应对业务的持续增长给系统性能带来的挑战,我们考虑用分布式架构来设计即时通讯服务,使系统具有持续扩展及提升的能力。</p>
<h3>2.2 语言选择</h3>
<p>目前,马蜂窝技术体系主要包括 PHP,Java,Golang,技术栈比较丰富,使业务做选型时可以根据问题场景选择更合适的工具和语言。</p>
<p>结合 IM 具体应用场景,我们选择 Go 的原因包括:</p>
<h5><strong>1. 性能</strong></h5>
<p>在性能上,尤其是针对网络通信等 IO 密集型应用场景。Go 系统的性能更接近 C/C++。</p>
<h5><strong>2. 开发效率</strong></h5>
<p>Go 使用起来简单,代码编写效率高,上手也很快,尤其是对于有一定 C++ 基础的开发者,一周就能上手写代码了。</p>
<h3>2.3 架构设计</h3>
<p>整体架构图如下:</p>
<p><img src="/img/bVbBwu6" alt="架构.png" title="架构.png"></p>
<blockquote>
<p><em>名词解释:</em></p>
<ul>
<li>客户:一般指购买商品的用户</li>
<li>商家:提供服务的供应商,商家会有客服人员,提供给客户一个在线咨询的作用</li>
<li>分发模块:即 Dispatcher,提供消息分发的给指定的工作模块的桥接作用</li>
<li>工作模块:即 Worker 服务器,用来提供 WebSocket 服务,是真正工作的一个模块。</li>
</ul>
</blockquote>
<p><strong>架构分层:</strong></p>
<ul>
<li>
<strong>展示层</strong>:提供 HTTP 和 WebSocket 两种接入方式。</li>
<li>
<strong>业务层</strong>:负责初始化消息线和业务逻辑处理。如果客户端以 HTTP 方式接入,会以 JSON 格式把消息发送给业务服务器进行消息解码、客服分配、敏感词过滤,然后下发到消息分发模块准备下一步的转换;通过 WebSocket 接入的业务则不需要消息分发,直接以 WebSocket 方式发送至消息处理模块中。</li>
<li>
<strong>服务层</strong>:由消息分发和消息处理这两层组成,分别以分布式的方式部署多个 Dispatcher 和 Worker 节点。Dispatcher 负责检索出接收者所在的服务器位置,将消息以 RPC 的方式发送到合适的 Worker 上,再由消息处理模块通过 WebSocket 把消息推送给客户端。</li>
<li>
<strong>数据层</strong>:Redis 集群,记录用户身份、连接信息、客户端平台(移动端、网页端、桌面端)等组成的唯一 Key。</li>
</ul>
<h3>2.4 服务流程</h3>
<h5><strong>步骤一</strong></h5>
<p>如上图右侧所示,用户客户端与消息处理模块建立 WebSocket 长连接。通过负载均衡算法,使客户端连接到合适的服务器(消息处理模块的某个 Worker)。连接成功后,记录用户连接信息,包括用户角色(客人或商家)、客户端平台(移动端、网页端、桌面端)等组成唯一 Key,记录到 Redis 集群。</p>
<h5><strong>步骤二</strong></h5>
<p>如图左侧所示,当购买商品的用户要给管家发消息的时候,先通过 HTTP 请求把消息发给业务服务器,业务服务端对消息进行业务逻辑处理。</p>
<p>(1) 该步骤本身是一个 HTTP 请求,所以可以接入各种不同开发语言的客户端。通过 JSON 格式把消息发送给业务服务器,业务服务器先把消息解码,然后拿到这个用户要发送给哪个商家的客服的。</p>
<p>(2) 如果这个购买者之前没有聊过天,则在业务服务器逻辑里需要有一个分配客服的过程,即建立购买者和商家的客服之间的连接关系。拿到这个客服的 ID,用来做业务消息下发;如果之前已经聊过天,则略过此环节。</p>
<p>(3) 在业务服务器,消息会异步入数据库。保证消息不会丢失。</p>
<h5><strong>步骤三</strong></h5>
<p>业务服务端以 HTTP 请求把消息发送到消息分发模块。这里分发模块的作用是进行中转,最终使服务端的消息下发给指定的商家。</p>
<h5><strong>步骤四</strong></h5>
<p>基于 Redis 集群中的用户连接信息,消息分发模块将消息转发到目标用户连接的 WebSocket 服务器(消息处理模块中的某一个 Worker)</p>
<p>(1) 分发模块通过 RPC 方式把消息转发到目标用户连接的 Worker,RPC 的方式性能更快,而且传输的数据也少,从而节约了服务器的成本。</p>
<p>(2) 消息透传 Worker 的时候,多种策略保障消息一定会下发到 Worker。</p>
<h5><strong>步骤五</strong></h5>
<p>消息处理模块将消息通过 WebSocket 协议推送到客户端:</p>
<p>(1) 在投递的时候,接收者要有一个 ACK(应答) 信息来回馈给 Worker 服务器,告诉 Worker 服务器,下发的消息接收者已经收到了。</p>
<p>(2) 如果接收者没有发送这个 ACK 来告诉 Worker 服务器,Worker 服务器会在一定的时间内来重新把这个信息发送给消息接收者。</p>
<p>(3) 如果投递的信息已经发送给客户端,客户端也收到了,但是因为网络抖动,没有把 ACK 信息发送给服务器,那服务器会重复投递给客户端,这时候客户端就通过投递过来的消息 ID 来去重展示。</p>
<p>以上步骤的数据流转大致如图所示:</p>
<p><img src="/img/bVbBwvb" alt="流程" title="流程"></p>
<h3>2.5 系统完整性设计</h3>
<h4><strong>2.5.1 可靠性</strong></h4>
<h5><strong>(1)消息不丢失</strong></h5>
<p>为了避免消息丢失,我们设置了超时重传机制。服务端会在推送给客户端消息后,等待客户端的 ACK,如果客户端没有返回 ACK,服务端会尝试多次推送。</p>
<p>目前默认 18s 为超时时间,重传 3 次不成功,断开连接,重新连接服务器。重新连接后,采用拉取历史消息的机制来保证消息完整。</p>
<h5><strong>(2)多端消息同步</strong></h5>
<p>客户端现有 PC 浏览器、Windows 客户端、H5、iOS/Android,系统允许用户多端同时在线,且同一端可以多个状态,这就需要保证多端、多用户、多状态的消息是同步的。</p>
<p>我们用到了 Redis 的 Hash 存储,将用户信息、唯一连接对应值 、连接标识、客户端 IP、服务器标识、角色、渠道等记录下来,这样通过 key(uid) 就能找到一个用户在多个端的连接,通过 key+field 能定位到一条连接。</p>
<h4><strong>2.5.2 可用性</strong></h4>
<p>上文我们已经说过,因为是双层设计,就涉及到两个 Server 间的通信,同进程内通信用 Channel,非同进程用消息队列或者 RPC。综合性能和对服务器资源利用,我们最终选择 RPC 的方式进行 Server 间通信。在对基于 Go 的 RPC 进行选行时,我们比较了以下比较主流的技术方案:</p>
<ul>
<li>Go STDRPC:Go 标准库的 RPC,性能最优,但是没有治理</li>
<li>RPCX:性能优势 2*GRPC + 服务治理</li>
<li>GRPC:跨语言,但性能没有 RPCX 好</li>
<li>TarsGo:跨语言,性能 5*GRPC,缺点是框架较大,整合起来费劲</li>
<li>Dubbo-Go:性能稍逊一筹, 比较适合 Go 和 Java 间通信场景使用</li>
</ul>
<p>最后我们选择了 RPCX,因为性能也很好,也有服务的治理。</p>
<p>两个进程之间同样需要通信,这里用到的是 ETCD 实现服务注册发现机制。</p>
<p>当我们新增一个 Worker,如果没有注册中心,就要用到配置文件来管理这些配置信息,这挺麻烦的。而且你新增一个后,需要分发模块立刻发现,不能有延迟。</p>
<p>如果有新的服务,分发模块希望能快速感知到新的服务。利用 Key 的续租机制,如果在一定时间内,没有监听到 Key 有续租动作,则认为这个服务已经挂掉,就会把该服务摘除。</p>
<p>在进行注册中心的选型时,我们主要调研了 ETCD,ZK,Consul,三者的压测结果参考如下:</p>
<p><img src="/img/bVbBwvh" alt="etcd" title="etcd"></p>
<p><img src="/img/bVbBwvn" alt="etcd" title="etcd"></p>
<p>结果显示,ETCD 的性能是最好的。另外,ETCD 背靠阿里巴巴,而且属于 Go 生态,我们公司内部的 K8S 集群也在使用。</p>
<p>综合考量后,我们选择使用 ETCD 作为服务注册和发现组件。并且我们使用的是 ETCD 的集群模式,如果一台服务器出现故障,集群其他的服务器仍能正常提供服务。</p>
<p>通过保证服务和进程间的正常通讯,及 ETCD 集群模式的设计,保证了 IM 服务整体具有极高的可用性。</p>
<h4><strong>2.5.3 扩展性</strong></h4>
<p>消息分发模块和消息处理模块都能进行水平扩展。当整体服务负载高时,可以通过增加节点来分担压力,保证消息即时性和服务稳定性。</p>
<h4><strong>2.5.4 安全性</strong></h4>
<p>处于安全性考虑,我们设置了黑名单机制,可以对单一 uid 或者 ip 进行限制。比如在同一个 uid 下,如果一段时间内建立的连接次数超过设定的阈值,则认为这个 uid 可能存在风险,暂停服务。如果暂停服务期间该 uid 继续发送请求,则限制服务的时间相应延长。</p>
<h3>2.6 性能优化和踩过的坑</h3>
<h4><strong>2.6.1 性能优化</strong></h4>
<h5><strong>(1) JSON 编解码</strong></h5>
<p>开始我们使用官方的 JSON 编解码工具,但由于对性能方面的追求,改为使用滴滴开源的 Json-iterator,使在兼容原生 Golang 的 JSON 编解码工具的同时,效率上有比较明显的提升。以下是压测对比的参考图:</p>
<p><img src="/img/bVbBwvp" alt="DD.png" title="DD.png"></p>
<h5><strong>(2) time.After</strong></h5>
<p>在压测的时候,我们发现内存占用很高,于是使用 Go Tool PProf 分析 Golang 函数内存申请情况,发现有不断创建 time.After 定时器的问题,定位到是心跳协程里面。</p>
<p>原来代码如下:</p>
<p><img src="/img/bVbBwvE" alt="代码0.png" title="代码0.png"></p>
<p>优化后的代码为:</p>
<p><img src="/img/bVbBwvH" alt="代码1.png" title="代码1.png"></p>
<p>优化点在于 for 循环里不要使用 select + time.After 的组合。</p>
<h5><strong>(3) Map 的使用</strong></h5>
<p>在保存连接信息的时候会用到 Map。因为之前做 TCP Socket 的项目的时候就遇到过一个坑,即 Map 在协程下是不安全的。当多个协程同时对一个 Map 进行读写时,会抛出致命错误:fetal error:concurrent map read and map write,有了这个经验后,我们这里用的是 sync.Map</p>
<h4>2.6.2 踩坑经验</h4>
<h5><strong>(1) 协程异常</strong></h5>
<p>基于对开发成本和服务稳定性等问题的考虑,我们的 WebSocket 服务基于 Gorilla/WebSocket 框架开发。其中遇到一个问题,就是当读协程发生异常退出时,写协程并没有感知到,结果就是导致读协程已经退出但是写协程还在运行,直到触发异常之后才退出。这样虽然从表面上看不影响业务逻辑,但是浪费后端资源。在编码时应该注意要在读协程退出后主动通知写协程,这样一个小的优化可以这在高并发下能节省很多资源。</p>
<h5><strong>(2) 心跳设计</strong></h5>
<p>举个例子,之前我们在闲时心跳功能的开发中走了一些弯路。最初在服务器端的心跳发送是定时心跳,但后来在实际业务场景中使用时发现,设计成服务器读空闲时心跳更好。因为用户都在聊天呢,发一个心跳帧,浪费感情也浪费带宽资源。</p>
<p>这时候,建议大家在业务开发过程中如果代码写不下去就暂时不要写了,先结合业务需求用文字梳理下逻辑,可能会发现之后再进行会更顺利。</p>
<h5><strong>(3) 每天分割日志</strong></h5>
<p><img src="/img/bVbBwvL" alt="日志.png" title="日志.png"></p>
<p>日志模块在起初调研的时候基于性能考虑,确定使用 Uber 开源的 ZAP 库,而且满足业务日志记录的要求。日志库选型很重要,选不好也是影响系统性能和稳定性的。ZAP 的优点包括:</p>
<ul>
<li>显示代码行号这个需求,ZAP 支持而 Logrus 不支持,这个属于提效的。行号展示对于定位问题很重要。</li>
<li>ZAP 相对于 Logrus 更为高效,体现在写 JSON 格式日志时,没有使用反射,而是用内建的 json encoder,通过明确的类型调用,直接拼接字符串,最小化性能开销。</li>
</ul>
<p><strong>小坑:</strong></p>
<p>每天写一个日志文件的功能,目前 ZAP 不支持,需要自己写代码支持,或者请求系统部支持。</p>
<h2>Part.3 性能表现</h2>
<h5><strong>压测 1:</strong></h5>
<p>上线生产环境并和业务方对接以及压测,目前定制业务已接通整个流程,写了一个 Client。模拟定期发心跳帧,然后利用 Docker 环境。开启了 50 个容器,每个容器模拟并发起 2 万个连接。这样就是百万连接打到单机的 Server 上。单机内存占用 30G 左右。</p>
<h5><strong>压测 2:</strong></h5>
<p>同时并发 3000、4000、5000 连接,以及调整发送频率,分别对应上行:60万、80 万、100 万、200 万, 一个 6k 左右的日志结构体。</p>
<p>其中有一半是心跳包 另一半是日志结构体。在不同的压力下的下行延迟数据如下:</p>
<p><img src="/img/bVbBwvW" alt="WX20191216-105353.png" title="WX20191216-105353.png"></p>
<p><strong>结论:</strong>随着上行的并发变大,延迟控制在 24-66 毫秒之间。所以对于下行业务属于轻微延迟。另外针对 60 万 5k 上行的同时,用另一个脚本模拟开启 50 个协程并发下行 1k 的数据体,延迟是比没有并发下行的时候是有所提高的,延迟提高了 40ms 左右。</p>
<h2>Part.4 总结</h2>
<p>基于 Go 重构的 IM 服务在 WebSocket 的基础上,将业务层设计为配有消息分发模块和消息处理模块的双层架构模式,使业务逻辑的处理前置,保证了即时通讯服务的纯粹性和稳定性;同时消息分发模块的 HTTP 服务方便多种编程语言快速对接,使各业务线能迅速接入即时通讯服务。</p>
<p>最后,我还想为 Go 摇旗呐喊一下。很多人都知道马蜂窝技术体系主要是基于 PHP,有一些核心业务也在向 Java 迁移。与此同时,Go 也在越来越多的项目中发挥作用。现在,云原生理念已经逐渐成为主流趋势之一,我们可以看到在很多构建云原生应用所需要的核心项目中,Go 都是主要的开发语言,比如 Kubernetes,Docker,Istio,ETCD,Prometheus 等,包括第三代开源分布式数据库 TiDB。</p>
<p>所以我们可以把 Go 称为云原生时代的母语。「云原生时代,是开发者最好的时代」,在这股浪潮下,我们越早走进 Go,就可能越早在这个新时代抢占关键赛道。希望更多小伙伴和我们一起,加入到 Go 的开发和学习阵营中来,拓宽自己的技能图谱,拥抱云原生。</p>
<p><strong>本文作者:Anti Walker,马蜂窝旅游网电商交易基础平台研发工程师。</strong></p>
<p><img src="/img/bVbpQy1" alt="WechatIMG171.png" title="WechatIMG171.png"></p>
马蜂窝推荐排序算法模型是如何实现快速迭代的
https://segmentfault.com/a/1190000020966725
2019-11-11T14:39:47+08:00
2019-11-11T14:39:47+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
3
<p>(马蜂窝技术原创文章,微信ID:mfwtech)</p>
<h3>Part.1马蜂窝推荐系统架构</h3>
<p>马蜂窝推荐系统主要由召回(Match)、排序(Rank)、重排序(Rerank)几个部分组成,整体架构图如下:</p>
<p><img src="/img/remote/1460000020966728" alt="" title=""></p>
<p>在召回阶段,系统会从海量的内容库筛选出符合用户偏好的候选集(百级、千级);排序阶段在此基础上,基于特定的优化目标(如点击率)对候选集内容进行更加精准的计算和选择,为每一条内容进行精确打分,进而从候选集的成百上千条内容中选出用户最感兴趣的少量高质量内容。</p>
<p>本文我们将重点介绍马蜂窝推荐系统中的核心之一——排序算法平台,它的整体架构如何;为了给用户呈现更加精准的推荐结果,在支撑模型快速、高效迭代的过程中,排序算法平台发挥了哪些作用及经历的实践。</p>
<h2>Part.2 排序算法平台的演进</h2>
<h3>2.1 整体架构</h3>
<p>目前,马蜂窝排序算法线上模型排序平台主要由<strong>通用数据处理模块、可替换模型生产模块、监控与分析模块</strong>三部分组成,各模块结构及平台整体工作流程如下图所示:<img src="/img/remote/1460000020966729" alt="" title=""></p>
<h4><strong>2.1.1 模块<strong><em><em>功能</em></em></strong></strong></h4>
<p><strong>(1) 通用数据处理模块</strong></p>
<p>核心功能是特征建设以及训练样本的构建,也是整个排序算法最为基础和关键的部分。数据源涉及点击曝光日志、用户画像、内容画像等等,底层的数据处理依赖 Spark 离线批处理和 Flink 实时流处理。</p>
<p><strong>(2) 可替换模型生产模块</strong></p>
<p>主要负责训练集的构建、模型的训练以及生成线上配置,实现模型的无缝同步上线。</p>
<p><strong>(3) 监控与分析模块</strong></p>
<p>主要包括上游依赖数据的监控、推荐池的监控,特征的监控与分析,模型的可视化分析等功能。</p>
<p>各个模块的功能以及他们之间的交互使用 JSON 配置文件进行集成,使模型的训练和上线仅仅需要修改配置就能完成,极大提升了开发效率,为排序算法的快速迭代打下了坚实的基础。</p>
<h4><strong>2.1.2 主要配置文件类型</strong></h4>
<p>配置文件主要分为 TrainConfig、MergeConfig、OnlineConfig、CtrConfig 四类,其作用分别为:</p>
<p><strong>(1)TrainConfig</strong></p>
<p>指训练配置,主要包括训练集配置和模型配置:</p>
<ul>
<li>训练集配置包括指定使用哪些特征进行训练;指定使用哪些时间段内的训练数据;指定场景、页面、和频道等</li>
<li>模型配置包括模型参数、训练集路径、测试集路径、模型保存路径等</li>
</ul>
<p><strong>(2)MergeConfig</strong></p>
<p>指特征配置,包括上下文特征、用户特征、物品特征、交叉特征的选择。</p>
<p>这里,我们将交叉特征的计算方式也实现了配置化。例如用户特征中有一些向量特征,内容特征也有一些向量特征。当我们希望使用某两个向量的余弦相似度或者欧式距离作为一个交叉特征给模型使用时,这种交叉特征的选择和计算方式可以直接通过配置实现,并且同步的线上配置中供线上使用。</p>
<p><strong>(3)OnlineConfig</strong></p>
<p>指线上配置,训练数据构建的过程中自动生成供线上使用,包括特征的配置(上下文特征、用户特征、内容特征、交叉特征)、模型的路径、特征的版本。</p>
<p><strong>(4)CtrConfig</strong></p>
<p>指默认 CTR 配置,作用为针对用户和内容的 CTR 特征进行平滑处理。</p>
<p><strong>2.1.3 特征工程</strong></p>
<p>从应用的视角来看,特征主要包括三类,用户特征(User Feature)、内容特征(Article Feature)、上下文特征(Context Feature)。</p>
<p>如果按获取的方式又可以分为:</p>
<ul>
<li>统计特征(Statistics Feature):包括用户、内容、特定时间段内的点击量/曝光量/CTR 等</li>
<li>向量特征(Embedding Feature):以标签、目的地等信息为基础,利用用户点击行为历史,使用 Word2Vec 训练的向量特征等;</li>
<li>交叉特征(Cross Feature):基于标签或目的地向量,构建用户向量或物品向量,从而得到用户与物品的相似度特征等</li>
</ul>
<h3>2.2 排序算法平台 V1</h3>
<p>在排序算法平台 V1 阶段,通过简单的 JSON 文件配置,平台就能够实现特征的选择、训练集的选择、分场景 XGBoost 模型的训练、XGBoost 模型离线 AUC 的评估、生成线上配置文件自动同步上线等功能。</p>
<p><img src="/img/remote/1460000020966730" alt="" title=""></p>
<h3>2.3 排序算法平台 V2</h3>
<p>针对上面存在的这些问题,我们在排序算法平台的监控分析模块增加了<strong>数据验证、模型解释</strong>的功能,帮助我们对模型的持续迭代优化提供更加科学、精准的依据。</p>
<p><img src="/img/remote/1460000020966731" alt="" title=""></p>
<h4><strong>2.3.1 数据验证(DataVerification)</strong></h4>
<p>在算法平台 V1 阶段,当模型离线效果(AUC)表现很好,而线上效果不符合预期时,我们很难排查定位问题,影响模型迭代。</p>
<p>通过对问题的调查和分析我们发现,造成线上效果不符合预期的一个很重要的原因,可能是目前模型的训练集是基于数仓每天汇总的一张点击曝光表得到。由于数据上报延迟等原因,这张离线的点击曝光表中的一些上下文特征与实时的点击曝光行为可能存在误差,带来一些离线和线上特征不一致的问题。</p>
<p>针对这种情况,我们增加了数据验证的功能,将离线构建的训练集与线上打印的实时特征日志进行各个维度的对比分析。</p>
<p>具体做法就是以线上的实时点击曝光日志(包含所使用的模型、特征以及模型预测分等信息)为基础,为每条实时点击曝光记录都增加一个唯一 ID,在离线汇总的点击曝光表中也会保留这个唯一 ID。这样,针对一条点击曝光记录,我们就可以将离线构建的训练集中的特征,与线上实际使用的特征关联起来,对线上和离线模型的 AUC、线上和离线模型的预测分以及特征的情况进行对比,从而发现一些问题。</p>
<p>举例来说,在之前的模型迭代过程中,模型离线 AUC 很高,但是线上效果却并不理想。通过数据验证,我们首先对比了线上和离线模型 AUC 的情况,发现存在效果不一致的现象,接着对比线上和离线模型的预测分,并找到线上和离线预测分相差最大的 TopK 个样本,对它们的离线特征和线上特征进行对比分析。最后发现是由于数据上报延迟造成了一些线上和离线上下文特征的不一致,以及线上XGBoost、DMatrix 构建时选的 missingValue 参数有问题,从而导致了线上和离线模型预测分存在偏差。上述问题修复后,线上 UV 点击率提升了 16.79%,PV 点击率提升了 19.10%。</p>
<p>通过数据验证的功能和解决策略,我们快速定位到了问题的原因,加速算法模型迭代开发的过程,提升了线上的应用效果。</p>
<h4><strong>2.3.2 模型解释(ModelExplain)</strong></h4>
<p>模型解释可以打开机器学习模型的黑盒,增加我们对模型决策的信任,帮助理解模型决策,为改进模型提供启发。关于模型解释的一些概念,推荐给大家两篇文章来帮助理解:《Why Should I Trust You Explaining the Predictions of Any Classifier》、《A Unified Approach to Interpreting Model Predictions》。</p>
<p>在实际开发中,我们总是在模型的准确性与模型的可解释性之间权衡。简单的模型拥有很好的解释性,但是准确性不高;而复杂的模型提高模型准确性的同时又牺牲了模型的可解释性。使用简单的模型解释复杂的模型是当前模型解释的核心方法之一。</p>
<p>目前,我们线上模型排序使用的是 XGBoost 模型。但在 XGBoost 模型中,传统的基于特征重要性的模型解释方法,只能从整体上对每个特征给出一个重要性的衡量,不支持对模型的局部输出解释,或者说单样本模型输出解释。在这样的背景下,我们的模型解释模块使用了新的模型解释方法 Shap 和 Lime,不仅支持特征的重要性,也支持模型的局部解释,使我们可以了解到在单个样本中,某个特征的某个取值对模型的输出可以起到何种程度的正向或负向作用。</p>
<p>下面通过一个从实际场景中简化的示例来介绍模型解释的核心功能。首先介绍一下几个特征的含义:</p>
<p><img src="/img/remote/1460000020966732" alt="" title=""></p>
<p><img src="/img/remote/1460000020966733" alt="" title=""></p>
<p>我们的模型解释会对单个样本给出以下的分析:</p>
<ul><li><em>U0_-_I1</em></li></ul>
<p><img src="/img/remote/1460000020966734" alt="" title=""></p>
<ul><li><em>U0_-_I2</em></li></ul>
<p><img src="/img/remote/1460000020966735" alt="" title=""></p>
<ul><li><em>U0_-_I3</em></li></ul>
<p><img src="/img/remote/1460000020966736" alt="" title=""></p>
<p>如图所示,模型对单个样本 <em>U0_-_I2_,_U0_-_I3_的预测值为 0.094930, 0.073473, 0.066176。针对单个样本的预测,各个特征值起到多大的正负向作用可以从图中的特征条形带的长度看出,红色代表正向作用,蓝色代表负向作用。这个值是由下表中的 shap_value 值决定的:</em></p>
<p><img src="/img/remote/1460000020966738" alt="" title=""></p>
<p><img src="/img/remote/1460000020966739" alt="" title=""></p>
<p>其中,<code>logit_output_value = 1.0 / (1 + np.exp(-margin_output_value)),logit_base_value = 1.0 / (1 + np.exp(-margin_base_value))</code>,output_value 是 XGBoost 模型输出值;base_value 是模型期望输出;近似等于整个训练集中模型预测值的均值;shap_value 是对该特征对预测结果起到的正负向作用的一个衡量。</p>
<p>模型预测值logit_output_value,0.094930>0.073473>0.066176,所以排序结果为 <em>I1</em>> <em>I2_>_I3_,_U0_-_I1</em> 的预测值为0.094930,特征 doubleFlow_article_ctr_7_v1=_I1_ctr起到了 0.062029 的正向作用,使得预测值相较于基值,有增加的趋势。同理,ui_cosine_70=0.894006,起到了 0.188769 的正向作用。</p>
<p>直观上我们可以看出,内容 7 天点击率以及用户-内容相似度越高,模型预测值越高,这也是符合预期的。实际场景中,我们会有更多的特征。</p>
<p>Shap 模型解释最核心的功能是支持局部单样本分析,当然它也支持全局的分析,如特征重要性,特征正负向作用,特征交互等。下图是对特征 doubleFlow_article_ctr_7_v1 的分析,可以看出,内容 7 天点击率小于阈值对模型的预测起负向作用,大于阈值对模型的预测起正向作用。</p>
<p><img src="/img/remote/1460000020966740" alt="" title=""></p>
<h2>Part.3 近期规划</h2>
<p>近期,排序算法平台将继续提升训练模型的线上应用效果,并把特征的实时作为工作重点,快速反映线上的变化。</p>
<p>当前排序算法平台使用的 XGBoost 模型优点是不需要太多的特征工程,包括特征缺失值处理、连续特征离散化、交叉特征构建等。但也存在许多不足,包括:</p>
<ol>
<li>很难处理高纬稀疏特征</li>
<li>需要加载完整的数据集到内存进行模型的训练,不支持在线学习算法,很难实现模型的实时更新。</li>
</ol>
<p>针对这些问题,后期我们将进行 Wide&Deep,DeepFM 等深度模型的建设,如下图所示:</p>
<p><img src="/img/remote/1460000020966741" alt="" title=""></p>
<p>另外,当前的模型每次都是预测单个 Item 的分数,然后进行排序取一刷的结果,(Learning to rank,pointwise)。后期我们希望可以实现一次给用户推荐一刷的结果(Learning to rank,listwise),给用户带来更加实时、准确的推荐结果。</p>
<p><strong>本文作者:夏鼎新、王磊,马蜂窝推荐算法平台研发工程师。</strong></p>
<p><img src="/img/remote/1460000020966742" alt="" title=""></p>
马蜂窝 IM 移动端架构的从 0 到 1
https://segmentfault.com/a/1190000020761250
2019-10-22T10:44:23+08:00
2019-10-22T10:44:23+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
31
<p><em>(马蜂窝技术原创内容,公众号 ID:mfwtech)</em></p>
<p>移动互联网技术改变了旅游的世界,这个领域过去沉重的信息分销成本被大大降低。用户与服务供应商之间、用户与用户之间的沟通路径逐渐打通,沟通的场景也在不断扩展。这促使所有的移动应用开发者都要从用户视角出发,更好地满足用户需求。</p>
<p>论坛时代的马蜂窝,用户之间的沟通形式比较单一,主要为单纯的回帖回复等。为了以较小的成本快速满足用户需求,当时采用的是非实时性消息的方案来实现用户之间的消息传递。</p>
<p>随着行业和公司的发展,马蜂窝确立了「内容+交易」的独特商业模式。在用户规模不断增长及业务形态发生变化的背景下,为用户和商家提供稳定可靠的售前和售后技术支持,成为电商移动业务线的当务之急。</p>
<h2>一、设计思路与整体架构</h2>
<p>我们结合 B2C,C2B,C2C 不同的业务场景设计实现了马蜂窝旅游移动端中的私信、用户咨询、用户反馈等即时通讯业务;同时为了更好地为合作商家赋能,在马蜂窝商家移动端中加入与会话相关的咨询用户管理、客服管理、运营资源统计等功能。</p>
<p>目前 IM 涉及到的业务如下:</p>
<p><img src="/img/remote/1460000020761253" alt="" title=""></p>
<p>为了实现马蜂窝旅游 App 及商家 IM 业务逻辑、公共资源的整合复用及 UI 个性化定制,将问题拆解为以下部分来解决:</p>
<ol>
<li>IM 数据通道与异常重连机制,解决不同业务实时消息下发以及稳定性保障;</li>
<li>IM 实时消息订阅分发机制,解决消息定向发送、业务订阅消费,避免不必要的请求资源浪费;</li>
<li>IM 会话列表 UI 绘制通用解决方案,解决不同消息类型的快速迭代开发和管理复杂问题;</li>
</ol>
<p>整体实现结构分为 4 个部分进行封装,分别为下图中的数据管理、消息注册分发管理、通用 UI 封装及业务管理。</p>
<p><img src="/img/remote/1460000020761254" alt="" title=""></p>
<h2>二、技术原理和实现过程</h2>
<h3>2.1 通用数据通道</h3>
<p>对于常规业务展示数据的获取,客户端需要主动发起请求,请求和响应的过程是单向的,且对实时性要求不高。但对于 IM 消息来说,需要同时支持接收和发送操作,且对实时性要求高。为支撑这种要求,客户端和服务器之间需要创建一条稳定连接的数据通道,提供客户端和服务端之间的双向数据通信。</p>
<h4><strong>2.1.1 数据通道基础交互原理</strong></h4>
<p>为了更好地提高数据通道对业务支撑的扩展性,我们将所有通信数据封装为外层结构相同的数据包,使多业务类型数据使用共同的数据通道下发通信,统一分发处理,从而减少通道的创建数量,降低数据通道的维护成本。</p>
<p><img src="/img/remote/1460000020761255" alt="" title=""></p>
<p>常见的客户端与服务端数据交互依赖于 HTTP 请求响应过程,只有客户端主动发起请求才可以得到响应结果。结合马蜂窝的具体业务场景,我们希望建立一种可靠的消息通道来保障服务端主动通知客户端,实现业务数据的传递。目前采用的是 HTTP 长链接轮询的形式实现,各业务数据消息类型只需遵循约定的通用数据结构,即可实现通过数据通道下发给客户端。数据通道不必关心数据的具体内容,只需要关注接收与发送。</p>
<h4><strong>2.1.2 客户端数据通道实现原理</strong></h4>
<p>客户端数据通道管理的核心是维护一个业务场景请求栈,在不同业务场景切换过程中入栈不同的业务场景参数数据。每次 HTTP 长链接请求使用栈顶请求数据,可以模拟在特定业务场景 (如与不同的用户私信) 的不同处理。数据相关处理都集中封装在数据通道管理中,业务层只需在数据通道管理中注册对应的接收处理即可得到需要的业务消息数据。</p>
<p><img src="/img/remote/1460000020761257" alt="" title=""></p>
<h3>2.2 消息订阅与分发</h3>
<p>在软件系统中,订阅分发本质上是一种消息模式。非直接传递消息的一方被称为「发布者」,接受消息处理称为「订阅者」。发布者将不同的消息进行分类后分发给对应类型的订阅者,完成消息的传递。应用订阅分发机制的优势为便于统一管理,可以添加不同的拦截器来处理消息解析、消息过滤、异常处理机制及数据采集工作。</p>
<h4><strong>2.2.1 消息订阅</strong></h4>
<p>业务层只专注于消息处理,并不关心消息接收分发的过程。订阅的意义在于更好地将业务处理和数据通道处理解耦,业务层只需要订阅关注的消息类型,被动等待接收消息即可。</p>
<p><img src="/img/remote/1460000020761258" alt="" title=""></p>
<p>业务层订阅需要处理的业务消息类型,在注册后会自动监控当前页面的生命周期,并在页面销毁后删除对应的消息订阅,从而避免手动编写成对的订阅和取消订阅,降低业务层的耦合,简化调用逻辑。订阅分发管理会根据各业务类型维护订阅者队列用于消息接收的分发操作。</p>
<h4><strong>2.2.2 消息分发</strong></h4>
<p>数据通道的核心在于维护多消息类型各自对应的订阅者集合,并将解析的消息分发到业务层。</p>
<p><img src="/img/remote/1460000020761259" alt="" title=""></p>
<p>数据通道由多业务消息共用,在每次请求收到新消息列表后,根据各自业务类型重新拆分成多个消息列表,分发给各业务类型对应的订阅处理器,最终传递至业务层交予对应页面处理展示。</p>
<h3>2.3 会话消息列表绘制</h3>
<p>基于不同的场景,如社交为主的私信、用户服务为主的咨询反馈等,都需要会话列表的展示形式;但各场景又不完全相同,需要分析当前会话列表的共通性及可封装复用的部分,以更好地支撑后续业务的扩展。</p>
<h4><strong>2.3.1 消息在列表展示的组成结构</strong></h4>
<p>IM 消息列表的特点在于消息类型多、UI 展示多样化,因此需要建立各类型消息和布局的对应关系,在收到消息后根据消息类型匹配到对应的布局添加至对应消息列表。</p>
<p><img src="/img/remote/1460000020761260" alt="" title=""></p>
<h4><strong>2.3.2 消息类型与展示布局管理原理</strong></h4>
<p>对于不同消息类型及展示,问题的核心在于建立<strong>消息类型、消息数据结构、消息展示布局管理</strong>的映射关系。以上三者在实现过程中通过建立映射管理表来维护,各自建立列表存储消息类型/消息体封装结构/消息展示布局管理,设置对应关系关联 3 个列表来完成查找。 </p>
<p><img src="/img/remote/1460000020761261" alt="" title=""></p>
<h4><strong>2.3.3 一次收发消息 UI 绘制过程</strong></h4>
<p>各类型消息在内容展示上各有不同,但整体会话消息展示样式可以分为 3 种,分别是<strong>接收消息、发送消息和处于页面中间的消息样式,</strong>区别只在于内部的消息样式。所以消息 UI 的绘制可以拆分成 2 个步骤,首先是创建通用的展示容器,然后再填充各消息具体的展示样式。</p>
<p><img src="/img/remote/1460000020761262" alt="" title=""></p>
<p>拆分的目的在于使各类型消息 UI 处理只需要关注特有数据。而如通用消息如头像、名称、消息时间、是否可举报、已读未读状态、发送失败/重试状态等都可以统一处理,降低修改维护的成本,同时使各消息 UI 处理逻辑更少、更清晰,更利于新类型的扩展管理。</p>
<p>收发到消息后,根据消息类型判断是「发送接收类型」还是「居中展示类型」,找到外层的布局样式,再根据具体消息类型找到特有的 UI 样式,拼接在外层布局中,得到完整的消息卡片,然后设置对应的数据渲染到列表中,完成整个消息的绘制。</p>
<h2>三、细节优化 & 踩坑经验</h2>
<p>在实现上述 IM 系统的过程中,我们遇到了很多问题,也做了很多细节优化。在这里总结实现时需要考虑的几点,以供大家借鉴。</p>
<h3>3.1 消息去重</h3>
<p>在前面的架构中,我们使用 msg_id 来标记消息列表中的每一条消息,msg_id 是根据客户端上传的数据,进行存储后生成的。</p>
<p><img src="/img/remote/1460000020761263" alt="" title=""><img src="/img/remote/1460000020761264" alt="" title=""></p>
<p>客户端 A 请求 IM 服务器之后生成 msg_id,再通过请求返回和 Polling 分发到客户端 A 和客户端 B。当流程成立的时候,客户端 A 和客户端 B 通过服务端分发的 msg_id 来进行本地去重。但这种方案存在以下问题:</p>
<p><img src="/img/remote/1460000020761265" alt="" title=""></p>
<p>当客户端 A 因为网络出现问题,无法接受对应发送消息的请求返回的时候,会触发重发机制。此时虽然 IM 服务器已经接受过一次客户端 A 的消息发送请求,但是因为无法确定两个请求是否来自同一条原始消息,只能再次接受,这就导致了重复消息的产生。解决的方法是引入客户端消息标识 id。因为我们已经依附旧有的 msg_id 做了很多工作,不打算让客户端的消息 id 代替 msg_id 的职能,因此重新定义一个 random_id。</p>
<p><img src="/img/remote/1460000020761266" alt="" title=""></p>
<p>random_id = random + time_stamp。random_id 标识了唯一的消息体,由一个随机数和生成消息体的时间戳生成。当触发重试的时候,两次请求的 random_id 会是相同的,服务端可以根据该字段进行消息去重。</p>
<h3>3.2 本地化 Push</h3>
<p>当我们在会话页或列表页的环境下,可以通过界面的变化很直观地观察到收取了新消息并更新未读数。但从会话页或者列表页退出之后,就无法单纯地从界面上获取这些信息,这时需要有其他的机制,让用户获知当前消息的状态。</p>
<p>系统推送与第三方推送是一个可行的选择,但本质上推送也是基于长链接提供的服务。为弥补推送不稳定性与风险,我们采用数据通道+本地通知的形式来完善消息通知机制。通过数据通道下发的消息如需达到推送的提示效果,则携带对应的 Push 展示数据。同时会对当前所处的页面进行判断,避免对当前页面的消息内容进行重复提醒。</p>
<p><img src="/img/remote/1460000020761267" alt="" title=""></p>
<p>通过这种<strong>数据通道+本地通知</strong>展示的机制,可以在应用处于运行状态的时间内提高消息抵达率,减少对于远程推送的依赖,降低推送系统的压力,并提升用户体验。</p>
<h3>3.3 数据通道异常重连机制</h3>
<p>当前数据通道通过 HTTP 长链接轮询 (Polling) 实现。不同业务场景下对 Polling 的影响如下图所示:</p>
<p><img src="/img/remote/1460000020761268" alt="" title=""></p>
<p>由于用户手机所处网络请求状态不一,有时候会遇到网络中断或者服务端异常的情况,从而终止 Polling 的请求。为能够让用户在网络恢复后继续会话业务,需要引入重连机制。</p>
<p>在重试机制 1.0 版本中,对于可能出现较多重试请求的情况,采取的是添加 60s 内连续 5 次报错延迟重试的限制。具体流程如下:</p>
<p><img src="/img/remote/1460000020761269" alt="" title=""></p>
<p>在实践中发现以下问题:</p>
<ul>
<li>当服务端突然异常并持续超过 1 分钟后,客户端启动执行重试机制,并每隔 1 分钟重发一次重连请求。这对服务器而言就相当于遭受一次短暂集中的「攻击」,甚至有可能拖垮服务器。</li>
<li>当客户端断网后立刻进行重试也并不合理,因为用户恢复网络也需要一定时间,这期间的重连请求是无意义的。</li>
</ul>
<p>基于以上问题分析改进,我们设计了第二版重试机制。此次将 5 次以下请求错误的延迟时间修改为 5 - 20 秒随机重试,将客户端重试请求分散在多个时间点避免同时请求形成对服务器对瞬时压力。同时在客户端断网情况下也进行延迟重试。</p>
<p><img src="/img/remote/1460000020761270" alt="" title=""></p>
<p>Polling 机制修改后请求量划分,相对之前请求分布比较均匀,不再出现集中请求的问题。</p>
<p><img src="/img/remote/1460000020761271" alt="" title=""></p>
<h3>3.4 唯一会话标识</h3>
<h4><strong>3.4.1 为何引入消息线 ID</strong></h4>
<p>消息线就是用来表示会话的聊天关系,不同消息线代表不同对象的会话,从 DB 层面来看需要一个张表来存储这种关系 uid + object_id + busi_type = 消息线 ID。</p>
<p><img src="/img/remote/1460000020761272" alt="" title=""></p>
<p>在 IM 初期实现中,我们使用会话配置参数(包含业务来源和会话参数)来标识会话 id,有三个作用:</p>
<ul>
<li>查找商家 id,获取咨询来源,进行管家分配</li>
<li>查找已存在的消息线</li>
<li>判断客户端页面状态,决定要不要下发推送,进行消息提醒</li>
</ul>
<p>这种方式存在两个问题:</p>
<ul>
<li>通过业务来源和会话参数来解析对应的商家 id,两个参数缺失一个都会导致商家 id 解析错误,还要各种查询数据库才能得到商家 id,影响效率;</li>
<li>通过会话类型切换接口标识当前会话类型,切换页面会频繁触发网络请求;如果请求接口发生意外容易引发消息内容错误问题,严重依赖客户端的健壮性</li>
</ul>
<p>用业务来源和会话参数帮助我们进行管家分配是不可避免的,但我们可以通过引入消息线 ID 来绑定消息线的方式,替代业务来源和会话参数查找消息线的作用。另外针对下发推送的问题已通过上方讲述的本地推送通知机制解决。</p>
<h4><strong>3.4.2 何时创建消息线</strong></h4>
<ul>
<li>当进入会话页发消息时,检查 DB 中是否存在对应消息线,不存在则将这条消息 id 当作消息线 id 使用,存在即复用。</li>
<li>当进入会话时,根据用户 id 、业务类型 id 等检查在 DB 中是否已存在对应消息线,不存在则创建消息线,存在即复用。</li>
</ul>
<h4><strong>3.4.3 引入消息线目的</strong></h4>
<ul>
<li>减少服务端查询消息线的成本。</li>
<li>移除旧版状态改变相关的接口请求,间接提高了推送触达率。</li>
<li>降低移动端对于用户消息匹配的复杂度。</li>
</ul>
<h2>四、展望及近期优化</h2>
<h3>4.1 数据通道实现方式升级为 Websocket</h3>
<p>WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。</p>
<p>与目前的 HTTP 轮询实现机制相比, Websocket 有以下优点:</p>
<ul>
<li>
<strong>较少的控制开销</strong>。在连接创建后,服务器和客户端之间交换数据时,用于协议控制的数据包头部相对较小。在不包含扩展的情况下,对于服务器到客户端的内容,此头部大小只有 2 至 10 字节(和数据包长度有关);对于客户端到服务器的内容,此头部还需要加上额外的 4 字节的掩码。相对于 HTTP 请求每次都要携带完整的头部,开销显著减少。</li>
<li>
<strong>更强的实时性</strong>。由于协议是全双工的,服务器可以随时主动给客户端下发数据。相对于 HTTP 需要等待客户端发起请求服务端才能响应,延迟明显更少;即使是和 Comet 等类似的长轮询比较,其也能在短时间内更多次地传递数据。</li>
<li>
<strong>保持连接状态</strong>。与 HTTP 不同的是,Websocket 需要先创建连接,这就使其成为一种有状态的协议,在之后通信时可以省略部分状态信息。而 HTTP 请求可能需要在每个请求都携带状态信息(如身份认证等)。</li>
<li>
<strong>更好的二进制支持</strong>。Websocket 定义了二进制帧,相对 HTTP,可以更轻松地处理二进制内容。</li>
<li>
<strong>支持扩展</strong>。Websocket 定义了扩展,用户可以扩展协议、实现部分自定义的子协议,如部分浏览器支持压缩等。</li>
<li>
<strong>更好的压缩效果</strong>。相对于 HTTP 压缩,Websocket 在适当的扩展支持下,可以沿用之前内容的上下文,在传递类似的数据时,可以显著地提高压缩率。</li>
</ul>
<p>为了进一步优化我们的数据通道设计,我们探索验证了 Websocket 的可行性,并进行了调研和设计:</p>
<p><img src="/img/remote/1460000020761273" alt="" title=""></p>
<p>近期将对 HTTP 轮询实现方案进行替换,进一步优化数据通道的效率。</p>
<h3>4.2 业务功能的扩展</h3>
<p>计划将 IM 移动端功能模块打造成通用的即时通讯组件,能够更容易地赋予各业务 IM 能力,使各业务快速在自有产品线上添加聊天功能,降低研发 IM 的成本和难度。目前的 IM 功能实现主要有两个组成,分别是公用的数据通道与 UI 组件。</p>
<p>随着马蜂窝业务发展,在现有 IM 系统上还有很多可以建设和升级的方向。比如消息类型的支撑上,扩展对短视频、语音消息、快捷消息回复等支撑,提高社交的便捷性和趣味性;对于多人场景希望增加群组,兴趣频道,多人音视频通信等场景的支撑等。</p>
<p>相信未来通过对更多业务功能的扩展及应用场景的探索,马蜂窝移动端 IM 将更好地提升用户体验,并持续为商家赋能。</p>
<p><strong>本文作者:马蜂窝电商业务 IM 移动端研发团队。</strong></p>
<p>(马蜂窝技术原创内容)</p>
<p><img src="/img/remote/1460000020761274" alt="" title=""></p>
马蜂窝数据仓库的架构、模型与应用实践
https://segmentfault.com/a/1190000020613071
2019-10-08T14:48:57+08:00
2019-10-08T14:48:57+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
3
<p><em>(马蜂窝技术原创内容,公众号ID:mfwtech)</em></p>
<h2>一、马蜂窝数据仓库与数据中台</h2>
<p>最近几年,数据中台概念的热度一直不减。2018 年起,马蜂窝也开始了自己的数据中台探索之路。</p>
<p>数据中台到底是什么?要不要建?和数据仓库有什么本质的区别?相信很多企业都在关注这些问题。</p>
<p>我认为数据中台的概念非常接近传统数据仓库+大数据平台的结合体。它是在企业的数据建设经历了数据中心、数据仓库等积累之后,借助平台化的思路,将数据更好地进行整合与统一,以组件化的方式实现灵活的数据加工与应用,以更清晰的数据职能组织应对业务的快速变化,以服务的方式更好地释放数据价值的一种方式。</p>
<p>所以,数据中台更多的是体现一种管理思路和架构组织上的变革。在这样的思想下,我们结合自身业务特点建设了马蜂窝的数据中台,核心架构如下:</p>
<p><img src="/img/remote/1460000020613074" alt="" title=""></p>
<p>在中台建设之前,马蜂窝已经建立了自己的大数据平台,并积累了一些通用、组件化的工具,这些可以支撑数据中台的快速搭建。作为中台的另一大核心部分,马蜂窝数据仓库主要承担数据统一化建设的工作,包括统一数据模型,统一指标体系等。下面介绍马蜂窝在数据仓库建设方面的具体实践。</p>
<h2>二、数据仓库核心架构</h2>
<p>马蜂窝数据仓库遵循标准的三层架构,对数据分层的定位主要采取维度模型设计,不会对数据进行抽象打散处理,更多注重业务过程数据整合。现有数仓主要以离线为主,整体架构如下:</p>
<p><img src="/img/remote/1460000020613075" alt="" title=""><img src="/img/remote/1460000020613076" alt="" title=""></p>
<p>如图所示,共分为 3 层:<strong>业务数据层、公共数据层与应用数据层</strong>,每层定位、目标以及建设原则各不相同。</p>
<p><strong>(1)业</strong><strong>务数据层</strong>:包含 STG(数据缓冲层)与 ODS(操作数据层)两层,这两层数据结构与业务数据几乎一致。</p>
<ul>
<li>
<strong>STG</strong>:也叫数据准备区,定位是缓存来自 DB 抽取、消息、日志解析落地的临时数据,结构与业务系统保持一致;负责对垃圾数据、不规范数据进行清洗转换;该层只为 ODS 层服务;</li>
<li>
<strong>ODS</strong>:操作数据层定位于业务明细数据保留区,负责保留数据接入时点后历史变更数据,数据原则上全量保留。模型设计依据业务表数据变更特性采取拉链、流水表两种形式。</li>
</ul>
<p><strong>(2)公共数据层</strong>:细分为 DWD(明细数据层)、DWS(汇总数据层)、DIM(公共维度层) 三层,主要用于加工存放整合后的明细业务过程数据,以及经过轻度或重度汇总粒度公共维度指标数据。公共数据层作为仓库核心层,定位于业务视角,提炼出对数据仓库具有共性的数据访问、统计需求,从而构建面向支持应用、提供共享数据访问服务的公共数据。</p>
<ul>
<li>
<strong>DWD</strong>:这一层是整合后的业务过程明细数据,负责各业务场景垂直与水平数据整合、常用公共维度冗余加工,以及明细业务标签信息加工;</li>
<li>
<strong>DWS</strong>:汇总数据层按照主题对共性维度指标数据进行轻度、高度聚合;</li>
<li>
<strong>DIM</strong>:对维度进行统一标准化定义,实现维度信息共享。</li>
</ul>
<p><strong>(3)应用数据层</strong>:DWA 层,主要用于各产品或各业务条线个性化的数据加工,例如商业化产品数据、搜索推荐,风控等。</p>
<h2>三、数据模型设计</h2>
<h3>3.1 方法选择</h3>
<p>数据模型是对现实世界数据特征的抽象,数据模型的设计方法就是对数据进行归纳和概括的方法。目前业界主要的模型设计方法论有两种,一是数据仓库之父 Bill Inmon 提出的<strong>范式建模</strong>方法,又叫 ER 建模,主张站在企业角度自上而下进行数据模型构建;二是 Ralph Kimball 大师倡导的<strong>维度建模</strong>方法,主张从业务需求出发自下而上构建数据模型。</p>
<p>大数据环境下,业务系统数据体系庞杂,数据结构多样、变更频繁,并且需要快速响应各种复杂的业务需求,以上两种传统的理论都已无法满足互联网数仓需求。在此背景下,马蜂窝数据仓库采取了「以需求驱动为主、数据驱动为辅」的混合模型设计方式,来根据不同的数据层次选择模型。主要从以下四个方面综合考虑:</p>
<p><strong>1. 面向主题</strong>:采用范式模型理论中的主题划分方法对业务数据进行分类。</p>
<p><strong>2. 一致性保证:</strong>采用维度模型理论中的总线结构思想,建立统一的一致性维度表和一致性事实表来保证一致性。</p>
<p><strong>3. 数据质量保证</strong>:无论范式建模还是维度建模都非常重视数据质量问题,综合使用两个理论中的方法保证数据质量。</p>
<p><strong>4. 效率保证</strong>:合理采取维度退化、变化维、增加冗余等方法,保证数据的计算和查询效率。</p>
<p><img src="/img/remote/1460000020613077" alt="" title=""><img src="/img/remote/1460000020613078" alt="" title=""></p>
<p>其中,ODS 选择保持贴源的范式模型,不做进一步模型抽象,只是从节省存储角度考虑,对该层采取拉链处理。DWD 与 DWS 基于对构建成本、性能,易用性角度的考虑,主要采取维度模型和一些宽表模型。宽表模型的本质是基于维度模型的扩展,对整个业务以及全节点信息进行垂直与水平方式整合;同时采用退化维度的方式,将不同维度的度量放入数据表的不同列中,实现业务全流程视图的构建,来提升宽表模型的易用性、查询效率,且易于模型的扩展。</p>
<ul>
<li>
<strong>水平整合</strong>:水平整合就是将同一业务多数据源的数据整合到一个模型中,如果多数据源业务数据存在交集,则需要按照预设的业务规则选取一份保留,避免整合后的业务数据交叉。例如商品数据如果未进行主数据管理,不同业务线的商品信息就会散落在各业务系统表中,无法满足企业级的数据分析需求,这时就需要将这些商品数据按照业务主题进行水平整合。</li>
<li>
<strong>垂直整合</strong>:一次完整的业务流转通常要经历多个环节,各节点信息产生的时点不同、储存的数据表不同。垂直整合就是将同一业务中各关键节点信息整合至业务全流程宽表模型中。马蜂窝订单交易模型的构建就采用了这种方式,下文将进行详细介绍。</li>
</ul>
<h3>3.2 设计目标</h3>
<p>马蜂窝数据仓库在模型设计上以准确性、易用性、及时性为设计目标,以满足业务人员对数据的多样需求。</p>
<ul>
<li>
<strong>准确性</strong>:数据质量管控要在建模过程中落地,为数据准确性保驾护航。</li>
<li>
<strong>易用性</strong>:兼顾模型的可扩展性和可理解性。</li>
<li>
<strong>及时性</strong>:充分考虑模型的使用效率,提供方便快捷的数据查询和数据计算服务。</li>
</ul>
<h3>3.3 设计流程</h3>
<p>马蜂窝数仓模型设计的整体流程涉及需求调研、模型设计、开发测试、模型上线四个主要环节,且规范设计了每个阶段的输出与输入文档。</p>
<p><img src="/img/remote/1460000020613079" alt="" title=""></p>
<ol>
<li>
<strong>需求调研</strong>:收集和理解业务方需求,就特定需求的口径达成统一,在对需求中涉及到的业务系统或系统模块所承担的功能进行梳理后进行表字段级分析,并对数据进行验证,确保现有数据能够支持业务需求。</li>
<li>
<strong>模型设计</strong>:根据需求和业务调研结果对模型进行初步归类,选择合适的主题域进行模型存放;确定主题后进入数据模型的设计阶段,逻辑模型设计过程要考虑总线结构构建、模型规范定义等关键问题;物理模型设计以逻辑模型为基础,兼顾存储性能等因素对逻辑模型做的物理化的过程,是逻辑模型的最终物理实现.物理模型在一般情况下与逻辑模型保持一致,模型设计完成后需要进入评审与 Mapping 设计。</li>
<li>
<strong>模型开发</strong>:就是对模型计算脚本的代码实现过程,其中包含了数据映射、脚本实现、测试验证等开发过程。单元测试完成后需要通知业务方一起对模型数据进行业务验证,对验证问题做收集,返回验证模型设计的合理性。</li>
<li>
<strong>模型上线</strong>:完成验证后的模型就可以在线上生产环境进行部署。上线后需要为模型配置监控,及时掌握为业务提供数据服务的状况。我们还将模型的实体和属性说明文档发布给仓库数据的使用者,使模型得到更好地应用。</li>
</ol>
<h3>3.4 主题分类</h3>
<p>基于对目前各个部门和业务系统的梳理,马蜂窝数据仓库共设计了 4 个大数据域(交易、流量、内容、参与人),细分为 11 个主题:</p>
<p><img src="/img/remote/1460000020613080" alt="" title=""><img src="/img/remote/1460000020613081" alt="" title=""></p>
<p>以马蜂窝订单交易模型的建设为例,基于业务生产总线的设计是常见的模式,即首先调研订单交易的完整过程,定位过程中的关键节点,确认各节点上发生的核心事实信息。模型是数据的载体,我们要做的就是通过模型(或者说模型体系)归纳生产总线中各个节点发生的事实信息。</p>
<p>订单生产总线:</p>
<p><img src="/img/remote/1460000020613082" alt="" title=""></p>
<p>如上图所示,我们需要提炼各节点的核心信息,为了避免遗漏关键信息,一般情况下抽象认为节点的参与人、发生时间、发生事件、发生协议属于节点的核心信息,需要重点获取。以下单节点为例,参与人包括下单用户、服务商家、平台运营人员等;发生时间包括用户的下单时间、商家的确认时间等;发生的事件即用户购买了商品,需要记录围绕这一事件产生的相关信息;发生协议即产生的订单,订单金额、约定内容等都是我们需要记录的协议信息。</p>
<p>在这样的思路下,总线架构可以在模型中不断添加各个节点的核心信息,使模型支撑的应用范围逐步扩展、趋于完善。因此,对业务流程的理解程度将直接影响产出模型的质量。</p>
<p>涉及的业务节点越多,业务流程也就越复杂。从数据的角度看,这些业务过程会产生两种基本的场景形态,即数据的拆分和汇聚。随着流程的推进,前一节点的原子业务单位在新节点中可能需要拆分出更多信息,或者参与到新节点的多向流程。同样,也可能发生数据的汇聚。以某个订单为例,下单节点数据是订单粒度的,而到支付节点就发生了数据拆分。数据的拆分、汇聚伴随着总线的各节点,可能会一直发散下去。</p>
<p><img src="/img/remote/1460000020613083" alt="" title=""></p>
<p>鉴于上述情况,在模型实现过程中,我们不能把各节点不同粒度的数据信息都堆砌在一起,那样会产生大量的冗余信息,也会使模型本身的定位不清晰,影响使用。因此,需要输出不同粒度的模型来满足各类应用需求。例如既会存在订单粒度的数据模型,也会存在分析各个订单在不同时间节点状态信息的数据模型。</p>
<p><img src="/img/remote/1460000020613084" alt="" title=""></p>
<p><img src="/img/remote/1460000020613085" alt="" title=""></p>
<p>基于维度建模的思路,在模型整合生产总线各节点核心信息之后,会根据这些节点信息进一步扩展常用的分析维度,以减少应用层面频繁关联相关分析维度带来的资源消耗,模型会反范式冗余相关维度信息,以获取应用层的使用便捷。最终建立一个整合旅游、交通、酒店等各业务线与各业务节点信息的马蜂窝全流程订单模型。</p>
<h2>四、数据仓库工具链建设</h2>
<p>为提升数据生产力,马蜂窝数据仓库建立了一套工具链,来实现采集、研发、管理流程的自动化。现阶段比较重要的有以下三大工具:</p>
<h3>1. 数据同步工具</h3>
<p>同步工具主要解决两个问题:</p>
<ul>
<li>从源系统同步数据到数据仓库 </li>
<li>将数据仓库的数据同步至其他环境</li>
</ul>
<p>下面重点介绍从源系统同步数据到数据仓库。</p>
<p>马蜂窝的数据同步设计支撑灵活的数据接入方式,可以选择抽取方式以及加工方式。抽取方式主要包括增量抽取或者全量抽取,加工方式面向数据的存储方式,是需要对数据进行拉链式保存,或者以流水日志的方式进行存储。</p>
<p>接入时,只需要填写数据表信息配置以及具体的字段配置信息,数据就可以自动接入到数据仓库,形成数仓的 ODS 层数据模型,如下:</p>
<p><img src="/img/remote/1460000020613086" alt="" title=""></p>
<p><img src="/img/remote/1460000020613087" alt="" title=""></p>
<p><img src="/img/remote/1460000020613088" alt="" title=""></p>
<h3>2. 任务调度平台</h3>
<p>我们使用 Airflow 配合自研的任务调度系统,不仅能支持常规的任务调度,还可以支持任务调度系统各类数据重跑,历史补数等需求。</p>
<p>别小看数据重跑、历史补数,这两项功能是在选择调度工具中重要的参考项。做数据的人都清楚,在实际数据处理过程中会面临诸多的数据口径变化、数据异常等,需要进行数据重跑、刷新、补数等操作。</p>
<p>我们设计的「一键重跑」功能,可以将相关任务依赖的后置任务全部带出,并支持选择性地删除或虚拟执行任意节点的任务:</p>
<ul>
<li>如果选择删除,这该任务之后所依赖的任务均不执行</li>
<li>如果选择虚拟执行,则会忽略(空跑)掉该任务,后置的所有依赖任务还是会正常执行。</li>
</ul>
<p>如下是基于某一个任务重跑下游所有任务所列出的关系图,选中具体的执行节点,就可以执行忽略或者删除。</p>
<p><img src="/img/remote/1460000020613089" alt="" title=""></p>
<h3>3. 元数据管理工具</h3>
<p>元数据范畴包括技术元数据、业务元数据、管理元数据,在概念上不做过多阐述了。元数据管理在数据建设起着举足轻重的作用,这部分在数仓应用中主要有 2 个点:</p>
<p><strong>(1)血缘管理</strong></p>
<p>血缘管理可以追溯数据加工整体链路,解析表的来龙去脉,用于支撑各类场景,如:</p>
<ul>
<li>支持上游变更对下游影响的分析与调整</li>
<li>监控各节点、各链路任务运行成本,效率</li>
<li>监控数据模型的依赖数量,确认哪些是重点模型</li>
</ul>
<p>如下是某一个数据模型中的血缘图,上下游以不同颜色进行呈现:</p>
<p><img src="/img/remote/1460000020613091" alt="" title=""></p>
<p><img src="/img/remote/1460000020613092" alt="" title=""></p>
<p><strong>(2)数据知识管理</strong></p>
<p>通过对技术、业务元数据进行清晰、详尽地描述,形成数据知识,给数据人员提供更好的使用向导。我们的数据知识主要包括实体说明与属性说明,具体如下:</p>
<p><img src="/img/remote/1460000020613093" alt="" title=""></p>
<p><img src="/img/remote/1460000020613094" alt="" title=""><img src="/img/remote/1460000020613095" alt="" title=""></p>
<p><img src="/img/remote/1460000020613096" alt="" title=""></p>
<p>当然,数仓工具链条中还有非常多工具,例如自动化建模工具,数据质量管理工具,数据开发工具等,都已经得到了很好地实现。</p>
<h2>五、数仓应用——指标平台</h2>
<p>有了合理的数仓架构、工具链条支撑数据研发,接下来,就要考虑如何把产出的数据对外赋能。下面以马蜂窝数据应用利器-指标平台,进行简单介绍。</p>
<p>几乎所有的企业都会构建自己的指标平台,每个企业建立的标准都不一样。在这个过程中会遇到指标繁多、定义不清楚、查询缓慢等问题。为尽量避免这些问题,指标平台在设计时需要遵循几大原则:</p>
<ol>
<li>指标定义标准,清晰,容易理解,且不存在二义性,分类明确</li>
<li>指标生产过程简单、透明、可配置化</li>
<li>指标查询效率需要满足快速响应</li>
<li>指标权限管理灵活可控</li>
</ol>
<p>基于以上原则,马蜂窝的指标平台按照精细化的设计进行打造,指标平台组成架构如下图:</p>
<p><img src="/img/remote/1460000020613097" alt="" title=""></p>
<p>其中:</p>
<ol>
<li>数据仓库是指标数据的来源,所有指标目前都是通过数据仓库统一加工的</li>
<li>指标管理包括指标创建与指标元数据管理:数仓负责生产并创建最核心、最基础的指标;其他人员可以基于这些指标,按照规则进行指标的派生;元数据管理记录指标的具体来源路径,说明指标的数据来源是数仓表,或者是 Kylin,MySQL 或 ES</li>
<li>指标字典对外呈现指标的定义、口径、说明等,保证指标的透明化及可解释性</li>
<li>数据服务接受指标的查询请求,针对不同场景判断查询的成本,选择最优链路进行指标查询,并返回指标查询的结果</li>
<li>多维查询将可以提供查询服务的指标与维度通过界面呈现,用户可以基于维度选择指标或基于指标选择维度,查询具体需要的数据</li>
<li>权限管理贯彻始终,可以支持表级、指标级、维值级别的权限管理</li>
</ol>
<h2>六、总结</h2>
<p>企业的数据建设需要经历几个大的步骤:</p>
<ul>
<li>第一步,业务数据化:顾名思义,一切业务都能通过数据反映,主要指的是将传统线下流程线上化;</li>
<li>第二步,数据智能化:光有数据还不行,还需要足够的智能,如何通过智能化的数据支撑运营、营销及各类业务,这是数据中台当前解决的主要问题;</li>
<li>第三步,数据业务化:也就是我们常说的数据驱动业务,数据不能只是数据,数据价值最大化在于可以驱动新的业务创新,带动企业增长。</li>
</ul>
<p>目前大部企业目前都停留在第二个阶段,因为这一步需要足够夯实,才能为第三步打好基础,这也是为什么各大企业要投入很大成本到大数据平台、数据仓库乃至数据中台的建设中。</p>
<p>马蜂窝数据中台的建设才刚刚起步。我们认为,理想的数据中台需要具备<strong>数据标准化、工具组件化、组织清晰化</strong>这三个核心前提。为了向这一目标迈进,我们将建立统一、标准化的数据仓库作为当下数据中台的重点工作之一。</p>
<p>数据来源于业务,最终也将应用于业务。只有对数据足够重视,与业务充分衔接,才能实现数据价值的最大化。在马蜂窝,从管理层,到公司研发、产品、运营、销售等各角色,对数据非常重视,数据产品的使用人数占公司员工比例高达 75%。</p>
<p>大量用户的使用,驱动着我们在数据中台建设的路上不断前进。如何将新兴技术能力应用到数据仓库的建设,如何以有限的成本高效解决企业在数据建设中面临的问题,将是马蜂窝数仓建设一直的思考。</p>
<p><strong>本文作者:颜博,马蜂窝数据仓库研发负责人。</strong></p>
<p><img src="/img/remote/1460000020613098" alt="" title=""></p>
一种对开发更友好的前端骨架屏自动生成方案
https://segmentfault.com/a/1190000020309764
2019-09-06T14:33:35+08:00
2019-09-06T14:33:35+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
67
<p><strong><em>(马蜂窝技术原创内容,公众号 ID:mfwtech)</em></strong></p>
<p>一份来自 Akamai 的研究报告显示,在对 1048 名网购户进行采访后发现:</p>
<ul>
<li>约 47% 的用户期望他们的页面在两秒之内加载完成。</li>
<li>如果页面加载时间超过 3s,约 40% 的用户会选择离开或关闭页面。</li>
</ul>
<p><img src="/img/bVbxnDd?w=743&h=418" alt="" title=""></p>
<p>一直以来,为了提升用户在页面加载时的体验,无论是 Web 还是 iOS、Android 的应用中,前端开发工程师都做了许多工作。除了解决如何让网页展现速度更快的问题,还有很重要的一点就是提升用户对加载等待时间的感知。「菊花图」以及由其衍生出的各种加载动画就是一类常见的解决方案,相信无论是开发者还是用户对下面这个图标都不会陌生:</p>
<p><img src="/img/bVbxnDe?w=900&h=383" alt="" title=""></p>
<p>本文要介绍的「骨架屏」则被视为菊花图升级版的方案。受现有骨架屏方案的启发,马蜂窝电商前端研发团队实现了一种自动化生成骨架屏的方法,并在马蜂窝商城的多个页面中实现应用,取得了不错的效果。</p>
<h2>一、什么是骨架屏</h2>
<p>骨架屏可以理解为在页面数据尚未返回或页面未完成完全渲染前,先给用户呈现一个由灰白块组成的当前页面大致结构,让用户产生页面正在逐渐渲染的感受,从而使加载过程从视觉上变得流畅。生成后的骨架屏页面如下图所示:</p>
<p><img src="/img/bVbxnDl?w=154&h=266" alt="" title=""></p>
<p>骨架屏的主要优势为:</p>
<ol>
<li>用户避免看到长时间的白页</li>
<li>可以获知页面的大体结构,减小用户认为页面出错而离开的机率</li>
<li>与菊花图相比视觉更加流畅</li>
</ol>
<h2>二、常见的前端骨架屏方案</h2>
<p>在选择骨架屏之前,我们也考虑了一些其他的方法,比如能否通过服务端渲染(SSR)的方式来避开前端白屏时间的问题。但发现需要涉及项目过多,还会涉及服务的构建与部署;或是通过 prerender-spa-plugin 提供简单的预呈现,它对 SPA 支持友好,但需要额外的 webpack 配置,且因为包源的问题,下载时间过长,有时还会莫名失败,等等,都因为种种原因最终放弃。</p>
<p>经过一系列调研后,我们对业界常见的几种骨架屏解决方案,以及它们的优势、不足进行了一个简单的梳理。</p>
<h3>1. UI 骨架屏图</h3>
<p>即通过 UI 提供符合页面首页样式的图来充当骨架屏,将骨架屏 base64 图片插入 root 根节点,在 webpack 打包时嵌入项目中。</p>
<p>这是一种简单粗暴的方法,实现起来比较容易。但缺点也很明显,就是需要 UI 设计师支持和开发介入,不能自动生成。</p>
<h3>2. 手写骨架屏</h3>
<p>即通过手写 HTML、CSS 的方式为目标页定制骨架屏。这种方式可以做到对页面真实样式的复刻。不过一旦由于各种原因导致页面样式发生改变,就需要再改一遍骨架屏的样式和布局,极大增加了维护的成本。</p>
<h3>3. 自动生成静态骨架屏 </h3>
<p>目前比较受关注的是饿了么开源的插件 page-skeleton-webpack-plugin,其具体实现原理为:</p>
<ul><li><strong>生成骨架屏</strong></li></ul>
<p>通过 Puppeteer 操控 handless Chrome 打开需要生成的骨架屏页面,在等待页面加载完成之后,保留页面布局样式的前提下,通过对页面中元素进行增删,对已有元素通过层叠样式进行覆盖,使其展示为灰白块。然后将修改后的 HTML 和 CSS 提取出来,将页面分为不同的块区域,例如文本块、图片块、按钮块、SVG、伪类元素块等,分别对每个块进行处理,使其尽量与原页面保持一致。这里用到了 Puppeteer page 实例的 addScriptTag 方法来将处理块的脚本插入到 headless Chrome 打开的页面当中。</p>
<p>实际生成的骨架屏页面与原页面可能还会存在差距,插件通过 memory-fs 将骨架屏写入内存中,可以通过预览页面对生成的骨架屏进行二次编辑和效果预览,修改完成后点击生成按钮就能生成一份新的骨架屏写入到项目中。</p>
<p>借一张图来说明:</p>
<p><img src="/img/bVbxnDx?w=1080&h=587" alt="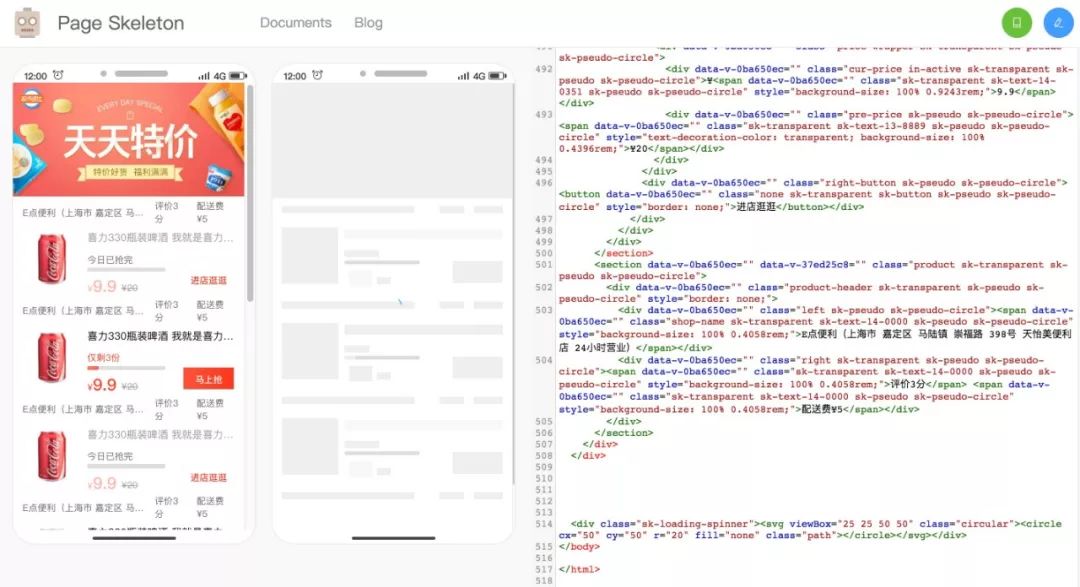" title=""></p>
<ul><li><strong>插入骨架屏</strong></li></ul>
<p>骨架屏的 DOM 结构和 CSS 通过离线生成后,在构建时注入模板 (EJS) 中的节点下面,插入到 HTML 是在 after-emit 钩子函数中进行。</p>
<p>page-skeleton-webpack-plguin 生成骨架屏的方案可以根据项目中不同的路由页面生成相应的骨架屏页面,并将骨架屏页面通过 webpack 打包到对应的静态路由页面中。</p>
<p>它的不足之处在于:</p>
<ul>
<li>实际使用过程中无法监听接口返回导致生成骨架屏的时机是否准确</li>
<li>生成的页面与业务人员写的结构质量有直接关系,经常出现需要手工二次调整的情况</li>
</ul>
<p>在这样的背景下,马蜂窝电商研发前端团队希望找一种在提升用户体验的同时,对开发更友好的骨架屏生成方式,能针对不同的业务场景自动生成出相似的骨架屏,并且实现自动注入。对于开发而言,只需要执行一条命令,或者简单配置,就可以生成骨架屏,不需要再考虑后续的维护工作。</p>
<p>在方案调研过程中,<strong>draw-page-structure</strong> 为我们的设计提供了灵感。</p>
<h3>4. draw-page-structure</h3>
<ul><li><strong>生成骨架屏:</strong></li></ul>
<pre><code>// dps.config.js
{
url: 'https://baidu.com',
output: {
filepath: '/Users/famanoder/DrawPageStructure/example/index.html',
injectSelector: '#app'
},
background: '#eee',
animation: 'opacity 1s linear infinite;',
// ...
}
</code></pre>
<p>根据 URL 指定的线上地址,配合 Puppeteer 获取当前页面的 DOM 结构,并对其中元素节点生成骨架屏文件到 filepath 指定的文件里面,就可以生成骨架屏页面,结果如下图所示:</p>
<p><img src="/img/bVbxnDB?w=197&h=300" alt="" title=""></p>
<ul><li><h4>插入骨架屏</h4></li></ul>
<p>将上述生成的骨架屏文件插入到页面根节点下面一般为 id="app" 的节点,然后在通用工具里提供主动销毁骨架屏的方法,就可以帮助开发主动控制或销毁骨架屏,显示页面真实内容。</p>
<p>draw-page-structure 的设计思想很大程度上可以满足我们的需求,不足的是只能对线上已经存在的 URL 生成骨架屏,不支持开发环境。另外由于是自动生成,当页面存在重定向(如果未登录重定向到登录页面)的情况时,生成的骨架屏可能与预期不一致。而且它的内部实现并不完善,可能导致某些结构复杂的页面下生成的骨架屏需要二次优化调整。</p>
<p>于是,我们开始了进一步的探索。</p>
<h2>三、对开发更友好的实现方案</h2>
<h3>1. 设计思路</h3>
<p>基于对现有方案的借鉴,我们想到了在配置文件中指定要生成骨架屏的页面 URL 和文件输出的目录,运行时读取配置文件中的配置项,通过 Puppeteer 打开指定的页面并注入 evalDom.js 的方法。因为此 JS 是在 Puppeteer 里面执行的,所以可以获取到当前页面完整的 DOM 结构,这给我们留下了非常大的发挥空间。</p>
<p>最初我们是从获取到的 DOM 结构中的 body 标签出发,递归去处理页面上的所有节点,处理完成后用生成的 DIV 替换原有元素的位置。第一版方案中通过 getBoundingClientRect 和 getComputedStyle 的方法来获取元素所有计算属性和相对于视口的宽高和位置,然后结合元素本身的样式属性递归渲染,保留页面原始 DOM 嵌套层次。</p>
<p>但由于能够决定元素位置的属性实在太多,如 position,z-index、width、height、top、display、box-sizing、flex 等都需要考虑,导致无法聚焦对页面 DOM 结构处理的逻辑,而且这些属性在处理完成后还需要加到最终生成骨架屏节点的 style 上,这样骨架屏文件可能比原来完整的页面结构还大,这肯定不是我们希望的。</p>
<p>优化后的方案是用 getBoundingClientRect 和 getComputedStyle 获取元素相关属性,然后直接通过绝对定位的方式来生成最终的骨架屏节点。这样在页面上最终需要的属性主要是 position、z-index、top、left、width、height、background、border-radius。除了无法保证页面原始的 DOM 结构,其它需求基本都可以满足,也更加聚焦于节点的处理。</p>
<p>主要实现流程如下图:</p>
<p><img src="/img/bVbxnDH?w=576&h=626" alt="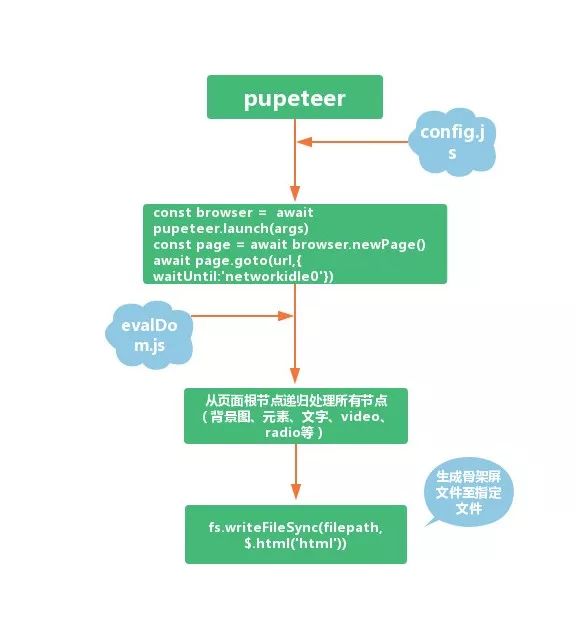" title=""></p>
<p>该方案目前主要应用于马蜂窝电商业务的多页面项目中,包括下单页、签证页等,以下单页为例,展示效果如下图:</p>
<p><img src="/img/bVbxnEv?w=1079&h=900" alt="" title=""></p>
<h3>2. 实现方式</h3>
<ul><li><strong>生成骨架屏</strong></li></ul>
<p><strong>(1) config.js 配置</strong></p>
<pre><code>const dpsConfig = {
// 默认生成位置为当前项目目录skeleton文件夹,已有骨架屏页面不会再次生成,新页面配置只需要添加新条目即可
visa_guide: {
url: 'https://w.mafengwo.cn/sfe-app/visa_guide.html?mdd_id=10083', // 必填项
},
call_charge: {
url: 'http://localhost:8081/sfe-app/call_charge.html?rights_id=25', // 必填项 待生成骨架屏页面的地址,用百度(https://baidu.com)试试也可以
//url:'https://www.baidu.com',
device: 'pc', // 非必填,默认mobile
background: '#eee', // 非必填
animation: 'opacity 1s linear infinite;', // 非必填
headless:false, // 非必填
customizeElement: function(node) { // 非必填
//返回值枚举如果是true表示不会向下递归到这层为止,如果返回值是一个对象那么节点的档子就按照对象里面的样式来绘制
//如果返回值为0表示正常递归渲染
//如果返回值为1表示渲染当前节点不在向下递归
//如果返回值为2表示对当前节点不作任何处理
if(node.className === 'navs-bottom-bar'){
return 2;
}
return 0;
},
showInitiativeBtn: true,// 非必填 如果此值设置为true表示开发需要主动触发生成骨架屏了,此时headless需设置为false
writePageStructure: function(html) { // 非必填
// 自己处理生成的骨架屏
// fs.writeFileSync(filepath, html);
// console.log(html)
},
init: function() { // 非必填
// 生成骨架屏之前的操作,比如删除干扰节点
}
}
}
module.exports = dpsConfig;
</code></pre>
<p><strong>(2)Puppeteer 新打开页面并返回浏览器实例、openPage</strong></p>
<pre><code>const ppteer = require('puppeteer');
const { log, getAgrType } = require('./utils');
const insertBtn = require('../insertBtn');
const devices = {
mobile: [375, 667, 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'],
ipad: [1024, 1366, 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1'],
pc: [1200, 1000, 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1']
};
async function pp({device = 'mobile', headless = true, showInitiativeBtn = false}) {
const browser = await ppteer.launch({headless});//返回browser实例
async function openPage(url, extraHTTPHeaders) {
const page = await browser.newPage();
let timeHandle = null;
if(showInitiativeBtn){
browser.on('targetchanged', async ()=>{//监听页面路由变化,并获取当前标签页的最新的页面,在showInitiativeBtn为true时插入按钮由开发控制主动生成骨架屏
const targets = await browser.targets();
const currentTarget = targets[targets.length - 1]
const currentPage = await currentTarget.page();
clearTimeout(timeHandle)
setTimeout(()=>{
if(currentPage){
currentPage.evaluate(insertBtn);
}
},300)
})
}
try{
let deviceSet = devices[device];
page.setUserAgent(deviceSet[2]);
page.setViewport({width: deviceSet[0], height: deviceSet[1]});
if(extraHTTPHeaders && getAgrType(extraHTTPHeaders) === 'object') {
await page.setExtraHTTPHeaders(new Map(Object.entries(extraHTTPHeaders)));
}
await page.goto(url, {
waitUntil: 'networkidle0'//不再有网络连接时触发(至少500ms后)
});
}catch(e){
console.log('\n');
log.error(e.message);
}
return page;
}
return {
browser,
openPage
}
};
module.exports = pp;
</code></pre>
<p><strong>(3)在浏览器环境里执行 evalDom.js 和 evalDom.js 中处理 node 节点的主要逻辑</strong></p>
<pre><code>agrs.unshift(evalScripts);//evalScripts = require('../evalDOM');在puppeteer里执行evalDom.js并将config.js里配置的参数传递给evalDom
html = await page.evaluate.apply(page, agrs);
</code></pre>
<pre><code>//evalDom.js主要逻辑
startDraw: function () {
const $this = this;
const nodes = this.rootNode.childNodes;
this.beforeRenderDomStyle();
function childNodesStyleConcat(childNodes) {
for (let i = 0; i < childNodes.length; i++) {
const currentChildNode = childNodes[i];//当前子节点
//有哪些节点要跳过绘制骨架屏的过程
if ($this.shouldIgnoreCurrentElement(currentChildNode)) { //是否应该忽略当前节点,不采取任何措施。后续这个地方可以由用户指定哪些节点应该被略去,todo
continue;
}
const backgroundHasurl = analyseIfHadBackground(currentChildNode);
const hasDirectTextChild = childrenNodesHasText(currentChildNode);//判断当前元素是不是有直接的子元素并且此元素是Text
if ($this.customizeElement && $this.customizeElement(currentChildNode) !== 0 && $this.customizeElement(currentChildNode) !== undefined) {
//开发者自定义节点需要渲染的样子,默认返回false表示使用正常递归的算法来处理。如果返回值是true表示不会在向下递归,如果返回值是一个对象那么表示开发需要自定义样式此时直接绘制就好。todo
if (getArgtype($this.customizeElement(currentChildNode)) === 'object') {
console.log('object');
//此处如果返回一个对象表示对象要自定义最后绘制的对象
} else if ($this.customizeElement(currentChildNode) === 1) {
//如果此时返回true,表示此节点要过滤
getRenderStyle(currentChildNode);
} else if ($this.customizeElement(currentChildNode) === 2){
continue ;
}
continue;
}
if (backgroundHasurl || analyseIsEmptyElement(currentChildNode) || hasDirectTextChild || shouldDrawCurrentNode(currentChildNode)) { //如果当前元素是内联元素或者当前元素非内联元素,但是不包含子节点或者子节点都是内联元素的话那么我们就在当前的骨架屏上绘制此节点。
getRenderStyle(currentChildNode, hasDirectTextChild);
} else if (currentChildNode.childNodes && currentChildNode.childNodes.length) { //如果当前节点包含子节点
//递归
childNodesStyleConcat(currentChildNode.childNodes);
}
}
}
childNodesStyleConcat(nodes);
return this.showBlocks();
},
</code></pre>
<ul>
<li>上述 rootNode 为根节点,默认为 document.body 或者可以由开发指定</li>
<li>主要逻辑为判断当前节点是否需要忽略、是否设置了背景图片、是否含有文本信息、开发是否指定了当前节点的处理方式等,对满足条件的渲染其对应的骨架屏节点,否则处理当前节点的子节点</li>
<li>所有节点处理完成后,调用 showBlocks 将生成的骨架屏节点拼接位 HTML 字符串,以便后续处理</li>
</ul>
<p><strong>(4) getRenderStyle 生成骨架屏样式</strong></p>
<pre><code>const styles = [
'position: fixed',
`z-index: ${zIndex}`,
`top: ${top}%`,
`left: ${left}%`,
`width: ${width}%`,
`height: ${height}%`,
'background: '+(background || '#eee'),
];
const radius = getStyle(node, 'border-radius');
radius && radius != '0px' && styles.push(`border-radius: ${radius}`);
blocks.push(`<div style="${styles.join(';')}"></div>`);
</code></pre>
<ul><li>zIndex、top、left、width、height 为处理后的属性,然后把所有骨架屏节点的字符串都 push 进 blocks 这个数组中。</li></ul>
<p><strong>(5) 最终生成骨架屏的 HTML 文件如下:</strong></p>
<pre><code><html><head></head>
<body><div style="position: fixed;z-index: 999;top: 89.805%;left: 4.267%;width: 91.467%;height: 11.994%;background: #eee"></div></body></html>
</code></pre>
<ul><li><strong>插入骨架屏</strong></li></ul>
<p>在项目入口 index.html 文件内添加</p>
<pre><code><body>
<div id="app">
</div>
<% if(htmlWebpackPlugin.options.hasSkeleton) { %>
<div id="skeleton"><!-- 骨架屏通过htmlWebpackPlugin在启动打包的时候自动注入 -->
<%= htmlWebpackPlugin.options.loading.html %>
</div>
<% } %>
<!-- built files will be auto injected -->
</body>
</code></pre>
<h2>四、 总结</h2>
<p>目前,该方案已经支持由开发主动控制骨架屏生成时间,这样就避免了页面重定向的过程中无法生成正确的骨架屏,同时可以支持在本地开发时生成骨架屏。未来我们将实现支持开发自定义生成骨架屏节点的样式和组件骨架屏的生成,并优化 evalDom.js 内部节点过滤、处理的算法。敬请期待!</p>
<p>最后,我们正在招聘资深前端开发工程师,欢迎感兴趣的同学发送简历至:kangcenbo@mafengwo.com。</p>
<p><strong>本文作者:康岑波、孙昊男,马蜂窝电商平台前端研发工程师。</strong></p>
<p><img src="/img/bVbxnEz?w=1080&h=481" alt="" title=""></p>
API 资源隔离系统设计与实现
https://segmentfault.com/a/1190000020258515
2019-09-02T11:40:59+08:00
2019-09-02T11:40:59+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
6
<p><em>(马蜂窝技术原创内容,公众号 ID:mfwtech)</em></p>
<h2><strong>Part 1 背景</strong></h2>
<p>大交通业务需要对接机票、火车票、租车、接送机等业务的外部供应链,供应商的数据接口大部分通过 HTTP、HTTPS 等协议进行通信。</p>
<p>为了保证开发进度并支持集成测试时进行多场景支持,我们往往需要对供应商接口进行 MOCK。之前我们在开发环境和测试环境对外部接口的调用没有统一管控,无法实现调用开关,也无法对调用量进行统计和限制。</p>
<p>为了解决这些问题,我们设计了接入 API 资源隔离系统 <strong>JARVIS</strong>_(Join Api Resource Virtual Isolation System)_,希望它可以像钢铁侠中的 Jarvis 一样帮我们解决资源的管控问题。</p>
<h2><strong>Part 2 设计原则</strong></h2>
<ol>
<li>图形化操作,提供管理后台,对开发和测试同学的交互要友好。</li>
<li>对业务无侵入,无需修改业务系统代码,保证测试的代码和发布的是一致的。</li>
<li>业务关联,这个系统是为业务服务的,需要提供必要的业务关联性。</li>
<li>支持丰富的匹配规则,可以用于绝大部分使用场景。</li>
<li>所配即所得,管理规则可以即时生效。</li>
<li>请求响应可追溯,提供详细的日志记录和查询功能。</li>
</ol>
<h2><strong>Part 3 设计与实现</strong></h2>
<h3>整体思路</h3>
<p>供应商资源管控系统位于内部接入网关和外部供应商接口之间,在开发和测试环境对外部供应商资源提供了全局的代理,在系统中的位置如下:</p>
<p><img src="/img/remote/1460000020258518" alt="" title=""></p>
<p>资源管控系统系统分两大部分:</p>
<ol>
<li>
<strong>Config Center</strong>:主要实现业务线、环境、供应商、供应商 API 和 API 对应的 MOCK 规则的配置管理。</li>
<li>
<strong>API Server</strong>:主要负责请求的接受、MOCK 规则匹配、MOCK 规则的响应和日志记录。</li>
</ol>
<h3>关键功能</h3>
<ul>
<li>采用配置中心和 API 服务器分离的结构,支持集群部署</li>
<li>同时支持模拟响应和代理访问两种响应方式</li>
<li>支持 Mock 规则修改后即时生效</li>
<li>自动适应上游服务的环境隔离</li>
<li>同一 API 在同一环境下支持多种场景,并且有优先级区分</li>
<li>Mock 规则会关联业务系统,如业务线、环境、供应商、供应商的 API 等</li>
<li>会进行 Mock 请求调用次数的计数,并且支持超量熔断和超量报警</li>
<li>支持 Mock 调用的日志记录和可视化查询。</li>
</ul>
<h3>规则配置与管理</h3>
<p>主要包含业务线信息配置、环境配置、供应商配置、供应商所属 API 配置、Mock 规则配置。业务信息之间的关系如下 :</p>
<p><img src="/img/remote/1460000020258519" alt="" title=""></p>
<p>1. 「业务线」指的是如国内机票、国际机票、火车票、租车、接送机等业务类型</p>
<p>2. 「环境」包含两层含义:</p>
<ul>
<li>一为部署环境,分为 dev 开发环境、qa 测试环境、sim 预发环境、prod 生产环境四种,可以理解为以下四个互相隔离的集群。</li>
<li>二为在 qa 环境下为了区分多个项目进行了环境隔离,如开放平台代号为 kfpt,乘机人代号为 cjr。</li>
</ul>
<p>3. 「供应商」是指业务接入的各种商家,商家可以归属到某条业务线</p>
<p>4. 「供应商」 API 是指供应商提供的一系列基于 HTTP 或 HTTPS 的接口</p>
<p>5.「 MOCK 规则」是指为了对供应商接口进行仿真或代理而配置的规则,用于后续的规则匹配和返回响应信息。MOCK 规则会归属某个供应商 API,同时归属于某个环境。</p>
<p>6.「 场景」是用来区分同一供应商 API 且在同一环境下面不同场景的区分,分为通用场景和具象场景两大类,在规则匹配时优先匹配具象场景,如果具象场景未匹配成功则进行通用场景匹配。</p>
<h3>响应规则的匹配和响应过程</h3>
<p>规则匹配和内容响应的流程如下:</p>
<p><img src="/img/remote/1460000020258520" alt="" title=""></p>
<p>1. 规则加载和刷新,接收到内部系统的调用后,会判断当前的规则缓存是否为空,如果为空则会加载全部可用的 MOCK 规则加载到缓存中。</p>
<p>2. 环境隔离标识自适应, 内部的服务通常是采用环境隔离方式部署,环境隔离标识(envTag)会影响到规则的匹配。</p>
<p>3. 规则匹配 ,根据请求的 URL 对规则进行匹配,最终可能匹配多条规则。将匹配到的规则分为具象场景规则和通用场景规则两组。对具象场景的 MOCK 规则根据请求参数进行匹配,如果命中则返回。对通用场景的 MOCK 规则根据请求参数进行匹配,如果命中则返回。</p>
<p>4. 结果响应,如果没有匹配到 Mock 规则,直接返回默认的错误信息。如果匹配到 Mock 规则,先判断是 Mock 类型还是 Proxy 类型,对于 Mock 类型会按照规则的配置返回状态码和响应内容,如果是 Proxy 类型则先调用供应商的真实接口再将获取到的内容返回给调用方。对接口当日的调用次数进行显示,如果超过阈值则会触发报警并进行服务熔断。</p>
<h3>主要 Feature</h3>
<p><strong>1. 多种匹配条件</strong></p>
<p>支持根据 header、param、JsonPath、body 等多种方式进行参数提取和匹配。</p>
<p><strong>2. Mock 规则热生效</strong></p>
<p>Mock 规则新增或修改后会热生效,实现所配即所得。在消息新增和修改后会触发规则变更的切面,进而通过 RocketMQ 发送规则变更消息,消息以广播的形式进行发送,API Server 会监听该消息,收到后会触发规则的刷新。</p>
<p><strong>3. 环境隔离支持</strong></p>
<p>内部的网关服务通常是采用环境隔离方式部署,我们采用在 HttpHeader 中增加 envTag 属性来传递环境标识。会判断 envTag 是否为空,如果为空则不进行 URL 的重新组装,如果为空则会将上述 URL 中的 {env} 部分替换为实际对应的 envTag。</p>
<p><img src="/img/remote/1460000020258521" alt="" title=""></p>
<p>环境隔离主要是分为两步来实现:</p>
<ul>
<li>在我们接入网关层面,通过 join-common 自动提取并传递来自上游的环境隔离标识 envTag,并将其写入到 HTTP Header 中。</li>
<li>在 API Server 我们接收到请求后会判断请求是否携带 envTag 标识,如果携带会将 URL 中的 {env} 部分替换为实际对应的 envTag,最终匹配到环境对应的规则上面。如果没有携带 envTag 则会去匹配默认的环境规则。</li>
</ul>
<p><strong>4. 多场景支持</strong></p>
<ul>
<li>每个规则对应一个环境和一个供应商接口,但是会分为请求成功、请求失败等场景</li>
<li>多个人在同一个项目中进行开发和测试的时候会产生冲突</li>
</ul>
<p>为应对这种问题,我们提出了「场景」的概念,分为通用场景和具象场景:</p>
<ul>
<li>通用场景故名思义就是用来应对正常的请求,一般会放开 Proxy 开关,直接请求到供应商的接口</li>
<li>具象场景用于对应某个具体的 Case,比如北京飞上海 1 成人 1 儿童的查询,我们通过更加详细的参数进行匹配</li>
</ul>
<p>在匹配层级上面优先匹配具象场景的规则,如果匹配失败才会继续匹配通用场景的规则。</p>
<p><strong>5. 超限熔断与报警</strong></p>
<p>根据在供应商 API 层面设置的请求上限进行校验,如果当日的请求超限,会进行规则的降级,并通过企业微信发送报警信息。</p>
<p><strong>6. 报文自动加密与解密</strong></p>
<p>有些供应商的报文传输是密文的形式,我们在 JARVIS 系统中根据对应的供应商在编辑时是明文,在保存的时候会根据协议加密为密文。</p>
<p><strong>7. 请求日志记录与查询</strong></p>
<p>对所有的请求都会记录请求报文、响应报文、命中规则等信息,由于报文体积较大且调用量较大,我们使用 ElasticSearch 进行存储。</p>
<h2><strong>Part 4 项目实战</strong></h2>
<p>目前已经在开发和测试环境代理了全部的供应商接口:</p>
<p><strong>1. 国内开放平台开发支持</strong></p>
<p>近期我们在国内机票开放平台,前期由我方提供标准接,口由供应商接口并没有完全实现,我们根据文档生成了全部的 Mock 数据并针对每个接口的各种场景定制了 Mock 规则,保障了项目的开发进度并且实现了多场景的覆盖。</p>
<p><strong>2. 暑期压力测试支持</strong></p>
<p>近期进行了暑运压力测试,测试时通过 Mock 功能隔离了对外部供应商的访问,并通过设置响应延迟时间模拟了供应商接口不同状况下的响应时间。</p>
<h2><strong>Part 5 后续路线图</strong></h2>
<p>后续主要计划在以下方向进行改进和优化:</p>
<ol>
<li>
<strong>供应商接口管理</strong>,实现接口 Schema 的定义与管理,并实现对请求参数和响应内容校验。</li>
<li>
<strong>增加模版化响应</strong>,减少人工配置,提高使用效率。</li>
<li>
<strong>完善统计系统</strong>,实现资源使用情况的可视化。</li>
<li>
<strong>易用性优</strong>化,收集大家在使用过程中遇到的问题进行持续改进,做到可用、易用、好用。</li>
</ol>
<h2><strong>Part 6 结语</strong></h2>
<p>目前国际机票、国内机票、接送机等业务全部接入了 JARVIS 系统,也经历了几个大项目开发和测试过程的检验,在性能和可用性方面也做了多次优化,目前还存在很大的改进空间,我们也会持续进行完善。</p>
<p>最后,大交通团队正在招聘 Java 架构师,有兴趣的同学欢迎发送简历至:anzidong@mafengwo.com</p>
<p><strong>本文作者:安自东,马蜂窝大交通团队研发技术专家。</strong></p>
<p><img src="/img/remote/1460000020258522" alt="" title=""></p>
马蜂窝视频编辑框架设计及在 iOS 端的业务实践
https://segmentfault.com/a/1190000020236919
2019-08-30T11:26:37+08:00
2019-08-30T11:26:37+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
4
<p><strong><em>(马蜂窝技术公众号原创内容,ID: mfwtech)</em></strong></p>
<p>熟悉马蜂窝的朋友一定知道,点击马蜂窝 App 首页的发布按钮,会发现发布的内容已经被简化成「图文」或者「视频」。</p>
<p>长期以来,游记、问答、攻略等图文形式的形态一直是马蜂窝发展的优势所在。将短视频提升至与图文并列的位置,是因为对于今天的移动互联网用户来说,内容更真实直观、信息密度更大、沉浸感更强的短视频已经成为刚需。为了使旅游用户拥有更好的内容交互体验,丰富和完整原有的内容生态体系,马蜂窝加码了对短视频领域的布局。</p>
<p>现在,每天都会有大量短视频在马蜂窝产生,覆盖美食、探店、景点打卡、住宿体验等多种当地玩乐场景。马蜂窝希望平台的短视频内容除了「好看」之外,更要「好用」。这个「好用」不仅仅是为有需求的用户提供好用的旅行信息,更是指通过技术让用户的短视频创作更加简单易行。</p>
<p>为此,我们在马蜂窝旅游 App 的视频编辑功能中提供了「自定义编辑」与「模板创作」两种编辑模式,使用户既可以通过「模板」快速创作与模板视频同款的炫酷视频,也能够进入「自定义编辑」模式发挥自己的创意,生成个性化视频。</p>
<p>本文将围绕马蜂窝旅游 App iOS 端中的视频编辑功能,和大家分享我们团队视频编辑框架的设计及业务实践。</p>
<h2>Part.1 需求分析</h2>
<p>如前言所述,我们要做的是能够支持「自定义编辑」与「模板创作」两种模式的视频编辑功能。</p>
<p><img src="/img/remote/1460000020236922" alt="" title=""></p>
<p><strong>图1:产品示意图</strong></p>
<p>首先我们梳理一下「自定义编辑」模式下,需要提供的功能:</p>
<ul>
<li>视频拼接:将多段视频按顺序拼接成一段视频</li>
<li>播放图片:将多张图片合成一段视频</li>
<li>视频裁剪:删除视频中某个时间段的内容</li>
<li>视频变速:调整视频的播放速度</li>
<li>背景音乐:添加背景音乐,可以与视频原音做混音</li>
<li>视频倒播:视频倒序播放</li>
<li>转场过渡:拼接的两段视频切换时增加一些过渡效果</li>
<li>画面编辑:画面旋转,画布分区、设置背景色,增加滤镜、贴纸、文字等附加信息</li>
</ul>
<p>有了上述这些功能,便可以满足「自定义编辑」模式的需求,能够让用户通过我们的视频编辑功能完成自己的创作。但是为了进一步降低视频编辑功能的使用门槛,让制作炫酷视频变得简单,我们还需要支持「模板创作」模式。即为用户提供「模板视频」,用户只需要选择视频或者图片,便可创作出与「模板视频」有同样编辑特效的同款视频,实现「一键编辑」。</p>
<p>支持「模板创作」模式后,我们视频编辑功能最终的流程图如下:</p>
<p><img src="/img/remote/1460000020236923" alt="" title=""></p>
<p><strong>图2:完整流程图</strong></p>
<p>如图所示,在媒体文件之外,多了一个模板 A 的输入,模板 A 描述了要对用户选择的媒体文件做哪些编辑。同时在编辑器的输出中多了一个模板 B,模板 B 描述了用户在完成编辑后,最终做了哪些编辑。其中模板 B 的输出,为我们解决了「模板视频」来源的问题,即「模板视频」既可以通过运营手段生产,也可以将用户通过「自定义编辑」模式创作的视频作为模板视频,使其他用户浏览该用户发布的视频时,可以快速创作同款视频。</p>
<p>通过上述需求分析的过程,可以总结出我们的视频编辑功能主要支持两个能力:</p>
<ol>
<li><strong>常规视频编辑的能力</strong></li>
<li><strong>描述如何编辑的能力</strong></li>
</ol>
<p>这两个能力的划分,为我们接下来进行视频编辑框架的设计提供了方向。</p>
<h2>Part.2 框架设计</h2>
<p>常规视频编辑的能力是一个视频编辑框架需要提供的基本能力,能够支撑业务上的「自定义编辑」模式。「描述如何编辑」的能力则是将常规视频编辑能力进行抽象建模,描述「对视频做哪些编辑」这件事,然后将这种描述模型转化为具体的视频编辑功能,便能够支撑起业务上的「模板创作」模式。所以我们的编辑框架可以划分为两个主要的模块:</p>
<ul>
<li>编辑模块</li>
<li>描述模块</li>
</ul>
<p>在两个模块之间,还需要一个转换模块,完成视频编辑模块与描述模块之间的双向转换。下图为我们需要的视频编辑框架示意图:</p>
<p><img src="/img/remote/1460000020236924" alt="" title=""></p>
<p><strong>图3:视频编辑框架示意图</strong></p>
<ul>
<li>
<strong>编辑模块</strong>所需要的具体功能,可以随着业务上的需求不断迭代添加,目前我们要支持的功能如图中所列。</li>
<li>
<strong>描述模块</strong>则需要一个描述模型,将媒体素材与各种编辑功能完整的描述出来。同时也需要将模型保存成文件,从而能够被传输分发,我们称之为描述文件。</li>
<li>另外在描述文件的基础上,「模板创作」模式中的「模板」还需要标题、封面图等运营相关的信息。所以还需要提供一个<strong>运营加工</strong>的功能,能够让运营同事将描述文件加工为模板。</li>
<li>
<strong>转换模块</strong>负责的则是将视频编辑功能抽象为描述文件、将描述文件解析为具体的编辑功能的任务,保证抽象与解析的正确性至关重要。</li>
</ul>
<p>视频编辑模块在不同的开发平台上都有很好的实现方案,比如 iOS 原生提供的 AVFoundation,使用广泛的第三方开源库 GPUImage,以及更加通用的 ffmpeg 等。具体的实现方案可以结合业务场景与项目规划进行选择,我们目前在 iOS 端采用的方案是苹果原生的 AVFoundation。如何结合 AVFoundation 实现我们的视频编辑框架会在下文具体介绍。接下来我们就来看下具体功能模块的设计与实现。</p>
<h2>Part.3 模块功能与实现</h2>
<h3>3.1 描述模块</h3>
<h4><strong>3.1.1 功能划分</strong></h4>
<p>首先我们对「自定义编辑」模式下需要支持的具体功能进行分析,发现可以以编辑的对象为标准,将编辑功能划分为两类:段落编辑、画面编辑。</p>
<ul><li>
<strong>段落编辑</strong>:将视频段看作编辑对象,不关心画面内容,只在视频段层面上进行编辑,包含如下功能:</li></ul>
<p><img src="/img/remote/1460000020236925" alt="" title=""></p>
<p><strong>图4:段落编辑</strong></p>
<ul><li>
<strong>画面编辑</strong>:将画面内容作为编辑对象,包含如下功能:</li></ul>
<p><img src="/img/remote/1460000020236926" alt="" title=""></p>
<p><strong>图5:画面编辑</strong></p>
<h4><strong>3.1.2 视频编辑描述模型</strong></h4>
<p>有了编辑功能的划分后,要描述「对视频进行哪些编辑」,我们还需要一个视频编辑描述模型。定义如下几个概念:</p>
<ul>
<li>
<strong>时间线</strong>:由时间点组成的单向递增直线,起始点为 0 点</li>
<li>
<strong>轨道</strong>:以时间线为坐标系的容器,容器内存放的是每个时间点需要的内容素材及「画面编辑」功能</li>
</ul>
<ol><li>轨道具有类型,一条轨道仅支持一种类型</li></ol>
<ul><li>
<strong>段落</strong>:轨道中的一段,即轨道所属时间线上两个时间点及两点之间的部分</li></ul>
<ol><li>段落也具有类型,与其所属轨道类型保持一致</li></ol>
<p>轨道类型列表:</p>
<p><img src="/img/remote/1460000020236927" alt="" title=""></p>
<p>其中「视频」、「图片」、「音频」类型轨道,是提供画面与声音内容的轨道。其余几个类型的轨道,则是用于描述具体做哪些画面编辑功能的轨道。特效类型轨道中可以指定若干画面编辑效果,如旋转、分区等。</p>
<p>结合编辑功能的划分,我们可以看出段落编辑功能的编辑对象是轨道内的段落,画面编辑功能的编辑对象是轨道内存放的内容素材。</p>
<p>有了时间线、轨道、段落三个概念以及段落编辑、画面编辑两个编辑行为的划分后,我们在抽象层面描述视频的编辑过程如下:</p>
<p><img src="/img/remote/1460000020236928" alt="" title=""></p>
<p><strong>图6:视频编辑描述模型示意图</strong></p>
<p>如上图所示,通过该模型,我们已经能够完整的描述出「对视频进行哪些编辑」:</p>
<ul>
<li>创作一个时长 60 秒的视频,内容素材有视频,图片,音乐,分别对应轨道 1、轨道 2、轨道 3,并且有转场、滤镜效果,由轨道 4、轨道 5 指定(其他效果不再单独描述,以转场、滤镜效果为参考)。</li>
<li>该视频由轨道 1 的 [0-20] 段、轨道 2 的 [15-35] 段、轨道 1 的 [30-50] 段以及轨道 2 的 [45-60] 段拼接而成。</li>
<li>[0-60] 视频全段有背景音乐,音乐由轨道 3 指定。</li>
<li>[15-20]、[30-35]、[45-50] 三段内有转场效果,转场效果由轨道 4 指定。</li>
<li>[15-35] 段有滤镜效果,滤镜效果由轨道 5 指定。</li>
</ul>
<h4><strong>3.1.3 描述文件与模板</strong></h4>
<p>有了上述的视频编辑描述模型后,我们还需要具体的文件来存储和分发该模型,即描述文件,我们使用 JSON 文件来实现。同时还需要提供运营加工的能力,使运营同事为描述文件添加一些运营信息,生成模板。</p>
<ul><li>
<strong>描述文件</strong>: 根据视频编辑模型生成一份 JSON 文件</li></ul>
<p>举个?</p>
<pre><code>{
"tracks": [{
"type": "video",
"name": "track_1",
"duration": 20,
"segments": [{
"position": 0,
"duration": 20
}, ...]
}, {
"type": "photo",
"name": "track_2",
"duration": 20,
"segments": [{
"position": 15,
"duration": 20
}, ...]
},
{
"type": "audio",
"name": "track_3",
"duration": 60,
"segments": [{
"position": 0,
"duration": 60
}]
}, {
"type": "transition",
"name": "track_4",
"duration": 5,
"segments": [{
"subtype": "fade_black",
"position": 15,
"duration": 5
}, ...]
}, {
"type": "filter",
"name": "track_5",
"duration": 20,
"segments": [{
"position": 15,
"duration": 20
}]
}, ...
]
}
</code></pre>
<ul><li>模板: 由描述文件+若干业务信息组成的JSON文件</li></ul>
<p>举个?</p>
<pre><code>{
"title": "模板标题",
"thumbnail": "封面地址",
"description": "模板简介",
"profile": { //描述文件
"tracks": [...]
}
}</code></pre>
<p>通过上述视频编辑描述模型与描述文件及模板的定义,结合转换器,我们便可以在用户使用「自定义」编辑功能的基础上,生成一份描述文件来描述用户最终对视频进行的编辑行为。反过来我们也可以通过解析描述文件,将用户选择的素材根据描述文件进行编辑,快速生成与描述文件中的编辑行为「同款」的视频。</p>
<h3>3.2 编辑模块</h3>
<h4><strong>3.2.1 AVFoundation 介绍</strong></h4>
<p>AVFoundation 音视频编辑分为素材混合、音频处理、视频处理、导出视频这四个流程。</p>
<p><strong>(1)素材混合器 AVMutableComposition</strong></p>
<p>AVMutableComposition 是一个或多个轨道(AVCompositionTrack)的集合,每个轨道会根据时间线存储源媒体的文件信息,比如音频、视频等。</p>
<pre><code>//AVMutableComposition 创建一个新AVCompositionTrack的API
- (nullable AVMutableCompositionTrack *)addMutableTrackWithMediaType:(AVMediaType)mediaType preferredTrackID:(CMPersistentTrackID)preferredTrackID;
</code></pre>
<p>每个轨道由一系列轨道段(track segments)组成,每个轨道段存储源文件的一部分媒体数据,比如 URL、轨道 ID(track identifier)、时间映射(time mapping)等。</p>
<pre><code>//AVMutableCompositionTrack部分属性
/* provides a reference to the AVAsset of which the AVAssetTrack is a part */
AVAsset *asset;
/* indicates the persistent unique identifier for this track of the asset */
CMPersistentTrackID trackID;
NSArray<AVCompositionTrackSegment *> *segments;</code></pre>
<p>其中 URL 指定文件的源容器,轨道 ID 指定需要用到的源文件轨道,而时间映射指定的是源轨道的时间范围,并且还指定其在合成轨道上的时间范围。</p>
<pre><code>//AVCompositionTrackSegment的时间映射
CMTimeMapping timeMapping;
//CMTimeMapping定义
typedef struct
{
CMTimeRange source; // eg, media. source.start is kCMTimeInvalid for empty edits.
CMTimeRange target; // eg, track.
} CMTimeMapping;</code></pre>
<p><img src="/img/remote/1460000020236929" alt="" title=""></p>
<p><strong>图7:AVMutableComposition合成新视频的流程 </strong></p>
<p><em><strong>(来源:</strong><strong>苹果官方开发者文档)</strong></em></p>
<p><strong>(2) 音频混合 AVMutableAudioMix </strong></p>
<p>AVMutableAudioMix 可以通过 AVMutableAudioMixInputParameters 指定任意轨道的任意时间段音量。</p>
<pre><code>//AVMutableAudioMixInputParameters相关api
CMPersistentTrackID trackID;
- (void)setVolumeRampFromStartVolume:(float)startVolume toEndVolume:(float)endVolume timeRange:(CMTimeRange)timeRange;</code></pre>
<p><img src="/img/remote/1460000020236930" alt="" title=""></p>
<p><strong>图8:音频混合示意图</strong></p>
<p><em><strong>(来源:</strong><strong>苹果官方开发者文档)</strong></em></p>
<p><strong>(3)视频渲染 AVMutableVideoComposition</strong></p>
<p>我们还可以使用 AVMutableVideoComposition 来直接处理 composition 中的视频轨道。处理一个单独的 video composition 时,你可以指定它的渲染尺寸、缩放比例、帧率等参数并输出最终的视频文件。通过一些针对 video composition 的指令(AVMutableVideoCompositionInstruction 等),我们可以修改视频的背景颜色、应用 layer instructions。</p>
<p>这些 layer instructions(AVMutableVideoCompositionLayerInstruction 等)可以用来对 composition 中的视频轨道实施图形变换、添加图形渐变、透明度变换、增加透明度渐变。此外,你还能通过设置 video composition 的 animationTool 属性来应用 Core Animation Framework 框架中的动画效果。</p>
<p><img src="/img/remote/1460000020236931" alt="" title=""></p>
<p><strong>图9:AVMutableVideoComposition 处理视频 </strong></p>
<p><em><strong>(来源:</strong><strong>苹果官方开发者文档)</strong></em></p>
<p><strong>(4) 导出 AVAssetExportSession</strong></p>
<p>导出的步骤比较简单,只需要把上面几步创建的处理对象赋值给导出类对象就可以导出最终的产品。</p>
<p><img src="/img/remote/1460000020236932" alt="" title=""></p>
<p><strong>图10:导出流程</strong></p>
<p><em><strong>(来源:</strong><strong>苹果官方开发者文档)</strong></em></p>
<h4><strong>3.2.2 编辑模块的实现</strong></h4>
<p>结合 AVFoundation 框架,我们在视频编辑模块中分别实现了如下几个角色:</p>
<ul><li>
<strong>轨道</strong>:有视频与音频两种类型,存放帧图与声音。</li></ul>
<ol>
<li>在视频类型的轨道中,扩展出图片类型轨道,即通过空的视频文件生成视频轨道,将所选的图片作为帧图提供给混合器。</li>
<li>附加轨道:AVFoundation 提供了 AVVideoCompositionCoreAnimationTool 这个工具,能够方便的将 CoreAnimation 框架内的内容应用到视频帧图上。所以添加文字的功能,我们在预览端通过 UIKit 创建了一系列预览视图,导出时转换到该工具的 CALayer 上。</li>
</ol>
<ul>
<li>
<strong>段落</strong>:轨道中的某个时间段,作为段落编辑的对象。</li>
<li>
<strong>指令</strong>:关联到指定的视频段落,进行图片处理,绘制每一帧画面。</li>
</ul>
<ol>
<li>一个指令可以关联多条视频轨道,从这些视频轨道的指定时间段内获取帧图,作为画面编辑的对象。</li>
<li>指令中画面编辑的具体实现方案,采用 CoreImage 框架。CoreImage 本身提供了一些内置的图片实时处理功能。CoreImage 不支持的特效,我们通过自定义 CIKernel 的方式来实现。</li>
</ol>
<ul>
<li>
<strong>音频混音器</strong>:针对添加音乐的功能,我们使用 AVMutableAudioMix 完成。</li>
<li>
<strong>视频混合器</strong>:我们最终要得到的视频文件,一般包含一条视频轨道、一条音频轨道。混合器就是将我们输入的媒体资源转换为轨道,根据用户的操作或者由描述模型转换,对视频进行段落编辑、组装指令进行画面编辑,对音频轨道进行混音,结合 AVPlayerItem 与 AVExportSession,提供实时预览与最终合成的功能。</li>
</ul>
<p>有了上述几个角色后,在 iOS 端的视频编辑模块实现示意图如下:</p>
<p><img src="/img/remote/1460000020236933" alt="" title=""></p>
<p><strong>图11:视频编辑模块示意图</strong></p>
<p>如上图所示,混合器中包含两条视频轨道与一条音频轨道。一般来说输入的视频与图片文件,都会生成一条对应的视频轨道,理论上混合器中应该有多条视频轨道。我们图中混合器只保持两条视频轨道与一条音频轨道,首先是为解决视频解码器数量限制的问题,后面会有具体描述。其次是为了保证实现转场过渡功能。</p>
<p>指令序列由若干在时间段上连续的指令组成,每个指令由时间段、帧图来源轨道、画面编辑效果组成。视频编辑功能中的段落编辑功能,便是对指令段的拼接;画面编辑功能,便是每个指令段对帧图做的编辑处理。混合器提供的预览功能,可以将编辑改动实时展示给用户。确定了编辑效果后,通过混合器提供的合成功能,便完成了最终视频文件的合成。</p>
<h4><strong>3.2.3 转换器 </strong></h4>
<p>有了视频编辑模块的实现方案后,我们已经能够支持「自定义编辑」模式。最后通过转换器的连接,便可以将描述模型与编辑模块整合在一起,完成对「模板创作」模式的支持。这里转换器的实现较为简单,即将 JSON 格式描述文件解析为数据模型,混合器根据用户选择的素材与描述模型创建自己内部的轨道模型,拼接指令段即可。</p>
<p>另一方面,混合器在完成编辑导出时,将自己内部的轨道模型与指令信息组装成数据模型,生成 JSON 格式的描述文件。</p>
<p><img src="/img/remote/1460000020236934" alt="" title=""></p>
<p><strong>图12:描述模型与编辑模块相关转换</strong></p>
<h2>Part.4 近期优化方向</h2>
<h3>4.1 踩过的坑</h3>
<p>在实现上述编辑框架的过程中,我们遇到过很多的问题,多数是由于 AVFoundation 中错误信息不够明确,定位问题比较耗时,总结起来大部分都是轨道时间轴对齐引起的问题。除时间轴对齐问题外,我们在这里总结几个在实现时需要考虑到的问题,与大家分享一下,避免踩同样的坑。</p>
<p><strong>(1) 混合器轨道数量限制</strong></p>
<ul><li>
<strong>问题</strong>:AVMutableComposition 可以同时添加很多的轨道,即一个 composition 内可以同时存在多条视频轨道,并且可以正常通过 AVPlayer 预览播放。所以我们最初实现的编辑模块,混合器中支持多条视频轨道,如下图所示。这种多条轨道结构,预览时没有问题,导出时却出现了「无法解码」的报错。转换前的混合器结构图:</li></ul>
<p><img src="/img/remote/1460000020236935" alt="" title=""></p>
<p><strong>图13:转换前的混合器结构图</strong></p>
<ul>
<li>
<strong>原因</strong>:经查证后发现是苹果设备对视频播放解码器的数量有限制,导出视频时,每条视频轨道会使用一个解码器,这就导致导出时如果视频轨道数量超出解码器数量的限制,无法导出。</li>
<li>
<strong>解决方案</strong>:轨道模型转换,将最初混合器中的多视轨结构转换为目前的双视轨结构,这样在导出时便不会超出解码器数量限制。</li>
</ul>
<p><strong>(2) 性能优化:倒播功能实现方案</strong></p>
<ul>
<li>
<strong>问题</strong>:最初的实现方案为导出一个新的视频文件,帧序列是原视频文件中的倒序。如果原视频文件很大,用户只裁剪了一种的一段,对这一段进行倒播时,仍然会将原视频文件进行倒序处理,导出一份新的视频,是一个十分耗时的操作。</li>
<li>
<strong>解决方案</strong>:根据时间点获取视频文件的对应帧,倒播时只是将正常时间点转换为倒播后的时间点即可,不操作视频文件。类似于对数组的操作,只操作下标,而不直接改变数组的顺序。</li>
</ul>
<p><strong>(3) 性能优化:减少内存使用率</strong></p>
<ul>
<li>
<strong>问题</strong>:预览时使用原图尺寸,消耗内存严重,添加多个高清图片后,预览过程会出现内存告警。</li>
<li>
<strong>解决方案</strong>:在不影响用户体验的情况下,使用低分辨率的图片进行预览,导出时使用原图。</li>
</ul>
<h3>4.2 近期规划</h3>
<p>目前这套视频编辑框架在马蜂窝旅游 App iOS 端运作良好,能够支撑业务的不断迭代,可以快速扩展出更多的画面编辑功能,当然也还有一些需要优化的细节有待完善。</p>
<p>近期我们会结合机器学习与 AR 技术,探索一些有趣好玩的视频编辑场景,为用户提供更加个性化的旅行记录工具。</p>
<p><strong>本文作者:李旭、赵成峰,马蜂窝内容中心 iOS 研发工程师。</strong></p>
<p><img src="/img/remote/1460000020236936" alt="" title=""></p>
测试人员为什么要深入到项目实现中去?
https://segmentfault.com/a/1190000020186818
2019-08-26T12:01:14+08:00
2019-08-26T12:01:14+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
9
<p><em>(“马蜂窝技术”公众号原创内容,ID: mfwtech)</em></p>
<p>一个项目从需求确定到最后上线,通常来说流程是这样的:</p>
<p><img src="/img/remote/1460000020186821" alt="" title=""></p>
<p>「测试」作为一个项目质量保证角色,在上面的整个流程中均有参与。而用例设计、项目测试环节更像测试的主场,PRD 的评审测试人员也会发表很多自己的观点,对项目的技术评审虽然测试人员也有参与,但也不如前两个环节的参与程度深。 </p>
<p>其实,一个优秀的测试人员应该深入到项目的每一个环节中去发现问题,提出自己的观点,保证项目质量。那么要真正深入到项目实现中,测试应该怎么做呢?</p>
<h2><strong>一、Review 接口定义结构</strong></h2>
<p>接口定义文档在测试过程是测试人员接触比较多的设计文档,尤其是与最外层面向用户的接口设计相关的部分。在参加接口文档评审、编写接口用例这些场景下,测试人员都会仔细阅读接口设计文档。</p>
<p>通过接口文档,可以帮助测试人员清晰了解到前端与后断是怎么交互的,每个页面哪些操作与后端存在交互,不同的接口之间是否存在关联,清楚这些可以帮助测试人员在测试过程中对出现的问题进行精准判断,确定导致问题出现的范围。</p>
<p>在阅读接口文档可以关注以下几个方面:</p>
<ul>
<li>接口中定义字段是否考虑了扩展性;</li>
<li>字段是否必须有明确的说明;如果是代码实现需要清晰定义 NotNull/NotBlank;</li>
<li>字段含义是否存在歧义,字段的含义要有明确的解释;</li>
<li>接口是否覆盖到了所有业务场景;</li>
<li>返回值结构、内容是否正确;通常返回值都有固定格式规范,返回值结构要规范统一,并且接口请求失败有明确的失败原因;</li>
<li>字段类型是否正确;</li>
<li>入参风格统一;比如日期格式如果是 yyyy-mm-dd 格式,每个接口最好都统一。</li>
</ul>
<p>除了上面提到这些,在接口文档还要关注数据库表结构,确保表结构能满足接口需求;接口返回数据量要控制在一个合理的范围,返回数据量太大会有传输压力从而产生性能问题;接口之间要注意低耦</p>
<h2><strong>二、关注架构设计方案</strong></h2>
<p>对于测试工程师来说学习项目架构或者说系统架构是一个不小挑战,因为基本上所有的架构知识、开发框架都是基于开发人员进行设计的,而这些内容对于开发人员也是一个不小的挑战。</p>
<p>那测试人员为什么还要去了解学习?有测试同行曾经开玩笑说「了解项目的架构设计是为了在开会的时候听懂开发在说什么」。虽然是一句玩笑话,但也说明测试人员需要了解这方面的内容重要性。了解项目的架构设计可以在以下几方帮助到测试人员:</p>
<h3>1. 培养测试人员的架构思维</h3>
<p>因为测试环节不应该仅仅发生在提测后,在前期项目设计阶段也同样需要进行测试,只有通过对业务代码、架构设计、用到的技术有了解,才能够在设计阶段发现缺陷。</p>
<h3>2. 帮助测试更全面、更有针对性地进行</h3>
<p>比如性能测试,如果不清楚整个系统的架构,没办法对压测结果进行分析,甚至设计的压测方案可能都是存在问题的。还有就是在压测时候尤其互联网的系统架构压测时经常需要「预热」,需要预热的原因我们清楚吗?因为服务端会对数据进行缓冲。</p>
<p>比如在项目架构迁移时如何做到不漏测,拿火车票电子票从 PHP 迁移到 Java 的乘车人模块为例,迁移前和迁移后访问乘车人模块流程如下图所示。</p>
<h4>1)迁移前电子票和抢票访问乘车人模块方式:</h4>
<h4><img src="/img/remote/1460000020186822" alt="" title=""></h4>
<h4>2)迁移后如下(黄色部分是这次迁移改动部分)</h4>
<h4><img src="/img/remote/1460000020186823" alt="" title=""></h4>
<p>从流程图中可以看出,乘车人模块是抢票和电子票两个业务的公共模块,而此次迁移只有电子票的 App 调用 Java 接口访问乘车人,其他还是调用旧接口,所以乘车人模块重构后要保证电子票和抢票的两个端(App 和小程序)不管从旧接口还是从新接口访问功能都正常,就要弄清楚电子票和抢票这个两个业务哪部分做了迁移,哪部分没有迁移,技术方案设计是怎么样的,这样才能保证不漏测。</p>
<p>那测试人员应该怎么了解一个项目的架构呢?测试人员学习架构或者说了解架构设计应该有测试的独特视角,通常能做到清楚基本原理、了解被测系统部署架构、用到了哪些技术,从测试的角度调用到哪些接口就够了,当然如果能学习的深入更好。</p>
<p>首先,不管是已经上线的项目还是在正在进行中的项目,都有系统架构图,先从系统架构图入手,了解服务都有哪些,这些服务分布在哪一层,比如有面向用户接入层,中间处理不同业务的业务层服务,还有从外部服务获取数据外部接入层服务,还有数据存储、缓冲,不同层之间进行交互的协议、中间件都可以从架构图中看到,能帮助我们快速的对整个项目建立一个框架。</p>
<p>其次,查看服务之间的业务交互关系,明确业务数据流转。通过阅读流程图、泳道图、时序图都能帮助测试人员理清楚各个微服务之间的交互关系。下图是根据我自己对马蜂窝大交通抢票业务的理解,梳理的业务架构图:</p>
<p><img src="/img/remote/1460000020186824" alt="" title=""></p>
<p>另外,清楚业务状态机也很重要。熟悉状态机能帮助测试人员更加清晰的理解业务,需求文档是对业务功能的概括,状态机是对业务功能不同情况的分解。</p>
<p>最后,了解一些架构设计知识,比如为什么要用消息队列,好处是什么,在项目中不断积累架构相关的知识,架构相关的知识不断的丰满在进行项目设计方案评审时就可从测试角度提出问题,发现问题,对项目质量起到帮助,因为越早发现问题,损失越小。</p>
<h2><strong>三、关注数据库设计</strong></h2>
<p>数据库的重要性不言而喻,任何一条业务线都离不开。数据库表设计是否合理、是否考虑了业务扩展、是否考虑了读写分离等,都是需要测试人员在参加数据库设计评审,甚至在数据库设计时考虑的。下面分享一些在 Review 数据库设计表时的参考检查项:</p>
<p>1)不同表,相同含义的字段命名是否统一;</p>
<p>2)字段类型是否符合要求,比如数据量大的字段类型设计成 int,应该用 bigint 更合理;</p>
<p>3)字段长度设计是否合理;举例,曾经测试过一个功能,每 10 分钟查询 Redis 中 key 的值存到 MySQL 中,统计值和查询 key 分两列存储,字段长度设计是 60,实际情况是 key 的长度远远大于 60,对 key 进行截断存储,导致查询不到不结果。</p>
<p>4)字段是否为空;接口设计字段可以空,但是表结构设计字段 NOT NULL,与接口数据结构设计不一致,提交的时候显然回报错;</p>
<p>5)是否存在冗余字段;当然有些情况为了效率会允许冗余字段的存在;</p>
<p>6)是否需要分库分表。</p>
<p>除了以上提到的点,在数据库设计方面需要 Review 的内容还有很多,比如是否需要考虑读写分离、表之间的关联是否合理等等。建议大家去了解一些与数据库设计规则相关的知识,来帮助我们在 Review 或者参与数据库设计时发现更多问题。</p>
<h2><strong>四、阅读开发的代码</strong></h2>
<p>说到 Code Review 大家并不陌生,上线前分支合并 Master 要进行 Code Review,开发人员相互交叉进行 Review,研发同学常会听到这样的对话「飞哥帮我 review 下代码」。</p>
<p>Code Review 对于开发人员是很重要的 Check 步骤,对于测试人员也是一样,一个发现缺陷、理解项目的重要手段。阅读代码可以从以下几个方面帮助到我们:</p>
<h4>1. 检查测试用例的遗漏点</h4>
<p>我们都知道测试做不到穷尽测试,不管是做单元测试还是功能用例都不容易做到全部覆盖,尤其是有多个条件的情况下越不容易做到,Code Review 可以帮助我们再次检查是否测试中遗漏功能点。</p>
<h4>2. 帮助测试人员更加熟悉系统,深入理解业务</h4>
<p>黑盒测试的被测对象是已经成型的系统,不能清楚看到业务功能是在系统架构哪部分上实现的。比如现在流行的微服务架构,一个业务功能可能是多个微服务相互协作完成,通过阅读代码,能够清晰的知道业务实现的入口在哪里,调用了哪些服务,一个业务场景从开始到结束经过哪些环节都可以清楚地看到。</p>
<h4>3. 发现增量功能 Bug 和设计缺陷</h4>
<p>业务线的功能是不断迭代的,因提升体验而进行的功能优化和增加新功能都在迭代的范围内。测试人员面对是整个业务线,每次的迭代需要准确判断本次迭代影响的范围来确定测试范围。通过业务代码清楚具体的实现细节、实现方式,在业务功能迭代时,测试人员能准确的判断出代码增量是哪部分,关联受影响的代码是哪部分,确定测试范围,做到精准的测试,在设计评审时反馈可会产生影响的功能给开发人员,与开发形成良好的互动。</p>
<p>说了阅读代码的好处,<strong>测试人员如何去 Review 开发人员代码?从哪几个方面入手?</strong></p>
<h3>1. 带着任务看代码</h3>
<p>带着任务去看代码就是清楚本次迭代有哪些功能,最好在 Review 之前在熟悉一下测试用例,带着功能实现是否存在问题心态去看,关注业务逻辑实现、接口参数定义部分,一些配置的 config 实现可以不用关注,避免陷入到与功能无关的细节中。</p>
<h3>2. 关注代码条件判断</h3>
<p>实现业务逻辑各类条件的判断是必不可少的,也是容易出问题的地方,条件判断错误功能表现可能就是「失之毫厘,差之千里」。条件的判断需要结合业务实际情况,如:</p>
<p>(1)检查 if 语句中每个条件表达式是否正确。比如:变量取值 isNotBlank 和 isNotEmpty 就会导致不同结果,涉及与、或、非的表达式尤其要注意;</p>
<p>(2)检查条件表达式是否涵盖所有关联的变量。举个例子:一个订单状态流转和 a、b 两个变量的取值有关系,其中 b 变量在某些特情况下影响订单状态。如果在条件中只考虑对 a 的判断而忽略 b,就导致功能不完整。</p>
<p>在进行火车票的改签测试有这样一个 bug,同一个乘客成功购票后——>将票改签到其他日期——>再退票,然后这个乘客在买同样日期相同车次的票提示行程冲突,预期结果是:用户已经改签到其他日期并且退票,可以再次购买。下图是一个简化的流程图,判断是否行程冲突(黄色部分是导致bug的原因):</p>
<p><img src="/img/remote/1460000020186825" alt="" title=""></p>
<p>从流程图可以看出如果乘客有已出票的订单需要先判断是否出行或退票,如果否的话说明还是在出票状态,那需要继续判断是否进行了改签,如果已经改签允许用户继续创单,导致 Bug 的原因就是少判断了是否改签这个条件。</p>
<p>(3)检查对条件不同值给出的处理结果是否正确。举一个简单的例子:学生成绩不同区间对应 a、b、c 三个不同档有如下伪码:</p>
<p>If (s>=90):</p>
<p>Print「a」</p>
<p>Elseif (s>=80 && s<90):</p>
<p>Print「b」</p>
<p>Else:</p>
<p>Print「c」</p>
<p>上面的这段代码没有考虑s取异常值的情况,学生成绩取值是大于等于0的,还有就是成绩大于100时,在c档是否合理,也需要考虑实际需求。</p>
<h3>3. 关注循环语句</h3>
<p>所有的循环是否都有结束条件即所有的循环都能正常的结束;进入循环的入口条件是否正确即能进入到循环中;循环的条件是否存在越界的错误等。</p>
<h3>4. 检查代码中接口定义与接口文档的定义是否一致</h3>
<h3>5. 针对增量代码进行 Review</h3>
<p>通常由于时间有限,没有足够的时间阅读所有的代码,可以选择仅对对增量代码进行 Review,检查是否存在功能遗漏、改动代码对是否原有功能产生影响。</p>
<h3>6. Review 后知识沉底</h3>
<p>前面的几点都是再说如何去做,在阅读代码的过程中进行知识沉淀也很重要。在 Review 完成后,可以对发现的问题进行整理归类,在后面的测试过程中可以做为测试用例进行补充。Review 完成可以尝试画服务的流程图,项目架构图,帮助的自己对项目理解更深入。</p>
<h3>7. 测试人员进行代码的反讲</h3>
<p>阅读完代码后,测试人员反讲对代码的理解,可以邀请开发人员一起参加。</p>
<p>当然,我们在看到代码会碰到很多问题,可以向开发同学请教,了解代码结构,比如哪部分是业务实现代码,哪些是和数据库交互设计、哪些配置文件、哪些是接口定义文件,这些都可以帮助我们快速了解项目代码结构。</p>
<h2><strong>五、熟悉项目配置文件</strong></h2>
<p>为了灵活应对一些由于突发状况或频繁上线对业务带来的影响,在项目的实现过程中研发人员会把一些功能通过配置文件的方式去实现,比如流控配置、对不同业务场景的需求配置、为进行灰度测试的配置等,除此之外还有静态的环境配置。在配置文件内容的 Review 中应该关注的重点包括:</p>
<ul>
<li>不同环境的配置文件不同,以防止将测试环境的配置同步到生产环境产生损失</li>
<li>功能配置开关,比如限流、降级服务开关、外部依赖如供应商的上下线</li>
<li>业务参数配置,业务功能的一些参数需要随时灵活配置,比如一些活动规则、临时性的通知信息</li>
<li>除了业务相关配置还有中间件的配置也需要关注,比如 tomcat、dubbo、mq 的参数设置很重要,对服务性能的影响非常明显。</li>
</ul>
<p>测试人员深入到一个项目中,需要了解熟悉的远远不止我在上面提到这几个方面,还有很多,比如缓冲设计、缓冲失效时间设置,存储方式等,服务日志记录,随着对业务、系统架构的熟悉,这些都需要去了解,从而在测试中帮助到我们。</p>
<h2><strong>总结</strong></h2>
<p>上面是我对测试人员为什么要深入到一个项目实现中的,以及如何去深入的一些看法。测试作为项目最后一个环节,新的测试技术、手段、理念不断出现,但是保证项目质量的目标没有变。而深入到项目中,了解项目代码、了解项目设计对于一个优秀测试人员是必须具备的技能。当然,文中的内容也存在一些局限,欢迎其他测试小伙伴一起交流。</p>
<p>最后,马蜂窝大交通团队也在持续招聘中,测试、前端、Java 开发多个坑位,欢迎有意向的小伙伴来勾搭,简历请发送至邮箱:dongmin@mafengwo.com</p>
<p><strong>本文作者:董敏,大交通研发团队测试工程师。</strong></p>
<p><strong><img src="/img/remote/1460000020186826" alt="" title=""></strong></p>
多渠道推广场景下,如何实现 App 用户增长的精准归因?
https://segmentfault.com/a/1190000020165791
2019-08-23T15:54:00+08:00
2019-08-23T15:54:00+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
1
<p>为了实现用户的快速增长,以推广 App 为目标的线上广告投放是很多平台获取新用户的重要方式。随道移动互联网的发展,现在 App 推广的渠道越来越丰富,除了 WAP 站点、第三方 App 之外,HTML5 成了 App 推广的又一个主战场。</p>
<p>选好了合适的推广平台,预算(理论上)也到位了,作为直面用户的重要一环,如果没有做好对投放效果的追溯和评估,将直接影响到用户增长的整个过程,使之前的种种努力功亏一篑。</p>
<p>App 激活是指新用户首次打开 App 的行为。在进行一轮广告投放之后,对 App 激活渠道的归因分析是定位用户来源、效果评估和推广成本核算的主要方式之一。</p>
<h2>传统的 App 激活渠道归因</h2>
<p>目前常见的 App 激活归因方式有设备号归因、渠道号归因、IP+UA 归因等。以下分别进行简要介绍。</p>
<h3>1.设备号归因</h3>
<p>设备号归因主要应用于第三方 App 中推广,应用场景以信息流广告为主。</p>
<p>大多数情况下,第三方 App 都可以获取到用户移动终端的设备号,如 iOS 系统下设备的 IDFA、Android 设备的 IMEI。因此在信息流等广告中,第三方平台反馈给广告主的点击数据通常会包含用户的设备号信息。当用户下载 App 完成激活后,可以将获取到的设备号与第三方广告平台反馈的设备号进行匹配进行归因,来评估投放效果。</p>
<p><img src="/img/remote/1460000020165794" alt="" title=""></p>
<p>这种方式的归因相对比较精准。但需要说明的是,为了得到更准确的分析结论,我们会同时使用多种归因方式,通常来说设备号归因的优先级较高。这就带来一个问题,通过其他形式推广带来的激活很可能会首先与设备号归因的方式匹配。比如用户点击了信息流广告之后并没有产生下载 App 的愿望,而在之后点击了 HTML5 广告并促使其完成了最终下载激活 App 的行为。</p>
<p>按照行业通用的 Last Click(最后一次点击)的计算方式,实际应该归因在 HTML5 广告下。但 HTML5 的渠道又无法获取用户的设备号信息,所以这次行为很可能就会被归因在优先级较高的信息流形式下,导致误差的产生。</p>
<p><img src="/img/remote/1460000020165795" alt="" title=""></p>
<h3>2.渠道号归因</h3>
<p>「渠道号」指写入安装包的渠道标识。一般会将渠道号提前写入 APK 安装包里,然后分发给不同渠道,渠道号会伴随安装包的整个使用周期。用户激活 App 后,可以从安装包获取到渠道号标识信息进行匹配,所以理论上也是相对准确的归因。</p>
<p><img src="/img/remote/1460000020165796" alt="" title=""></p>
<p>但这种方式会出现被手机应用厂商拦截的情况,也容易被不良的渠道方拿来进行数据作弊,从而无法有效评估真实的线上推广效果。</p>
<h3>3.IP+UA 归因</h3>
<p>IP+UA 是指通过将用户点击广告时的 IP、User-Agent(简称 UA,用来提取用户的操作系统、版本号、手机型号等信息)信息与激活时的 IP、UA 进行关联匹配实现归因分析,一般来说使用短链来收集这两个信息,好处是用户友好、方便管理、方便信息收集和设置。</p>
<p><img src="/img/remote/1460000020165797" alt="" title=""></p>
<p>IP+UA 归因主要应用在 Web 站内导流、SEM 推广和一些无法通过设备号及渠道号归因的广告投放场景下使用,如 HTML5 广告、WAP 广告等。所以 IP + UA 虽然也是一种主要的归因方式,但本质上是一种模糊匹配的归因,因为这种方式无法直接获取用户客户端的设备号等精准信息,并且用户的 IP、UA 两个参数容易随环境变动和重复,因此使用的优先级也较低。</p>
<p>比如在办公环境网络下,多个用户使用同一个 IP,或者多个激活 App 的用户使用的手机品牌和型号完全相同等情况下,很难实现精准归因。更糟糕的是用户点击广告的 IP 与激活时的 IP 很有可能是不一致的,比如用户在 Wi-Fi 环境下点击并下载了 App,但是在 4G 环境下进行了激活,由于网络环境的改变,IP 地址也会随之改变;再如,同一个网络环境下 IP 相同,A 用户点击了广告但未下载,B 用户没看到广告,但通过应用市场直接下载 App 激活了,并且这两个用户的手机品牌和型号完全相同,也就是 UA 一致,这些情况下 IP+UA 的归因方式都是完全无效的。</p>
<p>由于 IP+UA 存在的这些问题导致这种方式的使用优先级较低,但又会导致上文提到的 HTML5 广告推广会被匹配到信息流广告渠道中。</p>
<h3>小结</h3>
<p>综上所述,提高对不同渠道归因方式的精准度,降低分析误差产生的可能性非常重要。</p>
<p>在调研的过程中发现,我们了解到现有一些方案在 IP+UA 方式的基础上进行了一些优化,比如通过注册用户和短链节点计算关联度来进行归因,以及在现有 IP+UA 的基础上更改匹配算法来达到归因的目的。但这些方法基本还是在围绕 IP 和 UA 两个参数进行调优,对于上文中所说的 IP 更改或 UA 有效信息相同情况下的归因错误问题,仍然无法避免。</p>
<h2>基于剪贴板的用户唯一标识归因分析</h2>
<p>为了应对获取设备号失败 (如用户关闭广告追踪),或在 HTML5、WAP 广告投放场景下使用 IP+UA 精准度不高的问题,我们设计了一种基于「剪贴板」归因的方案,来提升渠道归因的精准度。</p>
<p>使用剪贴板进行归因分析的特点在于,可以通过获取唯一标识的方式,提升在 HTML5、WAP 等无法获取设备号的广告投放场景下的归因准确性,同时减少由设备号匹配带来的噪音。</p>
<h3>1. 实现流程</h3>
<p>具体流程如下图所示:</p>
<p><img src="/img/remote/1460000020165798" alt="" title=""></p>
<p>(1)在 HTML5、WAP 等广告投放中,当用户点击广告时向剪贴板写入唯一标识;</p>
<p>(2)写入系统剪贴板的同时由服务器记录用户唯一标识;</p>
<p>(3)用户下载 App 激活后,由 App 读取剪贴板符合规则的信息并上报到服务器;</p>
<p>(4)服务器关联点击时记录的唯一标识和 App 激活后上报的唯一标识进行归因。</p>
<h3>2. 主要优势</h3>
<h4>(1) 使用户具有唯一确定性</h4>
<p>上文提到 IP+UA 的短链匹配存在的主要问题包括:</p>
<ul>
<li>用户点击数据的 IP 地址与激活 IP 地址发生改变则完全不能进行归因,而用户网络环境切换是较为普遍的情况;</li>
<li>相同网络环境(IP 相同)、不同用户但设备类型(UA 相同)相同而导致的归因错误</li>
</ul>
<p>在剪贴板归因的方式下,当用户触发点击时会向用户的不同操作系统(Android 、iOS)剪贴板写入一个形如特殊字符+随机字符串+特色字符的标记,(例:$f803489a$),形成当前点击广告信息用户的唯一标识。当用户下载 App 进行激活时,客户端就会读取到剪贴板中这个唯一标识并上报给服务器,服务器接收信息后进行规则验证和存储,在 App 激活时进行唯一标识的关联匹配,最终实现精准归因,从而有效解决了 HTML5、WAP 等投放场景下通过 IP+UA 方式的归因误差问题。</p>
<h4>(2) 通用于 Android、iOS 系统,数据获取简便</h4>
<p>使用剪贴板可以通用于 Android、iOS 系统,数据读取获取简单,有效架设了 HTML5、WAP 等广告投放与客户端 App 之间的桥梁。并且,由于在 Android Q 版本之后将获取不到 IMEI(安卓手机设备号),剪贴板归因将有可能应用到更多的场景。</p>
<h4>(3) 标识信息生成规则灵活</h4>
<p>写入剪贴板的唯一标识信息可按照任意规则进行生成,只要是可以区别于其他剪贴板的内容,能够用来唯一表示一次广告点击来源的口令即可。同时可以在该标识中加入投放站点的标识信息,这样后面 App 在读取剪贴板信息时可以进行渠道信息的初步验证,从而减少无用信息的上报。</p>
<h3>3. 应用</h3>
<p>目前在马蜂窝用户增长激活归因分析中,应用了剪贴板归因方式后,整体归因准确率提升超过 11% 。</p>
<p>在进行归因分析时,由于唯一标识可以明确用户的渠道来源,因此可以优先应用剪贴板归因,再用 IP+UA 作为辅助验证手段来提高归因分析的准确性。建议可以将基于剪贴板的唯一标识归因方式与设备号归因放到同一个优先级进行匹配,如采用 Last Click 判定形式时,可根据设备号查找设备信息的最近一条点击,同时与唯一标识对应的广告点击进行时间比对,取时间距离最近的一条点击作为推广来源,达到减少设备号归因误差的目的。</p>
<h2>总结</h2>
<p>精准的归因在 App 推广中非常重要。比如当前推广一个旅游 App 的成本大概在几元到几十元不等,传统归因方式引发的分析误差很可能会造成双倍损失,更重要的是如果不能精确分析是哪种渠道带来的用户,我们就不能准确评估推广效果,用户增长的持续优化更是无从谈起。</p>
<p>精准的归因分析是精细化运营的利刃,马蜂窝用户增长团队也会不断探索,尽可能多地到哪些被忽视的场景中,挖掘那些饱有价值的流量与新增入口。</p>
<p>最后,也欢迎更多伙伴加入马蜂窝用户增长团队,现有前端、服务端、算法、测试多个坑位在持续招聘中,有意向的朋友可以发送简历至:lipei@mafengwo.com.</p>
<p><strong>本文作者:徐练胜,马蜂窝用户增长团队服务端研发工程师。</strong></p>
<p>(马蜂窝技术公众号原创内容)</p>
<p><img src="/img/remote/1460000020165799" alt="" title=""></p>
每个程序员都可以「懂」一点 Linux
https://segmentfault.com/a/1190000020042176
2019-08-12T11:16:45+08:00
2019-08-12T11:16:45+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
9
<blockquote>提到 Linux,作为程序员来说一定都不陌生。但如果说到「懂」Linux,可能就没有那么多人有把握了。到底用 Linux 离懂 Linux 有多远?如果决定学习 Linux,应该怎么开始?要学到什么程度?懂一点 Linux,对于程序员有什么价值?通过马蜂窝内容中心高级研发总监李鸿的这次内部分享,你会得到一些答案。</blockquote>
<p><em>(本文根据马蜂窝技术研发团队内部分享整理,搜索马蜂窝技术公众号,后台回复 「linux」获取 PPT 全文。__)</em></p>
<p>大家好。我先简单介绍一下自己,我是李鸿,目前负责马蜂窝内容中心的技术研发和团队管理。</p>
<p>接到今天这个任务的时候,我就在思考要分享什么内容。在座的同学应该有一些工作的时间比较久,也有一些刚从学校毕业。所以今天所讲的东西,如果能让不同阶段和技术背景的同学产生共鸣,让大家改变了一些对技术的看法,甚至是产生了一点对职业规划上的影响,我认为这次分享才有意思。</p>
<p>出于这些考虑,我选择了今天的主题——每个程序员都可以「懂」一点 Linux。</p>
<p><img src="/img/remote/1460000020042179?w=1080&h=474" alt="" title=""></p>
<p><strong>主讲人:李鸿</strong></p>
<p><strong>马蜂窝旅游网内容中心研发高级总监</strong></p>
<p>(李鸿,现为马蜂窝内容中心技术团队负责人。拥有十余年移动互联网从业经验,多年从事移动地图 App、LBS 企业级服务和智慧交通相关产品研发。个人技术兴趣聚焦在 Linux 生态,包括 Linux 内核等底层技术。)</p>
<h2>Question 1 :为什么讲这个主题?</h2>
<p>想到这个内容,也是基于我自己在技术成长上的一些感悟。</p>
<p>我比在座大多数同学年长几岁,大概十几年前大学毕业。今天我在跟很多面试候选人聊的时候,我会问他们「为什么选择计算机专业」,大部分人给我的答案都是碰巧选了计算机,或者听说这个专业的就业前景不错。</p>
<p>当然也会有同学和我一样,是出于喜欢。我最早接触到计算机还是读初中的时候,当时电脑很贵,家里也没有。有一次在商店里我看到了一台「小霸王」学习机,有人通过在键盘上敲一敲,就能真的在屏幕上出现一点东西,我觉得简直太有意思了,就在当时,我知道自己以后一定会学计算机。</p>
<p>大学之后,基本大一大二接触的都是 Windows。一天偶然看到一些 Linux 代码,从那之后我就开始自学 Linux,直到钻研 Linux 的内核。十几年后我再来看,还是会感叹 Linux 世界的神奇,而且庆幸自己的选择没错。</p>
<p>所以今天,我想分享下在学 Linux 这个过程中的一些思考:什么才是真正的 Linux、它为什么好、我们应该从哪里入手开始学习,希望大家可以有所收获。</p>
<h2>Question 2 :你 「懂」Linux 吗?</h2>
<p>当问到是不是懂 Linux 的时候,包括我身边的很多朋友都会说「还可以啊,我一直都在用」;也可能会说「懂一点,我听说过 Linus 这个人」,等等。但至少我认为,如果你只是在说以下这些,真的不叫「懂」Linux:</p>
<p><img src="/img/remote/1460000020042180?w=510&h=341" alt="" title=""></p>
<p>那什么才叫「懂」Linux ?如果把这件事讲透,我认为核心要解决的就是<strong>三个「W」——What,Why,How</strong>。</p>
<p><strong>What</strong>:一些同学在开始投入某个技术领域的时候,可能基础比较薄弱,会很辛苦地学习。学了一段时间以后自己觉得学到了好多东西,但其实很多人并没有学到这个方向的关键、核心和本质。比如我遇到过很多做大数据分析的人,说到 Hadoop、Spark,相关的单词可以说不少,但问到「Spark 和 Hadoop 有什么本质的区别」,「Spark 对数据的界定有什么本质的不一样」这些问题的时候,还是说不上来。</p>
<p>每个程序员的时间和精力是很宝贵的。在我们整个职业生涯中,可能用十年、二十年去学透一、两个东西已经很不容易了。如果决定花时间去学习某个技术之前,一定要想清楚学的是什么,千万不要学偏了,甚至都没走在自己规划的职业方向上。</p>
<p><strong>Why</strong>:为什么学?是出于兴趣爱好?是对实施架构很重要?是会影响你的职业规划?是这项技术将来会有很好的市场收益?……不管你的答案是什么,自己要比较清晰。</p>
<p>有一些同学技术学得很杂,问哪个都说比较熟。但问他哪个技术他比较有研究,是他比较资深的,好像又都没有。这就是他没想清楚「Why」,也就想不清楚自己的重心要放在哪里。</p>
<p><strong>How</strong>:前两个问题解决完,就应该去思考「How」。到底应该怎么学,才能学得越来越好。</p>
<p>今天我们是围绕 Linux 在解决这三个 W,换成任何别的技术,其实都有相通之处。最近 7、8 年我面试过不下 500 个 Java 研发,几乎每次我都会问「能不能用七八个概念说说你对 Java 的认识,或者你为什么喜欢 Java」,很少有候选人人能真的把这个问题说清楚。</p>
<p>所以我建议各位同学,以后再投入一项技术的学习之前,都先从以上三个 W 去审视一下,看你是不是真的清楚要学的是什么,为什么学,怎么才能学好。</p>
<h2>What——什么叫做懂 Linux</h2>
<h4><strong>1. 知道为什么学</strong></h4>
<p>一定不是说因为 Linux 「时髦」,也不是现在的工作中急需用它去解决某个问题,而是确实会对长远的知识架构和的职业发展产生质的影响,才值得花费精力和时间。</p>
<h4><strong>2. 知道要构建怎么样的 Linux 知识架构,并对专攻的技术方向提供源源不断的能量</strong></h4>
<p>学习一个东西要先看全局,要去想 Linux 整体的知识架构、各部分占的比重、在它背后还需要掌握哪些知识、学习它带来的收益是什么等等,真正形成系统和规范化的学习。如果一开始没有建立起整个知识架构的话,后面会浪费大量时间。</p>
<p>这里特别强调「<strong>专攻</strong>」。我认为专攻某个方向的价值远远大于泛泛地了解。大家职业生涯越是走得远,越会发现专攻某个方向的意义。如果开始就是泛泛地学,后面对自己的定位会非常困难,因为你不知道自己的优势是什么,适合在什么岗位,应该选择什么路径来发展。</p>
<h4><strong>3. 知道学习 Linux 的最优方法</strong></h4>
<p>要想学好 Linux,最核心的还是要找到正确的方法。什么才是学 Linux 最好的方法?是去翻翻文章、看看文档吗?是去学敲命令吗?是去学 SHELL 吗?如果这些都不叫「学」,什么才是学 Linux 最优的方法?</p>
<h4><strong>4. 知道 Linux 背后的设计哲学、优点、历史和文化</strong></h4>
<p>我们身边有很多技术同学关注的都是怎么使用 Linux ,于是就去把书里是怎么讲的、用过的人是怎么说的统统记下来,根本不会思考记录的这些内容背后体现了什么。如果长期只处在一个单向接收信息的过程里,你就无法练习出反思和总结的能力,更不要说可以达到批判性地审视某个技术,甚至提出质疑的水平。</p>
<p>而要想真正从学习中获得成长,能够和接收到的信息产生互动,去引发更多的思考,就要去知道 Linux 背后的设计哲学、它的优势、历史文化是什么。</p>
<h4><strong>5. 喜欢 Linux,爱上她</strong></h4>
<p>学习的辛苦、做研发的辛苦,相信大家都深有体会。那么坚持去学习、去学好某个技术的最大前提,是你要喜欢它,甚至热爱它。因为只有这样你才会觉得这个过程有意思,才会产生继续向下深挖的兴趣,才会愿意去做更多的推理。 </p>
<p>不只是 Linux,包括现在工作中用的语言、开发环境等等,如果大家实在喜欢不起来,我建议你再去探索一下,去找到自己真正喜欢的领域。</p>
<p>说了这么多,如果用一个词来判断什么是「懂」Linux,我想应该是去看自己能不能真正「理解」Linux。</p>
<h2>Why——为什么要懂 Linux</h2>
<p>今天的主题是「每个」研发都可以懂一点 Linux ,这是为什么?其实很多技术是可以不懂的。比对后端需要的是处理业务逻辑,那就不需要一定去懂前端的 WebGL;再比如做大数据的同学,也不需要太懂编译。为什么 Linux 我就建议每个同学都要去学一点?而且为什么在那么多操作系统中,我只挑了 Linux 呢?</p>
<h3>-为什么选 Linux ?</h3>
<ul><li><h4><strong>开放</strong></h4></li></ul>
<p>投入一个有开放的心态、开放视角的技术,给我们带来的成长和收益将是无穷的,这也是开源世界带给我们的一个重要课题。我非常相信一点,随着国内经济的发展、大家认识的逐渐完整,中国的软件市场也会越来越开放,大家所处的大环境会越来越好。</p>
<p>Linux 的成功也一定离不开它的开放,离不开整个开源社区的贡献、生态的参与,以及由此带给大家的成就感,驱动他们更愿意去把一些成就分享出去,去开放合作,等等,这些都是促使 Linux 不断走向强大的原因。</p>
<ul><li><h4><strong>遵循标准</strong></h4></li></ul>
<p>对标准的遵循也是 Linux 可以达到今天这样成就的关键。这也是很大的话题。其中有一点我认为非常重要,就是它继承了 Unix 的设计思想,它的 Unix-alike (类 Unix 系统) 设计哲学。</p>
<p>因此,选择 Linux 就是因为它足够优秀,可以带给我们值得去探索和深思,并且可以运用到学习和工作中的知识和思想。</p>
<p>那学习操作系统的意义又是什么呢?</p>
<h3>-为什么要学操作系统</h3>
<h4>1. 带来视角上的提升和改变</h4>
<p>简单画了一个图来代表我对计算机世界的一些理解,可以看到图中每个圆是一环套一环的</p>
<p><img src="/img/remote/1460000020042181" alt="" title=""></p>
<h5><strong>(1)使用软件</strong></h5>
<p>最里面的圆代表的就是一个最小的视野,它对应的是用户拥有的视野。因为作为软件的使用人员,用户是不会去关心背后的开发原理、逻辑实现的,用户只关心这个软件是不是好用。</p>
<h5><strong>(2)开发软件</strong></h5>
<p>对于我们学计算机、做研发的人来说,去使用一个软件其实是比较容易的。因为我们所在的是「开发软件」这个圈子,相对于用户来说,我们站在一个更外围的视角,我们对使用软件这件事看得更加透彻,角度更开阔。</p>
<p>聊一个生活中的例子,我有一次去参观南京中山岭的宋美龄宫,在去之前听别人说,美龄宫像一颗宝石一样,被许多由不同颜色树叶构成的项链包裹在中间。听起来就很美,也我非常好奇,于是去了之后我一直在找这条「项链」。结果当然是找不到。因为大家所说的「项链」是通过航拍看到的图形,我是走在树林中,那肯定看不到。</p>
<p><img src="/img/remote/1460000020042182?w=532&h=363" alt="" title=""></p>
<p><em><strong>图:宋美龄宫</strong></em></p>
<p><em><strong>(来源于网络)</strong></em></p>
<p>你会发现,站的高度不一样,你的视角就会不一样。同样的道理,研发同学之所以理解和使用软件更快,就是因为与用户相比站的角度更高,看的范围更广,我们知道软件设计背后的原理,以及它的交互逻辑,就会很快上手。</p>
<h5><strong>(3)开发框架和库</strong></h5>
<p>如果大家去听一个前端的讲座,为什么当介绍到讲师是某个框架的作者时,我们就会觉得这个分享很厉害?</p>
<p>绝大部分研发,可能 80%~90% 甚至 95% 的同学都是处在「开发软件」这个层面的,我们使用各种现存的框架、开发库去实现业务逻辑。</p>
<p>但是一定有少部分研发关注的是更外围的事情,去做一些开发框架、开发库的实现。这一层的研发需要的能力确实要更强,因为他要思考整个框架怎么拆分模块,怎么样去适应接口让程序员用更好地用起来等等,所以要考虑得更深、更广,挑战也更多。</p>
<p>细心的同学可能注意到了我在「开发软件」与「开发框架和库」中间画了一条红线。我想表达什么意思是,软件研发同学会做出一些很棒的软件,是因为你有这样的能力,也是因为大家头上是戴上了一顶那些开发框架和库的同学给的安全帽的。比如 Java 开发会考虑内存的管理和回收,但这个机制其实是做 Java 开发环境的人帮你做了考虑,帮你提供了应对问题的策略,可以让你更「安全」地做事情。</p>
<h5><strong>(4)操作系统</strong></h5>
<p>再往下看,所有的开发库和开发框架,都是放在一个操作系统上的,与之对应的这一层的研发人员考虑的东西会更加复杂,因为他们要提供的是最基础的环境,是上层实现的基石。</p>
<h5><strong>(5)硬件、规范、协议</strong></h5>
<p>大家看到再往下我画了一个骷髅,也就是说这一层是真正厉害的人,他们做的是硬件、规范和协议,比如说指令系统,我们说的复杂指令系统和简洁指令系统这两个大的指令系统的阵营,在二三十年的时间里都一直在为自己的阵营 PK,目的是为了讨论出更适合软件发展的规范。再比如发明 TCP/IP 协议的人,他们最初在一片混沌的状态下,居然能够提出 TCP/IP 的概念,让我们现在可以非常简单地去做通讯。所以达到这一层的人,我们已经称为天才了。</p>
<h5><strong>(6)数学</strong></h5>
<p>再往下就是数学。我认为计算机回到最后一定是数学,比如说在大学我们都要学习的离散数学、统计学、范式、逻辑学、图灵机等等。数学是对整个计算机体系提升一个最基础的支撑。</p>
<p>所以通过这个图形我们还可以看到,研发同学如果要持续地成长,是绝对存在路径的。我觉得有两个角度是大家可以思考,一是你在专注的方向持续地积累,形成自己的竞争壁垒;同时你可以尝试走入下一个更大的层面,看一看是不是会你的视野,对服务的一些思考,对解决问题的能力都带来一些帮助。</p>
<h4>2. 构建高效的工作和学习环境</h4>
<p>学习 Linux 另外一个非常有用的地方就是「效率」的提升。研发同学每天都要和操作系统打交道,在上面做大量的工作和学习,不管是写代码、看文档、自动跑一些任务、做一些搜索、写一些东西等等。如果懂一点 Linux,懂它的设计哲学,你能更好掌握怎么去用 Linux 更高效。</p>
<p>不夸张地说,如果你真的能够成为一个 Linux 的 Hacker,我认为你的工作和学习效率提升十倍以上是没问题的。我自己就会用 VIM 的话来解决几乎所有问题。</p>
<p><img src="/img/remote/1460000020042183" alt="" title=""></p>
<p>搞技术做工程,如果思想越高、越宏观、越系统,能达到的能力就会越强。懂一点 Linux,首先就是为我们提供这样一种提升视角的方法,帮我们站在一个更外围的角度思考每天的工作和专攻的技术,它们背后是什么样的实现原理和设计思想,它处在怎样的一个体系中,获得了怎样的支撑。 </p>
<p>计算机一个最本质的地方就是「自动化」,所以大家要真的能够理解「自动化」这个词的意义。我们写软件、做管理系统,都是为了要解决以前需要人工来做的事,更好地解放我们的大脑。</p>
<p>既然自动化是最本质的,我们就应该反思在自己的工作和学习中,是不是用到了自动化的思想,你是不是还可以忍受机械、繁琐、低效地处理问题?现在的方式是不是应该改进?通过去学 Linux,可以帮助我们构建一个高效的学习和工作环境,去解决这些问题。</p>
<h4>3. 借鉴优秀的学习样板和实例</h4>
<p>第三个就是对 Linux 的借鉴。其实所有的计算机工程问题,无非都是围绕架构设计、技术选型、代码质量、设计风格、工作流程,自动化程度等相关的问题。如果可以做到理解 Linux,你就会发现在这个操作系统上的很多组件,其实就为我们提供了如何解决计算机工程问题非常多有益的实例。</p>
<p><img src="/img/remote/1460000020042184" alt="" title=""></p>
<p>就如大家在关注一些优秀的开源项目的讨论列表时,你也会觉得有一些人提出的建议并不好,但你可能说不清原因。这时有人做出了一些列举,论证这个建议为什么不好,你就会非常认同,并且吸取他思考问题和解决问题的方法。学习操作系统的过程也一样,Linux 本身就是一个很好的样板和实例,包括它的设计理念、代码质量、文档编写、协同、软件工程、演进以及它的文化,方方面面都会为我们提升非常好的借鉴。</p>
<p>这里我想再展开说一下演进和文化。</p>
<p><strong>演进</strong>是什么?其实我们很多人在做项目的时候是很容易走偏的,因为计算机世界每增加一个维度,它可选择的结果都会带来级数级别的增长。而我们在一个软件项目的推进实现中,要考虑的维度可能成百上千。要在这些纷繁复杂的选择中真的找准方向去演进,需要非常清晰地思考。通过去看一个软件的发展历史,你可以去体会那些优秀的人是如何在一些关键的点上把握方向,来为你自己在做判断的时候提供指导。</p>
<p>另外就是<strong>文化</strong>。我认为包括 Linux 在内的开源项目,核心的文化就是「就事论事,有技术情怀,追求极致,Open 的沟通」。这些理念对每个技术人员的成长都非常重要。比如当我们身处一个规模比较大的公司,成员之间难免会存在沟通上的障碍,可能就会导致误解的产生和对对方的不认可。如果大家以一个统一的文化作为前提,就会用彼此认同的理念和方式去思考问题,也就更容易达成协作。</p>
<h2>How——怎么做到懂 Linux</h2>
<p>最后我们看看用什么方法去学习,才能够越来越懂 Linux。</p>
<h4>1. 理解设计哲学</h4>
<p>我们只有对一件事有了深刻的认识,并且认同之后,才有可能去花时间学好。所以首先我认为要深刻认识到 Linux 背后的设计哲学是什么。</p>
<p>关于 Linux 的设计哲学很多地方都有介绍,我这里也特意没有进行翻译,希望大家对表述中关键的英文单词也建立起认知:</p>
<p><img src="/img/remote/1460000020042185?w=668&h=346" alt="" title=""></p>
<p>下面我把每个点简单地说一下。</p>
<blockquote><h5><strong>Everything is a process; if it's not a process, it's a file</strong></h5></blockquote>
<p>Linux 操作系统认为「任何事都是一个进程,或者说一个线程,是一个执行体;如果它不是一个线程,那么它就是一个文件。」</p>
<p>大家不要认为这句话理所当然,其实很多操作系统都没有这样一个概念,但是在 Linux 的世界,大量的东西是以进程的概念存在的。如果你认为它不是一个可以运行的东西,那它极大可能就是个文件。你会发现很多新的技术都是在这样的设计思想之上,比如说容器。</p>
<p>这种思想的好处是什么呢?我们说解决计算机的问题有一个重要的技巧,就是当你能够把各种复杂的事情都看成是一码事儿,能够从统一的视角去概括它,并且面对它、处理它,那解决起来就会容易很多。因为当计算机面对复杂的现实世界,它能做的就是一层一层的抽象,最后抽出一个非常简单且统一的视角,可以直接地去处理。这是大家在写代码的时候可以去思考的。当你发现你做出的设计能够把两、三个不一样的东西,从一个更高的视角进行统一,这时的你就会比很多人了不起。</p>
<blockquote><h5><strong>One tool to do one task</strong></h5></blockquote>
<p>第二点,一个工具解决一个问题。它的理念是说要把东西做好、做到极致,就要去做专。如果你做的不能比别人更好,你就不要去做,而是要去想如何通过一种方式让用户可以在你的应用上调用自己喜欢的东西,这就是 One tool to do one task。对我们在做程序的时候也有很多帮助,比如是不是能把现在的应用做得非常内聚,而不是去做更多的东西。</p>
<blockquote><h5><strong>Three standards I/O channel</strong></h5></blockquote>
<p>第三点是说每个进程都有三个标准的 I/O:标准输入、标准输出、标准错误,好处是你就会清楚地知道任何终端进程默认都有这三个数据交流的端口,可以自由的进行拼装或者 I/O 重定向,进行功能组合,这其实也就是第四个哲学所说的——</p>
<blockquote><h5><strong>Combine tools seamlessly</strong></h5></blockquote>
<p>把工具无缝地拼接起来。</p>
<blockquote><h5><strong>Plain text preferred</strong></h5></blockquote>
<p>这一点也是我非常喜欢的,就是能用 Text 一定要用 Text。Text 是一种人可以读,机器也可以处理的内容,可以解决好多问题。我们一般说 Plain Text 是指英文。比如说大家写注释要用英文写,它带来的好处是,我们可以通过脚本自动化分析各种 Comment,谁的 Comment 写得多,谁的单词拼错了,谁的 Comment 中包含非常重要的信息,需要重点去跟踪等等。</p>
<blockquote><h5><strong>CLI, not GUI</strong></h5></blockquote>
<p>提倡用命令行,不要用图形化界面。因为命令行可以非常高效进行人机对话,图形化界面对程序员来说是非常低效的。如果做一次更改,我们更希望通过敲键盘的方式来快速告诉计算机应该做什么。</p>
<blockquote><h5><strong>Provide the mechanism, not the policy</strong></h5></blockquote>
<p>这点我建议大家背下来,就是如果你做一个好的大型框架,应该去提供机制,而不是提供策略。也就是要提供创造更多可能性的能力,不要把需要适应到特殊场景下的定制化的内容写死在代码里。所有的软件在这种设计上这点是非常相通的,好的软件一定是为大家提供更多的灵活性和适用场景。</p>
<h4>2. 学习 Linux 的三个层次</h4>
<p>以上的设计哲学都非常重要。那么知道了这些,该怎么学 Linux 呢?大家不要在一开始学的时候就一定要去学内核,或者想要全都懂,于是就认为 Linux 很难。关于「懂」Linux 的阶段,我简单分成了三个层次:</p>
<p><img src="/img/remote/1460000020042186" alt="" title=""></p>
<p><strong>第一个层次就是 Use</strong>,先用起来。但前提是用的时候要符合上面提到的那些标准,也就是要了解它的设计哲学,要知道它的优势,而不是只听别人说怎么配、怎么选才好。</p>
<p>如果把懂 Linux 分为十个「档」,那么 Use 对应的大概是 1-3。其实对于我们 70-80% 的程序员来说,到这里已经非常不错。</p>
<p><strong>第二个层次是 Code</strong>。这里的 Code 不是指在后台写一个 Java 的业务程序,或者是前台写一个网页,而是指系统编程(System Programm),通过编码的方式和操作系统直接对话,而不再是点击鼠标去控制。</p>
<p>虽然系统编程跟大部分人的工作不会强相关。但是通过在应用层用语言(主要是 C 语言)去跟操作系统对话,你会看到在整个操作系统背后的一系列东西是怎么构建起来的,去我们提高视野、提升效率,以及得到更多优秀的借鉴都有很多帮助。除了 Code,如果大家有时间和精力,我建议还可以去了解一下 C 语言。C 语言非常纯粹,就是来告诉你内存长什么样,怎么去控制内存、指令、堆栈,怎么去进行参数传递的方法调用等,你会学到大量计算机架构相关的原理。</p>
<p><strong>第三层是 Hack</strong>,它的档到对应到 8-10, 这可能是每个希望做到极致的技术人最后的追求,去了解内核这一层。</p>
<h5>第一阶段:Use Linux</h5>
<p><strong>(1)终端、键盘、命令</strong>。刚才在讲 Linux 的设计哲学时,我们提到过一条——「CLI, not GUI」。所以对于程序员来说,在学如何跟 Linux 操作系统对话的时候,一定是使用终端、键盘、命令。我想跟大家说,如果你现在还习惯用鼠标,那你可能要反省,看看自己对自动化理解的程度是不是太低了。</p>
<p><strong>(2)一个字符编辑器</strong>。要去找一款自己喜欢的字符编辑器,并且用起来。</p>
<p><strong>(3)SHELL</strong>。第三,如果要用 Linux 理论去提高我们的视角,就一定要掌握一版 SHELL 脚本,并且去深刻理解。至于用哪个版本大家可以根据自己的喜好决定,目前我用的是 ZSH,感兴趣的同学可以去了解下。</p>
<p><strong>(4)文件系统、进程线程、IO 组合、用户权限、资源管理</strong>。再往下我们可以尝试通过编程的方式去调用文件系统、进程线程、IO、用户权限、资源管理等等,去更加系统的了解。这些都会了之后会发现慢慢,以后再写一种高层的代码也就没那么难了。</p>
<p><strong>(5)解剖 Linux</strong>。通过解剖 Linux 可以知道 Linux 是怎么装拼起来的,对它会有一个更直观的认知。我大概在十年前开始接触 LFS(Linux From Scratch LFS),现在它已经演化出了无数个版本,它会告诉你如何开始从零构建一个 Linux 系统,而且它好的地方在于是从源代码的方式去讲怎么编译,最后拼成一个操作系统。这个工作因为需要比较多的精力,所以建议大家三个月到半年的时间跑一次,会很有成就感。</p>
<p><strong>(6)深刻理解背后的文化和哲学</strong>。关于 Linux 背后的文化和哲学,可能总结起来就是那么简单几句话,开始会比较难理解。但是大家如果把这几句话当成一种「信仰」,每次在学和用的时候都能再深刻地体会一遍,可能过了半年,说不定某一天你会突然发现想通了。</p>
<p><strong>(7)参与社区</strong>。大家在参与社区的时候,一定要知道知识的价值是要通过 10 年、20 年的努力去沉淀、去积累的,要持续地参与到社区当中。</p>
<p><strong>(8)最后一个就是持之以恒</strong>,去融入到你的工作、学习和生活当中。Linux 学习曲线的特点是一开始就很陡,不像 Windows,一开始很平滑。但一旦爬过这个陡坡,就会看到一个全新的世界,并且可以一直持续往上走。</p>
<h4>第二阶段:Code Linux</h4>
<p>这个阶段就是刚才我们讲到的,要用编程语言去和 Linux 对话,通过 Code 开始了解二进制 ELF。ELF 是在 Linux 世界的执行文件格式,通过了解 ELF 可以知道一个执行文件是怎么拼写的,它的内存是怎么存在的,指令是怎么跑的,数据是怎么取的,动态库是怎么加载的……如果把这些都搞定,至少在 Linux 领域,就不会再有什么是让你觉得理解起来比较吃力的事情。</p>
<h4>第三阶段:Hack Linux</h4>
<p>关于如何 Hack,这个问题非常庞大和复杂。如果大家有尝试走到这一层的勇气和愿望,我非常愿意和大家一起交流。</p>
<h2>内容总结</h2>
<p>总结一下今天我们讲到的一些内容:</p>
<ul>
<li>知道为为什么要学 Linux:视野、效率、借鉴</li>
<li>知道要构建什么样的 Linux 知识架构,并对自己专攻的技术方向提供源源不断的能源:三个 W(What, Why , How)</li>
<li>知道学习 Linux 最优方法:确定层次 (Use, Code, Hack),实践,持之以恒,融入每天的工作、学习和生活</li>
<li>知道 Linux 背后的设计哲学、优点、历史和文化</li>
<li>喜欢上 Linux,爱上她</li>
</ul>
<p>在分享最后,我想和大家聊聊最近经常思考的一个问题。现在我们总会听到身边一些人在抱怨,说计算机行业已经非常饱和,互联网也已经发展到了一定阶段,再过五年十年计算机就要被淘汰了,研发人员也会面临失业。</p>
<p>我对这个观点是非常不赞同的。</p>
<p>每个人都可以不用工作,每天很开心地享受生活,这应该是大多数人理想的状态。但是人类总要养活自己,唯一能达到这种理想状态的情况,就是由计算机、机器人、电脑帮我们人类完成大部分的工作,不管是做家务、交通出行、盖房子等等。如果这个理想状态的标准是 100 分,对比我们现在,可能仅仅处在 0.1 分的阶段。所以怎么可能会存在纯粹的失业呢?</p>
<p>为什么大家还要进行这样一个讨论?我只能认为有些程序员还没有喜欢计算机,担心自己学不好。学习这个过程的确不容易。就像我们看一本哲学书,开始想要读懂非常困难,但随着人生阅历的增长,随着我们在生活、学习和工作中不断验证书中的道理,你就会体会到其中的道理,提升自己看问题的视角和解决问题的能力。所以最后,我希望大家不要害怕学习,并且相信这个行业的前景,和程序员这份职业可以创造的价值。</p>
<p>以上就是我的分享,谢谢!</p>
<p>(马蜂窝技术公众号原创内容)</p>
<p><img src="/img/remote/1460000020042187?w=1080&h=481" alt="" title=""></p>
支撑马蜂窝会员体系全面升级背后的架构设计
https://segmentfault.com/a/1190000019884889
2019-07-26T14:59:58+08:00
2019-07-26T14:59:58+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
18
<p>流量红利正逐渐走向终结,这已经不再是什么秘密。后互联网时代,如何维系住用户群,提升用户在平台上的体验是整个行业都需要考虑的事情。正是出于这一原因,现在全行业都在关注会员体系的搭建,这也是马蜂窝 2019 年重点投入的方向之一。 </p>
<p>面对这个全行业都在发力的会员市场,要对「马蜂窝特色」的会员体系进行有力的支撑,无疑对会员体系的架构设计提出更高的要求。</p>
<p>马蜂窝会员体系建设从 2018 年 9 月份开始启动,经过前期对会员身份和会员权益的摸索,伴随业务的快速发展,到 2019 年上半年,为了让更多用户体验到马蜂窝高质量的会员服务,公司推出了更灵活、维度更多、权益更丰富的会员模式。在这样的背景下,初期较为粗旷的底层技术也需要及时做出调整,对核心架构和服务进行升级。</p>
<h2>一、会员身份策略改造</h2>
<p>早期的会员身份模块由会员产品、用户属性和时间属性共同构成:</p>
<p><img src="/img/remote/1460000019884892" alt="" title=""></p>
<p>可以看到早期的会员产品比较单一,因此将产品信息设计成一级结构。这种设计的好处是逻辑简单,可以快速实现,但不易扩展,一旦新增会员类别以及不同卡种之间出现复杂关系时,不论是对项目或者对代码本身而言,维护成本都将成倍增长。</p>
<p>从 2019 年年初开始,马蜂窝会员体系进行了全面升级,主要体现在以下几个方面:</p>
<ul>
<li>
<strong>更完善的获客渠道</strong>,增加了在小程序端的服务展示;</li>
<li>
<strong>更丰富的会员类别</strong>,新增了非常多卡种,在最初的年度金卡和体验金卡基础上,增加了季度金卡、 7 日卡、「蜂享卡」,未来还计划推出月度金卡、学生卡等;</li>
<li>
<strong>更低的获取门槛</strong>,早期的会员身份只能通过在 App 中购买获得,为了让更多用户享受到品质更高的服务,增加了通过完成用户激励任务、供应商合作、产品搭售、线下实体卡等会员获取方式。</li>
</ul>
<p>这也意味着,同一时间段内用户的会员身份将变得愈发复杂,早期单一的会员身份策略和模型设计已经不能满足需求。重新设计会员身份的时候,我们明确了未来无论业务线如何划分会员身份,底层结构都要能够较好地支持,因此决定把会员模块身份抽离出来。会员体系升级后,产品信息调整为以 SKU 作为最小粒度重新划分,同时增加了用户信息中的来源以及获取渠道信息:</p>
<p><img src="/img/remote/1460000019884893" alt="" title=""></p>
<h2>二、会员中心架构设计和优化</h2>
<p>在明确了新的会员身份策略后,我们对整个会员体系进行了梳理,将现阶段的会员中心架构设计如下: <br><img src="/img/remote/1460000019884894" alt="" title=""></p>
<p>合上面的架构图来看,目前马蜂窝会员中心系统主要划分为数据存储、核心服务、接口层、应用层四大部分:</p>
<ul>
<li>
<strong>数据储存</strong>:主要基于 MySQL 和 Redis,以及马蜂窝统一日志系统 MES</li>
<li>
<strong>核心服务</strong>:这是当前马蜂窝会员体系中最重要的一层。核心服务又可以分为三大块:<p>(1)「四驾马车」:会员身份、权益、增值服务接入、会员积分,驱动着整个会员体系的运转;</p>
<p>(2)交易营销:辅助四驾马车快速往前跑;</p>
<p>(3)支撑模块:与会员体系对接的公司级别支撑模块,包括风控、监控、日志、消息总线、商家结算对账等</p>
</li>
<li>
<strong>接口层</strong>:会员体系对外暴露的接口,包括了会员身份、权益领取、蜂蜜消费等接口</li>
<li>
<strong>应用层</strong>:主要是面向 C 端的应用,包括会员频道页、蜂蜜中心、用户权益中心、任务中心等</li>
</ul>
<p>下面重点围绕「核心服务」层展开介绍。</p>
<h3>2.1「四驾马车」</h3>
<h4>2.1.1 会员身份</h4>
<p>目前,市面上很多常见的会员产品都是采用普通的续费模式,比如一些视频平台的年度会员、季度会员。这种模式的特点是只进行时间的区分,在会员身份后生效后享受的权益完全相同,通过续费使权益时效得到相应延长。</p>
<p>但是马蜂窝由于业务的特殊性,会员体系需要设计得更为立体。如果只采用单纯的续费模式,会影响高忠诚度用户的使用体验。</p>
<ul>
<li>首先,在同一类别的会员身份下,时长不同的产品对应的权益也不同。以金卡会员为例,季度金卡、年度金卡这种同类别下的会员身份,可以通过续费升级,但它们彼拥有的权益不完全相同,比如年度金卡 96 折抵额上限为 500 元,季度金卡只有 100 元。</li>
<li>另外,同一用户在同一时间内,只要满足条件,就可同时拥有不同类别的卡种,比如金卡和蜂享卡。</li>
</ul>
<p>为了满足上述需求,我们决定引入用户身份的叠加以及续费模型。通过增加会员 SKU 叠加、续费关系表,使用户在一个时间段内不仅可以同时拥有多种身份,还可以续费已有卡种。</p>
<p><img src="/img/remote/1460000019884895" alt="" title=""></p>
<p>上图是会员身份的时间轴示意。横轴代表时间,纵轴代表不同的卡种。我们通过最终 SKU 时间轴便可以确认用户当前的会员身份。</p>
<p>我们将用户已有的每个 SKU 时间轴拉平,当用户在某个时间点发出购买新卡种的请求时,查看当前生效的时间轴中是否已有用户正在购买的 SPU,如果没有则叠加,如已有则需要再判断 SKU 之间的配置策略,决定是叠加还是续费;然后继续计算出正在购买的 SKU 生效时间轴;接下来根据配置好的规则,对比当前购买生效时间轴和已有 SKU 时间轴的身份关系,决定用户是否可以完成此次购买,如:</p>
<ul>
<li>前置身份:指必须已经购买某个 SKU,才可以购买当前 SKU</li>
<li>冲突身份:指如果已经购买某个 SKU,就不可以购买当前 SKU</li>
</ul>
<p>为了满足不同的业务需求,这里的叠加、续费关系都是可以通过运营来配置的。整个流程大致示意如下:<img src="/img/remote/1460000019884896" alt="" title=""></p>
<p>为了让用户的体验更好,当同时拥有多重身份的时候,我们会根据数据分析结果调整会员 SPU 权重,优先展示权重高的权益。比如当前会员同时拥有金卡和门票卡,数据显示金卡权益的使用率或者关注度高于其他产品,则提升金卡权重,金卡身份和相关权益会在用户进入会员频道页时首先展示。</p>
<h4>2.1.2 权益中心</h4>
<p>除了身份体系,最重要的就是会员权益,它直接体现会员的不同级别。会员项目发展初期,一切都是从零开始,对拓展性要求不高,每出现一种新的身份、卡种,都需要从头设计其所含权益,开发效率很低,后台的配置也很分散。后期为了支撑业务快速发展,我们开始考虑将权益中心进行拆分,分成两部分进行改造。</p>
<p><strong>第一步是权益池的搭建</strong>,下图是权益池的基本模型:</p>
<h3><img src="/img/remote/1460000019884897" alt="" title=""></h3>
<p>我们将会员权益中通用的属性抽象出来,定义为原则上不变的基础属性,形成「权益物料」存放在权益池中,通用的属性主要包括:</p>
<ul>
<li>权益类型:主要有兑换码、折扣购买、优惠券、三方跳转 4 种,目前能支持到马蜂窝所有的权益类型</li>
<li>供应商:不同供应商提供了不同的权益,甚至还有不同的权益接入流程和权益消费流程,同时和涉及了不同的供应商结算模式</li>
<li>下发时机:主动下发或者被动下发,例如金卡 96 折权益,是用户购买会员的核心权益,这种权益在用户购卡之后便直接下发至用户账户。其他的权益例如机场贵宾厅、QQ 绿钻、腾讯视频季卡等则需要用户主动领取。</li>
<li>基础属性:权益的基础属性依赖于权益类型、下发时机、供应商,也就是说不同的供应商或者不同的权益类型和下发时机,都会组合出不同的权益基础属性,这里的属性大多是这些权益的固定属性。最终这 4 大属性共同组成了基本的权益物料。</li>
</ul>
<p>下图是用户开卡及权益发放的流程示意:</p>
<p><img src="/img/remote/1460000019884898" alt="" title=""></p>
<p>当会员产品支付完成后,会员中心会通知权益中心发放权益;权益中心进行权益过滤之后通知优惠中心,最终由优惠中心完成被动权益的发放;需要用户主动领取的权益则只为用户发放使用权利,最终由用户决定是否领取。</p>
<p><strong>第二步权益规则的配置</strong>。有了第一步的基础之后,会员中心为权益池中的权益物料配置相应的权益规则,之后展示给用户。</p>
<p><img src="/img/remote/1460000019884899" alt="" title=""></p>
<p>权益规则主要划分为:</p>
<ul>
<li>条件规则:指确定权益的一些基本前提,主要指会员身份、前求来源、当前业务等</li>
<li>通用规则:指对外展示的标准,包括文案、排序、上下线时间、权益说明等等</li>
<li>运营规则:这是权益规则中变动最多,也是体现权益中心精细化运营的一部分。不同的用户身份拥有不同的权益价格、兑换价格以及不同的标签,差异化地显示用户的身份特权</li>
</ul>
<p>我们抽象出了权益规则中的通用属性,形成权益对外展示统一的标准。当然,只有通用的权益规则配置是远远不够的,因此在不影响核心权益规则的前提下,在后台加入了扩展规则模板的配置,以便满足特殊权益不同规则的需求,实现动态规则配置,使用起来更加灵活。</p>
<h4>2.1.3 第三方权益接入</h4>
<p>权益池中有一部分是站内权益,比如核心的金卡商品 96 折、马蜂窝优惠券、接送机等。这些权益的发放和消费在站内建立的统一规则下完成,接入起来相对容易。</p>
<p>权益池中有一部分是站内权益,比如核心的金卡商品 96 折、马蜂窝优惠券、接送机等。这些权益的发放和消费在站内建立的统一规则下完成,接入起来相对容易。</p>
<p>另外一部分是需要接入的站外权益,也就是为会员供提的增值服务,比如机场贵宾厅、旅行保险等。不同的第三方都有自己权益规则的特殊性,目前无法抽象成统一标准,也就无法采用 OpenAPI 的方式接入。</p>
<p>现阶段我们把第三方权益的接入进行了流程上的整合,最终形成了两大类方式:</p>
<ul>
<li>一类是权益领取在马蜂窝内完成,用户所有的操作完全在我们的应用里进行,完成后异步再调用第三方接口为用户发放权益。</li>
<li>第二类是权益领取过程完全在第三方系统中进行,主要针对一些积分兑换的权益。用户点击领取权益后跳转至第三方页面,交互完成之后异步回调马蜂窝接口,马蜂窝系统根据回调情况进行积分的增加或者扣减。这种方式的弊端是用户体验完全由第三方决定,可控性不高;但优势在于能够快速接入一些复杂的权益玩法,比如一些游戏类权益,避免投入大量精力去开发。</li>
</ul>
<p><img src="/img/remote/1460000019884900" alt="" title=""></p>
<p>上图是两种领取模式的流程对比图,可以看到每一步的三方对接都是通过异步方式进行的,这样当第三方系统出现异常不会影响到马蜂窝的正常服务,使系统可用性得到保证。</p>
<h4>2.1.4 会员积分</h4>
<p>成长体系对于搭建完整的会员体系非常重要,以内容社区起家的马蜂窝在这方面有天然的优势。我们决定引入已有的用户积分体系「蜂蜜」来承载一部分会员积分的功能。通过与会员中心打通增强与会员用户的线上互动,提高用户活跃度和黏性。在不同的蜂蜜场景和蜂蜜策略下,用户可以赚取积分,满足相应条件后可以兑换所需权益;此外,我们也正在拓展更多蜂蜜和 B 端的结合方式,希望促进平台和商家的共赢。</p>
<p><img src="/img/remote/1460000019884901" alt="" title=""></p>
<p>上图是会员体系利用蜂蜜中心提供的服务以及一些近期规划示意。如何利用好激励机制使整个会员体系更加完善,实现对会员用户更加精细化的运营,对于马蜂窝「内容+交易」战略的深化而言是一个重要的课题,也是研发团队需要不断探索的方向。</p>
<h3>2.2 营销活动的性能优化</h3>
<p>实现了会员身份、权益中心、第三方权益接入、蜂蜜中心的改造后,会员中心也完成了升级之路的第一步。</p>
<p>为了让更多用户了解会员机制并体验会员权限,我们推出了很多营销活动。其中不少活动都存在秒杀的场景。以下部分就来重点介绍为保障这些营销活动的稳定可靠而进行的技术优化。</p>
<h4>2.2.1 并发控制</h4>
<p>在秒杀场景中,需要防止由高并发导致的库存超卖。关于这个问题业界已经有不少成熟的解决方案,比如采用悲观锁、分布式锁、乐观锁、队列串行、Redis 原子操作等等,当然最理想的是用分布式锁来实现。</p>
<p>考虑到目前的并发量级以及技术成本,我们决定先采用 MySQL 乐观锁的方式来实现现阶段的秒杀功能。大家知道数据库内部 Update 同一行是不允许并发的,只有当该行被更新后才会释放。我们的方案是通过增加唯一的 Version 来防止超卖的情况发生:在每次数据 Update 的时候判断版本号是否和数据库中的一致,不一致则表示当前库存已经被其他用户占用,此时抛出异常;如果一致则完成当前用户对库存的占用。</p>
<h4>2.2.2 流量削峰</h4>
<p>要缓解由瞬间流量爆发造成的数据库压力,我们首先要明确会引起瞬间 QPS 剧增的场景。</p>
<p>一种情况是接口被恶意重刷。由于我们的秒杀业务需要用户必须登录,伪造 Session 的可能性较低,因此如果这种情况发生,很有可能是由同一个 UID 遍历刷接口导致的。这里只需要加上 UID 的 Redis 锁,使一个 UID 在一定时间内只能透过一次请求,这样绝大部分的遍历刷接口行为就能被拦住。</p>
<p>还有一种情况是由流量突发引起,可能是真实的抢购用户数量巨大,也可能是对方使用了大量设备请求,这才是我们目前面对的实际场景。前面我们提到的加 MySQL 乐观锁来避免超卖,如果瞬时流量巨大 MySQL 的读写、锁表等现象会比较严重,当数据库压力达到极限就会被打挂。因此为了减小数据库的瞬时压力,我们需要在服务层做好限流。比如当库存只有 1000 件,但是有 1w 请求打到数据库时,其实后面的请求都没有意义。我们知道不论是 Memcache 还是 Redis,单机下每秒扛住 10w 请求都不会有太大问题。所以在没有完成分布式锁的情况下,我们是用 Redis 来做最基本的限流,使大部分的请求被拦截在服务层,只有少量请求会穿透到数据库。</p>
<p><img src="/img/remote/1460000019884902" alt="" title=""></p>
<p>上图是当前秒杀体系简单的流程图。后续如果这类会员营销活动依旧是业务重点,我们还是会采用 Redis 分布式锁的方式来优化,搭建更为完善的秒杀体系。</p>
<h3>2.3 风险控制</h3>
<p>关于支撑模块的部分主要分享与风险控制相关的内容。为了保证享受到会员服务的是真实用户,我们需要识别并抵御由黑产带来的潜在风险,保障系统的正常运行,严控由此带来的损失。</p>
<p><img src="/img/remote/1460000019884903" alt="" title=""></p>
<p>上图是目前会员体系中安全控制的结构示意。API 路由层主要负责数据收集和风险预估,收集上来的数据统一写入到公司的日志系统 MES 中存储。我们使用了滑窗模式的限流方式,当发现总访问量超过一定阈值则会将大流量或者过快的请求记录到会员疑似黑名单的表中,再进行路由层的限流处理并接入公司级别风控体系,根据对不同业务场景的识别采用相关风控策略;最终通过邮件、短信等方式通知到路由层相应的技术负责人,尽快处理。</p>
<h2>三、总结和展望</h2>
<p>在进行马蜂窝会员体系架构的搭建的实战过程中,我们积累了很多有价值的经验,其中感受最深的就是切忌盲目优化,系统层面上的重构更要首先以业务为导向去关注核心框架的升级和技术体系的演进,不要因为过度陷入技术细节而迷失方向。</p>
<p>今后,我们还将积极调研和应用更多主流、前沿技术,比如会员标签、用户画像体系的引入,真正把这些技术用好用活,使会员中心发挥更大价值。</p>
<p><strong>本文作者:马蜂窝电商会员项目研发团队</strong>。</p>
<h2>彩蛋</h2>
<p>欢迎大家关注马<strong>蜂窝技术公众号后台,并针对本文</strong>积极留言,发表观点或者进行更多相关的技术交流。<strong>截至 7 月 27 日 7:00 pm</strong>,我们将从公众号后台筛选出留言质量最高的 <strong>7 位读者赠送马蜂窝季度金卡</strong>,千万别错过!(扫描下方二维码关注公众号)</p>
<p><img src="/img/remote/1460000019884904" alt="" title=""></p>
马蜂窝 IM 系统架构的演化和升级
https://segmentfault.com/a/1190000019832652
2019-07-22T11:06:23+08:00
2019-07-22T11:06:23+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
34
<p>今天,越来越多的用户被马蜂窝持续积累的笔记、攻略、嗡嗡等优质的分享内容所吸引,在这里激发了去旅行的热情,同时也拉动了马蜂窝交易的增长。在帮助用户做出旅行决策、完成交易的过程中,IM 系统起到了重要的作用。</p>
<p>IM 系统为用户与商家建立了直接沟通的渠道,帮助用户解答购买旅行产品中的问题,既促成了订单交易,也帮用户打消了疑虑,促成用户旅行愿望的实现。伴随着业务的快速发展,几年间,马蜂窝 IM 系统也经历了几次比较重要的架构演化和转型。</p>
<h2>IM 1.0 —— 初期阶段</h2>
<p>初期为了支持业务快速上线,且当时版本流量较低,对并发要求不高,IM 系统的技术架构主要以简单和可用为目的,实现的功能也很基础。</p>
<p>IM 1.0 使用 PHP 开发,实现了 IM 基本的用户/客服接入、消息收发、咨询列表管理功能。用户咨询时,会通过平均分配的策略分配给客服,记录用户和客服的关联关系。用户/客服发送消息时,通过调用消息转发模块,将消息投递到对方的 Redis 阻塞队列里。收消息则通过 HTTP 长连接调用消息轮询模块,有消息时即刻返回,没有消息则阻塞一段时间返回,这里阻塞的目的是降低轮询的间隔。消息收发模型如下图所示:</p>
<p><img src="/img/bVbvnv7?w=950&h=628" alt="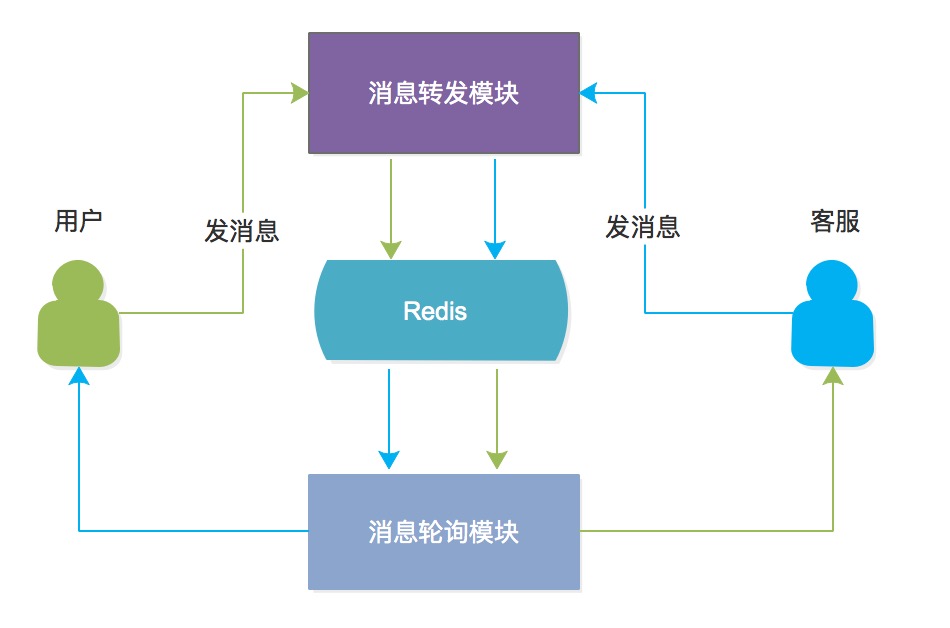" title=""></p>
<h3>消息轮询模块优化</h3>
<p>上图模型中消息轮询模块的长连接请求是通过 php-fpm 挂载在阻塞队列上,当该请求变多时,如果不能及时释放 php-fpm 进程,会对服务器性能消耗较大,负载很高。</p>
<p>为了解决这个问题,我们对消息轮询模块进行了优化,选用基于 OpenResty 框架,利用 Lua 协程的方式来优化 php-fmp 长时间挂载的问题。Lua 协程会通过对 Nginx 转发的请求标记判断是否拦截网络请求,如果拦截,则会将阻塞操作交给 Lua 协程来处理,及时释放 php-fmp,缓解对服务器性能的消耗。优化的处理流程见下图:</p>
<p><img src="/img/bVbvnwA?w=1528&h=1174" alt="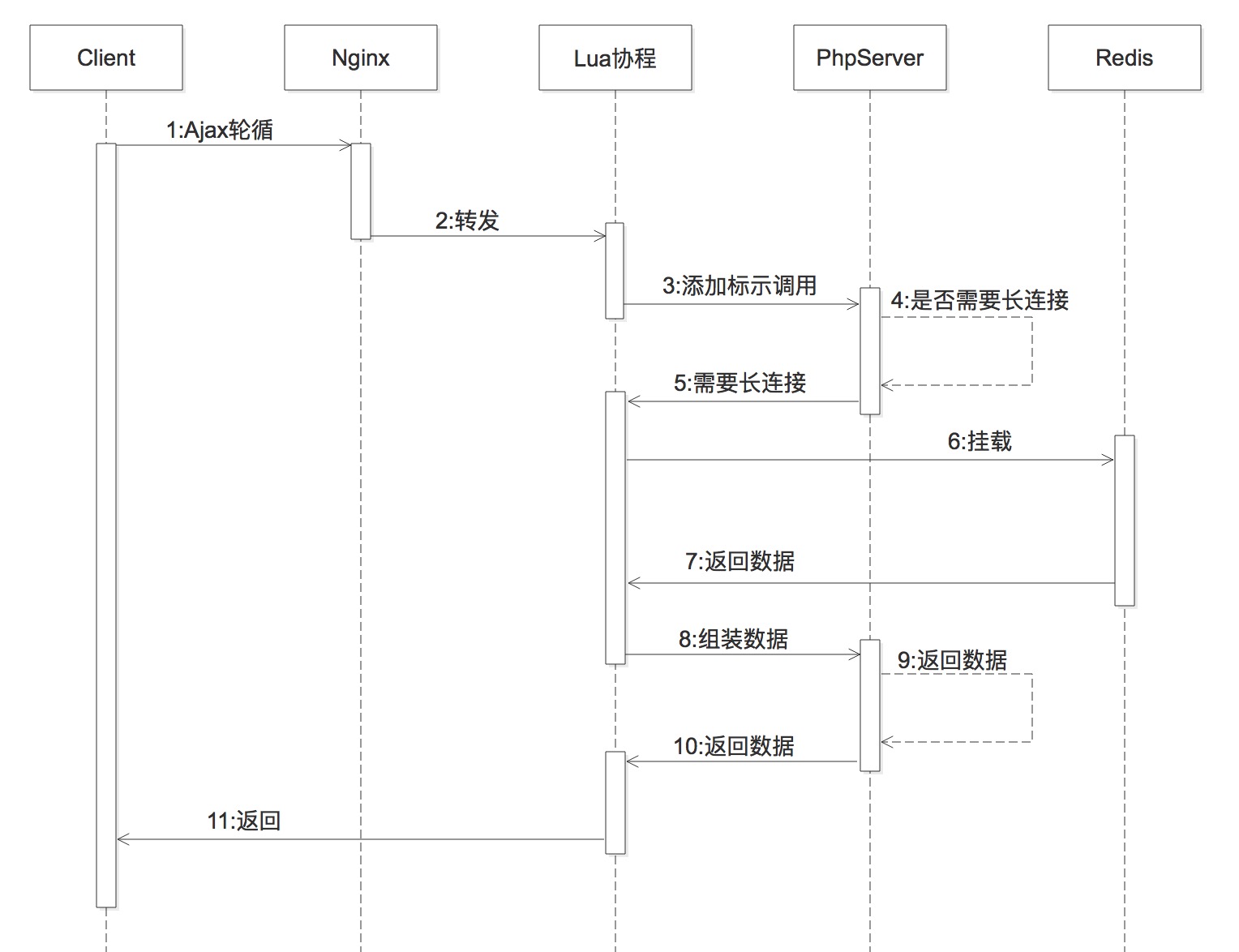" title=""></p>
<h2>IM 2.0 —— 需求定制阶段</h2>
<p>伴随着业务的快速增长,IM 系统在短期内面临着大量定制需求的增加,开发了许多新的业务模块。面对大量的用户咨询,客服的服务能力已经招架不住。因此,IM 2.0 将重心放在提升业务功能体验上,比如在处理用户的咨询时,将从前单一的分配方式演变为采用平均、权重、排队等多种方式;为了提升客服的效率,客服的咨询回复也增加了可选配置,例如自动回复、FAQ 等。</p>
<p>以一个典型的用户咨询场景为例,当用户打开 App 或者网页时,会通过连接层建立长连接,之后在咨询入口发起咨询时,会携带着消息线索初始化消息链路,建立一条可复用、可检索的消息线;发送消息时,通过消息服务将消息存储到 DB 中,同时会根据消息线检索当前咨询是否被分配到客服,调用分配服务的目的是为当前咨询完善客服信息;最后将客服信息更新到链路关系中。</p>
<p>这样,一条完整的消息链路就建立完毕,之后用户/客服发出的消息通过转发服务传输给对方,处理流程如下图所示:</p>
<p><img src="/img/bVbvnwJ?w=1412&h=998" alt="" title=""></p>
<h2>IM 3.0 —— 服务拆分阶段</h2>
<p>业务量在不断积累,随着模块增加,IM 系统的代码膨胀得很快。由于代码规范没有统一、接口职责不够单一、模块间耦合较多等种原因,改动一个需求很可能会影响到其它模块,使新需求的开发和维护成本都很高。</p>
<p>为了解决这种局面,IM 系统必须要进行架构升级,首要任务就是服务的拆分。目前,经过拆分后的 IM 系统整体分为 4 块大的服务,包括客服服务、用户服务、IM 服务、数据服务,如下图所示:</p>
<p><img src="/img/bVbvnwN?w=1238&h=922" alt="" title=""></p>
<ul>
<li>
<strong>客服服务</strong>:围绕提升客服效率和用户体验提供多种方式,如提供群组管理、成员管理、质检服务等来提升客服团队的运营和管理水平;通过分配服务、转接服务来使用户的接待效率更灵活高效;支持自动回复、FAQ、知识库服务等来提升客服咨询的回复效率等。</li>
<li>
<strong>用户服务</strong>:分析用户行为,为用户做兴趣推荐及用户画像,以及统计用户对马蜂窝商家客服的满意度。</li>
<li>I<strong>M 服务</strong>:支持单聊和群聊模式,提供实时消息通知、离线消息推送、历史消息漫游、联系人列表、文件上传与存储、消息内容风控检测等。</li>
<li>
<strong>数据服务</strong>:通过采集用户咨询的来源入口、是否咨询下单、是否有客服接待、用户咨询以及客服回复的时间信息等,定义数据指标,通过数据分析进行离线数据运算,最终对外提供数据统计信息。主要的指标信息有 30 秒、1 分钟回复率、咨询人数、无应答次数、平均应答时间、咨询销售额、咨询转化率、推荐转化率、分时接待压力、值班情况、服务评分等。</li>
</ul>
<h3>用户状态流转</h3>
<p>现有的 IM 系统 中,用户咨询时一个完整的用户状态流转如下图所示:</p>
<p><img src="/img/bVbvnwR?w=1210&h=272" alt="" title=""></p>
<p>用户点击咨询按钮触发事件,此时用户状态进入初始态。发送消息时,系统更改用户状态为待分配,通过调用分配服务分配了对应的客服后,用户状态更改为已分配、未解决。当客服解决了用户或者客服回复后用户长时间未说话,触发系统自动解决的操作,此时用户状态更改为已解决,一个咨询流程结束。</p>
<h3>IM 服务的重构</h3>
<p>在服务拆分的过程中,我们需要考虑特定服务的通用性、可用性和降级策略,同时需要尽可能地降低服务间的依赖,避免由于单一服务不可用导致整体服务瘫痪的风险。在这期间,公司其它业务线对 IM 服务的使用需求也越来越多,使用频次和量级也开始加大。初期阶段的 IM 服务当连接量大时,只能通过修改代码实现水平扩容;新业务接入时,还需要在业务服务器上配置 Openresty 环境及 Lua 协程代码,业务接入非常不便,IM 服务的通用性也很差。</p>
<p>考虑到以上问题,我们对 IM 服务进行了全面重构,目标是将 IM 服务抽取成独立的模块,不依赖其它业务,对外提供统一的集成和调用方式。考虑到 IM 服务对并发处理高和损耗低的要求,选择了 Go 语言来开发此模块,新的 IM 服务设计如下图:</p>
<p><img src="/img/bVbvnwS?w=1340&h=744" alt="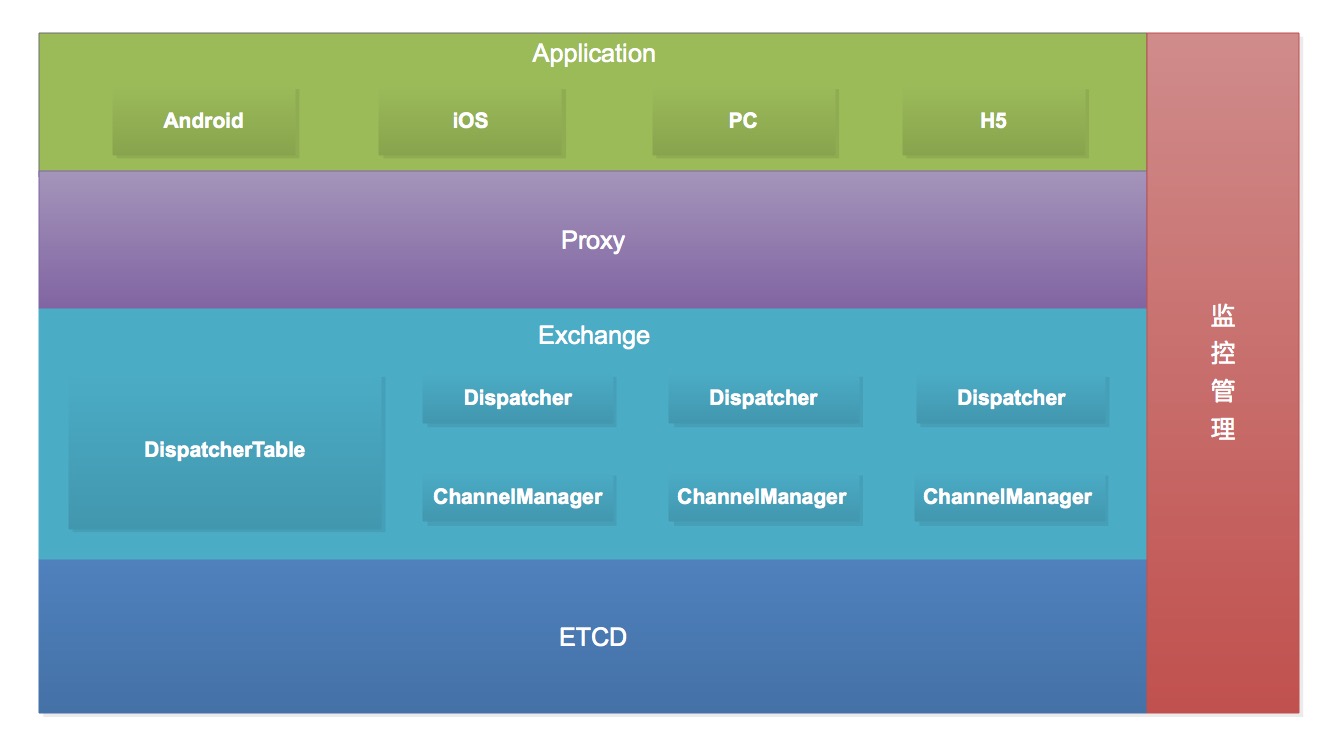" title=""></p>
<p>其中,比较重要的 Proxy 层和 Exchange 层提供了以下服务:</p>
<p>1. <strong>路由规则</strong>,例如 ip-hash、轮询、最小连接数等,通过规则将客户端散列到不同的 ChannelManager 实例上。</p>
<p>2. <strong>对客户端接入的管理</strong>,接入后的连接信息会同步到 DispatchTable 模块,方便 Dispatcher 进行检索。</p>
<p>3.<strong>ChannelManager 与客户端间的通信协议</strong>,包括客户端请求建立连接、断线重连、主动断开、心跳、通知、收发消息、消息的 QoS 等。</p>
<p>4. <strong>对外提供单发、群发消息的 REST 接口</strong>。这里需要根据场景来决定是否使用,例如用户咨询客服的场景就需要通过这个接口下发消息,主要原因在以下 3 点:</p>
<ul>
<li>发消息时会有创建消息线、分配管家等逻辑,这些逻辑目前是 PHP 实现,IM 服务需要知道 PHP 的执行结果,一种方式是使用 Go 重新实现,另外一种方式是通过 REST 接口调用 PHP 返回,这样会带来 IM 服务和 PHP 业务过多的网络交互,影响性能。</li>
<li>转发消息时,ChannelManager 多个实例间需要互相通信,例如 ChannelManager1 上的用户 A 给 ChannelManager2 上的客服 B 发消息,如果实例间无通信机制,消息无法转发。当要再扩展 ChannelManager 实例时,新增实例需要和其它已存在实例分别建立通信,增加了系统扩展的复杂度。</li>
<li>如果客户端不支持 WebSocket 协议,作为降级方案的 HTTP 长连接轮循只能用来收消息,发消息需要通过短连接来处理。其它场景不需要消息转发,只用来给 ChannelManager 传输消息的场景,可通过 WebSocket 直接发送。</li>
</ul>
<h3>改造后的 IM 服务调用流程</h3>
<p>初始化消息线及分配客服过程由 PHP 业务完成。需要消息转发时,PHP 业务调用 Dispatcher 服务的发消息接口,Dispatcher 服务通过共享的 Dispatcher Table 数据,检索出接收者所在的 ChannelManager 实例,将消息通过 RPC 的方式发送到实例上,ChannelManager 通过 WebSocket 将消息推送给客户端。IM 服务调用流程如下图所示:</p>
<p><img src="/img/bVbvnwZ?w=1250&h=728" alt="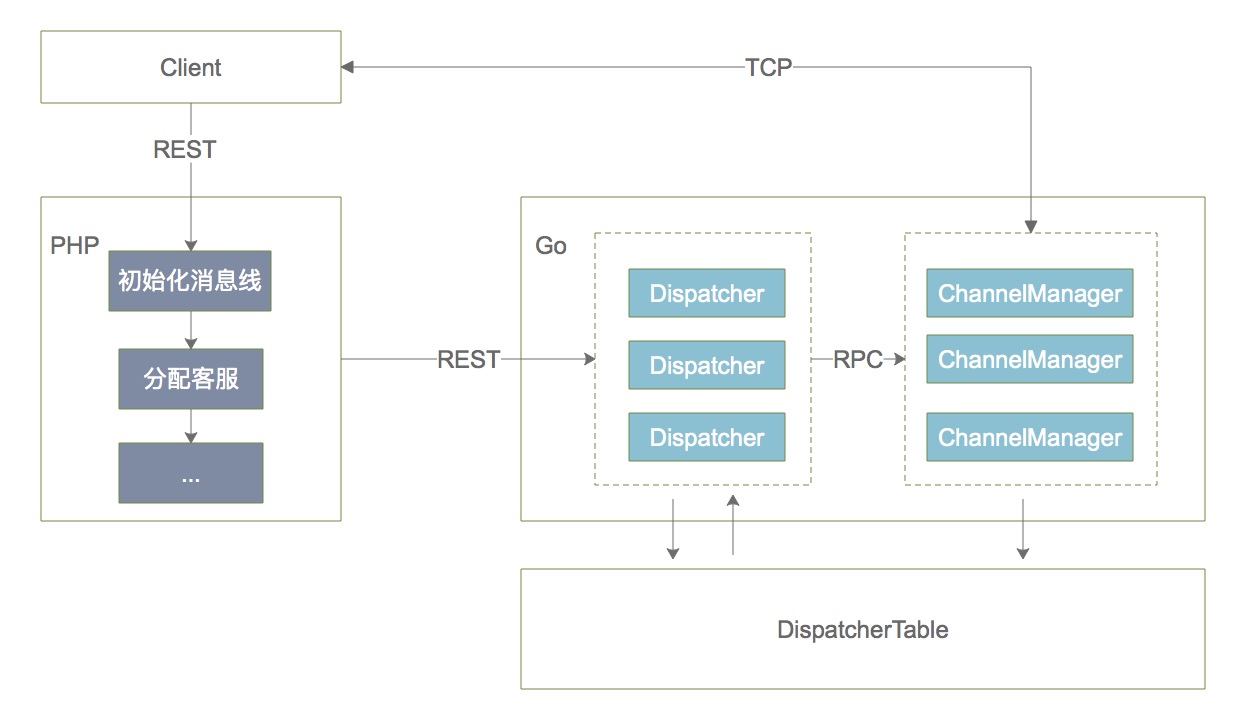" title=""></p>
<p>当连接数超过当前 ChannelManager 集群承载的上限时,只需扩展 ChannelManager 实例,由 ETCD 动态的通知到监听侧,从而做到平滑扩容。目前浏览器版本的 JS-SDK 已经开发完毕,其它业务线通过接入文档,就能方便地集成 IM 服务。</p>
<p>在 Exchange 层的设计中,有 3 个问题需要考虑:</p>
<p><strong>1. 多端消息同步</strong></p>
<p>现在客户端有 PC 浏览器、Windows 客户端、H5、iOS/Android,如果一个用户登录了多端,当有消息过来时,需要查找出这个用户的所有连接,当用户的某个端断线后,需要定位到这一个连接。</p>
<p>上面提到过,连接信息都是存储在 DispatcherTable 模块中,因此 DispatcherTable 模块要能根据用户信息快速检索出连接信息。DispatcherTable 模块的设计用到了 Redis 的 Hash 存储,当客户端与 ChannelManager 建立连接后,需要同步的元数据有 uid(用户信息)、uniquefield(唯一值,一个连接对应的唯一值)、wsid(连接标示符)、clientip(客户端 ip)、serverip(服务端 ip)、channel(渠道),对应的结构大致如下:</p>
<p><img src="/img/bVbvnw7?w=1234&h=400" alt="" title=""></p>
<p>这样通过 key(uid) 能找到一个用户多个端的连接,通过 key+field 能定位到一条连接。连接信息的默认过期时间为 2 小时,目的是避免因客户端连接异常中断导致服务端没有捕获到,从而在 DispatcherTable 中存储了一些过期数据。</p>
<p><strong>2. 用户在线状态同步</strong></p>
<p>比如一个用户先后和 4 个客服咨询过,那么这个用户会出现在 4 个客服的咨询列表里。当用户上线时,要保证 4 个客服看到用户都是在线状态。</p>
<p>要做到这一点有两种方案,一种是客服通过轮询获取用户的状态,但这样当用户在线状态没有变化时,会发起很多无效的请求;另外一种是用户上线时,给客服推送上线通知,这样会造成消息扩散,每一个咨询过的客服都需要扩散通知。我们最终采取的是第二种方式,在推送的过程中,只给在线的客服推送用户状态。</p>
<p><img src="/img/bVbvnxg?w=1270&h=712" alt="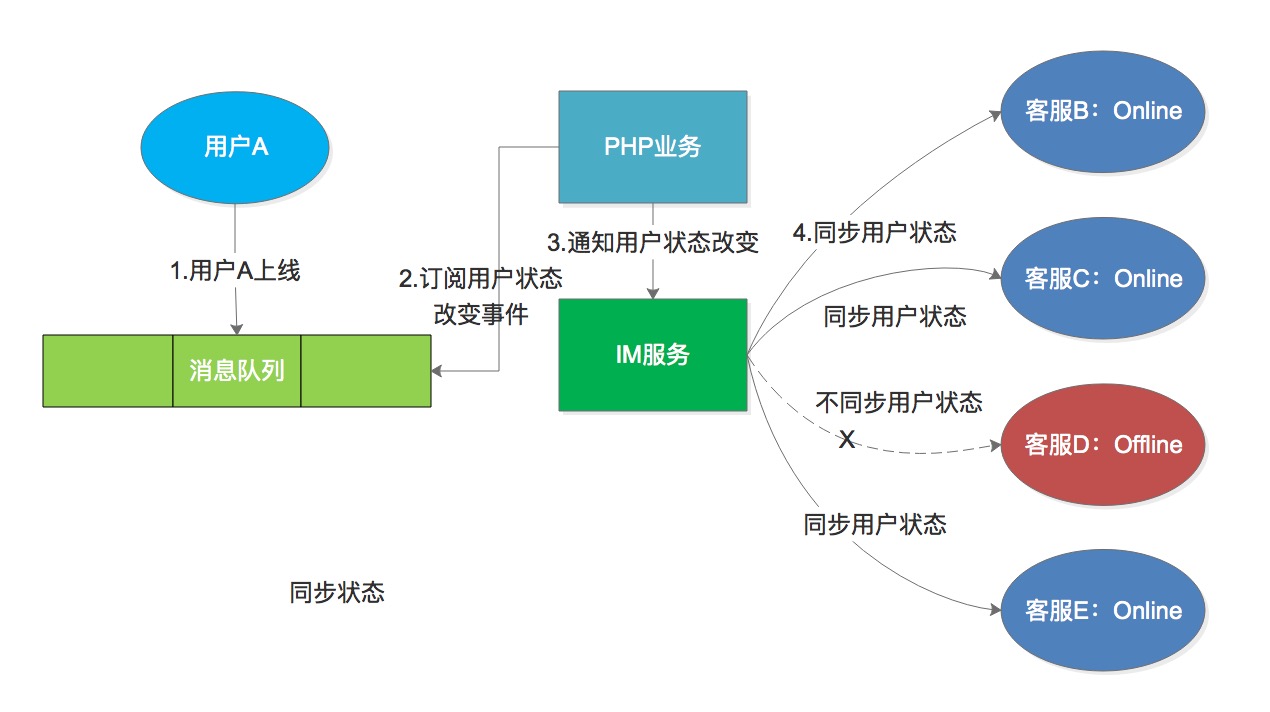" title=""></p>
<p><strong>3. 消息的不丢失,不重复</strong></p>
<p>为了避免消息丢失,对于采用长连接轮询方式的我们会在发起请求时,带上客户端已读消息的 ID,由服务端计算出差值消息然后返回;使用 WebSocket 方式的,服务端会在推送给客户端消息后,等待客户端的 ACK,如果客户端没有 ACK,服务端会尝试多次推送。</p>
<p>这时就需要客户端根据消息 ID 做消息重复的处理,避免客户端可能已收到消息,但是由于其它原因导致 ACK 确认失败,触发重试,导致消息重复。</p>
<h3>IM 服务的消息流</h3>
<p>上文提到过 IM 服务需要支持多终端,同时在角色上又分为用户端和商家端,为了能让通知、消息在输出时根据域名、终端、角色动态输出差异化的内容,引入了 DDD (领域驱动设计)的建模方法来对消息进行处理,处理过程如下图所示:</p>
<p><img src="/img/bVbvnxh?w=1682&h=1256" alt="" title=""></p>
<h2>总结和展望</h2>
<p>伴随着马蜂窝「内容+交易」模式的不断深化,IM 系统架构也经历着演化和升级的不同阶段,从初期粗旷无序的模式走向统一管理,逐渐规范、形成规模。 </p>
<p>我们取得了一些进步,当然,还有更长的路要走。未来,结合公司业务的发展脚步和团队的技术能力,我们将不断进行 IM 系统的优化。目前我们正在计划将消息轮询模块中的服务端代码用 Go 替换,使其不再依赖 PHP 及 OpenResty 环境,实现更好地解耦;另外,我们将基于 TensorFlow 实现向智慧客服的探索,通过训练数据模型、分析数据,进一步提升人工客服的解决效率,提升用户体验,更好地为业务赋能。</p>
<p><strong>本文作者:马蜂窝电商平台 IM 研发团队。</strong></p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p><img src="/img/bVbvnxq?w=1875&h=835" alt="" title=""></p>
基于 MySQL Binlog 的 Elasticsearch 数据同步实践
https://segmentfault.com/a/1190000019762367
2019-07-15T11:12:53+08:00
2019-07-15T11:12:53+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
15
<h2>一、背景</h2>
<p>随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品、订单等数据的多维度检索。</p>
<p>使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。而数据进行异构存储后,随之而来的就是数据同步的问题。</p>
<h2>二、现有方法及问题</h2>
<p>对于数据同步,我们目前的解决方案是建立数据中间表。把需要检索的业务数据,统一放到一张MySQL 表中,这张中间表对应了业务需要的 Elasticsearch 索引,每一列对应索引中的一个Mapping 字段。通过脚本以 Crontab 的方式,读取 MySQL 中间表中 UTime 大于上一次读取时间的所有数据,即该段时间内的增量,写入Elasticsearch。</p>
<p>所以,一旦业务逻辑中有相应字段的数据变更,需要同时顾及 MySQL 中间表的变更;如果需要 Elasticsearch 中的数据即时性较高,还需要同时写入 Elasticsearch。</p>
<p>随着业务数据越来越多,MySQL 中间表的数据量越来越大。当需要在 Elasticsearch 的索引中新增 Mapping 字段时,相应的 MySQL 中间表也需要新增列,在数据量庞大的表中,扩展列的耗时是难以忍受的。</p>
<p>而且 Elasticsearch 索引中的 Mapping 字段随着业务发展增多,需要由业务方增加相应的写入 MySQL 中间表方法,这也带来一部分开发成本。</p>
<h2>三、方案设计</h2>
<h3>1. 整体思路</h3>
<p>现有的一些开源数据同步工具,如阿里的 DataX 等,主要是基于查询来获取数据源,这会存在如何确定增量(比如使用utime字段解决等)和轮询频率的问题,而我们一些业务场景对于数据同步的实时性要求比较高。为了解决上述问题,我们提出了一种基于 MySQL Binlog 来进行 MySQL 数据同步到 Elasticsearch 的思路。Binlog 是 MySQL 通过 Replication 协议用来做主从数据同步的数据,所以它有我们需要写入 Elasticsearch 的数据,并符合对数据同步时效性的要求。</p>
<p>使用 Binlog 数据同步 Elasticsearch,业务方就可以专注于业务逻辑对 MySQL 的操作,不用再关心数据向 Elasticsearch 同步的问题,减少了不必要的同步代码,避免了扩展中间表列的长耗时问题。</p>
<p>经过调研后,我们采用开源项目 go-mysql-elasticsearch 实现数据同步,并针对马蜂窝技术栈和实际的业务环境进行了一些定制化开发。</p>
<h3>2. 数据同步正确性保证</h3>
<p>公司的所有表的 Binlog 数据属于机密数据,不能直接获取,为了满足各业务线的使用需求,采用接入 Kafka 的形式提供给使用方,并且需要使用方申请相应的 Binlog 数据使用权限。获取使用权限后,使用方以 Consumer Group 的形式读取。</p>
<p>这种方式保证了 Binglog 数据的安全性,但是对保证数据同步的正确性带来了挑战。因此我们设计了一些机制,来保证数据源的获取有序、完整。</p>
<h4><strong>1). 顺序性</strong></h4>
<p>通过 Kafka 获取 Binlog 数据,首先需要保证获取数据的顺序性。严格说,Kafka 是无法保证全局消息有序的,只能局部有序,所以无法保证所有 Binlog 数据都可以有序到达 Consumer。</p>
<p>但是每个 Partition 上的数据是有序的。为了可以按顺序拿到每一行 MySQL 记录的 Binglog,我们把每条 Binlog 按照其 Primary Key,Hash 到各个 Partition 上,保证同一条 MySQL 记录的所有 Binlog 数据都发送到同一个 Partition。</p>
<p>如果是多 Consumer 的情况,一个 Partition 只会分配给一个 Consumer,同样可以保证 Partition 内的数据可以有序的 Update 到 Elasticsearch 中。</p>
<h3><img src="/img/remote/1460000019762370?w=920&h=657" alt="" title=""></h3>
<h4><strong>2). 完整性</strong></h4>
<p>考虑到同步程序可能面临各种正常或异常的退出,以及 Consumer 数量变化时的 Rebalance,我们需要保证在任何情况下不能丢失 Binlog 数据。</p>
<p>利用 Kafka 的 Offset 机制,在确认一条 Message 数据成功写入 Elasticsearch 后,才 Commit 该条 Message 的 Offset,这样就保证了数据的完整性。而对于数据同步的使用场景,在保证了数据顺序性和完整性的情况下,重复消费是不会有影响的。</p>
<p><img src="/img/remote/1460000019762371" alt="" title=""></p>
<h2>四、技术实现</h2>
<p><img src="/img/remote/1460000019762372" alt="" title=""></p>
<h3>1. 功能模块</h3>
<h4>配置解析模块</h4>
<p>负责解析配置文件(toml 或 json 格式),或在配置中心(Skipper)配置的 json 字符串。包括 Kafka 集群配置、Elasticsearch 地址配置、日志记录方式配置、MySQL 库表及字段与 Elasticsearch 的 Index 和 Mapping 对应关系配置等。</p>
<h4>规则模块</h4>
<p>规则模块决定了一条 Binlog 数据应该写入到哪个 Elasticsearch 索引、文档_id 对应的 MySQL 字段、Binlog 中的各个 MySQL 字段与索引 Mapping 的对应关系和写入类型等。</p>
<p>在本地化过程中,根据我们的业务场景,增加了对 MySQL 表各字段的 where 条件判断,来过滤掉不需要的 Binlog 数据。</p>
<h4>Kafka 相关模块</h4>
<p>该模块负责连接 Kafka 集群,获取 Binlog 数据。</p>
<p>在本地化过程中,该模块的大部分功能已经封装成了一个通用的 Golang Kafka Consumer Client。包括 Dba Binlog 订阅平台要求的 SASL 认证,以及从指定时间点的 Offset 开始消费数据。</p>
<h4>Binlog 数据解析模块</h4>
<p>原项目中的 Binlog 数据解析针对的是原始的 Binlog 数据,包含了解析 Replication 协议的实现。在我们的使用场景中,Binlog 数据已经是由 canal 解析成的 json 字符串,所以对该模块的功能进行了简化。</p>
<p>binlog json字符串示例 </p>
<p><img src="/img/remote/1460000019762373" alt="" title=""></p>
<p>上面是一个简化的 binlog json 字符串,通过该条 binlog 的 database 和 table 可以命中一条配置规则,根据该配置规则,把 Data 中的 key-value 构造成一个与对应 Elasticsearch 索引相匹配的 key-value map,同时包括一些数据类型的转换:</p>
<p><img src="/img/remote/1460000019762374" alt="" title=""></p>
<h4>Elasticsearch相关模块</h4>
<p>Binlog 数据解析模块生成的 key-value map,由该模块拼装成请求_bulk 接口的 update payload,写入 Elasticsearch。考虑到 MySQL 频繁更新时对 Elasticsearch 的写入压力,key-value map 会暂存到一个 slice 中,每 200ms 或 slice 长度达到一定长度时(可以通过配置调整),才会调用 Elasticsearch 的_bulk 接口,写入数据。</p>
<h3>2. 定制化开发</h3>
<h4><strong>1). 适应业务需求</strong></h4>
<h4>upsert</h4>
<p>业务中使用的索引数据可能是来自多个不同的表,同一个文档的数据来自不同表的时候,先到的数据是一条 index,后到的数据是一条 update,在我们无法控制先后顺序时,需要实现 upsert 功能。在_bulk 参数中加入</p>
<pre><code>{
"doc_as_upsert" : true
}</code></pre>
<h4>Filter</h4>
<p>实际业务场景中,可能业务需要的数据只是某张表中的部分数据,比如用 type 字段标识该条数据来源,只需要把 type=1或2的数据同步到 Elasticsearch 中。我们扩展了规则配置,可以支持对 Binlog 指定字段的过滤需求,类似:</p>
<pre><code> select * from sometable where type in (1,2)
</code></pre>
<h4>2)快速增量</h4>
<p>数据同步一般分为全量和增量。接入一个业务时,首先需要把业务现有的历史 MySQL 数据导入到 Elasticsearch 中,这部分为全量同步。在全量同步过程中以及后续增加的数据为增量数据。</p>
<p>在全量数据同步完成后,如果从最旧开始消费 Kafka,队列数据量很大的情况下,需要很长时间增量数据才能追上当前进度。为了更快的拿到所需的增量 Binlog,在 Consumer Group 消费 Kafka 之前,先获取各个 Topic 的 Partition 在指定时间的 offset 值,并 commit 这些 offset,这样在 Consumer Group 连接 Kafka 集群时,会从刚才提交的 offset 开始消费,可以立即拿到所需的增量 Binlog。</p>
<h4><strong>3). 微服务和配置中心</strong></h4>
<p>项目使用马蜂窝微服务部署,为新接入业务提供了快速上线支持,并且在业务 Binlog 数据突增时可以方便快速的扩容 Consumer。</p>
<p>马蜂窝配置中心支持了各个接入业务的配置管理,相比于开源项目中的 toml 格式配置文件,使用配置中心可以更方便的管理不同业务不同环境的配置。</p>
<h2>五、日志与监控</h2>
<h2><img src="/img/remote/1460000019762375" alt="" title=""></h2>
<p>从上图中可以看出,订单各个表的数据同步延时平均在 1s 左右。把延时数据接入 ElastAlert,在延时数据过多时发送报警通知。</p>
<p>另一个监控指标是心跳检测,单独建立一张独立于业务的表,crontab 脚本每分钟修改一次该表,同时检查上一次修改是否同步到了指定的索引,如果没有,则发送报警通知。该心跳检测,监控了整个流程上的 Kafka、微服务和 ES,任何一个会导致数据不同步的环节出问题,都会第一个接到通知。</p>
<h2>六、结语</h2>
<p>目前接入的最重要业务方是电商的订单索引,数据同步延时稳定在 1s 左右。这次的开源项目本地化实践,希望能为一些有 Elasticsearch 数据同步需求的业务场景提供帮助。</p>
<p><strong>本文作者</strong>:张坤,马蜂窝电商研发团队度假业务高级研发工程师。</p>
<p>(马蜂窝技术原创内容,转载请保留出处及文末二维码,谢谢)</p>
<p><img src="/img/remote/1460000019762376" alt="" title=""></p>
领域驱动设计在马蜂窝优惠中心重构中的实践
https://segmentfault.com/a/1190000019743441
2019-07-12T15:29:48+08:00
2019-07-12T15:29:48+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
28
<h2>前言</h2>
<p>正如领域驱动设计之父 Eric Evans 所著一书的书名所述,领域驱动设计(Domain Driven Design)是一种软件核心复杂性应对之道。</p>
<p>在我们解决现实业务问题时,会面对非常复杂的业务逻辑。即使是同一个事物,在多个子业务单元下代表的意思也是不完全一样的。比如「商品」这个词,在商品详情页语境中,是指「商品基本信息」;在下单页语境中,是指「购买项」;而在物流页面语境中,又变成了「被运送的货物」。</p>
<p>DDD 的核心思想就是让正确的领域模型发挥作用。所谓「术业有专攻」,DDD 指导软件开发人员将不同的子业务单元划分为不同的子领域,在各个子领域内部分别对事物进行建模,来应对业务的复杂性。</p>
<h2>一、重构优惠中心的背景</h2>
<p>我们在实际的开发过程中都遇到过这种情况,最初因为业务逻辑比较单一,为了快速实现功能, 以及对成本、风险等因素的综合考虑,我们会为业务统一创建一个大的模型,各个模块都使用这同一个模型。但随着业务的发展,各子领域的逻辑越来越复杂,对这个大模型的修改就会变成一种灾难,有时明明是要改一个 A 子领域的逻辑,却莫名其妙影响到了 B 或者 C 子领域的线上功能。</p>
<p>优惠中心就是一个例子。优惠中心主要负责马蜂窝各业务线商品的优惠活动管理,以及计算不同用户的优惠结果。「商品管理」和「优惠管理」作为两个不同的业务单元,在初期被设计为共用一个商品模型,由商品模块统一管理。</p>
<p><img src="/img/bVbu0k7?w=404&h=593" alt="图片描述" title="图片描述"></p>
<h2>出现的问题</h2>
<p>随着业务的发展,优惠的形式不断推陈出新,业务形态逐渐多样,业务方的需求也越来越个性化,导致后期的优惠中心无论从功能上还是系统上都出现了一些具体的问题:</p>
<p><strong>1. 功能上来说,不够灵活</strong></p>
<p>优惠信息是作为商品信息的一个属性在商品管理模块配置的。比如为了引导用户使用 App 需要设置 A 类型优惠,就通过在商品信息的编辑页面增加一个 A 类型优惠配置项实现;如果某个商品的 A 类型优惠需要在 0:00 分生效,业务同学就必须在电脑前等到 0:00 更新商品信息来上线优惠活动。</p>
<p>另外,如果想要创建针对所有商品都适用的优惠,按照之前的模式,所有的商品都要设置一遍,这几乎是不可接受的。</p>
<p><strong>2. 从系统层面看,不易扩展</strong></p>
<p>优惠信息存储在商品信息中,优惠信息是通过商品管理模块的接口输出的。如果要新增一种优惠类型,商品信息相关的表就要增加字段,商品的表会越来越大;如果要迭代一个优惠的逻辑,就有可能影响到商品管理模块的功能。</p>
<p><strong>3. 不利于迭代</strong></p>
<p>由于优惠信息仅仅作为商品的一个属性,没有自己的生命周期,所以很难去统计某一次设置的优惠的投入产出比,从而指导后续的功能优化。</p>
<h2>重构优惠中心的预期</h2>
<ul>
<li>
<strong>系统层面上</strong>,要把优惠相关的业务逻辑独立出来,单独设计和实现;</li>
<li>
<strong>应用层面上</strong>,优惠中心会有自己的独立后台,负责管理优惠活动;也会有独立的优惠计算接口,负责 C 端用户使用优惠时的计算。</li>
</ul>
<h2>二、为什么选择 DDD</h2>
<h3>避免贫血模型</h3>
<p>基于传统的 MVC 架构开发功能的时候,Model 层本质上是一个 DAO 层,业务逻辑通常会封装在 Service 层,然后 Controller 通过调用 Service 层来完成对外的功能。这种模式下,数据和行为分别被割裂到了 Model 和 Service 两层。我们把这种只承载数据,但没有业务行为的 Model 称为「贫血模型」。</p>
<p>我们在和业务方了解需求的过程中,使用到的对象都是现实业务的映射,是行为和属性的综合体。需求确定好之后,我们开发的过程中,人为把行为和数据拆分成了两部分,做了一次转换。随着需求的迭代,人员的更迭,开发看到的代码和业务方的需求越来越对应不上,导致很多代码谁也不知道对应的是什么业务逻辑,这种现象被称为由贫血模型带来的「失忆症」,最终导致的是一个维护成本极高的大泥潭系统。</p>
<p>领域驱动设计的核心就是基于业务逻辑去建模,避免贫血模型,减少设计和开发过程中对业务信息的丢失和转换。在业务逻辑迭代的过程中,系统通过调整对应的业务模型就可以完成迭代。</p>
<h2>三、落地过程</h2>
<h3>关键点:业务逻辑抽象</h3>
<p>要做到基于业务逻辑建模,就要合理地抽象。因为业务表象千差万别,产品经理和软件设计人员需要和业务专家深入交流,并且从离散的信息中抽象出业务内在的逻辑。</p>
<p>比如旅游业务售卖的商品和标品不同,有些优惠是不考虑人群的,比如使用优惠券,所有类型的库存都可以享受;但如 N 人 N 折这类优惠,成人价可以享受,儿童价和单房差就不可以。基于这个特点,我们对优惠中心的商品模型做了抽象,抽象出来「是否可以参与件数计算」和 「是否可以参与价格计算」两个通用属性。这样既实现了基于业务逻辑建模,又不会陷入业务逻辑千差万别的表象中。</p>
<h3>3.1 战术设计</h3>
<h4>第一步:统一语言,提炼关键词</h4>
<p>准确的语言对于产品、运营、开发等各方对齐需求非常重要,我们需要将优惠逻辑当中的概念抽象为各方都能理解的词语,以达成共识。作为开发人员来说,对领域的理解一般来说是比较少的,为了抽象出合理的语言让产品和业务方都能理解,就需要充分理解业务背景和需求。<strong>在熟悉业务和需求的过程中,提炼出若干关键字,这些关键词就是最初产生的领域概念和通用语言。</strong>比如:</p>
<ul>
<li>
<strong>优惠类型</strong>:表示一种优惠规则和对应的优惠方案。比如早鸟优惠,就是早多少钱买(优惠规则),减多少钱/打几折(优惠方案);</li>
<li>
<strong>优惠活动</strong>:拥有完整的生命周期,需要包含时间、平台、人员、商品等(限制维度)的某种优惠类型的使用过程信息;</li>
<li>
<strong>优惠发现</strong>:根据指定的商品、人员和平台,找出可以使用的优惠活动列表服务;</li>
<li>
<strong>优惠计算</strong>:根据指定的商品、人员、平台以及购买数量,计算出这一次购买行为可以享受的优惠金额及优惠明细;</li>
<li>
<strong>优惠排序</strong>:各种优惠类型在计算的时候是有先后顺序的,如果有打折的优惠存在,那顺序不同,计算的结果也会不同;</li>
<li>
<strong>优惠互斥</strong>:某些优惠之间存在互斥的关系,比如使用了金卡 96 折优惠,就不能使用马蜂窝优惠券。</li>
</ul>
<h4>第二步:抽象领域模型</h4>
<p>根据单一职责的原则,一个领域概念对应一个领域对象。领域对象有<strong>实体</strong>和<strong>值对象</strong>之分:</p>
<ul>
<li>
<strong>实体</strong>:实体是有状态的和唯一标识的,包含属性和行为;</li>
<li>
<strong>值对象</strong>:值对象是无状态的,是只读的,包含属性和行为。</li>
</ul>
<p>区分实体和值对象对系统设计有很大意义,实体是我们需要重点关注和设计的,而值对象则只使用它的「值」就可以了。这样可以简化系统的复杂度,将精力聚焦在核心领域对象。不难理解,优惠活动毋庸置疑是一个实体,优惠类型就是一个值对象。</p>
<p>但也存在某些业务行为是不能归于某个实体或值对象的,可以将它们归为领域服务:</p>
<ul><li>
<strong>领域服务</strong>:领域服务本质上就是一些操作,不包含状态,通常用于协调多个实体。实体和值都属于领域对象,领域对象之间的交互逻辑不能放在领域对象内部,必须由服务来实现,从而有效地保护领域模型。</li></ul>
<p>有一些领域逻辑,比如「优惠排序」和「优惠互斥」,他们涉及到多个优惠类型,也就是多个领域对象。如果也被设计为领域对象,就打破了单一职责的原则,所以我们把这部分跨多个领域对象的业务逻辑放到「领域服务」层。</p>
<h4>第三步:抽象领域对象之间的关联关系</h4>
<p>将相关联的领域对象进行显式分组,来表达整体的概念(也可以是单一的领域对象),也就是<strong>「聚合」</strong>。</p>
<p>比如优惠活动是优惠类型、优惠范围等的聚合;优惠类型是优惠规则和优惠方案的聚合;优惠规则是限制维度的聚合;优惠方案是优惠手段的聚合:</p>
<p><img src="/img/bVbu0k6?w=616&h=441" alt="图片描述" title="图片描述"></p>
<p><strong>聚合的主要功能是把领域对象分组,外部的唯一访问点就是聚合根</strong>,这样可以避免处理领域对象间的一一对应关系,只需要处理聚合和聚合之间的关系就行了。</p>
<h4>第四步:走查场景,调整领域模型</h4>
<p>领域模型的调整是贯穿整个设计和开发过程的,<strong>随着业务的调整,领域模型也需要调整</strong>。比如优惠中心后期引入了会员卡的优惠类型,那么就需要把优惠券这个优惠类型的显示,调整为与会员卡互斥的优惠券和与会员卡不互斥的两种。</p>
<h4>第五步:简化设计,降低系统复杂度</h4>
<p>建模的本质是对现实事物的一种简化和抽象,指导我们忽略和问题域无关的事实,提取和问题域息息相关的信息。以优惠中心为例,最初的方案里我们设计了优惠类型管理的功能,根据不同的优惠规则和优惠方案自动组合成不同类型的优惠类型。但是可以预见,未来的优惠类型是有限的,并且每个优惠类型都有会自己的特殊配置,比如 N 人优惠里的 每 N 人/第 N 人;早鸟中的提前 N 天等。也就是说,根据优惠规则和优惠方案自动生成优惠类型基本是没有使用场景的,因此也就去掉了这个设计。</p>
<p>再如,对优惠的限制我们最初是设计在优惠活动维度,经过权衡,为了降低系统复杂度,最后实现在了优惠类型层面。以「蜂抢」优惠类型为例,它的规则是所有的蜂抢活动都是 1 个用户只能抢一次,没有必要把这个限制放在优惠活动维度,在优惠类型层面控制就可以了。</p>
<h3>3.2 战略设计</h3>
<p><strong>战略设计处理的是不同限界上下文之间的拆分和集成逻辑</strong>。限界上下文比较抽象,结合我们在文章开始提到的不同语境中的「商品」例子来理解,同一个词如果不说明白所处的语境,是无法准确描述清楚其表达的含义的。「语境」其实就是「上下文」,对应不同「子领语」。同理,如果不在一个限定好的上下文中去设计领域模型,设计出的领域模型是不清晰的,它就会同时支持多个上下文。</p>
<p>这里需要说明一点,如果是从零搭建一个全新的电商系统,首先需要做的应该是战略设计。而优惠中心是建立在现有大的电商系统基础上,相当于作为其中一个子领域进行重构,所以我们才会先来做战术设计,再考虑在完整的电商系统下它与外部其他环境之间的关系,也就是战略设计。</p>
<h4>优惠中心内部场景区分</h4>
<p>优惠中心包括了服务于 B 端用户的优惠活动管理和服务于 C 端用户的优惠计算这两个不同的子业务单元:</p>
<p><img src="/img/bVbu0k5?w=510&h=357" alt="图片描述" title="图片描述"></p>
<ul>
<li>
<strong>优惠活动</strong>处理的是优惠活动的增删改查,以及配套的统计等业务;优惠活动在这里是一个实体,有完整的生命周期,有上线、下线等状态,可以被创建和删除;</li>
<li>
<strong>优惠计算</strong>处理的是一个订单能享受哪些优惠,并减多少钱的问题;在这个场景里,优惠活动是一个值对象,只提供优惠计算需要的必要参数即可。</li>
</ul>
<h4>优惠中心与外部系统集成</h4>
<p>在整个电商系统的环境下,优惠中心作为一个子域,处于自己的限界上下文当中。<strong>使用优惠中心服务的详情页、下单页都处于自己各自的限界上下文</strong>,所以调用优惠中心的时候就需要设计它们之间的上下文映射方式。</p>
<p>调用和被调用方使用的战略设计方法通常有以下几种:</p>
<ul>
<li>
<strong>客户方-供应方</strong>:适用于同一个团队之间的协作,上游会有严格的自动化测试,来保证给到下游的数据是一定符合约定的;</li>
<li>
<strong>遵奉者</strong>:适用于不同团队协作,且上游不关心下游的标准,下游又完全「逆来顺受」地接受了上游给的数据的场景;</li>
<li>
<strong>防腐层</strong>:适用于上游不关心下游的标准,但是下游不甘心「逆来顺受」,就增加一层,来做转换处理,保持下游系统的独立性;</li>
<li>
<strong>开放主机服务</strong>:适用于中台(通用能力平台),对接方非常多,业务重复度高,并且已经有完善的测试机制和通用的模型。</li>
</ul>
<p>结合我们的实际情况来看,调用优惠中心的可能会是不同团队的开发人员,而优惠中心又不想被不同的上游侵入内部设计中,所以「客户方-供应方」和「遵奉者」模型都不适合;另外优惠中心前期接入方会比较少,而且会不断迭代,使用「开放主机服务」也不太合适。综合考虑下,<strong>防腐层</strong>的设计比较适合优惠中心。</p>
<p>下图是优惠中心的业务架构示意,中间的应用服务层采用的就是防腐层的设计,反映优惠中心与外部系统集成时的上下文映射关系:</p>
<p><img src="/img/bVbu0k4?w=1092&h=807" alt="图片描述" title="图片描述"></p>
<h4>3.3 架构实现</h4>
<p>优惠中心选择的是经典的<strong>分层架构</strong>。从上到下为用户接口层、应用服务层、领域层和仓储层。图中不同的颜色块分别对映外部服务、应用服务、领域服务、聚合根、实体、值对象和仓储。</p>
<ul>
<li>
<strong>用户接口层</strong>:处理和终端用户的交互逻辑;</li>
<li>
<strong>应用服务层</strong>:负责封装和转换领域层的返回数据给用户接口层;</li>
<li>
<strong>领域层</strong>:优惠中心的核心逻辑都在这一层,包括领域对象和领域服务。</li>
<li>
<strong>仓储层</strong>:仓储层负责把内存中的领域对象落地到存储介质,也负责从存储介质拿到原始数据后构造领域对象给领域层使用;这一层对领域层隐藏了底层的存储细节。虽然仓储层处在领域层下方,但是我们实现过程中采用了依赖注入的方式,将仓储层的具体实现注入到领域层中。</li>
</ul>
<h2>四、问题及近期规划</h2>
<h4>1. 价格层优惠</h4>
<p>现在公司面没有一个统一的商品中心,并且各业务线对商品的定义差别很大。比如自由行的商品包括出行日期、价格类别(成人价、儿童价)和套餐类别等层级;而火车票的商品包含座次、席别、目的地和出发地等层级。</p>
<p>如果优惠中心抽象出一种通用的商品层级来适配各个业务线,那实际上就是优惠中心要对商品进行标准定义,但是这个标准与后续商品中心的标准定义很有可能是不一致的,如果不一致优惠中心就要做大的改版。所以最终的解决方案可能还要通过推进统一商品中心的建立来解决。</p>
<h4>2. 性能问题</h4>
<p>领域驱动设计带来的弊端就是类的增多。目前优惠中心的技术栈基于 PHP, PHP 是一种解释型语言,在DDD 模式下即使有了 OPCode 等缓存技术,执行阶段的耗时相对其他静态数据类型的语言还是较大。所以后面计划将优惠中心使用 Java 技术栈重构,来进行性能上的优化。</p>
<h2>五、小结</h2>
<p>本文介绍了马蜂窝电商优惠中心基于 DDD 进行重构的一些实践经验。DDD 的思想也帮助我们在业务迭代的过程中将架构设计得更加合理。</p>
<p>当然,是否采用业务驱动设计的思想,需要取决于业务和团队的实际情况。在马蜂窝业务的快速发展下,我们在架构设计上还将做更多的探索,也将持续与大家交流。</p>
<p><strong>本文作者</strong>:徐兴旺,马蜂窝电商研发平台服务团队技术专家。</p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p><img src="/img/remote/1460000019743449?w=1080&h=481" alt="" title=""></p>
马蜂窝支付中心架构演进
https://segmentfault.com/a/1190000019673536
2019-07-05T11:32:44+08:00
2019-07-05T11:32:44+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
80
<p>为了更好地支持交易业务的快速发展,马蜂窝支付中心从最初只支持基础支付和退款的「刀耕火种」阶段,经历了架构调整的「刮骨疗伤」阶段,完成了到实现综合产品平台形态的「沉淀蓄力」阶段的演进。</p>
<p>目前,马蜂窝支付中心集成了包括基础订单、收银台、路由管理、支付通道、清算核对、报表统计等多种能力,为马蜂窝度假(平台、定制)、交通(机票、火车票、用车)、酒店(开放平台、代理商)等近 20 条业务线提供服务。本文将围绕支付中心整体演变过程中不同阶段的核心部分进行简要介绍。</p>
<h2>一、支付中心 1.0</h2>
<p>初期为快速响应业务的支付、退款以及一些基础需求,支付中心主要负责接入支付通道(支付宝、微信、连连等),由各业务线分别实现收银台,然后调用支付中心进行支付。业务系统、支付中心和第三方通道的交互流程图如下:</p>
<p><img src="/img/remote/1460000019673539?w=1580&h=832" alt="" title=""></p>
<p>各系统交互流程为:</p>
<ol>
<li>业务线将订单信息封装后请求到支付中心</li>
<li>支付中心对订单信息简要处理后增加支付信息请求到第三方支付通道</li>
<li>第三方支付通道将支付结果异步回调到支付中心</li>
<li>支付中心将第三方响应的数据简易处理后同步通知到各业务系统</li>
<li>业务系统进行逻辑处理、用户通知及页面跳转等</li>
</ol>
<p>业务发展初期,业务量较小,交易场景也比较单一,这样的设计可以快速响应业务需求,实现功能。但当业务复杂性不断提高,接入的业务也越来越多时,该架构就显得力不从心了。各业务线需要重复开发一些功能,并且支付中心不具备整体管控能力,开发维护成本越来越大。主要的问题包括:</p>
<ul>
<li>维护成本高:各业务线需单独维护收银台,调用支付系统完成支付,需分别保证幂等、安全等问题</li>
<li>容灾能力差:所有功能集中在一个大模块里,某个功能出问题,直接影响全部</li>
<li>结构不合理:架构单一,不能满足复杂业务场景</li>
<li>系统职责乱:收银台维护了收款方式及部分业务路由,缺乏统一的管控</li>
</ul>
<p>为了兼顾对快速发展中的业务的需求响应和系统的高可用性,保证线上服务的质量,我们快速进行了架构调整,开始了向支付中心 2.0 的演进。</p>
<h2>二、支付中心 2.0</h2>
<p>2.0 架构将各业务的公共交易、支付、财务等沉淀到支付中心,并主要解决了以下三个主要问题:</p>
<ul>
<li>
<strong>建立基础订单、支付、财务统一体系</strong>,抽象和封装公共处理逻辑,形成统一的基础服务,降低业务的接入成本及重复研发成本;</li>
<li>
<strong>构建安全、稳定、可扩展的系统</strong>,为业务的快速发展和创新需求提供基础支撑,解决业务「快」和支付「稳」之间的矛盾;</li>
<li>
<strong>沉淀核心交易数据</strong>,同时为用户、商家、财务提供大数据支撑。</li>
</ul>
<h3>2.1 核心能力</h3>
<p>支付中心 2.0 是整个交易系统快速发展的重要时段。在此过程中,不仅要进行架构的升级,还要保证服务的稳定。</p>
<p>目前支付中心对业务提供的主要能力包括:</p>
<ul>
<li>平台支付:用户可以使用微信、支付宝等第三方平台来完成支付</li>
<li>快捷支付:用户提供银行卡信息,进行便捷支付</li>
<li>协议支付:用户完成授权后,可以在不打断用户体验的场景下进行便捷支付</li>
<li>信用支付:用户可以选择花呗等分期产品进行透支支付</li>
<li>境外支付:用户可以选择境外支付通道完成境外产品的购买</li>
<li>线下支付:用户可以选择 ToB 通道完成特定场景的支付</li>
</ul>
<p>针对马蜂窝业务的特点,目前支持的核心交易场景包括:</p>
<ul>
<li>支付和退款:适用于普通商品的购买及退款</li>
<li>拆分支付:适用于限额或金额较大场景</li>
<li>合单支付:适用于保险等分账到不同收款账号的场景</li>
</ul>
<h3>2.2 架构设计</h3>
<p>演进过程中,首先是对相对独立,同时作为统一体系基础的网关进行模块化。支付网关对外抽象出支付、退款、查询这些标准请求,然后在网关基础上逐步梳理各支付通道,并逐步抽取出基础订单模块,解耦业务功能与支付功能,同时可支持复杂的业务场景。目前的系统功能整体架构如下:</p>
<p><img src="/img/remote/1460000019673540" alt="" title=""></p>
<p>如图所示,从架构上主要分为三个层次:</p>
<ul>
<li>
<strong>产品层:</strong>组合核心层提供的支付能力,对终端用户提供收银台、对运营财务人员提供运营财务系统</li>
<li>
<strong>核心层:</strong>支付中心核心模块,包括基础订单、支付路由、支付通道等</li>
<li>
<strong>支撑层:</strong>用来支撑整个系统的基础设施,包括监控报警、日志、消息队列等</li>
</ul>
<h4>2.2.1 产品层</h4>
<p>产品层主要包含消费者可见的收银台、支付管理后台和财务核算、对账的财会系统。本文重点介绍收银台的设计思路。</p>
<h5><strong>收银台</strong></h5>
<p>收银台包含 H5 收银台和 PC 收银台两部分:</p>
<p>移动端:</p>
<p><img src="/img/remote/1460000019673541" alt="" title=""></p>
<p>PC端:</p>
<p><img src="/img/remote/1460000019673542" alt="" title=""></p>
<p>如上图所示,收银台主要由三部分组成:订单基本信息(含订单号及支付金额)、订单详情(含日期信息、商品信息及基础信息)、支付方式(平台支付、信用支付等)。</p>
<p>由于收银台是整个支付中心面向用户的唯一入口,用户体验及安全性至关重要。为同时支持业务个性化和用户的一致性体验,收银台主要是通过<strong>定制化和配置化</strong>的方式实现。对业务同学来讲接入也非常简单,仅需通过订单号跳转至收银台页面,后续流程均由支付中心完成。 </p>
<p>用户下单后到达收银台页面,收银台通过订单所属业务线、支付金额、是否合单等信息,展示可用的支付通道。同时风控系统会从商品、订单、用户行为等维度进行监控,屏蔽高风险的支付渠道。支付渠道出现故障时可在收银台暂停展示。</p>
<p><strong>(1)定制化</strong></p>
<p><img src="/img/remote/1460000019673543" alt="" title=""></p>
<ul>
<li>为支持统一收银台下各业务线不同模式、不同展示的特性,使用工厂类继承的模式实现各业务数据及展示样式。</li>
<li>收银台主要属性分为展示模块和通道路由,其中重复及默认功能的模块由抽象类用模板的方式实现,子类使用默认方法或者重写父类方法即可达到自定义的实现。</li>
<li>收银台展示实现类已经实现了一套默认的收银台,其中包含大多数必须的组件(如倒计时,头部定制,订单详情等)。</li>
<li>一般情况下,各个业务线仅需简单添加特定的实现类,即可生成一个清晰又丰富的页面</li>
</ul>
<p><strong>(2)配置化</strong></p>
<p><img src="/img/remote/1460000019673544" alt="" title=""></p>
<p>收银台的配置化主要根据各业务的属性(业务类型、品类等)对后续操作做一定的流程处理配置化,比如:</p>
<ul>
<li>基于后端路由对收银台展示层做不同的处理,用户看到的可支持的通道列表(微信、支付宝等),以及排序置顶打标记等</li>
<li>满足不同场景、不同业务在同一种支付方式下收款到不同的收款账号</li>
<li>根据场景不同,走不同的结算方式,以及结算渠道等</li>
</ul>
<h4>2.2.2 核心层</h4>
<p>支付中心中的核心模块,包括基础订单、支付路由、支付通道等。</p>
<h5>基础订单</h5>
<p>基础订单系统是连接交易业务线、支付中心和结算系统的桥梁,实现了业务和支付结算解耦。主要涵盖了业务创建订单、关单、支付、退款、回调通知等 API 模块。基础数据支持普通支付、合单支付、拆分支付、保险支付等多种场景的支付功能,各个系统的交互流程如下:</p>
<p><img src="/img/remote/1460000019673545" alt="" title=""></p>
<p>目前基础订单系统可支持如下两种特殊场景:</p>
<p><strong>(1)一订单 VS 多商品</strong></p>
<p>创建一个基础订单可以包含 N 个商品(商品信息包含商品名称、商品 ID、单价、数量、折扣等,订单信息包含用户 UID、手机号、支付金额、订单折扣等汇总基础信息),N 个商品对应 M 个业务子订单 (M≦N),所有业务子订单的业务类型若一样则为普通模式,否则为搭售模式;每个业务订单对应一个对账单元(支付成功后会将支付信息同步给对账系统),一订单 VS 多商品的创单模式基本支持目前所有场景,包括未来可能的购物车模式。</p>
<p><strong>(2)一订单 VS 多支付单</strong></p>
<p>普通订单用户选择支付宝、微信等渠道会生成一个支付单;当金额超过 5000 元时可以选择拆分订单金额支付,此时会生成多个支付单;如果下单勾选保险就会走第三方合单支付,会生成两个支付单;同时拆分支付也会导致用户部分支付或者超额支付,监控会针对异常支付情况进行自动退款;大金额订单有 10% 以上的转换率提升, 一订单 VS 多支付单模型更好的支持了马蜂窝的支付场景。</p>
<h5>通道路由管理</h5>
<p>通道路由主要包含两方面,一个是业务侧需要控制支付通道,一个是支付侧需要选择支付账户。</p>
<p><strong>(1)支付账户管理</strong></p>
<p><img src="/img/remote/1460000019673546" alt="" title=""></p>
<p>支付创建订单和处理回调等流程中,需要根据业务类型、支付方式和支付通道确定支付账号,早期版本这个对应关系是通过配置文件维护的。一个业务类型对应多个配置项,每新增一个业务需要增加多个配置,而且随着更多支付通道的接入,新增业务需要配置的信息也越来越多,不易维护。</p>
<p>经过优化,把现有的配置对应关系放到数据库中,数据表由业务类型、支付方式、支付通道唯一确定一个收款账号,支付账号的具体参数信息还是放在文件配置中。创建订单时根据业务类型、支付方式、支付通道查询收款账号,把账号信息记录到支付订单数据表,回调时直接从订单表查询支付账号。</p>
<p><strong>(2)支付通道管理</strong></p>
<p><img src="/img/remote/1460000019673547" alt="" title=""></p>
<p>目前对接了支付宝、支付宝国际、微信、京东支付、applepay、连连支付、银联 2B 等第三方通道,每一个通道下有多个支付产品。第三方通道的接口形式差异很大,但是都提供下单、退款、查询、支付通知、账单下载等标准功能。支付中心对这些支付通道做了一次封装,用一个抽象类作为基类,使用模版方法设计模式,在基类中定义了一个标准流程,具体的实现在通道各自的实现类中。客户类只需要关心基类的公共方法,和具体通道无关。</p>
<h4>2.2.3 支撑层</h4>
<p>支撑层包含监控报警、日志管理、加签验签、配置管理、消息总线等模块。其中日志使用 ELK 进行收集管理,系统配置采用公司自研的分布式配置中心进行管理,消息总线也是使用公司二次封装的 RabbitMQ 进行消息分发及消费。</p>
<p>由于支付系统对可用性有极高要求以及支付数据的敏感性,支付中心独立实现了监控报警系统,下面将详细描述该监控报警系统的功能及设计思路。</p>
<h5>监控系统</h5>
<p>为保证监控的实时性及有效性,监控依赖的资源如数据库必须和业务库要进行隔离(避免鸡蛋放在同一个篮子里)。支付监控系统涵盖了 API 监控、 服务性能监控、数据库监控等,能够提供统一的报警、分析和故障排除能力。从异常数据采集到故障问题主动发现及稳定性趋势分析,为支付体系优化提供数据支撑。</p>
<p><strong>(1)监控后台</strong></p>
<p>后台主要包含监控用户管理以及监控项创建管理,用户可以根据需求对应的监控项目,可配置的参数涵盖 API 请求地址、请求方式、可用性、正确性、 响应时间等性能数据以及报警方式和策略;详细配置如下图:</p>
<p><img src="/img/remote/1460000019673548" alt="" title=""></p>
<p>接口监控可以针对固定 host IP 绑定以及设置超时时间,监控请求支持 GET、POST 两种方式,POST 方式可以设置固定请求参数辅助,监控频率支持分钟、秒两种级别配置;响应数据模块可以校验 HTTP code 是否异常,配置响应数据类型,比较检测返回 key 值,针对 DB 监控还可以设置 DB 查询超时时间;报警模块目前支持短信和邮件两种方式,可以设置最小、最大报警阈值,超过最大阈值每隔最大报警数会触发一次报警,规避了故障期间短信轰炸问题。</p>
<p><strong>(2)监控核心</strong></p>
<p>为了实现最快监控频率 10 秒,同时可以支持成千上万的监控项并行运行,支付监控采用了多进程管理的方式。父进程创建指定数量的子进程,每个子进程完成固定数量的监控任务退出任务,此时父进程实时监控子进程状态并创建新的子进程执行任务;父进程还可以接受外部信号完成服务重启以及停止,流程如下:</p>
<p><img src="/img/remote/1460000019673549" alt="" title=""></p>
<p><strong>(3)监控报警</strong></p>
<p>执行监控项会根据监控配置进行接口请求以及返回数据分析处理,然后通过 Redis 计数方式按报警策略进行报警通知。日常监控短信示例:</p>
<p><img src="/img/remote/1460000019673550" alt="" title=""></p>
<h3>2.3 实践经验</h3>
<p><strong>(1)数据一致性</strong></p>
<p>上文提到,我们采用模块化的方式来解耦业务功能与支付功能。在这个过程中,每引入一个模块就会涉及到系统交互问题,因此最核心的便是数据一致性问题。针对数据一致性问题需要引入事务,实时、延迟校验以及补偿机制保证数据的最终一致性。从架构看是很清晰的,但是对于整个改造过程是艰难的,犹如给飞行的飞机更换发动机,所以我们也把这个过程形容为一个刮骨疗伤的阶段。</p>
<p><strong>(2)稳定性</strong></p>
<p>支付服务都是由第三方支付通道提供的,支付通道存在不稳定性。比如用户用支付宝支付了一笔订单,由于各种原因,支付中心没有收到支付成功的通知,用户又用微信再次付款,导致重复支付。</p>
<p>为了解决这个问题,支付中心采用定时扫描的策略,主动发现重复支付单并自动执行退款,不需要人工参与。退款流程中,退款单需要经过申请、审核、调用退款接口等流程,在调接口环节,可能会发生失败。调用失败的退款单,会根据退避算法发起重试,逐渐加大重试间隔,直到次数超过限制。失败单数量超过阈值、或者有订单处于失败时间超过阈值时会触发报警。自动处理不了的退款单可以人工检测,或线下退款。</p>
<h2>三、总结 & 展望</h2>
<p>目前,马蜂窝支付中心已经具备支持多业务、多场景、多支付方式的能力,但想要实现一个真正意义上「百花齐放」的平台,还有很多地方需要改进和完善。</p>
<p>即将到来的支付中心 3.0 将以微服务的思想把单体应用按照业务进行解耦,会逐渐从一个高耦合的单一系统演变为众多子系统组成的高并发、高可用、支持更多交易支付场景的分布式系统。微服务化拆分后,在系统结构上将更加清晰,但对于整体系统的开发管理和维护也将带来更大的挑战。</p>
<p>伴随马蜂窝「内容+交易」的战略升级,支付中心也会探索更多的支付方式和能力,持续为各业务线赋能。</p>
<p><strong>本文作者:马蜂窝电商支付结算团队。</strong></p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p><img src="/img/remote/1460000019673551" alt="" title=""></p>
马蜂窝容器化平台前端赋能实践
https://segmentfault.com/a/1190000019544104
2019-06-21T10:39:27+08:00
2019-06-21T10:39:27+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
53
<p>容器对前端开发真的有用吗?答案是肯定的。</p>
<p>最初当我向公司的前端同学「安利」容器技术的时候,很多人都会说:「容器?这不是用在后端的技术吗?我不懂啊,而且前端开发用不上吧。」</p>
<p><img src="/img/remote/1460000019544107" alt="" title=""></p>
<p>但其实,今天我们讨论的「前端」已经不是传统意义上的「前端」, 首先体现在终端类型的多样性,比如 iOS,Android,小程序等;另外,伴随着 Node.js 等技术的兴起,前端开发的边界也在逐渐服务端延伸。来到大前端时代,如何以工程化、服务化和自动化的方式来进行应用开发,实现业务的持续迭代、高可用、高并发是每一个成功的互联网产品不断探索的事情,而渐为成熟的容器技术大大提高了这个过程的效率。</p>
<p>本文将结合马蜂窝容器化平台赋能前端应用构建的实践经验,介绍整个平台背后的设计和实现原理,取得的一些效果及问题的优化方案。</p>
<h2>容器与前端的结合点</h2>
<p>一般来说前端的开发流程是这样的:创建服务/项目 → 本地开发 → 开发环境测试 → 生产环境测试 → 生产灰度 → 上线。</p>
<p>基于容器化平台进行前端开发的优势在于,前端和后端完全分离,我们只需要关注前端的项目构建,而不需要和后端代码一起打包。每个构建版本及每个访问规则也都是独立的,一个版本构建失败并不影响其他版本的构建及访问。</p>
<p>那么,容器和前端的结合点在哪里?容器的优势在前端应用研发的哪个环节发生作用?我们可以从开发、测试、生产这三个阶段分别来看。</p>
<h3> 开发环节</h3>
<p>容器消除了线上线下的环境差异,保证了应用生命周期的环境一致性标准化。而对于前端开发来说,要完成的任务往往是完成内容的呈现和响应用户的输入,处理的是 HTML、JS、CSS 等静态资源,文件直接发送到客户端,不需要一个运行环境,这里好像用不上容器。</p>
<p>那 Build 的时候呢?毕竟不同的项目是用不同的 Node 版本在做构建,不同的容器可以进入不同的 Node 版本,这样就不会污染本机的 Node 环境。但其实没有容器,前端还可以用 NVM 去管理 Node 版本,切换起来很随意,也就是一两行命令就能搞定的事情。而且本地开发很方便,看起来真的没有必要用容器。</p>
<p>可以说,容器本身并没有帮助前端在开发阶段变得更加便利。因此如果对容器技术不熟悉,开发阶段没有必要非要用容器。</p>
<h3>测试环节</h3>
<p>过去我们用虚拟机进行测试的一个常见的方案是,前端研发把自己的代码上传到虚拟机的一个目录下,QA 可以直接通过域名进行测试。但问题是,公司有很多的产品线,可能会存在很多项目同时提测的情况。虚拟机对系统资源的消耗比较大,数量有限,并且难扩容,影响测试效率。</p>
<p>如果使用容器化平台就不会出现这方面的担忧。因为容器非常轻量,消耗低、启动快,可以迅速扩容,不用担心不够用的问题。</p>
<h3>生产环节</h3>
<p>容器的另一个优势是它可以实现应用程序的版本控制。比如我们在上线之后发现版本有问题需要回滚,这种情况不可避免,传统的做法是通过 Git 或者 SVN 回滚,一旦合入的代码想回退或者拆分就很难操作,而且重新部署也很耗时。</p>
<p>基于容器化的平台,我们可以直接通过流控,把流量切到旧的版本上去,几需要几秒钟的时间,回滚效率大大提升。</p>
<p>再如,前端性能的一个重要指标是页面加载时间,如果出现首页白屏是非常破坏用户体验的,特别是在做活动的时候,我们把几乎所有流量都引导到活动页,出现白屏会非常让人抓狂。找到运维排查之后发现有台服务器挂了,只能通过重启来解决。但是重启机器存在很多不确定性,有可能这台机器就起不来了,这种情况很常见。</p>
<p>但如果运行在容器化平台上,一个容器就是一个进程,一台机器如果宕机,集群会快速从另外一个节点把服务拉起,而且是秒级的,基本不用担心用户的访问会出现问题。</p>
<p>总结来看,容器与虚拟机相比主要的优势体现在可以实现快速扩容、秒级回滚和稳定保活。因此容器化对于前端开发来说,更重要的意义是能够保证服务的快速迭代,以及线上服务的稳定性。</p>
<h2>前端需要了解的容器知识点</h2>
<p>通过上面的介绍,相信大家已经对容器技术为前端开发带来了哪些变化有了一些感受。那么为了更好地应用这项技术,前端同学也应该掌握一些容器的基础知识。</p>
<h3> 容器是什么</h3>
<p>首先我们来看容器到底是什么,它为什么轻量、高性能。通过下面这张图片,我们可以将虚拟机和容器进行一个更加直观的对比:</p>
<p><img src="/img/remote/1460000019544108" alt="" title=""></p>
<p>虚拟机通过在物理服务器上层通过运行 Hypervisor 模拟硬件系统,来提升服务器的能力和容量。每个虚拟机中有一个内核,运行着不同的操作系统,启动之后会做进程管理、内存管理之类的事情。但对于前端应用的构建来说,可能只是需要一个 Nginx 做静态服务器,这种场景下使用虚拟机就太重了。</p>
<p>容器之所以轻量,是因为容器没有 Hypervisor 层和内核层,每个容器都共享宿主机的内核和系统调用。因此一个容器内包含的仅仅是一个程序运行所需要的最少文件,启动容器就是启动进程,对资源的开销更小,维护起来更简单。</p>
<h3>镜像、容器和 Docker </h3>
<p>这是大家在聊到容器技术的时候经常会提到的三个词,下面来说下它们各自的概念以及之间的联系是什么。</p>
<p><strong>镜像</strong>:可以简单理解为一层层文件系统的集合,或者说一些目录的集合。比如对于我们的前端代码,最下面那层目录可能是 Nginx 运行所需要的二进制,然后在上面再加一层目录是我们的代码,比如说 index.html。这个镜像分层所有的分层生成以后,都是只读的,每一层文件不可修改。</p>
<p><strong>容器</strong>:其实就是在上面的目录上再加一层目录。但它其实是一个空目录,区别就在于容器最上面一层是可读可写的,也就是说容器 = 镜像 + 读写层。</p>
<p><img src="/img/remote/1460000019544109" alt="" title=""></p>
<p>比如我如果想修改之前的 index.html ,是通过把新的版本累加在之前的镜像上。也就是说生成容器以后,所有的变更都发生在顶层的镜像可写层,下面的这些层是不允许往里面写东西的,但是可以累加,就像堆积木一样,一直加上去,而原来的镜像不会被容器修改,这也是镜像可以被多个容器共享的原因。 </p>
<p><strong>Docker</strong>:容器技术其实早就存在,Docker 是用来实现容器化技术的一种工具,也是目前业界最通用的一种方式,来帮我们制作镜像,然后把镜像运行成为容器并管理起来。</p>
<h2>容器化平台如何为前端赋能</h2>
<p>介绍完简单的概念,我们就和大家一起来看马蜂窝容器化平台的整体架构,我们是如何为前端赋能,以及赋予什么样的能力。</p>
<p>我们基于 Docker 和 Kubernetes 搭建了容器云平台,将应用的构建、部署、资源调度、应用管理等能力抽象出来,以服务的方式提供给研发人员,提升线上服务的稳定性和研发效率。下图从应用的角度出发,展示了前端应用在容器化平台的生命周期:</p>
<p><img src="/img/remote/1460000019544110" alt="" title=""></p>
<h3>应用中心</h3>
<p>应用是容器云平台的基本操作对象。云平台一个非常大的好处是屏蔽了项目的类型,不分前端或后端。于是在应用的外壳下,不管是前端的代码,还是后端的代码,都可以享受同样的服务。比如传统意义上应用在后端的限流、熔断、服务治理等能力一样可以赋予前端,使前端同学聚焦在业务开发上,而不需要关注底层的实现。</p>
<p><img src="/img/remote/1460000019544111" alt="" title=""></p>
<p>这是应用中心的一个创建页面,只需要几步,一个应用就可以创建完成,并且托管到我们的云平台上:</p>
<p><img src="/img/remote/1460000019544112" alt="" title=""></p>
<h3>版本管理</h3>
<p><img src="/img/remote/1460000019544113?w=529&h=355" alt="" title=""></p>
<p>创建完应用之后就要开始构建版本。通过使用容器,我们将应用程序、配置和依赖关系等打包成一个个代码镜像,然后去告诉线上服务器怎么让它们用容器化的方式运行起来。因此版本管理包含代码镜像和运行时配置两部分内容。</p>
<p><strong>1. 代码镜像</strong></p>
<p>我们使用基于 Pipeline + Docker 的 Drone 作为 CI 工具,它非常灵活,容易扩展。Drone 的灵活性体现在 Pipeline 的配置上,可以通过设置 .drone.yml 文件的方式在项目中控制构建镜像的过程。 </p>
<p><img src="/img/remote/1460000019544114" alt="" title=""></p>
<p>为了更好地支持公司级别的应用,我们向镜像注入一些内部经常用到的包来构建一个通用的基础镜像。在构建的同时会做一些 CI,比如单元测试、漏洞检测等。 </p>
<p><img src="/img/remote/1460000019544115" alt="" title=""></p>
<p><strong>2. 运行时配置</strong></p>
<p>运行时配置分成 Nginx 配置和部署运行时的配置两个部分</p>
<p><strong>(1)Nginx 配置</strong></p>
<p>Nginx 配置主要针对 Node 前端项目来说。将 Nginx 配置开放给应用有这么几点好处:</p>
<ul>
<li>前端同学可以自己去<strong>配置 history 模式</strong>,不需要再去找服务端来配合。</li>
<li>
<strong>自定义多个 locatio</strong>n。在面对多页应用时,可以通过配置 Nginx 把请求转发到指定的入口文件,实现指定路由。</li>
<li>
<strong>自定义 cache 缓存策略</strong>。缓存策略选择更灵活,提升用户体验,降低服务器处理请求的压力。</li>
</ul>
<p><img src="/img/remote/1460000019544116" alt="" title=""></p>
<p><strong>(2)部署运行配置</strong></p>
<p>部署运行配置是要告诉系统平台要如何运行版本包。这里其实也就为后续部署到 Kubernetes KVM 宿主机等多种平台留好了扩展。</p>
<p>总结来看,在版本管理的部分我们实现了以下几点能力:</p>
<ul>
<li>配置文件驱动,一个应用多份灵活好扩展</li>
<li>Nginx 配置等开放给应用,遵循 DevOps 思想,高效赋能</li>
<li>标准化版本产物,一处构建,处处运行</li>
</ul>
<h3>部署管理</h3>
<p>接下来我们需要把已经构建好的版本包部署到集群上去运行。</p>
<p><img src="/img/remote/1460000019544117?w=601&h=521" alt="" title=""></p>
<p>在线上可能会有许多台机器,V1、V2、V3 指的是各种版本。这个版本可以有多个实例。如果服务出现故障,我们主要通过两种方式来保证稳定高活:</p>
<ul>
<li>
<strong>高效调度</strong>:通过 Kubernetes 调度器将指定运行的容器调度到资源满足要求、最合适的节点上去</li>
<li>
<strong>多副本支撑</strong>:自动部署一个容器应用的多份副本,并持续监控。如果容器挂掉自动启动副本</li>
</ul>
<p>结合我们之前说到的主页白页的例子具体说明,我们会在容器化平台上持续看管容器,如果服务挂了,就在迅速在别的节点上启动起来。这里需要注意的是,「多份」不仅仅是说在两台机器上启动就叫多份,如果两台机器都在一个机柜上,甚至在一个机房里,那么启动多份也没有意义。</p>
<p>到这里,我们已经把服务部署到线上,并且实现稳定运行。但是完成部署,不代表用户就能访问,也不代表就能访问到正确的版本,所以接下来就到服务治理的环节。</p>
<h3>服务治理</h3>
<p>服务治理是一个比较大的概念,可以应用的场景也很多。它的其中一个内容是让用户访问到指定的一线上版本。</p>
<p><strong>技术方案</strong></p>
<p>首先介绍下实现原理:</p>
<p><img src="/img/remote/1460000019544118" alt="" title=""></p>
<p>我们采用的是一个 支持 xds 协议的网关。当新的配置通过 xds 协议推送给网关时,它就会自动进行热更新、热重启,然后去适应新的配置。比如说开始网关指向的是 V1 版本,如果我们现在希望指向 V2 版本,只需要把最新的配置通过 xds 协议推送给网关,它就会应用新的配置,通过这种方式就可以将指定版本部署到线上。</p>
<p>推送这里我们用的是 Pilot 组件,并针对推送速度进行了优化。Pilot 组件会不断监听数据,发现有变更后就会取出。</p>
<p><strong>应用场景</strong></p>
<p>针对这种设计,我们主要将其应用在三个场景中:回滚、分流和 ABTest。</p>
<p><strong>1. 回滚</strong></p>
<p>所谓回滚其实就是流控,比如一开始网关指向的是 V2 版本:</p>
<p><img src="/img/remote/1460000019544119" alt="" title=""></p>
<p>如果发现有问题,我只需要给网关推送一个新的配置,它就可以指向之前那个版本,非常快速:</p>
<p><img src="/img/remote/1460000019544120" alt="" title=""></p>
<p><strong>2. 分流</strong></p>
<p>分流主要应用在文章开始说到的提测场景中。过去使用虚拟机,由于不同的虚拟机有不同的域名,前端同学在测试的时候要么就是为了适配虚拟机去修改代码,要么就是需要测试同学或者产品同学自己去修改自己本机的 host,非常不方便。</p>
<p>而使用容器化的方式,如说现在默认访问的是 V2 版本,但我们现在需要测试 V1 或 V3 版本,就可以推出一个配置给网关,告诉它说如果请求里面的 cookie 含有标识 V=V1,就把请求转发至 V1 版本;同样如果 cookie 包含 V=V3,就将请求转发到 V3, 所有的转发都在网关层完成。</p>
<p><img src="/img/remote/1460000019544121" alt="" title=""></p>
<p>为了使服务更易用,我们提供了一个插件去自动识别云平台部署的服务和版本。QA 和 产品同学在测试的时候,只需要点选版本就可以,系统会自动完成 cookie 注入。然后向服务端发送请求时,网关就会发现这个携带了某个版本的 cookie,自动完成转发:</p>
<p><img src="/img/remote/1460000019544122" alt="" title=""></p>
<p><strong>3. ABTest</strong></p>
<p>同样的原理,我们可以通过配置指定用户的 UID,控制用户去访问 ABTest 中的不同版本,这里支持的方式有很多,比如注入 cookie、不同的 head 头、不同的请求方式等等,非常灵活。</p>
<p><img src="/img/remote/1460000019544123?w=983&h=232" alt="" title=""></p>
<p>以上是服务治理的内容。总的来说,我们能够自动化部署访问规则,可能只需要前端同学做一个 git-push tag 的操作,就已经打好版本并部署到开发环境甚至是生产环境,而整个过程对于平台的使用者来说是无感知的: </p>
<ul>
<li>自动化部署访问规则,完整 CI/CD</li>
<li>灵活的分流策略,带来秒级回滚,灰度,abtest 等功能</li>
<li>结合 chrome 插件,体验流畅</li>
</ul>
<p>以上介绍了基于容器化云平台我们可以为前端赋予哪些能力。经过一些时间的探索,目前我们的流程已经比较通畅,但不可避免还是会遇到一些问题。</p>
<h2>那些年我们遇到的 404</h2>
<h3>1. 上线后,发现 js 访问404 </h3>
<p>这种情况对用户体验来说非常糟糕。经过排查后我们发现问题出现在为了做到高可用,我们的网关配置了多个。</p>
<p>因为网关的转发配置是通过推送下发的,多个网关之前就会存在时间差。有的网关先收到新的推送,有的后收到。当用户的请求打到了其中一个网关拿到了一个 html,会告诉它应该访问哪个 hash 的 js。但如果不巧的是 hash 的 js 却访问到了另外一个网关,然后转发到另外一个版本,也就是另外一个容器,那么 hash 值肯定就不一样了,找不到对应的文件,导致 404。</p>
<p><img src="/img/remote/1460000019544124" alt="" title=""></p>
<p>这个问题不仅云平台会存在,只要是分布式的部署方案都可能存在时差的问题。我们的解决方案是让所有网关都连接到同一个 Pilot。因为网关的数量是有限的,这时配置的下发就是由一个组件去负责推送所有的网关,因为 xds 协议本身是基于 GRPC 实现的,是一个长连接的操作,所以速度非常快。当由一个节点去做推送,所有网关接收到配置的时差可以控制在在毫秒间,几乎没有影响。也就是 A 网关接收到新配置的同时,基本上 B 网关也已经接收到新配置,这时候所有请求无论打到哪个网关,他们都会指向同一个版本,这个时候线上就不会再出现 404 的请求。</p>
<h3>2. 灰度环境,js 访问 404</h3>
<p>之前说到,我们的灰度方案是应用插件做 cookie,理论上来说只要 cookie 的配置正确,就可以转发到指定的版本上去。那么既然我的 html 已经没问题了,为什么 js 还会出现 404? </p>
<p>排查后发现,因为 js 请求的时候有一个标签叫「匿名标签」,如果我们在用 js 的时候打了匿名的标签,浏览器在发 js 请求时就不会携带任何身份的标识,网关就会认为访问到一个默认版本,也就是线上的版本,这个时候如果请求再到 V2 版本就会 404。 </p>
<h2>近期规划</h2>
<h3>1. 尽可能释放构建 Pipeline</h3>
<p>目前我们构建镜像的方式主要是用 npm install 和 npm run build 两个命令。之后我们会尽可能去释放 Pipeline,包括基础镜像、Node 版本等,让前端同学可以实现更多自定义的需求。</p>
<h3>2. 优化构建和部署时间</h3>
<p>目前我们构建镜像的方案没有很好地利用 Docker 的缓存机制,因此会影响构建的时间。我们目前也在做优化,尽可能减少甚至消灭大部分 npm install 的时间和 build 的时间。</p>
<h3>3. 释放监控告警能力</h3>
<p>目前我们已经完成了一部分监控告警能力的建设,主要是由平台维护团队在使用,去监控 QPS 状况、服务是否稳定,有没有重启等,团队内部也会收到很多告警。但我们认为这种报警其实更应该发送给服务的负责人,后面我们慢慢要将这部分能力释放出来,并且不断完善和优化告警规则。</p>
<h2>总结</h2>
<p>最后简单总结:</p>
<p><strong>容器化之后到底给前端赋能了什么?</strong></p>
<ul>
<li>提高测试效率</li>
<li>服务更加稳定,运维高效</li>
</ul>
<p><strong>马蜂窝云平台如何进一步给前端赋能?</strong></p>
<ul>
<li>应用中心:一步上云,无差别享受云平台带来的服务</li>
<li>版本管理:实践 DevOps思想,赋能 Nginx 配置;配置驱动,灵活好扩展 </li>
<li>部署管理:智能调度,稳定高活 </li>
<li>服务治理:秒级回滚,秒级恢复,灰度访问,ABTest等众多功能</li>
</ul>
<p>目前我们在如何通过容器化的方式帮助前端完成应用研发有了一定的探索,并且通过云平台的方式上做到更进一步的赋能,希望能带给大家一些技术思维上的启发。</p>
<p><strong>本文作</strong><strong>者:周磊</strong>,马蜂窝旅游网基础平台服务化研发工程师。</p>
<p><em>(题图来源于网络)</em></p>
<p><img src="/img/remote/1460000019544125?w=1080&h=481" alt="" title=""></p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
马蜂窝大交通业务质量体系建设初步实践
https://segmentfault.com/a/1190000019476725
2019-06-14T10:17:10+08:00
2019-06-14T10:17:10+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
14
<p>质量是决定产品能否成功、企业能否持续发展的关键因素之一。如何做好质量体系建设,这是个比较大的话题,包含的范围很广,也没有固定的衡量标准。</p>
<p>打开一个互联网公司招聘网站,搜索「测试工程师」岗位时,你会发现几乎全部 JD 都包含一条要求「建设或者参与建设所负责业务的质量体系」。那么,是不是谈到质量保障就只是测试团队的职责?测试团队在这个过程中如何发挥价值?本文将结合马蜂窝大交通测试团队在质量体系从无到有搭建过程中的实践,来谈一下对质量体系建设的看法和理解。</p>
<h2>质量管理的常见误区</h2>
<p>在谈到质量管理的时候,很多团队在开始时会容易进入几个误区:</p>
<p><strong>测试环节再关注</strong></p>
<p>在实际项目中,很多时候都在测试阶段才发现大量实现类 bug,测试人员每天拉着研发修 bug;要么就是在临近上线的时候发现了一个重大问题,导致修复验证时间不够,但又只能「硬着头皮」上线。质量保障是要贯穿项目实施从需求提出到研发到测试全阶段的,如果到测试环节才来关注,已经晚了。</p>
<p><strong>质量保障是 QA 的事</strong></p>
<p>有了良好的质量我们才能提升用户体验和留存率。和第一个问题相类似,很多人会认为质量只是 QA 的事,和其他角色没有太大的关系。而实际上,软件的质量是在整个研发过程中逐步形成的,离不开 QA 团队,但只靠 QA 团队关注肯定是不够的,业务中的全部角色都需要提升质量意识:开发要增强自测;产品要提前规划和测试好要上线的内容,当在质量和上线时间发生冲突时应该首选质量;运营同学对自己配置的运营页面要经过测试后再上线等等。</p>
<p><strong>测试人员不需要懂代码</strong></p>
<p>在开发快速迭代的环境下,对测试工作的技能要求越来越高,测试和开发之间的合作更加快速紧密。全手工测试的方式主要有两个问题,一是时间成本高,无法满足当前快速迭代的需求,而且容易出错;二是测试人员自身的技术水平得不到提升,成长性受限。</p>
<p>除了手工测试之外,需要根据业务和团队的需要适时开展接口自动化、UI 自动化、Code Review 等提升效率的工作。两者有效的结合才是测试质量保证的关键。</p>
<p><strong>正常上线就大功告成</strong></p>
<p>一个项目从需求提出、开发、测试、发布只是走完了线下流程,虽然系统经过了严格的测试,但是毕竟线上的情况和场景会更加复杂多变,上线后才是真正经受线上用户考验的时候,我们必须关注线上日志、用户反馈、线上报警等,及时修复线上问题,并将用户提出的合理化建议转为产品优化或产品需求并实现,形成整个闭环。</p>
<h2>大交通研发质量体系建设</h2>
<p>为了帮助用户更好地完成消费决策闭环,马蜂窝上线了大交通业务,为用户提供购买机票、火车票等服务。为了提升系统的稳定性、更好地支持高并发,大交通将原有 PHP 架构的交通业务重构成支持高并发和更稳定的 Java 集群架构,同时逐渐将各模块的业务容器化,来提升系统的整体性能并且可维护。</p>
<p>大交通测试团队主要负责机票、火车票和用车业务的测试。为了避免上面说的四个误区并结合研发团队的具体情况,大交通研发质量体系建设主要是从项目流程、业务测试、线上事件和工具建设四个方面来进行的。现阶段质量体系建设的目标有 2 点:</p>
<ul>
<li>缩短线下项目的工期,减少线下 bug 数量</li>
<li>减少线上问题数量</li>
</ul>
<p>质量体系大盘如下图所示,其中虚线框中的部分是规划中或者正在进行中的,实线框中的部分已经完成。</p>
<p><img src="/img/remote/1460000019476728?w=865&h=595" alt="" title=""></p>
<h3>1. 管控项目流程,提升交付质量</h3>
<p>产品的质量不是依靠一个团队或一个阶段就可以保障的,需要在研发的整个流程、每一个阶段进行控制和管理。</p>
<p><strong>1.1 分类需求,明确项目周期</strong></p>
<p>大交通业务从无到有,业务功能开发需要具有快速迭代和交付的能力,目前采用的是双周迭代模式,挑战性是比较强的。为了在项目快速上线的同时保证质量,我们按照需求的不同类型和等级梳理了交付的核心时间节点。</p>
<p>目前大交通客户端页面较少,大多为 H5 前端页面。以双周迭代为前提,需求一共分为 3 类:</p>
<ul>
<li>
<strong>日常</strong> - 开发工期较短,1 个迭代内完成。</li>
<li>
<strong>项目</strong> - 开发工期 3 天以上,大约 2 个迭代内完成。</li>
<li>
<strong>线上事件</strong> – 计划外的突发状况,通常来说紧急程度高,可能会直接影响线上业务,需要及时响应。</li>
</ul>
<p><img src="/img/remote/1460000019476729" alt="" title=""></p>
<p>需求包含产品需求和技术需求。为了合理安排开发资源,日常需求和项目需求进行双周 PK,根据项目价值、优先级、资源情况等确认后续 2 周的需求范围。日常、项目主要流程如下图所示:</p>
<p><img src="/img/remote/1460000019476730" alt="" title=""></p>
<p><strong>1.2 项目进度可视化管理</strong></p>
<p>要缩短交付周期,如何让团队更好的协作,敏捷的推进产品研发是需要考虑的问题。整体思路采用 SCRUM 敏捷的方法论来推进,此类落地工具有很多,我们选择的是 TAPD 来管理整个研发生命周期。比如用故事墙对大型项目的迭代规划状态进行可视化管理;对于专项任务使用看板进行阶段性同步等,透明团队工作,让每个角色都能对进度直接负责,提升协作效率。</p>
<p><img src="/img/remote/1460000019476731" alt="" title=""></p>
<p><strong>1.3 持续集成工作流</strong></p>
<p>Bug 发现的时机越晚,修复 bug 所需的时间就越长,项目工期就越长。为了提升每一个环节的交付质量从而减少线下 bug 和加速项目进度,我们在流程中针对各角色逐步推进了以下机制:</p>
<p><img src="/img/remote/1460000019476732" alt="" title=""></p>
<p>i)<strong>针对产品和 UI </strong>,我们约定需求 PK 通过后 3 天内进行需求评审,提升需求的交付速度;开发联调结束后和提测前参与 Show Case,第一时间验收产品。</p>
<p>ii) <strong>针对研发</strong>,在测试环境 CI/CD 中加入了 Sonar 静态代码扫描,只有通过质量阀后才能部署;联调结束后运行自测用例并将结果标注在用例管理工具中;并组织 Show Case,给产品、运营、测试展示主流程。</p>
<p>iii)<strong>针对测试</strong>,将测试用例评审时间提前,尽量跟开发技术方案评审时间一致,在提测前 2 天就开始部署隔离的测试环境供开发连调和自测。</p>
<p><em>(隔离的测试环境是为了多项目并行而使用,会在后续章节中详细介绍。)</em></p>
<p>iv)<strong>运营同学</strong>提出的需求,会在 Show Case 时邀请运营第一时间参与产品验收。</p>
<p><strong>1.4 培养全员项目管理意识</strong></p>
<p>大交通技术团队目前没有专职 PM,所有项目的 PM 均为技术兼职。为了保障所有日常和项目均能如期甚至提前完成、更好的让项目流程落地以及优化项目流程,由测试团队负责人等 3 人兼任 PMO,针对项目流程中的问题为研发和产品同学进行分享和培训,提升研发人员的项目管理能力和产品同学的流程意识。</p>
<p>良好的项目流程制定和优化、项目流程落地、每个环节负责人都高质量地交付给下一个环节的负责人,是保障产品质量的第一步。</p>
<h3>2. 加强业务测试,实现功能保障</h3>
<p>业务规模快速发展,业务逻辑越来越复杂,系统级别交互越来越多,都给测试团队带来极大挑战。大交通测试团队内部主要是从 5 个方面来提升业务测试能力:</p>
<p><strong>2.1 熟悉业务流程和功能</strong></p>
<p>对于测试人员来说,熟悉业务流程、功能等需求,才能打开思维,在测试过程中做到有的放矢。比如大交通的机票业务对基础数据准确性要求很高,还有虚仓、改签、航变、运价、值机等特有的功能,这些都需要测试人员去深入了解。我们会非定期邀请产品、运营同学进行机票业务的培训,同时测试也会给开发同学反讲和培训一些业务。</p>
<p>随着团队新人的加入和系统越来越多以及越来越复杂,为了避免漏测,我们启动了梳理各业务功能、功能入口矩阵图的工作。举个例子,机票保险除了 C 端用户页面,运营后台和供应商后台也有相应功能,那么机票保险相关的业务我们需要把全部入口都考虑到。矩阵图给技术方案评审、测试计划和测试方案制定提供了指导性意义。</p>
<p><strong>2.2 阅读后端代码</strong></p>
<p>作为系统测试工程师,不需要对开发代码了如指掌、掌握每一个方法,但是适当的阅读代码和代码的逻辑是有必要的。</p>
<p>大交通研发后端代码以 Java 为主,在熟悉业务的前提下,有 Java 代码基础的测试人员每个季度都会设定阅读后端微服务代码的绩效目标,阅读代码、搞清微服务、数据库或缓存、定时任务之间的调用关系、沉淀成文档、并反讲给编写该微服务的开发,由开发来判断阅读效果。读完部分甚至全部代码之后,后续的新项目中可以更加自如地从头把控产品质量,如技术方案是否合理、对增量代码进行 Code Review 提前发现 bug、协助开发定位问题原因,并推动开发在编码前进行技术方案、接口协议、数据库评审。</p>
<p>下图是机票测试同学阅读机票接入基础数据相关代码时梳理的部分流程图:</p>
<p><img src="/img/remote/1460000019476733" alt="" title=""></p>
<p><strong>2.3 测试覆盖率统计</strong></p>
<p>覆盖率是度量测试完整性和有效性的一个常用手段。在大交通业务体系中,有些项目的逻辑分支非常复杂,为了评估手工、接口自动化、UI 自动化等黑盒测试手段是否能覆盖全部代码逻辑分支。近期我们启动了增量代码覆盖率统计项目,目前在小型项目中试用,一轮测试完成后查看覆盖率统计数据,在二轮测试中则重点覆盖第一轮中未涉及的部分。</p>
<p>有时候某些逻辑分支构造测试场景非常困难,这时需要引入 Code Review 等手段来进行覆盖。需要注意的是,即使把增量代码百分百覆盖掉,也不代表就万事大吉了,有时候开发会漏开发某部分代码,这种情况下最好的情况是在技术方案评审和结合功能矩阵图来设计测试用例时发现,但我们建议在测试后期仍要再来审视一次是否有遗漏开发的情况。</p>
<p>除了增量代码测试,每次项目上线前还需要对业务主流程进行回归测试。</p>
<p><strong>2.4 推进项目自测</strong></p>
<p>大交通有些较为简单的日常和项目测试没有介入,采用开发自测+产品验收后直接上线的模式。测试同学不定期会给开发和产品同学培训测试基础知识,比如:部署隔离的 Java 测试环境、部署 PHP 代码,前端微服务切换、Mock 平台使用等,有些项目测试也会提供测试用例由产品来执行,通过培训使没有测试介入的项目也能够保证质量。</p>
<p><strong>2.5 数据统计分析</strong></p>
<p>在推进代码质量时,我们以月为单位需对项目和 Bug 进行数据汇总,并通过对数据进行分析,发现和总结项目过程中的问题及产生原因,针对问题提出项目目优化和质量提升建议并在项目组中推动施行。</p>
<p>月度报告关注的是项目质量往更优发展,而不是统计本身。通过数据展示,大家也可以知道我们的项目质量在持续提高,比如在多个机票大项目并行的情况下,大交通今年 Q1 的线下 bug 总数比去年 Q4 下降了 1/4, 通过数据大家可以感受到项目的整体质量越来越好,也是对团队很好的鼓舞。</p>
<h3>3. 关注线上,形成问题闭环</h3>
<p>在文章最初部分我们讲过只关注线下是不够的,必须要关注线上,将线下和线上结合在一起形成闭环。大交通在线上问题的发现、处理、汇总上主要做了以下几个方面的工作:</p>
<p><img src="/img/remote/1460000019476734" alt="" title=""></p>
<p><strong>3.1 标准化反馈流程</strong></p>
<p>测试团队制定了一套完整的线上问题处理和反馈机制,明确工作流,并借助工具(TAPD)落地。</p>
<p><img src="/img/remote/1460000019476735" alt="" title=""></p>
<p>内部用户和外部客服人员反馈问题后,由运营、产品统一记录到 TAPD 中,由技术支持人员过滤问题,复现并确认问题是否有效,如果有效则判断问题类型:如是咨询类问题,则技术支持直接回复;如是 bug(即线上故障),则转交开发解决;如是产品改进,则转交产品记录。遇重大问题开发则通知 Team Leader 关注。无论何种类型的问题,都会在 TAPD 流转,直至问题问题报告人验证并关闭。最终,处理结果将反馈至内外部用户。</p>
<p><img src="/img/remote/1460000019476736" alt="" title=""></p>
<p>高优先级问题会被优先处理,处理完毕后也会尽快组织故障 Review。</p>
<p><strong>3.2 主动发现问题</strong></p>
<p>除了线上报警外,技术支持也会定期巡检各业务,预防重大线上问题发生,并通过数据大盘、数据库异常数据、小时报等异常数据来主动发现线上问题并推动解决。</p>
<p><strong>3.3 质量会议</strong></p>
<p>每周固定召开质量会议,由技术支持发起,开发、测试、产品、运营参加,对上周的线上问题逐个进行 Review,故障类问题分析原因、以点带面将类似问题全部解决;咨询类问题转需求和运营工具、释放人力;产品缺陷类转为产品需求。每月初的质量会议也会对上月的线上问题进行整体 Review,针对问题提出质量建议并推动落地。</p>
<p>目前大交通的线上故障月度数据呈下降趋势,与线下项目质量提升、每周的质量会议和全员质量意识培养密不可分,并且随着产品改进类需求上线,用户体验也越来越好。</p>
<h3>4. 完善工具建设,提升测试效能</h3>
<p>只有手工点点点是远远不够的,结合大交通的实际业务场景,测试团队的工具建设主要围绕环境支撑、压力测试、测试平台、UI 自动化、接口自动化等方面展开。</p>
<p><strong>4.1 环境支撑</strong></p>
<p>无论 Code Review 做得多么完美,最终都需要进行集成测试。良好的测试环境是对测试效率和项目质量的保障,同时测试环境适合与否会对测试结果的真实性和正确性很重要。</p>
<p>大交通的测试环境共有 3 套:Dev 环境、QA 环境、预发环境。之前测试环境出现过一些较明显的问题,比如:</p>
<ul>
<li>在抢占开发 Dev 环境的情况下同时最多只能测试两个 Java 代码变更项目(QA 和 Dev 各测试一个),严重影响效率。</li>
<li>QA 环境上频繁部署引起测试中断。</li>
<li>QA 环境上出了真实的票产生了资损。</li>
<li>Dev 环境上开发自测的很完美,但提测后部署到 QA 环境之后连主流程都不工作。</li>
</ul>
<p>为了解决以上问题,我们进行了测试环境改造及预发环境打通。</p>
<p><strong>4.1.1 测试环境改造</strong></p>
<p>针对以上问题,我们将提升测试环境的<strong>稳定性、并行性、隔离性、实时性</strong>作为重点指标进行测试环境改造:</p>
<ul>
<li>
<strong>相对稳定性</strong>:<p>- QA 有需要时部署 </p>
<p>- Java 代码:回收开发同学 Jenkins 权限</p>
<p>- PHP 代码:推动公司 PHP 部署平台(AOS)进行改造,只有 owner 和分享的人才能部署</p>
</li>
<li>
<strong>并行性</strong>:<p>- Java:所有微服务均引入测试环境隔离插件,同时支持多项目并行测试</p>
</li>
<li>
<strong>隔离性</strong>:<p>- 测试环境的订单不能出到线上</p>
<p>- 机票接入:订单拦截</p>
</li>
<li>
<strong>实时性</strong>:<p>- 除被测代码外,其他代码也要实时更新。</p>
</li>
</ul>
<p>良好的测试环境有力的保障了多项目并行开发、连调和测试。提测前 2 天测试同学就开始协助开发部署项目隔离环境,开发在隔离环境中连调和自测,自测通过后测试同学直接在该项目隔离环境进行测试,大大节约了从 Dev 到 QA 的转换时间。</p>
<p><strong>4.1.2 预发环境打通</strong></p>
<p>大交通测试环境中的数据库、MQ、Redis 等中间件跟生产环境是分开的,账户是虚拟账户,出的票是模拟票,因此测试环境跟生产环境还是有很大差距的。过去测试环境结束后直接上线的项目中,有些服务上线后连启动都是失败的。</p>
<p>为了能在更加接近生产环境的条件下进行测试,提高一次上线成功率,我们启动了打通机票、火车票预发环境的技术项目,对预发环境我们的定位是:</p>
<ul>
<li>上线前预演</li>
<li>真实账户、真实交易</li>
<li>代码与生产隔离</li>
</ul>
<p>机票火车票的预发环境全部打通后,全部项目在测试环境结束后上预发进行主流程回归,然后上线。</p>
<p>目前采用的测试流程如下:</p>
<p><img src="/img/remote/1460000019476737" alt="" title=""></p>
<p><strong>4.2 压力测试</strong></p>
<p>在高并发的场景的搜索类项目和活动类项目中,我们进行压力测试。压测流程如下图所示。这里可以参考之前马蜂窝技术公众号发布过的一篇<a href="https://link.segmentfault.com/?enc=2bTDRILB0Py6LClPrfJ79Q%3D%3D.xg4LlD82EmkFALgTi4A%2BFiJLNiRfDqDEjbphRKoJprI3bOdxK93%2BtUWSBf2Wc3URuVbNVqgQ3O%2FenR129k0fRUSTsPXrtNIGQHbejRMRoCqspMdqzEOTCNLRwo1euaTidRYllMHji%2FFsinChch%2FKzBnx8SyfhTNgGkUPgx74VboPs0hEJA5Xwsy03Q0Fh8KQXdfCTAkXJcB750ACNJRbpP1iEBas%2Bvz1nfVRtbjxwkXwqJnL%2F22dHfb8vR3qYQDKK6b0BtkQ5XOhf2C2L9ueiudTFxy4y3VQHg4LT4zs1LZlhgSjRtfewun14lVlhzyg" rel="nofollow">关于压力测试的文章</a>,在此不过多展开。</p>
<p><img src="/img/remote/1460000019476738" alt="" title=""></p>
<p><strong>4.3 测试平台</strong></p>
<p>测试平台是大交通测试的门户网站,大交通研发业务线后端使用 Java,前端统一使用 VUE,为了让大家更快地熟悉大交通研发技术栈,测试平台采用了跟研发前、后端一致的架构。</p>
<p>测试平台的最终目标是将团队开发的工具,如代码覆盖率统计、数据工厂、压测结果展示等整合在一起,后续计划把接口自动化、UI 自动化等功能逐步加入,逐步完善测试平台功能,并以界面化的形式开放给团队内外部人员使用,提升测试效率。</p>
<p><img src="/img/remote/1460000019476739" alt="" title=""></p>
<p><strong>4.4 数据工厂</strong></p>
<p>数据工厂基于大交通测试平台开发。在一些逆向交易的需求测试中,需要先创建不同类型的订单作为测试前提,如果从前端下机票订单的话,一共需要操作5步:首页->列表页->报价页->订单填写页->乘机人选择页。为了简化创建订单的步骤和方便产品验收以及外部团队回归使用,我们设计并实现了机票数据工厂,希望可以实现国内国际机票测试一键生单,向研发、测试快速提供订单数据,为测试环境回归提供数据。</p>
<p>大交通机票测试环境中除了项目隔离环境外,还维护了一套稳定的主干环境,该环境中代码基本和线上保持一致,数据工厂基于主干测试环境来创建机票订单。</p>
<p>目前数据工厂一共分为四个模块:国内/国际机票生单模块、模拟支付模块、出票模块和日志记录模块。四个模块和机票服务端的调用关系如下图所示:</p>
<p><img src="/img/remote/1460000019476740" alt="" title=""></p>
<p>目前数据工厂实现了生单、模拟支付、出票和操作日志等功能,填写了参数之后,在前端页面直接点击相应按钮就可以了。</p>
<p><img src="/img/remote/1460000019476741" alt="" title=""></p>
<p><strong>4.5 接口自动化</strong></p>
<p>接口自动化的好处不言而喻,我们采用的是比较通用的接口自动化框架 TestNG+Rest-assured+Maven,目前在 Jenkins 上配置运行,后面要对接到测试平台。</p>
<p>目前覆盖主流程的回归测试用例在测试环境定期运行,搜索类接口的自动化在线上定期运行进行监控,有异常时会发邮件报警。除此之外接口自动化还用于数据创建、主流程回归和迁移类项目测试中。</p>
<p><img src="/img/remote/1460000019476742" alt="" title=""></p>
<h2>遇到的一些困难</h2>
<p>在搭建质量体系的过程中,我们也遇到了一些困难:</p>
<h3>1. 流程改进中的困难</h3>
<p>比如 Sonar 静态代码扫描的引入。之前 Sonar 只是放在了 CI 平台并没有跟 CD 绑定在一起也没有引入质量阀,需要专职人员来督促开发进行扫描和检查扫描结果,引入静态代码扫描的效果并不是很好。</p>
<p>为了让 Sonar 自动的发挥它的代码检查效能,我们将 Sonar 引入测试环境 CD 平台,制定了统一的质量阀,Sonar 扫描不通过质量阀的就无法部署到测试环境,最初以一个项目为试点启用、发现问题和解决问题,现在全部项目在提测前都需要通过 Sonar 代码扫描并通过质量阀,通过之后才可以提交测试。</p>
<h3>2. 业务测试和工具开发时间冲突</h3>
<p>大交通没有专职的测试开发岗位,发生冲突的情况下优先保障业务测试,业务测试间隙期来做工具开发工作,在这样的情况下有一些跟业务测试结合比较紧密的自动化工作开展的比较缓慢,目前我们的接口自动化只覆盖了核心回归用例,后面需要把接口自动化和大多数项目测试结合在一起,真正把接口自动化应用于项目测试中。</p>
<h2>总结</h2>
<p>大交通测试团队成立了不到一年,经过一段时间的摸索和实践,在研发质量上有了一定的提升,但我们在质量体系建设的道路上才刚刚起步。随着业务系统越来越复杂,对测试人员和质量体系的要求也会越来越高,也需要全体成员不断提升质量思维、持续追求质量。未来,我们将不断积累方法、优化流程和完善工具,保证高质量的持续交付。</p>
<p><strong>本文作者</strong>:孙海燕,马蜂窝大交通业务测试专家、大交通测试团队负责人。</p>
<p><em>(题图来源于网络)</em></p>
<p><img src="/img/remote/1460000019476743" alt="" title=""></p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
马蜂窝用户内容贡献能力模型构建
https://segmentfault.com/a/1190000019428395
2019-06-10T10:31:51+08:00
2019-06-10T10:31:51+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
5
<p>在用户个性化时代,垂直化、精细化的运营,被看作企业重要的竞争力。完整、清晰的用户画像体系,可以帮助企业从海量的用户信息中发掘每个用户的行为特性、潜在能力及兴趣等信息,从而为用户提供具有针对性的服务。</p>
<p>马蜂窝拥有海量的用户出行体验数据,在成长和发展的过程中一直在探索如何通过基于海量 UGC 的数据挖掘出每个用户的基本特征、对旅游主题、目的地的偏好和潜在兴趣,从而精准地定位和标记用户,将优质的内容、商品和服务与用户进行连接。</p>
<p>今天这篇文章,主要围绕马蜂窝用户标签体系中的「用户贡献能力」标签,来介绍我们如何挖掘那些对马蜂窝的 UGC 有贡献能力的群体,这样做的价值是什么。</p>
<h2>挖掘用户内容贡献能力的意义</h2>
<p>鼓励用户分享原创内容、彼此借鉴旅游信息,是马蜂窝得以持续吸引用户的核心。这些用户产生的原创内容不仅包括记录自己旅游体验的攻略、游记,也包括帮助其他用户解决旅行疑惑的问答、点评等。通过这种互享型的内容互动模式,越来越多存在个性化旅行需求的用户在马蜂窝完成旅游消费决策的闭环。</p>
<p>为了更好地帮助用户提升决策效率,我们需要挖掘出那些拥有丰富的自由行经验,并且具有一定内容生产能力的旅行者,围绕内容增长、用户活跃制定相关策略。</p>
<p>如果只通过用户的等级划分来评估该用户的影响力,显然是存在问题的。我们都知道,用户等级作为用户激励体系中的一种方式,是对用户过往行为的认可,因此等级一般只会上升不会下降,这种特点导致:</p>
<ul>
<li>
<strong>用户核心输出能力无法得到有效量化</strong>:用户只要每天进行打卡、回复、评论等简单行为也会慢慢升级到高级别;</li>
<li>
<strong>用户升级以后等级固化:</strong>例如用户很长时间没有登录,但从等级来看他的影响力依然很强;</li>
<li>
<strong>无法感知用户的内容输出意愿</strong>:即使用户等级高且在近期有过登录行为,但对哪些话题感兴趣、是否存在生产内容的意愿我们无从感知。</li>
</ul>
<p><img src="/img/remote/1460000019428398?w=811&h=274" alt="" title=""></p>
<p>为了解决以上问题,我们将内容贡献能力作为用户画像标签体系中的一个字段进行挖掘,并应用到马蜂窝很多业务当中,比如:</p>
<p><strong>旅游问答邀请</strong></p>
<p>马蜂窝问答可以看成是一种更快捷、简短、个性化的旅游攻略。我们可以圈定近期在该领域内容贡献丰富的、以及内容受欢迎的相关用户,推荐给提问者定向邀请回答,保证旅行者的问题能够快速、准确地被解答。</p>
<p><img src="/img/remote/1460000019428399?w=727&h=1101" alt="" title=""></p>
<p><strong>马蜂窝 KOL 挖掘</strong></p>
<p>利用用户内容贡献能力标签,我们可以更精准地挖掘活跃的、专业的、热爱旅行并能生产高质量内容的 KOL,一方面可以在线上通过邀请入驻、内容推荐等方式,让这些资深旅行者的优质内容得到更多曝光;另一方面,可以将 KOL 的力量组合起来,转移到线下,用他们的亲身经验最简单地带动用户的直观认知,比如「马蜂窝指路人」等。</p>
<p><img src="/img/remote/1460000019428400?w=1080&h=569" alt="" title=""></p>
<p><strong>图:马蜂窝旅行家专栏</strong></p>
<p><strong><img src="/img/remote/1460000019428401?w=743&h=711" alt="" title=""></strong></p>
<p><strong>图:马蜂窝指路人俱乐部</strong></p>
<h2>用户内容贡献能力模型</h2>
<p>简单来说,就是从用户的的活跃度、在一定时间内的受欢迎度、输出意愿三个维度构建模型,从而对用户贡献能力进行测度,即:</p>
<p><strong>用户内容贡献能力 = 用户的输出意愿 + 用户的活跃度 + 用户的受欢迎程度</strong></p>
<h3>1. 用户活跃度模型</h3>
<p>RFM 模型我们很多人都不陌生,这是衡量用户价值和用户创利能力的经典工具。这里我们基于马蜂窝旅游社区的场景,将 RFM 模型的三个因素调整为:</p>
<p><img src="/img/remote/1460000019428402" alt="" title=""></p>
<p><strong>A(Activity)</strong>:用户活跃度</p>
<p><strong>e^(-αt)</strong>:最近一次访问时间距今天的时间衰减,采用指数衰减,其中 α 为衰减系数。这里利用指数衰减函数做为时间衰减因子,F*E 可以理解为用户的活跃的热度,时间衰减因子体现了用户活跃的热度随着时间逐渐衰减的过程。在马蜂窝场景下,通过对实际数据的调参,我们选择当时间 t 为一年(365)的时候衰减为最小值 0.0001,此时带入公式求出 α 的值。这里考虑的是用户一年未贡献任何的内容则意愿衰减至最低,求得 α 为 0.0189;</p>
<p><strong>F(Frequency):</strong> 用户在特定时间内的内容贡献频次。这里也是基于场景包含对游记、问答、攻略、笔记(图、文、视频结合)等所有类型内容的计算;</p>
<p><strong>E(Engagements)</strong>:用户最近一次贡献内容的类型,不同类型的 UGC 对应的值不同。例如产出一篇游记的难度以及内容的价值要高于回答一个用户的问题,和以图片、视频为主的笔记。经过在马蜂窝全站计算不同类型的文章在 UGC 数量占比,得出如下结论:游记的 E 值为 5,问答值为 2.5,笔记值为 3 。</p>
<h3>2. 用户受欢迎程度 </h3>
<p>无论是什么形式的 UGC,被认可的方式通常基本都是通过其他用户的点赞、评论、收藏、分享几种方式。在马蜂窝,游记、问答、攻略、笔记等不同的文章形式欢迎度是不同的,比如以图片、视频形式为主要呈现形式的短内容(笔记 )虽然曝光较多,但是被点赞、评论等认可度却不如攻略或者游记这样的长文章。</p>
<p>因此这里通过分析社区中游记、问答、笔记等不同内容的被赞情况进行分析,算出一个用户欢迎程度最终综合得分和平均分,如下:</p>
<p><img src="/img/remote/1460000019428403?w=413&h=38" alt="" title=""></p>
<p>以上,W 代表的是用户受欢迎程度的综合得分,α、β、χ 分别代表不同类型内容的权重因子。这里通过计算全站不同形式的文章被赞的情况进行分析,得出 α:β:χ = 1:1.05:0.98 ,为了计算方便近似取 α、β、χ 均为1。</p>
<p>Travel 值表示游记的受欢迎程度,计算方式是通过点赞、收藏、分享、回复等相关特征,作为衡量一篇文章是否受欢迎的特征属性,然后通过 logistic 回归模型训练特征权重,如下:</p>
<p><img src="/img/remote/1460000019428404" alt="" title=""></p>
<p><img src="/img/remote/1460000019428405?w=548&h=83" alt="" title=""></p>
<p>Y 表示训练的文章是否是优质,W_i 代表权重,通过模型训练得出权重的值,N 代表文章类型,vote代表点赞,Fav 代表收藏,Comment 代表评论,Share 代表分享。最后求得权重以通过权重计算 Travel 来评判一篇游记受欢迎的程度。Answer、Note 的计算方式同上。经模型训练的得出结果如下(这里为了计算方便,四舍五入取值小数点后一位):</p>
<p>游记:w1:0.1,w2:0.5,w3:0.2,w4:0.4;</p>
<p>问答:w1:0.2,w2:0.9,w3:0.3,w4:0.6;</p>
<p>笔记:w1:0.1,w2:0.5,w3:0.3,w4:0.6;</p>
<h3>3. 用户分享意愿 </h3>
<p>用户分享意愿是根据为用户打标签和 PageRank 来实现。将用户贡献内容标签作为用户兴趣的代表,然后结合实际场景,根据 PageRank 计算模型来分析话题与用户之间的关系,结合标签相似度计算向用户推荐其感兴趣、分享意愿高的内容。比如当用户贡献内容标签与当前话题的标签分类属于同一类的时候,我们可以理解为用户对当前同类标签的话题输出意愿是比较强的。如果用户还贡献过当前话题标签相类似的内容,用户的分享意愿会对应提高。如下:</p>
<p><img src="/img/remote/1460000019428406?w=158&h=80" alt="" title=""></p>
<p>D 代表用户的内容写作意愿程度,d_i 代表用户对某一类型的文章的贡献意愿(比如写作游记的意愿);</p>
<p><img src="/img/remote/1460000019428407" alt="" title=""></p>
<p>T_i 代表用户在过去时间生产的某一类型内容占用户分享的所有内容比值,其中 T_1 代表游记,T_2 代表问答,T_3 代表笔记;</p>
<p>C_i 代表用户写过的某一类型的文章其中出被评选为优质的数量,同理 C_1 为贡献优质游记的数量,C_2 为贡献优质问答数量,C_3 为贡献优质笔记数量。</p>
<p>N 代表阻尼系数,这里默认 N 值为 0.85。</p>
<p>综上,通过「用户的输出意愿 + 用户的活跃度 + 用户的受欢迎程度」,我们就可以给出相应的用户 UGC 等级,从而使用户的内容贡献能力得到客观、有效地量化。</p>
<h2>小结</h2>
<p>用户内容贡献模型充分考虑了用户等级设置中没有突出用户行为类型、时间衰减因素,以及没有充分挖掘用户兴趣的三个问题,提出了一种新的模型视角,并在马蜂窝的当前产品中充分应用。</p>
<p>未来,我们会继续优化算法,例如在模型中加入评论等多个维度的属性;在内容影响力方面加入内容画像的质量分+文章本身的得分,而不仅仅局限于优质、蜂首、采纳回答等等,来更加准确地挖掘用户内容贡献能力,完善马蜂窝用户标签体系。</p>
<p><strong>本文作者:于允飛 & 张阳</strong>,马蜂窝推荐架构 & 用户画像研发工程师。</p>
<p><em>(题图来源:网络)</em></p>
<p><em><img src="/img/remote/1460000019428408" alt="" title=""></em></p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
马蜂窝大交通业务监控报警系统架构设计与实现
https://segmentfault.com/a/1190000019353585
2019-05-31T17:14:08+08:00
2019-05-31T17:14:08+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
6
<p>部门的业务线越来越多,任何一个线上运行的应用,都可能因为各种各样的原因出现问题:比如业务层面,订单量比上周减少了,流量突然下降了;技术层面的问题,系统出现 ERROR ,接口响应变慢了。拿大交通业务来说,一个明显的特点是依赖很多供应商的服务,所以我们还需要关注调用供应商接口是否出现异常等等。</p>
<p>为了让大交通下的各业务线都能够通过报警尽早发现问题、解决问题,进而提升业务系统的服务质量,我们决定构建统一的监控报警系统。一方面在第一时间发现已经出现的系统异常,及时解决;另一方面尽早发现一些潜在的问题,比如某个系统目前来看没有影响业务逻辑的正常运转,但是一些操作耗时已经比较长等,这类问题如果不及时处理,将来就很可能影响业务的发展。</p>
<p>本文主要介绍马蜂窝大交通业务监控报警系统的定位、整体架构设计,以及我们在落地实践过程中的一些踩坑经验。</p>
<h2>架构设计与实现</h2>
<p>我们希望监控报警系统主要具备以下三个能力:</p>
<p><strong>1. 常用组件自动报警</strong>:对于各业务系统常用的框架组件(如 RPC ,HTTP 等)创建默认报警规则,来方便框架层面的统一监控。</p>
<p><strong>2. 业务自定义报警</strong>:业务指标由业务开发自定义埋点字段,来记录每个业务和系统模块的特殊运行状况。</p>
<p><strong>3. 快速定位问题</strong>:发现问题并不是目的,解决才是关键。我们希望在完成报警消息发送后,可以让开发者一目了然地发现问题出现在什么地方,从而快速解决。</p>
<p>在这样的前提下,报警中心的整体架构图和关键流程如下图所示:</p>
<p><img src="/img/remote/1460000019353588?w=482&h=301" alt="" title=""></p>
<p>纵向来看,Kafka 左侧是报警中心,右侧是业务系统。</p>
<p>报警中心的架构共分为三层,最上层是 WEB 后台管理页面,主要完成报警规则的维护和报警记录的查询;中间层是报警中心的核心;最下面一层是数据层。业务系统通过一个叫做 mes-client-starter 的 jar 包完成报警中心的接入。</p>
<p>我们可以将报警中心的工作划分为五个模块:</p>
<p><img src="/img/remote/1460000019353589" alt="" title=""></p>
<h3>1. 数据收集</h3>
<p>我们采用指标采集上报的方式来发现系统问题,就是将系统运行过程中我们关注的一些指标进行记录和上传。上传的方式可以是日志、 UDP 等等。</p>
<p>首先数据收集模块我们没有重复造轮子,可是直接基于 MES (<a href="https://link.segmentfault.com/?enc=egMyelmxQQBpksj1f4DsiA%3D%3D.eOfEeZoRHgGm7xT5O6WiiFRYPSuImYM%2BBYAQRlohGTSKKIui%2B%2Bvic7ESYbnAnO2a9MBOkm3b%2FMaUKVELXtZhxN16Hmg9sxceKVx0Vdoh35js0EdyK46iR0b8a6dow8x4tuHdUivKEpfm5vlJJm7FsTPPSw4a%2BmlqoSHAiyXJmeDjI9wb8fd39RPAcL7wyWcbKTRN75EPJ8xhH4xTHxSTq%2Bh2y3dVaAzO9VfbVYLBa%2F68hacwT9L0z0R1EFmfMeI3xjrvXJUKK%2Fbe%2B0eylhW%2FzbdMEhwOwKIxsVoI5QCQOvFH71m3aaKRMIRdA6fjgdh5" rel="nofollow">马蜂窝内部的大数据分析工具</a>)来实现,主要考虑下面几个方面的原因:一来数据分析和报警在数据来源上是相似的;二来可以节省很多开发成本;同时也方便报警的接入。</p>
<p>那具体应该采集哪些指标呢?以大交通业务场景下用户的一次下单请求为例,整个链路可能包括 HTTP 请求、Dubbo 调用、SQL 操作,中间可能还包括校验、转换、赋值等环节。一整套调用下来,会涉及到很多类和方法,我们不可能对每个类、每个方法调用都做采集,既耗时也没有意义。</p>
<p>为了以最小的成本来尽可能多地发现问题,我们选取了一些系统常用的框架组件自动打点,比如 HTTP、SQL、我们使用的 RPC 框架 Dubbo ,实现框架层面的统一监控。</p>
<p>而对于业务来说,每个业务系统关注的指标都不一样。对于不同业务开发人员需要关注的不同指标,比如支付成功订单数量等,开发人员可以通过系统提供的 API 进行手动埋点,自己定义不同业务和系统模块需要关注的指标。</p>
<h3>2. 数据存储</h3>
<p>对于采集上来的动态指标数据,我们选择使用 Elasticsearch 来存储,主要基于两点原因:</p>
<p><strong>一是动态字段存储。</strong>每个业务系统关注的指标可能都不一样,每个中间件的关注点也不同,所以埋哪些字段、每个字段的类型都无法预知,这就需要一个可以动态添加字段的数据库来存储埋点。Elasticsearch 不需要预先定义字段和类型,埋点数据插入的时候可以自动添加。</p>
<p><strong>二是能够经得起海量数据的考验</strong>。每个用户请求进过每个监控组件都会产生多条埋点,这个数据量是非常庞大的。Elasticsearch 可以支持大数据量的存储,具有良好的水平扩展性。</p>
<p>此外,Elasticsearch 还支持聚合计算,方便快速执行 count , sum , avg 等任务。</p>
<h3> 3. 报警规则</h3>
<p>有了埋点数据,下一步就需要定义一套报警规则,把我们关注的问题量化为具体的数据来进行检查,验证是否超出了预设的阈值。这是整个报警中心最复杂的问题,也最为核心。</p>
<p>之前的整体架构图中,最核心的部分就是「规则执行引擎」,它通过执行定时任务来驱动系统的运行。首先,执行引擎会去查询所有生效的规则,然后根据规则的描述到 Elasticsearch 中进行过滤和聚合计算,最后将上一步聚合计算得结果跟规则中预先设定的阈值做比较,如果满足条件则发送报警消息。</p>
<p>这个过程涉及到了几个关键的技术点:</p>
<p><strong>1). 定时任务</strong></p>
<p>为了保证系统的可用性,避免由于单点故障导致整个监控报警系统失效,我们以「分钟」为周期,设置每一分钟执行一次报警规则。这里用的是 Elastic Job 来进行分布式任务调度,方便操控任务的启动和停止。</p>
<p><strong>2). 「三段式」报警规则</strong></p>
<p>我们将报警规则的实现定义为「过滤、聚合、比较」这三个阶段。举例来说,假设这是一个服务 A 的 ERROR 埋点日志:</p>
<pre><code>app_name=B is_error=false warn_msg=aa datetime=2019-04-01 11:12:00
app_name=A is_error=false datetime=2019-04-02 12:12:00
app_name=A is_error=true error_msg=bb datetime=2019-04-02 15:12:00
app_name=A is_error=true error_msg=bb datetime=2019-04-02 16:12:09
</code></pre>
<p>报警规则定义如下:</p>
<ul>
<li>
<strong>过滤</strong>:通过若干个条件限制来圈定一个数据集。对于上面的问题,过滤条件可能是:app_name=A , is_error=true , datetime between '2019-14-02 16:12:00' and '2019-14-02 16:13:00'.</li>
<li>
<strong>聚合</strong>:通过 count,avg,sum,max 等预先定义的聚合类型对上一步的数据集进行计算,得到一个唯一的数值。对于上面的问题,我们选择 count 来计算出现 ERROR 的次数。</li>
<li>
<strong>比较</strong>:把上一步得到的结果与设定的阈值比较。</li>
</ul>
<p><strong>对于一些复杂条件的报警</strong>,比如我们上边提到的失败率和流量波动,应该如何实现呢?</p>
<p>假设有这样一个问题:如果调用的 A 服务失败率超过 80%,并且总请求量大于 100,发送报警通知。</p>
<p>我们知道,失败率其实就是失败的数量除以总数量,而失败的数量和总数量可以通过前面提到的<strong>「过滤+聚合」</strong>的方式得到,那么其实这个问题就可以通过如下的公式描述出来:</p>
<pre><code>failedCount/totalCount>0.8&&totalCount>100
</code></pre>
<p>然后我们使用表达式引擎 fast-el 对上面的表达式进行计算,得到的结果与设定的阈值比较即可。</p>
<p><strong>3) 自动创建默认报警规则</strong></p>
<p>对于常用的 Dubbo, HTTP 等,由于涉及的类和方法比较多,开发人员可以通过后台管理界面维护报警规则,报警规则会存储到 MySQL 数据库中,同时在 Redis 中缓存。</p>
<p>以 Dubbo 为例,首先通过 Dubbo 的 ApplicationModel 获取所有的 provider 和 consumer,将这些类和方法的信息与规则模板结合(规则模板可以理解为剔除掉具体类和方法信息的规则),创建出针对某个类下某个方法的规则。</p>
<p>比如:A 服务对外提供的 dubbo 接口/ order / getOrderById 每分钟平均响应时间超过 1 秒则报警;B 服务调用的 dubbo 接口/ train / grabTicket /每分钟范围 false 状态个数超过 10 个则报警等等。</p>
<h3>4. 报警行为</h3>
<p>目前在报警规则触发后主要采用两种方式来发生报警行为:</p>
<ul>
<li>
<strong>邮件报警</strong>:通过对每一类报警制定不同的负责人,使相关人员第一时间获悉系统异常。</li>
<li>
<strong>微信报警</strong>:作为邮件报警的补充。</li>
</ul>
<p>之后我们会持续完善报警行为的策略,比如针对不同等级的问题采用不同的报警方式,使开发人员既可以迅速发现报警的问题,又不过多牵扯在新功能研发上的精力。</p>
<h3> 5. 辅助定位</h3>
<p>为了能够快速帮助开发人员定位具问题,我们设计了命中抽样的功能:</p>
<p>首先,我把命中规则的 tracer_id 提取出来,提供一个链接可以直接跳转到 kibana 查看相关日志,实现链路的还原。</p>
<p>其次,开发人员也可以自己设置他要关注的字段,然后我会把这个字段对应的值也抽取出来,问题出在哪里就可以一目了然地看到。</p>
<p>技术实现上,定义一个命中抽样的字段,这个字段里面允许用户输入一个或者多个 dollar 大括号。比如我们可能关注某个供应商的接口运行情况,则命中抽样的字段可能为下图中上半部分。在需要发送报警消息的时候,提取出里面的字段,到 ES 中查询对应的值,用 freemarker 来完成替换,最终发送给开发人员的消息是如下所示,开发人员可以快速知道系统哪里出了问题。</p>
<p><img src="/img/remote/1460000019353590" alt="" title=""></p>
<h2>踩坑经验和演进方向</h2>
<p>大交通业务监控报警系统的搭建是一个从 0 到 1 的过程,在整过开发过程中,我们遇到了很多问题,比如:内存瞬间被打满、ES 越来越慢、频繁 Full GC ,下面具体讲一下针对以上几点我们的优化经验。</p>
<h3>踩过的坑</h3>
<p><strong>1. 内存瞬间被打满</strong></p>
<p>任何一个系统,都有它能承受的极限,所以都需要这么一座大坝,在洪水来的时候能够拦截下来。</p>
<p><img src="/img/remote/1460000019353591?w=234&h=223" alt="" title=""></p>
<p>报警中心也一样,报警中心对外面临最大的瓶颈点在接收 Kafka 中传过来的 MES 埋点日志。上线初期出现过一次由于业务系统异常导致瞬间大量埋点日志打到报警中心,导致系统内存打满的问题。</p>
<p>解决办法是评估每个节点的最大承受能力,做好系统保护。针对这个问题,我们采取的是限流的方式,由于 Kafka 消费消息使用的是拉取的模式,所以只需要控制好拉取的速率即可,比如使用 Guava 的 RateLimiter :</p>
<pre><code>messageHandler = (message) -> {
RateLimiter messageRateLimiter = RateLimiter.create(20000);
final double acquireTime = messageRateLimiter.acquire();
/**
save..
*/
}</code></pre>
<p><strong>2. ES 越来越慢</strong></p>
<p>由于 MES 日志量比较大,也有冷热之分,为了在保证性能的同时方便数据迁移,我们按照应用 + 月份的粒度创建 ES 索引,如下所示:</p>
<p><img src="/img/remote/1460000019353592" alt="" title=""></p>
<p><strong>3. 频繁 Full GC</strong></p>
<p>我们使用 Logback 作为日志框架,为了能够搜集到 ERROR 和 WARN 日志,自定义了一个 Appender。如果想搜集 Spring 容器启动之前(此时 TalarmLogbackAppender 还未初始化)的日志, Logback 的一个扩展 jar 包中的 DelegatingLogbackAppender 提供了一种缓存的方式,内存泄漏就出在这个缓存的地方。</p>
<p>正常情况系统启动起来之后,ApplicationContextHolder 中的 Spring 上下文不为空,会自动从缓存里面把日志取出来。但是如果因为种种原因没有初始化这个类 ApplicationContextHolder,日志会在缓存中越积越多,最终导致频繁的 Full GC。</p>
<p>解决办法:</p>
<p>1. 保证 ApplicationContextHolder 的初始化</p>
<p>2. DelegatingLogbackAppender 有三种模式:OFF SOFT ON ,如果需要打开,尽量使用 SOFT模式,这时候缓存被存储在一个由 SoftReference 包装的列表中,在系统内存不足的时候,可以被垃圾回收器回收掉。</p>
<p><img src="/img/remote/1460000019353593" alt="" title=""></p>
<h3>近期规划</h3>
<p>目前这个系统还有一些不完善的地方,也是未来的一些规划:</p>
<ul>
<li>
<strong>更易用</strong>:提供更多的使用帮助提示,帮助开发人员快速熟悉系统。</li>
<li>
<strong>更多报警维度</strong>:目前支持 HTTP,SQL, Dubbo 组件的自动报警,后续会陆续支持 MQ,Redis 定时任务等等。</li>
<li>
<strong>图形化展示</strong>:将埋点数据通过图形的方式展示出来,可以更直观地展示出系统的运行情况,同时也有助于开发人员对于系统阈值的设置。</li>
</ul>
<h2>小结 </h2>
<p>总结起来,大交通业务监控报警系统架构有以下几个特点:</p>
<ul>
<li> 支持灵活的报警规则配置,丰富的筛选逻辑</li>
<li>自动添加常用组件的报警,Dubbo、HTTP 自动接入报警</li>
<li>接入简单,接入 MES 的系统都可以快速接入使用</li>
</ul>
<p>线上生产运维主要做 3 件事:发现问题、定位问题、解决问题。发现问题,就是在系统出现异常的时候尽快通知系统负责人。定位问题和解决问题,就是能够为开发人员提供快速修复系统的必要信息,越精确越好。</p>
<p>报警系统的定位应该是线上问题解决链条中的第一步和入口手段。将其通过核心线索数据与数据回溯系统( tracer 链路等),部署发布系统等进行有机的串联,可以极大提升线上问题解决的效率,更好地为生产保驾护航。</p>
<p>不管做什么,我们最终的目标只有一个,就是提高服务的质量。</p>
<p><strong>本文作者:宋考俊,马蜂窝大交通平台高级研发工程师。</strong></p>
<p><em>(题图来源:网络)</em></p>
<p><em><img src="/img/remote/1460000019353594?w=1080&h=481" alt="" title=""></em></p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
马蜂窝ABTest多层分流系统的设计与实现
https://segmentfault.com/a/1190000019279770
2019-05-24T10:21:12+08:00
2019-05-24T10:21:12+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
34
<h2>什么是 ABTest</h2>
<p>产品的改变不是由我们随便「拍脑袋」得出,而是需要由实际的数据驱动,让用户的反馈来指导我们如何更好地改善服务。正如马蜂窝 CEO 陈罡在接受专访时所说:「有些东西是需要 Sense,但大部分东西是可以用 Science 来做判断的。」</p>
<p>说到 ABTest 相信很多读者都不陌生。简单来说,ABTest 就是将用户分成不同的组,同时在线试验产品的不同版本,通过用户反馈的真实数据来找出采用哪一个版本方案更好的过程。</p>
<p>我们将原始版本作为对照组,以每个版本进行尽量是小的流量迭代作为原则去使用 ABTest。一旦指标分析完成,用户反馈数据表现最佳的版本再去全量上线。</p>
<p><img src="/img/remote/1460000019279773?w=783&h=308" alt="" title=""></p>
<p>很多时候,一个按钮、一张图片或者一句文案的调整,可能都会带来非常明显的增长。这里分享一个ABTest 在马蜂窝的应用案例:</p>
<p><img src="/img/remote/1460000019279774?w=609&h=476" alt="" title=""></p>
<p>如图所示,之前我们交易中心的电商业务团队希望优化一个关于「滑雪」的搜索列表。可以看到优化之前的页面显示从感觉上是比较单薄的。但是大家又不确定复杂一些的展现形式会不会让用户觉得不够简洁,产生反感。因此,我们将改版前后的页面放在线上进行了 ABTest。最终的数据反馈表明,优化之后的样式 UV 提高了 15.21%,转化率提高了 11.83%。使用 ABTest 帮助我们降低了迭代的风险。</p>
<p>通过这个例子,我们可以更加直观地理解 ABTest 的几个特性:</p>
<ul>
<li>
<strong>先验性</strong>:采用流量分割与小流量测试的方式,先让线上部分小流量用户使用,来验证我们的想法,再根据数据反馈来推广到全流量,减少产品损失。</li>
<li>
<strong>并行性</strong>:我们可以同时运行两个或两个以上版本的试验同时去对比,而且保证每个版本所处的环境一致的,这样以前整个季度才能确定要不要发版的情况,现在可能只需要一周的时间,避免流程复杂和周期长的问题,节省验证时间。</li>
<li>
<strong>科学性</strong>:统计试验结果的时候,ABTest 要求用统计的指标来判断这个结果是否可行,避免我们依靠经验主义去做决策。</li>
</ul>
<p>为了让我们的验证结论更加准确、合理并且高效,我们参照 Google 的做法实现了一套算法保障机制,来严格实现流量的科学分配。</p>
<h2>基于 Openresty 的多层分流模型</h2>
<p>大部分公司的 ABTest 都是通过提供接口,由业务方获取用户数据然后调用接口的方式进行,这样会将原有的流量放大一倍,并且对业务侵入比较明显,支持场景较为单一,导致多业务方需求需要开发出很多分流系统,针对不同的场景也难以复用。</p>
<p>为了解决以上问题,我们的分流系统选择基于 Openresty 实现,通过 HTTP 或者 GRPC 协议来传递分流信息。这样一来,分流系统就工作在业务的上游,并且由于 Openresty 自带流量分发的特性不会产生二次流量。对于业务方而言,只需要提供差异化的服务即可,不会侵入到业务当中。</p>
<p>选型 Openresty 来做 ABTest 的原因主要有以下几个:</p>
<p><img src="/img/remote/1460000019279775?w=683&h=294" alt="" title=""></p>
<h3>整体流程</h3>
<p><img src="/img/remote/1460000019279776?w=701&h=402" alt="" title=""></p>
<p>在设计 ABTest 系统的时候我们拆分出来分流三要素,第一是确定的终端,终端上包含了设备和用户信息;第二是确定的 URI ;第三是与之匹配的分配策略,也就是流量如何分配。</p>
<p>首先设备发起请求,AB 网关从请求中提取设备 ID 、URI 等信息,这时终端信息和 URI 信息已经确定了。然后通过 URI 信息遍历匹配到对应的策略,请求经过分流算法找到当前匹配的 AB 实验和版本后,AB 网关会通过两种方式来通知下游。针对运行在物理 web 机的应用会在 header 中添加一个名为 abtest 的 key,里面包含命中的 AB 实验和版本信息。针对微服务应用,会将命中微服务的信息添加到 Cookie 中交由微服务网关去处理。</p>
<h3>稳定分流保障:MurmurHash算法</h3>
<p>分流算法我们采用的 MurmurHash 算法,参与算法的 Hash 因子有设备 id、策略 id、流量层 id。</p>
<p>MurmurHash 是业内 ABTest 常用的一个算法,它可以应用到很多开源项目上,比如说 Redis、Memcached、Cassandra、HBase 等。MurmurHash 有两个明显的特点:</p>
<ol>
<li>快,比安全散列算法快几十倍</li>
<li>变化足够激烈,对于相似字符串,比如说「abc」和「 abd 」能够均匀散布在哈希环上,主要是用来实现正交和互斥实验的分流</li>
</ol>
<p>下面简单解释下正交和互斥:</p>
<ul>
<li>
<strong>互斥</strong>。指两个实验流量独立,用户只能进入其中一个实验。一般是针对于同一流量层上的实验而言,比如图文混排列表实验和纯图列表实验,同一个用户在同一时刻只能看到一个实验,所以他们互斥。</li>
<li>
<strong>正交</strong>。正交是指用户进入所有的实验之间没有必然关系。比如进入实验 1 中 a 版本的用户再进行其它实验时也是均匀分布的,而不是集中在某一块区间内。</li>
</ul>
<p><strong>流量层内实验分流</strong></p>
<p>流量层内实验的 hash 因子有设备 id、流量层 id。当请求流经一个流量层时,只会命中层内一个实验,即同一个用户同一个请求每层最多只会命中一个实验。首先对 hash 因子进行 hash 操作,采用 murmurhash2 算法,可以保证 hash 因子微小变化但是结果的值变化激烈,然后对 100 求余之后+1,最终得到 1 到 100 之间的数值。</p>
<p>示意图如下:</p>
<p><img src="/img/remote/1460000019279777?w=485&h=322" alt="" title=""></p>
<p><strong>实验内版本分流</strong></p>
<p>实验的 hash 因子有设备 id、策略 id、流量层 id。采用相同的策略进行版本匹配。匹配规则如下:</p>
<p><img src="/img/remote/1460000019279778?w=521&h=334" alt="" title=""></p>
<h3>稳定性保障:多级缓存策略</h3>
<p>刚才说到,每一个请求来临之后,系统都会尝试去获取与之匹配的实验策略。实验策略是在从后台配置的,我们通过消息队列的形式,将经过配置之后的策略,同步到我们的策略池当中。</p>
<p>我们最初的方案是每一个请求来临之后,都会从 Redis 当中去读取数据,这样的话对 Redis 的稳定性要求较高,大量的请求也会对 Redis 造成比较高的压力。因此,我们引入了多级缓存机制来组成策略池。策略池总共分为三层:</p>
<p><img src="/img/remote/1460000019279779?w=1080&h=1196" alt="" title=""></p>
<p><strong>第一层 lrucache</strong>,是一个简单高效的缓存策略。它的特点是伴随着 Nginx worker 进程的生命周期存在,worker 独占,十分高效。由于独占的特性,每一份缓存都会在每个 worker 进程中存在,所以它会占用较多的内存。</p>
<p><strong>第二层 lua_shared_dic</strong>t,顾名思义,这个缓存可以跨 worker 共享。当 Nginx reload 时它的数据也会不丢失,只有当 restart 的时候才会丢失。但有个特点,为了安全读写,实现了读写锁。所以再某些极端情况下可能会存在性能问题。</p>
<p><strong>第三层 Redis。</strong></p>
<p>从整套策略上来看,虽然采用了多级缓存,但仍然存在着一定的风险,就是当 L1、L2 缓存都失效的时候(比如 Nginx restart),可能会面临因为流量太大让 Redis 「裸奔」的风险,这里我们用到 lua-resty-lock 来解决这个问题,在缓存失效时只有拿到锁的这部分请求才可以进行回源,保证了 Redis 的压力不会那么大。</p>
<p>我们在缓存 30s 的情况下对线上数据的进行统计显示,第一级缓存命中率在 99% 以上,第二级缓存命中率在 0.5 %,回源到 Redis 的请求只有 0.03 %。</p>
<h3>关键特性</h3>
<ul>
<li>
<strong>吞吐量</strong>:当前承担全站 5% 流量</li>
<li>
<strong>低延迟</strong>:线上平均延时低于 2ms</li>
<li>
<strong>全平台</strong>:支持 App、H5、WxApp、PC,跨语言</li>
<li>
<strong>容灾</strong>:</li>
<li>自动降级:当从 redis 中读取策略失败后,ab 会自动进入到不分流模式,以后每 30s 尝试 (每台机器) 读取 redis,直到读取到数据,避免频繁发送</li>
<li>请求手动降级:当出现 server_event 日志过多或系统负载过高时,通过后台「一键关闭」来关闭所有实验或关闭 AB 分流</li>
</ul>
<h3>性能表现</h3>
<p>响应时间分布</p>
<p><img src="/img/remote/1460000019279780?w=875&h=349" alt="" title=""></p>
<p>TPS 分布</p>
<p><img src="/img/remote/1460000019279781?w=897&h=356" alt="" title=""></p>
<p>测试工具采用 JMeter,并发数 100,持续 300s。 </p>
<p>从<strong>响应时间</strong>来看,除了刚开始的时候请求偏离值比较大,之后平均起来都在 1ms 以内。分析刚开始的时候差距比较大的原因在于当时的多级缓存里面没有数据。</p>
<p><strong>TPS</strong>的压测表现有一些轻微的下降,因为毕竟存在 hash 算法,但总体来说在可以接受的范围内。 </p>
<h3>A/B发布 </h3>
<p>常规 A/B 发布主要由 API 网关来做,当面临的业务需求比较复杂时, A/B 发布会通过与与微服务交互的方式,来开放更复杂维度的 A/B 发布能力。</p>
<p><img src="/img/remote/1460000019279782?w=786&h=212" alt="" title=""></p>
<h2>小结</h2>
<p>需要注意的是,ABTest 并不完全适用于所有的产品,因为 ABTest 的结果需要大量数据支撑,日流量越大的网站得出结果越准确。通常来说,我们建议在进行 A/B 测试时,能够保证每个版本的日流量在 1000 个 UV 以上,否则试验周期将会很长,或很难获得准确(结果收敛)的数据结果推论。</p>
<p>要设计好一套完整的 ABTest 平台,需要进行很多细致的工作,由于篇幅所限,本文只围绕分流算法进行了重点分享。总结看来,马蜂窝 ABTest 分流系统重点在以下几个方面取得了一些效果:</p>
<ul>
<li>采用流量拦截分发的方式,摒弃了原有接口的形式,对业务代码没有侵入,性能没有明显影响,且不会产生二次流量。</li>
<li>采用流量分层并绑定实验的策略,可以更精细直观的去定义分流实验。通过和客户端上报已命中实验版本的机制,减少了服务数据的存储并可以实现串行实验分流的功能。</li>
<li>在数据传输方面,通过在 HTTP 头部增加分流信息,业务方无需关心具体的实现语言。</li>
</ul>
<p>近期规划改善:</p>
<ul>
<li>监控体系。</li>
<li>用户画像等精细化定制AB。</li>
<li>统计功效对于置信区间、特征值等产品化功能支持。</li>
<li>通过 AARRR 模型评估实验对北极星指标的影响。</li>
</ul>
<p>这套系统未来需要改进的地方还有很多,我们也将持续探索,期待和大家一起交流。</p>
<p><strong>本文作者</strong>:<strong>李培,</strong>马蜂窝基础平台信息化研发技术专家;<strong>张立虎,</strong>马蜂窝酒店研发静态数据团队工程师。</p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p><em><img src="/img/remote/1460000019279783?w=1080&h=481" alt="" title=""></em></p>
<p>关注马蜂窝技术,找到更多你需要的内容</p>
马蜂窝推荐系统容灾缓存服务的设计与实现
https://segmentfault.com/a/1190000019235457
2019-05-20T14:36:57+08:00
2019-05-20T14:36:57+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
8
<p>数据库突然断开连接、第三方接口迟迟不返回结果、高峰期网络发生抖动...... 当程序突发异常时,我们的应用可以告诉调用方或者用户「对不起,服务器出了点问题」;或者找到更好的方式,达到提升用户体验的目的。</p>
<h2>一、背景</h2>
<p>用户在马蜂窝 App 上「刷刷刷」时,推荐系统需要持续给用户推荐可能感兴趣的内容,主要分为根据用户特性和业务场景,召回根据各种机器学习算法计算过的内容,然后对这些内容进行排序后返回给前端这几个步骤。</p>
<p>推荐的过程涉及到 MySQL 和 Redis 查询、REST 服务调用、数据处理等一系列操作。对于推荐系统来说,对时延的要求比较高。马蜂窝推荐系统对于请求的平均处理时延要求在 10ms 级别,时延的 99 线保持在 1s 以内。</p>
<p><img src="/img/remote/1460000019235460?w=2098&h=602" alt="" title=""></p>
<p>当外部或者内部系统出现异常时,推荐系统就无法在限定时间内返回数据给到前端,导致用户刷不出来新内容,影响用户体验。</p>
<p><img src="/img/remote/1460000019235461?w=2100&h=592" alt="" title=""></p>
<p>所以我们希望通过设计一套容灾缓存服务,实现在应用本身或者依赖的服务发生超时等异常情况时,可以返回缓存数据给到前端和用户,来减少空结果数量,并且保证这些数据尽可能是用户感兴趣的。</p>
<h2>二、设计与实现</h2>
<h3>设计思路和技术选型</h3>
<p>不仅仅是推荐系统,缓存技术在很多系统中已经被广泛应用,小到 JVM 中的常用整型数,大到网站用户的 session 状态。缓存的目的不尽相同,有些是为了提高效率,有些是为了备份;缓存的要求也高低不一,有些要求一致性,有些则没有要求。我们需要根据业务场景选择合适的缓存方案。</p>
<p>结合到我们上面提到的业务场景和需求,我们采用了基于 OHC 堆外缓存和 SpringBoot 的方案,实现在现有推荐系统中增加本地容灾缓存系统。主要是考虑到以下几点因素:</p>
<p><strong>1. 避免影响线上服务,将业务逻辑和缓存逻辑隔离</strong></p>
<p>为了不影响线上服务,我们将缓存系统封装为一个 CacheService,配置在现有流程的末端,并提供读、写的 API 给外部调用,将业务逻辑和缓存逻辑隔离。</p>
<p><strong>2. 异步写入缓存,提高性能</strong></p>
<p>读、写缓存都会带来时间消耗,特别是写入缓存。为了提高性能,我们考虑将写入缓存做成异步的方式。这部分使用的是 JDK 提供的线程池 ThreadPoolExecutor 来实现,主线程只需要提交任务到线程池,由线程池里的 Worker 线程实现写入缓存。</p>
<p><strong>3. 本地缓存,提高访问速度</strong></p>
<p>在推荐系统中,给用户推荐的内容应该是千人千面的,甚至同一位用户每次刷新看到的内容都可能不同,这就不要求缓存具有强一致性。因此,我们只需要进行本地缓存,而不需要采用分布式的方式。这里使用到的是开源缓存工具 OHC,缓存的数据来源于成功处理过的请求。</p>
<p><strong>4. 备份缓存实例,保证可用性</strong></p>
<p>为了保证缓存的可用性,我们不仅在内存中进行缓存,还定时备份到文件系统中,从而保证在可以应用启动时从文件系统加载到内存。具体可以使用 SpringBoot 提供的定时任务、ApplicationRunner 来实现。</p>
<h3>整体架构</h3>
<p>我们保持了推荐系统的现有逻辑,并在现有流程的末端,配置了 CacheModule 和 CacheService,负责所有和缓存相关的逻辑。</p>
<p><img src="/img/remote/1460000019235462?w=1610&h=574" alt="" title=""></p>
<p>其中,CacheService 是缓存的具体实现,提供读写接口;CacheModule 对本次请求的数据进行处理,并决定是否需要调用 CacheService 对缓存进行操作。</p>
<h3>模块解读</h3>
<p><strong>1. CacheModule</strong></p>
<p>在完成推荐系统的原有流程处理之后,CacheModule 会对得到的响应报文进行判断,比如是否抛出了异常,响应是否为空等,然后决定是否读取缓存或者提交缓存任务。</p>
<p>CacheModule 的工作流程如图所示,其中橘黄色部分代表对 CacheService 的调用:</p>
<p><img src="/img/remote/1460000019235463?w=1756&h=888" alt="" title=""></p>
<ul>
<li>
<strong>提交缓存任务</strong>。如果该次请求没有抛出异常,并且响应结果也不为空,则会提交一个缓存任务到 CacheService。任务的 key 值为对应的业务场景,value 为本次响应计算得到的内容。提交的动作是非阻塞的,对接口的耗时影响很小。</li>
<li>
<strong>读取缓存数据</strong>。当应用本身或者依赖应用抛出异常时,系统会根据业务场景的 key 值从 CacheService 中读取缓存并返回给调用方。当出现用户本身已经刷完所有可用数据的情况时,就不需要读取缓存,而是将请求的数据及时反馈给用户。</li>
</ul>
<p><strong>2. CacheService</strong></p>
<p>在缓存的具体实现上,CacheService 使用到了从 Apache Cassandra 项目中独立出来的 OHC。另外因为我们整个应用是基于 SpringBoot 的,也用到了 SpringBoot 提供的各种功能。</p>
<p>上文说到对缓存没有强一致性的要求,所以我们采用的是本地缓存而非分布式缓存,并且抽象出一个 CacheService 类负责对本地缓存进行维护。</p>
<p><strong>(1) 数据格式</strong></p>
<p>推荐系统返回数据时,根据业务场景和用户特征设定以「屏」为单位返回数据,每屏可以包含多个内容项,所以采取 key-set 的数据格式:key 值为业务场景,比如首页的「视频」频道;缓存内容则为「屏」的集合。</p>
<p><strong>(2) 存储位置</strong></p>
<p>对于 Java 应用,缓存可以存放在内存中或者硬盘文件中。而内存空间又分为 heap(堆内存)和 off-heap(堆外内存)。我们对这几种方式进行了对比:</p>
<p><img src="/img/remote/1460000019235464" alt="" title=""></p>
<p>为了保证较快的读写速度,避免缓存 GC 影响线上服务,所以选择 off-heap 作为缓存空间。OHC 最早包含在 Apache Cassandra 项目中,之后独立出来,成为了基于 off-heap 的开源缓存工具。它既可以维护大量的 off-heap 内存空间,同时也使用于低开销的小型缓存实体。所以我们使用 OHC 作为 off-heap 的缓存实现。</p>
<p><strong>(3) 文件备份</strong></p>
<p>在应用重启时,off-heap 中的缓存为空。为了尽快载入缓存,我们使用 SpringBoot 的 Scheduling Tasks 功能,定期将缓存从 off-heap 备份到文件系统;通过继承 SpringBoot 的 ApplicationRunner 监听应用启动的过程,启动完成后将硬盘中的备份文件加载到 off-heap,保证缓存数据的可用性。</p>
<p>CacheService 维护一个任务队列,队列中保存着 CacheModule 通过非阻塞的方式提交的缓存任务,由 CacheService 决定是否要执行这些缓存任务。</p>
<p><strong>(4) 对 CacheModule 提供的 API</strong></p>
<ul>
<li>读取缓存时,传入 key 值,缓存模块随机从 set 中读取数据返回。</li>
<li>写入缓存时,将 key 和 value 封装为一个任务,提交到任务队列,由任务队列负责异步写入缓存。</li>
</ul>
<p><strong>(5) 任务队列与异步写入</strong></p>
<p>这里我们使用了 JDK 中的线程池来实现。在构造线程池时,使用 LinkedBlockingQueue 作为任务队列,可以实现快速增删元素;因为应用的 QPS 在 100 以内,所以工作线程数目固定为 1;队列写满之后,则执行 DiscardPolicy,放弃插入队列。</p>
<p><strong>(6) 缓存数量控制</strong></p>
<p>如果缓存占用内存空间过大,会影响线上应用,我们可以采用为不同的业务场景配置最大缓存数量来控制缓存数量。没有达到配置值时,将成功处理过的数据写入缓存;达到配置值时可以随机抽样覆盖原有缓存项,来保证缓存的实时性。</p>
<p>综合考虑以上各个方面,CacheService 的设计如下:</p>
<p><img src="/img/remote/1460000019235465" alt="" title=""></p>
<h3>线上表现</h3>
<p>为了验证容灾缓存的效果,我们在命中缓存时进行了埋点,并通过 Kibana 查看每小时缓存的命中数量。如图所示,在 18:00 到 19:00 系统存在一定的超时,而这段时间由于缓存服务发挥了作用,使系统的可用性得到提升。</p>
<p><img src="/img/remote/1460000019235466" alt="" title=""></p>
<p>我们还对 OHC 的读取和写入速度进行了监控。写入缓存的时延在毫秒级别,并且是异步写入;读取缓存的时延在微秒级别。基本没有给系统增加额外的时间消耗。</p>
<p><img src="/img/remote/1460000019235467" alt="" title=""></p>
<h3>踩过的坑</h3>
<p>在将缓存写入 OHC 之前,需要进行序列化,我们使用了开源的 kryo 作为序列化工具。之前在使用 kyro 时,发现对于没有实现 Serializable 的类,反序列化时可能失败,比如使用 List#subList 方法返回的内部类 java.util.ArrayList$SubList。这里可以手动注册 Serializer 来解决这个问题,在 Github 上开源的 kryo-serializers 仓库提供了各种类型的 serializers。</p>
<p>另外一点,需要注意根据具体使用场景,来配置 OHC 中的 capacity 和 maxEntrySize。如果配置的值太小的话,会导致写入缓存失败。可以在上线之前测算缓存的空间占用,合理设置整个缓存空间的大小和每个缓存 entry 的大小。</p>
<h2>三、优化方向</h2>
<p>基于 SpringBoot 和 OHC,我们在现有的推荐系统中增加了一个本地容灾缓存系统,当依赖服务或者应用本身突发异常时可以返回缓存的数据。</p>
<p>该缓存系统还存在一些不足,我们近期会针对以下几点进行重点优化:</p>
<ul>
<li>缓存数目写满之后,目前应用会随机覆写已经存在的缓存。未来可以进行优化,将最老的缓存项替换。</li>
<li>在某些场景下缓存的粒度不够精细,比如目的地页推荐共用一个缓存的 key 值。未来可以根据目的地的 ID,为每个目的地配置一份缓存。</li>
<li>现在推荐系统还有部分配置依赖于 MySQL,未来会考虑将在本地进行文件缓存。</li>
</ul>
<p>[参考资料]</p>
<p><a href="https://link.segmentfault.com/?enc=WmywhIfw2B3MKLLr6uf8%2BA%3D%3D.ouTlSpyLm%2F5phh9ZYLX6mKbu91MwI%2BByRODL0lapc8yN1ppin7Dqgt%2BjmwmZ1631xosT1UQj%2FORN7gxzJ%2B2Vu9jUGOL8N03nzIzDBgHqd2U%3D" rel="nofollow">1. Java Caching Benchmarks 2016 - Part 1</a></p>
<p><a href="https://link.segmentfault.com/?enc=Xz%2B3WCCXlaF244%2BhtbEAWg%3D%3D.3Ddw8adg1RqEKoUKkEP8eE06aQwZGsnsSJt18nn42Z0Trt3NldtrOWmHGXxj%2B5Wjkss%2Fg45iK0O53GeAhtw6dw%3D%3D" rel="nofollow">2. On Heap vs Off Heap Memory Usage</a></p>
<p><a href="https://link.segmentfault.com/?enc=rqdkp0dXnLIpLzqq2kXzlQ%3D%3D.0NCwDpt0rjH6r%2B9PtxWto3QU5MOrCcpqSI52eoZPa0I%3D" rel="nofollow">3. OHC - An off-heap-cache</a></p>
<p><a href="https://link.segmentfault.com/?enc=mO7pWvmE6OfROr1cfCam%2FA%3D%3D.POsZfMVcW0AcFR95lU3oeTC3LxBd4eWRHOvU%2FPkNEC1kY60Fe0r0KdFL5C9kkvW0" rel="nofollow">4. kryo-serializers</a></p>
<p><a href="https://link.segmentfault.com/?enc=mfQQVIuq7bw3NEF0Fkq6CQ%3D%3D.cn33BvN841ADn0xtD93LYMtaY%2BY8hyoFyjtVP96T%2B07DSbcHRBuKqbuRT8EPBCSK" rel="nofollow">5. scheduling-tasks</a></p>
<p><strong>本文作者:孙兴斌,马蜂窝推荐和搜索后端研发工程师。</strong></p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p><em><img src="/img/remote/1460000019136542?w=1080&h=481" alt="" title=""></em><br>关注马蜂窝技术公众号,找到更多你需要的内容</p>
马蜂窝 iOS App 启动治理:回归用户体验
https://segmentfault.com/a/1190000019136535
2019-05-10T14:07:03+08:00
2019-05-10T14:07:03+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
25
<p>增长、活跃、留存是移动 App 的常见核心指标,直接反映一款 App 甚至一个互联网公司运行的健康程度和发展动能。启动流程的体验决定了用户的第一印象,在一定程度上影响了用户活跃度和留存率。因此,确保启动流程的良好体验至关重要。</p>
<p>「马蜂窝旅游」App 是马蜂窝为用户提供服务的主要阵地,其承载的业务模块不断丰富和完善,产品功能日趋复杂,已经逐渐成长为一个集合旅行信息、出行决策、自由行产品及服务交易的一站式移动平台。</p>
<p>「马蜂窝旅游」iOS App 历经几十个版本的开发迭代,在启动流程上积累了一定的技术债务。为了带给用户更流畅的使用体验,我们团队实施了数月的专项治理,也总结出一些 iOS 启动治理方面的实践经验,借由本文和大家分享。</p>
<h2>0X0 如何定义「启动」</h2>
<p>要分析和解决启动问题,我们首先需要界定启动的内涵和边界,从哪开始、到哪结束,中间经历了哪些阶段和过程。以不同视角去观察时,可以得出不同结论。</p>
<h3>技术视角</h3>
<p>App 启动原本就是程序启动的技术过程。作为开发人员,我们很自然地更愿意从技术阶段去看待和定义启动的流程。</p>
<p>App 启动的方式分为<strong>冷启动</strong>和<strong>热启动</strong>两种。简单来说,冷启动发生时后台是没有这个应用的进程的,程序需要从头开始,经过漫长的准备和加载过程,最终运行起来。而热启动则是在后台已有该应用进程的情况下发生的,系统不需要重新创建和初始化。因此,从技术视角讨论启动治理时,主要针对冷启动。</p>
<p>从技术视角出发,分析 iOS 的启动过程,主要分为两个阶段:</p>
<ul>
<li>pre-main: main() 函数是程序执行入口,从进程创建到进入 main 函数称为 premain 阶段, 主要包括了环境准备、资源加载等操作;</li>
<li>post-main: main() 函数到-didFinishLaunchWithOptions:方法执行结束。该阶段已获得代码执行控制权,是我们治理的主要部分。</li>
</ul>
<pre><code><premain> <postmain>
+----------------X------------------------------------X--------->
start main -didFinishLaunchWithOptions:
</code></pre>
<h3>用户视角</h3>
<p>iOS App 是面向终端用户的产品,因此衡量启动的最终标准还是要从用户视角出发。</p>
<p>从用户视角定义启动,主要以用户主观视觉为依据,以页面流程为标准。这样看来,常见的 App 启动可以分为三个阶段:</p>
<p><img src="/img/remote/1460000019136538" alt="" title=""></p>
<p><strong>T1:闪屏页</strong></p>
<ul>
<li>闪屏页是启动过程中的静态展示页。在冷启动的过程中,App 还没有运行起来,需要经历环境准备和初始化的过程。这个过渡阶段需要展示一些视图,供阻塞等待中的用户浏览。</li>
<li>iOS 系统 (SpringBoard) 根据 App Bundle 目录下的 Info.plist 中"Launch screen interface file base name"字段的值,找到所指定的 xib 文件,加载渲染展示该视图。</li>
<li>闪屏页的展示是系统行为,因此无法控制;加载的是 xib 描述文件,无法定制动态展示逻辑,因此是静态展示。</li>
<li>对应技术启动阶段的 pre-main 阶段</li>
</ul>
<p><strong>T2(可选):欢迎页(广告)</strong></p>
<ul>
<li>App 运行后根据特定的业务逻辑展示的第一个页面。常见的有广告页和装机引导流程。</li>
<li>欢迎页是业务定制的,因此可根据业务需要优化展示策略,该阶段本身也是可选的。</li>
</ul>
<p><strong>T3:目标页 (落地页) </strong></p>
<ul>
<li>App 启动的目标页。</li>
<li>可以是首页或特定的落地页</li>
<li>目标页的加载渲染渲染完成标志着 T3 阶段的结束,也标志着启动流程的结束。</li>
</ul>
<p>启动治理的最终目标是提升用户体验,在这样的思想下,本文关于启动流程的讨论主要围绕用户视角进行。</p>
<h2>0X1 方法论及关键指标</h2>
<h3>APM 方法论</h3>
<p>对 iOS 启动的治理,本质上是对应用性能优化 (App Performance Management) 的过程,其基本的方法论可以归纳为:</p>
<p><strong>界定问题</strong></p>
<ul>
<li>准确描述现象,确定问题的边界</li>
<li>确定量化评价手段,明确关键指标</li>
</ul>
<p><strong>分析问题</strong></p>
<ul>
<li>分析问题产生的主要原因,根本原因</li>
<li>确定问题的重要性,优先级</li>
<li>性能问题可能是单点的短板,也可能是复杂的系统性问题,切忌「头痛医头,脚痛医脚」。要严谨全面地分析问题,找到主要原因、根本原因予以优先解决</li>
</ul>
<p><strong>解决问题</strong></p>
<ul>
<li>确定解题的具体技术方案</li>
<li>根据关键指标量化成果</li>
<li>对问题进行总结,积累沉淀</li>
</ul>
<p><strong>持续监控</strong></p>
<ul>
<li>性能问题是持续的,长期的</li>
<li>对关键技术指标建立长效的监控机制,确保增量能被及时反馈,予以处理</li>
</ul>
<h3>关键指标</h3>
<p><strong>1. 启动耗时</strong></p>
<p>启动耗时是衡量启动性能的核心指标,因为它直接影响了用户体验并对用户转化率产生影响。</p>
<p>对启动耗时指标的拆解有助于细粒度地监控启动过程,帮助找到问题环节。具体可以拆解为:</p>
<ul>
<li>
<p><strong>技术启动耗时指标</strong></p>
<ul>
<li>pre-main</li>
<li>core-postmain</li>
</ul>
</li>
<li>
<p><strong>主观启动耗时指标</strong></p>
<ul>
<li>T1_duration :从程序运行起点到主视窗可见</li>
<li>T2_duration</li>
<li>T3_duration</li>
<li>total_duration</li>
</ul>
</li>
</ul>
<p>根据对马蜂窝 App 用户的行为数据分析确认,我们得到以下结论:</p>
<ul>
<li>启动耗时和启动流失率正相关</li>
<li>启动耗时和次日留存负相关</li>
</ul>
<p><strong>2.启动流失率</strong></p>
<p><strong>1). 如何定义启动流失</strong></p>
<p>用户视角的启动流程完成前(即目标页渲染完成前),用户主动离开 App(进入后台,杀死 App, 切换到其他 App 等),记做<strong>一次启动流失</strong>。</p>
<p>启动流失率计算公式为:</p>
<ul>
<li>启动 PV 流失率:启动流失 PV / App 首次进入前台 PV</li>
<li>启动 UV 流失率:启动流失 UV / DAU</li>
<li>UV 绝对流失率:当日仅进入前台一次且流失的 UV / DAU</li>
</ul>
<p><strong>2) 如何定义首次进入前台</strong></p>
<p>我们先来区分下<strong>冷启动,热启动和首次进入前台</strong>的概念:</p>
<p>iOS App 有后台机制,App 可在某些条件下,在用户不感知的情况下在后台启动(如后台刷新)。由于用户不感知,如果当日该用户没有主动进入前台,则不会记作活跃用户。因此,单纯的后台启动不是启动流失率的分母。</p>
<p>但是当 iOS App 从后台启动,并留在内存中没有被操作系统清除,而一段时间后,用户触发 App 进入前台,这种情况虽然是热启动,但应被看作「首次进入前台」。</p>
<p><strong>3) 如何定位流失的时机</strong></p>
<p>根据定义,用户主动离开 App 则记作一次流失。从技术角度可以找到两个点:</p>
<ul>
<li>applicationdidEnterBackground</li>
<li>applicaitonWillTerminate</li>
</ul>
<p>但在实践的典型场景中我们发现,从用户点击 Home 键到程序接收到-applicationdidEnterBackground 回调存在一定的时间差,该时间差会影响到流失率的判断。</p>
<p>例如,用户在时刻 0.0s 启动 app,启动总时长为 4.0s。用户在时刻 3.8s 点击了 home 键离开 App,则应该记作 launch_leave = true。而程序在时刻 4.3s 接收到了-applicationDidEnterBackground 回调,此时启动已经结束,获得了启动耗时 4.0s。通过比较 Tleave > Tlaunch_total,则错误地记为 launch_leave = false。</p>
<p>由此推测,这里的 delay 是设置灵敏度阻尼,消除用户决策的摆动。这个延时大约在 0.5s 左右。</p>
<p>为了避免这个误差,我们的解决方案是利用 inactive 状态,找到准确的用户决策起点:</p>
<ul>
<li>用户即将离开前台时,会先进入 inactive 状态,通过-appWillResignActive:拿到决策起点的时间戳 Tdetermine</li>
<li>根据用户最终决策行为,是否确实离开,再决定决策 Tdetermine 是否有效</li>
<li>最终根据有效的 Tdetermine 作为判断流失行为的标准,而不是-applicationdidEnterBackground 的时间点</li>
</ul>
<p><strong>3. 启动广告曝光率</strong></p>
<p>广告是 App 盈利的主要手段之一。广告曝光率直接决定了广告点击消费率;而广告曝光 PV 和加载 PV 直接影响了广告售价。</p>
<p>我们定义:启动广告曝光率 = 启动广告曝光 PV / 启动广告加载 PV。</p>
<p>其中广告素材需要下载,素材渲染需要一定耗时,这些都会对广告曝光率产生影响。进一步来说,启动广告的曝光率会受到 App 启动性能的影响,但更主要的是受缓存和曝光策略的影响,详细阐述在下文「精细化策略」部分介绍。</p>
<h2>0X2 iOS App 启动优化</h2>
<p>以上,我们对 iOS App 启动治理的思路和关键指标进行了分析和拆解,下面来说一下从技术层面和业务层面,我们对启动性能的优化和流程治理分别做了哪些事情。</p>
<h3> 一、技术启动优化</h3>
<p>1. <strong>优化pre-main</strong></p>
<p><strong>1). pre-main 主要流程分析</strong></p>
<p>在进行该阶段的优化前,我们需要对 Pre-Main 阶段的过程有所了解,网上的文章较多,这里主要推荐两篇 WWDC 参考文章:</p>
<ul>
<li>App Startup Time: Past, Present, and Future(<a href="https://link.segmentfault.com/?enc=YdBBBrXTgm0NPahDXvgocQ%3D%3D.kf%2B7Qfq6Sc44JQ6DR55KcjimtYA8Xc7UWJCN83yXmphGPtlBjK6GawqFrPEBNuxd5nXF1ZCjEX3d0KmrsQHZVw%3D%3D" rel="nofollow">https://developer.apple.com/v...</a>)</li>
<li>Optimizing App Startup Time(<a href="https://link.segmentfault.com/?enc=teE%2B6hLXDgy5y%2Fh7q8wh1w%3D%3D.lJKRye%2FylorLau2sF8D7Yq%2BdqTaK86Wzc5Z7%2BQLTtIK1Zf6CksGhx8TY7wDJMvvkrhqsZCVLCsq079DEjDv8jQ%3D%3D" rel="nofollow">https://developer.apple.com/v...</a>)</li>
</ul>
<p>总结来看,pre-main 主要流程包括:</p>
<p> 1. fork 进程</p>
<p> 2. 加载 executable</p>
<p> 3. 加载 DYLD</p>
<p> 4. 分析依赖,迭代加载动态库</p>
<p> a. rebase</p>
<p> b. rebind</p>
<p> c. 耗时多</p>
<p> 5. 准备环境</p>
<p> a. 准备 OC 运行时</p>
<p> b. 准备 C++环境</p>
<p> 6. main 函数</p>
<p><strong>2). 优化建议</strong></p>
<ul><li>尽量少使用动态库</li></ul>
<p> a. 尽量编译到静态库中,减少 rebase,rebind 耗时</p>
<p> b.尽量合并动态库,减轻依赖关系</p>
<ul>
<li>控制 Class 类的数量规模</li>
<li>由于 selector 需要在初始化时做唯一性检查,应尽量减少使用</li>
<li>少用 initializers </li>
</ul>
<p> a. 严格控制 +load 方法使用</p>
<ul><li>多用 Swift </li></ul>
<p> a. Swift 没有运行时</p>
<p> b. Swift 没有 initializers</p>
<p> c. Swift 没有数据不对齐问题</p>
<p><strong>3). 性能监控:如何获取启动起点</strong></p>
<p>启动的结束时间相对来说是比较好确定的,但如何定位启动的起点,是启动监控的一个难点。</p>
<p>对于开发环境,可以通过 Xcode 配置启动参数,获得 pre-main 的启动报告:</p>
<pre><code>DYLD_PRINT_STATICS = 1
</code></pre>
<p>对于线上环境,根据 premain 主要流程的分析,我们的解决方案是:</p>
<ol>
<li>创建动态库 ABootMonitor.dylib</li>
<li>ABootMonitor.dylib 实现+load 方法,记录启动起点时间</li>
<li>将 ABootMonitor.dylib 放在 executable 动态库依赖的头部</li>
</ol>
<p>通过上述方法,可以在线上环境尽量地模拟出最早的启动时间点,从而更好地监测优化效果。</p>
<p><strong>2. 优化post-main</strong></p>
<p>post-main 阶段的技术优化主要针对两个方法的执行耗时来进行:</p>
<ol>
<li>- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:</li>
<li>- (void)applicationDidBecomeActive:(UIApplication *)application;</li>
</ol>
<p>为什么包含 2,需要我们对 iOS App 生命周期有一定理解。从操作系统的视角来看,iOS App 本质上是一个进程。对于 Mac OS/iOS 系统,进程的生命周期状态包括了:</p>
<ul>
<li>not-running</li>
<li>
<p>running </p>
<ul><li>进程激活,可以运行的状态</li></ul>
</li>
<li>
<p>suspend </p>
<ul><li>进程被挂起,不可以执行代码,通常在 UIApplication 进入后台后一段时间被系统挂起</li></ul>
</li>
<li>
<p>zombie </p>
<ul><li>进程回收前的临时状态,很短暂</li></ul>
</li>
<li>
<p>terminated </p>
<ul><li>进程终止,并被清理</li></ul>
</li>
</ul>
<p>而对于 UIApplication,定义了生命周期状态:</p>
<pre><code>// UIApplication.h
typedef NS_ENUM(NSInteger, UIApplicationState) {
UIApplicationStateActive, // 前台, UIApplication响应事件
UIApplicationStateInactive, // 前台, UIApplication不响应事件
UIApplicationStateBackground // 后台, UIApplication不在屏幕上显示
} NS_ENUM_AVAILABLE_IOS(4_0);
</code></pre>
<p>组合起来的状态机如下图:</p>
<p><img src="/img/remote/1460000019136539" alt="" title=""></p>
<p>通过上面的讨论,我们可以分析出以下问题:</p>
<ul>
<li>UIApplication 会因为某种原因,在用户不感知的情况下被唤起,进程进入 running 状态,但停留在 iOS 的 background 状态</li>
<li>每次冷启动都会执行- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:,但未必进入前台</li>
<li>在 didFinishLaunchingWithOptions 中进行大量 UI 和网络请求等操作是不合理</li>
</ul>
<p><strong>post-main 优化思路和建议</strong></p>
<ul>
<li>整理拆分启动项,以启动项为粒度进行测量</li>
<li>
<p>启动项执行尽量在背景线程</p>
<ul><li>启动的过程 CPU 占用较高,占用主线程会导致卡顿,耗时延长,用户体验不佳</li></ul>
</li>
<li>启动项并发执行</li>
<li>
<p>启动项延迟执行</p>
<ul>
<li>当 CPU 时间片跑满时,使用多线程并发不能提高性能,反而会因为频繁的线程上下文切换,造成 overhead 耗时增长</li>
<li>尽可能将启动项延迟执行,在时间轴上平滑,降低 CPU 利用率峰值</li>
</ul>
</li>
<li>
<p>启动项分组</p>
<ul>
<li>-didFinishLaunchingWithOptions 只执行必要的核心启动项</li>
<li>其他启动项,在首次调用-applicationDidBecomeActive:后执行</li>
</ul>
</li>
</ul>
<h3>二、精细化策略</h3>
<p><strong>1. 交互优化</strong></p>
<p>通过技术的实现手段,我们可以从客观上减少启动的绝对耗时。而从用户视角来看,对于启动是否流畅会受到很多心理因素的主观影响。因此从另一方面,我们可以从优化交互的角度提升用户体验。</p>
<p><strong>避免阻塞等待</strong></p>
<p>我们都希望用户可以尽快地使用 App,不要出现流失。但在快消费的时代,用户的耐心是极其有限的。</p>
<p>因此,如果有理由需要用户进行等待,就应该注意尽量避免产品流程是阻塞的。即使有更充足的理由必须让用户在阻塞状态原地等待,也应该给用户提供可响应的交互。</p>
<p>例如,在 T2 欢迎/广告页阶段,为了避免用户阻塞等待,应该提供明显的「跳过」按钮,允许用户进行跳过操作。</p>
<p>如果非要用户在这个阶段等待不可,也可以花一些小心思提供可响应的交互,比如点击触发视觉的变化等,不要让用户除了等待无事可做。</p>
<p><strong>增加视觉信息量</strong></p>
<p>增加屏幕上视图的信息量提供给用户消费,转移其注意力,降低用户对等待的感受。</p>
<p>例如,在 T1 闪屏页阶段,用户处于阻塞等待的状态,无法跳过。而且闪屏页是系统渲染的静态视图,我们无法提供动态响应。那么,我们可以通过在静态视图上提供更多信息量,给等待中的用户消费。</p>
<p>主观感受对比如下图:</p>
<p><img src="/img/remote/1460000019136540" alt="" title=""></p>
<p><strong>合理的动态提示</strong></p>
<ul><li><strong>合适的动画</strong></li></ul>
<p>事实上,早期在部分高性能 Android 设备上,App 的启动比同水平 iDevice 要快。但由于 iOS 设计了符合神经认知学的交互动画,使得主观感受到的时间缩短。</p>
<p>动画是否「合适」,关键在于对场景的选择和数量的把握。一个常见的动画耗时约为 0.25s,对于启动流程来说,已经可以解决或掩盖不少问题了。</p>
<ul><li><strong>合适的提示信息</strong></li></ul>
<p>好的交互体验和产品流程,至少应该是符合用户预期的。给以合适的动态提示,让用户知道此刻使用的 App 正在发生什么,可以极大地提升用户体验。</p>
<p>例如在 T2 广告页阶段,广告需要占时 3 秒钟的时间。交互上建议给与广告消失的倒计时提示:</p>
<ul>
<li>一方面,倒计时提示可以有动态 loading 的视觉效果,展现 App 的良好运行;</li>
<li>另一方面,倒计时可以让用户安心,主观上耗时减少,情绪上不至于焦虑和退出。</li>
</ul>
<p><strong>2. 基于场景的启动会话</strong></p>
<p>根据对启动过程的定义,我们可以列举出一些启动的「起点」和「终点」,比如:</p>
<p><strong>启动触发点:</strong></p>
<ul>
<li>点击 App 图标正常启动</li>
<li>初次安装</li>
<li>点击 PUSH 进入</li>
<li>应用间跳转</li>
<li>3DTouch</li>
<li>Siri 唤起</li>
<li>其他</li>
</ul>
<p><strong>启动终点--目标页:</strong></p>
<ul>
<li>应用首页</li>
<li>指定的落地页</li>
</ul>
<p>可以看出,启动的起点和终点多种多样,而对于启动流程的设定,很多都是和业务场景强相关的,比如:</p>
<ul>
<li>初次安装需要进入装机引导流程</li>
<li>正常启动需要展示广告</li>
<li>PUSH 进入可以不展示广告,直达落地页</li>
<li>其他</li>
</ul>
<p>如何才能维护这些复杂的启动关系,提高业务承载能力呢?我们的优化思路是基于场景创建启动会话:</p>
<ul>
<li>由启动参数和其他条件确定启动场景</li>
<li>根据启动场景创建具体的启动会话</li>
<li>启动会话接管之后的启动流程</li>
</ul>
<p><strong>3. 启动广告曝光和缓存策略</strong></p>
<p>广告曝光主要流程为:<strong>请求广告接口 —> 准备广告素材 —> 展示广告页,进行曝光。</strong></p>
<p>在准备广告素材环节,我们会判断广告素材是否命中缓存。如果命中则直接使用缓存,这样可以明显缩短广告加载的时间。如果没有命中,则开始下载广告素材。当广告素材超过设定的准备时长,则此次曝光不显示。</p>
<p>通过以往数据量化分析,我们发现通常情况下,广告未曝光的主要原因是由于广告素材准备超时,且素材体积和广告曝光率是负相关的。为了保证广告的曝光率,我们应该尽量减少广告素材的体积,并且提高广告素材缓存的命中率。</p>
<p>下面分别介绍下我们的启动广告预缓存策略和启动广告曝光策略。</p>
<p><strong>启动广告预缓存策略</strong></p>
<ul>
<li>广告素材接口和广告曝光接口分离</li>
<li>
<p>在可能的合适时机,下载广告素材</p>
<ul><li>例如后台启动,后台刷新等</li></ul>
</li>
<li>
<p>尽可能地提前下发广告素材</p>
<ul>
<li>拉长广告素材投放的时间窗口</li>
<li>常见地可提前半月下发广告素材</li>
<li>对于「双十一等大促活动,应尽早地下发素材</li>
</ul>
</li>
</ul>
<p><strong>启动广告曝光策略</strong></p>
<ul>
<li>
<p><strong>分级的广告曝光QoS策略</strong></p>
<ul>
<li>
<strong></strong>若业务许可,可对广告优先级进行分级</li>
<li>对于低优先级,应用 cache-only 的曝光策略</li>
<li>对于普通优先级,应用 max-wait 的曝光策略</li>
<li>对于高优先级,应用 max-retry 的曝光策略</li>
</ul>
</li>
<li>
<p><strong>灵活的曝光时机选择</strong></p>
<ul>
<li>
<p>通常我们仅在首次进入前台时,进行广告曝光,但这有一定的缺陷:</p>
<ul>
<li>启动耗时长了,用户体验差,启动流失率高</li>
<li>对于当日只有一次启动且启动流失的用户,丢了这个 DAU</li>
</ul>
</li>
<li>
<p>我们可以在 App 首次进入前台,和热启动切回前台时选择时机,进行有策略的曝光</p>
<ul>
<li>可依据策略,在首启时不展示广告页,提升用户体验,DAU,减少启动流失</li>
<li>
<p>可在 App 切回时展示,提升广告曝光 PV,和曝光率。</p>
<ul>
<li>由于 App 之前已经启动,此时大概率已经缓存了广告素材</li>
<li>由于 App 一次生命周期存在多次切回前台,曝光 PV 可以得到提升</li>
</ul>
</li>
</ul>
</li>
<li>根据马蜂窝 App 的统计分析,在激进策略下可提升曝光 PV 约 4 倍</li>
</ul>
</li>
</ul>
<h3>三、合理利用平台机制</h3>
<p>iOS 经过多年的迭代,提供了很多智能的平台机制。合理利用这些机制,可以强化 App 的功能和性能。</p>
<p><strong>1. 内存保活</strong></p>
<p>我们已经讨论了冷启动和热启动的区别:</p>
<ul>
<li>冷启动是进程并不存在的状态,一切需要从 0 开始。</li>
<li>热启动是指进程在内存中(iOS 不支持 SWAP),此时可能处于 background 的 running 状态或 suspend 状态,用户唤起进去前台。</li>
<li>热启动可以极大地减少 T1 闪屏页时间,从而减少启动耗时。</li>
</ul>
<p>因此,我们应该尽量增加热启动概率,并且尽量减少 App 在后台被系统回收的概率。</p>
<p>iOS App 生命周期中关于系统内回收策略如下:</p>
<ul>
<li>App 进入后台后,进程会活跃一段时间后,会被操作系统挂起,进入 suspend 状态。除非在 info.plist 指定进入后台即退出。</li>
<li>
<p>前台运行的 App 拥有内存的优先使用权</p>
<ul>
<li>当前台的 App 需要更多物理内存时,系统根据一定策略,将一部分挂起的 App 进行释放</li>
<li>系统优先选择占用内存多的 App 进行释放</li>
</ul>
</li>
</ul>
<p><strong>优化思路:</strong></p>
<ul>
<li>
<p>App 进入后台时,应该将内存资源竟可能的释放,尽量在内存中保活</p>
<ul>
<li>尤其对于可重得的图片,文件等资源进行释放</li>
<li>对于可持久化的非重要内存,也可做持久化后释放</li>
</ul>
</li>
<li>对于线上,应利用后台进程激活状态,加强对后台内存使用的监控</li>
</ul>
<p><strong>2. 后台拉起</strong></p>
<p>iOS 系统提供了一些机制,可以帮助我们实现在用户不感知的情况下拉起 App。合适的拉起策略,可以优化 App 性能和功能表现,比如提升当日首启热启动的概率;在后台准备更新一些数据,如更新 PUSH token、准备启动广告素材等。</p>
<p>iOS 常见的后台拉起机制包括:</p>
<ul>
<li>
<p>Background-fetch 后台刷新</p>
<ul>
<li>需要权限</li>
<li>在某特定时机拉起,智能策略</li>
</ul>
</li>
<li>
<p>PUSH </p>
<ul>
<li>静默推送</li>
<li>
<p>远端推送</p>
<ul>
<li>aps 中指定 "content-available = 1"</li>
<li>App 实现相关处理方法</li>
</ul>
</li>
</ul>
</li>
<li>地理围栏</li>
<li>后台网络任务 NSURLBackgroundSession</li>
<li>VOIP 等其他</li>
</ul>
<p>使用后台机制时,有以下几点需要注意:</p>
<ul>
<li>常见的后台机制需要 entitlement 声明和用户授权</li>
<li>部分节能模式会使部分拉起机制失效,导致节能量模式不可用</li>
<li>
<p>拉起策略参考用户意图,用户主动杀死 App,会使部分拉起机制失效</p>
<ul>
<li>正常进入后台,该 App 会向系统应用「AppSwitcher」注册,并受其管理</li>
<li>如果用户主动杀死 App,该 App 不会向「AppSwitcher」注册</li>
<li>后台拉起时,主要从 AppSwitcher 的注册列表选择 App 进行操作。例如,后台刷新会根据某种策略排序,依此拉起 AppSwitcher 中注册的部分 App</li>
</ul>
</li>
<li>
<p>批量拉起会导致服务端接口压力过大</p>
<ul><li>例如使用 PUSH 拉起,则短时间内可能有数千万的 App 被拉起,此时接口请求不亚于一次针对服务端的 DDOS 攻击,需要整理和优化</li></ul>
</li>
</ul>
<h3>四、结构化定制</h3>
<p><strong>页面栈/树优化</strong></p>
<p>App 通过页面进行组织,在启动过程中,我们需要构建根页面栈。</p>
<p>由上分析我们知道,App 存在后台拉起,我们建议在首次进入前台时才进行页面渲染操作。但另一方面,根页面栈是 App 的基本结构,应该作为核心启动流程。因此我们提出以下解决方案:</p>
<ul>
<li>涉及启动的页面,如首页、落地页等,应将页面栈创建、数据请求、页面渲染分离</li>
<li>在核心启动流程 (didFinishLaunch) 创建核心页面栈</li>
<li>在即将进入前台时,异步请求数据</li>
<li>
<p>在目标页即将展示时,进行渲染</p>
<ul>
<li>例如,在广告页消失前的 1s,通知首页进行渲染,如下图</li>
<li>由于目标页可能和 T2 等启动阶段重叠,应特别注意页面加载的性能问题,避免交叉影响</li>
</ul>
</li>
</ul>
<p><img src="/img/remote/1460000019136541" alt="" title=""></p>
<h2>0x3 结语</h2>
<p>经过团队 3 个月的持续优化治理,马蜂窝 iOS App 的启动优化取得了一些成果:</p>
<ul>
<li>启动耗时:约 3.6s,减少约 50%</li>
<li>PV启动流失率:降低约 30%</li>
<li>启动广告曝光率:大幅提升</li>
</ul>
<p>ios App 的启动治理乃至性能管理,是一个长期且艰巨的过程,需要各位开发同学具备良好的对平台和对代码性能的理解意识。其次,性能问题也常常是一个复杂的系统性问题,需要严谨地分析和推理,在此感谢支持以上工作的马蜂窝数据分析师。最后,这项工作需要建立完善的性能监控机制,持续跟踪,主动解决。</p>
<h2>One More Thing </h2>
<p>我们计划于近期将马蜂窝 iOS 的启动框架开源,欢迎持续关注马蜂窝公众号动态。期待和大家交流。</p>
<p><strong>本文作者:许旻昊,马蜂窝 iOS 研发技术专家。</strong></p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p><em><img src="/img/remote/1460000019136542?w=1080&h=481" alt="" title=""></em></p>
<p>关注马蜂窝技术公众号,找到更多你需要的内容</p>
马蜂窝火车票系统服务化改造初探
https://segmentfault.com/a/1190000018994674
2019-04-26T10:57:35+08:00
2019-04-26T10:57:35+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
69
<p>交通方式是用户旅行前要考虑的核心要素之一。为了帮助用户更好地完成消费决策闭环,马蜂窝上线了大交通业务。现在,用户在马蜂窝也可以完成购买机票、火车票等操作。</p>
<p>与大多数业务系统相同,我们一样经历着从无到有,再到快速发展的过程。本文将以火车票业务系统为例,主要从技术的角度,和大家分享在一个新兴业务发展的不同阶段背后,系统建设与架构演变方面的一些经验。</p>
<h2>第一阶段:从无到有</h2>
<p>在这个阶段,快速支撑起业务,填补业务空白是第一目标。基于这样的考虑,当时的火车票业务从模式上选择的是供应商代购;从技术的角度需要优先实现用户在马蜂窝 App 查询车次余票信息、购票、支付,以及取消、退票退款等核心功能的开发。</p>
<p><img src="/img/remote/1460000019022694" alt="" title=""></p>
<p><strong>图1-核心功能与流程</strong></p>
<h3>技术架构</h3>
<p>综合考虑项目目标、时间、成本、人力等因素,当时网站服务架构我们选择的是 LNMP(Linux 系统下 Nginx+MySQL+PHP)。整个系统从物理层划分为访问层 ( App,H5,PC 运营后台),接入层 (Nginx),应用层 (PHP 程序),中间件层 (MQ,ElasticSearch),存储层 (MySQL,Redis)。</p>
<p>对外部系统依赖主要包括公司内部支付、对账、订单中心等二方系统,和外部供应商系统。</p>
<p><img src="/img/remote/1460000019022695" alt="" title=""></p>
<p><strong>图 2-火车票系统 V1.0 技术架构</strong></p>
<p>如图所示,对外展现功能主要分为两大块,一块是 C 端 App 和 H5,另外是运营后台。二者分别经过外网 Nginx 和内网 Nginx 统一打到 php train 应用上。程序内部主要有四个入口,分别是:</p>
<ol>
<li>供其他二方系统调用的 facade 模块</li>
<li>运营后台调用的 admin 模块</li>
<li>处理 App 和 H5 请求的 train 核心模块</li>
<li>处理外部供应商回调模块</li>
</ol>
<p>四个入口会依赖于下层 modules 模块实现各自功能。对外调用上分两种情况,一种是调用二方系统的 facade 模块满足其公司内部依赖;一种是调用外部供应商。基础设施上依赖于搜索、消息中间件、数据库、缓存等。</p>
<p>这是典型的单体架构模式,部署简单,分层结构清晰,容易快速实现,可以满足初期产品快速迭代的要求,而且建立在公司已经比较成熟的 PHP 技术基础之上,不必过多担心稳定性和可靠性的问题。</p>
<p>该架构支撑火车票业务发展了将近一年的时间,简单、易维护的架构为火车票业务的快速发展做出了很大的贡献。然而随着业务的推进,单体架构的缺陷逐渐暴露出来:</p>
<ul>
<li>所有功能聚合在一起,代码修改和重构成本增大</li>
<li>研发团队规模逐渐扩大,一个系统多人开发协作难度增加</li>
<li>交付效率低,变动范围难以评估。在自动化测试机制不完善的情况下,易导致「修复越多,缺陷越多」的恶性循环</li>
<li>伸缩性差,只能横向扩展,无法按模块垂直扩展</li>
<li>可靠性差,一个 Bug 可能引起系统崩溃</li>
<li>阻碍技术创新,升级困难,牵一发而动全身</li>
</ul>
<p>为了解决单体架构所带来的一系列问题,我们开始尝试向微服务架构演进,并将其作为后续系统建设的方向。</p>
<h2>第二阶段:架构转变及服务化初探</h2>
<p>从 2018 年开始,整个大交通业务开始从 LNMP 架构向服务化演变。</p>
<h3>架构转变——从单体应用到服务化</h3>
<p>「工欲善其事,必先利其器」,首先简单介绍一下大交通在实施服务化过程中积累的一些核心设施和组件。</p>
<p>我们最主要的转变是将开发语言从 PHP 转为 Java,因此技术选型主要围绕 Java 生态圈来展开。</p>
<h4><strong>开发框架与组件</strong></h4>
<p><img src="/img/remote/1460000019022696" alt="" title=""></p>
<p><strong>图3-大交通基础组件</strong></p>
<p>如上图所示,整体开发框架与组件从下到上分为四层。这里主要介绍最上层大交通业务场景下的封装框架和组件层:</p>
<ul>
<li>mlang:大交通内部工具包</li>
<li>mes-client-starter:大交通 MES 技术埋点采集上报</li>
<li>dubbo-filter:对 Dubbo 调用的 tracing 追踪</li>
<li>mratelimit:API 限流保护组件</li>
<li>deploy-starter:部署流量摘除工具</li>
<li>tul:统一登录组件</li>
<li>cat-client:对 CAT 调用增强封装的统一组件</li>
</ul>
<h4><strong>基础设施体系</strong></h4>
<p>服务化的实施离不开基础设施体系的支持。在公司已有基础之上,我们陆续建设了:</p>
<ul>
<li>敏捷基础设施:基于 Kubernetes 和 Docker</li>
<li>基础设施监控告警:Zabbix,Prometheus,Grafana</li>
<li>业务告警:基于 ES 日志,MES 埋点 + TAlarm</li>
<li>日志系统 :ELK</li>
<li>CI/CD 系统:基于 Gitlab+Jekins+Docker+Kubernetes</li>
<li>配置中心:Apollo</li>
<li>服务化支撑 :Springboot2.x+Dubbo</li>
<li>服务治理:Dubbo-admin,</li>
<li>灰度控制</li>
<li>TOMPS :大交通应用管理平台</li>
<li>MPC 消息中心:基于 RocketMQ</li>
<li>定时任务:基于 Elastic-Job</li>
<li>APM 系统 :PinPoint,CAT</li>
<li>PHP 和 Java 双向互通支持</li>
</ul>
<p>如上所述,初步构筑了较为完整的 DevOps + 微服务开发体系。整体架构如下:</p>
<p><img src="/img/remote/1460000019022697?w=1080&h=772" alt="" title=""></p>
<p><strong>图4-大交通基础设施体系</strong></p>
<p>从上至下依次分为:</p>
<ul>
<li>访问层——目前有 App,H5 和微信小程序;</li>
<li>接入层——走公司公共的 Nginx,OpenResty;</li>
<li>业务层的应用——包括无线 API,Dubbo 服务,消</li>
<li>消息中心和定时任务——部署在 Kubernetes+Docker 中</li>
<li>中间件层——包括 ElasticSearch,RocketMQ 等</li>
<li>存储层——MySQL,Redis,FastDFS,HBase 等</li>
</ul>
<p>此外,外围支撑系统包括 CI/CD、服务治理与配置、APM 系统、日志系统、监控告警系统。</p>
<h4><strong>CI/CD 系统</strong></h4>
<ul>
<li>CI 基于 Sonar + Maven(依赖检查,版本检查,编译打包) + Jekins</li>
<li>CD 基于 Jekins+Docker+Kubernetes</li>
</ul>
<p>我们目前还没有放开 Prod 的 OPS 权限给开发,计划在新版 CD 系统中会逐步开放。</p>
<p><img src="/img/remote/1460000019022698?w=1080&h=610" alt="" title=""></p>
<p><strong>图5-CI/CD 体系</strong></p>
<h4><strong>服务化框架 Dubbo</strong></h4>
<p>我们选择 Dubbo 作为分布式微服务框架,主要有以下因素考虑:</p>
<ol>
<li>成熟的高性能分布式框架。目前很多公司都在使用,已经经受住各方面性能考验,比较稳定;</li>
<li>可以和 Spring 框架无缝集成。我们的架构正是基于 Spring 搭建,并且接入 Dubbo 时可以做到代码无侵入,接入也非常方便;</li>
<li>具备服务注册、发现、路由、负载均衡、服务降级、权重调节等能力;</li>
<li>代码开源。可以根据需求进行个性化定制,扩展功能,进行自研发</li>
</ol>
<p><img src="/img/remote/1460000019022699?w=1060&h=769" alt="" title=""></p>
<p><strong>图 6-Dubbo 架构</strong></p>
<p>除了保持和 Dubbo 官方以及社区的密切联系外,我们也在不断对 Dubbo 进行增强与改进,比如基于 dubbo-fitler 的日志追踪,基于大交通统一应用管理中心的 Dubbo 统一配置管理、服务治理体系建设等。</p>
<h3>服务化初探——抢票系统</h3>
<p>向服务化的演进决不能是一个大跃进运动,那样只会把应用拆分得七零八落,最终不但大大增加运维成本,而且看不到收益。</p>
<p>为了保证整个系统的服务化演进过程更加平滑,我们首先选择了抢票系统进行实践探索。抢票是火车票业务中的一个重要版块,而且抢票业务相对独立,与已有的 PHP 电子票业务冲突较少,是我们实施服务化的较佳场景。</p>
<p>在对抢票系统进行服务拆分和设计时,我们积累了一些心得和经验,主要和大家分享以下几点。</p>
<h4><strong>功能与边界</strong></h4>
<p>简单来说,抢票就是实现用户提前下抢票单,系统在正式开售之后不断尝试为用户购票的过程。从本质上来说,抢票是一种手段,通过不断检测所选日期和车次的余票信息,以在有余票时为用户发起占座为目的。至于占座成功以后的处理,和正常电子票是没有什么区别的。理解了这个过程之后,在尽量不改动原有 PHP 系统的前提下,我们这样划分它们之间的功能边界:</p>
<p><img src="/img/remote/1460000019022700?w=1080&h=1340" alt="" title=""></p>
<p><strong>图7-抢票功能划分</strong></p>
<p>也就是说,用户下抢票单支付成功,待抢票占座成功后,后续出票的事情我们会交给 PHP 电子票系统去完成。同理,在抢票的逆向方面,只需实现「未抢到票全额退」以及「抢到票的差额退」功能,已出票的线上退和线下退票都由 PHP 系统完成,这就在很大程度上减少了抢票的开发任务。</p>
<h4><strong>服务设计</strong></h4>
<p>服务的设计原则包括隔离、自治性、单一职责、有界上下文、异步通信、独立部署等。其他部分都比较容易把控,而有界上下文通俗来说反应的就是服务的粒度问题,这也是做服务拆分绕不过去的话题。粒度太大会导致和单体架构类似的问题,粒度太细又会受制于业务和团队规模。结合实际情况,我们对抢票系统从两个维度进行拆分:</p>
<p>1. 从业务角度系统划分为供应商服务 (同步和推送)、正向交易服务、逆向交易服务、活动服务。</p>
<p><img src="/img/remote/1460000019022701" alt="" title=""></p>
<p><strong>图8-抢票服务设计</strong></p>
<ul>
<li>正向交易服务:包括用户下抢票单、支付、取消、出票、查询、通知等功能</li>
<li>逆向交易服务:包括逆向订单、退票、退款、查询、通知等</li>
<li>供应侧:去请求资源方完成对应业务操作、下抢票单、取消、占座、出票等</li>
<li>活动服务:包括日常活动、分享、活动排名统计等</li>
</ul>
<p>2. 从系统层级分为前端 H5 层前后分离、API 接入层、RPC 服务层,和 PHP 之间的桥接层、异步消息处理、定时任务、供应商对外调用和推送网关。</p>
<p><img src="/img/remote/1460000019022702?w=1080&h=678" alt="" title=""></p>
<p><strong>图9-抢票系统分层</strong></p>
<ul>
<li>展示层:H5 和小程序,前后端分离</li>
<li>API 层:对 H5 和小程序提供的统一 API 入口网关,负责对后台服务的聚合,以 HTTP REST 风格对外暴露</li>
<li>服务层:包括上节所提到的业务服务,对外提供 RPC 服务</li>
<li>桥接层:包括调用 PHP 的代理服务,对 Java 侧提供 Dubbo RPC 服务,以 HTTP 形式调用统一的 PHP 内部网关;对 PHP 提供的统一 GW,PHP 以 HTTP 形式通过 GW 来调用 Java 服务</li>
<li>消息层:异步的消息处理程序,包括订单状态变更通知,优惠券等处理</li>
<li>定时任务层:提供各种补偿任务,或者业务轮询处理</li>
</ul>
<h4><strong>数据要素</strong></h4>
<p>对于交易系统而言,不管是用何种语言,何种架构,要考虑的最核心部分终归是数据。数据结构基本反应了业务模型,也左右着程序的设计、开发、扩展与升级维护。我们简单梳理一下抢票系统所涉及的核心数据表:</p>
<p>1. 创单环节:用户选择车次进入填单页以后,要选择乘车人、添加联系人,所以首先会涉及到乘车人表,这块复用的 PHP 电子票功能</p>
<p>2. 用户提交创单申请后,将会涉及到以下数据表:</p>
<ul>
<li>订单快照表——首先将用户的创单请求要素存储起来</li>
<li>抢票订单表 (order):为用户创建抢票单</li>
<li>区段表(segment):用于一个订单中可能存在的连续乘车而产生的多个车次情况 (类似机票航段)</li>
<li>乘车人表 (passenger):抢票单中包含乘车人信息</li>
<li>活动表 (activity):反映订单中可能包含的活动信息</li>
<li>物品表 (item):反映包含的车票,保险等信息</li>
<li>履约表:用户购买车票、保险后,最终会做票号回填,我们也叫票号信息表</li>
</ul>
<p>3. 产生占座结果后:用户占座失败涉及全额退款,占座成功可能涉及差额退款,因此我们会有退票订单表 (refund_order);虽然只涉及到退款,但同样会有 refund_item 表来记录退款明细。</p>
<h4><strong>订单状态</strong></h4>
<p>订单系统的核心要点是订单状态的定义和流转,这两个要素贯穿着整个订单的生命周期。</p>
<p>我们从之前的系统经验中总结出两大痛点,一是订单状态定义复杂,我们试图用一个状态字段来打通前台展示和后端逻辑处理,结果导致单一订单状态多达 18 种;二是状态流转逻辑复杂,流转的前置因素判断和后置方向上太多的 if else 判断,代码维护成本高。</p>
<p>因此,我们采用有限状态机来梳理抢票正向订单的状态和状态流转,关于状态机的应用,可以参照之前发过的一篇文章<a href="https://link.segmentfault.com/?enc=qFkBykBEXY6qQLB%2F2%2FBjwQ%3D%3D.gMYm2hzkaKG3Upe9395rMvw4eFppg3fHOuiuttZipcdfunapjjI378AXzfCfKHKR1pLRnrAM2glJkW09z5vWu%2B6A4jiId1dC%2Bm4APsLpiSsGJRD7Lkg6QHJ%2FOkAY7PunLeTFVYIraGsyA1voJJAnmw8y%2F1ijXH0BXVcPLNjsi2n9q4uxpxHak2z334gOprIezlCGIvsIQpZLrfoW7NtRz1zmCwwYVq67DJAImwNHS%2FwhNcazDAXw%2FJpFpqOVUMDRgOJ3dPKBuB2QZkby0IjJzzpdd5VGh1z%2B0OuG0YwPV5M3qjSdQzA3Kf5qSmhooJPS" rel="nofollow">《状态机在马蜂窝机票交易系统中的应用与优化》</a>,下图是抢票订单的状态流转图:</p>
<p><img src="/img/remote/1460000019022703?w=1080&h=779" alt="" title=""></p>
<p><strong>图10-抢票订单状态流转</strong></p>
<p>我们将状态分为订单状态和支付状态,通过事件机制来推进状态的流转。到达目标态有两个前提:一是原状态,二是触发事件。状态按照预设的条件和路线进行流转,将业务逻辑的执行和事件触发与状态流转拆分开,达到解耦和便于扩展维护的目的。</p>
<p>如上图所示,将订单状态定义为:初始化→下单成功→交易成功→关闭。给支付状态定义为:初始化→待支付→已支付→关闭。以正常 case 来说,用户下单成功后,会进入下单成功和待支付;用户通过收银台支付后,订单状态不变,支付状态为已支付;之后系统会开始帮用户占座,占座成功以后,订单会进入交易成功,支付状态不变。</p>
<p>如果仅仅是上面的双状态,那么业务程序执行倒是简单了,但无法满足前台给用户丰富的单一状态展示,因此我们还会记录关单原因。关单原因目前有 7 种:未关闭、创单失败、用户取消、支付超时、运营关单、订单过期、抢票失败。我们会根据订单状态、支付状态、关单原因,计算出一个订单对外展示状态。</p>
<h4><strong>幂等性设计</strong></h4>
<p>所谓幂等性,是指对一个接口进行一次调用和多次调用,产生的结果应该是一致的。幂等性是系统设计中高可用和容错性的一个有效保证,并不只存在于分布式系统中。我们知道,在 HTTP 中,GET 接口是天生幂等的,多次执行一个 GET 操作,并不会对系统数据产生不一致的影响,但是 POST,PUT,DELETE 如果重复调用,就可能产生不一致的结果。</p>
<p>具体到我们的订单状态来说,前面提到状态机的流转是需要事件触发的,目前抢票正向的触发事件有:下单成功、支付成功、占座成功、关闭订单、关闭支付单等等。我们的事件一般由用户操作或者异步消息推送触发,其中任意一种都无法避免产生重复请求的可能。以占座成功事件来说,除了修改自身表状态,还要向订单中心同步状态,向 PHP 电子票同步订单信息,如果不做幂等性控制,后果是非常严重的。</p>
<p>保证幂等性的方法有很多,以占座消息为例,我们有两个措施来保证幂等:</p>
<ol>
<li>占座消息都带有协议约束的唯一 serialNo,推送服务可以判断该消息是否已被正常处理。</li>
<li>业务侧的修改实现 CAS(Compare And Swap),简单来说就是数据库乐观锁,如 update order set order_status = 2 where order_id = 『1234' and order_status = 1 and pay_status = 2 。</li>
</ol>
<h4><strong>小结</strong></h4>
<p>服务化的实施具备一定的成本,需要人员和基础设施都有一定的基础。初始阶段,从相对独立的新业务着手,做好和旧系统的融合复用,能较快的获取成果。抢票系统在不到一个月的时间内完成产品设计,开发联调,测试上线,也很好地印证了这一点。</p>
<h2>第三阶段:服务化推进和系统能力提升</h2>
<p>抢票系统建设的完成,代表我们迈出了一小步,也只是迈出了一小步,毕竟抢票是周期性的业务。更多的时间里,电子票是我们业务量的主要支撑。在新老系统的并行期,主要有以下痛点:</p>
<ol>
<li>原有电子票系统由于当时因素影响,与特定供应商绑定紧密,受供应商制约较大;</li>
<li>由于和抢票系统及大交通其他系统之间的兼容成本较高,导致我们统一链路追踪、环境隔离、监控告警等工作实施难度很大;</li>
<li>PHP 和 Java 桥接层承接太多业务,性能无法保证</li>
</ol>
<p>因此,卸下历史包袱,尽快完成旧系统的服务化迁移,统一技术栈,使主要业务得到更加有力的系统支撑,是我们接下来的目标。</p>
<h3>与业务同行:电子票流程改造</h3>
<p>我们希望通过对电子票流程的改造,重塑之前应急模式下建立的火车票项目,最终实现以下几个目标:</p>
<ol>
<li>建立马蜂窝火车票的业务规则,改变之前业务功能和流程上受制于供应侧规则的局面;</li>
<li>完善用户体验和功能,增加在线选座功能,优化搜索下单流程,优化退款速度,提升用户体验;</li>
<li>提升数据指标和稳定性,引入新的供应侧服务,提高可靠性;供应商分单体系,提升占座成功率和出票率;</li>
<li>技术上完成到 Java 服务化的迁移,为后续业务打下基础</li>
</ol>
<p>我们要完成的不仅是技术上的重构,而是结合新的业务诉求,去不断丰富新的系统,力求达到业务和技术的目标一致性,因此我们将服务化迁移和业务系统建设结合在一起推进。下图是电子票流程改造后火车票整体架构:</p>
<h2><img src="/img/remote/1460000019022704?w=1080&h=666" alt="" title=""></h2>
<p><strong>图11-电子票改造后的火车票架构</strong></p>
<p>图中浅蓝色部分为抢票期间已经建好的功能,深蓝色模块为电子票流程改造新加入的部分。除了和抢票系统类似的供应商接入、正向交易、逆向交易以外,还包括搜索与基础数据系统,在供应侧也增加了电子票的业务功能。同时我们新的运营后台也已经建立,保证了运营支撑的延续性。</p>
<p>项目实施过程中,除了抢票所说的一些问题之外,也着重解决以下几个问题。</p>
<h4><strong>搜索优化</strong></h4>
<p>先来看用户一次站站搜索可能穿过的系统:</p>
<p><img src="/img/remote/1460000019022705?w=1061&h=224" alt="" title=""></p>
<p><strong>图12-站站查询调用流程</strong></p>
<p>请求先到 twl api 层,再到 tsearch 查询服务,tsearch 到 tjs 接入服务再到供应侧,整个调用链路还是比较长的,如果每次调用都是全链路调用,那么结果是不太乐观的。因此 tsearch 对于查询结果有 redis 缓存,缓存也是缩短链路、提高性能的关键。站站查询要缓存有几个难点:</p>
<ol>
<li>对于数据实时性要求很高。核心是余票数量,如果数据不实时,那么用户再下单占座成功率会很低</li>
<li>数据比较分散。比如出发站,到达站,出发日期,缓存命中率不高</li>
<li>供应侧接口不稳定。平均在 1000ms 以上</li>
</ol>
<p>综合以上因素考虑,我们设计 tsearch 站站搜索流程如下:</p>
<p><img src="/img/remote/1460000019022706?w=1080&h=1113" alt="" title=""></p>
<p><strong>图13-搜索设计流程</strong></p>
<p>如图所示,首先对于一个查询条件,我们会缓存多个渠道的结果,一方面是因为要去对比哪个渠道结果更加准确,另一方面可以增加系统可靠性和缓存命中率。</p>
<p>我们将 Redis 的过期时间设为 10min,对缓存结果定义的有效期为 10s,首先取有效;如果有效为空,则取失效;如果失效也为空,则同步限时 3s 去调用渠道获取,同时将失效和不存在的缓存渠道交给异步任务去更新。需要注意通过分布式锁来防止并发更新一个渠道结果。最终的缓存结果如下:</p>
<p><img src="/img/remote/1460000019022707" alt="" title=""></p>
<p>缓存的命中率会在 96% 以上,RT 平均在 500ms 左右,能够在保证用户体验良好的同时,做到及时的数据更新。</p>
<h4><strong>消息的消费</strong></h4>
<p>我们有大量业务是通过异步消息方式来处理的,比如订单状态变更消息、占座通知消息、支付消息等。除了正常的消息消费以外,还有一些特殊的场景,如顺序消费、事务消费、重复消费等,主要基于 RocketMQ 来实现。</p>
<p><strong>顺序消费</strong></p>
<p>主要应用于对消息有先后依赖的场景,比如创单消息必须先于占座消息被处理。RocketMQ 本身支持消息顺序消费,我们基于它来实现这种业务场景。从原理上来说也很简单,RocketMQ 限定生产者只能将消息发往一个队列,同时限定消费端只能有一个线程来读取,这样全局单队列,单消费者就保证了消息的顺序消费。</p>
<p><strong>重复消费</strong></p>
<p>RocketMQ 保障的是 At Least Once,并不能保证 Exactly Only Once,前面抢票我们也提过,一是通过要求业务侧保持幂等性,另外通过数据库表 message_produce_record 和 message_consume_record 来保证精准一次投递和消费结果确认。</p>
<p><strong>事务消费</strong></p>
<p>基于 RocketMQ 的事务消息功能。它支持二阶段提交,会先发送一条预处理消息,然后回调执行本地事务,最终提交或者回滚,帮助保证修改数据库的信息和发送异步消息的一致。</p>
<h4>灰度运行</h4>
<p>歼十战机的总设计师曾说过一句话:「造一架飞机不是最难的,难的是让它上天」,对我们来说同样如此。3 月是春游季的高峰,业务量与日俱增,在此期间完成系统重大切换,我们需要完备的方案来保障业务的顺利切换。</p>
<p><strong>方案设计</strong></p>
<p>灰度分为白名单部分和百分比灰度部分,我们首先在内部进行白名单灰度,稳定后进入 20% 流量灰度期。</p>
<p>灰度的核心是入口问题,由于本次前端也进行了完整改版,因此我们从站站搜索入口将用户引入到不同的页面,用户分别会在新旧系统中完成业务。</p>
<h2><img src="/img/remote/1460000019022708?w=1080&h=975" alt="" title=""></h2>
<p><strong>图14-灰度运行方案</strong></p>
<h4>搜索下单流程</h4>
<p>App 在站站搜索入口调用灰度接口获取跳转地址,实现入口分流。</p>
<p><img src="/img/remote/1460000019022709?w=1080&h=762" alt="" title=""></p>
<p><strong>图15-搜索下单分流</strong></p>
<h4>效果对比</h4>
<p><img src="/img/remote/1460000018994693" alt="" title=""><img src="/img/remote/1460000018994694?w=480&h=960" alt="" title=""></p>
<h2>近期规划</h2>
<p>我们只是初步实现了服务化在火车票业务线的落地实施,与此同时,还有一些事情是未来我们要去持续推进和改进的:</p>
<p><strong>1. 服务粒度细化</strong>:目前的服务粒度仍然比较粗糙。随着功能的不断增多,粒度的细化是我们要去改进的重点,比如将交易服务拆分为订单查询服务,创单服务,处理占座的服务和处理出票的服务。这也是 DevOps 的必然趋势。细粒度的服务,才能最大限度满足我们快速开发、快速部署,以及风险可控的要求。</p>
<p><strong>2. 服务资源隔离</strong>:只在服务粒度实现隔离是不够的。DB 隔离、缓存隔离、MQ 隔离也非常必要。随着系统的不断扩展与数据量的增长,对资源进行细粒度的隔离是另一大重点。</p>
<p><strong>3. 灰度多版本发布</strong>:目前我们的灰度策略只能支持新老版本的并行,未来除了会进行多版本并行验证,还要结合业务定制化需求,使灰度策略更加灵活。</p>
<h2>写在最后</h2>
<p>业务的发展离不开技术的发展,同样,技术的发展也要充分考虑当时场景下的业务现状和条件,二者相辅相成。比起设计不足而言,我们更要规避过度设计。</p>
<p>技术架构是演变出来的,不是一开始设计出来的。我们需要根据业务发展规律,将长期技术方案进行阶段性分解,逐步达成目标。同时,也要考虑服务化会带来很多新问题,如复杂度骤增、业务拆分、一致性、服务粒度、链路过长、幂等性、性能等等。</p>
<p>比服务支撑更难的是服务治理,这也是我们大家要深入思考和去做的事情。</p>
<p><strong>本文作者:李战平,</strong>马蜂窝大交通业务研发技术专家。</p>
<p><em>(题图来源:网络)</em></p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
<p><img src="/img/remote/1460000019022710?w=1080&h=481" alt="" title=""></p>
让前端监控数据采集更高效
https://segmentfault.com/a/1190000018918875
2019-04-19T10:23:12+08:00
2019-04-19T10:23:12+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
60
<p>随着业务的快速发展,我们对生产环境下的问题感知能力越来越关注。作为距离用户最近的一层,前端的表现是否可靠、稳定、好用,很大程度上决定着用户对整个产品的体验和感受。因此,对于前端的监控不容忽视。</p>
<p>搭建一套前端监控平台需要考虑的方面很多,比如数据采集、埋点模式、数据处理和分析、报警以及监控平台在具体业务中的应用等等。在这所有环节中,准确、完整、全面的数据采集是一切的前提,也为后续的用户精细化运营提供基础。</p>
<p>前端技术的日新月异给数据采集也带来了变化和挑战,传统的手工打点模式已经不能满足需求。如何在新的技术背景下让前端数据采集工作更加完善、高效,是本文讨论的重点。</p>
<h2>前端监控数据采集</h2>
<p>在采集数据之前,首先要考虑采集什么样的数据。我们重点关注两类数据,一类是与用户体验相关的,如首屏时间、文件加载时间、页面性能等;另外是帮助我们及时感知产品上线后是否出现异常的,比如资源错误、API 响应时间等。具体来说,我们对前端的数据采集具体主要分为:</p>
<ul>
<li>路由切换 (href、hashchange、pushState)</li>
<li>JsError</li>
<li>性能 (performance)</li>
<li>资源错误</li>
<li>API</li>
<li>日志上报</li>
</ul>
<h3><strong>路由切换</strong></h3>
<p>Vue、React、Angular 等前端技术的快速发展使单页面应用盛行。我们都知道,传统的页面应用是用一些超链接来实现页面切换和跳转的,而单页面应用是使用各自的路由系统来管理前端的每一个页面切换,例如 vue-router、react-router 等,跳转时仅刷新局部资源 ,js、css 等公共资源只需要加载一次,这就使传统网页进入离开的方式只有第一次打开能被记录。单页应用后续所有路由切换的方式有两种,一种是 Hash,一种是 HTML5 推出的 History API。</p>
<p><strong>1. href</strong></p>
<p>href 为页面初始化的第一次进入,这里只需要单纯上报「进入页面」事件即可。</p>
<p><strong>2. hashchange</strong></p>
<p>Hash 路由一个明显的标志是带有「 # 」。Hash 的优势是兼容性更好,但问题在于 URL 中一直存在「 # 」并不美观。我们主要通过监听 URL 中的 hashchange 来捕获具体的 hash 值进行检测。</p>
<pre><code>window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
</code></pre>
<p>需要注意的是,在新版 vue-router 中如果浏览器支持 history,即使 mode 选择 hash 也会优先选择 history 模式,虽然表现形式暂时还是 # 号,但实际上是模拟的,所以千万不要认为自己在 mode 选择了hash 就一定会是 hash。</p>
<p><strong>3. History API</strong></p>
<p>History 利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法进行路由切换,是目前主流的无刷新切换路由方式。与 hashchange 只能改变 # 后面的代码片段相比,History API (pushState、replaceState) 给了前端完全的自由。</p>
<p>PopState 是浏览器返回事件的回调,但是更新路由的 pushState、replaceState 并没有回调事件,因此,还需要分别在 history.pushState() 和 history.replaceState() 方法里处理 URL 的变化。在这里,我们运用到了一种类似 Java 的 AOP 编程思想,对 pushState 和 replaceState 进行改造。</p>
<p>AOP (Aspect-oriented programming)即面向切面编程,提倡针对同一类问题进行统一处理。AOP 的核心思想是让某个模块能够重用,它采用横向抽取机制,将功能代码从业务逻辑代码中分离出来,扩展功能而不修改源代码,相比封装来说隔离得更加彻底。</p>
<p>下面介绍我们的具体改造方式:</p>
<pre><code>// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
</code></pre>
<p>window.history.pushState 实际调用关系如图:</p>
<p><img src="/img/remote/1460000019022967?w=530&h=312" alt="" title=""></p>
<p>至此,我们对 pushState、replaceState 改造完毕,实现了有效地捕获路由切换。可以看到,我们在不侵入业务代码的情况下,对 window.history.pushState 进行了扩展,在调用的同时会主动 dispatchEvent 一个 pushState。</p>
<p>但在这里我们也能看到一个弊端,就是如果 AOP 代理函数发生 JS 错误,将会阻断后续的调用关系,使实际的 window.history.pushState 无法被调用。所以在使用此方式的时候,要对 AOP 代理函数的内容做好完善的 try catch,来防止业务上出现异常。</p>
<p><em>*__Tips:想自动捕获页面停留时间只需要在下一个进入页面事件触发时,通过上一个页面的打点时间和当前时间做差值即可,这时候可以上报一个【离开页面】事件。</em></p>
<h3><strong>JsError</strong></h3>
<p>前端项目中,由于 JavaScript 本身是一个弱类型语言,加上浏览器环境的复杂性、网络问题等,很容易发生错误。因此做好网页错误监控,不断优化代码,提高代码健壮性是一项很重要的工作。</p>
<p>JsError 的捕获可以帮助我们分析和监控线上问题,它与我们在 Chrome 浏览器的调试工具 Console 中看到的内容一致。</p>
<p><strong>1. window.onerror</strong></p>
<p>我们使用 window.onerror 捕获一般情况下 JS 错误的异常信息。捕获 JS 错误的方式有两种,window.onerror 和 window.addEventListener(‘error’)。一般情况下,捕获 JS 异常不推荐使用 addEventListener(‘error’),主要是因为它没有堆栈信息,而且还需要对捕获到的信息做区分,因为它会将所有异常信息捕获到,包括资源加载错误等。</p>
<pre><code>window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
</code></pre>
<p><strong>2. Uncaught (in promise)</strong></p>
<p>当 Promise 内发生 JS 错误或者 reject 信息未被业务处理的情况时,会抛出一个 unhandledrejection,并且这个错误不会被 window.onerror 以及 window.addEventListener('error') 捕获,这里需要用专门的 window.addEventListener('unhandledrejection') 进行捕获处理:</p>
<pre><code>window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
</code></pre>
<p>我们注意到 unhandledrejection 因为继承自 PromiseRejectionEvent,PromiseRejectionEvent 又继承自 Event,所以 msg、url、lineno、colno、stack 以字符串形式放到了 e.reason.stack 中,我们需要解析出来上述参数来和 onerror 参数对齐,为后续监控平台的指标统一化打下基础。</p>
<p><strong>3. 常见问题</strong></p>
<ul><li><strong>"Script error."</strong></li></ul>
<p>如果出现捕获的 msg 全部为 "Script error." ,问题在于你的 JS 地址和当前网页不在同一个域下。因为我们要经常在线上的版本做静态资源 CDN 化,会导致常访问的页面跟脚本文件来自不同的域名。这时如果没有进行额外的配置,浏览器出于安全方面的设计就容易出现 "Script error."。我们可以利用目前流行的 Webpack 打包工具来处理此类问题。</p>
<pre><code>// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
</code></pre>
<ul><li><strong>SourceMap</strong></li></ul>
<p>大部分场景下,生产环境中的代码都是经过压缩合并的,这使得我们捕获到的错误很难映射到具体的源码,为我们解决问题带来很大困扰,这里简要提出 2 个解决方案的思路。</p>
<p>生产环境我们需要添加 sourceMap 配置,这会导致安全隐患,因为这样外网就可以通过 sourceMap 进行源码映射。为了降低风险,我们可以通过如下方式:</p>
<ol>
<li>将 sourceMap 生成的 .map 文件设置公司内网访问,降低源码安全风险</li>
<li>在发布代码到 CDN 的时候,将 .map 文件存储到公司内网下</li>
</ol>
<p>这时我们已经拥有了 .map 文件,后续要做的就是通过捕获到的 lineno、colno、url 调用 mozilla/source-map 库进行源码映射,即可拿到真实的源码错误信息。</p>
<h3><strong>性能</strong></h3>
<p>性能指标的获取相对比较简单,在 onload 之后读取 window.performance 即可,里面包含了性能、内存等信息。这部分内容在很多现有的文章中都有介绍,因篇幅所限不在本文做过多展开,之后在相关主题文章中我们会有相关探讨,感兴趣的朋友可以添加「马蜂窝技术」公众号持续关注。</p>
<h3><strong>资源错误</strong></h3>
<p>首先我们要明确下资源错误捕获的使用场景,更多的是感知 DNS 劫持 及 CDN 节点异常等,具体方式如下:</p>
<pre><code>window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
</code></pre>
<p>这里只做基本演示,实际环境中我们会关心更多的 Element 错误,如 css、img、woff 等,大家可以根据不同的场景自行添加。</p>
<p><em>*资源错误的使用场景更多依赖其他几个维度,如:__地域、运营商等,后续的篇幅中我们会具体讲解。</em></p>
<h3><strong>API</strong></h3>
<p>市面上主流的框架(如 Axios、jQuery.ajax 等)中,基本上所有的 API 请求都是基于xmlHttpRequest 或者 fetch,所以捕获全局接口错误的方式就是封装 xmlHttpRequest 或者 fetch。这里,我们的 SDK 仍然使用到上文提及的 AOP 思想,对 API 进行拦截。</p>
<p><strong>1. XmlHttpRequest</strong></p>
<pre><code>var xhr = window.XMLHttpRequest;
var _open = xhr.prototype.open;
var _send = xhr.prototype.send;
var attr = {};
var openReplacement = function (method, url) {
// 可以存储method、url、时间打点等信息
attr.duration = new Date().getTime();
_open.apply(this, arguments);
}
var sendReplacement = function () {
methods.addEvent(this, 'readystatechange', function (attr) {
// 可以存储response的status、计算客户端实际响应时间
attr.status = this.status;
attr.duration = new Date().getTime() - attr.duration;
// 上报【API】事件
}.bind(this, , JSON.parse(JSON.stringify(attr))));
_send.apply(this, arguments);
}
xmlhttp.prototype.open = openReplacement;
xmlhttp.prototype.send = sendReplacement;
</code></pre>
<p><strong>2. Fetch</strong></p>
<p>需要注意的是,API 拦截一定要对 SDK 自己上报的 API 设置好忽略,否则将会导致循环上报问题。</p>
<pre><code>var _fetch = window.fetch;
window.fetch = function () {
var attr = {
method: arguments[1].method,
url: arguments[0],
duration: new Date().getTime()
};
return _fetch.apply(this, arguments).then(res => {
attr.status = res.status;
attr.duration = new Date().getTime() - attr.duration;
// 上报【API】事件
return res;
});
}
</code></pre>
<h3><strong>日志上报</strong></h3>
<p>为了监控前端应用是否正常运行,通常会在前端收集错误与性能等数据,最终将这些数据上报到服务端。因为日志上报并不是应用的主要功能逻辑,优先级比较低,所以我们在确保日志数据上报更高效的同时,还应该考虑如何尽可能地减少与其他关键操作的资源争抢。</p>
<p><strong>1. sendBeacon</strong></p>
<p>navigator.sendBeacon() 方法主要用于满足统计和诊断代码的需要。这些代码通常会在卸载文档之前,尝试通过 HTTP 将少量数据异步传输到 Web 服务器。它解决了日志上报在 unload 时成功率很低的问题。我们在埋点时有很多对离开页面时上报的需求,因为 SendBeacon 是异步的,不会影响当前页到下一个页面的跳转速度,可以更可靠地保障事件上报成功率,并且不影响路由切换。</p>
<pre><code>window.navigator.sendBeacon('上报事件的api', '数据参数')
</code></pre>
<p><strong>2. img.src</strong></p>
<p>当浏览器不支持 navigator.sendBeacon 时,我们可以采用模拟图片加载的方式发送日志上报事件,且不会存在跨域问题。</p>
<pre><code>var img = new Image();
img.src = API + '?' + '数据参数'
</code></pre>
<p><strong>3. 关于 XmlHttpRequest</strong></p>
<p>这里不推荐用 XmlHttpRequest。XHR 虽然支持异步请求,直接发送数据到后端,但是会受到跨域和同源的限制。而通过日志上报 API 跟业务是不在一个域下的,如果采用这种模式需要设置 Access-Control-Allow-Origin:* 跨域,非常不方便,并且在 unload 情况下上报发生的丢包率最高。</p>
<p>总结来看,日志上报推荐采用 sendBeacon -> img.src。在不影响用户路由切换和阻塞用户的情况下丢包率可以控制在 10%-30%,具体要看用户群体对应的环境。</p>
<h2>小结</h2>
<p>高效的前端数据采集对于搭建前端监控平台来说非常关键。本文我们分享了马蜂窝在保证数据采集及时、准确、全面等方面的一些思路和实践。需要提示大家注意的是,文中涉及到的演示只做了核心代码的关键描述,不具备生产使用,我们在实际使用中需要做好兼容及容错。</p>
<p>本文也将作为马蜂窝前端监控平台系列文章的开篇,今后还将陆续推出埋点模式、数据处理和分析、报警以及监控平台在具体业务中的应用等内容,欢迎大家持续关注。</p>
<p><strong>本文作者:王峥</strong>,马蜂窝大数据平台前端技术专家。</p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
<p><img src="/img/remote/1460000019022968?w=1080&h=481" alt="" title=""></p>
状态机在马蜂窝机票订单交易系统中的应用与优化实践
https://segmentfault.com/a/1190000018841838
2019-04-12T09:46:21+08:00
2019-04-12T09:46:21+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
9
<p>在设计交易系统时,稳定性、可扩展性、可维护性都是我们需要关注的重点。本文将对如何通过状态机在交易系统中的应用解决上述问题做出一些探讨。</p>
<h2>关于马蜂窝机票订单交易系统</h2>
<p>交易系统往往存在订单维度多、状态多、交易链路长、流程复杂等特点。以马蜂窝大交通业务中的机票交易为例,用户提交的一个订单除了机票信息之外可能还包含很多信息,比如保险或者其他附加产品。其中保险又分为很多类型,如航意险、航延险、组合险等。</p>
<p>从用户的维度看,一个订单是由购买的主产品机票和附加产品共同构成,支付的时候是作为一个整体去支付,而如果想要退票、退保也是可以部分操作的;从供应商的维度看,一个订单中的每个产品背后都有独立的供应商,机票有机票的供应商,保险有保险的供应商,每个供应商的订单都需要分开出票、独立结算。</p>
<p>用户的购买支付流程、供应商的出票出保流程,构成一个有机的整体穿插在机票交易系统中,密不可分。</p>
<h2>状态机在机票交易系统中的应用与优化</h2>
<h3>有限状态机的概念</h3>
<p>有限状态机(以下简称状态机)是一种用于对事物或者对象行为进行建模的工具。</p>
<p>状态机将复杂的逻辑简化为有限个稳定状态,构建在这些状态之间的转移和动作等行为的数学模型,在稳定状态中判断事件。</p>
<p>对状态机输入一个事件,状态机会根据当前状态和触发的事件唯一确定一个状态迁移。</p>
<p><img src="/img/remote/1460000019023437" alt="" title=""></p>
<p><strong>图1:FSM工作原理</strong></p>
<p>业务系统的本质就是描述真实的世界,因此几乎所有的业务系统中都会有状态机的影子。订单交易流程更是天然适合状态机模型的应用。</p>
<p>以用户支付流程为例,如果不使用状态机,在接收到支付成功回调时则需要执行一系列动作:查询支付流水号、记录支付时间、修改主订单状态为已支付、通知供应商去出票、记录通知出票时间、修改机票子订单状态为出票中…… 逻辑非常繁琐,而且代码耦合严重。</p>
<p>为了使交易系统的订单状态按照设计流程正确向下流转,比如当前用户已支付,不允许再支付;当前订单已经关单,不能再通知出票等等,我们通过应用状态机的方式来优化机票交易系统,将所有的状态、事件、动作都抽离出来,对复杂的状态迁移逻辑进行统一管理,来取代冗长的 if else 判断,使机票交易系统中的复杂问题得以解耦,变得直观、方便操作,使系统更加易于维护和管理。</p>
<h3>状态机设计</h3>
<p>在数据库设计层面,我们将整个订单整体作为一个主订单,把供应商的订单作为子订单。假设一个用户同时购买了机票和保险,因为机票、保险对应的是不同的供应商,也就是 1 个主订单 order 对应 2 个子订单 sub_order。其中主订单 order 记录用户的信息(UID、联系方式、订单总价格等),子订单 sub_order 记录产品类型、供应商订单号、结算价格等。</p>
<p>同时,我们把正向出票、逆向退票改签分开,抽成不同的子系统。这样每个子系统都是完全独立的,有利于系统的维护和拓展。</p>
<p>对于机票正向子系统而言,有两套状态机:主订单状态机负责管理 order 的状态,包括创单成功、支付成功、交易成功、订单关闭等;子订单状态机负责管理 sub_order 的状态,维护预订成功到出票的流程。同样,对于逆向退票和改签子系统,也会有各自的状态机。</p>
<p><img src="/img/remote/1460000019023438" alt="" title=""></p>
<p><strong>图2:机票主订单状态机状态转移示例</strong></p>
<h3>框架选型</h3>
<p>目前业界常用的状态机引擎框架主要有 Spring Statemachine、Stateless4j、Squirrel-Foundation 等。经过结合实际业务进行横向对比后,最终我们决定使用 Squirrel-Foundation,主要是因为:</p>
<ol>
<li>代码量适中,扩展和维护相对而言比较容易;</li>
<li>StateMachine 轻量,实例创建开销小;</li>
<li>切入点丰富,支持状态进入、状态完成、异常等节点的监听,使转换过程留有足够的切入点;</li>
<li>支持使用注解定义状态转移,使用方便;</li>
<li>从设计上不支持单例复用,只能随用随 New,因此状态机的本身的生命流管理很清晰,不会因为状态机单例复用的问题造成麻烦。 </li>
</ol>
<h3>MSM 的设计与实现</h3>
<p>结合大交通业务逻辑,我们在 Squirrel-Foundation 的基础之上进行了 Action 概念的抽取和二次封装,将状态迁移、异步消息糅合到一起,封装成为 MSM 框架 (MFW State Machine),用来实现业务订单状态定义、事件定义和状态机定义,并用注解的形式来描述状态迁移。</p>
<p>我们认为一次状态迁移必然会伴随着异步消息,因此把一个流程中必须要成功的数据库操作放到一个事务中,把允许失败重试并且对实时度要求不高的操作放到异步消息消费的流程中。</p>
<p>以机票订单支付成功为例,机票订单支付成功时,会涉及修改订单状态为已支付、更新支付流水号等,这些是在一个事务中;而通知供应商出票,则是放在异步消息消费中处理。异步消息的实现使用的是 RocketMQ,主要考虑到 RocketMQ 支持二阶段提交,消息可靠性有保证,支持重试,支持多个 Consumer 组。</p>
<p>以下具体说明:</p>
<p>1. 对每个状态迁移需要执行的动作,都会抽取出一个Action 类,并且继承 AbstractAction,支持多个不同的状态迁移执行相同的动作。这里主要取决于 public List<ActionCondition> matchConditions() 的实现,因此只需要 matchConditions 返回多个初始状态-事件的匹配条件键值对就可以了。每个 Action 都有一个对应的继承 MFWContext 类的上下文类,用于在 process saveDB 等方法中的通信。</p>
<p>2. 注册所有的 Action,添加每个状态迁移执行完成或者执行失败的监听。</p>
<p>3. 由于依赖 RocketMQ 异步消息,所以需要一个 Spring Bean 去继承 BaseMessageSender,这个类会生成异步消息提供者。如果要使用二阶段提交,则需要一个类继承 BaseMsgTransactionListener,这里可以参考机票的 OrderChangeMessageSender 和 OrderChangeMsgTransactionListener。</p>
<p>4. 最后,实现一个事件触发器类。在这个类里面包含一个 Apply 方法,传入订单 PO 对象、事件、对应的上下文,每次执行都实例化出一个状态机实例,并初始化当前状态,并调用 Fire 方法。</p>
<p>5. 实例化一个状态机对象,设置当前状态为数据库对应的状态,调用 Fire 方法之后,最终会执行到 OrderStateMachine 类里面用注解描述的 callMethod 方法。我们配置的是 callMethod = "action",它就会反射执行当前类的 Action 方法。</p>
<p>Action 方法我们的实现是通过 super.action(from, to, event, context),就会执行 MFWStateMachine 的 Action 方法,先去根据当前状态和事件获取对应的Action,这里使用到了「工厂模式」,然后执行 Process 方法。如果成功,会执行在 MFWStateMachine 类初始化的 TransitionCompleteListener,执行该 Action的 afterProcess 方法来修改数据库记录以及发送消息;如果失败,会执行TransitionExceptionListener,执行该 Action 的onException 方法来进行相应处理。</p>
<p>综上,MSM 可以根据 Action 类的声明和配置,来动态生成出 Squirrel-Foundation 的状态机定义,而不需要由使用方再去定义一次,使 MSM 的使用更方便。</p>
<p><img src="/img/remote/1460000019023439" alt="" title=""></p>
<p><strong>图3: UML</strong></p>
<h3>趟过的坑</h3>
<p><strong>1. 事务不生效</strong></p>
<p>最初我们使用 Spring 注解方式进行事务管理,即在 Action 类的数据库操作方法上加 <a href="https://link.segmentfault.com/?enc=zQRhA%2Bqlp2D5ydf1V%2FZAYQ%3D%3D.go30xkfOslUpeStIaW%2BzCVBLicqowtfzsov37x%2FMmhtZQ6LUOULz5j6YH4UYB8Ui" rel="nofollow">@Transactional</a> 注解,却发现在实践中不起作用。经过排查后发现, Spring 的事务注解是靠 AOP 切面实现的。在对象内部的方法中调用该对象其他使用 AOP 注解的方法,被调用方法的 AOP 注解会失效。因为同一个类的内部代码调用中,不会走代理类。后来我们通过手动开启事务的方式来解决此问题。</p>
<p><strong>2. 匹配 Action </strong></p>
<p>最初我们匹配 Action 有两种方式:精准匹配及非精准匹配。精准匹配是指只有当某个状态迁移的初始状态和触发的事件一致时,才能匹配到 Action;非精准匹配是指只要触发的事件一致,就可以匹配到 Action。后来我们发现非精准匹配在某些情形下会出现问题,于是统一改成了多条件精准匹配。即在执行状态机触发时执行的 Action 方法时,去精准匹配 Action,多个状态迁移执行的方法可以匹配到同一个 Action,这样能够复用 Action 代码而不会出问题。 </p>
<p><strong>3. 异步消息一致性</strong> </p>
<p>有一些情况是绝不能出现的,比如修改数据库没成功即发出了消息;或是修改数据库成功了,而发送消息失败;或是在提交数据库事务之前,消息已经发送成功了。解决这个问题我们用到了 RocketMQ 的事务消息功能,它支持二阶段提交,会先发送一条预处理消息,然后回调执行本地事务,最终提交或者回滚,帮助保证修改数据库的信息和发送异步消息的一致。</p>
<p><strong>4. 同一条订单数据并发执行不同事件</strong> </p>
<p>在某些情况下,同一条订单数据可能会在同一时间(毫秒级)同时触发不同的事件。如机票主订单在待支付状态下,可以接收支付中心的回调,触发支付成功事件;也可以由用户点击取消订单,或者超时未支付定时任务来触发关单事件。如果不做任何控制的话,一个订单将可能出现既支付成功又会被取消。</p>
<p>我们用数据库乐观锁来规避这个问题:在执行修改数据库的事务时,update 订单的语句带有原状态的条件判断,通过判断更新行数是否为 1,来决定是否抛出异常,即生成这样的 SQL 语句:update order where order_id = ‘1234' and order_status = ‘待支付'。</p>
<p>这样的话,如果两个事件同时触发同时执行,谁先把事务提交成功,谁就能执行成功;事务提交较晚的事件会因为更新行数为 0 而执行失败,最终回滚事务,就仿佛无事发生过一样。</p>
<p>使用悲观锁也可以解决这个问题,这种方式是谁先争抢到锁谁就可以成功执行。但考虑到可能会有脚本对数据库批量修改,悲观锁存在死锁的潜在问题,我们最终还是采用了乐观锁的方式。</p>
<h2>总结</h2>
<p>MSM 状态机的定义和声明在 Squirrel-Foundation 的基础之上,抽取出 Action 概念,并对 Action 类配置起始状态、目标状态、触发的事件、上下文定义等,使 MSM 可以根据 Action 类的声明和配置,来动态生成出 Squirrel-Foundation 的状态机定义,而不需要使用方再去定义一次,操作更简单,维护起来也更容易。 </p>
<p>通过使用状态机,机票订单交易系统的流程复杂性问题迎刃而解,系统在稳定性、可扩展性、可维护性等方面也得到了显著的改善和提升。</p>
<p>状态机的使用场景不仅仅局限于订单交易系统,其他一些涉及到状态变更的复杂流程的系统也同样适用。希望通过本文的介绍,能使有状态机了解和使用需求的读者朋友有所收获。</p>
<p><strong>本文作者:董天</strong>,马蜂窝大交通研发团队机票交易系统研发工程师。</p>
<p>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)</p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
<p><img src="/img/remote/1460000019023440" alt="" title=""></p>
马蜂窝张矗:我对技术团队绩效考核管理的几点思考
https://segmentfault.com/a/1190000018786591
2019-04-08T10:36:04+08:00
2019-04-08T10:36:04+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
6
<p>由于程序员的工作性质,使他们的工作时常很难量化。对于技术管理者来说,想要做好量化,应该从哪几个方面出发呢?本文为 2019 年 3 月 23 日马蜂窝技术副总裁张矗在由 TGO 鲲鹏会主办的 GTLC 北京站发表的演讲整理,希望可以通过文本和各位技术管理者一起思考。</p>
<p>口述 | 张矗</p>
<p>整理 | Rainie Liu</p>
<p><img src="/img/remote/1460000019023652?w=1080&h=720" alt="" title=""></p>
<p><strong>张矗</strong>,马蜂窝技术副总裁,北京理工大学工学硕士,TGO 鲲鹏会会员,拥有 10 多年的互联网技术和管理经验。2000 年加入新浪网;2007 年作为联合创始人参与创建开心网;2012 年加入马蜂窝旅游网,担任技术副总裁。</p>
<p>大家好,我是来自马蜂窝的张矗。在座的很多朋友可能都用过我的一些 App,2012 年我来到马蜂窝进行二次创业,我的整个工作经历都是集中在互联网行业,今天分享内容更多的适合在互联网领域,其他领域的同学可以参考一下。</p>
<h2>无法衡量就无法管理</h2>
<p>无法衡量就无法管理,这句话是管理学大师——彼得·德鲁克说的。其实后面还有一句话叫,无法管理就无法改进它。今天分享的主题主要是关于技术研发人员在绩效考核上如何进行衡量、量化。</p>
<p>我的分享主要分为三个部分,第一部分,对技术研发人员绩效考核这个事情的难度在哪里;第二部分,在做绩效考核这个事情上要去做量化的绩效考核,以及它的误区;第三部分,是在马蜂窝实践中所总结出来的一些思考。</p>
<h2>绩效考核量化,难于上青天</h2>
<p>由于程序员工作性质,很多时候工作无法进行量化,那么对于技术管理者来说,做好绩效考核量化就好比上青天。那么想要做好量化,应该从哪几个方面出发呢?</p>
<h3>1、创造性工作</h3>
<p>首先,我们需要意识到自己所做的工作本质上是创造性工作、脑力劳动。脑力劳动是需要思考的,是需要灵感的,可是你的个人情绪、工作节奏、团队状况都会影响整个团队的产出,你也不知道灵感什么时候能够迸发,创造性的工作在互联网领域其实是需要很多的试错,试错的成本也是很难预估的。</p>
<h3>2、黑盒</h3>
<p>技术研发的很多工作成果其实是一个黑盒。我们都知道用一些功能性的黑盒进行测试,但你并不知道黑盒后面真正发生了什么。同样是一个列表页,过去可能是排序,但今天可能变成推荐算法,工作量是不可同日而语的。</p>
<p>如果我们想用白盒测试,那么将会给成本带来很大的提升。有一个经常发生的现象,如果你是用外行考核内行的时候,黑盒效应会更加明显。</p>
<h3>3、经验量化</h3>
<p>经验对互联网行业中的工程师来说,作用是非常巨大的。举个例子,就像外科手术,有经验的大夫一刀下去,有问题的组织会给你清理得干干净净,并且术后对于病人的生活质量是有很大的保障和提升;没有经验的大夫可能会下刀更多,也没有清理干净,如果要让病人接受这样的手术还不如不动手术,这个类比放在代码重构是特别典型的事情。经验这个事情也很复杂,因为它很可能是局部的,你只是对某个领域有经验而已,并且它也是不稳定的,可能这一刀还可以,下一刀未必行。</p>
<h3>4、时间管理</h3>
<p>时间管理对于工程师的工作产能来说是非常重要的。很多工程师和设计师每天都会因为各种会议、面试,以及需求不断地被打扰,大家都身处其中,谁催得着急一些,那我就优先做谁的工作,只有到夜深人静的时候才能做一些自己真正想做的事情。那么不擅长于掌握时间管理的工程师经常会陷入应激式工作的方法,而不是统筹式工作的方法。这种多任务的工作,一件任务没有完成,另外一件任务接踵而来,会给心里形成一个巨大的压力,本质上是会造成崩溃的,并陷入绝望的状态,工程师应该都很清楚多任务系统切换起来效率影响也是巨大的。</p>
<h3>5、协作</h3>
<p>工程师很多时候也不是独自孤立地在工作,他需要与产品、设计师、测试、商务人员、销售共同完成互联网作品的呈现。在这个过程中,需要彼此间具有同理心,互相去理解对方,帮助对方弥补思维的缺陷,最终完成这件事情。在这个过程中你很难去比较谁的贡献更大,谁的工作更多,而且这里面还有不少很重要的岗位,以及它们还具有年龄的差异。</p>
<p>现在我们看各种发布会时,会发现不少 90 后的产品经理已经上位了。相信今天来到本次 GTLC 全球技术领导力峰会北京站的参会者大多还是 80 后、85 后的技术管理者,可能有些在场同学已经开始着急如何与 90 后产品经理一块 PK 了,这件事情已经发生了,如果你一味的忧愁可能会让事情变得更加复杂。</p>
<h2>技术工作量化的误区有哪些?</h2>
<h3>1、代码行数</h3>
<p><img src="/img/remote/1460000019023653" alt="" title=""></p>
<p>大部分朋友都知道在技术工作量化上第一个误区是代码行数。当前我们常常对工程师提出要求——把代码写得精简易读,但有些“经验丰富”的工程师仍然很容易地在代码里加入很多没用的东西,或者是用工具实现代码行数的增加,以此来体现“彰显”工作量。</p>
<h3>2、BUG 数量</h3>
<p><img src="/img/remote/1460000019023654" alt="" title=""></p>
<p>大家会觉得考察 BUG 数量也不是一个好的方法,虽然在实践过程中会不断地提出来用 BUG 数量进行考核,但当你真正用 BUG 数量考核时,通常会形成很不好的引导。因为很可能会出现,工作越多,BUG 数量就会越多的情况,从长期来看这样的引导是无法激励大家爆发出更大的潜力。</p>
<h3>3、项目完成时间</h3>
<p><img src="/img/remote/1460000019023655" alt="" title=""></p>
<p>项目完成时间的考核方法具有一定的迷惑性。我们大多都喜欢把项目提前完成的团队,但项目完成时间通常是由项目执行者来决定的。如果用项目完成时间来考核大家,我们一定会使用保守估计时间的方式,为自己留一段时间缓冲。</p>
<h3>4、潜力>产出</h3>
<p>2018 年我加入 TGO 鲲鹏会时,在一次分享中,搜狐的高琦老师(高琦,搜狐高级技术经理 & TGO 鲲鹏会会员)讲解燃尽图时,从敏捷的角度看,燃尽图是一条倾向于直线的角度,如果我们倾向于把项目的预估时间和实际预估时间趋于此,用它们作为考核也会很有问题。</p>
<p>总结来看,我们希望考核是激发大家更大的工作潜力,而不是引导大家回归工作或者是逃避问题。</p>
<h2>关于这些年我在马蜂窝技术工作的绩效考核思考</h2>
<p>明白了难度和误区,那么这些年里我又产生哪些思考呢?</p>
<h3>1、关注目标,而不是任务</h3>
<p>我曾经工作的第一家公司也实施过 KPI,但是我觉得是非常失败的。因为它像一场运动,我完全预料不到结果,就这么过去了。</p>
<p>而在上一家公司,我们用到了 O(目的)G(目标)S(策略)M(衡量和检测)的方法,这个方法实施得相当不错,其中最核心的部分是 O 和 G 的制定过程,再到 S 和 M 的拆解,但 OGSM 的方法在互联网圈没有 KPI 和 OKR 这么流行,因此大家了解得也不多。</p>
<p>最近一两年,马蜂窝事业部也开始尝试使用 OKR 的方式进行绩效考核。因为 OKR 大家都比较了解,并且 OKR 的概念已经存在了很长时间,现在又不断地被提出来,去年起百度也是全面开始转向 OKR。</p>
<p>由此,我想到了如何量化我们的绩效指标上相当重要、熟悉的一个话语,关注目标,而不是任务。</p>
<p><img src="/img/remote/1460000019023656" alt="" title=""></p>
<p>我们经常说我发布了什么,启动了什么,创建了什么,上线了什么,这些都是任务而不是目标。目标应该是我将某某指标从 X 转变成了 Y,只有这样才是目标,目标应该是可量化的。</p>
<p>举一个内部的例子给大家分享一下,在马蜂窝内部有很多的员工使用的系统,如 OA 系统、企业邮箱、代码管理,以及各个事业部他们自己运营的系统,这些对于员工来说是相当复杂的,需要去记住每个系统的密码,以及我需要在哪一处登录。为了给大家提供一个更加安全、便捷的登录方式,我们计划去打造统一登录的 SCS 系统,并且把所有第三方的系统和我们自己研发的系统的登录都要切换到统一的登录系统中。</p>
<p>一开始,我们团队认为只要完成系统研发任务就完成了,可我们的目标并不是去研发一套 SCS 系统,而是要将没有使用 SCS 的系统从 50 个减少为 3 个,以此达到安全和便捷的目的,但是我们一开始并没有注意从目标出发。在完成研发任务的过程中,团队也解决了很多的问题,包括一开始没有想到的场景,以及思维转化的过程。渐渐地,研发统一登录的 SCS 系统变得不是重点了,而变成我们要去切换某个系统,推进第三方研发,这样的转化使得我们的工作成果变得更有实际意义。</p>
<p>马蜂窝对于团队的要求是,不光要求你会写代码,还需要具备沟通协调的能力,以及规范的能力。我们可以看看业务团队,或者支持业务团队的研发团队,他们的指标需要去确定,业务团队的目标就是整个团队的目标,业务团队的目标就应该成为支撑这个业务团队和研发团队的主要目标。</p>
<p>有一种声音会说业务团队的目标完成好或者不好,有些时候跟研发一点关系都没有,这会让我们形成阶段性的短视现象,我们更应该从长期来看它是否有更公平和有效的方法。但短期误判也是倒逼我们审视业务团队和目标很重要的方法,因为团队是需要长期投资才能看到价值。比如说管理团队,我们也需要帮助他们找到一些可量化的目标,这个可量化的目标包括系统的稳定性标准、性能维持标准,员工满意度标准等。</p>
<h3>2、平衡</h3>
<p>主要的方法确定了我们也需要加入一些平衡的因素来解决我们实际操作中的困难,那么我们该如何平衡呢?</p>
<p><img src="/img/remote/1460000019023657?w=1080&h=537" alt="" title=""></p>
<p>只关注业务的目标确实会形成短期的现象,如团队贡献、考勤,但这两个目标都具备一个特点,它是一种阶段性的状态,它会阶段性的好或者是不好。</p>
<p>如团队贡献,你这个月在团队内部做了一个分享,你可能就拿到团队贡献;你帮助这个团队组织了一次团建,你也具备这样的团队贡献。再比如,考勤并不是让大家给自己的兄弟们上下班打卡,它可以带着主观的因素,你可以观察谁经常迟到早退,这是你能感受到的主观印象,你也会感受到有些人天天为了项目加班到很晚。这个过程你还需要识别有一些同学他是天天加班的,是为了混一个晚餐或者是打车费,这个鉴别还是比较容易的。</p>
<p>找平衡的过程也是把我们管理者的主观判断落实在客观标准的过程,团队中我们都会喜欢在群里积极回答别人的问题,乐于给大家做分享的同学,他们对团队的氛围贡献是非常有帮助的,因此更应该在团队贡献上拿到更多的分数。</p>
<p>有的同学会说把个人成长、学习能力、解决问题的能力这样的因素纳入到绩效考核的指标上来,但是我认为这是不妥的。个人成长这个事情很难衡量,这个月我看了一本书叫《成长》,在书中作者提到,他将能力范畴指标,与成绩晋升和基础薪资挂钩会显得更有效一些。</p>
<h3>3、层级区分</h3>
<p>当你跟团队成员设计目标的时候,一定要关注他当前所在的层级。</p>
<p><img src="/img/remote/1460000019023658" alt="" title=""></p>
<p><strong>初级工程师</strong>,按时完成工作、写好代码、完成测试,以及做好文档的编撰就是他的目标,那你要从这个方向上想好怎么给他量化;</p>
<p><strong>稍微有一些年限的工程师</strong>,需要做好架构设计、规避项目的风险,那么你可能需要从这些方面给他做好设计;</p>
<p><strong>更资深的工程师或者是技术经理位</strong>,他需要做到判断需求的轻重缓急,做好项目的安排,以及项目上线后的跟踪和整个状态的反馈。</p>
<p>总之,对于越是高级的人员,他的绩效考核越是要跟业务 KPI 关联起来,当给他设计目标的时,一定要想他的目标对他的上级、部门、公司、用户和社会的意义和价值所在。</p>
<p>现在我们能看见有很多工程师,他的专业技能已经达到了高级的水平,但是在理解上级目标,确定自己的目标或者是行动还没跟上。“巨婴”就是指,需要哄着才能干活的程序员。比如我们上线一个新的功能,大家在上线前也都很努力,为了完成任务,加班熬夜终于在深夜把这个项目推上线,但上线后很多工程师没有对新的数据表现和用户行为做跟踪。现在大家的分工越来越细,很多这样的活都是产品经理或者是公司帮助你,那么这样的工程师必然沦为螺丝钉。</p>
<p>我们只有不断拓宽自己的眼界,提升自己的视野,才能使我们不断从初级向高级进化。</p>
<h3>4、评估周期</h3>
<p>最后一点思考就是对于评估周期的思考。我们都很希望上级能告诉我,未来一个季度该做些什么工作。举个例子,比如某个团队会支持很多客户的工作,但是他只知道我当前有这样的事,这个月差不多能干完,接下来两个月该干什么还不太确定。这时,我给大家的建议是不妨把考核的周期缩短,按月来考核。考核的内容包括这个月实际做的工作,实际支持的客户的成果等。或者,你也可以对下个月的挖掘作为考核指标,不超过三个月进行一次考核。在互联网领域里,三个月一次考核我认为也是上限,当你对未来不是那么确定时,不妨缩短考核周期。</p>
<p>总体来看,想要通过业务量化研发人员的工作,我们首先是完成思维转化,这样的转化对那些具有综合能力的研发人员,或综合能力比较强的研发人员更有利的;对于管理者来说,你要思考如何用其他的方法来确保搞钻研的科学家们不会被亏待,以此确保你的长期利益和短期利益的平衡,最终才能达到长期利益的最大化。</p>
<p>最后,我们再回到关注目标这个词,如果大家在关注目标,实践关注目标这个事情碰到一些困难时,我也给大家提一个建议,你可以多想想老板都在想什么,谢谢大家。</p>
<p>(本文转载自公众微信号:TGO)</p>
<p>关注马蜂窝技术公众号,查看演讲视频 + PPT</p>
<p><img src="/img/remote/1460000019023659?w=1080&h=481" alt="" title=""></p>
马蜂窝搜索基于 Golang 并发代理的一次架构升级
https://segmentfault.com/a/1190000018701582
2019-03-29T14:28:20+08:00
2019-03-29T14:28:20+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
8
<p>搜索业务是马蜂窝流量分发的重要入口。很多用户在使用马蜂窝时,都会有目的性地主动搜索与自己旅行需求相关的各种信息,衣食住行,事无巨细,从而做出最符合需求的旅行决策。</p>
<p>因此在马蜂窝,搜索业务交互的下游模块非常多,主要有目的地、POI、热门景点、美食、商场、酒店、问答、攻略、机票火车票等等,通过实时、精准地返回搜索结果,帮助用户做出个性化旅行决策。</p>
<p>面对越来越高的流量,马蜂窝技术团队积极尝试对搜索架构进行优化和升级,来保证搜索业务的稳定和性能。</p>
<h2>方案背景</h2>
<p>由于历史原因,优化前的搜索服务与下游模块交的互方式主要为调用各下游模块提供的函数,并且采用串行调用。</p>
<p><img src="/img/remote/1460000019024016" alt="" title=""></p>
<p><strong>图 1: 马蜂窝搜索业务架构和技术体系</strong></p>
<h3>搜索技术体系</h3>
<ul>
<li>存储——MySQL、Memcache</li>
<li>模块交互——Function Call</li>
<li>检索——Elasticsearch</li>
</ul>
<h3>搜索业务架构</h3>
<p>我们将搜索业务抽象为三个功能模块:</p>
<p><strong>1. 决策系统</strong></p>
<p>负责根据用户意图、运营策略、点击日志等数据,结合决策系统相关算法和模型,决策应该展示哪些模块(游记、商品等)及各模块展示顺序。</p>
<p><strong>2. Agent</strong></p>
<p>负责根据决策系统确定要展示的模块,从 Elasticsearch 和业务方获取模块(如游记、商品等)数据。</p>
<p><strong>3. Format</strong></p>
<p>负责根据不同模块的 UI 交互定义格式化数据,补充 UI 交互缺失数据。</p>
<p>串行的函数级调用方式,使之前的搜索服务架构存在一系列问题:</p>
<ul>
<li>业务间耦合度高。随着交互模块越来越多,导致搜索服务耗时变得很长,平均达到 400-500 ms;</li>
<li>由于与各业务间交互的方式是 Function Call,使上游很难控制下游模块阻塞时间;</li>
<li>下游调用增加响应时间相应呈线性增长,使其很难再叠加新的功能,可扩展性差;</li>
<li>如果下游模块出现故障,会由于接口阻塞引起超时,导致搜索服务整体都受到影响,表现出白页,用户体验严重下降。</li>
</ul>
<p><img src="/img/remote/1460000019024017?w=495&h=313" alt="" title=""></p>
<p><strong>图 2:问题分析</strong></p>
<p>因此,我们需要找到一种方式来降低搜索服务对于下游模块的依赖,以及模块间的耦合,从而提升架构的整体可用性和性能。</p>
<h2>基于 Golang 的并发代理实现</h2>
<p>经过调研,我们开发了基于 Golang 协程实现的并发请求代理工具,将之前函数级调用的方式变为基于 TCP/IP 的 HTTP 接口调用来与下游模块解耦,同时将串行调用变为并发,实现超时控制和异常容错处理。</p>
<h3>主要技术选型——协程(Goroutine)</h3>
<p>Goroutine 是 Golang 轻量级线程实现,由 Go runtime 管理。它是 Go 并行设计的核心,也是 Golang 最重要的特性之一,相比于进程、线程任务的抢占式调度,需要频繁进行上下文信息的内核和用户空间切换,Goroutine 可以由程序控制,使得它更易用、更高效、更轻便。</p>
<p>Goroutine 维护了一组数据结构和多个线程,任务放在一个待执行队列中,由 Goroutine 维护的线程来拉取执行。当任务执行了操作系统的 IO 操作等需要等待时,Goroutine 利用 Linux IO 多路复用技术 (Epoll、Select) 进行执行队列的任务切换来实现并发。</p>
<p>相比于其他语言的线程,其默认占用内存为 2KB, 远小于其他语言的 M 级别。在性能开销方面,由于任务调度基本有程序控制,开销也远小于线程。</p>
<p>选型的过程中,我们对比了 PHP 的 Swoole、Java 多线程并行处理方案,它们的 CPU 和内存消耗比 Golang 的 Goroutine 要高出很多,并且并行请求数量会受到资源的限制,在高并发的情况下如果控制不当会导致服务崩溃。而使用 Goroutine 实现的并发代理,可以轻松支持千万级别的并发请求。</p>
<p><img src="/img/remote/1460000019024018" alt="" title=""></p>
<p><strong>图 3:并行与并发</strong></p>
<h3>Golang 并发代理实现</h3>
<p>代理服务按请求的处理流程,可以划分为 HTTP Server ——> 参数处理——> 并行请求 (协程调度)——> HTTP 模块 ——> API 层。目前我们的方案支持 HTTP/HTTPS 协议的请求。</p>
<p><img src="/img/remote/1460000019024019" alt="" title=""></p>
<p><strong>图 4:并发代理架构图</strong></p>
<p><strong>各模块功能概要</strong>:</p>
<ol>
<li>
<strong>HTTP Sever</strong>:使用 Go 语言 httpserver package 实现,用于接收和处理有代理需求的上游模块的 HTTP 请求;</li>
<li>
<strong>参数处理</strong>:根据定义好的交互协议,将上游模块的请求解析为并行请求商品、游记等下游模块的请求任务;</li>
<li>
<strong>协程调度</strong>:使用 Go 语言的 Goroutine 实现,负责执行对下游模块的并发请求任务;</li>
<li>
<strong>HTTP 模块</strong>:使用 Go 语言的 ioutil/http package 实现,负责与下游 API 模块以 HTTP 协议形式交互;</li>
<li>
<strong>API 模块</strong>:将下游模块的函数调用封装为 TCP/IP接口,将函数形式交互变为 HTTP 接口形式交互。</li>
</ol>
<p>搜索业务应用代理后,整体架构变化为:</p>
<p><img src="/img/remote/1460000019024020?w=369&h=547" alt="" title=""></p>
<p><strong>图 5:并发代理在搜索业务中的应用</strong></p>
<h2><strong>小结与后续规划</strong></h2>
<p>基于 Golang 的并发代理在马蜂窝搜索业务中已经使用了一段时间,很好地解决了之前存在的一些问题。目前,搜索服务平均耗时已经降低到240ms 左右,架构的可用性和可扩展性也得到很大提升,并且有效提高了系统资源的利用率。</p>
<p>现在并发代理只支持 HTTP,后续会增加 RPC,来更好地支持整体的服务化改造。在推进和实施搜索架构升级的过程中,我们也会把更多的经验分享出来,希望大家持续关注。</p>
<p><strong>本文作者</strong>:王江涛,马蜂窝搜索推荐研发工程师。</p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
<p><img src="/img/remote/1460000019024021" alt="" title=""></p>
Flutter 实现原理及在马蜂窝的跨平台开发实践
https://segmentfault.com/a/1190000018655179
2019-03-26T10:07:18+08:00
2019-03-26T10:07:18+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
4
<p>一直以来,跨平台开发都是困扰移动客户端开发的难题。</p>
<p>在马蜂窝旅游 App 很多业务场景里,我们尝试过一些主流的跨平台开发解决方案,比如 WebView 和 React Native,来提升开发效率和用户体验。但这两种方式也带来了新的问题。</p>
<p>比如使用 WebView 跨平台方式,优点确实非常明显。基于 WebView 的框架集成了当下 Web 开发的诸多优势:丰富的控件库、动态化、良好的技术社区、测试自动化等等。但是缺点也同样明显:渲染效率和 JavaScript 的执行能力都比较差,使页面的加载速度和用户体验都不尽如人意。</p>
<p>而使用以 React Native(简称 RN)为代表的框架时,维护又成了大难题。RN 使用类 HTML+JS 的 UI 创建逻辑,生成对应的原生页面,将页面的渲染工作交给了系统,所以渲染效率有很大的优势。但由于 RN 代码是通过 JS 桥接的方式转换为原生的控件,所以受各个系统间的差异影响非常大,虽然可以开发一套代码,但对各个平台的适配却非常的繁琐和麻烦。</p>
<h2>为什么是 Flutter</h2>
<p>2018 年 12 月初,Google 正式发布了开源跨平台 UI 框架 Flutter 1.0 Release 版本,马蜂窝电商客户端团队进行了调研与实践,发现 Flutter 能很好的帮助我们解决开发中遇到的问题。</p>
<ol>
<li>
<strong>跨平台开发</strong>,<strong>针对 Android 与 iOS 的风格设计了两套设计语言的控件实现</strong>(Material & Cupertino)。这样不但能够节约人力成本,而且在用户体验上更好的适配 App 运行的平台。</li>
<li>
<strong>重写了一套跨平台的 UI 框架,渲染引擎是依靠 Skia 图形库实现</strong>。Flutter 中的控件树直接由渲染引擎和高性能本地 ARM 代码直接绘制,不需要通过中间对象(Web 应用中的虚拟 DOM 和真实 DOM,原生 App 中的虚拟控件和平台控件)来绘制,使它有接近原生页面的性能,帮助我们提供更好的用户体验。</li>
<li>
<strong>同时支持 JIT 和 AOT 编译</strong>。JIT 编译方式使其在开发阶段有个备受欢迎的功能——热重载(HotReload),这样在开发时可以省去构建的过程,提高开发效率。而在 Release 运行阶段采用 AOT 的编译方式,使执行效率非常高,让 Release 版本发挥更好的性能。</li>
</ol>
<p>于是,电商客户端团队决定探索 Flutter 在跨平台开发中的新可能,并率先应用于商家端 App 中。在本文中,我们将结合 Flutter 在马蜂窝商家端 App 中的应用实践,探讨 Flutter 架构的实现原理,有何优势,以及如何帮助我们解决问题。</p>
<h2>Flutter 架构和实现原理</h2>
<p>Flutter 使用 Dart 语言开发,主要有以下几点原因:</p>
<ul>
<li>Dart 一般情况下是运行 DartVM 上,但是也可以编译为 ARM 代码直接运行在硬件上。</li>
<li>Dart 同时支持 AOT 和 JIT 两种编译方式,可以更好的提高开发以及 App 的执行效率。</li>
<li>Dart 可以利用独特的隔离区(Isolate)实现多线程。而且不共享内存,可以实现无锁快速分配。</li>
<li>分代垃圾回收,非常适合 UI 框架中常见的大量 Widgets 对象创建和销毁的优化。</li>
<li>在为创建的对象分配内存时,Dart 是在现有的堆上移动指针,保证内存的增长是程线性的,于是就省了查找可用内存的过程。</li>
</ul>
<p>Dart 主要由 Google 负责开发和维护。目前 Dart 最新版本已经是 2.2,针对 App 和 Web 开发做了很多优化。并且对于大多数的开发者而言,Dart 的学习成本非常低。</p>
<p>Flutter 架构也是采用的分层设计。从下到上依次为:Embedder(嵌入器)、Engine、Framework。</p>
<p><img src="/img/remote/1460000018655182" alt="" title=""></p>
<p><center>图 1: Flutter 分层架构图</center></p>
<p><strong>Embedder</strong>是嵌入层,做好这一层的适配 Flutter 基本可以嵌入到任何平台上去; <strong>Engine</strong>层主要包含 Skia、Dart 和 Text。Skia 是开源的二位图形库;Dart 部分主要包括 runtime、Garbage Collection、编译模式支持等;Text 是文本渲染。<strong>Framework</strong>在最上层。我们的应用围绕 Framework 层来构建,因此也是本文要介绍的重点。</p>
<h3>Framework</h3>
<p>1.【Foundation】在最底层,主要定义底层工具类和方法,以提供给其他层使用。</p>
<p>2.【Animation】是动画相关的类,可以基于此创建补间动画(Tween Animation)和物理原理动画(Physics-based Animation),类似 Android 的 ValueAnimator 和 iOS 的 Core Animation。</p>
<p>3.【Painting】封装了 Flutter Engine 提供的绘制接口,例如绘制缩放图像、插值生成阴影、绘制盒模型边框等。</p>
<p>4.【Gesture】提供处理手势识别和交互的功能。</p>
<p>5.【Rendering】是框架中的渲染库。控件的渲染主要包括三个阶段:布局(Layout)、绘制(Paint)、合成(Composite)。</p>
<p>从下图可以看到,Flutter 流水线包括 7 个步骤。</p>
<p><img src="/img/remote/1460000018655183?w=806&h=332" alt="" title=""></p>
<p><center>图 2: Flutter 流水线</center></p>
<p>首先是获取到用户的操作,然后你的应用会因此显示一些动画,接着 Flutter 开始构建 Widget 对象。</p>
<p>Widget 对象构建完成后进入渲染阶段,这个阶段主要包括三步:</p>
<ul>
<li>
<strong>布局元素</strong>:决定页面元素在屏幕上的位置和大小;</li>
<li>
<strong>绘制阶段</strong>:将页面元素绘制成它们应有的样式;</li>
<li>
<strong>合成阶段</strong>:按照绘制规则将之前两个步骤的产物组合在一起。</li>
</ul>
<p>最后的光栅化由 Engine 层来完成。</p>
<p><strong>在渲染阶段</strong>,控件树(widget)会转换成对应的渲染对象(RenderObject)树,在 Rendering 层进行布局和绘制。</p>
<p>在布局时 Flutter 深度优先遍历渲染对象树。数据流的传递方式是从上到下传递约束,从下到上传递大小。也就是说,父节点会将自己的约束传递给子节点,子节点根据接收到的约束来计算自己的大小,然后将自己的尺寸返回给父节点。整个过程中,位置信息由父节点来控制,子节点并不关心自己所在的位置,而父节点也不关心子节点具体长什么样子。</p>
<p><img src="/img/remote/1460000018655184" alt="" title=""></p>
<p><center>图 3: 数据流传递方式</center></p>
<p>为了防止因子节点发生变化而导致的整个控件树重绘,Flutter 加入了一个机制——<strong>Relayout Boundary</strong>,在一些特定的情形下 Relayout Boundary 会被自动创建,不需要开发者手动添加。</p>
<p>例如,控件被设置了固定大小(tight constraint)、控件忽略所有子视图尺寸对自己的影响、控件自动占满父控件所提供的空间等等。很好理解,就是控件大小不会影响其他控件时,就没必要重新布局整个控件树。有了这个机制后,无论子树发生什么样的变化,处理范围都只在子树上。</p>
<p><img src="/img/remote/1460000018655185" alt="" title=""></p>
<p><center>图 4: Relayout Boundary 机制</center></p>
<p>在确定每个空间的位置和大小之后,就进入<strong>绘制阶段</strong>。绘制节点的时候也是深度遍历绘制节点树,然后把不同的 RenderObject 绘制到不同的图层上。</p>
<p>这时有可能出现一种特殊情况,如下图所示节点 2 在绘制子节点 4 时,由于其节点 4 需要单独绘制到一个图层上(如 video),因此绿色图层上面多了个黄色的图层。之后再需要绘制其他内容(标记 5)就需要再增加一个图层(红色)。再接下来要绘制节点 1 的右子树(标记 6),也会被绘制到红色图层上。所以如果 2 号节点发生改变就会改变红色图层上的内容,因此也影响到了毫不相干的 6 号节点。</p>
<p><img src="/img/remote/1460000018655186" alt="" title=""></p>
<p><center>图 5: 绘制节点与图层的关系</center></p>
<p>为了避免这种情况,Flutter 的设计者这里基于 Relayout Boundary 的思想增加了<strong>Repaint Boundary</strong>。在绘制页面时候如果遇见 Repaint Boundary 就会强制切换图层。</p>
<p>如下图所示,在从上到下遍历控件树遇到 Repaint Boundary 会重新绘制到新的图层(深蓝色),在从下到上返回的时候又遇到 Repaint Boundary,于是又增加一个新的图层(浅蓝色)。</p>
<p><img src="/img/remote/1460000018655187" alt="" title=""></p>
<p><center>图 6: Repaint Boundary 机制</center></p>
<p>这样,即使发生重绘也不会对其他子树产生影响。比如在 Scrollview 上,当滚动的时候发生内容重绘,如果在 Scrollview 以外的地方不需要重绘就可以使用 Repaint Boundary。Repaint Boundary 并不会像 Relayout Boundary 一样自动生成,而是需要我们自己来加入到控件树中。</p>
<p><strong>6.【Widget】控件层</strong>。所有控件的基类都是 Widget,Widget 的数据都是只读的, 不能改变。所以每次需要更新页面时都需要重新创建一个新的控件树。每一个 Widget 会通过一个 RenderObjectElement 对应到一个渲染节点(RenderObject),可以简单理解为 Widget 中只存储了页面元素的信息,而真正负责布局、渲染的是 RenderObject。</p>
<p>在页面更新重新生成控件树时,RenderObjectElement 树会尽量保持重用。由于 RenderObjectElement 持有对应的 RenderObject,所有 RenderObject 树也会尽可能的被重用。如图所示就是三棵树之间的关系。在这张图里我们把形状当做渲染节点的类型,颜色是它的属性,即形状不同就是不同的渲染节点,而颜色不同只是同一对象的属性的不同。</p>
<p><img src="/img/remote/1460000018655188?w=806&h=223" alt="" title=""></p>
<p><center>图 7:Widget、Element 和 Render 之间的关系</center></p>
<p>如果想把方形的颜色换成黄色,将圆形的颜色变成红色,由于控件是不能被修改的,需要重新生成两个新的控件 Rectangle yellow 和 Circle red。由于只是修改了颜色属性,所以 Element 和 RenderObject 都被重用,而之前的控件树会被释放回收。</p>
<p><img src="/img/remote/1460000018655189" alt="" title=""></p>
<p><center>图 8: 示例</center></p>
<p>那么如果把红色圆形变成三角形又会怎样呢?由于这里发生变化的是类型,所以对应的 Element 节点和 RenderObject 节点都需要重新创建。但是由于黄色方形没有发生改变,所以其对应的 Element 节点和 RenderObject 节点没有发生变化。</p>
<p><img src="/img/remote/1460000018655190" alt="" title=""></p>
<p><center>图 9: 示例</center></p>
<p><strong>7. 最后是【Material】 & 【Cupertino</strong>】,这是在 Widget 层之上框架为开发者提供的基于两套设计语言实现的 UI 控件,可以帮助我们的 App 在不同平台上提供接近原生的用户体验。</p>
<h2>Flutter 在马蜂窝商家端App 中的应用实践</h2>
<h2>
<img src="/img/remote/1460000018655191?w=1080&h=1920" alt="" title=""><img src="/img/remote/1460000018655192" alt="" title="">
</h2>
<p><center>图 10: 马蜂窝商家端使用 Flutter 开发的页面</center></p>
<h3>开发方式:Flutter + Native</h3>
<p>由于商家端已经是一款成熟的 App,不可能创建一个新的 Flutter 工程全部重新开发,因此我们选择 Native 与 Flutter 混编的方案来实现。 <br>在了解 Native 与 Flutter 混编方案前,首先我们需要了解在 Flutter 工程中,通常有以下 4 种工程类型:</p>
<p><strong>1. Flutter Application</strong></p>
<p>标准的 Flutter App 工程,包含标准的 Dart 层与 Native 平台层。</p>
<p><strong>2. Flutter Module</strong></p>
<p>Flutter 组件工程,仅包含 Dart 层实现,Native 平台层子工程为通过 Flutter 自动生成的隐藏工程(.ios /.android)。</p>
<p><strong>3. Flutter Plugin</strong></p>
<p>Flutter 平台插件工程,包含 Dart 层与 Native 平台层的实现。</p>
<p><strong>4. Flutter Package</strong></p>
<p>Flutter 纯 Dart 插件工程,仅包含 Dart 层的实现,往往定义一些公共 Widget。</p>
<p>了解了 Flutter 工程类型后,我们来看下官方提供的一种混编方案(<a href="https://link.segmentfault.com/?enc=%2B4kRizGk15MRCaCFhkXROQ%3D%3D.%2F7uWmCNM%2BkHAdyIbTa9Pgg5XJrW%2BPSfgKFpyYsKqUSwVYCPdXQkOt8SF3HR3s%2BNXM8q156YgsYJhVMCSVm81%2BRcPX0lMWWMzpjZFU4fylW0%3D" rel="nofollow">https://github.com/flutter/flutter/wiki/Add-Flutter-to-existing-apps</a>),即在现有工程下创建Flutter Module 工程,以本地依赖的方式集成到现有的 Native 工程中。</p>
<p><strong>官方集成方案(以 iOS 为例)</strong></p>
<p>a. 在工程目录创建 FlutterModule,创建后,工程目录大致如下:</p>
<p><img src="/img/remote/1460000018655193?w=652&h=360" alt="" title=""></p>
<p>b. 在 Podfile 文件中添加以下代码:</p>
<pre><code>flutter_application_path = '../flutter_Moudule/'</code></pre>
<p>该脚本主要负责:</p>
<ul>
<li>pod 引入 Flutter.Framework 以及 FlutterPluginRegistrant 注册入口</li>
<li>pod 引入 Flutter 第三方 plugin</li>
<li>在每一个 pod 库的配置文件中写入对 Generated.xcconfig 文件的导入</li>
<li>修改 pod 库的 ENABLE_BITCODE = NO(因为 Flutter 现在不支持 bitcode)</li>
</ul>
<p>c. 在 iOS 构建阶段 Build Phases 中注入构建时需要执行的 xcode_backend.sh (位于 FlutterSDK/packages/flutter_tools/bin) 脚本:</p>
<pre><code>"$FLUTTER_ROOT/packages/flutter_tools/bin/xcode_backend.sh" build
</code></pre>
<p>该脚本主要负责:</p>
<ul>
<li>构建 App.framework 以及 Flutter.framework 产物</li>
<li>根据编译模式(debug/profile/release)导入对应的产物</li>
<li>编译 flutter_asset 资源</li>
<li>把以上产物 copy 到对应的构建产物中</li>
</ul>
<p>d. 与 Native 通信</p>
<ul>
<li>
<strong>方案一</strong>:改造 AppDelegate 继承自 FlutterAppDelegate</li>
<li>
<strong>方案二</strong>:AppDelegate 实现 FlutterAppLifeCycleProvider 协议,生命周期由 FlutterPluginAppLifeCycleDelegate 传递给 Flutter</li>
</ul>
<p>以上就是官方提供的集成方案。我们最终没有选择此方案的原因,是它直接依赖于 FlutterModule 工程以及 Flutter 环境,使 Native 开发同学无法脱离 Flutter 环境开发,影响正常的开发流程,团队合作成本较大;而且会影响正常的打包流程。(目前 Flutter 团队正在重构嵌入 Native 工程的方式)</p>
<p>最终我们选择另一种方案来解决以上的问题:<strong>远端依赖产物。</strong></p>
<p><img src="/img/remote/1460000018655194" alt="" title=""></p>
<p><center>图 11 :远端依赖产物</center></p>
<h4>iOS 集成方案</h4>
<p>通过对官方混编方案的研究,我们了解到 iOS 工程最终依赖的其实是 FlutterModule 工程构建出的产物(Framework,Asset,Plugin),只需将产物导出并 push 到远端仓库,iOS 工程通过远端依赖产物即可。</p>
<p>依赖产物目录结构如下:</p>
<p><img src="/img/remote/1460000018655195" alt="" title=""></p>
<ul>
<li>
<strong>App.framework</strong>: Flutter 工程产物(包含 Flutter 工程的代码,Debug 模式下它是个空壳,代码在 flutter_assets 中)。</li>
<li>
<strong>Flutter.framework:</strong>Flutter 引擎库。与编译模式(debug/profile/release)以及 CPU 架构(arm*, i386, x86_64)相匹配。</li>
<li>
<strong>lib.a & .h 头文件:</strong> FlutterPlugin 静态库(包含在 iOS 端的实现)。</li>
<li>
<strong>flutter_assets</strong>: 包含 Flutter 工程字体,图片等资源。在 Flutter1.2 版本中,被打包到 App.framework 中。</li>
</ul>
<h4>Android 集成方案</h4>
<p>Android Nativite 集成是通过 Gradle 远程依赖 Flutter 工程产物的方式完成的,以下是具体的集成流程。</p>
<p>a.创建 Flutter 标准工程</p>
<pre><code>$ flutter create flutter_demo
</code></pre>
<p>默认使用 Java 代码,如果增加 Kotlin 支持,使用如下命令:</p>
<pre><code>$ flutter create -a kotlin flutter_demo
</code></pre>
<p>b.修改工程的默认配置</p>
<p><img src="/img/remote/1460000018655196" alt="" title=""></p>
<ol>
<li>修改 app module 工程的 build.gradle 配置 apply plugin: 'com.android.application' => apply plugin: 'com.android.library',并移除 applicationId 配置</li>
<li>修改 root 工程的 build.gradle 配置<p><em>在集成过程中 Flutter 依赖了三方 Plugins 后,遇到 Plugins 的代码没有被打进 Library 中的问题。通过以下配置解决(这种方式略显粗暴,后续的优化方案正在调研)。</em></p>
</li>
</ol>
<pre><code>subprojects {
project.buildDir = "${rootProject.buildDir}/app"
}</code></pre>
<ol>
<li>app module 增加 maven 打包配置</li>
<li>c. 生成 Android Flutter 产物</li>
</ol>
<pre><code>$ cd android
$ ./gradlew uploadArchives</code></pre>
<p><em>官方默认的构建脚本在 Flutter 1.0.0 版本存在 Bug——最终的产物中会缺少 flutter_shared/icudtl.dat 文件,导致 App Crash。目前的解决方式是将这个文件复制到工程的 assets 下(在 Flutter 最新 1.2.1 版本中这个 Bug 已被修复,但是 1.2.1 版本又出现了一个 UI 渲染的问题,所以只能继续使用 1.0.0 版本)。</em></p>
<p>d.Android Native 平台工程集成,增加下面依赖配置即可,不会影响 Native 平台开发的同学</p>
<pre><code>implementation 'com.mfw.app:MerchantFlutter:0.0.5-beta'</code></pre>
<h3>Flutter 和 iOS、Android 的交互</h3>
<p>使用平台通道(Platform Channels)在 Flutter 工程和宿主(Native 工程)之间传递消息,主要是通过 MethodChannel 进行方法的调用,如下图所示:</p>
<p><img src="/img/remote/1460000018655197" alt="" title=""></p>
<p><center>图 12 :Flutter 与 iOS、Android 交互</center></p>
<p>为了确保用户界面不会挂起,消息和响应是异步传递的,需要用 async 修饰方法,await 修饰调用语句。Flutter 工程和宿主工程通过在 Channel 构造函数中传递 Channel 名称进行关联。单个应用中使用的所有 Channel 名称必须是唯一的; 可以在 Channel 名称前加一个唯一的「域名前缀」。</p>
<h3>Flutter 与 Native 性能对比</h3>
<p>我们分别使用 Native 和 Flutter 开发了两个列表页,以下是页面效果和性能对比:</p>
<h4>
<strong>iOS 对比</strong>(机型 6P 系统 10.3.3):</h4>
<p>Flutter 页面:</p>
<p><img src="/img/remote/1460000018655198" alt="" title=""><img src="/img/remote/1460000018655199" alt="" title=""></p>
<p>iOS Native 页面:</p>
<p><img src="/img/remote/1460000018655200" alt="" title=""><img src="/img/remote/1460000018655201" alt="" title=""></p>
<p>可以看到,从使用和直观感受都没有太大的差别。于是我们采集了一些其他方面的数据。</p>
<p>Flutter 页面:</p>
<p><img src="/img/remote/1460000018655202" alt="" title=""></p>
<p><img src="/img/remote/1460000018655203" alt="" title=""></p>
<p>iOS Native 页面:</p>
<p><img src="/img/remote/1460000018655204" alt="" title=""></p>
<p><img src="/img/remote/1460000018655205" alt="" title=""></p>
<p><img src="/img/remote/1460000018655206" alt="" title=""></p>
<p>另外我们还对比了商家端接入 Flutter 前后包体积的大小:39Mb → 44MB</p>
<p><img src="/img/remote/1460000018655207" alt="" title=""></p>
<p>在 iOS 机型上,流畅度上没有什么差异。从数值上来看,Flutter 在 内存跟 GPU/CPU 使用率上比原生略高。Demo 中并没有对 Flutter 做更多的优化,可以看出 Flutter 整体来说还是可以做出接近于原生的页面。</p>
<p><strong>下面是 Flutter 与 Android 的性能对比。</strong></p>
<p>Flutter 页面:</p>
<p><img src="/img/remote/1460000018655208" alt="" title=""></p>
<p>Android Native 页面:</p>
<p><img src="/img/remote/1460000018655209" alt="" title=""></p>
<p>从以上两张对比图可以看出,不考虑其他因素,单纯从性能角度来说,原生要优于 Flutter,但是差距并不大,而且 Flutter 具有的跨平台开发和热重载等特点极大地节省了开发效率。并且,未来的热修复特性更是值得期待。</p>
<h2>混合栈管理</h2>
<p>首先先介绍下 Flutter 路由的管理:</p>
<ul>
<li>Flutter 管理页面有两个概念:Route 和 Navigator。</li>
<li>Navigator 是一个路由管理的 Widget(Flutter 中万物皆 Widget),它通过一个栈来管理一个路由 Widget 集合。通常当前屏幕显示的页面就是栈顶的路由。</li>
<li>路由 (Route) 在移动开发中通常指页面(Page),这跟 web 开发中单页应用的 Route 概念意义是相同的,Route 在 Android 中通常指一个 Activity,在 iOS 中指一个 ViewController。所谓路由管理,就是管理页面之间如何跳转,通常也可被称为导航管理。这和原生开发类似,无论是 Android 还是 iOS,导航管理都会维护一个路由栈,路由入栈 (push) 操作对应打开一个新页面,路由出栈 (pop) 操作对应页面关闭操作,而路由管理主要是指如何来管理路由栈。</li>
</ul>
<p><img src="/img/remote/1460000018655210" alt="" title=""></p>
<p><center>图 14 :Flutter 路由管理</center></p>
<p>如果是纯 Flutter 工程,页面栈无需我们进行管理,但是引入到 Native 工程内,就需要考虑如何管理混合栈。并且需要解决以下几个问题:</p>
<p>1. 保证 Flutter 页面与 Native 页面之间的跳转从用户体验上没有任何差异</p>
<p>2. 页面资源化(马蜂窝特有的业务逻辑)</p>
<p>3. 保证生命周期完整性,处理相关打点事件上报</p>
<p>4. 资源性能问题</p>
<p>参考了业界内的解决方法,以及项目自身的实际场景,我们选择类似于 H5 在 Navite 中嵌入的方式,统一通过 openURL 跳转到一个 Native 页面(FlutterContainerVC),Native 页面通过 addChildViewController 方式添加 FlutterViewController(负责 Flutter 页面渲染),同时通过 channel 同步 Native 页面与 Flutter 页面。</p>
<ul>
<li>每一次的 push/pop 由 Native 发起,同时通过 channel 保持 Native 与 Flutter 页面同步——在 Native 中跳转 Flutter 页面与跳转原生无差异</li>
<li>一个 Flutter 页面对应一个 Native 页面(FlutterContainerVC)——解决页面资源化</li>
<li>FlutterContainerVC 通过 addChildViewController 对单例 FlutterViewController 进行复用——保证生命周期完整性,处理相关打点事件上报</li>
<li>由于每一个 FlutterViewController(提供 Flutter 视图的实现)会启动三个线程,分别是 UI 线程、GPU 线程和 IO 线程,使用单例 FlutterViewController 可以减少对资源的占用——解决资源性能问题</li>
</ul>
<h2>Flutter 应用总结</h2>
<p>Flutter 一经发布就很受关注,除了 iOS 和 Android 的开发者,很多前端工程师也都非常看好 Flutter 未来的发展前景。相信也有很多公司的团队已经投入到研究和实践中了。不过 Flutter 也有很多不足的地方,值得我们注意:</p>
<ol>
<li>虽然 1.2 版本已经发布,但是目前没有达到完全稳定状态,1.2 发布完了就出现了控件渲染的问题。加上 Dart 语言生态小,学习资料可能不够丰富。</li>
<li>关于动态化的支持,目前 Flutter 还不支持线上动态性。如果要在 Android 上实现动态性相对容易些,iOS 由于审核原因要实现动态性可能成本很高。</li>
<li>Flutter 中目前拿来就用的能力只有 UI 控件和 Dart 本身提供能力,对于平台级别的能力还需要通过 channel 的方式来扩展。</li>
<li>已有工程迁移比较复杂,以前沉淀的 UI 控件,需要重新再实现一套。</li>
<li>最后一点比较有争议,Flutter 不会从程序中拆分出额外的模板或布局语言,如 JSX 或 XM L,也不需要单独的可视布局工具。有的人认为配合 HotReload 功能使用非常方便,但我们发现这样代码会有非常多的嵌套,阅读起来有些吃力。</li>
</ol>
<p>目前阿里的闲鱼开发团队已经将 Flutter 用于大型实践,并应用在了比较重要的场景(如产品详情页),为后来者提供了良好的借鉴。马蜂窝的移动客户端团队关于 Flutter 的探索才刚刚起步,前面还有很多的问题需要我们一点一点去解决。不过无论从 Google 对其的重视程度,还是我们从实践中看到的这些优点,都让我们对 Flutter 充满信心,也希望在未来我们可以利用它创造更多的价值和奇迹。</p>
<p>路途虽远,犹可期许。</p>
<p><strong>本文作者</strong>:马蜂窝电商研发客户端团队。</p>
<p><strong>(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,禁止商业用途,谢谢配合。)</strong></p>
<p><strong>参考文献:</strong></p>
<ul>
<li>
<strong>Flutter's Layered Design</strong><p><a href="https://link.segmentfault.com/?enc=hIuUG4SL%2BweVKQ8bDLbkpA%3D%3D.1cwNIKCaeL%2FZlY348kvkfu%2F9ycT7rCmNaECQpHUrlktkl0QaZwyhwv5pBJvgfdkT" rel="nofollow">https://www.youtube.com/watch?v=dkyY9WCGMi0 </a></p>
</li>
<li>
<strong>Flutter's Rendering Pipeline</strong><p><a href="https://link.segmentfault.com/?enc=TqlWDPu7yxUP0XAg0t7uxA%3D%3D.x09twR4vfnpK23L8NbErR4u2UF1eaXJWa3IaZB7brnjZJU4sSqTAzZyf5WDnTCKj%2BKFdlWfX%2FqH2sYNLuhrQfQ%3D%3D" rel="nofollow">https://www.youtube.com/watch?v=UUfXWzp0-DU&t=1955s </a></p>
</li>
<li>
<strong>Flutter 原理与美团的实践</strong><p><a href="https://link.segmentfault.com/?enc=tMCy925jq7O8iH6t%2F3J7YQ%3D%3D.KGAcVq6L73ca7E%2B20hLgcy78t%2FR1AWO5rHa6O7HDt6byRcg84pkLJkAV%2BY6yeNhKKv8RlP6nKxM%2BB3S56%2Ff9Bg%3D%3D" rel="nofollow">https://juejin.im/post/5b6d59476fb9a04fe91aa778#comment </a></p>
</li>
</ul>
<p><strong>关注马蜂窝技术,找到更多你想要的内容</strong></p>
<p><img src="/img/remote/1460000018655211" alt="" title=""></p>
从国企到互联网,一个六年程序员的「得」与「失」
https://segmentfault.com/a/1190000018514229
2019-03-15T10:12:27+08:00
2019-03-15T10:12:27+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
1
<p>程序员,六年,四段工作经历,这也许是一份会被很多 HR 刷掉的简历。</p>
<p><img src="/img/remote/1460000018514232?w=640&h=427" alt="" title=""></p>
<p>从学生时代至今,我经历了两次大的方向转型和一次大的技术转型:从偏理论推导的数学科学到重工程实践的计算机学科,从「安稳固化」的国企到「活跃求变」的互联网;从「人人为我」的客户端到「我为人人」的服务端技术转型。</p>
<p>回看自己的经历,在方向选择上,我是后知后觉的。在 PC 时代即将谢幕时入场,完美地错过移动互联网时代的红利期/窗口期;技术选型上,我是「愚钝」的。一头扎进学习曲线最为漫长的 C++,又投入 Windows 封闭生态环境的怀抱,转型服务端之初「逆趋势」地被选择了「世界上最好的语言」(PHP)。</p>
<p>然而从硬币的另一面来说,我是幸运的。丰富的经历自不必多说,在这个过程中,我也初步丰富和完善了知识结构。虽不健壮,却也雁过留痕。</p>
<p>年岁渐长,我愈发感受到总结的必要性和重要性。这篇文章远谈不上什么感悟或是经验分享,只是想把曾经那些曾令我兴奋的、失落的、沮丧的故事说一说,也算是回看自己略显「折腾」的几年中那些「得」与「失」。</p>
<h2>瞒着父母,我从国企辞职</h2>
<p>作为一个从农村走出来的孩子,211 院校硕士毕业,在国企实习后顺利转正,是一件让我父母脸上颇为有光的事情。但是只不到两年,我在没告诉他们的情况下选择了离开。</p>
<p>我第一次经历了系统且完整的软件开发全过程,使用被时间证明足够稳定(过时)的 MFC 技术,开发和维护 OP 工具软件,实现私有的应用层通信协议。</p>
<p>大家对于国企的第一印象,可能都是「工作稳定、福利待遇完善、竞争压力小」。但对于刚出校门的毛头小子来说,要把之前书本中学到的理论知识转化为生产力,挑战总是有的。而且在国企环境下,对系统稳定性、信息安全性都有很高的要求。同事们严谨的工作方式,也帮助我养成了编程规范和及时留存技术文档的习惯。</p>
<p>工作之外,我享有充足的时间读书学习。技术类书籍当然看得最多,历史、社会和文学也都没落下,以至于让我一直有种未曾离校的错觉。</p>
<p>即便如此,我却并不感觉自由。正值国企改革,组织要逐步减少对母体的依赖,形成并完善自身的造血能力,但在彼时相对封闭的环境、较为传统的管理方式和复杂的内部流程下,即便是我也能感受到领导在推动新技术变革时的束缚和阻碍。</p>
<p>年轻的我还是希望能快速在技术成长上有所突破,接受更多挑战,于是告别了温馨的团队和相处融洽的同事。</p>
<h2>初入互联网,我的热情有了安放之处</h2>
<p>重新找工作的过程并不像第一次那么顺利。虽然也有「大厂」向我招手,但可能是上一段工作的缘故,让我格外向往更有活力、有朝气、有更多机会和挑战的工作环境。最终,我选择了一家正在快速发展的互联网创业公司。</p>
<p>收到 Offer 的兴奋感只持续不到一天的时间,巨大的危机意识便开始滋生。虽然我还是机缘巧合地成了公司很长一段时间内的唯一的 Windows 开发者,但对比我上一份工作输出的原始且粗糙的单文档/多文档应用,这款 ToC 产品面向的女性用户群体、舒服的粉红色主题,以及素级挑剔的 Boss,都是我之前没经历过的。</p>
<p>入职后我就接到了新产品的开发任务。一个月内,我每天的工作时间几乎是之前的两倍,甚至周末都来不及喘息,逐个击破 IM、DirectUI、WebUI、WebSocket、Http、Wke、libCef 等这些之前从未接触过技术,和团队的十几位伙伴如期推出第一个内测版本,然后持续优化和改进。我们把这个项目当成自己的孩子,在生长的过程中难免有这样那样的问题(长链接保活、多端登录、消息的即时性、有序性和可靠性等),也会调皮和闯祸,但我和我的小团队从基础通信功能切入到初具规模,实现了从 0 到 1。</p>
<p>这是技术长进最快的时光,我不知疲惫地持续探索、反复试错。但是后来的种种因素没能让它继续成长壮大,也许是资本,也许是机遇。虽然很惋惜,但至少让我感到充实。</p>
<p>这一次,也点燃了我的热情,让我看到了自己创业的可能性。于是毅然切换赛道,开始一段新的未知旅程。</p>
<h2>创过业才知道,原来这么难</h2>
<p>受万众创新,大众创业的鼓舞,在某个机遇下,我受邀加入一个背景出色的初创团队,开始一段热血征程。</p>
<p>创业项目是基于情绪模型开发网络情报监测与智能分析大数据平台,通过对国内外主流社交媒体海量数据的收集、清洗、处理、存储、分析,就当下发生的热点事件,及时生成可视化的图表及舆情分析报告,为政府和企事业单位提供决策参考依据。能近距离地与业界的营销高手、舆情专家、大律师等牛人共事,着实令我心血澎湃、干劲十足。</p>
<p>对比成熟型创业公司,我们面临着机遇、团队和资源的所有匮乏,我个人也接受着身兼产品、技术、运维、市场等数职的挑战。</p>
<p>在创业初期,我们学习并践行「先僵化,后优化,再固化」的企业管理三步曲,虚心学习国外同类优秀产品,诚心向成功的前辈取经探讨,细心地打磨产品每个细节,用心地解答种子用户提出的或需求或产品本身的各类问题,也会为每个肯定或进步而欢欣鼓舞,会为每次质疑或否定而知耻后勇。但屡次在小作坊式持续迭代与集团式快速布局的「无谓抗争」中妥协,也认清了自身无论心智、思维还是能力都与合格创业者的标准相距甚远的现实,且内心对技术变现的「执念」。而这一年,我的技术水平毫无进展,与我预设的成长速度极不匹配。我开始思考自己是不是偏离了轨道。</p>
<p>最终,我还是决定带着祝愿和遗憾离场。</p>
<h2>回归初心 —— 精进技术</h2>
<p>这次出发,我的目标更加清晰,希望加入到一个技术导向型并且具有一定规模的团队。很幸运来到了马蜂窝。我清空之前所有的优越感和不良习性,以空杯心态去接受一个未知但精彩的新领域,重新激活了对四周任何事物充满无限好奇与试探的欲望,虽有涟漪,却也静好。</p>
<p>在快速发展的过程中,组织架构和业务调整在所难免,我又面临着是坚持 PHP 还是拥抱 JAVA 的选择问题。这次我的选择是在较长的一段时间内做好辅助的角色,去支持各个业务线的顺利开展。不得不说,难免沮丧,但也有过顿悟。直到新的业务和交易系统迁移接近尾声,与领导的一次长时间谈话及往后的深思,我决定再次拥抱变化,以一种无知无畏的姿态面对挑战。</p>
<p>在再次转型后的一段时间内,我投入到 JAVA 技术栈的学习,渗透服务化改造的思想,训练工程化和系统化思维,迷失渐少,多有裨益,更有勇气和信心地直面挑战。</p>
<h2>一个中年程序员的碎碎念</h2>
<p>在每一次转型过程中,也会有一种清零不被认可的情绪让我挫败。或许是跨度太大造成匹配度不高的错觉,但更多的原因应归咎于自身的内功不足。时至今日,一路磕磕绊绊地走来,经历资本的疯狂与寒冬,经历心智的稚嫩与初步成熟,经历从零到一的兴奋与从一到百的困惑,也分享几点感悟:</p>
<ul>
<li>第一份要工作慎重选择,它会直接或间接地影响后续的职业发展;</li>
<li>危机可以拆分为危险和机遇,抓住机遇并化解危险方能成长;</li>
<li>技术人同样需要培养成本意识、风险管控和团队管理能力;</li>
<li>唯有变化是唯一确定的变量,保持开放的心态,积极拥抱变化,加强学习和强化自身,才有机会在持续的变化中立于不败之地。</li>
</ul>
<p>人到中年,我们无法避免焦虑感。尽管如此,我仍然非常反对「技术是吃青春饭」的观点。最后,我想和大家分享几点,我在这些不算成功的转型中的几点体会。</p>
<p><strong>1. 扎实的基本功非常重要</strong></p>
<p>很多面临职业转型期的技术人,都会纠结于是要先加强技术的深度还是广度。在我看来,程序员想要有好的发展,操作系统、网络协议、编程语言、算法等都非常重要。工程化思维通过项目实践来积累,新技术虽然层出不穷,但万变不离其宗。比如掌握了 C++这种学习路线陡峭的语言,在面对新语言时你会很快上手。</p>
<p><strong>2. 提前规划,重视积累和沉淀</strong></p>
<p>回头来看,我不后悔做出的每个选择。但如果重来一次,我一定会重视对职业路径的规划,让自己有更多积淀。以后该如何发展?继续精进技术?转型产品经理?还是技术负责人?提前规划,少走弯路,并且利用好你的技术优势,形成思维方法和知识体系。</p>
<p><strong>3. 不要只关注代码,也要经营身边的人</strong></p>
<p>关注你的家人、朋友、同事,学习经营每一份关系,因为只有稳定的家庭和更多的朋友,你才会踏实地在技术这条路上探索,并且得到更多的资源。而不是像我,在离开多年后,才知道原来身边的人有如此实力。</p>
<p><strong>4. 努力活成一个有趣的自己</strong></p>
<p>关于程序员的标签,我们都有所耳闻。其实技术只是手段或工具,比技术更重要、更有价值的东西比比皆是,比如独立之人格、自由之思想,健康之体魄等。建议大家可以多读书、多旅游,也许在某个不经意间,你会惊喜于发现自己刷新了世界观。</p>
<p>以上这些也许并不足以为各位提供实质的指导,但感谢你的阅读。</p>
<p>关注马蜂窝技术,找到更多你想要的内容</p>
<p><img src="/img/remote/1460000018514233" alt="" title=""></p>
如何基于匹配预设句式,动态提取用户评价标签
https://segmentfault.com/a/1190000018478060
2019-03-12T17:54:02+08:00
2019-03-12T17:54:02+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
1
<p>网络经济的发展使我们的消费渠道早已不止于实体场景。来自于用户的线上评价,成为如今影响我们消费行为决策的重要因素。</p>
<h2>背景</h2>
<p>在网上购物时,即使你已经浏览了商家对于商品的描述,你还是不会立即决定购买它,因为你不确定这些描述是否准确。这时你会寻找其他购买过此商品的用户评论,这些评论可能才会最终说服你。</p>
<p>购买旅行类产品也是一样。每天都有大量用户在马蜂窝平台用“评论”的方式,记录和评价他们在旅行中的感受和体验。而基于对评论内容深度挖掘产生的标签,则用一种更为简洁、直观的方式汇总评论信息中的重要内容,展示给更多的用户作为参考依据。</p>
<p>因此,如何在保证标签内容准确性的同时,体现出更符合用户语言习惯、让用户更容易理解的标签含义,对于提升用户在马蜂窝平台的体验,做出更符合自身需求的旅行决策,以及提升平台转化率、更好地监管商家服务品质等方面,都有很大价值。</p>
<p>从评价中提取标签的方式有很多,但在实际应用中存在一些问题,比如:</p>
<h4>1. 预设标签</h4>
<ul>
<li>
<strong>做法</strong>:预先定义好一些固定标签,由用户在发表点评时自主选择。</li>
<li>
<strong>不足</strong>:固定标签数量受限,无法覆盖用户全部需求,并且标签和用户内容可能不匹配。</li>
</ul>
<h4>2. 句法分析</h4>
<ul>
<li>
<strong>做法</strong>:对用户发布的点评内容进行解构,提取主题词和描述词组合后作为标签。</li>
<li>
<strong>不足</strong>:在评价量非常大的时候,这种方法会产生大量标签,对计算性能要求高,并且维护不便。</li>
</ul>
<h4>3.多层级标签定义</h4>
<ul>
<li>
<strong>做法</strong>:预先定义标签大类,在逐级细分,最后产生具体标签。</li>
<li>
<strong>不足</strong>:产生大量维护工作。并且定义的层级灵活性欠佳,而且匹配的标签是关键词加指标词,不能很好地表达用户的言语习惯。</li>
</ul>
<p>为了解决以上问题,马蜂窝推荐和搜索研发团队提出了一种通过匹配预设句式的模式,灵活、动态提取用户评论标签的方式,将每个预设句式归宿到固定标签分类,在分类显示中动态地采用最大数标签作为整个分类标签的显示方式,极大减少了固定标签的数量,并且每个句式是任意的多个词组联合组成,使最终提取的标签内容在更符合用户语言习惯的同时,更好地体现了不同评论内容标签的个性化和差异化。</p>
<h2>基于匹配预设句式模板动态提取用户评价标签 </h2>
<p>首先和大家解释几个关键的概念。</p>
<ul>
<li>
<strong>标签</strong>:标签可以理解成对一个给定信息进行的具体描述。比如“离望京地铁站近”、“步行到大望路地铁站 1 分钟”等;</li>
<li>
<strong>句式</strong>:这里,我们可以先简单理解成是对同一类型标签的集合,可以理解成“评价方式”,比如上句关于标签的举例,都是对“离地铁站近”的评价;</li>
<li>
<strong>标签类别</strong>:同样,我们先简单理解成是对同一类句式,也就是一类“评价”的集合,比如上述句式包含在“交通方便”这类评价里。</li>
</ul>
<p>三者关系可以描述为,一个标签类别包含了 m 个句式;一个句式会产生 n 个标签,所以一个标签类别最多会对应 m*n 个标签。</p>
<h3>标签系统总体结构</h3>
<p>系统主要有两部分内容:标签句式的定义和自动化的句式生成。今天主要介绍第一部分<strong>关于如何定义句式和产生标签</strong>。</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d22464d8a?w=807&h=369&f=png&s=123472" alt="" title=""></p>
<p><center>图1 - 标签系统结构</center></p>
<h3>具体做法和实施步骤</h3>
<h4>一、建立句式库</h4>
<p>顾名思义,句式库是对所有预设句式的集合。接下来我们会具体讲解如何定义句式和产生标签。</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d2298d87e?w=866&h=349&f=png&s=132099" alt="" title=""></p>
<p><center>图2 - 句式库示意</center></p>
<p><strong>1. 建立词库</strong></p>
<p>词库是由词组以及其包含的词语组成的。每个词组和词语分别具有唯一标识;词组是<strong>对其包含的词语的概括和汇总</strong>;词语为表示该词组的近义词、俗语、舶来词、英语、缩写等。例如:</p>
<p>•<strong>词组</strong>:表示“班车”的名称集合</p>
<p>•<strong>词语</strong>:班车,摆渡车,接泊车,shuttlebus 等是词组中的词语</p>
<p>词组也可以<strong>表示一类描述信息</strong>,比如:</p>
<p>•<strong>词组</strong>:表示“距离近”的集合</p>
<p>•<strong>词语</strong>:近,不远,很近,走路 1 分钟等</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d225da95b?w=866&h=380&f=png&s=100308" alt="" title=""></p>
<p><center>图3 - 词库示意</center></p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d22b23005?w=866&h=281&f=png&s=41134" alt="" title=""></p>
<p><center>图4 - 词组示意</center></p>
<p>另外还会建立<strong>排除词库</strong>。排除词库中,以后不对这些词进行处理,排除词库大部分是无具体意义词,比如“我们”,“他们”之类的代词、“呀”“耶”“哦”之类的语气助词,“之后”“然后”“所以”这样没有转折意义的连词等等。</p>
<p><strong>2. 对句式分类,得到标签类别</strong></p>
<p>标签类别为用户点评信息的概括和归类,将同一类型的句式归类为一个标签类别,每个标签类别代表了一类相近评价内容。</p>
<p>比如“服务好”类,代表所有描述服务好的评价信息,该标签类别由多个句式组成,例如“{老板}{热情}”,“{前台}{专业}”,表示的都是关于酒店和民宿服务这一类评价的句式,则这些句式产生的标签都会归属到相同的类型上,但不同业务的 UGC 产生的具体标签会各具特色。</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d22ac9132?w=866&h=485&f=png&s=90013" alt="" title=""></p>
<p><center>图5 - 句式分类示意</center></p>
<p><strong>3.基于词组进行句式组合</strong></p>
<p>每个句式表示一种逻辑语义,通过词组之间的组合定义句式,表达不同内容,并具有唯一标识。</p>
<p>每个句式的词组中用具体的词语组合得到的结果定义为其产生的标签,如“距离牡丹园地铁站近”“离牡丹园地铁站很近”等均为{离}{地铁站}{近}句式产生的标签。</p>
<p>参与句式组合的词组分为四类,分别是<strong>普通词组、独立词组、POI、固定文字</strong>。构建句式时,并列关系的词组之间用 OR 表示,可减少句式的定义数量。例如:</p>
<ul>
<li>
<strong>句式</strong>:{提供}[{地铁站}OR{码头}OR{公交站}OR{火车站}OR{机场}OR{市中心}]{班车}</li>
<li>
<strong>普通词组</strong>:“提供”、“班车”</li>
<li>
<strong>独立词组</strong>:当匹配到该句式的独立性词组时,均需要单独显示,突出标签的特色性。即“地铁站”“码头”等。<p>当匹配到“提供-地铁站-班车”以及“提供-码头-班车”时,其表示的是不同含义或者特别含义,虽然都在提供班车同一个标签分类下,但需要单独显示。同理匹配到POI(感兴趣点,为目的地下的一些景点、地点等,如故宫、泰山、火车站、公交站、医院等)中的任意一条记录,则该标签均需要单独显示。</p>
</li>
</ul>
<h4><strong>二.句式匹配,生成标签</strong></h4>
<p><strong>1. 生成标签</strong></p>
<p>从 UGC 内容中提取一条评价文本,按照常用标点符号加用户常用符号为拆分依据,得到若干子句。</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d4d499ef1?w=866&h=435&f=png&s=132030" alt="" title=""></p>
<p><center>图6 - UGC 评价原文</center></p>
<p><strong>1). 依次匹配</strong></p>
<p>标签类别库中的每个句式从第一个词组开始,用词组中的每个词语按长度排序后依次与子句进行匹配。</p>
<p>如果某一个句式中的词语与子句中的相匹配,则记录该词语及这个词语在子句中的位置,之后按句式的词组顺序,继续匹配下一个词组中的词语,且匹配的开始位置是上次匹配词语的结束位置的后一位,继续逐个匹配词组中的词语信息,依此类推,不断循环这个过程,直到这个句式的每个词组中的一个词语匹配成功,则记录的每个词组中的匹配词语组合就是这个句式匹配的标签。</p>
<p>比如句式{服务}{好},第一个词语 {服务}匹配到的词语是词组中的“酒店服务”,第二个词组{好}匹配到的词语是“不错”,则生成标签“酒店服务不错”。在另外一个子句中可能匹配到的标签是“酒店服务好”。虽然他们表现形式为不同的标签,但都是由一个句式产生的同一类型的标签。</p>
<p><strong>2). 顺序匹配</strong></p>
<p>比如“机场有班车去酒店”,和“酒店有班车去机场”虽然包含的汉字完全一样,但表达的却是不同含义。</p>
<p><strong>3). 词距阈值</strong></p>
<p>在匹配的过程中,如果相邻两个词组距离大于一定的阈值,则认为不匹配。</p>
<p>例如句式是“{房间}{大}”,评价子句是“酒店房间里有一幅画着蓝天和大海的油画”。如果没有词距的判断,则该评价子句将匹配到“{房间}{大}”的参考句式,但是该评价子句的意思与“房间大”这一标签表达的意思明显不同。假设将第二预定阈值设置为三个字的词距,评价子句中“房间”与“大”之间的词距超过了三个字,就可以判断参考句式与评价子句不相匹配,避免了错误匹配。</p>
<p>由于句式中的词语之间可能有一定的位置相关性,通过判断匹配词之间的距离是否符合阈值,剔除那些子句中成功匹配到的词语但是并不表示符合句式含义的内容。</p>
<p><strong>4).一“否”即否</strong></p>
<p>当一个句式匹配到一个标签时,则判断该句子和句式是否存在否定关系,如果有则认为不匹配。比如饭菜不好吃,则匹配不到{包含饭菜的词组}{包含好吃的词组}这样的句式上。</p>
<p>正确匹配之后,记录这个子句和标签的对应关系,并找到该句式在标签类别库中对应的标签类别号,建立被匹配的子句与所属的标签类别之间的关系。如果子句没有成功匹配到对应的句式,则保存到未匹配的子句存储中,之后用来继续挖掘可用标签信息。</p>
<p><strong>关于匹配方式这里,有一些经验和大家分享:</strong></p>
<p>对于<strong>容易混淆</strong>的词语,应首先建立好一个混淆词语库,比如“好”这个词语,对应的混淆库的词语有“好像”,“好似”等等。在匹配到一个词语时发现它是易混淆词,则查看该词语对应的混淆词是否在这个词语的位置上,如果成立则认为不匹配,比如饭菜好像是之前的。则匹配不到{包含饭菜的词组}{包含好吃的词组}这样的句式上。</p>
<p>对于一些<strong>繁体字</strong>的点评先转成简体汉字,之后进行匹配。</p>
<p>之前,我们对一些其他匹配方式也进行了调研。比如子句先分词,之后用每个词去发现句式中的词语是否存在,这样的效率是比较高,因为用哈希方式查找。</p>
<p>但这样要依赖分词的准确性,也无法满足用户个性化的需求,尤其在评价语句中,有大量的不符合语法的,口语化的表达和网络词语使用,所以分词很难做到非常准确,最后得到的标签匹配效果也不理想。</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d4f873857?w=866&h=775&f=png&s=127323" alt="" title=""></p>
<p><center>图7 - 产生的标签</center></p>
<p><strong>2. 确定显示标签</strong></p>
<p>在不同的目标下,会有不同评价方式,展示出来的标签也应该体现出相应的个性化和差异化。我们根据该目标所有评论对应的标签类别号,统计每个标签类别中所有句式产生的标签出现频次,将出现频次最高的标签作为该标签类别的显示名称。</p>
<p>例如标签类别“性价比好”有三个句式{性价比}{很好},{性价比}{高},{价格}{便宜},在某个目标下的评价统计中标签“性价比不错”“性价比高”“价格实惠”分别出现了 5 次,10 次,7 次,那么关于这个标签类别显示的标签为“性价比高”。</p>
<p>这里有一种特殊情况:如果在同一个标签类别下一个句式定义中,有需要独立显示的标签,则该句式产生的标签不会和其他句式标签合并,而是独立显示该句式中频次最高的标签。</p>
<p>比如句式{提供}{去}[{火车站}OR{飞机场}]{班车},其中设定{火车站}和{飞机场}是需要独立显示的标签,则最后这两个词语对应产生的频次最高的标签的结果是“提供去车站班车”和“提供到机场的班车”,这两个标签不会和该类别(提供班车)下的其他频次最高标签合并,比如“去车站方便”,而是作为两个标签独立显示。</p>
<p>再如,标签类别“位置好”中包含了两个句式,{离}{POI}{近}和{POI}{步行}{3}{分钟},因为POI是被设定需要独立显示的类别,若产生的标签“离故宫近”的频次为 10,“离景山近”的频次是 15,“故宫步行 3 分钟”的频次是 17,则在“位置好”标签类别下,分别显示标签“故宫步行 3 分钟”和“离景山近”。</p>
<p><strong>3. 对未匹配子句分词处理</strong></p>
<p>对于未被匹配的子句进行自动产生句式处理,使用内容分类,句法分析,依存分析,词义分析等方法自动产生标签分类和每个分类下的句式,用户可以对这些标签句式审核和调整。并可对已有词组推荐近义词等,丰富词组的词语数量。</p>
<p><strong>4.定位子句</strong></p>
<p>因为之前已经保存了标签和被匹配子句之间的关系,当点击标签时,会高亮显示对应的子句。</p>
<h2>小结</h2>
<p>本文介绍的关于预设句式模板定义,通过灵活的词组的组合方式,可以动态的匹配大量标签,很好的解决了标签定义量大的问题。</p>
<p>由于句式的定义符合用户对目标的评价习惯,所以能覆盖更多的用户点评,提高了召回率,且模板产生的标签更符合评价语言的表达方式。</p>
<p>由于文章篇幅所限,后期我们会再介绍自动的句式生产。大家可以<strong>订阅马蜂窝技术公众号</strong>持续关注。谢谢。</p>
<p><strong>本文作者</strong>:乔志军,马蜂窝搜索与推荐研发团队内容挖掘工程师。</p>
<p><center>关注马蜂窝技术,找到更多你想要的内容</center></p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/11/1696ab1d4de9668f?w=1080&h=481&f=png&s=299883" alt="" title=""></p>
基于 HTTP 请求拦截,快速解决跨域和代理 Mock
https://segmentfault.com/a/1190000018477995
2019-03-12T17:50:17+08:00
2019-03-12T17:50:17+08:00
马蜂窝技术
https://segmentfault.com/u/mafengwojishu
1
<p>近几年,随着 Web 开发逐渐成熟,前后端分离的架构设计越来越被众多开发者认可,使得前端和后端可以专注各自的职能,降低沟通成本,提高开发效率。</p>
<p>在前后端分离的开发模式下,前端和后端工程师得以并行工作。当遇到前端界面展示需要的数据,而后端对应的接口还没有完成开发的情况时,需要一个数据源来保证前端工作的顺利进行。</p>
<p>今天这篇文章,我们会介绍几种常见的方法和其中存在的问题,并提出如何基于HTTP 请求拦截,快速解决跨域和代理 mock 问题的方案。</p>
<h2>常见方法及问题</h2>
<h3>请求 mock 服务器</h3>
<p>最常规的做法是维护一个提供静态数据的 mock 服务器(它提供的数据称为 mock 数据),前端请求 mock 服务器获取数据即可,但这种静态数据维护不便。</p>
<h3>请求 AMP</h3>
<p>更好的做法是有一个根据接口定义来自动生成数据的 mock 服务器,我们称为AMP(接口管理平台,API Manage Platform),前端请求该服务器获取数据。</p>
<p>在这种场景下,如果有些接口已经完成开发,前端需要手动修改代码去设置不同接口的请求地址。当接口数量较多时,这种方法会变得非常低效。因此, AMP 一般也会同时提供代理功能,也就是指前端仍请求 AMP,AMP 会根据接口完成情况来决定返回 mock 数据,还是将请求再次代理到真实的业务服务器获取数据后返回。</p>
<p>但是这种方案的问题在于当涉及到需要角色权限验证的接口时,登录输入用户信息后在浏览器中会缓存 cookie,当访问与登录时同域名的接口时,浏览器会自动携带 cookie,由服务器解析 cookie 并鉴权后获取对应权限的接口数据。前端一般是在本地启动服务器进行开发,当业务服务器的接口完成开发,这时再采用请求 AMP 的方法切换接口数据,就会出现跨域的情况。</p>
<p>由于浏览器的安全机制决定跨域访问时无法携带 cookie,并且无法通过代码读取 cookie,因此通过代码传递 cookie 跨域不可行,而现有的解决方案也不完美:</p>
<ul>
<li>如果<strong>在 AMP 额外增加模拟登陆的功能</strong>,会因为所有接口的权限固定不变,无法适配一个接口对不同角色有不同权限而返回相应的数据;而且一旦鉴权的接口功能变更、失效等情况发生,都需要重写修改 AMP 的代理功能,代价较大。</li>
<li>如果<strong>利用浏览器插件保存登陆信息、提供代理</strong>,则需要兼容不同浏览器,成本太高。</li>
</ul>
<p>针对上述技术问题,本文提出了一种可跨浏览器,并在前端实现的不侵入业务代码的代理方法。</p>
<h2>基于 HTTP 请求拦截</h2>
<h3>实现前端接口代理</h3>
<p>基于 HTTP 请求拦截实现前端接口的方式,从更底层的角度实现了接口开发完成前后的 mock 数据,及业务服务器真实数据之间的切换,并且解决了现有技术中由 HTTP 请求通过 AMP 代理到业务服务器产生跨域无法携带权限信息,导致无法按照角色权限返回请求数据的技术问题。</p>
<h3>主要创新点</h3>
<ol>
<li>在更底层基于 XMLHttpRequest 和 Fetch API 实现拦截代理,不需要考虑主流浏览器类型,和 JavaScript 依赖的工具库;</li>
<li>在前端实现代理,保留了登陆信息,无需额外处理鉴权问题;</li>
<li>提供一种可以快速实现且可插拔的使用方式。</li>
</ol>
<p>总的来说,这个方案提供了一种可快速实现,运行在前端浏览器中,且不依赖浏览器类型的请求代理方法。</p>
<h3>设计思路</h3>
<p>Web 前端开发一般使用 JavaScript 语言,浏览器环境的 HTTP 请求都是基于 Fetch API 或 XMLHttpRequest API 来实现的(基于前者的请求记做 xhr,后者记做 fetch),主流的 Javascript 开源工具库如 Axios、Request 也是这样。所以,我们的方案就是要通过在<strong>底层拦截 xhr 或 fetch,根据一定的判断逻辑来实现前端代理功能。</strong></p>
<h3>实现方式</h3>
<p>首先,重新封装浏览器环境中原生的 XMLHttpRequest API 和 Fetch API。基本思路是将这两个原生的 API 保存起来,添加到各自重新封装的同名 API 中(记作新 API),为新 API 写入与原生 API 中同名的方法和属性,在携带请求参数的同名方法(比如下文中的 open 和 send)里加入拦截请求和代理的逻辑 ApiProxy,对外开放一个可配置该拦截逻辑的接口,用于配置针对不同的 HTTP 请求格式所请求数据的拦截和代理逻辑。</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/12/16970ed32ee0f3a4?w=866&h=331&f=jpeg&s=24673" alt="" title=""></p>
<p><center>图1:代理与AMP和终端业务的交互流程</center></p>
<p><strong>ApiProxy 在这个过程中的主要作用和工作流程可以归纳为</strong>:</p>
<ol>
<li>注册拦截器。接收并拦截 HTTP 请求,解析该请求中的参数,这里的参数是指能在 AMP 中唯一标识该接口的参数,比如域名+请求方法(如 GET、POST 等)+路径(如 <a href="https://link.segmentfault.com/?enc=Q6gsQNUD4%2F2f4IwqVt5tlQ%3D%3D.CZuToPF5L0Spr7Xnleqwx3iAS9yDyOpN%2BRneXuTRUdU%3D" rel="nofollow">https://service.com/user</a> 中的/user)。</li>
<li>根据该参数生成发送 AMP 的请求。AMP 实时维护了 mock 服务器上存储的接口以及业务服务器上存储的真实接口的相关信息,包括接口的定义、域名、属性、开发状态等。</li>
<li>AMP 根据请求查询接口定义数据,如果接口存在且状态是开发中,则返回根据接口定义生成的 mock 数据,否则返回特定响应标志,如图 1 中的「{code:』200302』}」。</li>
<li>Apiproxy 收到 AMP 的响应后判断是否有特殊标志,没有直接返回 mock 数据到原请求,有则表示后端接口开发完成,继续发送原 HTTP 请求到后端服务器请求后端服务器存储的真实数据,相当于没有对原请求做任何处理。</li>
</ol>
<p>和传统的将 HTTP 请求发送给 AMP 不同的是 ,AMP 根据接口状态判断是根据请求直接返回 mock 数据,还是开启代理将 HTTP 请求再发送给业务服务器(此时跨域访问会丢失原始 HTTP 请求中浏览器携带的 cookie),<strong>不直接将 HTTP 请求发送给 AMP,而是对请求正式发出之前进行拦截,并解析其中的参数发送给 AMP,由 AMP 反馈接口状态</strong>,若开发完成则将 HTTP 请求正式发送给业务服务器。因为没有修改该请求,只是延迟发送,这样就保持了原请求与业务服务器之间的所有鉴权等相关信息,由此解决了跨域访问无法携带 cookie 的问题。</p>
<h3>不同请求方式下 ApiProxy 的实现</h3>
<p>由于不同请求方式的底层设计不同,我们相应的具体封装手段也不同。</p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/12/16970ed32ec21378?w=866&h=506&f=jpeg&s=34785" alt="" title=""></p>
<p><center>图2:代理核心工作原理</center></p>
<h4>XMLHttpRequest</h4>
<p>对于 XMLHttpRequest 请求,在其 open 方法中解析请求,访问 AMP 根据响应结果判断是否需要继续发送原请求到后台服务器,一个 xhr 只有在其 send 方法被调用时才会真正的发起 HTTP 请求,而在 open 方法中无法获取到 send 方法传递的数据,所以拦截发生在 send 方法中。首先单独存储 send 方法中发送请求时的参数,然后直接返回,确保先不调用真正的 XMLHttpRequest 的 send 方法,将单独存储的参数生成对 AMP 的请求,执行上述 AMP 中的判断。</p>
<p><strong>实例</strong></p>
<p>1、定义与原生 XMLHttpRequest API 同名的接口,称为新的 XHR 接口;</p>
<p>2、重命名原生 XMLHttpRequest API 并添加到新的 XHR 接口;</p>
<p>3、在新的 XHR 接口中定义与原生 XMLHttpRequest API 同名的属性和方法;</p>
<p>4、在同名的 open 方法中解析 HTTP 请求,得到用来在 AMP 查询接口状态的参数(比如域名+请求方法+路径);</p>
<p>5、拦截将要发送的原请求,在同名的 send 方法中暂存原请求要发送的数据,暂停原请求的发送;</p>
<p>6、用 4 中的参数请求 AMP,查询接口状态,如果接口不存在或是已完成状态,则返回特殊标志,ApiProxy 取出 5 中暂存的数据,传递给原请求,并继续原请求的发送;否则,AMP 返回 mock 数据,ApiProxy 直接将该数据返回给原请求。</p>
<h4>Fetch API</h4>
<p>对于 Fetch API 而言,因为它是基于 Promise 实现的,拦截比较容易,只需要在 Fetch API 外层封装一个 Promise 入口,在其发起 fetch 请求前,先暂停原请求,解析数据请求 AMP,并等待响应,判断响应是否有特殊响应码,如果有则继续原请求,否则跳过原请求,直接返回 mock 数据。</p>
<h4>启动前端代理功能</h4>
<p>在前端实际开发中,可以借助打包工具,比如 webpack,自定义一个可配置的插件,开启后在开发环境中自动将代理拦截代码插入到主页面里,从而启动前端代理功能。</p>
<h2>小结</h2>
<p>本文提出的前端代理方法通过将代理职责下沉到前端,减少了 mock 服务器(或者接口管理平台)请求真实业务服务器步骤,同时将角色权限保持在前端请求中,进一步减少了代理所需要承担的工作量,从底层拦截 HTTP 请求的方法,绕过了利用浏览器插件做代理带来的浏览器兼容的问题。最后提供的利用打包工具(如 webpack)封装这种代理方法,实现快速插拔的前端代理。</p>
<p><strong>本文作者</strong>奴止,马蜂窝社区研发团队前端开发工程师,主要负责社区管理后台,接口管理平台开发等工作。</p>
<p><strong>关注马蜂窝技术,找到更多你需要的内容</strong></p>
<p><img src="https://user-gold-cdn.xitu.io/2019/3/12/16970ed32eb8e350?w=1080&h=481&f=png&s=299883" alt="" title=""></p>
<h3>附:参考资料</h3>
<p><strong>关于跨域</strong>:</p>
<p><a href="https://link.segmentfault.com/?enc=TIGXN3cyJsj2fj8EoR1Nnw%3D%3D.hfONafgZSFHsN8DMwJe9x%2BLZimtsWJfBHilhFc6XUeUGlFyK04gY44TRhLvIlETF2hUgiObpfQWjHqHq8VFdsA%3D%3D" rel="nofollow">https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS</a></p>
<p>关于XMLHTTPRequest:</p>
<p><a href="https://link.segmentfault.com/?enc=IIVB1UiFtSGT11I1Rt2TEA%3D%3D.Q7eH%2FPY%2Bx5EmDHLb0l5EqpLo0lbfnfE7qIG%2BhRcqSc8fRuzbXflEX7aaoqlH6sfsTd7YpEBj25UdvKgTw7G3Lw%3D%3D" rel="nofollow">https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest</a></p>
<p><strong>关于Fetch</strong>:</p>
<p>[<a href="https://link.segmentfault.com/?enc=BjXjOOoNOTCIAmGGgDTv5Q%3D%3D.N9v2kLpZ3t%2B79WFy1D8VJKTrPIijblWbhr8G4kCEcFXZ3OoloiCI1wDlk9BYqClz6yZoyEhOqFKlUKXY55gAEw%3D%3D" rel="nofollow">https://developer.mozilla.org...</a>](<a href="https://link.segmentfault.com/?enc=c6H9vOdhxZNgZ178s%2FH2eA%3D%3D.K2ofA8ziHciMGN1lN1q1Aa8I2MVHTdeZF05B1S5iNua6MqE2Yu3BGXc%2F4JUIVMKN3WwRp3%2BlYgb%2FJBu8WHbsaQ%3D%3D" rel="nofollow">https://developer.mozilla.org...</a></p>