
Produced by Brother Ma, it must be a boutique. Pay attention to the official account "MageByte" and add MageByte1024 to the other side of the man behind the hardcore article.
This article will deeply disassemble the cluster's nodes, slot assignment, command execution, resharding, redirection, failover, and messaging.
The purpose is to master what is Cluster? Cluster fragmentation principle, client data positioning principle, failover, master selection, what scenario to use Cluster, how to deploy cluster...
[toc]
Why do we need Cluster
65 Brother: Brother achieve automatic failover 1609ce39b71507, I can finally be happy with my girlfriend. I am not afraid that Redis will be down late at night.But recently encountered a bad problem, Redis needs to save 8 million key-value pairs, occupying 20 GB of memory.
I used a 32G memory host to deploy, but Redis sometimes responded very slowly. I used the INFO command to check the latest_fork_usec indicator (the last fork took time) and found that it was particularly high.
It is mainly caused by the Redis RDB persistence mechanism. Redis will fork the child process to complete the RDB persistence operation. The time consumed by fork execution is positively related to the amount of Redis data.
When Fork is executed, it will block the main thread. Because the amount of data is too large, the blocked main thread is too long, so Redis responds slowly.
65 Brother: With the expansion of business scale, the amount of data is getting larger and larger. It is difficult to expand the hardware of a single instance of the master-slave architecture, and saving large amounts of data will cause slow response problems. Is there any way to solve it?
To save large amounts of data, in addition to using large memory hosts, we can also use slice clusters. As the saying goes, "everyone picks up materials with high flames." If one machine cannot store all the data, then multiple machines will share the burden.
uses the Redis Cluster cluster, which mainly solves various slow problems caused by large data storage, and also facilitates horizontal expansion.
The two schemes correspond to the two expansion schemes for Redis data increase: vertical expansion (scale up), horizontal expansion (scale out).
- Vertical expansion: Upgrade the hardware configuration of a single Redis, such as increasing memory capacity, disk capacity, and using more powerful CPUs.
- Horizontal expansion: Increase the number of Redis instances horizontally, and each node is responsible for a part of the data.
For example, if you need a server resource with 24 GB of memory and 150 GB of disk, there are two solutions:

When facing millions and tens of millions of users, the horizontally-scaling Redis slice cluster will be a very good choice.
65 Brother: What are the advantages and disadvantages of these two solutions?
- Vertical expansion is simple to deploy, but when the amount of data is large and RDB is used to achieve persistence, it will cause blocking and slow response. In addition, limited by hardware and cost, the cost of expanding the memory is too large, such as expanding to 1T of memory.
- Horizontal expansion is easy to expand without worrying about the hardware and cost constraints of a single instance. However, slicing clusters will involve the distributed management of multiple instances. needs to solve how to reasonably distribute data to different instances, while also allowing clients to correctly access the data on the instance .
What is Cluster
Redis cluster is a distributed database solution. The cluster performs data management through sharding (a practice of "divide and conquer"), and provides replication and failover functions.
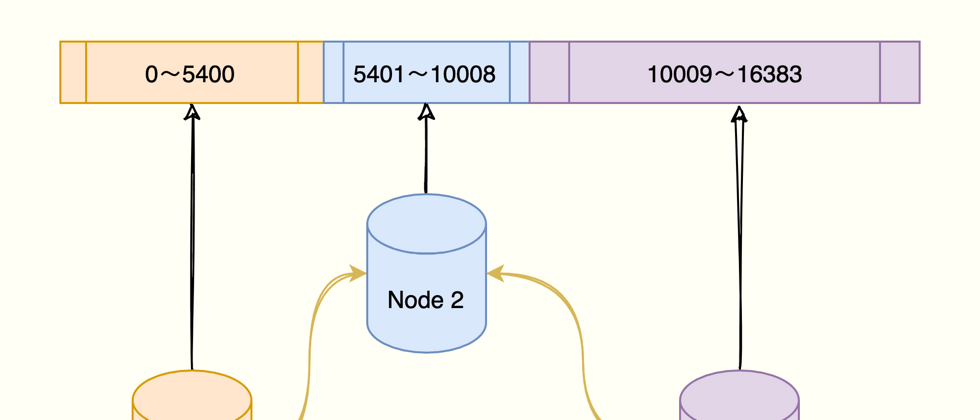
The data is divided into 16384 slots, and each node is responsible for a part of the slots. The slot information is stored in each node.
It is decentralized. As shown in the figure, the cluster is composed of three Redis nodes. Each node is responsible for a part of the data of the entire cluster, and the amount of data each node is responsible for may be different.

The three nodes are connected to each other to form a peer-to-peer cluster. They Gossip protocol. Finally, each node saves the slot allocation of other nodes.
Opening message
Technology is not omnipotent, and programmers are not the most powerful. You must figure it out and don't think that "I am number one in the world." Once we have this awareness, it may delay our growth.Technology is to solve problems. If a technology cannot solve a problem, then the technology is worthless.
Don't show off your skills, it's meaningless.
Cluster installation
Click -> " Redis 6.X Cluster to build " to view
A Redis cluster usually consists of multiple nodes (nodes). At the beginning, each node is independent of each other. They are all in a cluster that only contains their own. To form a truly working cluster, we must Connect each independent node to form a cluster containing multiple nodes.
The work of connecting each node can be CLUSTER MEET command: CLUSTER MEET <ip> <port> .
CLUSTER MEET command to a node node can make the node node and the node specified by ip and port perform a handshake (handshake). When the handshake is successful, the node node will add the node specified by ip and port to the current node node. In the cluster.

It's as if the node node said: "Hey, brother with ip = xx, port = xx, do you want to join the "Code Ge Byte" technology group, joining the cluster will find a way for the great god to grow, pay attention to "Code Ge Byte" The official account replied "Add Group", come with me if it is a brother! "
For the Redis Cluster building , please click on the bottom left corner of the article " read the original " or click -> " Redis 6.X Cluster to build " to view, please see the official details about Redis Cluster //redis.io/topics/cluster-tutorial .
Cluster implementation principle
65 Brother: After the data is sliced, the data needs to be distributed on different instances. How does the data correspond to the instances?
Starting with Redis 3.0, the official Redis Cluster solution is provided to implement slice clusters, which implements the rules of data and instances. The Redis Cluster solution uses a hash slot (Hash Slot, I will directly call it Slot) to handle the mapping between data and instances.
Follow the "code brother byte" to enter the cluster realization principle exploration journey......
Divide the data into multiple pieces and store them on different instances
The entire database of the cluster is divided into 16384 slots. Each key in the database belongs to one of these 16384 slots. Each node in the cluster can handle 0 or up to 16384 slots.
The key and hash slot mapping process can be divided into two major steps:
- According to the key of the key-value pair, use the CRC16 algorithm to calculate a 16-bit value;
- The 16-bit value is modulo 16384, and the number from 0 to 16383 represents the hash slot corresponding to the key.
Cluster also allows users to force a key to be hung on a specific slot. By embedding a tag mark in the key string, it can force the key to be hung in the same slot as the tag.
Hash slot and Redis instance mapping
65 Brother: How does the hash slot map to the Redis instance?
cluster create in the sample of the 1609ce39b71ab4 deployment cluster, Redis will automatically distribute 16384 hash slots evenly on the cluster instance, such as N nodes, and the number of hash slots on each node = 16384 / N.
In addition, you can use the CLUSTER MEET command to connect the three nodes 7000, 7001, and 7002 to a cluster, but the cluster is still offline because none of the three instances process any hash slots.
You can use the cluster addslots command to specify the number of hash slots on each instance.
65 Brother: Why do you want to make it manually?
Those who are able to work harder, the Redis instance configurations added to the cluster are different. If you bear the same pressure, it will be too difficult for garbage machines. Let the awesome machines support a little more.
For a cluster of three instances, assign hash slots to each instance through the following instructions: instance 1 is responsible for 0~5460 hash slots, instance 2 is responsible for 5461~10922 hash slots, instance 3 is responsible for 10923~16383 hash groove.
redis-cli -h 172.16.19.1 –p 6379 cluster addslots 0,5460
redis-cli -h 172.16.19.2 –p 6379 cluster addslots 5461,10922
redis-cli -h 172.16.19.3 –p 6379 cluster addslots 10923,16383The mapping relationship between key-value pair data, hash slot, and Redis instance is as follows:

The key of the Redis key-value pair is calculated by CRC16, then the total number of hash slots is 16394, and the modulus results are mapped to instance 1 and instance 2, respectively.
Remember, When 16384 slots are fully allocated, the Redis cluster can work normally .
Replication and failover
65 Brother: How does Redis cluster achieve high availability? Are Master and Slave separate from reading and writing?
The Master is used to process the slot, and the Slave node synchronizes the data of the master node Redis master-slave architecture data synchronization
When the master goes offline, the slave will continue to process the request instead of the master node. There is no read-write separation between the master and slave nodes, and the slave is only used as a high-availability backup for the downtime of the master.
Redis Cluster can set several slave nodes for each master node. When a single master node fails, the cluster will automatically promote one of the slave nodes to be the master node.
If a master node has no slave nodes, when it fails, the cluster will be completely unavailable .
However, Redis also provides a parameter cluster-require-full-coverage to allow some nodes to fail, and other nodes can continue to provide external access.
For example, the 7000 master node goes down, and 7003 as the slave becomes the Master node to continue to provide services. When the offline node 7000 comes back online, it will become the current slave node of 70003.
Fault detection
65 Brother: In " Redis High Availability Chapter: Sentinel Sentinel Cluster Principle " I know that Sentinel realizes automatic failover by monitoring, automatically switching the main library, and notifying the client. Cluster realize automatic failover?A node thinks that a certain node is disconnected does not mean that all nodes think it is disconnected. Only when most of the nodes responsible for processing the slot have determined that a node is offline, the cluster considers that the node needs a master-slave switch.
Redis cluster nodes use the Gossip protocol to broadcast their own status and changes in their perception of the entire cluster. For example, if a node finds that a node is out of connection (PFail), it will broadcast this information to the entire cluster, and other nodes can also receive this point of loss of connection information.
For the Gossip protocol, you can read an article by Wukong: "The virus invasion depends on distributed "
If a node has received the number of lost connections of a node (PFail Count) has reached the majority of the cluster, it can mark the node as a certain offline status (Fail), and then broadcast to the entire cluster, forcing other nodes to also receive the The fact that the node has gone offline, and immediately perform a master-slave switch over the missing node.
Failover
When a slave finds that its master node has entered the offline state, the slave node will start failover to the offline master node.
- Select a node from the offline Master and slave node list of the node to become the new master node.
- The new master node will revoke all slot assignments to the offline master node and assign these slots to itself.
- The new master node broadcasts a PONG message to the cluster. This PONG message allows other nodes in the cluster to immediately know that this node has changed from a slave node to a master node, and that the master node has taken over the responsibility of the offline node. Processing slot.
- The new master node starts to receive command requests related to the processing slot, and the failover is completed.
Master selection process
65 Brother: How was the new master node elected?
- The configuration epoch of the cluster is +1, which is a self-experience counter, with an initial value of 0, and it will be +1 each time a failover is performed.
- The slave node that detects that the master node goes offline broadcasts a
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUESTmessage to the cluster, requiring all master nodes that have received this message and have voting rights to vote for this slave node. - The master node has not voted for other slave nodes, then the master node will return a
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACKmessage to the slave node that requires voting, indicating that the master node supports the slave node to become the new master node. - The slave nodes participating in the election will receive the
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACKmessage. If the collected votes are >= (N/2) + 1 support, then the slave node will be elected as the new master node. - If there are no slave nodes that can collect enough support votes in a configuration epoch, the cluster enters a new configuration epoch and conducts elections again until a new master node is elected.
Similar to the sentinel, both are implemented based on the Raft algorithm, and the process is shown in the figure:

Is it feasible to store the relationship between key-value pairs and instances in a table?
65 Brother, let me test you: "The Redis Cluster solution assigns key-value pairs to different instances through hash slots. This process requires CRC calculations on the keys of key-value pairs and modulo the total number of hash slots. Map to the instance. If you use a table to directly record the correspondence between the key-value pair and the instance (for example, key-value pair 1 is on instance 2, key-value pair 2 is on instance 1), so there is no need to calculate key and hash The corresponding relationship between the slots is now available. Just look up the table. Why doesn't Redis do this?"
If you use a global table to record, if the relationship between the key-value pair and the instance changes (re-sharding, instance increase or decrease), you need to modify the table. If it is a single-threaded operation, all operations must be serialized, and the performance is too slow.
Multi-threading involves locking. In addition, if the amount of key-value pair data is very large, the storage space required to store the table data of the key-value pair and the instance relationship will also be large.
In the hash slot calculation, although the relationship between the hash slot and the instance time is also recorded, the number of hash slots is much smaller, only 16,384, and the overhead is very small.
How does the client locate the instance where the data is located
65 Brother: How does the client determine which instance the data accessed is distributed on?
The Redis instance will send its own hash slot information to other instances in the cluster through the Gossip protocol, realizing the diffusion of hash slot allocation information.
In this way, each instance in the cluster has all the mapping relationship information between the hash slots and the instance.
When slicing data, the key is calculated by CRC16 to calculate a value and then modulo 16384 to obtain the corresponding Slot. This calculation task can be executed when the client sends a request.
However, after locating the slot, you need to further locate the Redis instance where the Slot is located.
When the client connects to any instance, the instance responds to the client with the mapping relationship between the hash slot and the instance, and the client caches the mapping information between the hash slot and the instance locally.
When the client requests, it will calculate the hash slot corresponding to the key, locate the instance where the data is located through the locally cached hash slot instance mapping information, and then send the request to the corresponding instance.

Reallocate hash slots
65 Brother: What should I do if the mapping relationship between hash slots and instances has changed due to new instances or load balancing redistribution?
The instances in the cluster pass messages to each other through the Gossip protocol to obtain the latest hash slot allocation information, but the client cannot perceive it.
Redis Cluster provides a redirection mechanism: client sends the request to the instance, this instance has no corresponding data, the Redis instance will tell the client to send the request to other instances .
65 Brother: How does Redis tell the client to redirect to a new instance?
There are two situations: MOVED error, ASK error .
MOVED error
MOVED error (load balancing, data has been migrated to other instances): When the client sends a key-value pair operation request to an instance, and the slot where the key is located is not responsible for it, the instance will return A MOVED error directed to the node that is responsible for the slot.
GET 公众号:码哥字节
(error) MOVED 16330 172.17.18.2:6379The response indicates that the hash slot 16330 where the key-value pair requested by the client is located has migrated to the instance 172.17.18.2, and the port is 6379. In this way, the client establishes a connection with 172.17.18.2:6379 and sends a GET request.
At the same time, the client will also update the local cache, and update the corresponding relationship between the slot and the Redis instance to the correct .

ASK error
65 Brother: What if there is a lot of data in a slot, and part of it is migrated to a new instance, and part of it has not been migrated?
If the requested key is found on the current node, execute the command directly, otherwise, an ASK error response is required. If the slot migration is not completed, if the slot where the key to be accessed is located is being migrated from instance 1 to instance 2, instance 1. An ASK error message will be returned to the client: The hash slot of the key requested by the client is being migrated to instance 2. You first send an ASKING command to instance 2, and then send the operation command .
GET 公众号:码哥字节
(error) ASK 16330 172.17.18.2:6379For example, the client requests to locate the slot 16330 with key = "Official Account: Code Gebyte". In the instance 172.17.18.1, if node 1 can find it, it will directly execute the command, otherwise it will respond to the ASK error message and direct the client to the migration process. The target node 172.17.18.2.

Note: The ASK error command does not update the hash slot allocation information cached by the client.
Therefore, if the client requests Slot 16330 data again, it will still 172.17.18.1 instance first, but the node will respond to the ASK command to let the client send a request to the new instance.
MOVED command updates the client's local cache so that subsequent commands are sent to the new instance.
How big can the cluster be set up?
65 Brother: With Redis Cluster, I am no longer afraid of large amounts of data. Can I expand infinitely?
The answer is no, Redis officially gave the scale of Redis Cluster online is 1000 instances .
65 Brother: What exactly limits the size of the cluster?
The key lies in the communication overhead between instances. Each instance in the Cluster saves all hash slot and instance correspondence information (Slot mapping to the node table), as well as its own state information.
Each instance between the clusters spreads the data of the node Gossip Gossip protocol is roughly as follows:
- Randomly select some instances from the cluster and send
PINGmessages to the selected instances at a certain frequency to detect the status of the instances and exchange information with each other.PINGmessage encapsulates the sender's own status information, the status information of some other instances, and slot and instance mapping table information. - After the instance receives the
PINGmessage, it responds to thePONGmessage, which contains the same information as thePINGmessage.
Through the Gossip protocol between clusters, each instance can obtain the status information of all other instances after a period of time.
Therefore, when new nodes are added, node failures, and Slot mapping changes can be completed through the PING , PONG message propagation to complete the propagation and synchronization of the cluster status in each instance.
Gossip news
The structure of the message sent is composed clusterMsgDataGossip
typedef struct {
char nodename[CLUSTER_NAMELEN]; //40字节
uint32_t ping_sent; //4字节
uint32_t pong_received; //4字节
char ip[NET_IP_STR_LEN]; //46字节
uint16_t port; //2字节
uint16_t cport; //2字节
uint16_t flags; //2字节
uint32_t notused1; //4字节
} clusterMsgDataGossip;So for each instance to send a Gossip message, 104 bytes need to be sent. If the cluster is 1000 instances, then each instance will take about 10KB to PING
In addition, when the Slot mapping table is propagated between instances, each message also contains a Bitmap with a length of 16384 bits.
Each bit corresponds to a Slot. If the value = 1, it means that this Slot belongs to the current instance. This Bitmap occupies 2KB, so a PING message is about 12KB.
0609ce39b72537 is the PING . The sum of two messages is 24 KB PONG As the scale of the cluster increases, more and more heartbeat messages will occupy the network communication bandwidth of the cluster, reducing the cluster throughput.
Communication frequency of the instance
65 Brother: Brother Ma, the frequency of sending PING messages will also affect the cluster bandwidth, right?
After the Redis Cluster instance is started, by default, 5 instances are randomly selected from the local instance list every second, and then one instance that has not received the PING message for the longest time is found out of these 5 instances, and the PING message is sent to it. Instance.
65 Brother: Randomly choose 5, but there is no guarantee that the selected instance is the instance that has not received PING communication for the longest time in the entire cluster. Some instances may have not received the message, causing the cluster information they maintain to expire long ago. What should I do? ?
This is a good question. The instance of Redis Cluster will scan the list of local instances every 100 ms. When an instance is found to receive the PONG message last time> cluster-node-timeout / 2 . Then immediately send the PING message to this instance to update the cluster status information of this node.
When the cluster size becomes larger, it will further cause the network communication delay between instances. It may cause more PING messages to be sent frequently.
Reduce communication overhead between instances
- Each instance sends a
PINGmessage every second. Reducing this frequency may cause the status information of each instance of the cluster to fail to propagate in time. - Check every 100 ms
PONGmessage received exceedscluster-node-timeout / 2. This is the default periodic detection task frequency of the Redis instance, and we will not easily modify it.
Therefore, you can only modify cluster-node-timeout : the heartbeat time for judging whether the instance is faulty in the cluster, and the default is 15 S.
Therefore, To avoid excessive broadband cluster heartbeat message occupies the cluster-node-timeout transferred into 20 seconds, or 30 seconds, so PONG situation will ease message reception timeout.
However, it cannot be set too large. Both will cause the instance to fail, but you have to wait for cluster-node-timeout to detect this failure, which affects the normal service of the cluster,
to sum up
"Code Ge Byte" does not follow the trend or nonsense, and helps programmers grow.
"Redis Series" has published 7 articles so far, and each "Code Ge Byte" consumes a lot of energy and strives for perfection. Make sure that each article brings value to readers, so that everyone can get a real improvement.
- sentinel cluster realizes automatic failover , but when the amount of data is too large, it takes too long to generate RDB. When Fork is executed, it will block the main thread. Because the amount of data is too large, the main thread is blocked for too long, so Redis responds slowly.
- Using Redis Cluster mainly solves various slow problems caused by large data storage, and it is also convenient for horizontal expansion. When facing millions and tens of millions of users, the horizontally-scaling Redis slice cluster will be a very good choice.
- The entire database of the cluster is divided into 16384 slots. Each key in the database belongs to one of these 16384 slots. Each node in the cluster can handle 0 or up to 16384 slots.
- Redis cluster nodes use the Gossip protocol to broadcast their own status and changes in their perception of the entire cluster.
- After the client connects to any instance of the cluster, the instance sends the hash slot and instance mapping information to the client, and the client saves the information to locate the key to the corresponding node.
- The cluster cannot increase indefinitely. Because the cluster
Gossipprotocol, the communication frequency is the main reason for limiting the size of the cluster. The frequencycluster-node-timeout

Originality is not easy. If you think the article is good, I hope readers and friends will like, collect and share.


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。