
Kafka is a very popular messaging middleware. According to the official website, thousands of companies are already using it. Recently, I practiced a wave of Kafka, which is really good and powerful. Today we will learn about Kafka from three aspects: the installation of Kafaka under Linux, the visualization tool of Kafka, and the combination of Kafka and SpringBoot. I hope everyone can quickly get started with Kafka and master this popular messaging middleware after reading it!
SpringBoot actual combat e-commerce project mall (40k+star) address: https://github.com/macrozheng/mall
Introduction to Kafka
Kafka is an open source distributed message flow platform developed LinkedIn The main function is to provide a unified, high-throughput, low-latency platform for processing real-time data. Its essence is a message engine system publish-subscribe mode.
Kafka has the following characteristics:
High throughput and low latency: Kafka sends and receives messages very quickly, and the delay in processing messages using clusters can be as low as 2ms.High scalability: Kafka can be flexibly expanded and contracted, can be expanded to thousands of brokers, hundreds of thousands of partitions, and can process trillions of messages every day.Permanent storage: Kafka can safely store data in a distributed, durable, fault-tolerant cluster.High availability: Kafka can effectively expand the cluster in the availability zone. If a node is down, the cluster can still work normally.
Kafka installation
We will use the installation method under Linux, and the installation environment is CentOS 7.6. Docker is not used to install and deploy here, I personally feel that it is easier to install directly (mainly because the official does not provide a Docker image)!First we need to download the installation package of Kafka, the download address: https://mirrors.bfsu.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz

After the download is complete, unzip Kafka to the specified directory:
cd /mydata/kafka/
tar -xzf kafka_2.13-2.8.0.tgzAfter decompression is complete, enter the decompression directory:
cd kafka_2.13-2.8.0Although there is news that Kafka is about to remove Zookeeper, it has not been removed in the latest version of Kafka, so you still need to start Zookeeper before starting Kafka;

Start the Zookeeper service, the service will run on port2181
# 后台运行服务,并把日志输出到当前文件夹下的zookeeper-out.file文件中
nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zookeeper-out.file 2>&1 &Since Kafka is currently deployed on a Linux server, if you want to access the external network, you need to modify the Kafka configuration fileconfig/server.propertiesand modify the listening address of Kafka, otherwise you will not be able to connect;
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.5.78:9092Finally, start the Kafka service, and the service will run on port9092
# 后台运行服务,并把日志输出到当前文件夹下的kafka-out.file文件中
nohup bin/kafka-server-start.sh config/server.properties > kafka-out.file 2>&1 &Kafka command line operation
Next, we use the command line to operate Kafka and get familiar with the use of Kafka.First create a TopicconsoleTopic
bin/kafka-topics.sh --create --topic consoleTopic --bootstrap-server 192.168.5.78:9092Next check Topic;
bin/kafka-topics.sh --describe --topic consoleTopic --bootstrap-server 192.168.5.78:9092The following Topic information will be displayed;
Topic: consoleTopic TopicId: tJmxUQ8QRJGlhCSf2ojuGw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: consoleTopic Partition: 0 Leader: 0 Replicas: 0 Isr: 0Send a message to Topic:
bin/kafka-console-producer.sh --topic consoleTopic --bootstrap-server 192.168.5.78:9092Enter the information directly in the command line to send;

Reopen a window and get the message from Topic through the following command:
bin/kafka-console-consumer.sh --topic consoleTopic --from-beginning --bootstrap-server 192.168.5.78:9092
Kafka visualization
It is indeed a bit troublesome to use the command line to operate Kafka. Next, let's try the visualization tool kafka-eagle .Install JDK
If you are using CentOS, the full version of JDK is not installed by default, you need to install it yourself!Download JDK 8, download address: https://mirrors.tuna.tsinghua.edu.cn/AdoptOpenJDK/

After the download is complete, unzip the JDK to the specified directory;
cd /mydata/java
tar -zxvf OpenJDK8U-jdk_x64_linux_xxx.tar.gz
mv OpenJDK8U-jdk_x64_linux_xxx.tar.gz jdk1.8Add the environment variableJAVA_HOMEin the/etc/profilefile.
vi /etc/profile
# 在profile文件中添加
export JAVA_HOME=/mydata/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
# 使修改后的profile文件生效
. /etc/profileInstall kafka-eagle
kafka-eagleDownload the installation package ofkafka-eaglehttps://github.com/smartloli/kafka-eagle-bin/releases

After the download is complete,kafka-eagleto the specified directory;
cd /mydata/kafka/
tar -zxvf kafka-eagle-web-2.0.5-bin.tar.gzAdd the environment variableKE_HOMEin the/etc/profilefile;
vi /etc/profile
# 在profile文件中添加
export KE_HOME=/mydata/kafka/kafka-eagle-web-2.0.5
export PATH=$PATH:$KE_HOME/bin
# 使修改后的profile文件生效
. /etc/profileInstall MySQL and add the databaseke, it will be used afterkafka-eagleModify the configuration file$KE_HOME/conf/system-config.properties, mainly to modify the Zookeeper configuration and database configuration, comment out the sqlite configuration, and use MySQL instead;
######################################
# multi zookeeper & kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=localhost:2181
######################################
# kafka eagle webui port
######################################
kafka.eagle.webui.port=8048
######################################
# kafka sqlite jdbc driver address
######################################
# kafka.eagle.driver=org.sqlite.JDBC
# kafka.eagle.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
# kafka.eagle.username=root
# kafka.eagle.password=www.kafka-eagle.org
######################################
# kafka mysql jdbc driver address
######################################
kafka.eagle.driver=com.mysql.cj.jdbc.Driver
kafka.eagle.url=jdbc:mysql://localhost:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=rootUse the following command to startkafka-eagle;
$KE_HOME/bin/ke.sh startAfter the command is executed, the following information will be displayed, but it does not mean that the service has been started successfully, and you need to wait for a while;

Introduce a few usefulkafka-eaglecommands:
# 停止服务
$KE_HOME/bin/ke.sh stop
# 重启服务
$KE_HOME/bin/ke.sh restart
# 查看服务运行状态
$KE_HOME/bin/ke.sh status
# 查看服务状态
$KE_HOME/bin/ke.sh stats
# 动态查看服务输出日志
tail -f $KE_HOME/logs/ke_console.outIt can be accessed directly after the startup is successful. Enter the account passwordadmin:123456and the access address: http://192.168.5.78:8048/

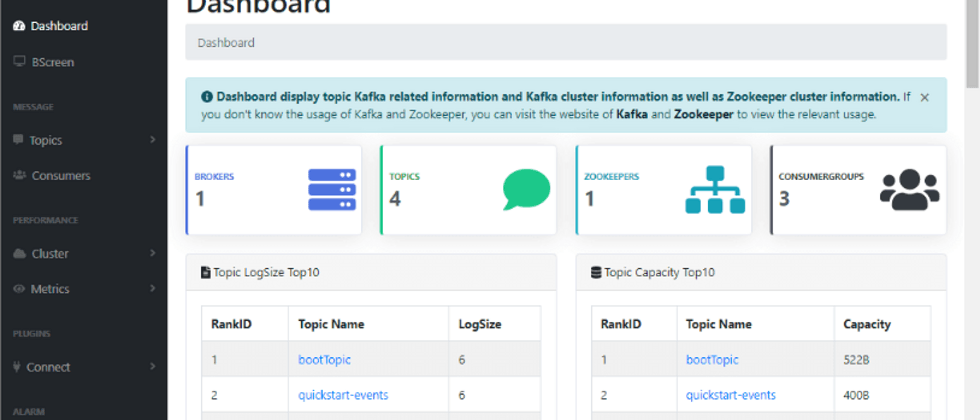
After successfully logging in, you can access the Dashboard, and the interface is still great!

Visualization tool usage
Before we created Topic using the command line, here you can create it directly through the interface;

We can also send messageskafka-eagle

We can consume the messages in Topic through the command line;
bin/kafka-console-consumer.sh --topic testTopic --from-beginning --bootstrap-server 192.168.5.78:9092The information obtained by the console is displayed as follows;

There is also a very interesting function calledKSQL, which can query the messages in Topic through SQL statements;

Visualization tools are naturally indispensable for monitoring. If you want to enablekafka-eagleon Kafka, you need to modify the Kafka startup script to expose the JMX port;
vi kafka-server-start.sh
# 暴露JMX端口
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
fiLook at the monitoring chart interface;

There is also a very irritating large-screen monitoring function;

There is also the command line function of Zookeeper. In short, the function is very complete and very powerful!

SpringBoot integrates Kafka
Operating Kafka in SpringBoot is also very simple. For example, Kafka's message mode is very simple, there is no queue, only Topic.First add Spring Kafka dependencypom.xml
<!--Spring整合Kafka-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.1</version>
</dependency>Modify the application configuration fileapplication.yml, configure the Kafka service address and consumergroup-id;
server:
port: 8088
spring:
kafka:
bootstrap-servers: '192.168.5.78:9092'
consumer:
group-id: "bootGroup"Create a producer to send messages to Kafka's Topic;
/**
* Kafka消息生产者
* Created by macro on 2021/5/19.
*/
@Component
public class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void send(String message){
kafkaTemplate.send("bootTopic",message);
}
}Create a consumer to obtain and consume messages from Kafka;
/**
* Kafka消息消费者
* Created by macro on 2021/5/19.
*/
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics = "bootTopic")
public void processMessage(String content) {
log.info("consumer processMessage : {}",content);
}
}Create an interface for sending messages and call the producer to send messages;
/**
* Kafka功能测试
* Created by macro on 2021/5/19.
*/
@Api(tags = "KafkaController", description = "Kafka功能测试")
@Controller
@RequestMapping("/kafka")
public class KafkaController {
@Autowired
private KafkaProducer kafkaProducer;
@ApiOperation("发送消息")
@RequestMapping(value = "/sendMessage", method = RequestMethod.GET)
@ResponseBody
public CommonResult sendMessage(@RequestParam String message) {
kafkaProducer.send(message);
return CommonResult.success(null);
}
}Call the interface directly in Swagger for testing;

The project console will output the following information, indicating that the message has been received and consumed.
2021-05-19 16:59:21.016 INFO 2344 --- [ntainer#0-0-C-1] c.m.mall.tiny.component.KafkaConsumer : consumer processMessage : Spring Boot message!to sum up
Through a wave of practice in this article, everyone can basically get started with Kafka. Installation, visualization tools, combined with SpringBoot, these are basically developer-related operations, and they are also the only way to learn Kafka.
Reference
Kafka official document: https://kafka.apache.org/quickstartkafka-eagleofficial document: http://www.kafka-eagle.org/articles/docs/introduce/getting-started.htmlKafka related concepts: https://juejin.cn/post/6844903495670169607
Project source code address
https://github.com/macrozheng/mall-learning/tree/master/mall-tiny-kafka
This article GitHub https://github.com/macrozheng/mall-learning has been included, welcome to Star!

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。