
01 Foreword
Hello, it hasn't been updated for a long time. Because I was interviewing recently. It took two weeks to prepare and took 5 offers within 3 days. Finally, I chose a unicorn offer from an Internet industry in Guangzhou. I just joined yesterday. These few days have just sorted out the interesting questions that were asked in the interview, and I also take this opportunity to share with you.
The interviewer of this company is a bit interesting. On the one hand, he is a younger brother of the same age and chatted together for two hours. The second side is an architect from Ali. He asked a scenario question:
The database has a field of string type, and the URL is stored. How to design an index?
At that time, I gave split field: the first half of the url must have a low degree of discrimination, and it is only high in the second half; I divided the high and low discrimination into two fields for storage, and created it in the field with high discrimination. index specific answers, and made maximize discrimination ideas.
The interviewer also approved my direction, but asked me if I have any other plans. I didn't answer it at the time. After I went back, I checked the information myself, and I will share with you the specific design plan here.
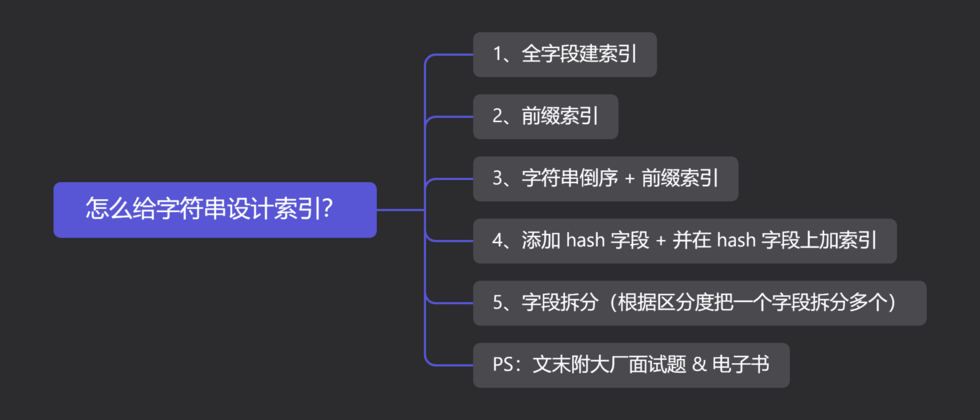
International practice, first on the mind map:

02 Entire field plus index
First show the table design:
CREATE TABLE IF NOT EXISTS `t`(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`url` VARCHAR(100) NOT NULL,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;Table data:

In fact, this question = string how to design index? , you might say that it is enough to execute the following statement directly?
alter table t add index index_url(url);I randomly drew a picture, the structure of the MySQL index_url is like this:

Indeed, this is possible. The execution of the following query statement only requires to scan once.
select id,url from t where url='javafish/nhjj/mybatis';But it still has a problem that wastes storage space . In this case, only suitable for storing short data and high enough discrimination (this is necessary, otherwise we will not build indexes on fields with low discrimination. ) . If you think about the entire field being so long, it must be a thief.
Is there a less space-consuming method? We naturally think of MySQL's prefix index .
03 prefix index
For the above table data, add a prefix index, there is no need to index the entire field, so you can build an index like this:
alter table t add index index_url(url(8));At this time, the structure of index_url is like this:

select id,url from t where url='javafish/nhjj/mybatis';Execute the same sql query, its process is like this:
- From the index_url index tree, find
javafish, and the first one found is ID1; the row with the primary key value of ID1 is found on the primary key, and it is judged that the value of url is notjavafish/nhjj/mybatis, and this row is discarded; - Take the next record of the location ID1 that was just found, and find that it is still
javafish, take out ID2, and then take the entire row on the ID index and judge that it is still wrong; - Repeat the previous step until the value obtained on index_url is not
javafish, the loop ends. In this process, to retrieve data from the primary key index 6 times, which means that 6 rows of are scanned. Through this comparison, you can easily find that after using the prefix index, may cause the query statement to read more data .
When we increase the length of the url prefix index to 10. You will find that executing the same query statement only needs scan 1 row to get the target data.
3.1 Prefix length selection
Seeing this, you may have also found out. uses the prefix index and defines the length, which can save space without adding too much additional query cost. Its choice is particularly critical . When there is little data, we can judge the choice of prefix length with the naked eye. How should we judge the data when the amount of data is large?
At this time, my mind keeps thinking, we can think that MySQL has count distinct de-counting operation, so we can execute the following sql to see what prefix length is appropriate.
select count(distinct url) as L from t;You can do batch operations like this:
SELECT
count( DISTINCT LEFT ( url, 8 ) ) AS L8,
count( DISTINCT LEFT ( url, 9 ) ) AS L9,
count( DISTINCT LEFT ( url, 10 ) ) AS L10,
count( DISTINCT LEFT ( url, 11 ) ) AS L11
FROM
t;The result is this:

The principle of our choice of prefix length is: high discrimination + less space ; considering the two factors, I will choose 10 as the length of the prefix index.
3.2 Insufficiency of prefix index
Although the prefix index is good, it has some shortcomings. For example, we said above, the length of the selection, it might lead to number of scanning lines increases .
Another point is that the prefix index is used. When you optimize sql, cannot use the index to cover the optimization point of not sure about index coverage suggest to read this article 160bf006a39ab7 "MySQL Index Principles"
For example: even if you modify the definition of index_url to the prefix index of url (100), at this time, although index_url already contains all the information, InnoDB still has to go back to the id index and check again, because the system is not sure about the prefix index Whether the definition of is truncated the complete information.
This is also a consideration for whether you choose a prefix index.
04 other ways
The above URLs are relatively short, and prefix index can also be used. Suppose the URL suddenly becomes longer (don’t ask why, it can become longer and thicker), and it grows like this:

Since the distinction of prefixes is really not high, the distinction is ideal when the minimum length is> 20. index is selected, the larger the disk space occupied, the less index values that can be placed on the same data page, and the lower the search efficiency.
Is there any other way to ensure the degree of distinction without taking up so much space?
Yes, such as: reverse order storage and add hash field
4.1 Reverse order storage
Let me talk about the first one. When storing URLs, store them in reverse order. At this time, the distinction of prefixes is very high, and the prefix index is established in reverse order. When querying, you can use the reverse function to check:
select url from t where url = reverse('输入的 url 字符串');4.2 Hash field
an integer field to the data table, which is used as the check code of the url, and at the same time establishes an index .
alter table t add url_crc int unsigned, add index(url_crc);When inserting, you can do this: call MySQL's crc32 function to calculate a checksum and save it in the library.
INSERT INTO t VALUE( 00000000007, 'wwww.javafish.top/article/erwt/spring', CRC32('wwww.javafish.top/article/erwt/spring'))Then insert such a result after execution.

But one thing to note is that every time a new record is inserted, the crc32 () function is used to get the check code to fill in this new field at the same time, and there may be conflicts.
That is to say, the results obtained by the crc32 () function of two different URLs may be the same, so the where part of the query statement needs to determine whether the value of the URL is the same:
select url from t where url_crc = crc32('输入的 url 字符串') and url = '输入的 url 字符串'In this way, it is equivalent to reducing the index length of the URL to 4 bytes, shortening the storage space and improving query efficiency.
4.3 Comparison of the two
: 160bf006a39c39 range query not supported.
The index created on the field stored in reverse order is sorted in the reverse order string, there is no way to use the index to perform range query. Similarly, the hash field method can only support equivalent queries.
The difference between them is mainly reflected in the following three aspects:
- Judging from the extra space , the reverse storage method is on the primary key index and does not consume additional storage space, while the hash field method requires an additional field. Of course, using a 4-byte prefix length for reverse storage should not be enough. If it is longer, this consumption is almost offset by the additional hash field.
- In CPU consumption , the reverse function requires an additional call to the reverse function each time it is written and read, while the hash field method requires an additional call to the crc32 () function. If you only look at the computational complexity of these two functions, the additional CPU resources consumed by the reverse function will be smaller.
- From the query efficiency , the query performance using the hash field method is relatively more stable. Because the value calculated by crc32 has a probability of conflict, but the probability is very small, it can be considered that the average number of scan rows per query is close to 1. After all, the reverse storage method still uses the prefix index method, which means that it will still increase the number of scan lines.
05 Summary
This article talks about four solutions, each of which has advantages and disadvantages. There is no way to judge which is the best, only the most suitable. In the development, you also need to choose according to the business, the general direction is: improve the degree of distinction & minimize the space occupied.
- Create a complete index directly, which may take up more space;
- Create a prefix index to save space, but it will increase the number of query scans, and you cannot use a covering index;
- Store in reverse order, and then create a prefix index to bypass the problem of insufficient discrimination of the prefix of the string itself;
- Create a hash field index, the query performance is stable, there is additional storage and calculation consumption, like the third method, does not support range scan.
06 Reference
- time.geekbang.org/column/article/71492
- cnblogs.com/Mr-Echo/p/12730797.html
07 Dachang Interview Questions & E-books
If you see this, and if you like this article, please help look good at .
When I first met, I didn't know what to give you. Simply send hundreds of e-books and 2021 latest interview materials . WeChat search JavaFish reply e-book to give you 1000+ programming e-books; reply interview to give you some interview questions; reply 1024 to give you a complete set of video tutorials.
Face questions all have answers, detailed as follows: there is a need to come and collect it, absolutely free, no routines get .



**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。