
TL;DR
- We need better metadata management of the container supply chain for better analysis;
- The OCI specification currently has no way to package container image artifacts or a set of container images. But they will do it slowly;
- At the same time, we need a package manager for container images;
Some background
I maintain an Tern , which is to generate a software bill of materials (SBOM) for container images. Many components installed in the container image are installed independently, rather than through the package manager. This makes it difficult for us to figure out the intention of the author who created this container image. It also did not provide more information about the contributors of the container image. Most container images are based on previously existing container images, and it is difficult to see this information through client tools or mirror warehouses.
I think if there is a "container mirror" package manager, it should be able to solve this problem. Therefore, I KubeCon 2018 . I asked whether the manifest of the container image can save this information so that the tool can analyze it according to the supply chain of the container image.
It turns out that the community is already considering how to manage things such as helm chart, OPA strategy, file system and signatures. This is why I participated in Open Container Project (OCI) to organize (I still owe @vbatts a favor to introduce me). The understanding at the time was that, in addition to the identification of the container image through the summary, no other management was required. There is also no need to manage dependencies, because all dependencies are packaged into the container image. Updates are handled by rebuilding the container again and keeping a scrolling label that downstream consumers can pull.
However, in addition to portability, the container ecology does not provide much. Managing container metadata together with container images can provide users and contributors with more valuable information about the supply chain. After two years and several supply chain attacks, we are still discussing how to best do this. Here, I try to summarize some of the proposed concepts and see how they meet our requirements for metadata management.
Back to the beginning
We write a package manager mainly for the following three reasons:
- Identification-Provide a name and other uniquely identifiable characteristics for your new file or package;
- Context-understand the relationship between your package and other packages (ie, dependency management);
- Freshness-to ensure that your package is maintainable and updated in its ecosystem;
There is actually a fourth reason, "build repeatability"-I think it belongs to the "context", but here, it is really worth mentioning, because it is necessary to understand the state of your package at a specific time. In this way, you can analyze the "good" state in the past and the "not so good" state in the present, that is, use the bisection method to analyze and build.
Due to some (good faith) assumptions, the container image ecosystem does not have these functions. A container can be identified by its digest. You don't need to manage the ecology, because the entire ecology already exists in one unit. You don't need to update the container-just build a new image and everything that needs to be updated will be updated. As long as your application is okay, it can work normally. However, if you plan to maintain your application for a long time, you must be prepared to deal with stack updates and major releases. We currently have no good way to manage stack updates other than "download the latest version" (a notable exception is Cloud Native Buildpacks, but we will focus on general cases here). Destructive changes to the stack may prevent you from rebuilding the image, which forces you to keep an old version of the image because you already know that the image will work. As you can imagine, maintaining a set of container images will become more laborious. It would be great if the information needed to maintain a set of container images is built-in and available when needed.
Mirror warehouse for managing metadata
We can build a separate metadata storage solution, but now we have a mirror warehouse. With some improvements, they can be used to store supplementary metadata along with container images. The organization has already done this for the source image containing the source tarball and the signed payload (as cosign did).
The advantage of using a mirror repository is that metadata can be stored with the target mirror. The recommendations to the OCI specification mainly involve structuring and citing these data. This is basically server-side package management. It is very difficult for these suggestions to be merged, because the current client-server relationship is very close, and any changes to the server will affect the client. The packaging mechanism for the client Any changes to will also affect the server. Therefore, the current OCI specification cannot include enhanced features in addition to extending the specification to keep pace with the current Docker client and Docker registry working methods.
This article is not to criticize the current ecology, but to lead the conversation to a place where the community can maintain their container mirrors more sustainably. Personally, I also want to prove that a package manager is needed in the field of container mirroring, although the mirror warehouse can support the link between related artifacts and container mirrors, and it can also support the link between container mirrors.
Package managers in other ecosystems also have a client-server relationship, so the architecture of sharing the pressure between the client and the server is not new. It's just that in the current scenario, this relationship is slightly different.
Identification
Container mirroring works a bit like Merkle Tree has a mirror configuration data block, and one or more data blocks representing the container file system. Each data block has been hashed and placed in the Image Manifest that has been hashed.

This package can now be identified very well, but it lacks other identifiable features, the most obvious being the name and version. In the container world, the name is usually the name of a mirror repository, and the version is usually a tag.

Just like Git, all references to filesets are hash values, and other references can point to them, such as HEAD , FETCH_HEAD or tag. Tags can follow semantic version control and can be moved to another commit. No one in the open source world does this because it would break the inherent contract between the project maintainer and other members of the community. The tag of the container image does not need to follow the rules of semantic version control, but many language package managers rely on it, so there is a certain hope for using semantic versioning to control the container image.
In any case, the hash value is a pretty good identifier for the container image.
What about other identifiable characteristics? Here are some features used by other package managers:
- License and copyright information
- Author/supplier
- Release date
- Link to source code
- List of third-party components (operating system used, packages that need to be pre-installed, etc.)
The last item may become quite long, because the actual third-party components required to create a container image may reach hundreds. Recently, I have been advocating that this information should be placed in an SBOM (software material list) along with the container image. The container image signature is another artifact that can be propagated with the container image, such as the separate front of the image list, or a signature payload.
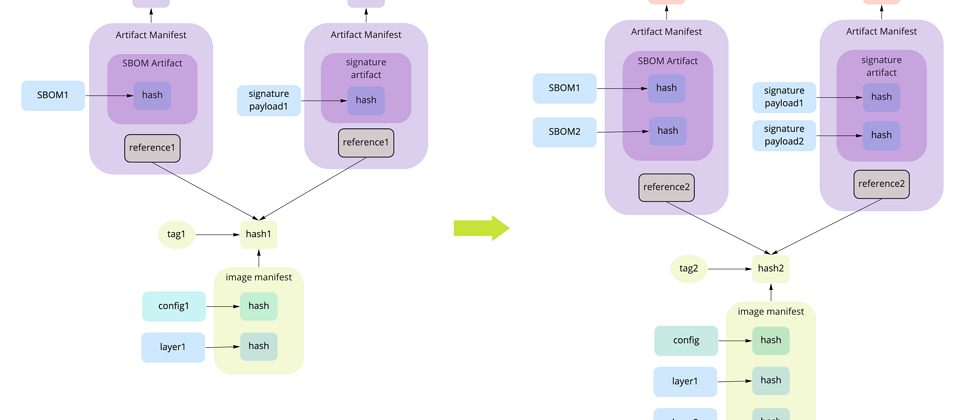
We now have identification artifacts for multiple container images, and we want to associate them with the container image. The current OCI recommends using references (reference), a reference is a list that contains the hash of the blob and its reference list. In our example, the reference is the hash value of the image manifest.

There are still some problems with this layout:
- The registry may only recognize marked artifacts, so it will delete anything that is not marked;
- Deleting the mirror will result in a null reference;
A quick solution might be to mark all the lists.

This means that something needs to be able to track tags and their relationships, as well as track the versions of all artifacts.
A long-term solution might be to define a canonical list of artifacts that the registry will recognize and treat it as a special existence. If this is the case, then you need to calculate or track the number of citations associated with each listing.

Registry implementers can follow the links in the graph in any way they want. For example, in this figure, the number of references to each list will be tracked (minus the hash), but when the mirror list is deleted, the operation will walk down the tree to the end of each reference, and follow a certain Delete them in the order in which they are referenced until the reference count is 0.

But here, in order to track all related objects, we are entering some complex tracking systems. This is package management done on the registry side. An argument can be made to implement a neutral garbage collector, which can be used by the registry or the client, but we are now a bit ahead.
I hope this is enough to show that it is necessary to track the collection of artifacts, whether on the client side or the server side, or both.
Context
It is understood that a container has no external dependencies at runtime. However, when building, the final container image does depend on the state of the initial container image, which is usually the image defined by FROM Due to the magic of Merkle Trees, there is no connection between the derived mirror image and the previous mirror image. Therefore, all references to the old image need to be created once for the new image, and some additional artifacts need to be added.

Compared with the normal citation mechanism, the artifact list mechanism may have an advantage, because the number of citations is kept to a minimum while the artifact metadata is updated.

Both of these mechanisms support the requirements of supply chain security, chain of custody, and genealogical checks. Both of these mechanisms require reference management . In the former, the client will copy the SBOM and signature list of the original image, update its reference, and add a new list. In the latter, the client must download the artifact list, supplement it, and push it along with the new container image. Either way, the client needs to understand some syntax, whether it is tag name, artifact structure, or artifact type, not to mention some understanding of the ecosystem from which the artifact comes. (SBOMs and signatures are just two common types of work that can be included).
One use case I have been considering is how to link a series of images together to describe a cloud native application. For example, a jaeger application is actually a collection of containers with its own dependency graph,
If these links can be described in a format that can be uploaded to the registry, then the entire image can be transferred between the registries together with its supplementary artifacts.

This is the marginal part of my imagination (my diagram is too complicated), but I hope these use cases show that if a package manager is not needed now, it will soon be needed to manage these high-level relationships.
Update
This is where I hope that semantic version control can be taken more seriously. The package manager uses semantic version control to allow a series of compatible versions across the stack. This allows downstream consumers to adapt to the update with minimal disruption. At present, since container images can only be identified by their abstracts, tag is the only way to identify the version of the container image. This is where the package manager is really useful.
Normally, the client queries the server to see if any packages required by their application have been updated. The client then tells the user that the update they want to download is available, and if the user has a compatible version range of their application, the client will download the new version within this range.
The current distribution SPEC supports listing tags. In addition, the registry does not provide any way to manage updates, maybe this is all the registry side needs. This also means that the work of checking and updating mainly falls on the client.
Next step
The community agreed that these proposals are too big to accept for the current SPEC project. However (hopefully) there will be an open dialogue trying to break down these changes into absorbable parts, thereby allowing backward compatibility with the current state and pushing the norm forward.
Maybe in the future, there is no need to have a package manager, because the registry, mirror and artifact formats are responsible for providing all the information needed for the inference supply chain. But at that time a distant future, during this period, we need something to fill the gap, which is a package manager.
Original author of this article nishakm Original address: https://nishakm.github.io/code/metadata/ Authorized translation
Welcome to subscribe to my article public account【MoeLove】







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。