
In recent years, with the development of real-time communication technology, online meetings have gradually become an indispensable and important office tool in people’s work. According to incomplete statistics, about 75% of online meetings are pure voice meetings, that is, there is no need to turn on the camera and Screen sharing function. At this time, the voice quality and clarity in the meeting are crucial to the online meeting experience.
Author|Seven Qi
Review|Taiyi
Preface
In real life, the meeting environment is extremely diverse, including open noisy environments, instantaneous non-stationary keyboard tapping sounds, etc. These put forward a great deal to the traditional speech front-end enhancement algorithms based on signal processing. challenge. At the same time, with the rapid development of data-driven algorithms, academia [1] and industry [2,3,4] gradually emerged intelligent speech enhancement algorithms for deep learning, and achieved good results, the AliCloudDenoise algorithm In this context, it came into being. With the help of neural network's excellent nonlinear fitting ability, combined with traditional speech enhancement algorithms, in continuous iterative optimization, the noise reduction effect and performance consumption in real-time conference scenes are carried out. After a series of optimizations and improvements, it can finally maintain high voice fidelity while fully ensuring the noise reduction capability, providing an excellent voice conference experience for the Alibaba Cloud video cloud real-time conference system.


The development status of speech enhancement algorithms
Speech enhancement refers to a technology that requires a certain method to filter out the noise when clean speech is interfered by various noises in real life scenarios to improve the quality and intelligibility of the speech. In the past few decades, traditional single-channel speech enhancement algorithms have been rapidly developed, which are mainly divided into time domain methods and frequency domain methods. The time domain method can be roughly divided into parameter filtering method [5,6] and signal subspace method [7], and frequency domain methods include spectral subtraction, Wiener filtering and speech amplitude spectrum estimation methods based on minimum mean square error. [8,9] etc.
The traditional single-channel speech enhancement method has the advantages of small calculation amount and real-time online speech enhancement, but its ability to suppress non-stationary sudden noises, such as the sudden car whistle on the road, etc., is enhanced by traditional algorithms. There will be a lot of residual noise, which will cause poor subjective hearing and even affect the intelligibility of voice information. From the perspective of algorithmic mathematical theory derivation, traditional algorithms still have the problem of too many assumptions in the process of analytical solution solving, which makes the effect of the algorithm have a clear upper limit, and it is difficult to adapt to complex and changeable actual scenarios. Since 2016, deep learning methods have significantly improved the performance of many supervised learning tasks, such as image classification [10], handwriting recognition [11], automatic speech recognition [12], language modeling [13] and machine translation [14] ] And so on, many deep learning methods have also appeared in speech enhancement tasks.

Figure 1 The classic algorithm flow chart of the traditional single-channel speech enhancement system
Speech enhancement algorithms based on deep learning can be roughly divided into the following four categories according to different training targets:
• Hybrid method based on traditional signal processing
This type of algorithm mostly replaces one or more sub-modules of the traditional speech enhancement algorithm based on signal processing by a neural network, and generally does not change the overall processing flow of the algorithm. A typical representative is Rnnoise [15].
• Speech enhancement algorithm based on time-frequency mask approximation (Mask_based method)
This type of algorithm trains a neural network to predict the time-frequency mask, and applies the predicted time-frequency mask to the frequency spectrum of the input noise to reconstruct a pure speech signal.
Commonly used time-frequency masks include IRM[16], PSM[17], cIRM[18], etc. The error function during training is shown in the following formula:

• Speech enhancement algorithm based on feature mapping (Mapping_based method)
This type of algorithm realizes the direct mapping of features by training a neural network. Common features include amplitude spectrum, logarithmic power spectrum and complex spectrum, etc. The error function during training is shown in the following equation:

• Based on end-to-end speech enhancement algorithm (End-to-end method)
This type of algorithm takes the data-driven idea to its extreme. Under the premise of reasonable data set distribution, it ignores frequency domain transformation and directly performs end-to-end numerical mapping from time-domain speech signals. It has been widely active in academia in the past two years. One of the research directions.
AliCloudDenoise speech enhancement algorithm
1. Algorithm principle
After comprehensively considering business usage scenarios and weighing many factors such as noise reduction effect, performance overhead, and real-time performance, the AliCloudDenoise speech enhancement algorithm adopts the Hybrid method, which uses the ratio of the noise energy in the noisy speech to the target human voice energy as the fitting The goal is to use traditional signal processing gain estimators such as the minimum mean square error short-time spectral amplitude (MMSE-STSA) estimator to obtain the denoising gain in the frequency domain, and finally obtain the enhanced time-domain speech through inverse transformation signal. In the choice of network structure, taking into account real-time performance and power consumption, abandoning the RNN structure and choosing the TCN network, the basic network structure is shown in the following figure:

2. Algorithm optimization in real-time meeting scenarios
1. What should I do if there are too many people next to me during a meeting?
Problem background
In real-time conference scenarios, a common type of background noise is Babble Noise, which is the background noise composed of the conversations of multiple speakers. This type of noise is not only non-stationary, but also similar to the target speech component of the speech enhancement algorithm. In the process of suppressing this kind of noise, the difficulty of algorithm processing increases. A specific example is listed below:

Problem analysis and improvement plan
After analyzing dozens of hours of audio in office scenes containing Babble Noise, combined with the human voice vocalization mechanism, it is found that this type of noise has the characteristics of long-term stable existence. As we all know, in the speech enhancement algorithm, the contextual information (contextual information) The effect of the algorithm has a very important impact, so for Babble Noise, a type of noise that is more sensitive to contextual information, the AliCloudDenoise algorithm systematically aggregates the key stage features in the model through dilated convolutions, and explicitly increases Feel the wild, and additionally incorporate gating mechanisms, so that the improved model has a significant improvement in the processing effect of Babble Noise. The following figure shows the comparison of the key model parts before improvement (TCN) and after improvement (GaTCN).

The results on the voice test set show that the proposed GaTCN model under the IRM target voice quality PESQ[19] is 9.7% higher than the TCN model, and the speech intelligibility STOI[20] is 3.4% higher than the TCN model; in Mapping a The priori SNR [21] target voice quality PESQ is improved by 7.1% compared with the TCN model, and the speech intelligibility STOI is improved by 2.0% compared with the TCN model, and it is better than all baseline models. See Table 1 and Table 2 for details of indicators.

Table 1 Comparison details of objective index voice quality PESQ

Table 2 Comparison of objective indicators of speech intelligibility STOI
Improved effect display:

2. How can you drop words at a critical moment?
Problem background
In the speech enhancement algorithm, the phenomenon of swallowing or disappearing of specific words such as the disappearance of the end of a sentence is an important factor that affects the subjective listening sense of the enhanced speech. In the real-time meeting scene, due to the variety of languages involved, the speaker speaks a variety of content , This phenomenon is more common, the following is a specific example:
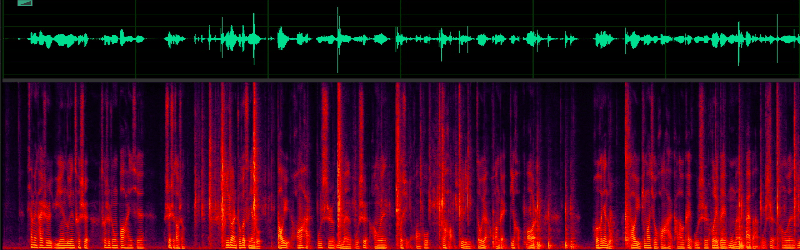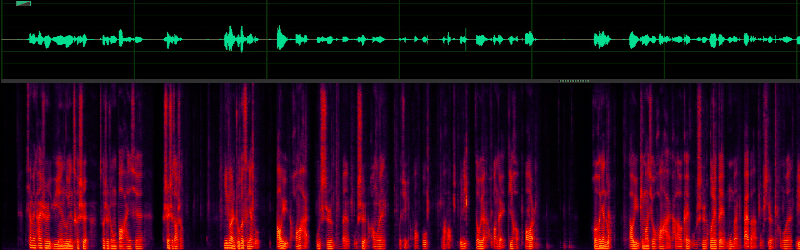
Problem analysis and improvement plan
On the 1w+ speech test data set constructed by classification, by counting the timing of the phenomenon of swallowing and dropping characters after enhancement, and visualizing the corresponding frequency domain characteristics, it is found that the phenomenon mainly occurs in unvoiced, repetitive and long tones. At the same time, in the classification statistics with the signal-to-noise ratio as the dimension, it is found that the phenomenon of swallowing and dropping characters under the condition of low signal-to-noise ratio has increased significantly. Based on this, the following three aspects have been carried out. Improve:
• At the data level: First, the distribution statistics of specific phonemes in the training data set are carried out, and after a relatively small conclusion is drawn, the speech components in the training data set are enriched in a targeted manner.
• Noise reduction strategy level: To reduce the low signal-to-noise ratio, use a combined noise reduction strategy in specific situations, that is, perform traditional noise reduction first, and then perform AliCloudDenoise noise reduction. The disadvantages of this method are reflected in the following two aspects. First, combined reduction Noise will increase the algorithm overhead. Secondly, traditional noise reduction will inevitably cause spectrum-level sound quality damage, which will reduce the overall sound quality. This method can indeed improve the phenomenon of swallowing and dropped characters, but it has not been used online because of its obvious shortcomings.
• Training strategy level: After targeted enrichment of the speech components in the training data set, it will indeed improve the phenomenon of swallowed and dropped characters after enhancement, but this phenomenon still exists. After further analysis, it is found that its spectral characteristics and some noise The frequency spectrum characteristics of SPP are highly similar, which makes it difficult to locally converge in network training. Based on this, the AliCloudDenoise algorithm uses the auxiliary output speech probability in training, and the training strategy is not adopted in the deduction process. The calculation formula of SPP is as follows:

The results on the speech test set show that the proposed dual-output auxiliary training strategy improves the voice quality PESQ by 3.1% compared with the original model under the IRM target, and the speech intelligibility STOI improves by 1.2% compared with the original model; in Mapping a priori SNR The voice quality PESQ under the target is improved by 4.0% compared with the original model, and the speech intelligibility STOI is improved by 0.7% compared with the original model, and it is better than all baseline models. For details of indicators, see Table 3 and Table 4.

Table 3 Comparison of objective indicators voice quality PESQ

Table 4 Comparison of objective indicators of speech intelligibility STOI
Improved effect display:
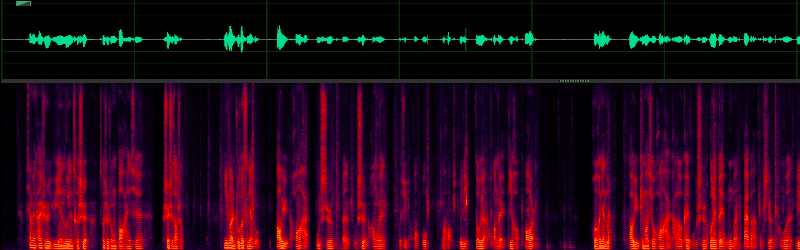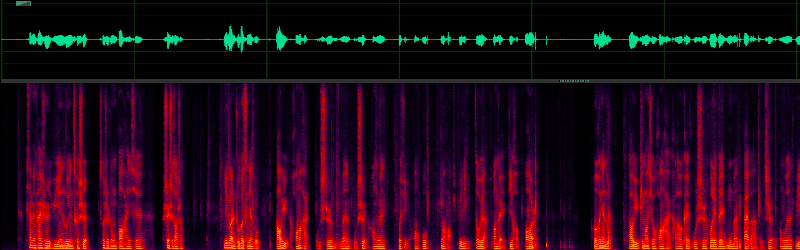
Third, how to make the algorithm applicable to a wider range of equipment
For real-time conference scenarios, the operating environment of the AliCloudDenoise algorithm generally includes PC, mobile, and IOT devices. Although the requirements for energy consumption are different in different operating environments, the CPU usage, memory capacity, bandwidth, and power consumption are all different. It is the key performance indicator we pay attention to. In order to enable the AliCloudDenoise algorithm to provide services for various business parties, we have adopted a series of energy consumption optimization methods, mainly including model structural tailoring, resource adaptive strategies, weight quantification and training Quantification, etc., and through some auxiliary convergence strategies, an intelligent voice enhancement model of about 500KB was finally obtained while the accuracy was reduced by 0.1%, which greatly broadened the application range of the AliCloudDenoise algorithm.
Next, we first briefly review the model lightweight technology involved in the optimization process, then introduce the resource adaptation strategy and model quantification, and finally give the key energy consumption indicators of the AliCloudDenoise algorithm.
1. Model lightweight technology adopted
The lightweight technology for deep learning models generally refers to a series of technical means for optimizing the "operating cost" of the model's parameter amount and size, calculation amount, energy consumption, and speed. Its purpose is to facilitate the deployment of models in various hardware devices. At the same time, lightweight technology also has a wide range of uses in computing-intensive cloud services, which can help reduce service costs and increase corresponding speed.
The main difficulty of lightweight technology is that while optimizing operating costs, the effect, generalization, and stability of the algorithm should not be significantly affected. For the common "black box" neural network model, it has a certain degree of difficulty in all aspects. In addition, part of the difficulty of lightweight is also reflected in the difference of optimization goals.
For example, the reduction of the model size does not necessarily reduce the amount of calculation; the reduction of the model calculation amount may not necessarily increase the operating speed; the increase of the operating speed does not necessarily reduce the energy consumption. This difference makes it difficult for lightweighting to solve all performance problems in a "package". It requires a variety of angles and the use of multiple technologies to achieve a comprehensive reduction in operating costs.
At present, common lightweight technologies in academia and industry include: parameter/operation quantization, pruning, small modules, structural hyperparameter optimization, distillation, low rank, sharing, etc. Among them, various technologies correspond to different purposes and requirements. For example, parameter quantization can compress the storage space occupied by the model, but still restores to floating-point numbers during calculations; parameter + global quantization of calculations can reduce the volume of parameters and reduce the amount of chip calculations at the same time, but It requires the chip to have the support of the corresponding arithmetic unit to achieve the speed-up effect; knowledge distillation uses a small student network to learn the high-level features of a large model to obtain a lightweight model with performance matching, but there are some difficulties in optimization and it is mainly suitable for simplifying the task of expression (Such as classification).
Unstructured fine tailoring can eliminate the most redundant parameters and achieve excellent simplification, but it requires dedicated hardware support to reduce the amount of calculation; weight sharing can significantly reduce the model size, but the disadvantage is that it is difficult to accelerate or save energy; AutoML structure super parameters Search can automatically determine the optimal model stack structure for small-scale test results, but the complexity of the search space and the goodness of iterative estimation limit its application. The following figure shows the lightweight technology mainly used by the AliCloudDenoise algorithm in the energy consumption optimization process.

2. Resource adaptive strategy
The core idea of the resource adaptation strategy is that the model can adaptively output lower-precision results that meet the limited conditions when the resources are insufficient, and do the best when the resources are sufficient, and output the enhanced results with the best accuracy to achieve The most direct idea of this function is to train models of different scales and store them in the device and use them on demand, but will increase the storage cost. The AliCloudDenoise algorithm uses a hierarchical training scheme, as shown in the following figure:

The results of the middle layer are also output, and the unified constraint training is finally carried out through the joint loss. However, the following two problems were found in the actual verification:
• The features extracted by the relatively shallow network are more basic, and the enhancement effect of the shallow network is poor.
• After the output structure of the middle layer network is increased, the enhancement results of the last layer of the network will be affected. The reason is that during the joint training process, it is hoped that the shallow network can also output relatively good enhancement results, which destroys the original network structure extraction features Distribution layout.
In response to the above two problems, we adopted the optimization strategy of multi-scale Dense connection + offline hyperparameter pre-pruning to ensure that the model can dynamically output voice enhancement results with an accuracy range of not more than 3.2% on demand.
3. Model quantification
In the optimization of the memory capacity and bandwidth required by the model, the weight quantization tool of the MNN team [22] and the python offline quantization tool [23] are mainly used to realize the conversion between FP32 and INT8. The schematic diagram of the scheme is as follows:

4. Key energy consumption indicators of AliCloudDenoise algorithm

As shown in the figure above, in terms of the algorithm library size of the Mac platform, the competing product is 14MB. The current mainstream output algorithm library of the AliCloudDenoise algorithm is 524KB, 912KB and 2.6MB, which has significant advantages; in terms of running consumption, the test results of the Mac platform show that , Competitors’ cpu occupies 3.4%, AliCloudDenoise algorithm library’s 524KB cpu occupies 1.1%, 912KB’s cpu occupies 1.3%, and 2.6MB’s cpu occupies 2.7%. Especially under long-term operating conditions, the AliCloudDenoise algorithm is obvious Advantage.
Fourth, the evaluation results of the algorithm's technical indicators
The evaluation of the voice enhancement effect of the AliCloudDenoise algorithm is currently mainly focused on two scenarios, the general-purpose scenario and the office meeting scenario.
1. Evaluation results in general scenarios
In the test set of general-purpose scenarios, the speech data set consists of two parts: Chinese and English (a total of about 5000 pieces), and the noise data set contains four common types of typical noise, stationary noise (Stationary noise), non-stationary noise (Non- stationary noise), office noise (Babble noise) and outdoor noise (Outdoor noise), the intensity of environmental noise is set between -5 to 15db, the objective indicators are mainly measured by PESQ voice quality and STOI voice intelligibility. Both indicators are The larger the value, the better the enhanced voice effect.
As shown in the following table, the evaluation results on the voice test set of general-purpose scenarios show that the AliCloudDenoise 524KB algorithm library has 39.4% (English voice) and 48.4% (Chinese voice) improvements on PESQ compared with traditional algorithms. There are 21.4% (English voice) and 23.1% (Chinese voice) improvements respectively, and it is basically the same as the algorithm of competing products. The AliCloudDenoise 2.6MB algorithm library has improved PESQ by 9.2% (English voice) and 3.9% (Chinese voice) respectively compared with competing algorithms, and 0.4% (English voice) and 1.6% (Chinese voice) on STOI respectively. The improvement shows a significant effect advantage.

2. Evaluation results in the office scenario
Combined with the business acoustic scene of the real-time meeting, we made a separate evaluation for the office scene. The noise is the noisy noise in the actual recorded real office scene. A total of about 5.3h of evaluation noisy speech was constructed. The following figure shows the comparison results of AliCloudDenoise 2.6MB algorithm library and competing products 1, competing products 2, traditional 1 and traditional 2. The comparison results of these four algorithms on SNR, P563, PESQ and STOI indicators, you can see the AliCloudDenoise 2.6MB algorithm library Has obvious advantages.

Future outlook
In the real-time communication scenario, AI + Audio Processing still has many research directions to be explored and implemented. Through the integration of data-driven ideas and classic signal processing algorithms, it can provide audio front-end algorithms (ANS, AEC, AGC) and audio back-end algorithms. End-to-end algorithms (bandwidth expansion, real-time bel canto, voice change, sound effects), audio codec, and audio processing algorithms (PLC, NetEQ) under weak networks bring effect upgrades, providing users of Alibaba Cloud Video Cloud with the ultimate audio experience.
references
[1] Wang D L, Chen J. Supervised speech separation based on deep learning: An overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1702-1726.
[2] https://venturebeat.com/2020/04/09/microsoft-teams-ai-machine-learning-real-time-noise-suppression-typing/
[3] https://venturebeat.com/2020/06/08/google-meet-noise-cancellation-ai-cloud-denoiser-g-suite/
[4] https://medialab.qq.com/#/projectTea
[5] Gannot S, Burshtein D, Weinstein E. Iterative and sequential Kalman filter-based speech enhancement algorithms[J]. IEEE Transactions on speech and audio processing, 1998, 6(4): 373-385.
[6] Kim J B, Lee K Y, Lee C W. On the applications of the interacting multiple model algorithm for enhancing noisy speech[J]. IEEE transactions on speech and audio processing, 2000, 8(3): 349-352.
[7] Ephraim Y, Van Trees H L. A signal subspace approach for speech enhancement[J]. IEEE Transactions on speech and audio processing, 1995, 3(4): 251-266.
[8] Ephraim Y, Malah D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on acoustics, speech, and signal processing, 1984, 32(6): 1109-1121.
[9] Cohen I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging[J]. IEEE Transactions on speech and audio processing, 2003, 11(5): 466-475.
[10]Ciregan D, Meier U, Schmidhuber J. Multi-column deep neural networks for image classification[C]//2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012: 3642-3649.
[11]Graves A, Liwicki M, Fernández S, et al. A novel connectionist system for unconstrained handwriting recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2008, 31(5): 855-868.
[12]Senior A, Vanhoucke V, Nguyen P, et al. Deep neural networks for acoustic modeling in speech recognition[J]. IEEE Signal processing magazine, 2012.
[13]Sundermeyer M, Ney H, Schlüter R. From feedforward to recurrent LSTM neural networks for language modeling[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(3): 517-529.
[14]Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[15] Valin J M. A hybrid DSP/deep learning approach to real-time full-band speech enhancement[C]//2018 IEEE 20th international workshop on multimedia signal processing (MMSP). IEEE, 2018: 1-5.
[16] Wang Y, Narayanan A, Wang D L. On training targets for supervised speech separation[J]. IEEE/ACM transactions on audio, speech, and language processing, 2014, 22(12): 1849-1858.
[17] Erdogan H, Hershey J R, Watanabe S, et al. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks[C]//2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015: 708-712.
[18] Williamson D S, Wang Y, Wang D L. Complex ratio masking for monaural speech separation[J]. IEEE/ACM transactions on audio, speech, and language processing, 2015, 24(3): 483-492.
[19] Recommendation I T U T. Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs[J]. Rec. ITU-T P. 862, 2001.
[20] Taal C H, Hendriks R C, Heusdens R, et al. A short-time objective intelligibility measure for time-frequency weighted noisy speech[C]//2010 IEEE international conference on acoustics, speech and signal processing. IEEE, 2010: 4214-4217.
[21] Nicolson A, Paliwal K K. Deep learning for minimum mean-square error approaches to speech enhancement[J]. Speech Communication, 2019, 111: 44-55.
[22] https://www.yuque.com/mnn/cn/model_convert
[23] https://github.com/alibaba/MNN/tree/master/tools/MNNPythonOfflineQuant
"Video Cloud Technology" Your most noteworthy audio and video technology public account, pushes practical technical articles from the front line of Alibaba Cloud every week, and exchanges and exchanges with first-class engineers in the audio and video field. The official account backstage reply [Technology] You can join the Alibaba Cloud Video Cloud Technology Exchange Group to discuss audio and video technologies with the author and get more industry latest information.






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。