
In the business scenario of mobile applications, we need to save such information: a key is associated with a data collection, and at the same time, the data in the collection should be statistically sorted.
Common scenarios are as follows:
- Give a userId to determine the user's login status;
- The check-in status of 200 million users in the last 7 days, and the total number of users who checked-in continuously in the past 7 days;
- Count the number of new users added each day and the number of retained users on the next day;
- Count the number of unique visitors (UV) of the website
- List of latest comments
- Music chart according to the volume of play
Under normal circumstances, the number of users and visits we face is huge, such as the number of users at the level of millions or tens of millions, or visit information at the level of tens of millions or even hundreds of millions.
Therefore, we must choose a collection type that can count large amounts of data (for example, billions) very efficiently.
How to choose a suitable data set, we must first understand the commonly used statistical models, and use reasonable data to solve practical problems.
Four types of statistics:
- Binary status statistics;
- Aggregate statistics;
- Sort statistics
- Base statistics.
This article will use the String, Set, Zset, List, hash other extended data types Bitmap , HyperLogLog to achieve.
The instructions involved in the article can be run and debugged through the online Redis client, address: https://try.redis.io/, super convenient.
Message
Share more and pay more, create more value for others in the early stage and ignore the rewards. In the long run, these efforts will reward you twice.
Especially when you are just starting to work with others, don't worry about short-term returns. It doesn't make much sense. It's more about training your vision, perspective, and problem-solving ability.
Binary status statistics
Brother Ma, what is binary status statistics?
That is to say, the values of the elements in the set are only 0 and 1. In the scenario of check-in and check-in and whether the user is logged in, you only need to record check-in (1) or not check-in (0), logged-in (1) or Not logged in (0).
Suppose we use Redis' String type implementation in the scenario of judging whether a user is logged in ( key -> userId, value -> 0 means offline, 1-login ), if we store the login status of 1 million users, if you use characters To store in the form of strings, 1 million strings need to be stored, and the memory overhead is too large.
For the binary state scene, we can use Bitmap to achieve it. For example, we use one bit to indicate the login status, and 100 million users only occupy 100 million bits of memory ≈ (100000000/8/1024/1024) 12 MB.
大概的空间占用计算公式是:($offset/8/1024/1024) MBWhat is Bitmap?
The underlying data structure of Bitmap uses the String type SDS data structure to store the bit array. Redis uses the 8 bits of each byte array, and each bit represents the binary state of an element (either 0 or 1 ).
You can think of Bitmap as an array with bits as the unit. Each unit of the array can only store 0 or 1. The subscript of the array is called the offset in the Bitmap.
For visual display, we can understand that each byte of the buf array is represented by a row, each row has 8 bits, and the 8 grids respectively represent the 8 bits in this byte, as shown in the following figure:

8 bits form a Byte, so Bitmap will greatly save storage space. This is the advantage of Bitmap.
Determine user login status
How to use Bitmap to determine whether a user is online among a large number of users?
Bitmap provides GETBIT、SETBIT operation, through an offset value offset to read and write the bit of the offset position of the bit array, it should be noted that the offset starts from 0.
Only one key = login_status is needed to store the user login status collection data. The user ID is used as the offset, and it is set to 1 for online and 0 for offline. Use GETBIT determine whether the corresponding user is online. 50 million users only need 6 MB of space.
SETBIT command
SETBIT <key> <offset> <value>Set or clear the bit value of the key value at offset (only 0 or 1).
GETBIT command
GETBIT <key> <offset>Get the value of the bit of the key value at offset, and return 0 when the key does not exist.
Suppose we want to determine the login status of the user with ID = 10086:
The first step is to execute the following instructions to indicate that the user has logged in.
SETBIT login_status 10086 1The second step is to check whether the user is logged in, and the return value of 1 means logged in.
GETBIT login_status 10086The third step is to log out and set the value corresponding to offset to 0.
SETBIT login_status 10086 0User's monthly check-in status
In the check-in statistics, each user's daily check-in is represented by 1 bit, and only 365 bits are needed for one year's check-in. There are only 31 days in a month, and only 31 bits are required.
For example, how should the user with statistical number 89757 check in in May 2021?
The key can be designed as uid:sign:{userId}:{yyyyMM} , and the value of each day of the month-1 can be used as the offset (because the offset starts from 0, so offset = date-1).
The first step is to execute the following command to record the user's check-in on May 16, 2021.
SETBIT uid:sign:89757:202105 15 1The second step is to determine whether user number 89757 has clocked in on May 16, 2021.
GETBIT uid:sign:89757:202105 15The third step is to count the number of times the user has BITCOUNT in in May, using the instruction 0610f48c084c22. This command is used to count the number of bits with value = 1 in the given bit array.
BITCOUNT uid:sign:89757:202105In this way, we can realize the user's check-in situation every month, isn't it great?
How to count the time of the first check-in this month?
Redis provides the BITPOS key bitValue [start] [end] instruction, and the returned data indicates the offset position bitValue
By default, the command will detect the entire bitmap, and the user can specify the range to be detected start parameters and end
So we can get userID = 89757 by executing the following command to get the date first punched in
BITPOS uid:sign:89757:202105 1It should be noted that we need to return the value + 1 to indicate the day when the card was first punched in, because the offset starts from 0.
Total number of users who have checked in consecutively
After recording the check-in data of 100 million users for 7 consecutive days, how to count the total number of users who check-in for 7 consecutive days?
We use the date of the day as the key of the Bitmap and the userId as the offset. If it is a check-in, the bit of the offset position is set to 1.
The data of each bit in the set corresponding to the key is the check-in record of a user on that date.
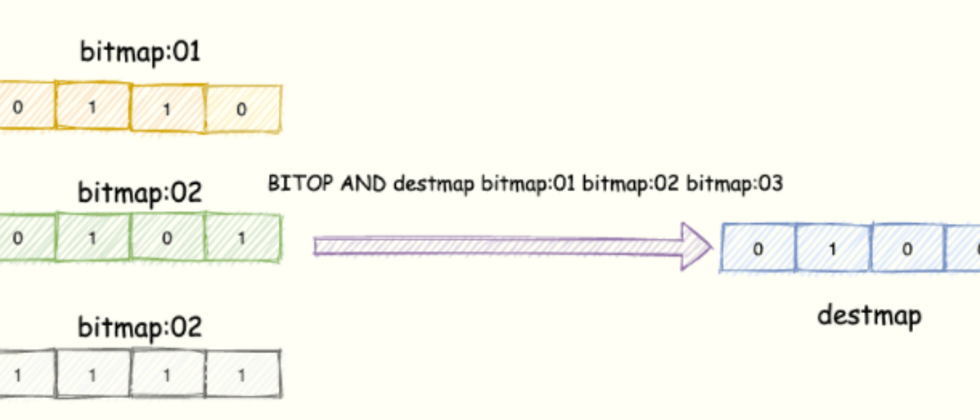
There are a total of 7 such Bitmaps. If we can do an AND operation on the corresponding bits of these 7 Bitmaps.
The same UserID offset is the same. When a userID is in the offset position corresponding to the 7 Bitmaps, the bit = 1 means that the user has clocked in continuously for 7 days.
The result is saved in a new Bitmap, we then count the number of bit = 1 BITCOUNT
Redis provides the BITOP operation destkey key [key ...] for bitmap operations on one or more key = key Bitmap.
opration can be and , OR , NOT , XOR . When BITOP processes strings of different lengths, the missing part of the shorter string will be treated as 0 .
The empty key also regarded as a string sequence 0
It is easy to understand, as shown in the figure below:

Three Bitmaps, the corresponding bit bits are "ANDed", and the result is saved in the new Bitmap.
The operation instruction means to perform AND operation on three bitmaps and save the result in destmap. Then perform BITCOUNT statistics on destmap.
// 与操作
BITOP AND destmap bitmap:01 bitmap:02 bitmap:03
// 统计 bit 位 = 1 的个数
BITCOUNT destmapSimply calculate the memory overhead of the next 100 million bits of Bitmap, which occupies about 12 MB of memory (10^8/8/1024/1024), and the memory overhead of a 7-day Bitmap is about 84 MB. At the same time, we'd better set the expiration time for Bitmap, let Redis delete the expired check-in data, and save memory .
summary
Thinking is the most important thing. When we encounter statistical scenarios that only need the binary status of statistical data, such as whether users exist, whether ip is blacklisted, and check-in and clock-in statistics, we can consider using Bitmap.
Only one bit is needed to represent 0 and 1, which will greatly reduce the memory usage when counting massive data.
Base Statistics
Cardinality statistics: Count the number of unique elements in a set, commonly used to calculate the number of independent users (UV).
The most direct way to achieve cardinality statistics is to use the Set ). When an element has never appeared before, an element is added to the set; if it does, the set remains unchanged.
When the page visits are huge, a very large Set collection is needed for statistics, which will waste a lot of space.
In addition, such data does not need to be very accurate. Is there a better solution?
This question is a good question. Redis provides the HyperLogLog data structure to solve statistical problems in various scenarios.
HyperLogLog is an inaccurate deduplication base number scheme. Its statistical rules are based on probability and the standard error is 0.81%. This accuracy is sufficient to meet UV statistical requirements.
The principle of HyperLogLog is too complicated. If you want to understand, please go to:
Website's UV
Realized by Set
A user visiting a website multiple times in a day can only be counted as once, so it is easy to think of implementing it through Redis' Set collection.
When user number 89757 accesses " Redis why is so fast", we put this information in the Set.
SADD Redis为什么这么快:uv 89757When the user ID 89757 visits the "Why is Redis so fast" page multiple times, the deduplication function of Set can ensure that the same user ID will not be recorded repeatedly.
Use the SCARD "Why is Redis so fast" page. The instruction returns the number of elements in a set (that is, the user ID).
SCARD Redis为什么这么快:uvRealized by Hash
If the code is old and wet, it can also be implemented using the Hash type, using the user ID as the key of the Hash collection, and when accessing the page, execute the HSET command to set the value to 1.
Even if the user repeatedly visits and executes the command repeatedly, it will only set the value of this userId to "1".
Finally, using the HLEN command to count the number of elements in the Hash set is UV.
as follows:
HSET redis集群:uv userId:89757 1
// 统计 UV
HLEN redis集群HyperLogLog King Solution
The code is old and wet, although the set is good, if the article is very popular and reaches tens of millions of levels, a set will save the IDs of tens of millions of users, and the memory consumed by more pages will be too large. The same is true for the Hash data type. What to do?
HyperLogLog advanced data structure provided by Redis (don't just know the five basic data types of Redis). This is a data collection type used for cardinality statistics. Even if the amount of data is large, the space required to calculate the cardinality is fixed.
Each HyperLogLog only needs to spend 12KB of memory at most to calculate the base of 2 to 64 elements.
Redis has HyperLogLog the storage of 0610f48c0852f6. When the count is relatively small, the storage space uses a coefficient matrix, which takes up a small space.
Only when the count is large and the space occupied by the sparse matrix exceeds the threshold will it be transformed into a dense matrix, occupying 12KB of space.
PFADD
Add the ID of each user who visits the page to HyperLogLog .
PFADD Redis主从同步原理:uv userID1 userID 2 useID3PFCOUNT
Use PFCOUNT obtain the UV value of the page Redis master-slave synchronization principle
PFCOUNT Redis主从同步原理:uvPFMERGE usage scenario
HyperLogLog addition to the above PFADD and PFCOIUNT , but also provides a PFMERGE , the plurality HyperLogLog combined together to form a new HyperLogLog value.
Syntax
PFMERGE destkey sourcekey [sourcekey ...]Usage scenario
For example, in the website we have two pages with similar content, and the operation said that the data of these two pages need to be merged.
The UV visits of the pages also need to be merged, then PFMERGE can come in handy at same user accessing these two pages will only be counted as once.
As shown below: The two Bitmap collections of Redis and MySQL respectively store the user access data of two pages.
PFADD Redis数据 user1 user2 user3
PFADD MySQL数据 user1 user2 user4
PFMERGE 数据库 Redis数据 MySQL数据
PFCOUNT 数据库 // 返回值 = 4The combined plurality HyperLogLog (Merge) is a HyperLogLog, HyperLogLog close to the base of the combined set of all visible HyperLogLog the input (observed set) of union .
Both user1 and user2 have accessed Redis and MySQL, only one access.
Sorting statistics
four collection types of Redis (1610f48c085522 List, Set, Hash, Sorted Set ), List and Sorted Set are ordered.
- List: Sort according to the order in which the elements are inserted into the List. The usage scenarios can usually be used as message queues, latest lists, and rankings;
- Sorted Set: Sorting according to the score weight of the elements, we can determine the weight value of each element by ourselves. Usage scenarios (ranking boards, such as according to the number of plays and the number of likes).
List of latest comments
The code is old and wet, I can use the order of List insertion to sort the comments list
For example, the backend reply list of WeChat official account (don't use the bar, for example), each official account corresponds to a List, and this List stores all the user comments of the official account.
Whenever a user comments, use LPUSH key value [value ...] insert to the head of the List team.
LPUSH 码哥字节 1 2 3 4 5 6Then use LRANGE key star stop get the elements in the specified range of the list.
> LRANGE 码哥字节 0 4
1) "6"
2) "5"
3) "4"
4) "3"
5) "2"Note that not all the latest lists can be implemented with List. For lists that are frequently updated, list type paging may cause list elements to be duplicated or omitted.
For example, in the current comment list List ={A, B, C, D} , the left side represents the latest comment, and D is the earliest comment.
LPUSH 码哥字节 D C B ADisplay the latest 2 comments on the first page, and get A and B:
LRANGE 码哥字节 0 1
1) "A"
2) "B"According to the logic we want, the second page can get C and D LRANGE byte 2 3.
If a new comment E is generated before the second page is displayed, the comment E is byte E, List = {E, A, B, C, D }.
Now execute LRANGE code brother byte 2 3 to get the second page comment and find that B appears again.
LRANGE 码哥字节 2 3
1) "B"
2) "C"The reason for this is that List is sorted by the position of the elements. Once a new element is inserted, List = {E,A,B,C,D} .
The position of the original data in the List is moved one bit backward, resulting in reading all the old elements.

summary
Only lists that do not require paging (for example, only the first 5 elements of the list are fetched each time) or with low update frequency (for example, the statistics are updated once a day in the early morning) are suitable to be implemented with the List type.
For lists that need to be paged and updated frequently, they need to be implemented using the Sorted Set type.
In addition, the latest list that needs to be searched by the time range can not be realized by the List type. It needs to be realized by the Sorted Set type, such as the order list that is queried with the transaction time range as the condition.
Leaderboard
The code is old and wet. For the scene of the latest list, both List and Sorted Set can be implemented. Why use List? It is not better to use Sorted Set directly, it can also set the score weight to sort more flexibly.
The reason is that the memory capacity of the Sorted Set type is several times that of the List type. For the case where the number of lists is small, it can be implemented with the Sorted Set type.
For example, if we want a weekly music chart, we need to update the playback volume in real time, and we need to display it in pages.
In addition, the sorting is determined according to the playback volume, and the List cannot be satisfied at this time.
We can save the music ID in the Sorted Set collection, score to the amount of playback of each song, and set score = score +1 every time the music is played.
ZADD
For example, we add the play volume of "Blue and White Porcelain" and "Hua Tian Cuo" to the musicTop collection:
ZADD musicTop 100000000 青花瓷 8999999 花田错ZINCRBY
Every time "Blue and White Porcelain" is played, the score +1 ZINCRBY
> ZINCRBY musicTop 1 青花瓷
100000001ZRANGEBYSCORE
Finally, we need to get the top ten play volume music list, the current maximum play volume is N, which can be obtained by the following command:
ZRANGEBYSCORE musicTop N-9 N WITHSCORESBrother 65: But how do we get this N?
ZREVRANGE
You can use the ZREVRANGE key start stop [WITHSCORES] command.
Among them, the order of the elements score decreasing (from large to small).
It has the same score members value lexicographical ordering of reverse ( Reverse Order the lexicographical arrangement).
> ZREVRANGE musicTop 0 0 WITHSCORES
1) "青花瓷"
2) 100000000summary
Even if the elements in the set are updated frequently, Sorted Set can accurately obtain the sequentially arranged data ZRANGEBYSCORE
When facing scenes that need to display the latest list, leaderboard, etc., if the data is updated frequently or needs to be displayed in pages, it is recommended to give priority to using Sorted Set.
Aggregate statistics
It refers to the aggregation results of multiple collection elements, for example:
- Count the common data of multiple elements (intersection);
- Count one of the unique elements of the two sets (difference set statistics);
- Count all the elements of multiple sets (union statistics).
The code is old and wet, what kind of scenes will use intersection, difference, and union?
Redis's Set type supports addition, deletion, modification, and checking in the collection. The bottom layer uses the Hash data structure. Both add and remove are O(1) time complexity.
It also supports the intersection, union, and difference operations between multiple sets. Use these set operations to solve the statistical problems mentioned above.
Intersection-mutual friend
For example, the mutual friends in QQ are the intersection in aggregated statistics. We use the account as the Key, and the friends of the account as the value of the Set collection.
Simulate a collection of friends of two users:
SADD user:码哥字节 R大 Linux大神 PHP之父
SADD user:大佬 Linux大神 Python大神 C++菜鸡
To count the mutual friends of two users, only the intersection of the two Set sets is required. The following command:
SINTERSTORE user:共同好友 user:码哥字节 user:大佬After the command is executed, the intersection data of the two sets of "user: code brother byte" and "user: big brother" is stored in the user: mutual friend set.
Difference-the number of new friends added per day
For example, to count the number of new registered users of a certain App every day, you only need to take the difference of the total number of registered users in the past two days.
For example, the total number of registered users for key = user:20210601 is stored in the 0610f48c085c59 set collection, and the total number of users for key = user:20210602 is stored in the collection 0610f48c085c5c.

The following instructions execute the difference calculation and store the result in the user:new collection.
SDIFFSTORE user:new user:20210602 user:20210601After execution, the user:new set at this time will be the number of new users on 2021/06/02.
In addition, there is a possible acquaintance function on QQ, which can also be realized by subtraction, which is to subtract your mutual friends from the set of friends of your friends.
Union-a total of new friends
It is still an example of subtraction. To count the total number of new users added in the two days of 2021/06/01 and 2021/06/02, only the union of the two sets needs to be performed.
SUNIONSTORE userid:new user:20210602 user:20210601At this time, the new set userid:new is the new friends added in two days.
summary
The calculation complexity of the difference, union, and intersection of Set is relatively high. In the case of a large amount of data, if these calculations are performed directly, it will cause the Redis instance to block.
Therefore, you can deploy a cluster specifically for statistics, let it be dedicated to aggregate calculations, or read data to the client, and complete the aggregate statistics on the client, so that other services can be prevented from being unable to respond due to congestion.
recommended in the
Redis Journal: A killer for fast recovery without fear of downtime
Redis High Availability: You call this the principle of Sentinel cluster
Redis High Availability: How much data can the Cluster support?







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。