

SQL basic knowledge finishing
select 查询结果,如: [学号,平均成绩:组函数avg(成绩)]
from 从哪张表中查找数据,如:[涉及到成绩:成绩表score]
where 查询条件,如:[b.课程号='0003' and b.成绩>80]
group by 分组,如:[每个学生的平均:按学号分组](oracle,SQL server中出现在select 子句后的非分组函数,必须出现在group by子句后出现),MySQL中可以不用
having 对分组结果指定条件,如:[大于60分]
order by 对查询结果排序,如:[增序: 成绩 ASC / 降序: 成绩 DESC];
limit 使用limt子句返回topN(对应这个问题返回的成绩前两名),如:[ limit 2 ==>从0索引开始读取2个]limit==>从0索引开始 [0,N-1]select * from table limit 2,1;
-- 含义是跳过2条取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据
select * from table limit 2 offset 1;
-- 含义是从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条group function : deduplication distinct() statistics total sum() calculation count count() average avg() maximum max() minimum min()
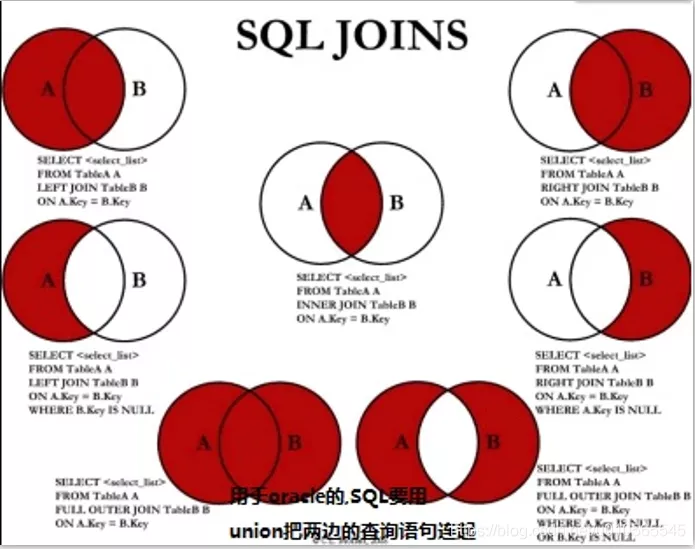
Multi-table join : inner join (default inner omitted) join...on..left join left join tableName as b on a.key == b.key right join right join join union (no duplication (filtering and deduplication) ) And union all (duplicate [do not filter to remove duplicates])
- union
- union all (duplicate)
- oracle (SQL server) database
- intersect
- minus(except) subtraction (difference set)
oracle
One, database objects: table (table) view (view) sequence (sequence) index (index) synonym (synonym)
1. View: stored select statement
create view emp_vw
as
select employee_id, last_name, salary
from employees
where department_id = 90;
select * from emp_vw;DML operations can be performed on simple views
update emp_vw
set last_name = 'HelloKitty'
where employee_id = 100;
select * from employees
where employee_id = 100;1). Complex view
create view emp_vw2
as
select department_id, avg(salary) avg_sal
from employees
group by department_id;
select * from emp_vw2;Complex views cannot be DML operations
update emp_vw2
set avg_sal = 10000
where department_id = 100;2. Sequence: used to generate a set of regular values. (Usually used to set the value of the primary key)
create sequence emp_seq1
start with 1
increment by 1
maxvalue 10000
minvalue 1
cycle
nocache;
select emp_seq1.currval from dual;
select emp_seq1.nextval from dual;problem: crack, cause :
- When multiple tables share the same sequence.
- rollback
An exception occurs
create table emp1( id number(10), name varchar2(30) ); insert into emp1 values(emp_seq1.nextval, '张三'); select * from emp1;3. Index: improve query efficiency
Automatic creation: Oracle will automatically create indexes for columns with unique constraints (unique constraints, primary key constraints)
create table emp2(
id number(10) primary key,
name varchar2(30)
)Create manually
create index emp_idx
on emp2(name);
create index emp_idx2
on emp2(id, name);4. Synonyms
create synonym d1 for departments;
select * from d1;5. Table:
DDL: data definition language create table .../ drop table ... / rename ... to..../ truncate table.../alter table ...
DML: Data Manipulation Language
insert into ... values ...
update ... set ... where ...
delete from ... where ...【important】
select ... 组函数(MIN()/MAX()/SUM()/AVG()/COUNT())
from ...join ... on ... 左外连接:left join ... on ... 右外连接: right join ... on ...
where ...
group by ... (oracle,SQL server中出现在select 子句后的非分组函数,必须出现在 group by子句后)
having ... 用于过滤 组函数
order by ... asc 升序, desc 降序
limit (0,4) 限制N条数据 如: topN数据
- union 并集
- union all(有重复)
- intersect 交集
- minus 相减
DCL : 数据控制语言 commit : 提交 / rollback : 回滚 / 授权grant...to... /revoke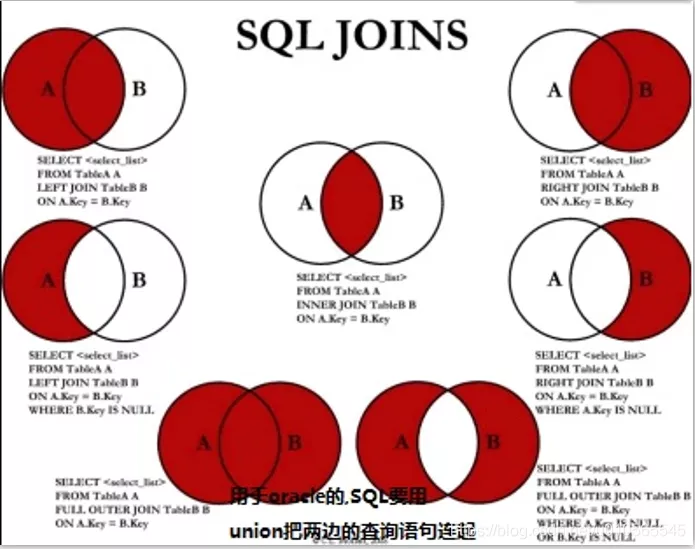
index
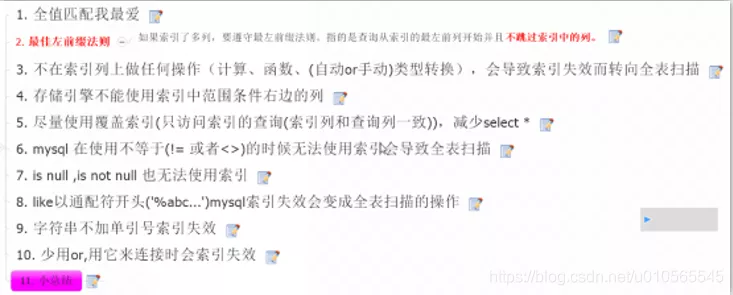
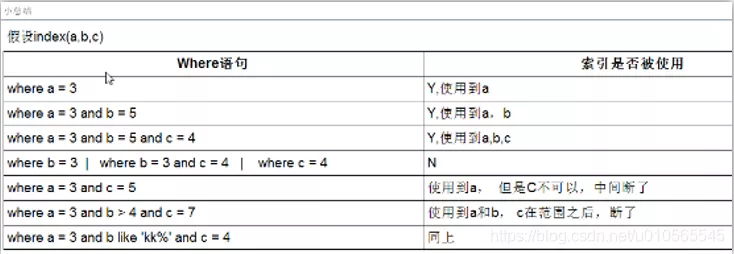

When to create an index:




select employee_id, last_name, salary, department_id
from employees
where department_id in (70, 80) --> 70:1 80:34- union
- union all (with duplicate parts)
- intersect
minus subtraction
select employee_id, last_name, salary, department_id from employees where department_id in (80, 90) --> 90:4 80:34Question: Query the information of employees whose salary is greater than that of employee No. 149
select * from employees where salary > ( select salary from employees where employee_id = 149 )Question: Query the employee_id, manager_id, department_id of other employees whose manager_id and department_id are the same as those of employee 141 or 174
select employee_id, manager_id, department_id from employees where manager_id in ( select manager_id from employees where employee_id in(141, 174) ) and department_id in ( select department_id from employees where employee_id in(141, 174) ) and employee_id not in (141, 174); select employee_id, manager_id, department_id from employees where (manager_id, department_id) in ( select manager_id, department_id from employees where employee_id in (141, 174) ) and employee_id not in(141, 174);Use subqueries in the from clause
select max(avg(salary)) from employees group by department_id; select max(avg_sal) from ( select avg(salary) avg_sal from employees group by department_id )Question: Return the last_name, department_id, salary and average salary of employees who are higher than the average salary of the department
select last_name, department_id, salary, (select avg(salary) from employees where department_id = e1.department_id) from employees e1 where salary > ( select avg(salary) from employees e2 where e1.department_id = e2.department_id ) select last_name, e1.department_id, salary, avg_sal from employees e1, ( select department_id, avg(salary) avg_sal from employees group by department_id ) e2 where e1.department_id = e2.department_id and e1.salary > e2.avg_sal; case...when ... then... when ... then ... else ... endQuery: If the department is 10, the salary is 1.1 times, the department number is 20, the salary is 1.2 times, and the rest is 1.3 times
SELECT employee_id, last_name, salary, CASE department_id WHEN 10 THEN salary * 1.1 WHEN 20 THEN salary * 1.2 ELSE salary * 1.3 END "new_salary" FROM employees; SELECT employee_id, last_name, salary, decode( department_id, 10, salary * 1.1, 20, salary * 1.2, salary * 1.3 ) "new_salary" FROM employees;Question: Explicit employee_id, last_name and location of the employee. Among them, if the employee's department_id is the same as the department_id whose location_id is 1800, the location will be'Canada', and the rest will be'USA'.
select employee_id, last_name, case department_id when ( select department_id from departments where location_id = 1800 ) then 'Canada' else 'USA' end "location" from employees;Question: Query employee's employee_id, last_name, and require sorting by employee's department_name
select employee_id, last_namefrom employees e1 order by ( select department_name from departments d1 where e1.department_id = d1.department_id )SQL optimization: do not use IN if you can use EXISTS
Question: Query employee_id, last_name, job_id, department_id information of company managers
select employee_id, last_name, job_id, department_id
from employees
where employee_id in (
select manager_id
from employees
)select employee_id, last_name, job_id, department_id
from employees e1
where exists (
select 'x'
from employees e2
where e1.employee_id = e2.manager_id
) Question: Query the department_id and department_name of the departments that do not exist in the employees table in the departments table
select department_id, department_name
from departments d1
where not exists (
select 'x'
from employees e1
where e1.department_id = d1.department_id
)Change the information of 108 employees: make their salary become the highest salary in the department, job becomes the job with the lowest average salary in the company
update employees e1
set salary = (
select max(salary)
from employees e2
where e1.department_id = e2.department_id
), job_id = (
select job_id
from employees
group by job_id
having avg(salary) = (
select min(avg(salary))
from employees
group by job_id
)
)
where employee_id = 108;Delete the employee with the lowest salary in the department of employee 108.
delete from employees e1
where salary = (
select min(salary)
from employees
where department_id = (
select department_id
from employees
where employee_id = 108
)
)
select * from employees where employee_id = 108;
select * from employees where department_id = 100
order by salary;
rollback;Common SQL interview questions: 50 classic questions
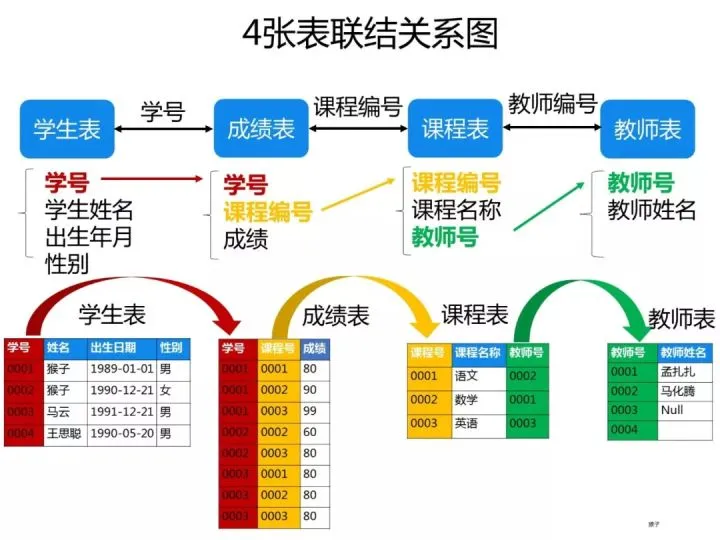
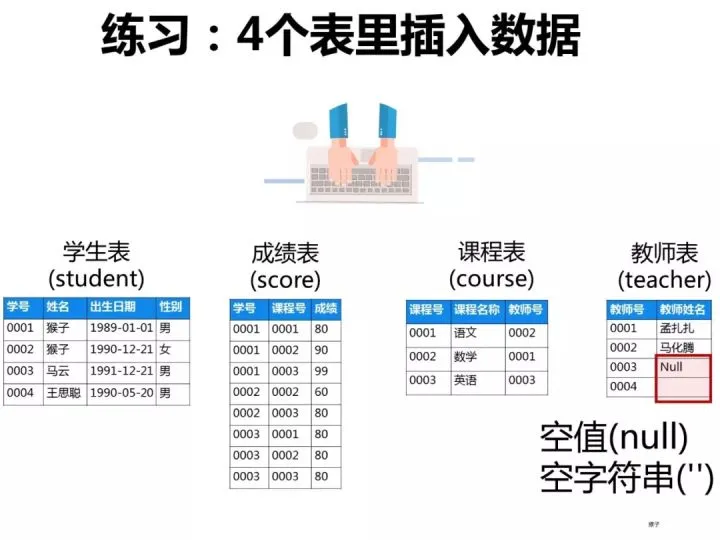
The following 4 tables are known:
- Student table: student (student number, student name, date of birth, gender)
- Score table: score (student number, course number, score)
- Course table: course (course number, course name, teacher number)
- Teacher table: teacher (teacher number, teacher name)
According to the above information, write the corresponding SQL statement in accordance with the following requirements. (Search for the technical road of migrant workers in the official account, reply "10241" and give you a collection of technical resources)
ps: These questions examine the ability to write SQL. For this type of question, you need to figure out the relationship between the four tables. The best way is to draw the relationship diagram on the draft paper and then write it. The corresponding SQL statement is easier. The following figure is the relationship diagram of the four tables I drew. You can see which foreign keys are related to each other:
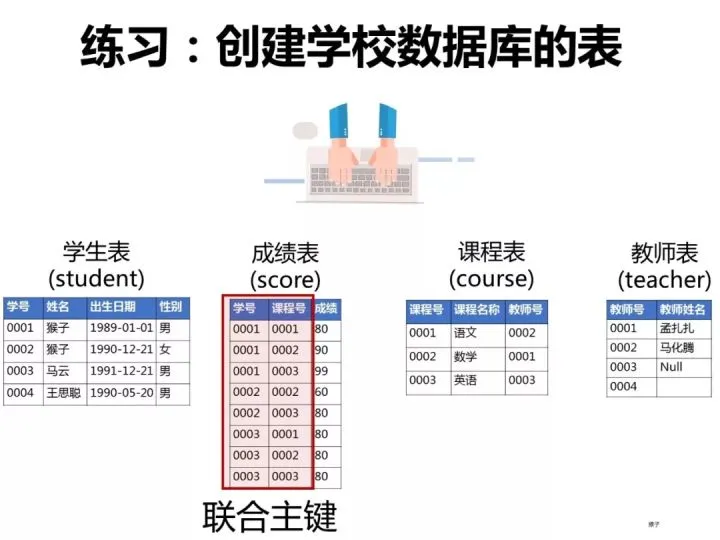
One, create a database and table
In order to demonstrate the running process of the topic, we first create the database and table in the client Navicat according to the following statement.
If you still don’t understand what a database is, what is a client Navicat, you can learn this first:
1. Create a table
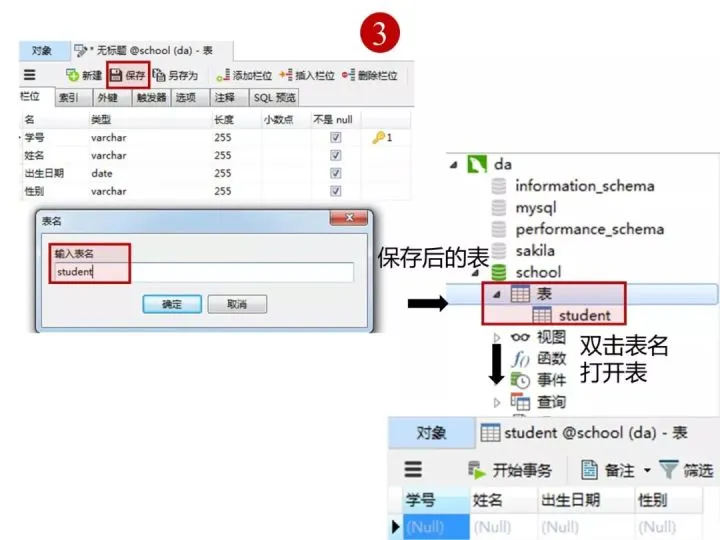
1) Create a student table (student)
Create the student table in the client Navicat as shown below. Recommendation: Summary of corporate interview questions
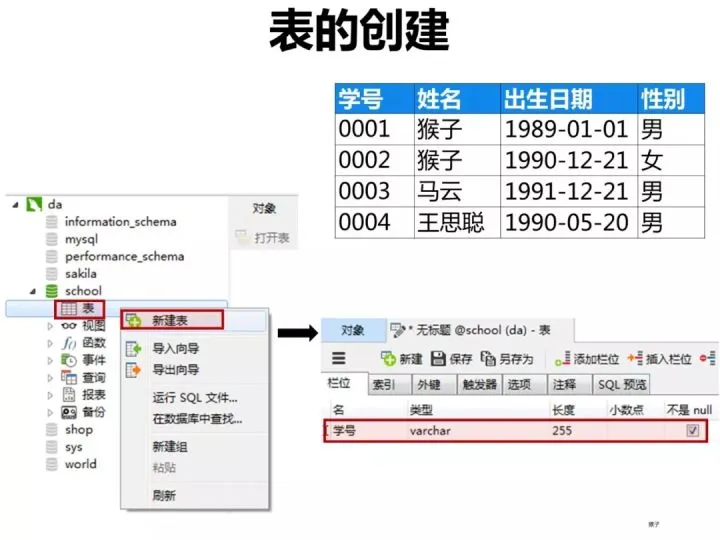
The "student number" column of the student table is set as the primary key constraint. The following figure shows the data type and constraint set for each column
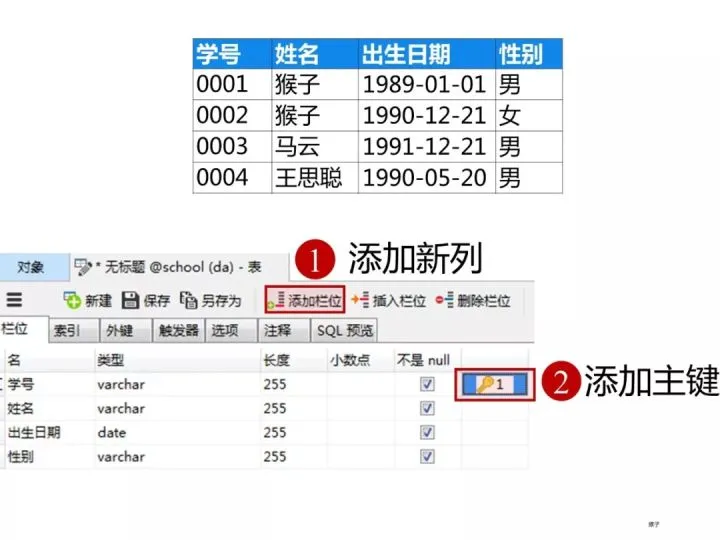
After creating the table, click "Save"
2) Create a score sheet (score)
Follow the same steps to create a "score table". "Student ID" and "Course ID" of the "curriculum schedule" are set together as the primary key constraint (joint primary key), and the column "score" is set to a numeric type (float, floating point value)

3) Create a course schedule (course)
The "course number" of the curriculum schedule is set as the primary key constraint

4) Teacher table (teacher)
The “Teacher ID” column of the teacher table is set as the primary key constraint, and the teacher name column is set to “null” (the red box is not checked), which means that this column is allowed to contain null values (null). Recommendation: Summary of corporate interview questions

Add data to the table
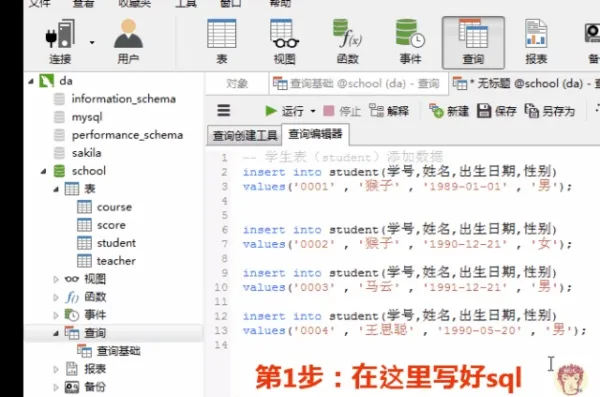
1) Add data to the student table
SQL to add data
insert into student(学号,姓名,出生日期,性别)
values('0001' , '猴子' , '1989-01-01' , '男');
insert into student(学号,姓名,出生日期,性别)
values('0002' , '猴子' , '1990-12-21' , '女');
insert into student(学号,姓名,出生日期,性别)
values('0003' , '马云' , '1991-12-21' , '男');
insert into student(学号,姓名,出生日期,性别)
values('0004' , '王思聪' , '1990-05-20' , '男');Operation in the client Navicat


2) Score
SQL to add data
insert into score(学号,课程号,成绩)
values('0001' , '0001' , 80);
insert into score(学号,课程号,成绩)
values('0001' , '0002' , 90);
insert into score(学号,课程号,成绩)
values('0001' , '0003' , 99);
insert into score(学号,课程号,成绩)
values('0002' , '0002' , 60);
insert into score(学号,课程号,成绩)
values('0002' , '0003' , 80);
insert into score(学号,课程号,成绩)
values('0003' , '0001' , 80);
insert into score(学号,课程号,成绩)
values('0003' , '0002' , 80);
insert into score(学号,课程号,成绩)
values('0003' , '0003' , 80);Operation in the client Navicat

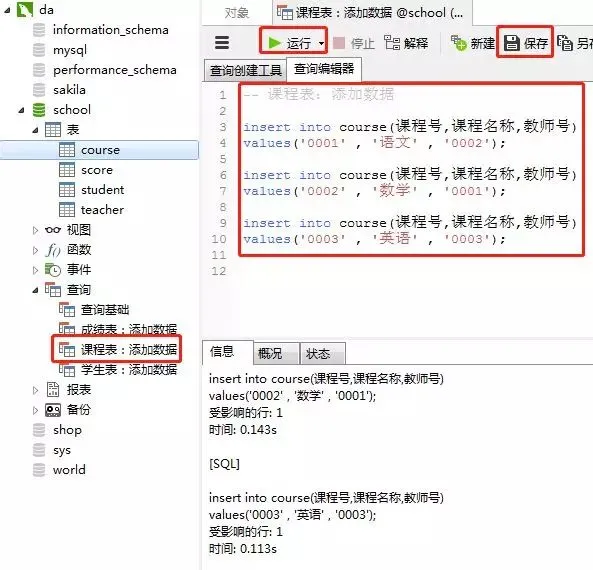
3) Course schedule
SQL to add data
insert into course(课程号,课程名称,教师号)
values('0001' , '语文' , '0002');
insert into course(课程号,课程名称,教师号)
values('0002' , '数学' , '0001');
insert into course(课程号,课程名称,教师号)
values('0003' , '英语' , '0003');Operation in the client Navicat
4) Add data to the teacher table
SQL to add data
-- 教师表:添加数据
insert into teacher(教师号,教师姓名)
values('0001' , '孟扎扎');
insert into teacher(教师号,教师姓名)
values('0002' , '马化腾');
-- 这里的教师姓名是空值(null)
insert into teacher(教师号,教师姓名)
values('0003' , null);
-- 这里的教师姓名是空字符串('')
insert into teacher(教师号,教师姓名)
values('0004' , '');Operation in the client Navicat
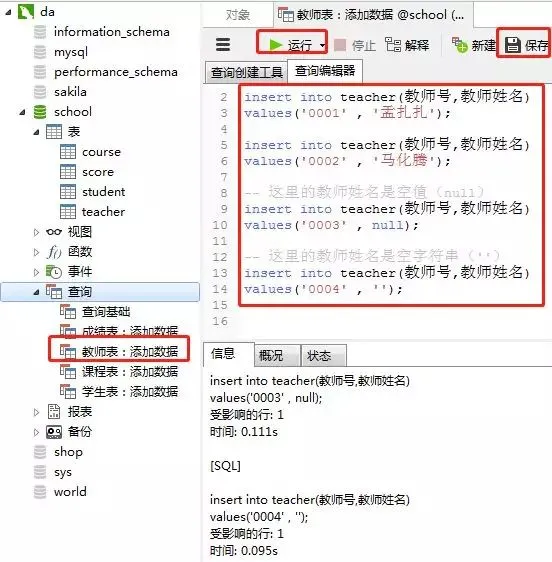
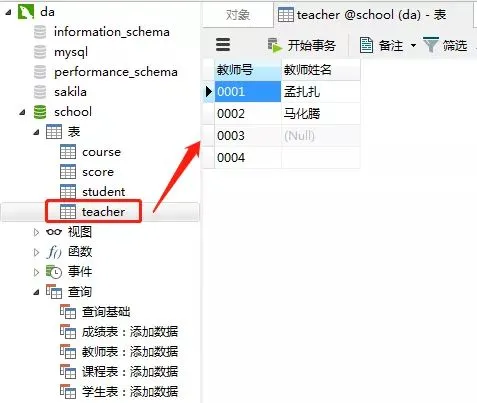
Add results
Three, 50 interview questions
In order to facilitate learning, I have classified 50 interview questions

Query the list of students whose surname is "Monkey"

Query the number of teachers surnamed "Meng"
select count(教师号)
from teacher
where 教师姓名 like '孟%';2. Summary statistics grouping analysis
Interview question: Query the total score of the course number "0002"
--分析思路
--select 查询结果 [总成绩:汇总函数sum]
--from 从哪张表中查找数据[成绩表score]
--where 查询条件 [课程号是0002]
select sum(成绩)
from score
where 课程号 = '0002';Query the number of students who have chosen a course
--这个题目翻译成大白话就是:查询有多少人选了课程
--select 学号,成绩表里学号有重复值需要去掉
--from 从课程表查找score;
select count(distinct 学号) as 学生人数
from score;
Query the highest and lowest scores of each subject, displayed in the following form: course number, highest score, lowest score
/*
分析思路
select 查询结果 [课程ID:是课程号的别名,最高分:max(成绩) ,最低分:min(成绩)]
from 从哪张表中查找数据 [成绩表score]
where 查询条件 [没有]
group by 分组 [各科成绩:也就是每门课程的成绩,需要按课程号分组];
*/
select 课程号,max(成绩) as 最高分,min(成绩) as 最低分
from score
group by 课程号;Query the number of students selected for each course
/*
分析思路
select 查询结果 [课程号,选修该课程的学生数:汇总函数count]
from 从哪张表中查找数据 [成绩表score]
where 查询条件 [没有]
group by 分组 [每门课程:按课程号分组];
*/
select 课程号, count(学号)
from score
group by 课程号;Query the number of boys and girls
/*
分析思路
select 查询结果 [性别,对应性别的人数:汇总函数count]
from 从哪张表中查找数据 [性别在学生表中,所以查找的是学生表student]
where 查询条件 [没有]
group by 分组 [男生、女生人数:按性别分组]
having 对分组结果指定条件 [没有]
order by 对查询结果排序[没有];
*/
select 性别,count(*)
from student
group by 性别;
Query the student number and average grade of students whose average score is greater than 60 points
/*
题目翻译成大白话:
平均成绩:展开来说就是计算每个学生的平均成绩
这里涉及到“每个”就是要分组了
平均成绩大于60分,就是对分组结果指定条件
分析思路
select 查询结果 [学号,平均成绩:汇总函数avg(成绩)]
from 从哪张表中查找数据 [成绩在成绩表中,所以查找的是成绩表score]
where 查询条件 [没有]
group by 分组 [平均成绩:先按学号分组,再计算平均成绩]
having 对分组结果指定条件 [平均成绩大于60分]
*/
select 学号, avg(成绩)
from score
group by 学号
having avg(成绩)>60;Check the student ID of at least two courses
/*
翻译成大白话:
第1步,需要先计算出每个学生选修的课程数据,需要按学号分组
第2步,至少选修两门课程:也就是每个学生选修课程数目>=2,对分组结果指定条件
分析思路
select 查询结果 [学号,每个学生选修课程数目:汇总函数count]
from 从哪张表中查找数据 [课程的学生学号:课程表score]
where 查询条件 [至少选修两门课程:需要先计算出每个学生选修了多少门课,需要用分组,所以这里没有where子句]
group by 分组 [每个学生选修课程数目:按课程号分组,然后用汇总函数count计算出选修了多少门课]
having 对分组结果指定条件 [至少选修两门课程:每个学生选修课程数目>=2]
*/
select 学号, count(课程号) as 选修课程数目
from score
group by 学号
having count(课程号)>=2;Query the list of same-sex students with the same name and count the number of people with the same name
/*
翻译成大白话,问题解析:
1)查找出姓名相同的学生有谁,每个姓名相同学生的人数
查询结果:姓名,人数
条件:怎么算姓名相同?按姓名分组后人数大于等于2,因为同名的人数大于等于2
分析思路
select 查询结果 [姓名,人数:汇总函数count(*)]
from 从哪张表中查找数据 [学生表student]
where 查询条件 [没有]
group by 分组 [姓名相同:按姓名分组]
having 对分组结果指定条件 [姓名相同:count(*)>=2]
order by 对查询结果排序[没有];
*/
select 姓名,count(*) as 人数
from student
group by 姓名
having count(*)>=2;Query failed courses and sort them by course number from largest to smallest
/*
分析思路
select 查询结果 [课程号]
from 从哪张表中查找数据 [成绩表score]
where 查询条件 [不及格:成绩 <60]
group by 分组 [没有]
having 对分组结果指定条件 [没有]
order by 对查询结果排序[课程号从大到小排列:降序desc];
*/
select 课程号
from score
where 成绩<60
order by 课程号 desc;Query the average score of each course, and the results are sorted in ascending order of average score. When the average score is the same, they are sorted in descending order by course number
/*
分析思路
select 查询结果 [课程号,平均成绩:汇总函数avg(成绩)]
from 从哪张表中查找数据 [成绩表score]
where 查询条件 [没有]
group by 分组 [每门课程:按课程号分组]
having 对分组结果指定条件 [没有]
order by 对查询结果排序[按平均成绩升序排序:asc,平均成绩相同时,按课程号降序排列:desc];
*/
select 课程号, avg(成绩) as 平均成绩
from score
group by 课程号
order by 平均成绩 asc,课程号 desc;Retrieve the student ID of the student whose course number is "0004" and the score is less than 60, and the results are sorted in descending order by score
/*
分析思路
select 查询结果 []
from 从哪张表中查找数据 [成绩表score]
where 查询条件 [课程编号为“04”且分数小于60]
group by 分组 [没有]
having 对分组结果指定条件 []
order by 对查询结果排序[查询结果按按分数降序排列];
*/
select 学号
from score
where 课程号='04' and 成绩 <60
order by 成绩 desc;Count the number of students elective for each course (only count for courses with more than 2 students)
It is required to output the course number and the number of electives. The query results are sorted in descending order by the number of people. If the number of people is the same, they are sorted in ascending order by the number of courses.
/*
分析思路
select 查询结果 [要求输出课程号和选修人数]
from 从哪张表中查找数据 []
where 查询条件 []
group by 分组 [每门课程:按课程号分组]
having 对分组结果指定条件 [学生选修人数(超过2人的课程才统计):每门课程学生人数>2]
order by 对查询结果排序[查询结果按人数降序排序,若人数相同,按课程号升序排序];
*/
select 课程号, count(学号) as '选修人数'
from score
group by 课程号
having count(学号)>2
order by count(学号) desc,课程号 asc;Query the student ID and average grades of students who failed more than two courses
/*
分析思路
先分解题目:
1)[两门以上][不及格课程]限制条件
2)[同学的学号及其平均成绩],也就是每个学生的平均成绩,显示学号,平均成绩
分析过程:
第1步:得到每个学生的平均成绩,显示学号,平均成绩
第2步:再加上限制条件:
1)不及格课程
2)两门以上[不及格课程]:课程数目>2
/*
第1步:得到每个学生的平均成绩,显示学号,平均成绩
select 查询结果 [学号,平均成绩:汇总函数avg(成绩)]
from 从哪张表中查找数据 [涉及到成绩:成绩表score]
where 查询条件 [没有]
group by 分组 [每个学生的平均:按学号分组]
having 对分组结果指定条件 [没有]
order by 对查询结果排序[没有];
*/
select 学号, avg(成绩) as 平均成绩
from score
group by 学号;
/*
第2步:再加上限制条件:
1)不及格课程
2)两门以上[不及格课程]
select 查询结果 [学号,平均成绩:汇总函数avg(成绩)]
from 从哪张表中查找数据 [涉及到成绩:成绩表score]
where 查询条件 [限制条件:不及格课程,平均成绩<60]
group by 分组 [每个学生的平均:按学号分组]
having 对分组结果指定条件 [限制条件:课程数目>2,汇总函数count(课程号)>2]
order by 对查询结果排序[没有];
*/
select 学号, avg(成绩) as 平均成绩
from score
where 成绩 <60
group by 学号
having count(课程号)>=2;If you can't do the above topic, you can review the SQL knowledge involved in this part:
3. Complex queries
Query the student ID and name of all students whose course scores are less than 60 points
[Knowledge Points] Subquery
1. Translate into the vernacular
1) Query result: student ID, name 2) Query condition: all students whose course scores are less than 60 need to be searched from the score table, using sub-query
The first step is to write a subquery (all students whose course grades are less than 60)
select 查询结果[学号]
from 从哪张表中查找数据[成绩表:score]
where 查询条件[成绩 < 60]
group by 分组[没有]
having 对分组结果指定条件[没有]
order by 对查询结果排序[没有]
limit 从查询结果中取出指定行[没有];
select 学号
from score
where 成绩 < 60;Step 2: Query result: student ID, name, condition is the student ID found in the previous step
select 查询结果[学号,姓名]
from 从哪张表中查找数据[学生表:student]
where 查询条件[用到运算符in]
group by 分组[没有]
having 对分组结果指定条件[没有]
order by 对查询结果排序[没有]
limit 从查询结果中取出指定行[没有];
select 学号,姓名
from student
where 学号 in (
select 学号
from score
where 成绩 < 60
);Query the student ID and name of students who have not studied all courses
/*
查找出学号,条件:没有学全所有课,也就是该学生选修的课程数 < 总的课程数
【考察知识点】in,子查询
*/
select 学号,姓名
from student
where 学号 in(
select 学号
from score
group by 学号
having count(课程号) < (select count(课程号) from course)
);Find out the student numbers and names of all students who have only taken two courses
select 学号,姓名
from student
where 学号 in(
select 学号
from score
group by 学号
having count(课程号)=2
);List of students born in 1990

/*
查找1990年出生的学生名单
学生表中出生日期列的类型是datetime
*/
select 学号,姓名
from student
where year(出生日期)=1990; Query the top two records of each subject
This kind of problem is actually common: group the maximum and minimum values of each group, and the largest N (top N) records of each group.
sql interview questions: topN questions
Such business problems are often encountered at work:
- How to find out which product the user likes most under each category?
- What if you find the 5 most clicked products in each category?
This kind of problem is actually common: group the maximum and minimum values of each group, and the largest N (top N) records of each group.
How to solve this kind of problems?
Below we give the answer through the example of the score sheet.
The transcript is the student's score, which has the student number (student number), course number (the student's elective course number), and the grade (the student's grades obtained by taking the course)

Group the maximum value of each group
Case: Group by course number to get the data in the row where the maximum score is located
We can use group by and summary functions to get a value (maximum, minimum, average, etc.) in each group. However, the data in the row where the maximum score is located cannot be obtained.
select 课程号,max(成绩) as 最大成绩
from score
group by 课程号;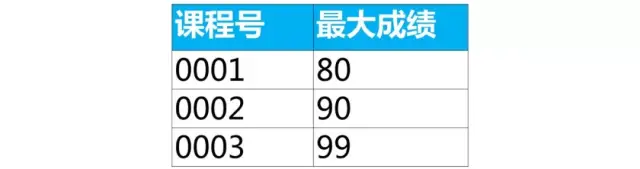
We can use correlated subqueries to achieve:
select *
from score as a
where 成绩 = (
select max(成绩)
from score as b
where b.课程号 = a.课程号);
The above query result has 2 rows of data for the course number "0001" because the maximum score 80 has 2
Group the minimum value of each group
Case: Group by course number to get the data in the row where the minimum score is located
The same use of associated subqueries to achieve
select *
from score as a
where 成绩 = (
select min(成绩)
from score as b
where b.课程号 = a.课程号);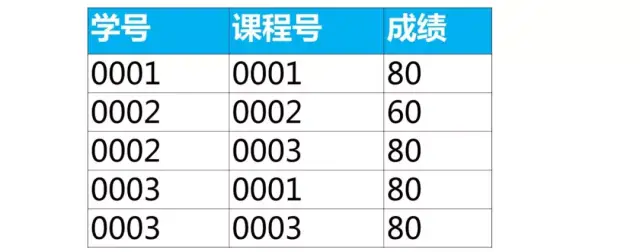
The largest N records in each group
Case: Query the top two records of each subject
Step 1, find out which groups are there
We can group by course number to find out which groups are there, corresponding to which course numbers are in this question
select 课程号,max(成绩) as 最大成绩
from score
group by 课程号;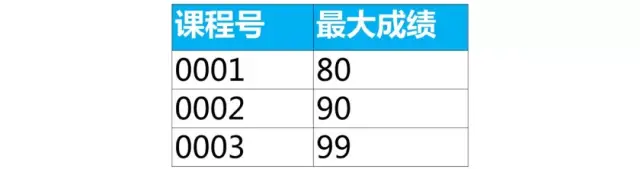
Step 2: First use the order by clause to sort the results in descending order (desc), and then use the limt clause to return topN (corresponding to the top two results returned by this question)
-- 课程号'0001' 这一组里成绩前2名
select *
from score
where 课程号 = '0001'
order by 成绩 desc
limit 2;Similarly, you can write other groups (other course numbers) to take out the top 2 SQL
Step 3, use union all to merge the selected data from each group together
-- 左右滑动可以可拿到全部sql
(select * from score where 课程号 = '0001' order by 成绩 desc limit 2)
union all
(select * from score where 课程号 = '0002' order by 成绩 desc limit 2)
union all
(select * from score where 课程号 = '0003' order by 成绩 desc limit 2);
Earlier, we used the order by clause to sort by a column in descending order (desc) to get the largest N records in each group. If you want to reach the minimum N records in each group, sort the order by clause in ascending order (asc) by a certain column.
The problem of seeking topN can also be implemented using custom variables, which will be introduced later.
If you don’t know much about multi-table merging, you can look at the "multi-table query" in "Learning SQL from Zero" that I talked about.
Summarize
Common interview questions: Take the maximum and minimum values of each group in groups, and the largest N (top N) records of each group.
Multi-table query
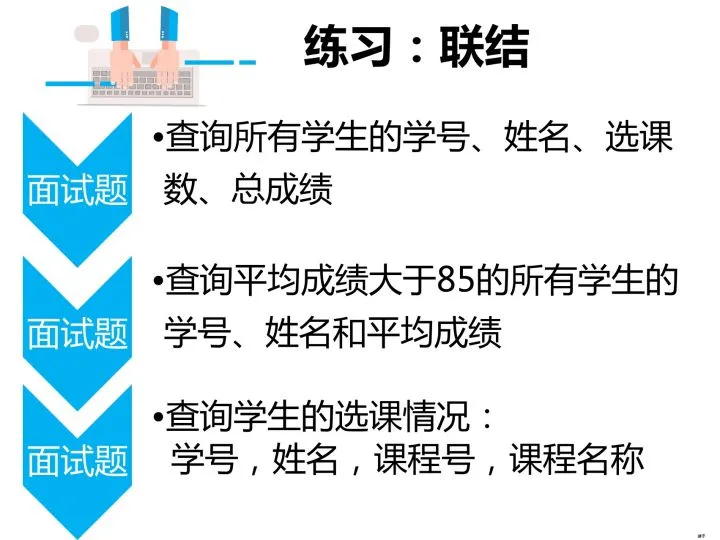
Query the student ID, name, number of courses, and total score of all students
select a.学号,a.姓名,count(b.课程号) as 选课数,sum(b.成绩) as 总成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号;Query the student ID, name, and average score of all students with an average score greater than 85
select a.学号,a.姓名, avg(b.成绩) as 平均成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号
having avg(b.成绩)>85;Query the student's course selection status: student ID, name, course number, course name
select a.学号, a.姓名, c.课程号,c.课程名称
from student a inner join score b on a.学号=b.学号
inner join course c on b.课程号=c.课程号;Query the number of pass and fail for each course
-- 考察case表达式
select 课程号,
sum(case when 成绩>=60 then 1
else 0
end) as 及格人数,
sum(case when 成绩 < 60 then 1
else 0
end) as 不及格人数
from score
group by 课程号;Use the segment [100-85],[85-70],[70-60],[<60] to count the scores of each subject, respectively: the number of people in each score segment, the course number and the name of the course
-- 考察case表达式
select a.课程号,b.课程名称,
sum(case when 成绩 between 85 and 100
then 1 else 0 end) as '[100-85]',
sum(case when 成绩 >=70 and 成绩<85
then 1 else 0 end) as '[85-70]',
sum(case when 成绩>=60 and 成绩<70
then 1 else 0 end) as '[70-60]',
sum(case when 成绩<60 then 1 else 0 end) as '[<60]'
from score as a right join course as b
on a.课程号=b.课程号
group by a.课程号,b.课程名称;Query the student number and name of the student whose course number is 0003 and whose course score is above 80 points|
select a.学号,a.姓名
from student as a inner join score as b on a.学号=b.学号
where b.课程号='0003' and b.成绩>80;The following is the student's score table (table name score, column name: student number, course number, grade)
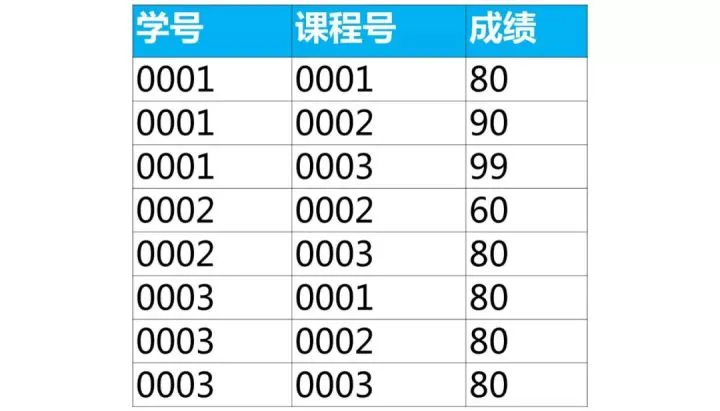
Use sql to implement the table row into the following table structure

[Summary of Interview Question Types] This type of question belongs to how to exchange ranks, and the ideas for solving the questions are as follows:
[Interview Questions] Below is the student's score sheet (table name score, column name: student number, course number, grade)

Use sql to implement the table row into the following table structure
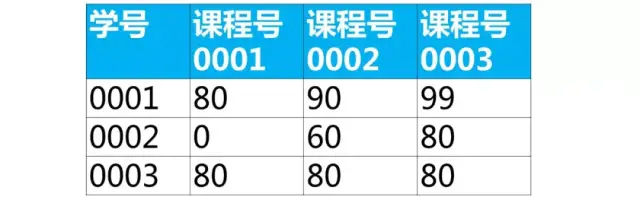
【answer】
Step 1, use the constant column to output the structure of the target table
You can see that the query result is very close to the target table
select 学号,'课程号0001','课程号0002','课程号0003'
from score;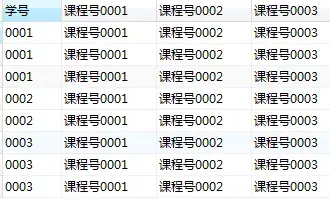
The second step, use case expressions, replace constants as the corresponding grades
select 学号,
(case 课程号 when '0001' then 成绩 else 0 end) as '课程号0001',
(case 课程号 when '0002' then 成绩 else 0 end) as '课程号0002',
(case 课程号 when '0003' then 成绩 else 0 end) as '课程号0003'
from score;
In this query result, each row represents the grade of a certain course of a certain student. For example, the first row is the result of'Student ID 0001' Elective Course No. 00001', while the scores of the other two columns of'Course ID 0002' and'Course ID 0003' are 0.
The grades of each student taking a certain course are in each box in the figure below. We can take out the grades of each course by grouping.

Level 3, grouping
Group, and use the maximum value function max to get the maximum value in each square in the figure above
select 学号,
max(case 课程号 when '0001' then 成绩 else 0 end) as '课程号0001',
max(case 课程号 when '0002' then 成绩 else 0 end) as '课程号0002',
max(case 课程号 when '0003' then 成绩 else 0 end) as '课程号0003'
from score
group by 学号;So we get the target table (row and column swap)
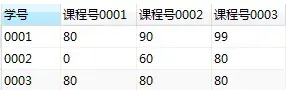
Author: sh_c_2450957609
blog.csdn.net/u010565545/article/details/100785261








**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。