
Apache Kyuubi (Incubating) (hereinafter referred to as Kyuubi) is an enterprise-level JDBC gateway built on Spark SQL, compatible with the HiveServer2 communication protocol, and providing high availability and multi-tenancy capabilities. Kyuubi has a scalable architecture design, and the community is working hard to enable it to support more communication protocols (such as RESTful, MySQL) and computing engines (such as Flink).
Kyuubi's vision is to make big data civilians. A typical usage scenario is to replace HiveServer2 to help enterprises migrate HiveQL to Spark SQL, and easily obtain 10 to 100 times performance improvement (the specific improvement is related to SQL and data). In addition, the two technologies that have become popular recently, LakeHouse and Data Lake, are closely integrated with Spark. If we can migrate the computing engine to Spark, then we are very close to these two technologies.
Kyuubi originated from NetEase, and this project has been open source since its inception. In the first two years of Kyuubi's development, its usage scenarios were mainly within NetEase. Since a major architectural upgrade and the release of Kyuubi 1.0 at the end of 2020, the entire Kyuubi community has become active, and the project has been adopted by more and more companies, and then entered the Apache Foundation incubator in June this year, and in September this year The first version 1.3.0-incubating after entering the incubator was released in October.
Kyuubi vs SparkThriftServer vs HiveServer2
We compare Kyuubi with other SQL on Spark solutions to see what kind of improvement can be brought by replacing HiveServer2 with Kyuubi. In the figure, Hive Server2 is marked with Hive on Spark, which is a function of Hive2. The earliest Hive will translate SQL into MapReduce for execution. The Hive on Spark solution actually translates SQL into Spark operator for execution, but this is just The replacement of physical operators, because Hive's SQL parsing logic is reused, the SQL dialect is still HiveQL, including subsequent SQL rewriting and optimization are all Hive optimizers. Spark2 abandoned the Hive on Spark solution and chose to do SQL parsing and optimization from scratch, creating Spark SQL and Catalyst. Therefore, Spark Thrift Server is only compatible with the Thrift communication protocol of HiveServer2, and its entire SQL analysis and optimization have been rewritten.

Kyuubi also uses Spark to parse, optimize and execute SQL, so for users, the communication protocol between the client and the server is exactly the same, because everyone is compatible with the communication protocol of HiveServer2. But in the SQL dialect, Kyuubi and Spark Thrift Server are Spark SQL, and HiveServer2 is HiveQL. The SQL compilation and optimization process is performed on the HiveServer2 process, and Spark is performed on the Driver side. For STS, Thrift Server and Driver are in the same process; for Kyuubi, Thrift Server and Spark Driver are separate, they can run in different processes on the same machine (such as YARN Client mode), or they can run on different machines (Such as YARN Cluster mode).
For the execution stage, when a SQL is submitted, HiveServer2 will translate it into a Spark Application. Each SQL submission will generate a brand new Spark application, which will go through the creation of Driver and Executor. After the SQL execution is over Destroy it again. Spark Thrift Server is the completely opposite way. A Spark Thrift Server only holds one Driver, and the Driver is resident. All SQL will be compiled and executed by this Driver. Kyuubi not only supports these two methods, but also supports a more flexible Driver sharing strategy, which will be described in detail later.
Kyuubi on Spark and CDH integration
CDH is one of the most widely used Apache Hadoop distributions. It integrates Spark itself, but disables the Spark Thrift Server function and spark-sql commands, so that users can only use Spark through spark-shell and spark-submit. Therefore, in CDH There are certain thresholds for using Spark SQL on the Internet. Hive is often used in SQL solutions on CDH. For example, we can connect to HiveServer2 through Beeline and HUE to submit SQL batch tasks or interactive queries. At the same time, we can also connect to HiveServer2 through BI tools such as Apache Superset. For data visualization, the final computing engine behind it can be MapReduce or Spark.

When we introduce Kyuubi, these Clients on the left side of the figure do not need to be changed. You only need to deploy Spark3 and Kyuubi Server (currently Kyuubi only supports Spark3), and then change the Client connection address to complete the transition from HiveQL to Spark. SQL migration. Of course, there may be differences between the HiveQL dialect and the Spark SQL dialect. You can choose to modify Spark or modify SQL to solve this problem.

An important concept in Kyuubi is called Engine Share Level. Kyuubi provides a more advanced Spark Driver sharing strategy through this feature. The concepts of Spark Engine and Spark Driver are equivalent, and both correspond to a Spark Application. Kyuubi currently provides three Engine sharing levels, SERVER, USER, and CONNECTION. The default is USER mode.
The SERVER mode is similar to Spark Thrift Server, Kyuubi Server will only hold one Spark Engine, that is, all queries will be submitted to one Engine to run. USER mode means that each user will use an independent Engine, which can achieve user-level isolation. This is also a more universal way. On the one hand, you don’t want to waste resources too much. Each SQL has an Engine, and the other The aspect also hopes to maintain a certain degree of isolation. CONNECTION mode refers to the creation of an Engine every time a client establishes a connection. This mode is similar to Hive Server2, but not completely the same. CONNECTION mode is more suitable for running batch calculations, such as ETL tasks, which often take tens of minutes or even hours. Users do not want these tasks to interfere with each other, and also hope that different SQLs have different configurations, such as 2G memory or 8G memory allocated for Driver . In general, the CONNECTION mode is more suitable for running batch tasks or large tasks, and the USER mode is more suitable for HUE interactive query scenarios.
You may be worried, did we make a thick layer of packaging for Spark, restricting many functions? Actually not, all Spark configurations are available in Kyuubi. When a request is sent to Kyuubi, Kyuubi will find a suitable Engine to run this task. If it cannot find it, it will create an Engine by splicing spark-submit commands, so all Spark-supported configurations can be used. As shown in the figure, the two modes of YARN Client and YARN Cluster are listed. How to write the configuration, the Spark Driver runs where, change to K8s, the Driver runs in Kubernetes, so Kyuubi's support for Kubernetes is natural.
There is another question frequently asked by users, is it USER mode or CONNECTION mode? A set of Kyuubi Server needs to be deployed separately in each scenario? unnecessary. We can solidify the commonly used configuration in kyuubi-defaults.conf. When the Client connects to the Kyuubi Server, you can override the default configuration items by writing some configuration parameters in the URL. For example, the USER mode is used by default, and when submitting batch tasks Select CONNECTION mode.
Implementation of Kyuubi Engine Isolation Level
How is Kyuubi's multiple flexible isolation levels achieved? The green component in the figure below is the Service Discovery Layer, which is currently implemented by ZooKeeper, but it is essentially a service registration/discovery component. We have found that some developers have integrated Kyuubi into Kubernetes and used API Server to implement Service Discovery Layer. This function has not yet been submitted to the community.

The User Side in the above figure is the Client side. The current strategy of the community is to be fully compatible with Hive Client to better reuse the Hive ecosystem. Hive itself implements the HA mode on the client side through ZooKeeper. After the server is started, it will register itself in ZooKeeper according to certain rules. When Beeline or other clients connect, set the connection address to the address of the ZooKeeper cluster, and the client can find it All servers under the specified path, randomly select one of them to connect. This is part of the HiveServer2 protocol, and Kyuubi is fully compatible.
A similar service registration and discovery mechanism is also used between Kyuubi Server and Engine. The registration path of Engine on Zookeeper will comply with certain rules. For example, under the USER isolation level, the path rule is /kyuubi_USER/{username}/{engine_node} . Kyuubi Server receives a connection request and will find available Engine nodes from a specific path according to the rules. If found, directly connect to the Engine; if not found, create an Engine and wait for its startup to complete. After the Engine startup is completed, an engine node will be created under the specified path according to the same rules, and its own (including the connection address, Version, etc.) fill in the node. In the YARN Cluster mode, the Engine will be assigned to any node in the YARN cluster to start. It is through this mechanism that the Server can find and connect to the Engine.
For CONNECTION mode, each Engine will only be connected once. In order to achieve this effect, Kyuubi designed the following path rules, /kyuubi_CONNECTION/{username}/{uuid}/{engine_node}, to achieve isolation through the uniqueness of UUID. So the way Kyuubi implements the engine isolation level is a very flexible mechanism. We currently support SERVER, USER and CONNECTION, but through simple extensions, it can support more and more flexible modes. On the main branch of the code, the community has implemented two additional sharing levels. One is GROUP, which allows a group of users to share an Engine; the other is Engine Pool, which allows a user to use multiple Engines to improve concurrency. Ability, an applicable scenario is BI chart display. For example, a Service Account is configured for Superset, corresponding to multiple Engines. When hundreds of charts are refreshed together, the calculation pressure can be allocated to different Engines.
Kyuubi实践 | 编译Spark3.1以适配CDH5并集成Kyuubi https://mp.weixin.qq.com/s/lgbmM1qNetuPB0-j-TAzkQ Apache Kyuubi on Spark 在CDH上的深度实践 https://my.oschina.net/u/4565392/blog/5264848
We have provided two articles on Kyuubi's official official account. The content contains the specific operation process of integrating Kyuubi into the CDH platform. The first one describes the integration with CDH5 (Hadoop2, enabling Kerberos), and the second one describes CDH6. (Hadoop3, Kerberos is not enabled) integration. It also has certain reference value for Hadoop distributions that integrate other non-CDH platforms.

Spark 3 features and enhancements brought by Kyuubi
Dynamic resource allocation
The first is dynamic resource allocation. Spark itself has provided the dynamic scalability of Executor. It can be seen that these parameter configurations are very clear in semantics, describing the minimum number of Executors, the maximum number of Executors, and the maximum idle time to control the dynamic creation and release of Executors.
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=0
spark.dynamicAllocation.maxExecutors=30
spark.dynamicAllocation.executorIdleTimeout=120
After the introduction of Kyuubi, combined with the creation mechanism of Share Level and Engine mentioned earlier, we can realize the dynamic creation of Driver, and then we also introduce a parameter, engine.idle.timeout, which stipulates that the Driver will be released after it has been idle for a long time. , In this way, the dynamic creation and release of Spark Driver is realized.
kyuubi.engine.share.level=CONNECTION|USER|SERVER
kyuubi.session.engine.idle.timeout=PT1HIt should be noted here that because the CONNECTION scene is special, the Driver will not be reused, so for the CONNECTION mode, engine.idle.timeout is meaningless, as long as the connection is disconnected, the Driver will exit immediately.
Adaptive Query Execution
Adaptive Query Execution (AQE) is an important feature brought by Spark 3. In short, it allows SQL to be optimized while executing. Take Join as an example, equivalent Inner Join, large tables do Sort Merge Join to large tables, and large tables do Broadcast Join to small tables, but the judgment of the size of the table occurs in the SQL compilation and optimization stage, that is, in the SQL execution Before.
We consider such a scenario, two large tables and a large table Join, add a filter condition, and then we find that after running the filter conditions, it becomes a large table and a small table Join, which can satisfy Broadcast Join Condition, but because the execution plan is generated before running the SQL, it is still a Sort Merge Join, which will introduce an unnecessary Shuffle. This is the entry point of AQE optimization. You can let SQL run a part first, and then go back and run the optimizer to see if you can meet some optimization rules to make SQL execute more efficiently.

Another typical scenario is data skew. When talking about big data, we are not afraid of large amounts of data, but we are afraid of data skew, because under ideal circumstances, the performance can be linearly improved through the horizontal expansion of hardware, but once there is data skew, it may lead to disasters. Take Join as an example. We assume that it is an equivalent Inner Join. Some partitions are particularly large. In this scenario, we will have some solutions that need to modify the SQL. For example, we can select these large ones for separate processing. As a result, the Union is together; or adding a salt for a specific Join Key, such as adding a number suffix to break it up, but at the same time keeping the semantics unchanged, that is to say, the data corresponding to the table on the right needs to be copied to achieve the equivalent Join Semantics, and finally remove the added number suffix.
It can be found that such a manual processing solution also has certain rules to follow. The process is automated in Spark, so after opening AQE in Spark3, it can automatically help solve this type of Join data skew problem. If there are many large tables Join in our ETL task, and the data quality is relatively poor, there is serious data skew, and there is no energy to optimize SQL one by one, the migration from HiveQL to Spark SQL can bring very significant performance. It's not an exaggeration to improve, 10 to 100 times!
Extension
Spark provides extension capabilities through Extension API, and Kyuubi provides KyuubiSparkSQLExtension, which uses Extension API to make some enhancements to the original optimizer. Here is a list of some of the enhanced rules, including the Z-order function, which supports the Z-order optimization sorting function when data is written through the custom optimizer rules, and implements the Z-order grammar support through the extended SQL grammar; There are also some rules that enrich the monitoring statistics; there are also some rules that limit the number of query partition scans and the number of results returned.

Take RepartitionBeforeWriteHive as an example to make a brief introduction. This rule is used to solve the problem of writing small files in Hive. For the Hive dynamic partition writing scenario, if the last stage of the plan is executed, the Partition distribution of the DataFrame is inconsistent with the partition distribution of the Hive table before the Hive table is written. When data is written, each task will hold the data When written to many Hive table partitions, a large number of small files will be generated. When we enable the RepartitionBeforeWriteHive rule, it will insert a Repartition operator according to the partition of the Hive table before writing to the Hive table to ensure that the data in the same Hive table partition is held by a task, and avoid writing to generate a large number of small files.
Kyuubi provides switches for all rules. If you only want to enable some of these rules, please refer to the configuration document to open them. KyuubiSparkSQLExtension provides a Jar. When using it, you can copy the Jar to ${SPAKR_HOME}/jars, or add Jar to the command parameter --jar, then turn on KyuubiSparkSQLExtension, and choose to turn on specific functions according to the configuration items.
Spark on ClickHouse
Data Source V2 API is also an important feature introduced by Spark3. Data Source V2 was first proposed in Spark 2.3 and was redesigned in Spark 3.0. The following figure uses a variety of colors to mark the Data Source V2 API provided by different Spark versions. We can see that each version adds a large number of APIs. It can be seen that the DataSourceV2 API has very rich functions, but what we value more is that it has a very good scalability, so that the API can continue to evolve.

Apache Iceberg provides a relatively complete adaptation to the Data Source V2 API at this stage, because Iceberg's community members are the main designers and promoters of the Data Source V2 API, which also provides us with a very good Demo.
ClickHouse is currently in the field of OLAP, especially in the field of single-table query. If we can combine the two big data components of Spark and ClickHouse, making Spark read and write ClickHouse as simple as accessing Hive tables, which can simplify a lot. Work to solve many problems.
Based on the Data Source V2 API, we implemented and open sourced Spark on ClickHouse. In addition to adapting the API to improve the ease of using Spark to operate ClickHouse, we also paid great attention to performance, including support for transparent reading and writing of local tables. ClickHouse implements a relatively simple distributed solution based on distributed tables and local tables. If you write to the distributed table directly, the overhead is relatively large. A workaround is to modify the adjustment logic, manually calculate the shards, and directly write to the local table behind the distributed table. This solution is cumbersome and may cause errors. When using Spark ClickHouse Connector to write ClickHouse distributed tables, you only need to use SQL or DataFrame API. The framework will automatically identify the distributed tables and try to convert the writing to the distributed table into the writing to the local table to achieve automatic transparency. Writing local tables brings great performance improvements.
project address:
Quote
https://github.com/housepower/spark-clickhouse-connector

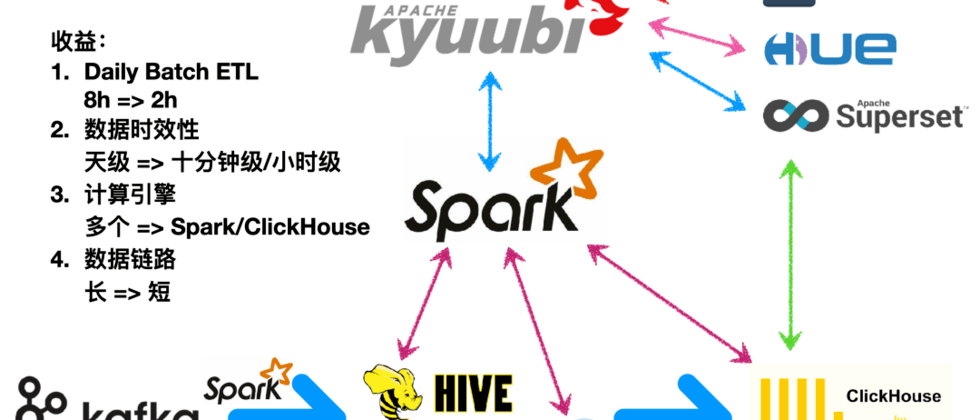
The following figure depicts a new generation of data platform after transformation, which has brought very significant benefits. Under the condition of unchanged hardware resources, first, the Daily Batch ETL dropped from 8 hours to 2 hours; secondly, through the introduction of Iceberg and incremental synchronization, the timeliness of data was reduced from day level to ten minutes level; third , Shrinking the computing engine, the original platform needs to be equipped with Hive, Elasticsearch, Presto, MongoDB, Druid, Spark, Kylin and other computing engines to meet different business scenarios. In the new platform, Spark and ClickHouse can meet most scenarios, greatly reducing The maintenance cost of the computing engine is reduced; finally, the data link is shortened. In the past, limited by the computing power of the RDMS, we often needed to process the data over and over again before displaying the data, and finally put the aggregation results in MySQL, but when After the introduction of ClickHouse, you usually only need to process the data into a wide table of themes. The report display uses ClickHouse's powerful single-table computing capabilities to perform on-site calculations, so the data link will be much shorter.

Kyuubi community outlook
Finally, look forward to the future development of the Kyuubi community. I just mentioned that the Kyuubi architecture is extensible. At present, Kyuubi is compatible with HiveServer2 because it only implements the Thrift Binary protocol; Kyuubi currently only supports the Spark engine, and the Flink engine is under development. This work is being done by community partners in T3 travel. The RESTful Frontend community is also doing it so that we can also provide RESTful APIs. We also plan to provide MySQL API, so that users can directly use MySQL Client or MySQL JDBC Driver to connect. Related issues or PRs in the community are attached.

The following are some of the features that will appear in version 1.4, including the Engine Pool, Z-order, Kerberos-related solutions that have just been mentioned, and the adaptation of the newly released Spark 3.2.
[KYUUBI #913] Support long running Kerberos enabled SQL engine
[KYUUBI #939] Add Z-Order extensions to support optimize SQL
[KYUUBI #962] Support engine pool feature
[KYUUBI #981] Add more detail stats to kyuubi engine page
[KYUUBI #1059] Add Plan Only Operations
[KYUUBI #1085] Add forcedMaxOutputRows rule for limitation
[KYUUBI #1131] Rework kyuubi-hive-jdbc module
[KYUUBI #1206] Support GROUP for engine.share.level
[KYUUBI #1224] Support Spark 3.2
. . .Finally, let's show the companies that are known to use Kyuubi. If you also use Kyuubi, or are investigating the enterprise-level Spark SQL Gateway solution, if you have any related questions, please share and discuss in our community.
GitHub share page:
Quote
https://github.com/apache/incubator-kyuubi/discussions/925

Concluding remarks
This article is based on the sharing content of Netease Shufan big data platform expert and Apache Kyuubi (Incubating) PPMC member Pan Cheng at the Apache Hadoop Meetup 2021 Beijing Station, focusing on actual landing cases to tell how to implement Apache Kyuubi (Incubating) on Spark and CDH Integration, and the benefits that this solution brings to the construction of enterprise data platforms, and look forward to the future development of the Apache Kyuubi (Incubating) community.

Apache Kyuubi (Incubating) project address:
https://github.com/apache/incubator-kyuubi
Video playback:
https://www.bilibili.com/video/BV1Lu411o7uk?p=20
Case Studies:
Apache Kyuubi's in-depth practice in T3 travel







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。