
Hi everyone, I'm Dongge.
This article would like to introduce to you hierarchical clustering , first introduce its basic theory through a simple example, and then use a practical case Python code to achieve the clustering effect.
First of all, clustering belongs to unsupervised learning of machine learning, and there are many methods, such as K-means , which is well-known. Hierarchical clustering is also a kind of clustering and is also very commonly used. Let me briefly review K-means , and then slowly introduce the definition and stratification steps of hierarchical clustering, which is more helpful for everyone to understand.
What is the difference between hierarchical clustering and K-means?
K-means working principle of 0619ae49d37813 can be briefly summarized as:
- Determine the number of clusters (k)
- Randomly select k points from the data as the centroid
- Assign all points to the nearest cluster centroid
- Calculate the centroid of the newly formed cluster
- Repeat steps 3 and 4
This is an iterative process until the centroid of the newly formed cluster does not change or the maximum number of iterations is reached.
However, K-means has some shortcomings. We must determine the number of clusters K before the algorithm starts, but we don’t actually know how many clusters there should be, so we generally set a value based on our own understanding. It may cause some deviations between our understanding and the actual situation.
Hierarchical clustering is completely different. It does not require us to specify the number of clusters at the beginning, but after forming the entire hierarchical cluster first, by determining the appropriate distance, the corresponding number of clusters and clusters can be automatically found.
What is hierarchical clustering?
Below we will introduce what is hierarchical clustering from the shallower to the deeper, let's take a simple example first.
Suppose we have the following points and we want to group them:

We can assign each of these points to a separate cluster, which is 4 clusters (4 colors):

Then based on the similarity (distance) of these clusters, combine the most similar (closest) points together and repeat this process until only one cluster remains:

The above is essentially building a hierarchy. First understand this, and later we will introduce its layering steps in detail.
Types of hierarchical clustering
There are mainly two types of hierarchical clustering:
- Agglomerated hierarchical clustering
- Split hierarchical clustering
Agglomerated hierarchical clustering
First let all points become a single cluster, and then continue to combine through similarity, until there is only one cluster at the end, this is the process of agglomerative hierarchical clustering, which is consistent with what we just said above.
Split hierarchical clustering
Splitting hierarchical clustering is just the opposite. It starts from a single cluster and gradually splits until it cannot be split, that is, each point is a cluster.
So it doesn't matter whether it is 10, 100, or 1000 data points, these points all belong to the same cluster at the beginning:

Now, in each iteration, split the two points furthest apart in the cluster and repeat this process until each cluster contains only one point:

The above process is split hierarchical cluster .
Steps to perform hierarchical clustering
The general process of hierarchical clustering has been mentioned above, but the key is here. How to determine the similarity of points and points?
This is one of the most important problems in clustering. The general method of calculating similarity is: Calculate the distance between the centroids of these clusters . The points with the smallest distance are called similar points. We can combine them, or call them distance-based algorithm .
In addition, in hierarchical clustering, there is a proximity matrix , which stores the distance between each point. Below we use an example to understand how to calculate the similarity, proximity matrix, and the specific steps of hierarchical clustering.
Case Introduction
Suppose a teacher wants to divide students into different groups. Now I have the scores of each student in the homework, and I want to divide them into groups based on these scores. Regarding how many groups you have, there is no fixed goal here. Since the teacher does not know which type of students should be assigned to which group, it cannot be solved as a supervised learning problem. Next, we will try to apply hierarchical clustering to divide students into different groups.
Here are the results of 5 students:

Create a proximity matrix
First, we have to create a proximity matrix, which stores the distance between each point, so we can get a square matrix of shape n X n.
In this case, the following 5 x 5 adjacency matrix can be obtained:

There are two points to note in the matrix:
- The diagonal elements of the matrix are always 0, because the distance between a point and itself is always 0
- Use the Euclidean distance formula to calculate the distance of off-diagonal elements
For example, we want to calculate the distance between points 1 and 2, the calculation formula is:
$$ \sqrt{(10-7)^2}=\sqrt{9}=3 $$
In the same way, fill in the remaining elements of the adjacent matrix after completing this calculation method.
Perform hierarchical clustering
This is achieved using agglomerative hierarchical clustering.
Step 1: First, we assign all points into a single cluster:

Here, different colors represent different clusters. The 5 points in our data are 5 different clusters.
Step 2: Next, we need find the smallest distance in the neighbor matrix and merge the points with the smallest distance . Then we update the proximity matrix:
The minimum distance is 3, so we will merge points 1 and 2:
Let's look at the updated cluster and update the neighbor matrix accordingly:



After the update, we took the largest value (7, 10) of the two points 1, 2 to replace the value of this cluster. Of course, in addition to the maximum value, we can also take the minimum or average value. Then, we will calculate the proximity matrix of these clusters again:
Step 3: Repeat step 2 until only one cluster remains.

After repeating all the steps, we will get the merged cluster as shown below:

This is the working principle of agglomerated hierarchical clustering. But the problem is that we still don’t know how many groups should we divide into? Is it 2, 3, or 4 groups?
Now let's introduce how to choose the number of clusters.
How to choose the number of clusters?
In order to obtain the number of hierarchical clusters, we used a concept called dendrogram .
Through the dendrogram, we can more conveniently select the number of clusters.
Go back to the example above. When we merge two clusters, the dendrogram will record the distance between these clusters accordingly and represent it in graphical form. The following is the original state of the tree diagram. The horizontal axis records the mark of each point, and the vertical axis records the distance between the points:

When two clusters are merged, they will be connected in a tree diagram, and the height of the connection is the distance between the points. The following is the process of hierarchical clustering we have just now.

Then begin to draw the tree diagram of the above process. Starting from merging samples 1 and 2, the distance between these two samples is 3.

You can see that 1 and 2 have been merged. The vertical line represents the distance between 1 and 2. In the same way, draw all the steps of merging clusters according to the hierarchical clustering process, and finally get this dendrogram:

Through the dendrogram, we can clearly visualize the steps of hierarchical clustering. The greater the distance between the vertical lines in the tree diagram, the greater the distance between clusters.
With this tree diagram, it is much more convenient for us to determine the number of cluster classes.
Now we can set up a threshold distance , draw a horizontal line. For example, we set the threshold to 12 and draw a horizontal line as follows:

From the intersection point, we can see that the number of clusters is the number of intersections with the threshold horizontal and vertical lines (the red line intersects with 2 vertical lines, we will have 2 clusters). Corresponding to the abscissa, one cluster will have a sample set (1,2,4), and the other cluster will have a sample set (3,5).
In this way, we solve the problem of determining the number of clusters in hierarchical clustering through the dendrogram.
Python code actual case
The above is the theoretical basis, and you can understand it with a little mathematical foundation. The following describes how to use the code Python to achieve this process. Here is the data of customer segmentation
The data set and code are here:
https://github.com/xiaoyusmd/PythonDataScience
Sharing is not easy, please give a star if you find it helpful!
This data comes from the UCI machine learning library. Our purpose is to subdivide wholesale distributors' customers based on their annual spending on different product categories (such as milk, groceries, regions, etc.).
First, standardize the data, in order to make all the data in the same dimension for easy calculation, and then apply hierarchical clustering to segment customers.
from sklearn.preprocessing import normalize
data_scaled = normalize(data)
data_scaled = pd.DataFrame(data_scaled, columns=data.columns)
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
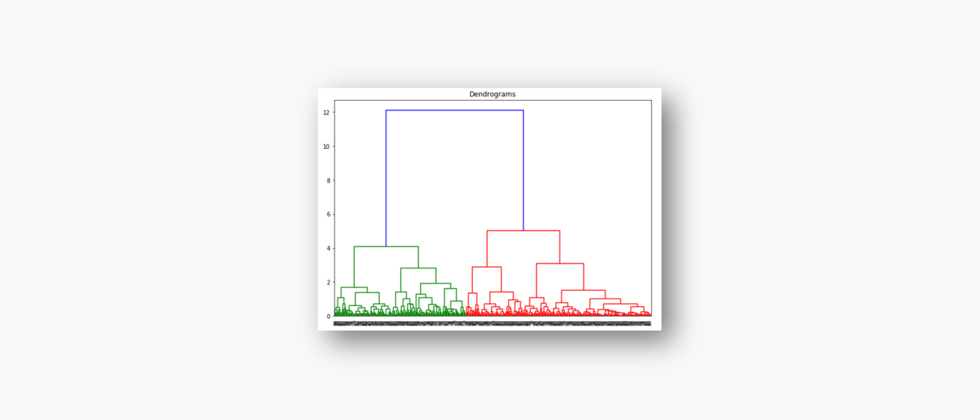
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))
The x-axis contains all samples, and the y-axis represents the distance between these samples. The vertical line with the largest distance is the blue line. If we decide to cut the dendrogram with a threshold of 6:
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))
plt.axhline(y=6, color='r', linestyle='--')
Now that we have two clusters, we need to apply hierarchical clustering to these two clusters:
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(data_scaled)
Since we have defined 2 clusters, we can see the values of 0 and 1 in the output. 0 represents the point belonging to the first cluster, and 1 represents the point belonging to the second cluster.
plt.figure(figsize=(10, 7))
plt.scatter(data_scaled['Milk'], data_scaled['Grocery'], c=cluster.labels_) 
Here we have successfully completed the clustering.
Reference: https://www.analyticsvidhya.com/blog/2019/05/beginners-guide-hierarchical-clustering/
Originality is not easy, I think it’s good.
In addition, please pay attention to my original public : 1619ae49d38135 Python Data Science


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。