
I believe everyone here has heard of cloud native, which has been a hot thing for the past three or four years. What is cloud native? The current cloud native is a very broad definition. It can be simply understood as your service is born for the cloud, or because now cloud native is based on Kubernetes container technology as the infrastructure, then as long as your services are running on Kubernetes, they It can be considered cloud native.
The topic I share with you today is the grayscale update that Luffy3 uses cloud native technology to achieve, mainly from the following 4 aspects:
- What is grayscale update
- Current status of grayscale updates
- Yunyuan Practice
- Summary and outlook
What is grayscale update
In order to give you a better understanding, I will use a simple example to tell you what gray update is.

Suppose you have an item about hotel reservations, and you need to provide a Web site for users to book rooms. In order to ensure the high availability of the business, the server developed by this project is distributed. Therefore, in the production environment, you set up a hotel reservation Web cluster, and set up a total of 3 servers to provide services to the outside world through the Nginx reverse proxy.
The picture on the left is a gray-scale update in the traditional sense, that is, part of the traffic is first directed to the new version for testing, if it can be fully promoted, if not, return to the previous version. For example, there are three machines deployed with the server, and the IP addresses are 0.2, 0.3, 0.4. For daily updates, choose to update on the 0.4 server first and see if there are any problems. After confirming that there are no problems, update 0.3 and 0.2.
The picture on the right uses container technology, which is more flexible than physical machine deployment. The concept it uses is instance, which is an instance, and multiple instances can be set up on the same machine. The access traffic will go through the gateway from left to right as shown in the figure. By adding some strategies on the gateway, 95% of the traffic will go to the original service above and 5% of the traffic go to the gray service below. By observing whether the grayscale service is abnormal, if there is no abnormality, you can update the container image version of the original service to the latest and delete the grayscale service below. This is not the same as the picture on the left. It is not a rolling update one after another, but directly updates all the original services with the help of an elastic resource platform.
Grayscale update status

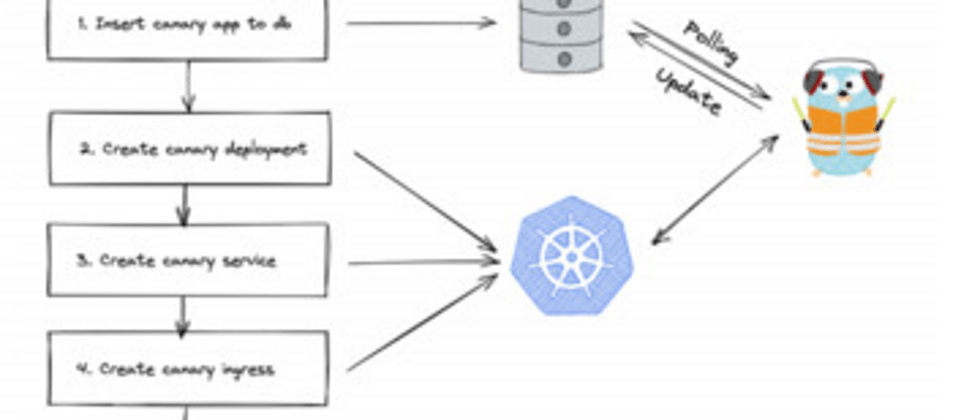
The above picture shows the status of grayscale update on Luffy2. The main problem is the API processing, because the previous state is maintained by the database, and the problem of inconsistent state is prone to occur.
The picture on the left is a simplified processing flow. When an API requests a service to request a gray-scale update of the service, the first step is to generate an App with a gray-scale name.
The second step is to explain to you in detail. First, put the generated App into the database and create a stateless service in Kubernetes. This usually takes about 10 minutes. During this period, a Go language program will continuously scan the App table to confirm whether the service has been created. At the same time, you also need to use Kubernetes to create forwarding rules, etc. After all the requirements are created, return to the original ok to the caller.
Performance issues are involved here, because there are many things to be processed in the database, which have to be processed one by one, and many of them are useless data. In the 10 minutes before scanning the App, even if you go to Kubernetes to call , Is also doing useless operations.
There is also a problem with a very long call chain. Many things created in Kubernetes will be included in the same API request. This can lead to a situation where the next step may crash after one step is completed at any time. At this time, you may want to consider whether to roll back, and if you roll back, you must delete related services and databases. This situation is more likely to occur when the more external components are called. The more intuitive solution is to simplify the API process, and Kubernetes provides CRD for this method.
Cloud native practice
CRD

The picture above is an explanation of CRD excerpted from the official Kubernetes website. Everyone should be familiar with this. The most important concept in Kubernetes is resources. Everything in it is a resource or object. The picture on the right is an example of a related stateless service, which contains the service version, type, label, and image version and the external port provided by the container. To create a stateless service in Kubernetes, you only need to complete the definition, and CRD can help us customize the content in the spec.
It should be noted that custom resources themselves can only be used to access structured data. Only when combined with a custom controller can it provide a true declarative API (Declarative API). By using the declarative API, you can declare or set the desired state of the resource, and synchronize the current state of the Kubernetes object to its desired state. That is, the controller is responsible for interpreting the structured data as a record of the user's desired state and continuously maintaining the state.

The picture above is about the related practices of declarative API, using the horizontal trigger method. For a simple example, the remote control used by the TV is edge triggered, as long as you press to change the channel, the change will be triggered immediately. The alarm clock is triggered horizontally. No matter how many times you change it before the alarm sounds, it will only trigger at the time you finally set. In summary, edge triggering pays more attention to timeliness and will give immediate feedback when changes are made. The horizontal trigger only pays attention to the final consistency, no matter what the front is, only to ensure that the final state is the same as we set.
Luffy3.0 CRD

The above picture is the overall structure of Luffy3.0 which is built on Kubernetes, and the service-related interactions with Kubernetes are all completed by apiserver.
In the lower right corner of the figure is a relational database. Relationships such as user relations and affiliation are all in this. It has a layer of redis cache on it to improve the efficiency of hot data query. The picture on the left is a few of our own CRDs. The second projects are related projects. When the project was founded that year, it was backed by CRD. First, it was written in the database, and then the CRD object of projects was created in Kubernetes.
Kubernetes client-go informer mechanism

Next, let’s talk about the implementation logic of informer. Informer is an SDK officially provided by Kubernetes to facilitate the interaction between you and Apiserver. It depends on the level trigger mechanism.
On the left side of the above picture is our apiserver, all data is stored in the key-value database ETCD. It uses the following structure when storing:
/registry/{kind}/{namespace}/{name}The prefix registry can be modified to prevent conflicts, kind is the type, and namespace is the namespace or project name, corresponding to Luffy3. The name at the end is the service name. When the object is created, updated, or deleted through apiserver, ETCD will feed back this event to apiserver. Then apiserver will open the changed object to informer. The informer is based on a single type {kind}, which means that if you have multiple types, you must have a corresponding informer for each type. Of course, this can be generated by code.
Going back to the informer implementation logic, when the informer is running, it will first go to Kubernetes to get the full amount of data. For example, if the current informer corresponds to a stateless service, it will get all the stateless services. Then continue to watch the apiserver, once the apiserver has a new stateless service, it will receive the corresponding event. After receiving a new event, the informer puts the time into the first-in-first-out queue for the controller to consume. The controller will pass the event to the module Processor for special processing. There are many listeners on the module Processor. These listeners are callback functions set for specific types.
Then let's take a look at why the lister and indexer in the controller are related. Because namespace is very similar to a directory, there will be a lot of stateless services in this directory. If you want to process according to a certain rule, processing on the native service is definitely the worst choice, and this is what the lister needs to do. It will cache this part and make an index, that is, inderxer. This index is very similar to a database and is composed of some keys.
For CRD, what needs to be realized is the contorller and the interaction between the informer and the controller. The other parts are generated by the code itself.

If the code is not generated, the above image will be used. The first three items are related to writing code. The API type requires us to fill in the definition of CRD, the definition of grayscale update, etc. After the definition is completed, the definition must be registered on Kubernetes, otherwise it will not work. Then, the code will generate the following 4 items, including deepcopy deep copy function, client, informer and lister using CRD.
The third piece is the controller related to the custom controller, including the Kubernetes rest client that interacts with the Apiserver, the time controller or the time function eventhandler and handlerfuncs, etc. What needs to be written here is the reconciliation function, because other officials have already encapsulated it for us, so you only need to define the reconciliation function.
After all encapsulation is completed, these things need to be stringed together. There are currently two mainstream choices, OperatorSDK and Kubebuilder.
OperatorSDK vs Kubebuilder

Let’s take a look at how the code is generated

Take OperatorSDK as an example to see how the code is generated. Of course, you can also choose to use Kubebuilder, there is little difference between the two generation methods. You can see the name of the warehouse in the "initialization project" in the above figure. It defines the version number of a version and the type canaryDeployment, which is a gray-scale no-service state. Then generate the corresponding resources and controllers. After finishing, write the reconciliation function and API definition just mentioned. It can be executed after all is completed, very simple.
Grayscale updated design

After talking about the above knowledge, let's take a look at the grayscale update. The figure above is a simple example of grayscale update, and the process starts from the left and ends on the right.
The first step is to create a grayscale service, which can be updated after creation. For example, in the Nginx example just now, the version number we created is 1.19. However, a bug was found in the current version during the grayscale process, and after the bug is fixed, the original service can be updated to version 1.20 and then the grayscale service can be deleted after confirming that it is correct. If you find that there are still bugs in version 1.20, you can also choose to delete the gray service and let your original service take over all traffic. This is how CRD simplifies the development steps.
There are 4 stages of gray update:
- create
- renew
- replace
- delete
Create
Because Kubernetes is triggered horizontally, all its creation and update processing logic is the same, just look at the final state.

This picture is more important, so you can take a closer look. The upper right part of the figure is the original service. The original service includes Kubernetes stateless service, Service internal domain name, ApisixRoute, Apisix routing rules, ApisixUpstrean, and some configurations of Apisix upstream. Below the original service is the gray-scale service, and the controller on the left is the aforementioned CRD controller.
After the original service is created, create a stateless service, configure the corresponding http forwarding rules, and then go to the ApisixRoute service station to configure the corresponding route. After that, only go to the container gateway to automatically locate the specified service. Then you can see that our custom CRD type name is CanaryDeployment, which is a grayscale stateless service. The process of creating this stateless service is the same as the original service.
How is the definition of CRD designed? The following figure is a simple example:

Let's not talk about apiVersion, let's look at the following parts in detail:
- kind: type, the type above is CanaryDeployment (stateless service)
- name: name
- namespace: location, under the test space of mohb-test
- version: version
- replicas: the number of gray-scale instances, this number is configurable
- weight: weight, which affects how much traffic the gray service takes over
- apisix: hb conversion rules corresponding to the service
- apisixRouteMatches: related functions
- parentDeployment: the name of the original stateless service
- template: This defines the configuration of mirroring, other commands, open ports, etc. just mentioned
Several problems may be encountered when defining CRDs. The first problem is that if the original service is deleted, the gray service will not be deleted automatically, and will be left behind. This problem occurs because there is no recycling technology for Kubernetes, and the ownerReferences of Kubernetes are needed to solve this problem. It can help you point the CRD of the gray-scale service to the stateless service of the original service, that is, the owner of the gray-scale service is responsible for the original service.

In this way, when deleting the original service, the owner will be responsible for deleting the gray-scale service. When deleting CanaryDeployment, only the Deployment to the right of it will be deleted.
The specific settings of ownerReferences are as follows:

When we define the CRD, we add the field in the red box. This field will specify whose owner it is and where it points to. The creation phase is basically completed here.
replaces
Next look at the second stage-replacement.

I control it by adding the field replace. By default, it is false. If the value is true, the controller will know to replace it with deployment. The question here is when to replace it? That is, when will the traffic be cut over. Although it is also possible to cut directly, it is undoubtedly better to wait until the original service is fully operational.
What exactly should I do?
This involves part of the logic of the informer. This requires the controller to be able to perceive whether the parentDeployment of the grayscale service has changed. This part of operator-sdk and Kubebuilder is very good. It can also import changes that are not CRD events into the reconciliation function, so that the controller can monitor stateless services.

You can look at the code for details. First register some watches to monitor the stateless service, and then write a function to make the stateless service correspond to CanaryDeployment, for example, mark the stateless service in the text back, so that when the event is sensed, you can see which stateless service is performing It replaces, and calculates the corresponding CanaryDeployment, and then compares whether there is a gap with the expectation by calling the reconciliation function.
cancel
Next, let's look at the last stage-the cancellation stage.
If you directly delete the object corresponding to CanaryDeployment, you will find that there is a deletionTimestamp field on the right side, which is the deletion time stamp of Kubernetes. As for the controller, it knows that this is already in the deleted state, and the corresponding content needs to be adjusted.

There is a problem. The deletion is an instant operation, and the deletion may be completed before the controller is up and running. Therefore, Kubernetes provides Finalizer, and Finalizer determines who will eventually release it.

Finalizer is custom, corresponding to our own controller. When Kubernetes sees that the Finalizer is not empty, it will not be deleted immediately, but out of the state of being deleted, which allows the controller to have time to do some corresponding processing.
Stress test wrk
After a set of things is done, the way to verify whether it is correct is to perform a stress test.

I used a more general tool to do the stress test, and I can set up more things. For example, some logical processing can be done. As in the example above, suppose there is a service, the original service requested will return "helloword", and the gray version will return "hello Hongbo". Then define the returned package, so that after each request, a function will be called to determine whether it is equal to 200. If it is not, there may be an exception during the cutting process. If it is equal to 200, you can check whether there is "Hongbo" in it. If so, it proves that the gray version is requested. In this way, the door sets a file (summary), and counts the number of requests to the original service, gray service, and failed requests.
In addition, you can make the following head settings:
- -c: how many links, such as 20
- -d: How long to put it down, such as 3 minutes
- -s: the address corresponding to the script

The above picture is the result of the stress test, you can take a look at it briefly.
Summary and planning
Next, I will talk to you about the summary after the introduction of CRD. After the introduction of CRD, based on the concept of Kubernetes event-driven and horizontal triggering, the complexity of implementation is simplified. And because of the adoption of the mature framework of OperatorSDK, you no longer need to care about the underlying implementation, and you can focus more on the business logic implementation. Reduce development costs and improve development efficiency.
Then regarding the future, there are the following plans:
- apisix adopts the subnet method to reduce the resources created and increase the success rate
- Supports grayscale by HTTP header and specific IP
- Grayscale service traffic comparison
The above is today's sharing of the practice of grayscale update, thank you for your support.







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。