
Original: https://blogs.gnome.org/rbultje/2015/09/28/vp9-encodingdecoding-performance-vs-hevch-264/
Published on September 28, 2015 by rbultje
A long time ago, I published about ffvp9, FFmpeg's native decoder for VP9 video codec, and its performance is significantly better than Google's decoder (part of libvpx). We also discussed encoding performance (mainly quality) and showed that VP9's performance is significantly better than H.264, although the speed is much slower. Since then, the elephant question in the room has been: how about HEVC? I couldn't solve this problem at the time because the blog post was mainly about decoders, and FFmpeg's HEVC decoder was immature (from a performance point of view). Fortunately, this problem has been solved! So here, I will compare the encoding (quality + speed) and decoding (speed) performance of VP9 and HEVC/H.264. [I introduced this before at the Webm Summit and VDD15, and also provided a Youtube version of the talk. ]
Coding quality
The most important issue with video codecs is quality. Scientifically speaking, we usually use standard codec settings to encode one or more video clips at various target bit rates, and then measure the objective quality of each output clip. The recommended objective indicator of video quality is SSIM. By plotting these bitrate/quality value pairs in the graph, we can compare video codecs. Now, when I say "codec", I really mean "encoder". For comparison, I compared libvpx (VP9), x264 (H.264) and x265 (HEVC), each of which uses 2-pass encoding to a set of target bitrates (x264/x265: –bitrate=250-16000; libvpx: –target-bitrate=250-16000) and SSIM adjustment (–tune=ssim) under the slowest (ie highest quality) setting (x264/5: –preset=veryslow; libvpx: –cpu-used=0), All forms of threading/tiling/slicing/wpp are disabled, and the key frame interval is 5 seconds. As a test segment, I used the Tears of Steel (1920×800) 2-minute segment (don’t stop, link expired).

This is a typical quality/bitrate chart. Please note that both axes are logarithmic. Let's first compare our two next-generation codecs (libvpx/x265 as the encoder for VP9/HEVC) with x264/H.264: they are much better (the green line is on the left of the blue, which means "The same quality has a smaller file size", or you can say that they are on the top, which means "the same file size has better quality"). Either way, they are better. This is to be expected.
How much better? Therefore, we usually try to estimate how many bits are needed for "blue" to achieve the same quality as (for example) "red" by comparing the actual red point with the interpolation point of the blue line (under the same SSIM score). For example, the red dot at 1960kbps has an SSIM score of 18.16. The blue line has two points at 17.52 (1950) and 18.63 (3900kbps). Interpolation gives an estimated point of approximately 2920kbps of SSIM=18.16, which is 49% larger. Therefore, to achieve the same SSIM score (quality), x264 requires 49% more bitrate than libvpx. Therefore, at this bit rate, libvpx is 49% better than x264, which is called bit rate improvement (%). At this bit rate, compared to libvpx, x265 has roughly the same improvement as x264.
The distance between the red/green line and the blue line becomes larger as the bit rate decreases, so the codec has a higher bit rate improvement at low bit rates. As the bit rate increases, the improvement decreases. We can also see the slight difference between the x265/libvpx of this clip: at low bit rates, x265 is slightly better than libvpx. At high bit rates, libvpx is better than x265. However, these differences are small compared to the improvements made to x264 by either encoder.
Encoding speed
So, these next-generation codecs sound great. Now let's talk about speed. Encoder developers don't like to talk about speed and quality at the same time, because they don't fit together well. To be honest: x264 is a very optimized encoder, and many people still use it. It’s not that they don’t want a better bitrate/quality ratio, but they complain that when they try to switch, they find that the encoder speeds of these new codecs are much slower, and when you increase their speed settings ( This will reduce their quality) and the benefits will disappear. Let's measure it! Therefore, I chose a target bitrate of 4000kbps for each encoder and used the same settings as before, but instead of using the slow preset, I used the variable speed preset (x265/x264: –preset=placebo-ultrafast; libvpx: – cpu-used=0-7).

This is a chart that people don't often talk about, so let's do it. In the horizontal direction, you will see the encoding time (in seconds) of each frame. Vertically, we see bit rate improvement. The indicator we introduced earlier is basically a combination of quality (SSIM) and bit rate compared to the reference point (x264 @veryslow is the reference point here, which is why the bit rate is improved Itself is 0%).
So what do these results mean? Well, first of all, yes, of course, as claimed, x265/libvpx is about 50% better than x264. However, they are also 10-20 times slower. This is not good! If you normalize for equal CPU usage, you will notice (again looking at the x264 point at 0%, 0.61 sec/frame), if you look at the intersection of the red line (libvpx) above the vertical, the bitrate will increase the normalization The CPU usage is only 20-30%. For x265, only 10%. To make matters worse, the x265 line actually intersects the x264 line to its left. In practice, this means that if the CPU usage target of x264 is faster than very slow, then you basically want to continue using x264, because under the same CPU usage target, for the same bitrate, x265 will provide more than x264 Poor quality. The situation of libvpx is slightly better than that of x265, but it is clear that these next-generation codecs still have a lot of work to do in this regard. This is not surprising, x264 is a much more mature software than x265/libvpx.
Decoding speed
Now let us look at the performance of the decoder. To test the decoder, I chose a 4000kbps x265/libvpx generated file and created an additional x264 file at a speed of 6500kbps. The SSIM scores of all these files roughly match, about 19.2 (PSNR=46.5). As a decoder, I use FFmpeg's native VP9/H264/HEVC decoder, libvpx and openHEVC. OpenHEVC is the "upstream" of FFmpeg's native HEVC decoder, and has slightly better assembly optimization (because they use intrinsics in idct routines, while FFmpeg still runs C code in this place, because it does not Like intrinsic functions).

So what does this mean? Let's start by comparing ffh264 and ffvp9. These are FFmpeg's H.264 and VP9 native decoders. Their decoding speed is about the same, ffvp9 is actually slightly faster, about 5% faster. Now, here comes the interesting thing. When scholars usually talk about next-generation codecs, they claim that it will be 50% slower. Why can't we see it here? The answer is simple: because we are comparing files of the same quality (not the same bitrate). Such optimized and mature decoders tend to spend most of their time on decoding coefficients. If the bit rate is 50% higher, it means you spend 50% more time on coefficient decoding. So, although the codec tool may be much more complicated in VP9 than in VP8/H.264, the bit rate saving prevents us from spending more time on actual decoding tasks with the same quality.
Next, let us compare ffvp9 with libvpx-vp9. The difference is huge: ffvp9 is 30% faster! But we already know. This is because FFmpeg's code base is better optimized than libvpx. This also introduces an interesting concept for potential encoder optimization: obviously (theoretically) we should be able to make an encoder that is better optimized (and therefore faster) than libvpx. Isn't that great?
Finally, let's compare ffvp9 with ffhevc: VP9 is 55% faster. This is partly because HEVC is much more complicated than VP9, and partly because of the C idct routines in ffhevc. For normalization, we also compared with openhevc (with idct intrinsic function). It is still 35% slower, so the VP9 story seems more interesting than HEVC at this time. FFmpeg's HEVC decoder still has a lot of work to do.
Multi-threaded decoding
Finally, let's take a look at the performance of multi-threaded decoding:
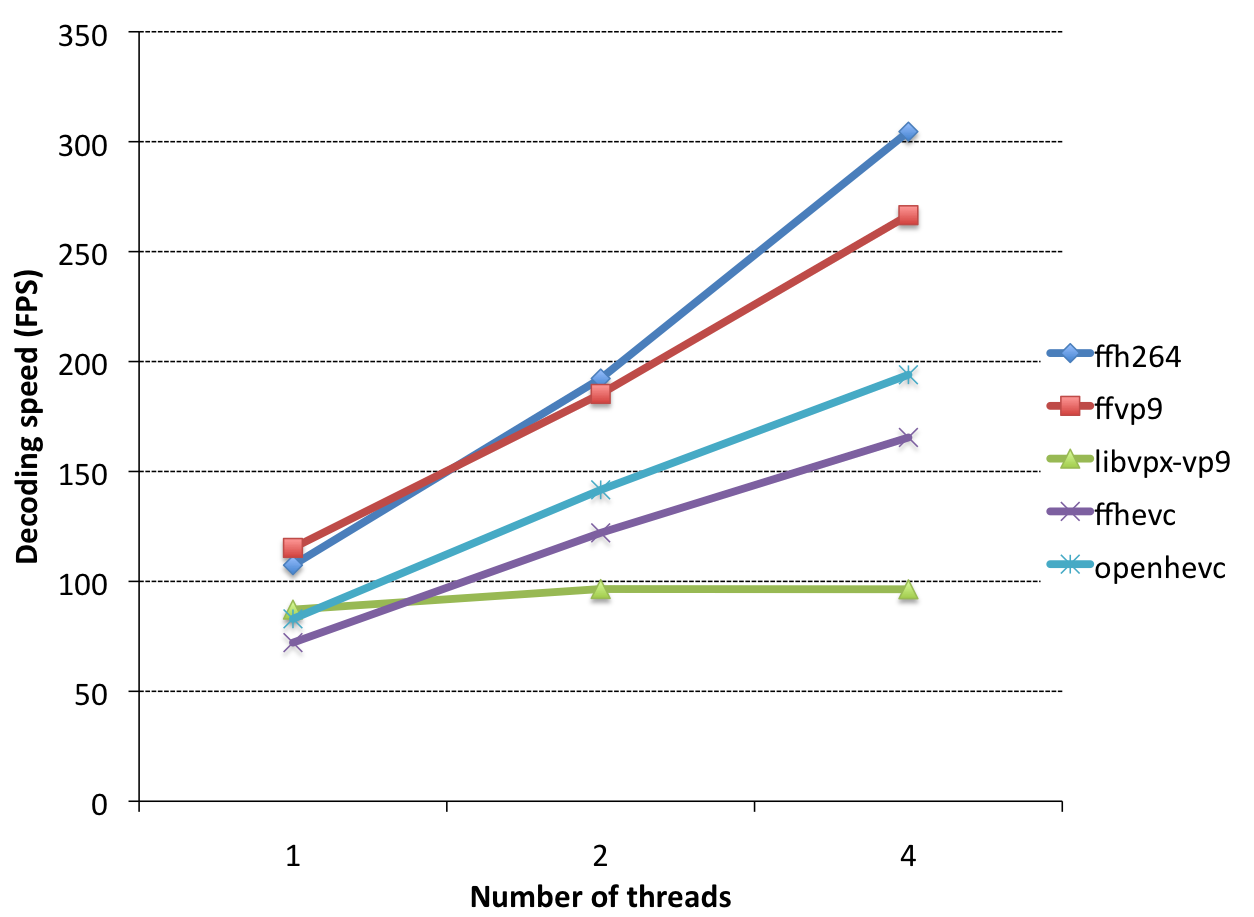
Similarly, let us start by comparing ffvp9 and ffh264: ffh264 is much more extensible. This is expected, the backward adaptive feature in VP9 affects the multi-threaded scaling to a certain extent, while ffh264 does not have such a feature. Next, ffvp9 and ffhevc/openhevc: their zoom ratios are roughly the same. Finally: libvpx-vp9. what happened? Well, when backward adaptation is enabled in the VP9 bitstream and tiling is disabled, libvpx does not use multithreading at all, so I call it the TODO item in libvpx. As ffvp9 proved, there is no reason for this to happen.
in conclusion
Compared to x264, the next-generation codec provides a 50% bit rate improvement, but at the highest settings required to achieve such results, its speed is 10-20 times slower.
Standardizing CPU usage, libvpx has some selling points compared to x264; except for very high-end scenes, x265 is still too slow to be used in most actual scenes.
ffvp9 is a great decoder, its performance is better than all other decoders.
Finally, I VDD15 lecture. This is a fair question, so I want to solve this problem here: Why don't I talk about encoder multithreading? There must be a lot of discussion there (slicing, tiling, frame multithreading, WPP). The answer is that the main goal of my encoder part is VOD (e.g. Youtube), they don't really care about multi-threading because it does not affect the total workload. If you encode four files in parallel on a 4-core machine and each file takes 1 minute, or you use 4 threads to serially encode each file, each of which takes 15 seconds, then either way, you The entire machine will be used for 1 minute. For customers of VOD streaming services, this is different, because you and I usually watch one Youtube video at a time.


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。