
1 Problem background
Accurate and direct knowledge question and answer ability is very important to build Xiaobu's image of "understanding knowledge and knowing you better". In the voice assistant scene, there are often problems such as polysemous or colloquial expression of a word. For example: Li Bai’s outfit, Li Bai’s poems, Li Bai played. The first Li Bai refers to the game character, the second refers to the poet Li Bai, and the third refers to the song Li Bai. How to accurately identify what the user refers to and give the correct answer is the challenge faced by Xiaobu Assistant.

Knowledge graph is the cornerstone for machines to understand the objective world, and has strong expressive ability and modeling flexibility. At present, OPPO's self-built knowledge graph OGraph has accumulated hundreds of millions of entities and billions of relationships. Next, let's take a look at how Xiaobu and Ograph will collide, solve entity ambiguity problems through entity link technology, and help Xiaobu be an intelligent assistant that can listen, speak, and understand you better.

2 Task introduction
Entity linking is a basic task in the field of NLP and knowledge graphs, that is, for a given Chinese text, the task of associating the entity description (mention) with the corresponding entity in the given knowledge base.
In 2009, the entity link task was first proposed at the TAC meeting. Before deep learning became popular in 2014, entity linking was done through statistical features and graph-based methods. In 2017, the Deep Joint solution was proposed, which uses the Attention structure for semantic matching to disambiguate entities. Later, the team used model structure innovation to achieve simultaneous entity recognition and disambiguation in the same model, and attention was still used for disambiguation. In 2018, the Deep Type solution was proposed to convert the disambiguation problem into entity classification. After obtaining the entity category, use the Link Count to determine the entity to be linked. Pre-training language models become popular in 2020. The Entity Knowledge solution uses a large amount of corpus and a powerful pre-training model to link entities with sequence annotations.

3 Technical solution
Entity linking is usually divided into three subtasks: entity recognition, candidate entity recall, and entity disambiguation.

3.1 Entity recognition
The role of entity recognition is to identify the entity description (namely mention) in the query. For example, Li Bai in Who is the emperor of the dynasty where Li Bai belongs is the mention to be identified. When performing entity recognition in general domains, entities are of large magnitude, multiple types, and diverse statements. Therefore, the solution must take into account both efficiency and generalization.
Xiaobu Assistant has developed a dictionary-based entity recognition using the self-developed matching tool Word Parser, which has advantages over open source tools in terms of performance and functions.

The entity link does not care about the entity type, so the entity recognition can use the B/I label or pointer annotation mode. At the same time, in order to improve the richness of the input information, the vocabulary information is introduced as a feature supplement, and the structures such as Lattice LSTM and FLAT are tested. The recognition effect is improved by about 1%.

3.2 Candidate entity recall
The goal of candidate entity recall is to use mention to recall all possible candidate entities, but there are a large number of nicknames, homophones, and colloquial expressions online, such as nickname aliases such as Juanfu and Dousen, and there will be expression errors, such as plump Ultraman, Ultraman Tractor, Qianya Ji, if there is no mapping from the alias to the correct entity, the recall cannot be completed. In the voice scenario, there is no direct user feedback, and it cannot be tapped by the user like a search. Therefore, the mining of entity aliases is quite challenging.

According to the characteristics of the problem, we have constructed two sets of schemes. Generic alias mining uses information extraction as the main mode to generate the auxiliary mining process, and makes full use of the description information, alias information and relationship information in OGraph to mine aliases.

Aiming at user input errors, homophone characters, near-phonetic characters and other alias mining, Xiaobu Assistant pioneered the creation of an alias discovery process based on feature clustering. The mining steps are as follows:
1) Query filtering: using domain keyword filtering and search click log filtering, the queries that may contain aliases to be mined are filtered from user search queries and Xiaobu Assistant online queries.

2) Entity recognition: Use entity recognition technology to identify entities from the query to be mined. The entity recognition model is obtained by using a general entity recognition model + vertical finetune.
3) Domain feature construction: Because the entity alias directly obtained by entity recognition is not accurate, and it is not associated with the entity standard name, it is necessary to construct the domain feature and associate the mined entity alias with the entity standard name. According to the characteristics of the scene, we selected the radical features and pinyin features.
4) Feature clustering: Use clustering to associate the mined entity alias with the entity standard name. By using this mining solution, hundreds of thousands of entity aliases were obtained, with an accuracy rate of 95%+, which solved the problem of online high-frequency aliases.

3.3 Entity Disambiguation
Entity disambiguation is the most critical step in entity linking. The essence of disambiguation is sorting. By sorting candidate entities, the ranking score of each candidate entity is obtained, and the final result is selected. The main problems of entity disambiguation are as follows:
1) In the voice assistant scene, it is mostly short text, so the context feature is missing, and additional construction features are needed to help disambiguation.
2) When disambiguating, we should not only use semantic features to disambiguate, but also fully consider the global disambiguation features. For example, Andy Lau in "Andy Lau gives lectures to students and compares bombs to girls' hands", from the semantics of Tsinghua University professor Andy Lau More in line, it is actually the title of the actor Andy Lau and the article title of "The Hurt Locker".

3) There are unaligned entities in the graph, which makes it difficult to disambiguate the model, and it is prone to corpus tagging errors. For example, China and the People's Republic of China are two entities in some open source maps, resulting in some correct labels for the entity of China in the training set, and some correct labels for the entity of the People’s Republic of China.
In response to the problems mentioned above, we started from the aspects of data preparation, model selection, model optimization, etc., and solved these problems through targeted optimization.
3.3.1 Data preparation
When constructing the disambiguation sample, we provide as much information as possible to the model. The sample consists of three parts: query sample, entity sample and statistical features.
Query sample structure: When the query sample is input, the position information of the mention is passed into the model so that the model can determine the specific position of the mention in the query. Therefore, the identifier # will be introduced, and the unified identifier "#" is added to both sides of the mention. The sample is as follows:

Entity description sample structure: The entity sample needs to contain the characteristics of the entity to be disambiguated. In the first edition of the entity sample, we designed the splicing of mention and standard name to indicate whether the standard name and mention are the same. Constructed "Type: entity type" "This description provides entity type information; at the same time, the entity description and the triplet information of the graph are added. In the second edition, we directly converted the feature of whether the standard name and mention are the same into the text description "same name/different", and added the feature of "non/is doctrine". By optimizing the feature expression method, the performance of the model is improved. About 2%.

Statistical feature sample construction: In order to avoid the disambiguation model only focusing on semantic features, we counted query and entity sample co-occurrence features, popularity, richness, mention co-occurrence features and other statistical features, as model input to assist in global disambiguation.

3.3.2 Model selection
In sorting learning, there are three common modes pointwise, pairwise and listwise. For the sorting task that only requires TOP1 for entity disambiguation, it does not need to consider the sequence relationship between candidate entities, but only considers the global correlation, so we choose pointwise method.

Summarizing the disambiguation models of the predecessors, Deep Joint starts from sorting, and Deep Type starts from classification. Both have achieved good results, indicating that both classification and sorting tasks are helpful for disambiguation. Therefore, we designed multi-tasks according to the characteristics of the tasks. Model framework, sorting and classification are performed at the same time, the two tasks share model parameters, train together, and the loss function is optimized together. By sharing the information of the sorting task and the classification task, the model can have better performance. The multi-task loss function is as follows.
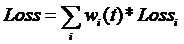
In order to better integrate the statistical features, we directly splice the statistical feature embedding to the feature vector for sorting.

The final structure of our model is as follows: we will splice the query sample and the entity sample into the pre-training language model, and splice the vector of the CLS position and the statistical feature embedding as the feature vector. The sorting task inputs the feature vector to the fully connected layer, and then finally outputs the score in the [-1,1] interval after tanh. The higher the score, the more likely it is to be the target entity. The classification task inputs the feature vector to the full link layer, and outputs the score of each classification through the softmax layer.
Through experiments, the effect of the multi-task-based entity link model is better than the single-task model. The specific F1 is shown in the table below.

3.3.3 Model optimization
In order to understand which input features the model pays attention to, the visualization method of mutual information is used to visualize the model, and the importance of each word is visualized. The deeper the color, the higher the importance. Through visualization, it is found that the model tends to focus on the type of entity and the fragments used to distinguish the entity, such as example 1 slow eating, food, eating method, ham sausage, example 2 Sandy, SpongeBob Squarepants, switching power supply brands. In the example of 3 kinds of characters, races, dreams, etc., we can see that the features that the multi-task model pays attention to are all helpful for disambiguation.


Confident Learning (CL) is an algorithm framework for identifying label errors and characterizing label noise. Aiming at the problem of labeling errors, according to the idea of belief learning, five models were trained on the original data using n-flod, and these models were used to predict the labels of the original training set, and then the labels output by the five models were merged as the real labels. In the original training set, samples with inconsistent real labels and original labels were cleaned up. We cleaned up 3% of samples, of which 80%+ had wrong labels.

Adversarial training refers to the method of constructing adversarial samples during model training and participating in model training. In the normal training process, if the gradient direction is steep, then a small disturbance will have a great impact. In order to prevent such disturbances, adversarial training uses perturbed adversarial samples to attack during model training, thereby improving the robustness of the model. It can be seen that the effects of the two methods of generating adversarial samples, FGM and PGD, have been improved significantly.

4 Technical application
4.1 Application in Xiaobu Assistant

In the Xiaobu assistant scene, users have great expectations for the intelligence of the voice assistant, and will ask various interesting questions, such as multi-hop questions, six-degree relationship queries, and so on. With the help of entity linking technology, Xiaobu Assistant can accurately identify what the user is referring to. With subgraph matching technology, it can process entity Q&A, structured Q&A, multi-hop Q&A, six-degree relationship query, etc., covering most structured questions.

In order to verify the physical linking capabilities of Xiaobu Assistant, we have tested our algorithm on both the self-built evaluation set and the Qianyan evaluation set, and good results can be achieved.
4.2 Application in OGraph
Entity links can not only be applied to KBQA, but are also a vital part of the information extraction process. The Ograph information extraction process uses the information extraction model Casrel and the MRC model specially trained for entity problems, and a large number of candidate triples can be obtained.
After getting the triples, we need to use entity linking technology to link the triples with the entities in the knowledge base. In order to ensure the recall of entity links, we optimized the recall ability of candidate entities, and used the mined entity alias vocabulary and ES retrieval system for recall to ensure the effect of the link, and produced millions of triples through the entire process.

5 Summary
Through the exploration of entity link technology, Xiaobu Assistant can better analyze various entity colloquial expressions, aliases and ambiguities. With the help of other KBQA processes and OGraph's rich knowledge reserves, it has been able to answer most of the questions raised by users, naturally Language comprehension is difficult and long, and the evolution of Xiaobu's assistant will never stop.
6 References
1.Deep Joint Entity Disambiguation with Local Neural Attention. Octavian-Eugen Ganea, Thomas Hofmann.
2.Improving Entity Linking by Modeling Latent Entity Type Information,Shuang Chen, Jinpeng Wang, Feng Jiang, Chin-Yew Lin.
3.End-to-End Neural Entity Linking. Nikolaos Kolitsas, Octavian-Eugen Ganea, Thomas Hofmann.
4.Investigating Entity Knowledge in BERT with Simple Neural End-To-End Entity Linking, Samuel Broscheit.
5.Towards Deep Learning Models Resistant to Adversarial Attacks. A Madry, A Makelov, L Schmidt, D Tsipras.
6.Confident Learning: Estimating Uncertainty in Dataset Labels. Curtis G. Northcutt, Lu Jiang, Isaac L. Chuang.
7.Towards a Deep and Unified Understanding of Deep Neural Models in NLP. Chaoyu Guan, Xiting Wang, Quanshi Zhang, Runjin Chen, Di He, Xing Xie.
Author profile
FrankFan OPPO Senior NLP Algorithm Engineer
Mainly engaged in dialogue and knowledge graph related work, with rich R&D experience in entity mining, sequence labeling, relationship extraction, entity linking, etc., and accumulated more than ten patents.
Get more exciting content, scan the code to follow the [OPPO Digital Intelligence Technology] public account





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。