

SET Redis distributed locks be implemented using the 061c537cd027fd instruction? CAP theory has always existed in the distributed field.
The doorway of distributed locks is not that simple. The distributed lock schemes we have seen on the Internet may be problematic.
"Brother Code" takes you step by step how to improve distributed locks step by step, and how to use distributed locks correctly in a high-concurrency production environment.
Before entering the text, let's think about it with questions:
- When do you need distributed locks?
- Are there any particulars about the location of the code for adding and unlocking?
- How to avoid the lock can no longer be deleted? ""
- What is the appropriate timeout period?
- How to avoid the lock being released by other threads
- How to implement reentrant locks?
- What security issues will the master-slave architecture bring?
- What is
Redlock - Redisson Distributed Lock Best Practice
- Watchdog implementation principle
- ……
When to use distributed locks?
Brother Code, give a popular example to explain when is a distributed lock needed?
There is only one doctor in the clinic, and many patients come for treatment.
A doctor can only provide medical services to one patient at a time. If this weren't the case, it would happen that when the doctor was going to prescribe medicine for "Xiao Caiji" who had kidney deficiency, the patient switched to "Xie Ba brother" with bad feet. At this time, the medicine was taken away by Xie Ba brother.
The medicine for kidney deficiencies was taken away by the smelly feet.
When concurrently reading and writing a [shared resource], in order to ensure the correctness of the data, we need to control that only one thread accesses it at the same time.
distributed lock is used to control the same time, only one thread in one JVM process can access the protected resource.
Getting started with distributed locks
65 Brother: What characteristics should distributed locks satisfy?
- Mutually exclusive: at any given moment, only one client can hold the lock;
- No deadlock: it is possible to acquire a lock at any time, even if the client that acquired the lock crashes;
- Fault tolerance: As long as most
Redishave been started, the client can acquire and release the lock.
Brother Code, I can use the SETNX key value command to achieve the "mutual exclusion" feature.This command comes from SET if Not eXists , which means: if key does not exist, set value to key , otherwise do nothing. The official Redis address says:
The return value of the command:
- 1: The setting is successful;
- 0: The key is not set successfully.
The following scenario:
Tired of typing code for a day, I want to relax and massage my neck and shoulders.
Technician No. 168 is the most sought-after. Everyone likes it. Therefore, the amount of concurrency is large, and distributed lock control is required.
Only one "client" is allowed to make an appointment for 168 technicians at the same time.
Xiao Caiji successfully applied for 168 technicians:
> SETNX lock:168 1
(integer) 1 # 获取 168 技师成功Brother Xie Ba arrived later, the application failed:
> SETNX lock 2
(integer) 0 # 客户谢霸哥 2 获取失败At this moment, customers who have successfully applied can enjoy the "shared resources" service of shoulder and neck relaxation provided by 168 technicians.
After the enjoyment is over, the lock must be released in time to give latecomers the opportunity to enjoy the service of 168 technicians.
Xiao Caiji, how do you release the lock?
Very simple, just use DEL delete this key .
> DEL lock:168
(integer) 1Brother Ma, have you seen "Dragon"? I have seen it because I have been served by one-stop service.
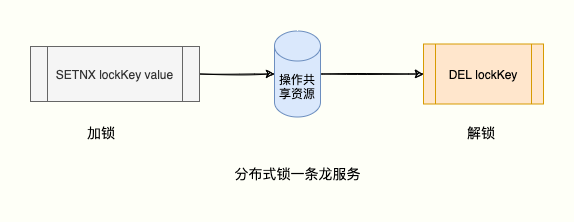
Xiao Caiji, things are not that simple.
This solution has a problem that prevents the lock from being released. The scenarios that cause this problem are as follows:
- The node where the client is located crashes and the lock cannot be released correctly;
- The business logic is abnormal and the
DELcommand cannot be executed.
In this way, the lock will always be occupied, locked in my hand, and I hung it up, so that other clients can no longer get the lock.
Timeout setting
Brother Code, I can set a "timeout period" when the lock is successfully acquired
For example, if you set a massage service for 60 minutes at a time, you can set the 60-minute expiration when you lock the key
> SETNX lock:168 1 // 获取锁
(integer) 1
> EXPIRE lock:168 60 // 60s 自动删除
(integer) 1In this way, the lock is automatically released after the point is reached, and other customers can continue to enjoy the 168 technician massage service.
Whoever writes like that is terrible.
"Lock" and "Set timeout" are two commands, they are not atomic operations.
If only the first item is executed, and the second item has no chance to execute, the "timeout period" setting will fail, and the lock cannot be released still.
Brother Ma, what should I do, I want to be served by one-stop service, to solve this problem
After Redis 2.6.X, the official expansion of SET command satisfies the semantics of setting the value when the key does not exist, and at the same time setting the timeout time, and satisfies the atomicity.
SET resource_name random_value NX PX 30000- NX: means that
resource_nameSETsucceed when 061c537cd02d99 does not exist, thus ensuring that only one client can obtain the lock; - PX 30000: Indicates that this lock has an automatic expiration time of 30 seconds.
This is not enough. We also need to prevent the locks that were not added by ourselves can be released. We can make a fuss on value.
Continue to look down...
Released the lock that was not added by yourself
So can I safely enjoy the one-stop service?
No, there is another scenario that will cause release someone else’s lock :
- Client 1 successfully acquired the lock and set a 30-second timeout;
- Client 1 has slow execution due to some reasons (network problems, FullGC occurrence...), and the execution is still not completed after 30 seconds, but the lock expired "automatically released";
- Customer 2 successfully applies for locking;
- The execution of client 1 is completed, execute
DELrelease the lock instruction, at this time the lock of client 2 is released.
There is a key issue that needs to be solved: your own locks can only be released by yourself.
How do I delete the lock I added?
When executing the DEL instruction, we have to find a way to check whether the lock was added by ourselves and then execute the delete instruction.
must be the person to
Brother Code, I set a "unique identifier" when I locked it as
valuerepresent the locked client.SET resource_name random_value NX PX 30000When releasing the lock, the client compares its own "unique identifier" with the "identity" on the lock to see if it is equal, and deletes if it matches, otherwise it has no right to release the lock.
The pseudo code is as follows:
// 比对 value 与 唯一标识
if (redis.get("lock:168").equals(random_value)){
redis.del("lock:168"); //比对成功则删除
}Have you ever thought that this is a GET + DEL instruction, and the issue of atomicity will be involved here.We can implement it through the Lua script, so that the judgment and deletion process is an atomic operation.
// 获取锁的 value 与 ARGV[1] 是否匹配,匹配则执行 del
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endIn this way, it is very important to identify the locked client by a unique value set to value. It is not safe to use DEL only, because one client may delete the lock of another client.
Using the above script, each lock is "signed" with a random string. Only when the "signature" of the client that deletes the lock matches the value of the lock will it be deleted.
The official document also says so: https://redis.io/topics/distlock
This scheme is relatively perfect, and it is probably this scheme that we use the most.
Set the lock timeout correctly
How to calculate the appropriate lock timeout period?
This time cannot be written indiscriminately. Generally, it is based on multiple tests in the test environment, and then after multiple rounds of pressure testing, for example, the average execution time is calculated to be 200 ms.
Then the time of 161c537cd0301b is enlarged to 3~5 times of the average execution time.
Why zoom in?
Because if there are network IO operations, JVM FullGC, etc. in the operation logic of the lock, the online network will not always be smooth sailing, and we need to leave a buffer time for network jitter.
Then I set it up a bit larger, for example, is it safer to set it for 1 hour?
Don't get into the horns, how big is big?
If the setting time is too long, once a downtime occurs and restart, it means that all nodes of the distributed lock service are unavailable within 1 hour.
Do you want O&M to manually delete this lock?
As long as the operation and maintenance really won't hit you.
Is there a perfect solution? No matter how the time is set, it is not appropriate.
We can let the thread that acquires the lock start a daemon thread , which is used to "life" the lock that is about to expire.
When locking, set an expiration time, and at the same time, the client opens a "daemon thread" to detect the expiration time of the lock regularly.
is about to expire, but the business logic has not been executed yet, the lock is automatically renewed and the expiration time is reset.
This principle works, but I can't write it.
Don't panic, there is already a library that encapsulates these tasks. It is called Redisson .
When using distributed locks, it uses an "automatic renewal" scheme to avoid lock expiration. This daemon thread is generally called a "watchdog" thread.
After optimization all the way, the plan seems to be more "rigorous", and the corresponding model is abstracted as follows.
- Pass
SET lock_resource_name random_value NX PX expire_time, and start the daemon thread at the same time to renew the lock of the client that is about to expire but has not been executed; - The client executes business logic operations to share resources;
- Release the lock through the
Luascript, first get to determine whether the lock was added by yourself, and then executeDEL.

This scheme is actually quite perfect, and it has already defeated 90% of programmers at this point.
But for programmers who pursue the ultimate, it is far from enough:
- How to achieve reentrant locks?
- How to solve the lock loss caused by the master-slave architecture crash recovery?
- Is there a doorway in the locked position of the client?
Pay attention to the location of the unlock code
According to the previous analysis, we already have a "relatively rigorous" distributed lock.
So "Xie Ba Ge" wrote the following code to apply distributed locks to the project. The following is the pseudo-code logic:
public void doSomething() {
redisLock.lock(); // 上锁
try {
// 处理业务
.....
redisLock.unlock(); // 释放锁
} catch (Exception e) {
e.printStackTrace();
}
}Have you ever thought: Once an exception is thrown during the execution of business logic, the program cannot execute the process of releasing the lock.
So the code to release the lock must be placed in the finally{} block.
There is also a problem with the location of the lock. If it is placed outside the try, if the redisLock.lock() , but the actual command has been sent to the server and executed, but the client reads the response timeout, which will result in no chance to execute the unlock code.
So redisLock.lock() should be written in the try code block to ensure that the unlocking logic will be executed.
In summary, the correct code location is as follows:
public void doSomething() {
try {
// 上锁
redisLock.lock();
// 处理业务
...
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
redisLock.unlock();
}
}Implement reentrant locks
65 Brother: How to realize the reentrant lock?
When a thread executes a piece of code and successfully acquires the lock and continues to execute it, it encounters the locked code again. Reentrancy ensures that the thread can continue to execute. Non-reentrant means that it needs to wait for the lock to be released and acquire the lock again successfully. In order to continue execution.
Explain reentrant with a piece of code:
public synchronized void a() {
b();
}
public synchronized void b() {
// pass
}Suppose that the X thread continues to execute the b method after acquiring the lock in method a. If not reentrant to at this time, the thread must wait for the lock to be released and compete for the lock again.
The lock is obviously owned by the X thread, but it still needs to wait for the lock to be released by itself, and then grab the lock. This seems very strange, I release myself~
Redis Hash reentrant lock
The Redisson class library implements reentrant locks through Redis Hash
After the thread has the lock, it encounters the lock method later, directly increases the number of locks by 1, and then executes the method logic.
After exiting the locking method, the number of locking times is reduced by 1. When the number of locking times is 0, the lock is really released.
You can see that the biggest feature of reentrant locks is counting, which counts the number of locks.
So when reentrant locks need to be implemented in a distributed environment, we also need to count the number of locks.
Locking logic
We can use the Redis hash structure to achieve, the key represents the shared resource that is locked, and the value of the fieldKey of the hash structure stores the number of locks.
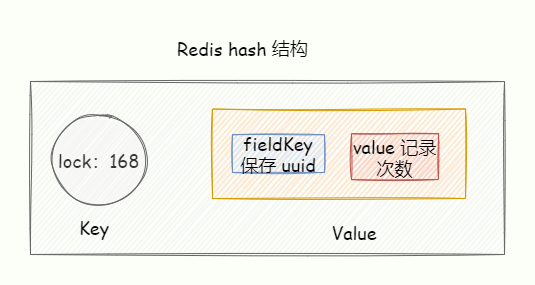
Achieve atomicity through Lua script, assuming KEYS1 = "lock", ARGV "1000, uuid":
---- 1 代表 true
---- 0 代表 false
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end ;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end ;
return 0;The lock code first uses the Redis exists command to determine whether the current lock exists.
If the lock does not exist, directly use hincrby create a hash table with a key of lock , and initialize the hash table with a key of uuid to 0, then add 1 again, and finally set the expiration time.
If the current lock exists, use hexists determine uuid exists in the hash table corresponding to the lock . If it exists, use hincrby again to add 1, and finally set the expiration time again.
Finally, if the above two logics do not match, return directly.
Unlock logic
-- 判断 hash set 可重入 key 的值是否等于 0
-- 如果为 0 代表 该可重入 key 不存在
if (redis.call('hexists', KEYS[1], ARGV[1]) == 0) then
return nil;
end ;
-- 计算当前可重入次数
local counter = redis.call('hincrby', KEYS[1], ARGV[2], -1);
-- 小于等于 0 代表可以解锁
if (counter > 0) then
return 0;
else
redis.call('del', KEYS[1]);
return 1;
end ;
return nil;First use hexists determine whether the Redis Hash table stores the given domain.
If the Hash table corresponding to the lock does not exist, or the key uuid does not exist in the Hash table, directly return nil .
If it exists, it means that the current lock is held by it. First use hincrby to reduce the number of reentrants by 1, and then determine the number of reentrants after calculation. If it is less than or equal to 0, use del delete the lock.
The unlock code execution method is similar to the lock, except that the return type of the unlock execution result is Long . Boolean is not used like locking is because in the unlocking lua script, the meaning of the three return values is as follows:
- 1 means the unlock is successful and the lock is released
- 0 means the number of reentrants is reduced by 1
nullrepresents that other threads tried to unlock, but the unlock failed.
Problems caused by the master-slave architecture
Brother Ma, the distributed lock is "perfect" here. I didn't expect that there are so many ways for distributed locks.
There is still a long way to go. The previously analyzed scenarios are all problems that may occur when locked in a "single" Redis instance, and they do not involve the problems caused by the Redis master-slave mode.
We usually use " Cluster" or " Sentry cluster " deployment mode to ensure high availability.
These two modes are based on the master-slave data synchronization replication ", and Redis's master-slave replication is asynchronous by default.
The following content comes from the official document https://redis.io/topics/distlock
Let's imagine what will happen in the following scenario:
- Client A successfully obtains the lock on the master node.
- When the lock acquisition information is not synchronized to the slave, the master goes down.
- The slave is elected as the new master. At this time, there is no data for client A to acquire the lock.
- Client B can successfully obtain the lock held by client A, which violates the mutual exclusion defined by distributed locks.
Although this probability is extremely low, we must acknowledge the existence of this risk.
The author of Redis proposed a solution called Redlock (Red Lock)
In order to unify the standard of distributed locks, the author of Redis created a Redlock, which is regarded as Redis's official guidelines for implementing distributed locks, https://redis.io/topics/distlock, but this Redlock is also used by some foreign companies. Distributed experts sprayed.
Because it is not perfect, there are "holes".
What is Redlock
Is this the red lock?

If you eat too much instant noodles, the Redlock red lock is an algorithm proposed to solve the problem of multiple clients holding the same lock due to a master-slave switch in the master-slave architecture.
You can see the official document ( https://redis.io/topics/distlock), the following translation is from the official document.
If you want to use Redlock, the official recommendation is to deploy 5 Redis master nodes on different machines. The nodes are completely independent and do not use master-slave replication. Using multiple nodes is for fault tolerance.
There are 5 steps for a client to obtain the lock :
- The client obtains the current time
T1(millisecond level); Use the same
keyandvalueto try to acquire locksNRedis- Each request is set with a timeout period (millisecond level), the timeout period is much less than the effective time of the lock, so that it is convenient to quickly try to send the request with the next instance.
- For example, the automatic release time of the lock is
10s, and the requested timeout time can be set to5~50within 4 milliseconds, which can prevent the client from blocking for a long time.
- The client obtains the current time
T2and subtracts theT1in step 1 to calculate the time taken to acquire the lock (T3 = T2 -T1). If and only if the clientN/2 + 1), and the total time T3 used to obtain the lock is less than the effective time of the lock, the lock is considered successful, otherwise the lock fails. - If the lock in step 3 is successful, then execute the business logic operation to share the resource. key is equal to the effective time minus the time used to acquire the lock (the result of the calculation in step 3).
- If for some reason, the lock acquisition fails (the lock has not been acquired in at least N/2+1 Redis instances or the lock acquisition time has exceeded the valid time), the on all Redis instances (even if Some Redis instances are not successfully locked at all).
In addition, the number of deployed instances is an odd number. In order to meet the principle of more than half, if it is 6 units, 4 units need to acquire the lock to be considered successful, so an odd number is more reasonable.
Things may not be so simple, Redis authors propose that after the program, by the industry's leading distributed systems experts questioned .
The two are like gods fighting. They come back and forth with sufficient arguments to put forward a lot of judgments on a problem...
- Martin Kleppmann questioned the blog: https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
- Redlock designer's reply: http://antirez.com/news/101
Redlock right and wrong
Martin Kleppmann believes that the purpose of locking is to protect the read and write of shared resources, and distributed locks should be "efficient" and "correct".
- Efficient: Distributed locks should meet high-efficiency performance. The logic performance of Redlock algorithm to acquire locks on 5 nodes is not high, the cost increases, and the complexity is also high;
- Correctness: Distributed locks should prevent concurrent processes from being able to read and write shared data by only one thread at the same time.
For these two points, we don't need to bear the cost and complexity of Redlock. Run 5 Redis instances and judge whether the lock satisfies the majority to be considered successful.
It is extremely unlikely that the master-slave architecture crashes and recovers, which is not a big deal. The stand-alone version is enough, Redlock is too heavy and unnecessary.
Martin believes that Redlock does not meet the security requirements at all, and there is still the problem of lock failure!
Martin's conclusion
- Redlock nondescript: For preference efficiency, Redlock is heavier, so there is no need to do this, and for preference correctness, Redlock is not safe enough.
- Unreasonable clock assumptions: The algorithm makes dangerous assumptions about the system clock (assuming that the clocks of multiple nodes are the same). If these assumptions are not met, the lock will fail.
- The correctness cannot be guaranteed: Redlock cannot provide fencing token , so the correctness problem cannot be solved. For correctness, please use software with a "consensus system", such as Zookeeper .
Redis author Antirez's rebuttal
In the Redis author's rebuttal article, there are 3 key points:
- Clock problem: Redlock does not need a completely consistent clock, just roughly the same. "Error" is allowed, as long as the error does not exceed the lock lease period. This kind of clock accuracy is not very demanding. , And this is also in line with the real environment.
Network delay and process suspension issues:
- Before the client gets the lock, no matter what time-consuming problem it experiences, Redlock can be detected in step 3.
- After the client gets the lock, NPC , and Redlock and Zookeeper are helpless.
- Question the fencing token mechanism.
We will see you in the next issue of the Redlock debate, and now we will enter the actual part of Redisson's implementation of distributed locks.
Redisson distributed lock
Based on the SpringBoot starter method, add a starter.
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.4</version>
</dependency>
But here you need to pay attention to the versions of springboot and redisson, because the official recommendation is that the redisson version and springboot version are used together.
Integrating Redisson with the Spring Boot library also depends on the Spring Data Redis module.
"Brother Code" uses SpringBoot 2.5.x version, so redisson-spring-data-25 needs to be added.
<dependency>
<groupId>org.redisson</groupId>
<!-- for Spring Data Redis v.2.5.x -->
<artifactId>redisson-spring-data-25</artifactId>
<version>3.16.4</version>
</dependency>Add configuration file
spring:
redis:
database:
host:
port:
password:
ssl:
timeout:
# 根据实际情况配置 cluster 或者哨兵
cluster:
nodes:
sentinel:
master:
nodes:In this way, we have the following Beans that can be used in the Spring container:
RedissonClientRedissonRxClientRedissonReactiveClientRedisTemplateReactiveRedisTemplate
Redis-based Redisson distributed reentrant lock RLock Java object implements the java.util.concurrent.locks.Lock interface.
Unlimited retry on failure
RLock lock = redisson.getLock("码哥字节");
try {
// 1.最常用的第一种写法
lock.lock();
// 执行业务逻辑
.....
} finally {
lock.unlock();
}
It will keep retrying when it fails to take the lock. It has an automatic watchdog extension mechanism. By default, it will continue for 30s, and it will continue for 30s every 30/3=10 seconds.
Retry after failure timeout, automatic renewal
// 尝试拿锁10s后停止重试,获取失败返回false,具有Watch Dog 自动延期机制, 默认续30s
boolean flag = lock.tryLock(10, TimeUnit.SECONDS); Automatically release the lock after timeout
// 没有Watch Dog ,10s后自动释放,不需要调用 unlock 释放锁。
lock.lock(10, TimeUnit.SECONDS);Retry after timeout, automatic unlock
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁,没有 Watch dog
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}Watch Dog automatic delay
If the node acquiring the distributed lock goes down and the lock is still in the locked state, a deadlock will occur.
In order to avoid this situation, we will set a timeout automatic release time for the lock.
However, there will still be a problem.
Suppose the thread acquires the lock successfully and sets a 30 s timeout, but the task has not been executed within 30 s, and the lock timeout is released, which will cause other threads to acquire locks that should not be acquired.
Therefore, Redisson provides a watchdog automatic delay mechanism, which provides a watchdog that monitors the lock. Its function is to continuously extend the validity period of the lock before the Redisson instance is closed.
In other words, if a thread that has obtained the lock has not completed the logic, the watchdog will help the thread to continuously extend the lock timeout time, and the lock will not be released due to the timeout.
By default, the watchdog renewal time is 30s, and it can also be specified separately by modifying Config.lockWatchdogTimeout.
In addition, Redisson also provides a locking method that can specify the leaseTime parameter to specify the lock time.
After this time, the lock is automatically unlocked, and the validity period of the lock will not be extended.
The principle is as follows:

has two points to note:
- watchDog will only take effect when the specified leaseTime is not displayed.
- lockWatchdogTimeout The set time should not be too small. For example, the setting is 100 milliseconds. After the lock is completed directly due to the network, when the watchdog goes to postponement, this key has been deleted in redis.
Source code guide
When the lock method is called, tryAcquireAsync is finally called. The call chain is: lock()->tryAcquire->tryAcquireAsync`, the detailed explanation is as follows:
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
//如果指定了加锁时间,会直接去加锁
if (leaseTime != -1) {
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
//没有指定加锁时间 会先进行加锁,并且默认时间就是 LockWatchdogTimeout的时间
//这个是异步操作 返回RFuture 类似netty中的future
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
//这里也是类似netty Future 的addListener,在future内容执行完成后执行
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
// leaseTime不为-1时,不会自动延期
if (leaseTime != -1) {
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
//这里是定时执行 当前锁自动延期的动作,leaseTime为-1时,才会自动延期
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}ScheduleExpirationRenewal will call renewExpiration to enable a timeout to execute the postponement action.
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
Timeout task = commandExecutor.getConnectionManager()
.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 省略部分代码
....
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
....
if (res) {
//如果 没有报错,就再次定时延期
// reschedule itself
renewExpiration();
} else {
cancelExpirationRenewal(null);
}
});
}
// 这里我们可以看到定时任务 是 lockWatchdogTimeout 的1/3时间去执行 renewExpirationAsync
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}scheduleExpirationRenewal will call renewExpirationAsync to execute the following lua script.
His main judgment is whether the lock exists in redis, and if it exists, pexpire will be extended.
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
- If the watch dog is still alive on the current node and the task is not completed, the lock will be renewed for 30 seconds every 10 seconds.
- When the program releases the lock operation, because the exception is not executed, the lock cannot be released, so the release lock operation must be placed in finally {};
- To make the watchLog mechanism effective, do not set the expiration time when locking.
- The delay time of watchlog can be specified by lockWatchdogTimeout. The default delay time, but do not set too small.
- The watchdog will delay every lockWatchdogTimeout/3.
- The delay is achieved through lua scripts.
Summarize
When you are finished, I suggest you close the screen and go through it again in your mind. What you are doing at each step, why you are doing it, and what problems you are solving.
We have combed through the various doorways in Redis distributed locks together from start to finish. In fact, many points are problems that will exist no matter what distributed locks are used. The most important thing is the process of thinking.
For the design of the system, everyone’s starting point is different. There is no perfect architecture, no universal architecture, but a good architecture that balances perfection and universality is a good architecture.


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。