
Query rewriting is to expand and rewrite the user's Query, and use a better expression to help users recall more results that meet their needs. Query rewriting is a very important extension and recall method for text Boolean retrieval systems. By optimizing the algorithm module, the search experience can be directly and significantly improved. This article mainly describes the iterative direction and implementation ideas of the query and rewrite project in the search scenario of Meituan, hoping to inspire or help students who are engaged in recall-related work in search, advertising, and recommendation.
1 Introduction
In the search scenario, due to the large number of inconsistencies between the user's search term Query and the retrieval text Document, under the text retrieval framework, the problem of missed recall caused by such text mismatches seriously affects the user experience. There are generally two solutions in the industry for this kind of problem: the user side expands the user's query words - that is, query rewriting, or the Document side expands the document keywords - that is, the Document tag. This article mainly introduces the former solution to solve the missing recall: Query Rewriting (Query Rewriting, or Query Expansion). The application method of query rewriting is to expand the original Query with rewritten words that are highly related to user needs. Multiple rewritten words are retrieved together with user search words, so as to use better expressions to help users find more merchants that meet their needs. , goods and services.
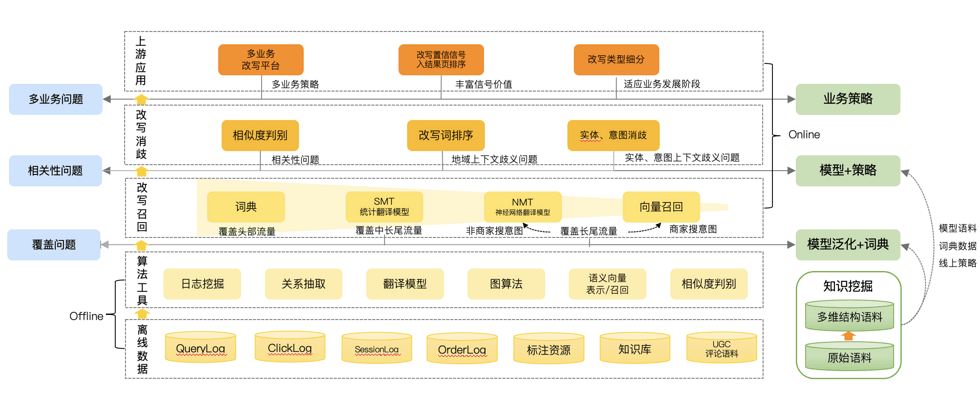
Under the technical framework of Meituan Search, query rewriting controls the text in the recall grammar, Named Entity Recognition (NER) [1] controls the retrieval domain in the recall grammar, intent recognition controls the relevance of recall and The distribution and product form of each business are the three core query and understanding signals. The query rewriting strategy takes effect on all the traffic of Meituan search. In addition to expanding user search terms, it is used as a basic semantic understanding signal in the entire Meituan search technology architecture, affecting users from index expansion, sorting features, front-end highlighting, etc. experience. It also has a direct and significant impact on the non-results rate, the number of recalled results, and the search click-through rate in the search recall results.

This article will introduce the iterative experience of query rewriting in the Meituan search scenario. The content is mainly divided into three parts. The first part will briefly introduce the challenges of the query rewriting task in the Meituan search scenario; the second part will introduce the practical experience of the overall technology stack construction on the query rewriting task The third part is the summary and outlook. At present, there is little public sharing of text recall strategies in the industry. I hope this article can inspire or help students who are engaged in recall-related work in search, advertising, and recommendation.
2. Background and Challenges
2.1 How to use the query rewrite signal in the Meituan search scenario
In the search scenario of Meituan, query rewriting is mainly used to solve the problem of missed recall caused by the following four types of semantic gaps:
- Semantic expansion: mainly synonyms, hyponyms, and common uppercase and lowercase numbers and traditional and simple conversions, such as "haircut", "haircut", "styling", "hair art", "hairdressing", "haircut", etc. .
- Gap in User Expression and Merchant Expression: Non-linguistic Synonyms. For example, the user expresses “learning guitar” in colloquial terms, and the merchant describes “guitar training” in writing; the user input does not exactly match the name of the merchant: “Hilton Hotel” (the merchant is more commonly described as “Hilton Hotel”).
- Scenario expansion: For example, in Meituan’s search scenario for “picking strawberries”, users’ corresponding needs based on their knowledge of the platform are “strawberry gardens”.
- Other missing recall problems: some problems such as many words and few words, error correction, etc., such as "house sweeping" corresponding to the needs of "housekeeping cleaning"; theoretically, query rewriting can solve all missing recall problems by adding rewritten words, such as "four pieces in winter" "Set" includes time-sensitive Internet celebrity concepts such as "rock candied haws, roasted sweet potatoes, fried chestnuts, and hot milk tea", which can also be solved by rewriting.

2.2 Difficulties and Challenges of Querying and Rewriting Signals in the Meituan Search Scenario
Search is to improve user reach efficiency and commercialization indicators as much as possible under the constraints of user search terms and supply, and Meituan's search scenario adds a third constraint of "region". The specific industry comparison is shown in the figure below:

By comparing the search scenarios in the industry, it can be found that in Meituan's search scenarios, user needs and service providers are mostly local-oriented, while the business in the field of life services is very fragmented. Compared with users' needs for a certain field of life services, localized supply is relatively less.
At the same time, Meituan search also aggregates the results of various forms of contract performance. In the search results, there will be clusters of natural results for businesses such as group buying, takeaway, grocery shopping, and selection, as well as recommended results when there are no local related businesses. Aggregate. With limited exposure positions, the irrelevant results of each natural result cluster will crowd out the benefits of other clusters, so ranking cannot be relied on to solve the correlation problem. This requires the query rewriting of the Meituan search scenario to be highly relevant and efficient in multiple business scenarios. The algorithm level needs to solve coverage problems, accuracy problems, and multi-business problems. Taking this requirement as a starting point, query rewriting also faces the following two challenges during specific algorithm iteration:
① 's query to users faces complex demand scenarios
- are many language ambiguities : Short Query increases the possibility of ambiguity. For example, in the Meituan scenario, "cut a hair" is a business name and cannot be rewritten as "haircut"; the same Query has different meanings in different cities, such as "Industrial University" "There are different schools in different cities.
- Cognitive Relevance : The user's search naturally has a cognition of the Meituan platform's "finding a store", and requires scene-related knowledge similar to "glasses" equivalent to "eyes store".
- are many scenarios : With the development of the business, the objective demand increases, and the scenarios for query and rewriting are more and more and more refined. At present, it has been connected to restaurants, shopping malls, hotel tourism, takeaways, commodities, advertisements, etc. Business scene.
② The supply of to the platform needs to take into account the characteristics of supply construction and development stage
- Most of Meituan merchants do not do keyword SEO (Search Engine Optimization): the problem of missed recall caused by text mismatch is more serious, and there is a great demand for rewriting.
- The exposed form of merchants makes the real interaction intention unclear: most merchants provide multiple dishes, commodities, and group order services at the same time. For example, a music training institution often provides training courses for multiple musical instruments.
- Strong correlation with business characteristics and development stage: Meituan is a platform that aggregates all aspects of life services, and each business has different needs for rewriting. For some heavy transaction businesses, weakly related rewriting is acceptable, while for some heavy experience In terms of business, the requirements for rewriting are stricter, and a certain degree of distinction is required.
3. Technical selection
Figure 4 below summarizes the current technical framework of query rewriting iterations and the corresponding problems to be solved. We have in-depth exploration in each sub-core module, such as offline candidate mining algorithm exploration, semantic relationship discrimination model, vectorized recall, and online generation of rewritten words. In addition to the iteration of the signal itself, the use of the signal has also achieved good online benefits by rewriting the graded signal, adding sorting, recalling correlation, etc.

Next, we will comprehensively introduce the iteration of each module technology under the query rewriting task from offline to online.
3.1 Raw corpus mining
High-quality data can significantly improve the rewriting effect of head flow and determine the ceiling of subsequent model performance. In terms of candidate set generation, mining based on search logs, based on translation ideas, based on graph computing, and based on Embedding are all commonly used methods in industry and academia; in terms of candidate set filtering and discrimination, there are sentence relationship classification and Embedding similarity calculation. and other methods. We summarize the advantages and disadvantages of each method in combination with the Meituan search scenario, and combine user behavior and semantic information in each mining algorithm component. The offline corpus mining will be introduced in detail below.
3.1.1 Search log to mine candidate corpus
Search log mining is a commonly used synonym acquisition method in the industry. The main directions of mining are:
- user searches and clicks on the common business: uses two queries that click on the same Document to build a correlation. This kind of correlation can mine a large number of word pairs, but the disadvantage of this simple assumption is also obvious, and the query of click co-occurrence may have different degrees of drift. In the Meituan scene, there are many stores providing comprehensive services, and there will be two types of group orders appearing in the same merchant in large numbers. It is more likely to find semantic drift noise such as "tooth extraction" → "tooth filling". In addition, this method relies on the effect of existing searches, and cannot mine the rephrased words of the query without results.
- from the search session: Session refers to an interactive process in which a user "opens the app → browses multiple pages, clicks and pays for multiple functions → leaves the app" within a period of time. This method uses the Query that the user continuously enters during the entire App access process to construct the relevant relationship. Session mining relies less on search results, so it has stronger generalization ability. However, the corresponding disadvantage is that the session time cut is not easy to determine, and the relationship between each search term in the sequence is relatively hidden, and there may even be no correlation. It is necessary to design the duration according to the characteristics of the business, and introduce clicks (for example, a session has no clicks on the search terms before the clicks, which may be due to specific requirements that have not been met) and other conditions for mining.
- word alignment: word alignment draws on the idea of translation. The specific method is to use the remaining part of the merchant title recalled by Query after removing the merchant name part as parallel corpus, and design some alignment strategies such as word alignment (including the same words), Pinyin alignment (same pinyin), structure alignment (word position after word segmentation is the same). The disadvantage of this method is that it strongly relies on the effect of existing searches.

- Merchant/in-product SEO: product scenario, some merchants will do SEO when they put on the shelves, such as: "Extended dog leash, dog collar, dog collar, dog teddy golden retriever pet, large, medium and small dog chain". The disadvantage of this type of mining source is that there is relatively large noise, and the noise correlation is relatively difficult to distinguish (there are noise types such as hyponymous types, apposition types, cheating, etc.).
All of the above simple methods can mine a large number of related word pairs, but the assumptions and design rules based on them are very simple, and the advantages and disadvantages are very obvious. Several optimized mining methods are described below.
3.1.2 Graph-Based Mining
Graph methods, such as classical collaborative filtering and Graph Embedding, recommend more similar documents by building a graph structure using the relationship between users and documents in recommendation scenarios. In the search scenario, the user's search query and the platform's Document can also be modeled into a graph structure by clicking, placing an order, etc. In the usage scenario of Meituan search, we have made the following two improvements to the composition method: ① The edge weight between Query and Document uses the number of clicks and click rate of Query to click on Document to obtain Wilson smoothing results, not just Query clicks The number of Documents, thereby improving the relevance; ② In the bipartite graph, the Query rewritten by the user in the Session is also regarded as the Document node, and the image is composed together with the clicked Document title, thereby increasing the amount of data mined.
We used the SimRank++ algorithm [2] verify the feasibility of the two optimization points of the composition method in the early days. The SimRank++ algorithm is a similarity measurement algorithm in the isomorphic information network. Its idea is: if two users are similar, then the same The items associated with the two users are also similar; if the two items are similar, the users associated with the two items are also similar. The advantage of this algorithm is that large-scale global optimization can be performed using Spark, and the edge weights can be adjusted as needed. After optimizing the composition, the manual evaluation of SimRank++ has increased the amount of query rewriting data by about 30% before and after optimization, and the accuracy rate has increased from 72% to 83%.

Subsequently, we tried other graph neural network models (GNNs) with the same idea. DeepWalk [3] adopts the random walk method in constructing Sentence context. Random walk generally builds the relationship between Query into a graph. By randomly walking from a point, multiple paths are established. The Query on each path forms a sentence, and then uses the context-dependent principle to train the Embedding of Query. The advantage of random walk is that the relationship is transitive, which is different from the co-occurrence of Query, and can establish a relationship between the query of indirect relationship. A small amount of data can generate enough training data by walking. For example, in Session1, the user searches Query1 first, then changes to Query2, and then queries. In Session2, the user searches for Query2 first, then changes to Query3, and then queries. The co-occurrence method cannot directly establish the relationship between Query1 and Query3, but random walk can be very good. resolved. In the rephrased word mining task, the graph-based method improves the mining efficiency and accuracy compared with the method of mining word pairs directly from the search log.
3.1.3 Based on Semantic Vector Mining
After word2vec [4] , the idea of Embedding quickly spread from the field of NLP to almost all fields of machine learning. In addition, the advantages of Embedding in the representation of data sparsity are also conducive to the exploration of subsequent deep learning. Converting Query Embedding to a low-dimensional semantic space and finding related words by calculating the similarity between Embeddings is a common and easy-to-practice mining method in the task of mining similar words. In addition to simply training large-scale word vectors on corpora such as user reviews (i.e., Figure 7a), the following two methods of constructing context have been tried in practice:
- Constructing Doc2Vec [5] by recalling merchants through Query: Embedding representation Query is trained through Query recalled or clicked merchants as context (ie Figure 7b). Due to the variety of services and commodities provided by the same merchant in the Meituan scenario, this method has relatively large noise without considering the category intention of Query itself.
- Construct a rewrite sequence [6] through the user Session: Train the Embedding representation Query through a Session sequence as the context (ie, Figure 7c). The advantage of this method is that it effectively utilizes the limitation of users to change words by themselves, and the mining coverage and accuracy are relatively higher.

After designing different context structures to obtain Embedding, in order to further improve the accuracy, the following basic steps are: ① After the training corpus has passed word segmentation, use fastText to train the word vector of Query. FastText training considers word-level Ngram features, which can Log in the word and word Embedding of Query to perform a simple sum or average to solve the OOV (Out-Of-Vocabulary) problem; ② In the target vocabulary, use the word vector to represent the word; ③ Use LSH to find the vector cosine similarity Candidate words above a certain threshold, or use the DSSM dual-tower model [7] to improve the accuracy through supervised training; ④ XGBoost combined with feature engineering for further filtering.
BERT [8] has profoundly changed the research and application ecology in the field of natural language processing since it was proposed. We have tried some methods using BERT Embedding. The most effective one is Sentence-BERT [9] or SimCSE [10] model obtains word vectors.
BERT calculates the semantic similarity through the downstream task of the relationship between sentences. The method is to use special characters to connect two sentences into a whole for classification. The problem is that it requires a large amount of redundant calculation due to the combination of pairs. Suitable for semantic similarity search or unsupervised clustering tasks. Sentence-BERT draws on the framework of the twin network model, inputs different sentences into the BERT model shared by two parameters, and obtains the representation vector of each sentence. This vector can be used for semantic similarity calculation, or it can be used for Supervised clustering task.
The method we practice is basically the same as the Sentence-BERT idea. We use the method on the left in the figure below to construct a supervised rewrite of the training data, and use the method on the right to perform vector calculation in historical search queries of different intent types.

Compared with the previous method, the double-tower structure BERT method has a stronger ability to capture semantics, and the supervised training method combined with some model structure adjustments can reduce various cases with serious drift. In addition, Sentence-BERT does not rely on statistical features and parallel corpus, and can be easily migrated and Fine-Tuning in any business, which is very friendly to some cold-start business scenarios. On this basis, the Faiss [11] vector retrieval method is used to construct an offline retrieval process, which can support efficient retrieval in a billion-level candidate pool. The rewriting candidates constructed by this method can reach tens of millions or even billions of data, and the actual measurement is accurate. higher rate. In recent years, methods such as comparative learning have continuously refreshed the list in the field of text representation, and continuous exploration can be made in terms of vector construction and vector interaction methods.
3.2 Semantic discriminant model
3.2.1 BERT Semantic Discriminant Model
Tens of millions of similar word pairs can be obtained from the above mining methods, but there are still a large number of cases with semantic drift, among which the problem of synonym drift is the most serious. The reason is that the assumption of Embedding based on the same context is too strong, and the contexts of synonyms are very similar, including the context of merchants and merchant categories (a merchant usually provides multiple services) and the context of user session change words (users are in a certain context. Therefore, it is easy to dig out the cognate case of "cello" → "violin", and it increases the difficulty of filtering bad cases from other dimensions such as user click behavior or intent classification.
However, the graph method ignores the problem of semantic drift due to its focus on relevance, and there are few Query nodes with small search volume, resulting in the comparison of cases such as "electric vehicle registration" → "electric vehicle monopoly", and the similarity score is not absolute meaning. In order to filter similar difficult cases from the semantic dimension, we solve this kind of problem by introducing the semantic information of BERT. BERT uses the idea of pre-training + fine-tuning to solve the problem of natural language processing. In addition to the deeper network, the design idea of the bidirectional language model can make better use of context information to avoid the problem of cognate drift. The following introduces some explorations on the relationship between BERT sentences in the query rewriting task.
At the beginning of BERT, we used mining data and a small amount of manual annotation data to perform two-stage Tuning on the inter-sentence relationship task on the MT-BERT [12] pre-trained on the Meituan scene corpus. In practice, it is found that the model trained on the existing mining data is not highly discriminative in some cases, such as the literal edit distances of "cello" → "violin" and "wine" → "grape" that we mentioned earlier Not a big case. Therefore, how to construct high-quality positive and negative example data is the key to approximating the upper limit of BERT's performance in query rewriting tasks.
Our first attempt is an approach to co-training, a semi-supervised approach that focuses on how to utilize a large amount of unlabeled data to improve model performance when there is less labeled data. Considering the high noise of offline mining data, we explored the method of NMT (Nature Machine Translation) and MT-BERT co-training to achieve the effect of improving data quality and model quality at the same time. The frame diagram of the overall system is as follows:

The entire collaborative training process is:
- Step1 The BERT discriminant model produces NMT training data: the MT-BERT model after offline mining of parallel corpus Fine-Tuning on the full amount of data to be predicted, sets a certain threshold and returns high-quality positive examples to NMT.
- Step2 NMT Fine-Tuning: Add some manually labeled data to the high-quality positive examples returned by BERT, and use it as the NMT model training data for training to obtain the NMT model and indicators.
- Step3 NMT generates the training data of the discriminant model: Randomly selects a certain number of Query and uses the NMT model to generate TopN rewritten word pairs, and outputs the Fine-Tuning data of the BERT discriminant model in the next stage.
- Step4 BERT discriminant model Fine-Tuning: uses the data generated in Step3 to take the head K word pairs as positive examples, the tail X words as negative examples, and perform Fine-Tuning on the BERT discriminant model.
- Loop the above steps until convergence: The loop iterates the above steps until both models converge on the evaluation set.
In the actual experiment, the collaborative training converges after 3 rounds of iterations, and the first two rounds of BERT and NMT on the artificially constructed Benchmark set are significantly improved, and the final effect is significantly better than directly using training samples + manually labeled data Tuning.
Collaborative training can effectively solve the cases with high literal text similarity such as "wine" → "grape", but the literal matching of "maqin" → "erhu" with high noise data frequency is not obvious, and the context is relatively similar. Case still exists. Here, the method of relation extraction is used to mine such difficult cases. For example, some pattern methods are used for the mining of apposition negative examples, mining sentences similar to "such as A, B, C, etc." mentioned in UGC, and construct high-quality apposition negative example data after filtering. After the optimization of negative example data, the accuracy of the model is further improved.
Finally, the training process of the BERT semantic discriminant model is divided into four stages: ① Unsupervised: Use the corpus of the Meituan scene to carry out Continue Train based on the BERT model; ② Semi-supervised: Use the data mined by the algorithm to perform Co-training Tuning; ③ Sample Enhanced Supervision: Use manually mined high-quality negative example Tuning; ④ Use manually labeled data for final Tuning. The accuracy of the final model reaches more than 94%, which solves a large number of semantic drift cases.
3.2.2 BERT Semantic Discrimination Model for Commodities
With the enrichment of Meituan's business scenarios, the proportion of e-commerce search and supply traffic has begun to increase, and the problem of misrewriting in the field of commodities has begun to increase. By analyzing the user Query and the rewritten case, it is found that the above model cannot be well migrated to the commodity field. The main reason is that in addition to the coverage of training data, in the commodity search scenario, the requirements for the corresponding rewriting of the user searching for the product are the same thing, and the accuracy of the rewriting is the same. The rate requirement is higher, but the user in the business scenario expresses the demand, and the corresponding rewriting requirement is to express the same demand. In addition, from the perspective of Document, the product recall field is relatively simple, and there is no problem that one merchant corresponds to multiple services when searching for merchants. The algorithm space is relatively large after the scene is simplified. Therefore, the rewritten discriminant model in the commodity field is optimized separately:
- training data to build : The first thing that the product rewriting model needs to solve is the problem of no training samples. Using regular methods such as SPU co-occurrence and vector recall, continuous follow-up of manual methods such as quality inspection and labeling data, and mining methods such as category combination, click, and UGC to construct difficult negative examples, millions of high-quality training data are finally constructed.
- data enhancement : Random Negatives, Batch Negatives, Hard Sample Negatives and other methods are used in the sampling process of model training to enhance the model's ability to identify and robust against misrewriting.
- Model structure optimization : Exploration on the model structure of the BERT between sentences in Baseline, and tried R-Drop [13] and Child-tuning [14] to improve the model expression ability. Overall F1 improved by 2.5PP.
- Graph-Vector Fusion : Try to construct a graph model based on the search results, and enhance the discriminative ability combined with the actual online search results. By doing entity recognition on the title of the recalled product online, and framing each entity as a node together with the Query, with the goal of predicting the edge type from the Query to the recalled entity, using the methods of GCN [15] and GAT [16] The resulting Graph Embedding is integrated into the BERT sentence relationship discrimination model through the vector Pooling method, and the final F1 increase is 1.6PP, which solves the ambiguity problem of rewriting "baby" as "doll" and recalling "toy doll" by mistake.
3.3 Online Services
Through the above mining methods, combined with the discriminant model to further improve the accuracy, high-quality rewriting pairs with a data volume of about 10 million can be obtained. However, the generalization efficiency of the application method of online dictionaries is low. The following will explain how to further improve the overall effect of query rewriting through online models.
Meituan query rewriting online has the following solutions: (1) high-precision dictionary rewriting; (2) higher-precision model rewriting (statistical translation model + XGBoost sorting model); (3) semantic NMT covering long-tail Query (Neural network translation model) End-to-end generation and rewriting; (4) Online vectorized retrieval covering business name search traffic.
Dictionary rewriting is a common method in the industry. It should be noted that synonym replacement needs to be combined with contextual information. For example, "people" and "civilians" can be synonymous alone, but in "People's Pharmacy" and "Civilian Pharmacy" It is a serious drift rewriting, and most of these problems can be solved by combining the entity recognition information design strategy after classifying the dictionary rewriting type. The following sections will introduce the last three online modules of Meituan search query rewriting.
3.3.1 SMT (Statistical Translation Model)
The problem of rewriting Query through offline mining is insufficient coverage, but the short term contained in a Query can be rewritten, such as a common example in the field of life services: "XX is broken" = "repair XX". Thinking from this perspective can abstract the query rewriting task as a typical machine translation task. You can set $f$ as the user search word, $e$ as the target rewrite word, the SMT as a whole can be abstracted as a noise channel model, and the SMT formula derivation is solved according to the Bayesian formula:
$$ \tilde{e} = arg \underset{e \in e^*}{\,max\,}p(e|f) = arg \underset{e \in e^*}{\,max\,}p(e|f) \frac{p(f|e)p(e)}{p(f)} = arg \underset{e \in e^*}{\,max\,}p(f|e)p(e)$$
The two obtained probabilities $p(f∣e)$ are the probability transition model, and $p(e)$ is the language model. Therefore, the rewriting model is divided into two parts, and the word alignment candidates are obtained by combining the existing parallel corpus of tens of millions, and the Decode model (probability transfer model) and the language model are trained respectively. In the actual construction process, some customized optimizations are made to the details of the model for the cases encountered:

- Alignment dictionary filtering: Due to the noise of the parallel corpus and the erroneous data generated by the alignment, we use the offline trained BERT semantic discriminant model to combine rules (such as the category cross entropy of the two Term distributions, whether they contain equal-dimensional features) The generated aligned vocabulary is filtered and optimized.
- structured Decode model: The Decode of SMT uses the BeamSearch algorithm. The parameters of BeamSearch are mainly divided into two parts: (1) The parameters of the mapping probability, on the basis of the score of the aligned vocabulary, some measures are added to measure the difference between the two terms. The similarity feature between the two; (2) the parameter of the transition probability, the information of the Term combination is added on the basis of the language model.
- sorting model: The ultimate purpose of rewriting is to recall more relevant and high-quality merchants, goods and services. Therefore, after obtaining a large number of rewriting results generated by SMT, two issues still need to be considered. On the one hand, semantic relevance, Another aspect is effectiveness. The solution is to introduce the XGBoost sorting model, and the features used take into account both the semantic correlation and the business statistical effect of the recall result dimension of rewritten words. The features used in semantic relevance include the click feature and text feature of the original word rewritten word; the text edit distance of the candidate pair, the text semantic similarity score, the number of session transfers, and the time interval. In terms of effectiveness, two aspects of geographical and popular information are introduced, including co-occurrence features such as exposure, click, and order placement in the two dimensions of Document and Document categories. The ranking model adopts the high-quality rewriting of Top3, which reduces the pressure of search and retrieval index, and can effectively ensure that the rewritten word recalls local high-quality relevant results.
In the end, the overall online framework is similar to the industry's classic Learning to Rewriting framework [17-18] . After the model goes online, the coverage of online traffic with rewrites has increased by nearly 12%, which is obtained on indicators such as QV_CTR. very considerable income.
3.3.2 NMT (Neural Network Translation Model)
After the introduction of synonym replacement and SMT statistical translation and rewriting online, the traffic coverage rate of online rewriting is close to 70%. However, there is still insufficient coverage in the long-tail query, which is mainly caused by the following two types of problems:
- The problem of mining efficiency introduced by word segmentation granularity: whether it is synonym replacement or SMT translation and rewriting based on shorter terms, there is a certain dependence on word segmentation results and candidates. The granularity of Chinese synonyms is often only the transformation of a certain word, such as "learning XX" → "training XX", and the rewriting of the single-character dimension is easy to cause Case, and it is impossible to excavate all "learning XX" to improve coverage. the goal of.
- The problem of complex Query rewriting with similar semantics that cannot be aligned: When the user enters some natural language Query, such as: "Where is the cheap mobile phone for sale?" On the merchant side, it is "Mobile phone discount". The generalization ability of the method based on word fragment candidates is better Weak and cannot solve similar problems.
Starting from the above problems, a generative rewriting model that does not rely on candidates is needed, and we consider using the deep semantic translation model NMT to solve such problems.
At the end of 2016, Google's neural network machine translation (GNMT) [19] announced that the neural network machine translation performance surpassed the 1989 IBM machine translation model (SMT, phrase-based machine translation model). Driving this huge development is the introduction of the Attention mechanism [20] 's Sequence to Sequence (Seq2Seq) end-to-end model. However, in actual use, it is found that the rewritten words generated by NMT have two problems that do not conform to semantics (uncommon or unfamiliar) and the rewriting has semantic drift, resulting in a low effective ratio of new online rewriting, and even leading to serious drift Cases . Therefore, to introduce NMT for rewriting, the above two problems must be optimized in combination with the use scenario of search. The goal is to generate rewritten words that have no intentional drift and can have actual recall effects. Based on the analysis and thinking of the above problems, it is the general goal to guide NMT to generate higher-quality rewriting by introducing environmental factors. From this perspective, we have investigated the methods of reinforcement learning.
The process of reinforcement learning is a cyclic process in which an agent (Agent) takes action (Action) to change its state (State), obtain rewards (Reward) and interact with the environment (Environment). We hope to use the idea of reinforcement learning to use the pre-trained NMT rewrite model as an Agent. During the process of reinforcement learning iteration, the generated rewrite (Action) generates the final exposure and click (Reward) through the search system (Environment) to guide the NMT. Optimize the model parameters (State).
After further research, we refer to the Google QA system [21] and Zhihu’s work [22] , that is, through the reinforcement learning method, the search system is regarded as an Environment, and the rewritten model is regarded as an Agent, so as to use the search system as an Environment and rewrite the model as an Agent. The quality of the results is taken into account. However, because the sorting in the Meituan scene is strongly related to sorting factors such as location and users, the feedback mechanism of using the entire Dasou as the Environment to recall the rewritten words and sorting forward cannot be used for reference, and requesting online sorting will lead to a series of projects such as slow training speed. question. Combined with the actual performance of NMT, consider giving priority to ensuring the semantic similarity of generated rewrites, and use the Dasou recall log combined with the BERT semantic discriminant model to do the Environment. The goal is the intersection of the original word and the rewritten word in the search system interaction. The degree of intersection and the natural semantic similarity Spend. The final overall frame diagram is as follows:

The algorithm module design and process are described in detail below:
Step 0 Pretrained NMT Generator
- model : The generator uses pre-trained NMT, and the model structure is the classic Seq2Seq model. Considering that the user's search term is short in the actual search scenario, an initialization Embedding based on word segmentation is used, and Attention is introduced between the Encoder-Decoder. The Attention mechanism can be a good substitute for the alignment mechanism in SMT, which is very consistent with query rewriting task background. In addition, we also use the BERT initialization encoder through Meituan corpus Fine-Tuning, which has the advantage of introducing more semantic information and faster model convergence.
- Pre-training data : Pre-training is very important in the whole system. Since the offline historical log is used to simulate the search system, in the reinforcement learning process, if the rewritten words generated by the generator are very rare, the Reward will be sparse, and the final system will not converge. Or the effect is not optimized. Therefore, we have made the following optimizations in the data. Considering that the advantage of NMT rewriting is semantic generalization, we have removed the proper noun aliases such as business names and addresses from the data obtained from the above offline mining; in the overall training, reinforcement learning will "Punish" the result of the rewritten word being the same as the original word. The consequence is that some proper nouns, such as some commodity names with fixed names, are rewritten into other commodities with drift, so a small number of commodity names are added to the training data. The original word rewriting pair of , limits the generalization ability of the model in this type of query.
- Model optimization : Short Query translation in query rewriting has been found to be prone to over-translation (repeated translation of certain words) and missed translation (some words are missed during translation) in practice. There are two reasons for over-translation, one is due to the noise of the training corpus or insufficient training, and the other is that in the case of OOV during the translation process, since NMT is a sequence problem, the subsequent translation process will lose information, resulting in over-translation. In addition to enriching and optimizing the training data, the method to solve the overturning problem also introduces the Coverage (coverage) mechanism. That is, a Coverage Vector is maintained for each source word to indicate the degree to which the word is translated. During the decoding process, the coverage information will be passed to the Attention Model, so that it can pay more attention to the untranslated source words. The problem of missing translation is due to the large number of one-to-many rewriting pairs in the training corpus, which makes NMT unable to learn accurate alignment information. This problem is solved by introducing edit distance in reinforcement learning.
Step 1 Original word rewritten word Input environment calculation feedback
From the user's point of view, a good rewritten word should have the same semantics, the newly recalled merchants of the rewritten word are very similar to the original word recalled merchants, and the distribution of the merchants that users click on should be relatively consistent. In addition, from the perspective of the effectiveness of rewriting, the rewriting words need to be smooth and popular search words with rich recall results. From the above analysis, it can be concluded that rewritings with high similarity should return positive feedback, and rewriting words that are dissimilar and incomprehensible should return negative feedback. Because the environment is divided into two parts, the offline search log simulates the search system and the BERT semantic discrimination system, which gives feedback to the generated Actions from the perspectives of the interaction between the search system and the user and the semantic discrimination.
- Offline search log simulates the search system : The offline search log contains the list of businesses finally exposed by the search system during a search and the user's click behavior on the list. By collecting search logs for a long period of time, we assume that historical queries are rich enough , store the recalled merchant ID list of historical Query and the user clicked merchant ID list two wide tables, in the process of reinforcement learning, by retrieving the original word and NMT on these two wide tables to generate the historical recalled merchant ID list and historical clicked merchants of the rewritten word ID list, this process can be compared to retrieval recall and click two-dimensional One-Hot vector to characterize the search term, and the mathematical representation of recall similarity and user intention similarity is obtained by calculating the coincidence of these two vectors. Through this method, we seem to get a more reasonable environmental output, but there are still several problems. One is that the original word is not in the historical query. We have designed a small fixed positive feedback for rewriting the original word from NMT. To solve this problem; the second is the situation where the rewritten word is not in the historical Query. We believe that the rewritten word should not be uncommon from the original word, so a fixed negative feedback is given to the situation where the rewritten word cannot be found. In addition, Sigmod smoothing is performed on the calculation of similarity to capture larger gradients of changes.
- BERT Simulates Semantic Discrimination System : Why do you need Semantic Discrimination with Simulated Search System? The reason is that a user's click on a business listing page does not necessarily fully represent their intent. On the one hand, as mentioned above, a merchant may have multiple semantically juxtaposed services. For example, most dental hospitals provide "tooth extraction" and "tooth filling" services, and the recall and click crossover of these two search terms are very large; on the other hand, there may be erroneous rewriting in the existing search system. Especially when the rewritten word is a popular search word or a substring of the original word, the user's click may generate a click because the image or business is popular, and such a click does not represent the original intention of the user. Therefore, the information of semantic discrimination is introduced into the reinforcement learning system, so as to avoid such problems of omission of search systems and user behaviors, and can also solve the Reward sparsity problem to a certain extent.
Step 2 The scorer adds of weights to the feedback generated by the environment.
According to the feedback score given by the environment, the normalized Reward is generated based on the weighted superposition. Here, multiple rounds of iterations are done according to the business scenario and practical problems, and a weighted feedback scorer is designed, which is used for search, user behavior, semantic discrimination, and literal matching. Different weights in several aspects are finally normalized to between 0-1 as the final feedback.
Step 3 Iterate the scorer result to in the loss that the generator continues to train.
According to the score of the scorer, the Reward is superimposed in the model Loss of NMT Fine-Tuning. Several methods are compared here. Among them, Google uses the average sentence length of the Batch to normalize and superimpose the averaged Loss. The effect is the best.
- Repeat steps 1-3 on the Query corpus of reinforcement learning until the model converges.
Through the effect analysis after the launch, the introduction of reinforcement learning NMT can solve the semantic type rewriting (picking tendons → tendons, labor disputes → labor disputes, firewood burning → firewood stove), uncommon abbreviations (French dessert shop → French dessert, foot finger →Foot nails), abbreviations caused by input errors (Yoga Instructor → Yoga Instructor, Mulberry Bath → Sauna Bath), natural language type Query to remove words (where to buy hair dye → hair dye, which hospital is the best for freckle removal → freckle removal hospital).
In general, reinforcement learning can improve the quality of rewritten words to a certain extent, especially in terms of relevance, after introducing the search system and user feedback, the accuracy and efficiency of rewriting have been greatly improved, and the accuracy of offline evaluation has increased from 69%. It has increased to 87%, improving the rewriting coverage of complex long-tail queries online without introducing bad BadCases that affect the user experience, and has achieved good results in indicators such as QV_CTR of the overall Meituan search long-tail query.
3.3.3 Online Vectorized Recall
Vectorized recall With the recent popularity of vector representation methods such as Sentence-BERT and SimCSE in academia, more and more companies have begun to try to apply them on a large scale, such as Facebook [23] , Taobao Search [24 ] , Jingdong [25] , etc. Thanks to the strong expressive ability of the pre-trained model, it has better generalization ability and accuracy than traditional methods such as DSSM.
There are two advantages to using vector recall in rewriting scenarios: on the one hand, Query and rewriting words are shorter and have similar lengths, and the semantics and types are more consistent, and the double towers with the same parameters can guarantee a certain accuracy; on the other hand, rewriting words from Retrieving from candidate pools instead of generating them can control the validity of rephrased words and restrict semantic types. By analyzing the missed recall problem of Meituan search, it is found that the merchant name fine search has a large problem of missed recall and recall. In addition, considering that in the Meituan scenario, the merchants provide rich services and the document side text is long and the intention is scattered, we first focus on the merchant intent. The vectorized recall (hereinafter referred to as "fuzzy rewriting") was tried in the problem of few and no results caused by text mismatches and achieved very good results, which will be described in detail below.
First of all, this kind of Case is summarized, and the problem to be solved by fuzzy rewriting is: when the user has a clear business intention, the text does not match, or the NER segmentation error leads to the problem of no result and missing recall. This kind of Case has a clear user intention but Query expression is vague. For example, searching for "Jiujiang Wagyu Roast Meat" did not recall the POI "Jiujiang Craft Barbecue", and searching for "Ningbo Laisi Train" did not recall the POI "Ningbo Train Laisi Theme Park". Such problems mix multiple textual variants and are difficult to solve within existing structured recall frameworks. After determining the boundary of the problem, it is concluded that this type of Case has the following characteristics: (1) Query is changeable, but the recall pool of business names is limited and definite; (2) Query and business name texts are short in length, which is very suitable for vectorization Recall algorithm; (3) It can get rid of the limitation of the existing Boolean retrieval recall framework and avoid missing recall caused by simple text matching. Therefore, we formulate a fuzzy rewriting process based on vector recall:

The following will focus on the core model of fuzzy rewriting and the two parts of the online service processing process.
model structure: model structure adopts two towers Query Tower $Q$ and POI Tower $P$, for a given Query and POI, use $q$ in the formula to represent the input Query text, $p$ to represent the input POI title text, The model calculation process is:
$$f(q,p)=G(Q(q),P(p))$$
Among them, $Q(q)$ represents the BERT tower that produces Query Embedding, $P(p)$ represents the BERT tower that produces POI title text Embedding, and $G$ represents the scoring calculation function, such as Inner Product, L2 distance, etc.
Vector Pooling: According to the characteristics of the BERT model, the farther each layer is from the downstream task, the stronger the generalization ability. After many experiments, it has been verified that using the penultimate layer vector for Avg Pooling The output results have higher accuracy and recall.
Negative Sampling: Facebook emphasized the problem of negative sample distribution in the paper "Embedding-based Retrieval in Facebook Search" [23] . We have three parts on negative sampling: Random Negatives, Batch Negatives, Hard Sample Negatives, and add a set of hyperparameters to adjust the ratio of the three. The more Random Negatives, the higher the quality of recalled merchants, but the lower the correlation; Batch Negatives refers to the practice of SimCSE, and the correlation is improved after adding; Hard Sample Negatives is to filter a batch of merchant names by rules. The text is very similar different merchants, as well as adding wrong rewrites and corrections, and adding them to each round of training at a lower ratio to further improve the expression of relevance.

Loss function: Loss uses the Pointwise Loss function of Binary Cross-Entropy, because in the case of a standard business name Label, the model predicts that the performance of rewriting the business name "absolutely correct" is better than that of Pairwise predicting "relatively correct" rewriting Merchant name. This is also reflected in the actual comparative experimental results.
online service construction: As shown in Figure 12, the online service is divided into four parts: pre-traffic division module, online text vectorization on Query side, ANN vector retrieval and post-rule.
- Pre-traffic division module: The pre-traffic division module controls the fuzzy rewriting service invocation logic, and is only invoked when the traditional text recall has no result under the search intent of the merchant name. On the one hand, the effect is guaranteed, and on the other hand, the traffic pressure on the downstream TFServing vector prediction service and vector retrieval service is reduced.
- Online text vectorization on the query side: The online performance of pre-trained models has always been one of the difficulties that plagued the implementation of large-scale NLP models in search systems. Tried Faster-Transformer on the model and converted the model to FP16 precision for acceleration. In addition to the cache of the overall service, considering that the query vector has nothing to do with the city, a layer of cache is also designed in this module to further reduce real-time calls.
- ANN retrieval: Vector retrieval uses the Antler vector retrieval engine developed by the Meituan search team. This service is packaged based on the Faiss library and implements vector retrieval algorithms such as IVFFlat and HNSW, and supports distributed vector retrieval, real-time indexing, and multi-field sharding. , vector subspace, scalar filtering and other retrieval capabilities, provide high-performance multi-field retrieval support for fuzzy rewriting to retrieve different POI libraries in different cities. The parameter adjustment of ANN also has an effect of 2PP up and down on the overall effect.
- Post-rules: By designing simple text filtering rules such as edit distance and a simple word weight strategy, priority is given to ensuring the relevance of the core part of the business name, and the effect of fuzzy rewriting is further improved.
After the fuzzy rewriting project was launched, the target cases such as "Jiujiang Wagyu Roast Meat" did not recall POI "Jiujiang Crafted Roast Meat" were solved very well. When users searched for the name of the merchant, there were many cases of changing words, many words, and few words. It has strong transformation ability, and after adding synonym replacement to the training data, it also solves the problem of missing recall of some synonyms and synonym replacement. From the perspective of online performance, QV_CTR, no result rate, and long-tail BadCase have large benefits, effectively improving the user search experience for this part of the traffic.
In addition to accumulating the algorithm engineering experience of vector retrieval, we conclude that the success of this project lies in defining a clear problem boundary through a series of problem discovery and problem classification, and making appropriate technical selections, using intent signal constraints The scope of application promotes the strengths and avoids weaknesses of the vector recall, and the final benefit exceeds expectations. Vector retrieval has been tried by major companies in the industry in recent years. We believe that there is still huge room for exploration in non-merchant name search traffic and commodity search traffic. Combined with the difficulties of multi-field, multi-service, and multi-business of merchants in the Meituan scenario , the variant of the model has a lot of points to try, we will introduce the exploration of the online vectorized retrieval direction in the subsequent articles, so stay tuned.
3.4 Platformization of query and rewrite service capabilities
After the iterations described above, the query rewriting project has contributed to good business benefits in different development periods of Meituan Search. And with the expansion of technical influence, it has gradually established cooperation with business parties such as Dianping App search, takeaway App search, search advertising, etc., and has accumulated corresponding data and technical capabilities in Meituan search products, takeaways, hotel tourism and other businesses . At the same time, each business has put forward some unique requirements for query rewriting according to its own development stage and business characteristics. For this, we have abstracted the core functions of query rewriting. The development direction of the entire technical framework is as follows:
- Data Refinement : The data level distinguishes several core businesses, and the provided word relationships include semantic dimensions such as synonyms, hyponyms, homonyms, and irrelevance. Use synonym hyponyms for search and recall, and synonyms for recommended advertisements. Irrelevant words are provided as negative examples for training correlation or ranking models. In the continuous mining process, data of different precisions are separated through models and manual verification, and the features of sorting have also obtained more than expected benefits.
- Algorithm Tooling : Provide comprehensive algorithm mining tools in terms of data volume coverage, continuously iterate model accuracy in terms of semantic discrimination, and solve the ambiguity problem of short texts in combination with application scenarios, track and explore cutting-edge methods in the industry.
- online service can operate and maintain : online service supports fast business access, online AB experiment and intervention, etc.

4. Summary and Outlook
This paper introduces the exploration and practical experience of query rewriting tasks in the Meituan scenario, and explores cutting-edge algorithm technologies such as semantic discriminant models, semantic retrieval models, and graph models on the topic of search and recall in vertical fields combined with actual business scenarios and user needs. Accumulates phrase association cognitive data in the field of life services. Among them, the offline data section introduces mining methods from various technical perspectives such as strategy, statistical translation, graph method and Embedding, and summarizes the starting point, effect, advantages and disadvantages of each method in practice. In terms of online models, combined with the structured retrieval characteristics of vertical search, high-precision dictionary rewriting, high-precision model rewriting (based on SMT statistical translation model and XGBoost sorting model), and optimization based on reinforcement learning methods covering long-tail Query are designed. Four online solutions for NMT model and vectorized recall for business search.
At present, rewriting traffic accounts for about 73% in Meituan App searches, and about 67% in Dianping App searches. The built query rewriting capability and service platform supports searches in various business channels and search advertising platforms, etc., and has achieved good benefits. Now the cluster QPS (Query Per Second) during the peak period of query rewriting service has reached 60,000 times per second. We will further invest in research and development to enhance the technical influence within the company and even in the industry.
How to better connect users with services, merchants, and commodities on the platform is a problem that requires long-term and multi-faceted investment. We may carry out iterations in the following directions in the future:
- Further explore vector retrieval : In the life service scenario, the needs of users and the services provided on the platform are huge, and will become more and more detailed and diverse. In recent years, methods such as comparative learning have continuously refreshed the list in the field of text representation, and the industry has also been exploring and deploying online vector recall. We believe that there is huge room for growth in this area and will continue to invest.
- Semantic Discriminant Model Exploration : Semantic understanding is inseparable from context, especially for users' understanding of short text search terms. Similar to the attempts made in Graph Embedding introduced above, methods such as multimodality can be considered in the future to better solve the problem of semantic discrimination in the search context.
- Generative Rewriting Exploration : Reinforcement learning can also try in the direction of SeqGAN [26] , and use better generators to solve the problem of long-tail search word rewriting.
- Further refine the capacit




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。