
Flow is a flow-based programming model. In this article, we will introduce reactive programming and its practice in Android development. You will learn how to bind the life cycle, rotation, and switching to the background and other states into Flow. and test that they perform as expected.
If you prefer to see this through video, check it out here:
https://www.bilibili.com/video/BV1db4y1p7nF/?aid=637490795&cid=555799182&page=1
△ Use Kotlin Flow to build a data flow "pipeline"
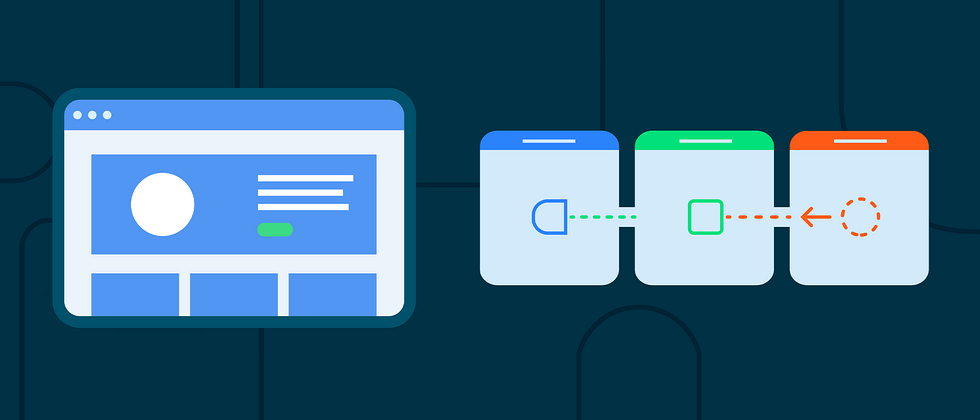
Unidirectional data flow

△ The process of loading the data stream
Every Android app needs to send and receive data in some way, such as getting a username from a database, loading a document from a server, and authenticating the user. Next, we will introduce how to load data into Flow, and then expose it to the view after transformation.
In order to make it easier for everyone to understand Flow, we will start with the story of Pancho. When Pancho, who lives on the mountain, wants to get fresh water from the lake, he will take a bucket and walk to the lake to get water, and then walk back, like most novices do at the beginning.

△ Pancho on the mountain
But sometimes Pahcho was unlucky, and when he got to the lake, he found that the water had dried up, so he had to look elsewhere for water. After this happened a few times, Pancho realized that building some infrastructure could solve the problem. So he installed some pipes by the lake, and when there is water in the lake, just turn on the faucet to get the water. Knowing how to install the pipes made it natural to combine pipes from multiple water sources so that Pancho would no longer have to check to see if the lake had dried up.

△ Pipe laying
In an Android app you can simply request data every time it is needed, for example we can use a suspend function to request data from the ViewModel every time the view starts, and then the ViewModel requests data from the data layer, and then all this again occurs in the opposite direction. But after a while, developers like Pancho often think that it is necessary to invest some cost to build some infrastructure, and we can stop requesting data and observe data instead. Observing the data is like installing a water intake pipe, any updates to the data source after deployment will automatically flow down the view, and Pancho will never have to walk to the lake again.

△ Traditional request data and one-way data flow
Programming
We call this type of system where the observer automatically reacts to changes in the observed object as reactive programming. Another design point of it is to keep the data flowing in only one direction, because it is easier to manage and less error.
The "data flow" of a sample application interface is shown in the figure below. The authentication manager tells the database that the user is logged in, and the database must tell the remote data source to load a different set of data; at the same time, these operations are fetching new data. Data will tell the view to display a spinning loading icon. To this I would say that while it works, it is prone to errors.

△ Intricate "data flow"
A better way would be to have the data flow in only one direction and create some infrastructure (like Pancho laying pipes) to combine and transform these data flows that can be modified with state changes, such as when the user logs out Reinstall the pipeline when you log in.

△ One-way data binding
uses Flow
It is conceivable that for these combinations and transformations, we need a mature tool to accomplish these operations. In this article we will use Kotlin Flow for this. Flow isn't the only dataflow builder out there, but it's well supported thanks to being part of coroutines. The water flow we have just used as a metaphor is called the Flow type in the coroutine library. We use the generic T to refer to any type of user data or page status carried by the data flow.

△ Producers and consumers
The producer will emit (send) data into the data stream, and the consumer will collect (collect) the data from the data stream. In Android, the data source or store is usually the producer of application data; the consumer is the view, which displays the data on the screen.
Most of the time you don't need to create the data flow yourself, because the libraries that the data source depends on, such as DataStore, Retrofit, Room or WorkManager, etc. common libraries are already integrated with coroutines and Flow. These libraries are like dams, they use Flow to provide data, you don't need to understand how the data is generated, you just "plug into the pipeline".

△ Libraries that provide Flow support
Let's look at an example of a Room. You can get notifications of changes in the database by exporting a data stream of a specified type. In this case, the Room library is the producer, which sends content every time it finds an update after each query.
@DAO
interface CodelabsDAO {
@Query("SELECT * FROM codelabs")
fun getAllCodelabs(): Flow<List<Codelab>>
}Create Flow
If you want to create your own dataflow, there are some options, such as the dataflow builder. Assuming we're in UserMessagesDataSource , when you want to frequently check for new messages within your app, you can expose user messages as a message list type data stream. We use the data flow builder to create the data flow, because Flow runs in the context of a coroutine, it takes a suspending code block as a parameter, which also means it is able to call suspending functions, which we can use in the code block while(true) to loop through our logic.
In the sample code, we first get the message from the API, then add the result to the Flow using the emit suspend function, which suspends the coroutine until the collector receives the data item, and finally we suspend the coroutine for a while. In Flow, operations are executed sequentially in the same coroutine, using the while(true) loop allows Flow to keep getting new messages until the observer stops collecting data. The pending block of code passed to the dataflow builder is often referred to as the "producer block".
class UserMessagesDataSource(
private val messagesApi: MessagesApi,
private val refreshIntervalMs: Long = 5000
) {
val latestMessages: Floa<List<Message>> = flow {
white(true) {
val userMessages = messagesApi.fetchLatestMessages()
emit(userMessages) // 将结果发送给 Flow
delay(refreshIntervalMs) // ⏰ 挂起一段时间
}
}
}Convert Flow
In Android, layers between producers and consumers can use intermediate operators to modify the data flow to suit the requirements of the next layer.
In this example, we take the latestMessages stream as the starting point of the data stream, then we can use the map operator to convert the data into different types, for example, we can use the map lambda expression to convert the original message from the data source to MessagesUiModel , this Operations can better abstract the current level, each operator should create a new Flow to send data according to its function. We can also filter the data stream using the filter operator to get the data stream containing important notifications. The catch operator can catch exceptions that occur in the upstream data flow. The upstream data flow refers to the data flow generated by the operator called between the producer code block and the current operator, and the data flow generated after the current operator. It is called downstream data flow. The catch operator can also re-throw the exception or send a new value when needed, we can see in the sample code that it re-throws IllegalArgumentExceptions when it catches it, and sends an empty list when other exceptions occur:
val importantUserMessages: Flow<MessageUiModel> =
userMessageDataSource.latestMessages
.map { userMessage ->
userMessages.toUiModel()
}
.filter { messageUiModel ->
messagesUiModel.containsImportantNotifications()
}
.catch { e ->
analytics.log("Error loading reserved event")
if (e is IllegalArgumentException) throw e
else emit(emptyList())
}Collection Flow
Now that we've seen how to generate and modify data streams, let's take a look at how to collect data streams. Collecting the data flow usually happens at the view layer, because this is where we want to display the data on the screen.
In this example, we want the latest news to appear in the list so that Pancho can keep up with what's going on. We can use the terminal operator collect to listen to all the values sent by the data stream, collect receives a function as a parameter which is called for each new value and since it is a suspend function it needs to be executed in a coroutine.
userMessages.collect { messages ->
listAdapter.submitList(messages)
}Using a terminal operator in a Flow will create a data flow on demand and start sending values, whereas an intermediate operator just sets up a chain of operations that delay execution while the data is being sent to the data flow. Each time userMessages is called on collect a new data stream is created, and its producer block will start flushing messages from the API at its own interval. In the , we call this data stream is created on demand and sends data only when it is observed.
Collect data stream on Android view
There are two things to keep in mind when collecting data streams in Android's views, the first is that resources should not be wasted when running in the background, and the second is configuration changes.
Safe Collection
Suppose we are in MessagesActivity , if we want to display a list of messages on the screen, we should stop collecting when the interface is not displayed on the screen, just like Pancho should turn off the faucet while brushing his teeth or sleeping. We have a variety of lifecycle-aware solutions to not collect information from the data stream when the information is not displayed on the screen, such as Lifecycle.repeatOnLifecycle(state) and Flow<T>.flowWithLifecycle(lifecycle, state) in the androidx.lifecycle:lifecycle-runtime-ktx package. You can also use the Flow<T>.asLiveData(): LiveData from the androidx.lifecycle:lifecycle-livedata-ktx package in the ViewModel to convert the data stream to LiveData so that you can use LiveData as usual to do this. However, for simplicity, it is recommended to use repeatOnLifecycle to collect data streams from the interface layer.
repeatOnLifecycle is a suspend function that receives Lifecycle.State as a parameter. The API is lifecycle aware, so it can automatically start a new coroutine with the code block passed to it when the lifecycle enters the responsive state, and leave the coroutine during the lifecycle. Cancel the coroutine when it is in state. In the above example, we use Activity's lifecycleScope to start the coroutine. Since repeatOnLifecycle is a suspend function, it needs to be called in the coroutine. The best practice is to call this function when the lifecycle is initialized, like in the example above we call it in the Activity's onCreate :
import androidx.lifecycle.repeatOnLifecycle
class MessagesActivity : AppCompatActivity() {
val viewModel: MessagesViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED)
viewModel.userMessages.collect { messages ->
listAdapter.submitList(messages)
}
}
// 协程将会在 lifecycle 进入 DESTROYED 后被恢复
}
}
}The restartable behavior of repeatOnLifecycle fully considers the life cycle of the interface, but it should be noted that until the life cycle enters DESTROYED , the coroutine calling repeatOnLifecycle will not resume execution, so if you need to collect from multiple data streams, then launch should be used multiple times within the repeatOnLifecycle code block to create a coroutine:
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
launch {
viewModel.userMessages.collect { … }
}
launch {
otherFlow.collect { … }
}
}
}If you only need to collect from one data stream, you can use flowWithLifecycle to collect data, which can send data when the life cycle enters the target state and cancel the inner producer when leaving the target state:
lifecycleScope.launch {
viewModel.userMessages
.flowWithLifecycle(lifecycle, State.STARTED)
.collect { messages ->
listAdapter.submitList(messages)
}
}In order to visually show the specific operation process, let's explore the life cycle of this Activity. First, it is created and visible to the user; then the user presses the home button to return the application to the background, and the Activity will receive onStop signal; onStart is called again when the app is reopened. If you call repeatOnLifecycle and pass STARTED state, the interface will only collect the signals from the data stream while it is on the screen, and cancel the collection when the app goes to the background.

△ Activity life cycle
repeatOnLifecycle and flowWithLifecycle are the new APIs of the lifecycle-runtime-ktx library in the 2.4.0 stable version. Before these APIs, you may have collected data streams from the Android interface in other ways, such as directly from the lifecycleScope like the above code. .launch , which seems to work but isn't necessarily safe, as this method will continue to collect data from the stream and update UI elements, even when the app exits to the background. It's slightly better if you use launchWhenStarted instead, because it suspends the collection while it's in the background. However, this will keep the data stream producer active, and may continue to emit data items that do not need to be displayed on the screen in the background, thus filling up the memory. Since the interface doesn't know how the stream producer is implemented, it's best to be cautious and use repeatOnLifecycle or flowWithLifecycle to avoid the interface collecting data or keeping the stream producer active while it's in the background.
Here is an example of an unsafe usage:
class MessagesActivity : AppCompatActivity() {
val viewModel: MessagesViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
// ❌ 危险的操作
lifecycleScope.launch {
viewModel.userMessage.collect { messages ->
listAdapter.submitList(messages)
}
}
// ❌ 危险的操作
LifecycleCoroutineScope.launchWhenX {
flow.collect { … }
}
}
}Configuration Changes
When you expose the data flow to the view, you must take into account that you are trying to pass data between two elements with different life cycles, not all life cycles will have problems, but in the life cycle of Activity and Fragment will compare tricky. When the device is rotated or a configuration change is received, all activities may be restarted but the ViewModel can be preserved, so you cannot simply expose any data flow from the ViewModel.

△ Rotating the screen will rebuild the Activity but retain the ViewModel
Take the cold flow in the code below as an example, since it restarts every time a cold flow is collected, repository.fetchItem() is called again after the device is rotated. We need some kind of buffer mechanism to keep data no matter how many times it is recollected, and to share data among multiple collectors, and StateFlow is designed for this purpose. In our lake analogy, StateFlow like a water tank that holds data even without a collector. Because it can be collected multiple times, it is safe to use it with an Activity or Fragment.
val result: Flow<Result<UiState>> = flow {
emit(repository.fetchItem())
}You could use a mutable version of StateFlow and update its value in the coroutine whenever you want, but doing so may not be very reactive programming style, as shown in the following code:
private val _myUiState = MutableStateFlow<MyUiState>()
val myUiState: StateFlow<MyUiState> = _myUiState
init {
viewModelScope.launch {
_muUiState.value = Result.Loading
_myUiState.value = repository.fetchStuff()
}
}Pancho will improve this by suggesting that you convert all types of streams to StateFlow , so that StateFlow will receive all updates from upstream streams and store the latest values, and the number of collectors can be 0 to any number, So ideal for use with ViewModel . Of course, there are some other types of Flow out there, but StateFlow is recommended because we can optimize it very precisely.

△ Convert any data flow to StateFlow
To convert the data stream to StateFlow , use the stateIn operator, which requires three parameters: initinalValue , scope , and started . Among them, initialValue is because StateFlow must have a value; and the coroutine scope is used to control when to start sharing. In the above example, we used viewModelScope ; the last started is an interesting parameter, we will talk about the role of WhileSubscribed(5000) later, First look at this part of the code:
val result: StateFlow<Result<UiState>> = someFlow
.stateIn(
initialValue = Result.Loading
scope = viewModelScope,
started = WhileSubscribed(5000),
)Let's take a look at these two scenarios: the first scenario is rotation, where the Activity (aka the data flow collector) is destroyed and rebuilt after a short period of time; the second scenario is going back to the home screen, which will will put our app into the background. In the rotation scene we don't want to restart any data flow to complete the transition as fast as possible, and in the back to the home screen scene we want to stop all data flow in order to save power and other resources.
We can correctly judge different scenarios by setting the timeout time. When the collection of StateFlow is stopped, all upstream data flows will not be stopped immediately, but will wait for a period of time. If the data is collected again before the timeout, the upstream data flow will not be canceled. That's what WhileSubscribed(5000) does. When the timeout is set, pressing the home button will cause the view to end the collection immediately, but StateFlow will stop its upstream data flow after the timeout period we set. If the user opens the app again, the upstream data flow will be automatically restarted . In the rotating scene the view is only stopped for a short time, no more than 5 seconds anyway, so the StateFlow will not restart, all upstream data flows will remain active as if nothing happened The same can be done to instantly present the rotated screen to the user.

△ Set the timeout time to deal with different scenarios
In general, it is recommended that you use StateFlow to expose dataflow via ViewModel , or asLiveData for the same purpose, for more details on StateFlow or its parent class SharedFlow , see: StateFlow and SharedFlow .
Test data stream
Testing data streams can be complicated because the objects to be processed are streaming data, here are tips that are useful in two different scenarios:
The first is the first scenario, the unit under test depends on the data flow, and the easiest way to test such a scenario is to replace the dependency with a mock producer. In this example, you can program this mock source to send what it needs to different test cases. You can implement a simple cold flow like in the above example, the test itself makes assertions on the output of the object under test, the output can be a data flow or any other type.

△ Test techniques that the unit under test relies on data flow
Simulate the data flow that the unit under test depends on:
class MyFakeRepository : MyRepository {
fun observeCount() = flow {
emit(ITEM_1)
}
}If the unit under test exposes a stream of data, and you want to validate that value or series of values, you can collect them in a number of ways. You can call the first() method on a data stream to collect and stop collecting after the first data item is received. You can also call take(5) and use the toList terminal operator to collect exactly 5 messages, which can be very helpful.

△ Test data flow skills
Test data flow:
@Test
fun myTest() = runBlocking {
// 收集第一个数据然后停止收集
val firstItem = repository.counter.first()
// 收集恰好 5 条消息
val first = repository.messages.take(5).toList()
}Review
Thanks for reading this article, I hope you have learned why reactive architecture is worth investing in and how to use Kotlin Flow to build your infrastructure. Information on this is provided at the end of the article, including guides covering the basics and articles that delve into certain topics. You can also learn more about these in the Google I/O app, for which we updated a lot on dataflow earlier.
- Tutorial: Kotlin Dataflow on Android
- Use a more secure way to collect Android UI data streams
- from LiveData to Kotlin
- Flow operator shareIn and stateIn usage notes
- The story behind the design of the repeatOnLifecycle API
- Sample Code: Google I/O Application
You are welcome Click here to submit feedback to us, or share your favorite content and found problems. Your feedback is very important to us, thank you for your support!






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。