

Three high Mysql - Mysql features and future development
introduction
The content is the study notes of the "High Concurrency, High Performance, High Availability Mysql Actual Combat" video of MOOC.com and the notes after personal organization and expansion. This section mainly talks about several new features commonly used in Mysql 5.8 and for internal servers. The optimization introduction, the theoretical part of the content is more simple to see and understand.
If the content is difficult, you can follow the "How Mysql Works" personal reading notes column to make up the lesson:
The address is as follows: Learn Mysql from scratch .
Mysql8.0 new features
Why is Mysql called 8.0? In fact, it is a number game and can be directly considered as 5.8.
What's new in Mysql8.0:
Window function: rank()
- Column separation, divided into multiple windows
- Execute specific functions in the window
-- partition by 排名,案例指的是按照顾客支付金额排名。
-- rank() 窗口函数
select *,
rank() over ( partition by customer_id order by amount desc) as ranking
from
payment;
hide index
- Temporarily hide an index.
- It can hide and display indexes, test the function of indexes, and evaluate the usability of indexes during development.
show index from payment;
-- 隐藏索引
alter table payment alter index fk_payment_rental Invisible;
-- 显示索引
alter table payment alter index fk_payment_rental Visible;Descending index
- Before 8.0, there were only ascending indexes. Since 8.0, the index sorting method of descending indexes has been introduced, which can also be used for some special queries.
Common Expressions (CTE)
- CTE expressions predefine intermediate results that are used repeatedly in complex statements
- It can be simply thought of as a temporary view
select b,d
from (select a,b from table1) join (select a,b from table2)
where cte1.a = cte2.c;
-- 简化
with
cte1 as (select a,b from table1),
cte1 as (select a,b from table2)
select b,d
from cte1 join cte2
where cte.a = cte2.c;
UTF8 encoding
- UTF8mb4 as the default character set
DDL transactions
- Support DDL transactions, metadata operations can be rolled back
For a DDL comparison between different databases, you can read this article:
InnoDB Cluster: Group replication does not mean that Mysql can be clustered, but to ensure data synchronization with strong consistency. The following is an explanation of some core components:
- Mysql Router: Routing
- The management side bypasses the routing for configuration, which can realize the free switching of the active and standby.

In addition, from the above picture, you can also see that in the new concept map, the node is generally not called master/slave. Well, zzzq is done.
Mysql's official group replication actually borrows the design idea of Percona XtraDB Cluster, but it adds some auxiliary tools to make it seem stronger. Strongly consistent group replication has already been implemented, such as Percona XtraDB Cluster, the design idea It is also a consensus protocol from Zookeeper, which can be considered to be similar in principle.

Finally, the biggest problem of strong consistency is whether the waiting time for synchronization can be accepted by the system, so it seems that group replication is trying to solve the data synchronization problem caused by replication. In fact, the cost seems to be relatively large.
Classification of databases
For the database, we can make the following summary. The mainstream databases on the market can basically be classified in the following ways: usage classification, storage form classification and architecture classification.
Category of use:
- OLTP: Online Transaction Processing
- OLAP: Online Analytical Processing
- HTAP: Transactional and Analytical Hybrid Processing
OLTP: Online transaction transaction and processing system, SQL statements are not complicated and are mostly used for transaction processing. The amount of concurrency is very high, and the requirements for availability are very high. (Mysql/Postgres)
OLAP: Online analytical processing system, the SQL statement is complex, and the amount of data is very large, with a single transaction as the unit. (Hive)
HTAP: Mixing the advantages of two databases, one architecture is multifunctional. (The design idea is excellent, but the actual output is likely to be similar to a new energy vehicle, and it is impossible to burn oil and burn it)
Storage form classification
- Row storage: the storage form of traditional databases
- Column storage: A format that gradually emerged for the analysis of large amounts of data in traditional OLTP databases. The row format is beneficial for data storage and data analysis.
- K/V storage: Whether it is row or column storage, it seems that the concept of KV cannot escape the concept of KV, which readers can think and understand by themselves.
Architecture Classification
Share-Everything
- CPU, memory, hard disk, all-in-one, similar to a computer (no database)
Share-Memory
- Multi-CPU independence, memory, hard disk, supercomputer architecture (multiple CPUs communicate with memory, the same large memory supercomputer)
SHare-Disk
- One CPU is bound to one memory, the hard disk is independent, and the shared storage architecture.
Shared-Nothing
- CPU, memory, hard disk sharing, common cluster architecture.
King of Monolithic Databases
To be honest, there are too few people using PostgresSQL in China. There is no choice and neglected excellent database in the domestic market. However, in foreign countries, with the continuous development of open source and better design than Mysql, the market share of PostgreSQL is increasing year by year. It is also a good template for designers. It is a very good reference material for both study and research. Finally, Postgresql is an open source community and is also active abroad. This is very important. Unfortunately, we can only honestly study Mysql in China. .
With the commercialization of Oracle, the progress of Mysql is gradually becoming smaller and smaller. I can't see his future.
Postgresql and Mysql are similar and more advanced:
- Mysql similar function
- Better performance and more stable
- higher code quality
- Has the advantage of catching up with Mysql
Good plugins include the ones that are not exhaustive, such as the following:
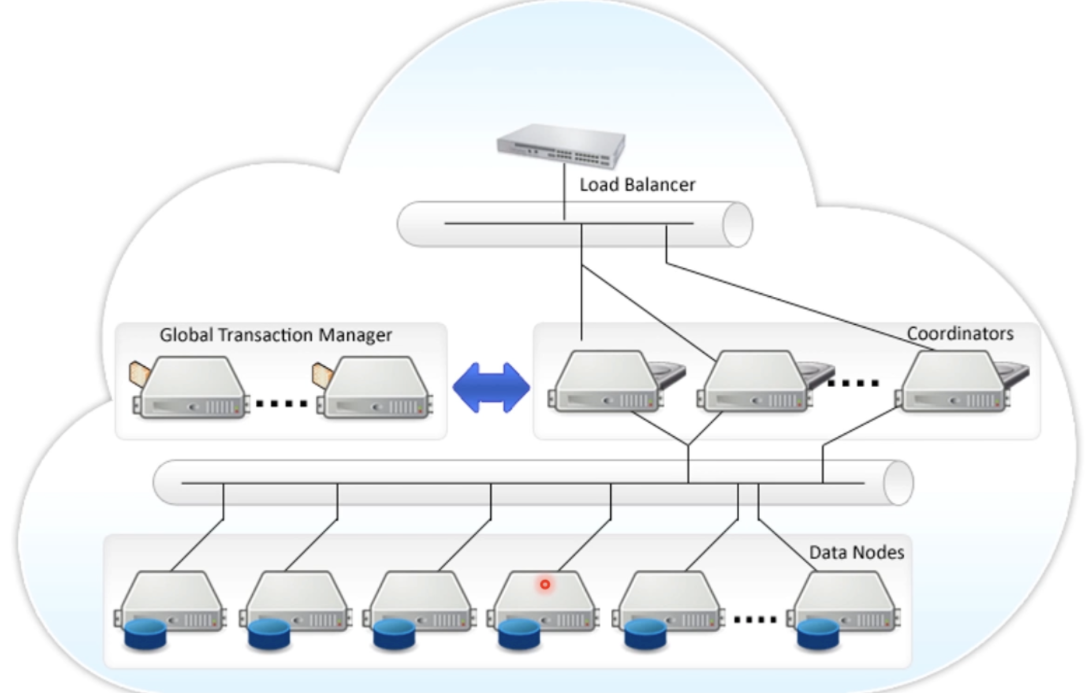
- Postgres-XL (OLTP)
- GTM manages the execution of each transaction
- Coordinator parses SQL, formulates execution plan, and distributes
- DataNode returns the execution result to Coordinator.
GreenPlum is a distributed analytics cluster for Postgres
- High Performance SQL Optimizer: GPORCA
- Implementation mechanism of Slice
How to change Mysql
Let's first look at the improvement of PolarDB. PolarDB is a product of Alibaba, so external technical personnel basically cannot touch this thing except that it may be used by internal personnel. Here is a brief introduction to the relevant design ideas.
The following are the relevant design drawings:

The following key components are included in PolarDB:
- ECS: Client
- Read/Write Splitter read-write separation middleware
- Mysql node, file system, data routing and data buffering. Active and standby servers
- RMDA unified management
Data Chunk Server: data storage bucket, storage server, and cluster storage
- Raft: Strongly consistent storage server.
- Log Shipping and Shared Storage

7. How to query data on the standby database
In the traditional way, the standby database is processed in the following way

Innovation and improvement points: When reading transaction changes, the method of superimposing redo log is used to prevent the problem of data inconsistency between read and write libraries

How to support Double Eleven?
When Double Eleven first appeared, it was a very hot topic. However, in the era of mature e-commerce, Double Eleven seems to have become a "daily activity"... The support of Double Eleven relies on the very core of the middle. Component: OceanBase , also known as new sql database.
The biggest feature of OceanBase, which belongs to the architecture of interexistence between ranks and columns , is that the computer room spans the world. The bottom layer of the storage engine is the partition layer of sharding, the Share-Nothing architecture, and the structure of one master and two backups used by data partitions.

How is the data updated?
The data update relies on the following process, which seems to be more responsible. In fact, the design idea here is somewhat similar to Google's "Bigtable" design in 2006, and SSTable first appeared in this paper. SSTable is mainly used to give LSM-Tree data structure. Log storage engine.
If you don't know what LSM-Tree is, you can read the following articles:
"Data-intensive system design" LSM-Tree VS BTree - Nuggets (juejin.cn)

Domestic hybrid database-TiDB
Introduction to TiDB:
The following content is quoted from the official introduction:
TiDB is an open source distributed relational database independently designed and developed by PingCAP . It is an integrated distributed database product that supports both online transaction processing and online analytical processing (Hybrid Transactional and Analytical Processing, HTAP). It can expand or shrink horizontally. It has important features such as capacity, financial-grade high availability, real-time HTAP, cloud-native distributed database, compatibility with MySQL 5.7 protocol and MySQL ecosystem. The goal is to provide users with one-stop OLTP (Online Transactional Processing), OLAP (Online Analytical Processing), and HTAP solutions. TiDB is suitable for various application scenarios such as high availability, high requirements for strong consistency, and large data scale.
In short, Tidb has the following features:
- One-click horizontal expansion or contraction
- Financial grade high availability
- real-time HTAP
HTAP database (Hybrid Transaction and Analytical Process). A 2014 Gartner report uses the term Hybrid Transactional Analytical Processing (HTAP) to describe a new type of application framework to break down the gap between OLTP and OLAP, which can be applied to both transactional database scenarios and analytical Database scene. Enable real-time business decisions. This architecture has obvious advantages: not only does it avoid tedious and expensive ETL operations, but it also enables faster analysis of the latest data. This ability to quickly analyze data will become one of the core competitiveness of future enterprises.
- Cloud-native distributed database
- Compatible with Mysql5.7 protocol and Mysql ecology.
Although TiDB has many criticized shortcomings after being used, and because it is a new type of database, there are relatively few answers to some practical problems, but as a very potential database, it is still worthy of our attention.
The architecture of TiDB is designed as follows:

- Pure distributed architecture, with good scalability, supports elastic expansion and contraction
- Supports SQL, exposes the network protocol of Mysql to the outside world, and is compatible with most Mysql syntaxes, and can directly replace Mysql in most scenarios
- High availability is supported by default. In the case of failure of a few copies, the database itself can automatically perform data repair and failover, which is transparent to the business.
- Support ACID transactions, friendly to some scenarios with strong consistency requirements, such as bank transfers
- It has a rich tool chain ecology, covering data migration, synchronization, backup and other scenarios
CockroachDB

Xiaoqiang Database, launched in 2015, initiated by former Google employees.
CockroachDB aims to create an open source, scalable, cross-regional replication and transaction-compatible ACID distributed database. It can not only achieve global (multi-data center) consistency, but also ensure the strong survivability of the database. Just like the name Cockroach (cockroach), it is an unbeatable Xiaoqiang.
The idea of CockroachDB comes from Google's global distributed database Spanner. The idea is to distribute data on multiple servers in multiple data centers to achieve a scalable, multi-version, globally distributed database that supports synchronous replication.
summary
This section mainly focuses on some new features of Mysql and how other third parties extend the database. At the same time, the classification of the database is introduced. We can find that the classification of the database can finally be divided according to a specific type.
write at the end
The content of this section is very simple, and readers can study in depth according to the relevant content.





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。