
How to solve cache breakdown (invalidation), cache penetration, and cache avalanche in Redis? We talked about using bloom filters to avoid "cache penetration".
Brother Ma, in which scenarios can the Bloom filter be used?
For example, when we use the "Tomorrow Toutiao" APP developed by "Code-beating" to watch news, how to ensure that the content recommended to the user will not be repeated each time, and how to filter the content that has already been seen?
You would say that we only need to record the history that each user has seen, and query the database to filter the existing data to achieve deduplication every time a recommendation is made.
In fact, if historical records are stored in a relational database, deduplication requires frequent exists queries to the database. When the system concurrency is high, it is difficult for the database to withstand the pressure.
Brother code, I can use the cache to store the historical data in Redis.
Absolutely, how much memory space will be wasted with so many historical records, so at this time we can use the Bloom filter to solve this deduplication problem . Fast and memory-saving, a must-have for Internet development!
When you encounter a large amount of data and need to deduplicate, you can consider the Bloom filter , as follows:
- Solve the problem of Redis cache penetration (interview focus);
- Mail filtering, use Bloom filter to achieve mail blacklist filtering;
- The websites crawled by the crawler are filtered, and the crawled websites are no longer crawled;
- Recommended news is no longer recommended;
What is a Bloom Filter
Bloom Filter was proposed by Burton Howard Bloom in 1970. It is a space efficient probabilistic data structure used to determine whether an element is in a set .
When the Bloom filter says that a certain data exists, the data may not exist; when the Bloom filter says that a certain data does not exist, then the data must not exist.
Hash tables can also be used to determine if an element is in a set, but a Bloom filter can do the same thing with 1/8 or 1/4 the space complexity of a hash table.
Bloom filters can insert elements, but cannot delete existing elements.
The more elements in it, the greater the false positive rate, but false negatives are impossible.
Bloom filter principle
The algorithm of BloomFilter is to first allocate a memory space as a bit array, and the initial values of the bit bits of the array are all set to 0.
When adding elements, use k independent Hash functions to calculate, and then set all K positions of the element Hash map to 1.
Detect whether the key exists, and still use the k Hash functions to calculate k positions. If the positions are all 1, it indicates that the key exists, otherwise it does not exist.
As shown below:

The hash function will collide, so the Bloom filter will have false positives.
The false positive rate here refers to the probability that BloomFilter judges that a key exists, but it does not actually exist, because it stores the Hash value of the key, not the value of the key.
So there is a probability that there are such keys, their contents are different, but the hash values after multiple hashes are the same.
For the key that BloomFilter judges does not exist, it is 100% non-existent. Contradictory method, if the key exists, then the corresponding Hash value position after each Hash must be 1, not 0. The existence of a Bloom filter does not necessarily exist.
Code brother, why is it not allowed to delete elements?
Deletion means that the corresponding k bits positions need to be set to 0, which may be bits corresponding to other elements.
So remove introduces false negatives, which are absolutely not allowed.
Redis integrated bloom filter
When Redis 4.0 officially provided a plug-in mechanism, the Bloom filter officially debuted. The following website can download the officially provided compiled extensible modules.
https://redis.com/redis-enterprise-software/download-center/modules/

Code Brother recommends using Redis version 6.x, minimum 4.x to integrate bloom filters. Check the version with the following command. The version installed by Code Brother is 6.2.6.
redis-server -v
Redis server v=6.2.6 sha=00000000:0 malloc=libc bits=64 build=b5524b65e12bbef5download
We compile and install ourselves and need to download it from github. The current release version is v2.2.14, download address: https://github.com/RedisBloom/RedisBloom/releases/tag/v2.2.14

Unzip and compile
decompress
tar -zxvf RedisBloom-2.2.14.tarCompile the plugin
cd RedisBloom-2.2.14
make If the compilation is successful, you will see the redisbloom.so file.
Install integration
You need to change the redis.conf file, add the loadmodule configuration, and restart Redis.
loadmodule /opt/app/RedisBloom-2.2.14/redisbloom.soIf it is a cluster, the configuration file of each instance needs to be added to the configuration.

Specify the configuration file and start Redis:
redis-server /opt/app/redis-6.2.6/redis.conf
The successfully loaded page is as follows:

Client connection Redis test.
BF.ADD --添加一个元素到布隆过滤器
BF.EXISTS --判断元素是否在布隆过滤器
BF.MADD --添加多个元素到布隆过滤器
BF.MEXISTS --判断多个元素是否在布隆过滤器 
Redis Bloom filter in action
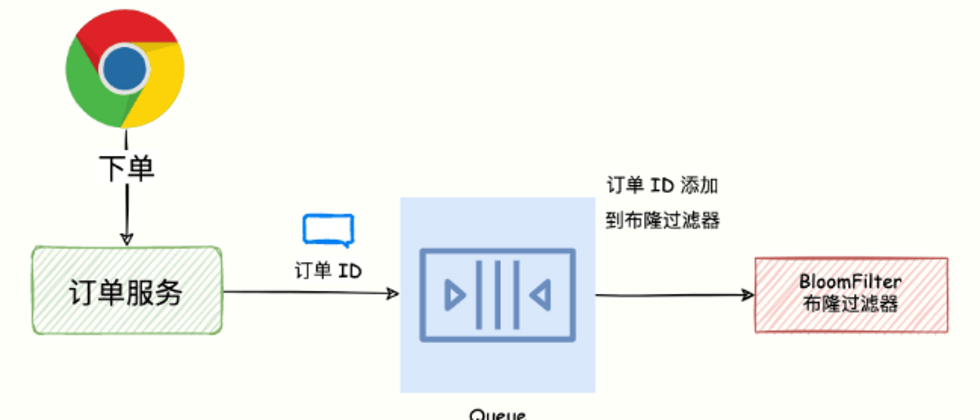
Let's use Bloom filter to solve the problem of cache penetration. Cache penetration: It means that a special request is querying a non-existent data, that is, the data does not exist in Redis nor in the database.
When a user buys an item to create an order, we send a message to mq to add the order ID to the bloom filter.

Before adding to the bloom filter, we manually create a bloom filter with the name orders error_rate = 0.1 and an initial capacity of 10000000 through the BF.RESERVE command:
# BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
BF.RESERVE orders 0.1 10000000- key: the name of the filter;
- error_rate: the expected error rate, the default is 0.1, the lower the value, the more space required;
- capacity: initial capacity, the default is 100. When the actual number of elements exceeds this initial capacity, the false positive rate increases.
- EXPANSION: optional parameter, when the data added to the bloom filter reaches the initial capacity, the bloom filter will automatically create a sub-filter, the size of the sub-filter is the size of the previous filter multiplied by the expansion; The default value is 2, which means that the default Bloom filter expansion is 2 times expansion;
- NONSCALING: optional parameter, after setting this item, when the data added to the bloom filter reaches the initial capacity, the filter will not be expanded, and an exception will be thrown ((error) ERR non scaling filter is full)
Note: The expansion of BloomFilter is accomplished by increasing the number of layers of BloomFilter. Each time a layer is added, multiple layers of BloomFilter may be traversed to complete the query, and the capacity of each layer is twice that of the previous layer (default).
If you do not use BF.RESERVE command to create, but the use of a Bloom filter Redis automatically created default error_rate is 0.01 , capacity is 100.
The smaller the error_rate of the rumble filter, the larger the storage space required. For scenarios that do not need to be too precise, the error_rate can be set slightly larger.
If the capacity of the Bloom filter is set too large, it will waste storage space, and if it is set too small, it will affect the accuracy, so before using it, you must estimate the number of elements as accurately as possible, and you need to add a certain amount of redundancy. space to avoid that the actual element might accidentally be much higher than the set value.
Add order ID to filter
# BF.ADD {key} {item}
BF.ADD orders 10086
(integer) 1 Use BF.ADD to add the element 10086 to the Bloom filter named orders .
If multiple elements are added at the same time, use BF.MADD key {item ...} as follows:
BF.MADD orders 10087 10089
1) (integer) 1
2) (integer) 1Check if an order exists
# BF.EXISTS {key} {item}
BF.EXISTS orders 10086
(integer) 1 BF.EXISTS Determine whether an element exists in BloomFilter , the return value = 1 means it exists.
If you need to batch check whether multiple elements exist in the bloom filter, use BF.MEXISTS , the return value is an array:
- 1: exists;
- 0: does not exist.
# BF.MEXISTS {key} {item}
BF.MEXISTS orders 100 10089
1) (integer) 0
2) (integer) 1 In general, we can avoid the cache penetration problem through three instructions BF.RESERVE、BF.ADD、BF.EXISTS .
Code brother, how to view the created Bloom filter information?
Use BF.INFO key to view, as follows:
BF.INFO orders
1) Capacity
2) (integer) 10000000
3) Size
4) (integer) 7794184
5) Number of filters
6) (integer) 1
7) Number of items inserted
8) (integer) 3
9) Expansion rate
10) (integer) 2return value:
- Capacity: preset capacity;
- Size: The actual occupancy, but how to calculate it needs to be further confirmed;
- Number of filters: the number of filter layers;
- Number of items inserted: The number of elements that have actually been inserted;
- Expansion rate: sub-filter expansion coefficient (default 2);
Code brother, how to delete the bloom filter?
Currently, Bloom filter does not support deletion, but Cuckoo Filter supports deletion.
Bloom filters generally exhibit better performance and scalability when inserting items (so if you are frequently adding items to your dataset, a Bloom filter might be ideal). The cuckoo filter is faster on inspection operations and also allows deletion.
If you are interested, you can take a look: https://oss.redis.com/redisbloom/Cuckoo_Commands/ )
Code brother, I want to know how you master so much technology?
In fact, I just read the official documents and do some simple processing. The actual content of this article is based on the example above in the official Redis document: https://oss.redis.com/redisbloom/ .
When you encounter problems, you must patiently find answers from official documents, and cultivate your ability to read and locate problems.
Redission Bloom filter in action
Code Brother's sample code is based on Spring Boot 2.1.4, code address: https://github.com/MageByte-Zero/springboot-parent-pom .
Add Redission dependencies:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.7</version>
</dependency>Configure Redission using Spring boot's default Redis configuration:
spring:
application:
name: redission
redis:
host: 127.0.0.1
port: 6379
ssl: falseCreate a Bloom filter
@Service
public class BloomFilterService {
@Autowired
private RedissonClient redissonClient;
/**
* 创建布隆过滤器
* @param filterName 过滤器名称
* @param expectedInsertions 预测插入数量
* @param falseProbability 误判率
* @param <T>
* @return
*/
public <T> RBloomFilter<T> create(String filterName, long expectedInsertions, double falseProbability) {
RBloomFilter<T> bloomFilter = redissonClient.getBloomFilter(filterName);
bloomFilter.tryInit(expectedInsertions, falseProbability);
return bloomFilter;
}
}unit test
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedissionApplication.class)
public class BloomFilterTest {
@Autowired
private BloomFilterService bloomFilterService;
@Test
public void testBloomFilter() {
// 预期插入数量
long expectedInsertions = 10000L;
// 错误比率
double falseProbability = 0.01;
RBloomFilter<Long> bloomFilter = bloomFilterService.create("ipBlackList", expectedInsertions, falseProbability);
// 布隆过滤器增加元素
for (long i = 0; i < expectedInsertions; i++) {
bloomFilter.add(i);
}
long elementCount = bloomFilter.count();
log.info("elementCount = {}.", elementCount);
// 统计误判次数
int count = 0;
for (long i = expectedInsertions; i < expectedInsertions * 2; i++) {
if (bloomFilter.contains(i)) {
count++;
}
}
log.info("误判次数 = {}.", count);
bloomFilter.delete();
}
}
Note: If it is a Redis Cluster cluster, you need RClusteredBloomFilter<SomeObject> bloomFilter = redisson.getClusteredBloomFilter("sample");
References
1. https://blog.csdn.net/u010066934/article/details/122026625
2. https://juejin.cn/book/6844733724618129422/section/6844733724706209806
3. https://www.cnblogs.com/heihaozi/p/12174478.html
4. https://www.cnblogs.com/allensun/archive/2011/02/16/1956532.html
5. https://oss.redis.com/redisbloom/Bloom_Commands/
6. https://oss.redis.com/redisbloom/
7. https://redis.com/blog/rebloom-bloom-filter-datatype-redis


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。