
In the business scenario of the mobile Internet, the amount of data is very large , and we need to save such information: a key is associated with a data set, and at the same time make statistics on this data set.
for example:
- Count the daily activity and monthly activity of a
APP; - Count how many different accounts visit a page every day (Unique Visitor, UV));
- Count the number of different entries that users search for every day;
- Count the number of registered IPs.
Usually, the number of users and visits we face are huge, such as the number of users at the level of millions or tens of millions, or the access information at the level of tens of millions or even billions .
Today, "Code Brother" uses different data types to implement: the function of counting how many different accounts visit a page every day, and gradually leads out HyperLogLog The principle is integrated with Java Redission Actual combat.
Tell everyone a trick, the official Redis website can now run Redis commands online: https://redis.io/ . As shown in the figure:

Implemented using Set
A user visiting a website multiple times in a day can only be counted as one time , so it is easy to think of implementing it through the Redis Set collection .
For example, when the WeChat ID is "Xiao Caiji" to access the article " Why is Redis so fast ", we store this information in the Set.
SADD Redis为什么这么快:uv 肖菜鸡 谢霸哥 肖菜鸡
(integer) 1"Xiao Caiji" visited the " Why is Redis so fast " page many times, and the deduplication function of Set ensures that the same "WeChat ID" will not be recorded repeatedly.
Use the SCARD command to count the page UV of "Why is Redis so fast". The command returns the number of elements in a collection (that is, the user ID).
SCARD Redis为什么这么快:uv
(integer) 2Implemented using Hash
If the code is old and wet, it can also be implemented by using the Hash type, using the user ID as the key of the Hash set, and executing the HSET command to set the value to 1 when accessing the page.
Even if "Xiao Caiji" repeatedly visits the page and executes the command repeatedly, it will only set the key equal to "Xiao Caiji" value to 1.
Finally, use the HLEN command to count the number of elements in the Hash collection is UV.
as follows:
HSET Redis为什么这么快 肖菜鸡 1
// 统计 UV
HLEN Redis为什么这么快Implemented using Bitmap
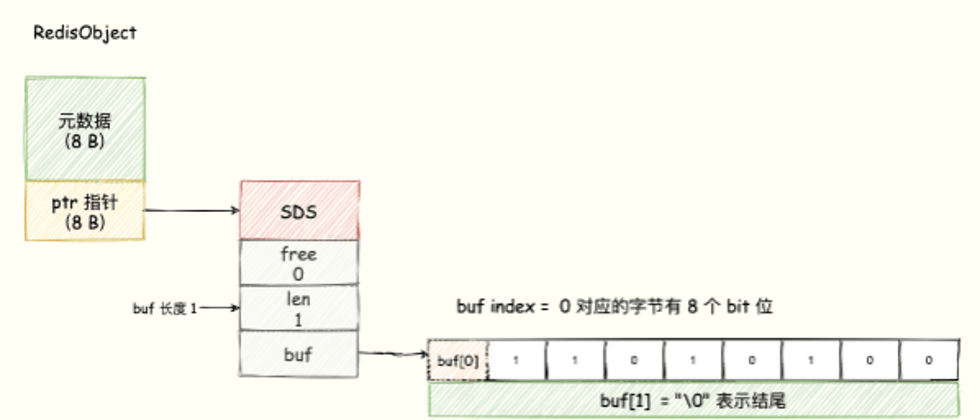
The underlying data structure of Bitmap uses the SDS data structure of String type to store the bit array. Redis uses the 8 bits of each byte array, and each bit represents the binary state of an element (either 0 or 1 ).
Bitmap provides the GETBIT、SETBIT operation to read and write the bit at the offset position of the bit array through an offset value offset. It should be noted that the offset starts from 0.
Bitmap can be regarded as a bit-unit array, each unit of the array can only store 0 or 1, the subscript of the array is called offset offset in Bitmap.
For visual display, we can understand that each byte of the buf array is represented by a row, each row has 8 bits, and the 8 grids respectively represent the 8 bits in the byte, as shown in the following figure:

8 bits form a Byte, so Bitmap will greatly save storage space. This is the advantage of Bitmap.
How to use Bitmap to count the number of unique user visits to a page?
Bitmap provides the SETBIT 和 BITCOUNT operation. The former writes the bit at the offset position of the bit array through an offset value offset. It should be noted that the offset starts from 0.
The latter counts the number of bits with value = 1 in the given specified bit array.
It should be noted that we need to convert the "WeChat ID" into a number, because offset is a subscript.
Suppose we convert "Xiao Caiji" to the code 6 .
The first step is to execute the following command to indicate that the code of "Xiao Caiji" is 6 and visit the article " Using Redis data types to achieve billion-level data statistics ".
SETBIT 巧用Redis数据类型实现亿级数据统计 6 1 The second step is to count the number of page visits and use the BITCOUNT command. This instruction is used to count the number of bits with value = 1 in a given bit array.
BITCOUNT 巧用Redis数据类型实现亿级数据统计HyperLogLog King Solution
Although Set is good, if the article is very popular and reaches the level of tens of millions, a Set will save the IDs of tens of millions of users, and the memory consumption will be too much if there are more pages.
The same is true for the Hash data type.
As for Bitmap, it is more suitable for the usage scenario of " binary state statistics ", and the statistical accuracy is high. Although the memory usage is less than
HashMap, it will still occupy a large amount of memory for a large amount of data.What to do?
These are typical "cardinality statistics" application scenarios, cardinality statistics: count the number of unique elements in a set.
The advantage of HyperLogLog is that the memory it requires does not change due to the size of the collection. No matter how many elements the collection contains, the memory required for HyperLogLog to perform calculations is always fixed and very small. of .
Each HyperLogLog only needs to spend up to 12KB of memory, and under the premise of standard error 0.81% , the cardinality of 2 to the 64th element can be calculated.
Redis in action
HyperLogLog is too simple to use. PFADD、PFCOUNT、PFMERGE Three commands to conquer the world.
PFADD
Add each user ID that visits the page to HyperLogLog .
PFADD Redis主从同步原理:uv userID1 userID 2 useID3PFCOUNT
Use PFCOUNT to obtain the UV value of the article " Redis Master-Slave Synchronization Principle ".
PFCOUNT Redis主从同步原理:uvPFMERGE usage scenarios
HyperLogLog` 除了上面的 `PFADD` 和 `PFCOIUNT` 外,还提供了 `PFMERGEgrammar
PFMERGE destkey sourcekey [sourcekey ...]For example, in the website we have two pages with similar content, and the operation says that the data of these two pages needs to be merged.
Among them, the UV traffic of the page also needs to be combined, then this time PFMERGE can come in handy, that is, the same user visits these two pages only once .
As shown below: Redis, MySQL two HyperLogLog collections respectively save two pages of user access data.
PFADD Redis数据 user1 user2 user3
PFADD MySQL数据 user1 user2 user4
PFMERGE 数据库 Redis数据 MySQL数据
PFCOUNT 数据库 // 返回值 = 4Merge multiple HyperLogLogs into one HyperLogLog. The cardinality of the merged HyperLogLog is close to the union of the observed set of all input HyperLogLogs.
Both user1 and user2 have accessed Redis and MySQL, only one visit.
Redission in action
The detailed source code "Code Brother" has been uploaded to GitHub: https://github.com/MageByte-Zero/springboot-parent-pom.git
pom dependencies
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.7</version>
</dependency>Add data to Log
// 添加单个元素
public <T> void add(String logName, T item) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
hyperLogLog.add(item);
}
// 将集合数据添加到 HyperLogLog
public <T> void addAll(String logName, List<T> items) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
hyperLogLog.addAll(items);
}merge
/**
* 将 otherLogNames 的 log 合并到 logName
*
* @param logName 当前 log
* @param otherLogNames 需要合并到当前 log 的其他 logs
* @param <T>
*/
public <T> void merge(String logName, String... otherLogNames) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
hyperLogLog.mergeWith(otherLogNames);
}Statistical base
public <T> long count(String logName) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
return hyperLogLog.count();
}unit test
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedissionApplication.class)
public class HyperLogLogTest {
@Autowired
private HyperLogLogService hyperLogLogService;
@Test
public void testAdd() {
String logName = "码哥字节:Redis为什么这么快:uv";
String item = "肖菜鸡";
hyperLogLogService.add(logName, item);
log.info("添加元素[{}]到 log [{}] 中。", item, logName);
}
@Test
public void testCount() {
String logName = "码哥字节:Redis为什么这么快:uv";
long count = hyperLogLogService.count(logName);
log.info("logName = {} count = {}.", logName, count);
}
@Test
public void testMerge() {
ArrayList<String> items = new ArrayList<>();
items.add("肖菜鸡");
items.add("谢霸哥");
items.add("陈小白");
String otherLogName = "码哥字节:Redis多线程模型原理与实战:uv";
hyperLogLogService.addAll(otherLogName, items);
log.info("添加 {} 个元素到 log [{}] 中。", items.size(), otherLogName);
String logName = "码哥字节:Redis为什么这么快:uv";
hyperLogLogService.merge(logName, otherLogName);
log.info("将 {} 合并到 {}.", otherLogName, logName);
long count = hyperLogLogService.count(logName);
log.info("合并后的 count = {}.", count);
}
}
Fundamental
HyperLogLog is a probabilistic data structure that uses a probabilistic algorithm to count the approximate cardinality of a collection. The origin of its algorithm is the Bernoulli process.
A Bernoulli process is a coin tossing experiment. Toss a normal coin, the landing may be heads or tails, and the probability of both is 1/2 .
The Bernoulli process is to keep tossing a coin until it lands heads, and record the number of k .
For example, if a coin is tossed once, it will appear heads, at this time k is 1 ; the first coin toss is tails, then continue tossing, until the third time it appears heads, this When k is 3.
For n Bernoulli process, we will get n number of throws with k1, k2 ... kn , where the maximum value here is k_max .
According to a mathematical derivation, we can draw a conclusion: 2^{k_ max} as the estimated value of n.
That is to say, you can approximate the number of Bernoulli processes based on the maximum number of throws.
Therefore, the basic idea of HyperLogLog is to estimate the overall cardinality by using the maximum value of the first 1 in the bit string of the numbers in the set to estimate the overall cardinality. However, this estimation method has a large error. In order to improve the error situation, the bucket average is introduced into HyperLogLog. The concept of , computes the harmonic mean of m buckets.
HyperLogLog in Redis has a total of 2^14 buckets, which is 16384 buckets. Each bucket is a 6-bit array, as shown in the figure below.

The principle of HyperLogLog is too complicated. If you want to know more, please move to:
- https://www.zhihu.com/question/53416615
- https://en.wikipedia.org/wiki/HyperLogLog
- How to count users' daily activity and monthly activity - Redis HyperLogLog detailed explanation
Redis optimizes the storage of HyperLogLog . When the count is relatively small, the storage space uses a coefficient matrix, which occupies a small space.
Only when the count is large and the space occupied by the sparse matrix exceeds the threshold will it be converted into a dense matrix, occupying 12KB of space.
Why only need 12 KB?
HyperLogLog in the implementation is 16384 buckets, that is, 2^14 , each bucket needs bits maxbits bits to store, the maximum can represent maxbits=63 , so the total memory occupied is 2^14 * 6 / 8 = 12k byte.
Summarize
Using Hash , Bitmap , HyperLogLog to achieve:
-
Hash: The algorithm is simple, the statistical precision is high, and it is used with a small amount of data, which will occupy a lot of memory for massive data; -
Bitmap: Bitmap algorithm, suitable for "binary statistics scenario", please refer to my article for details. For a large number of different page data statistics, it will still occupy a large amount of memory. -
Set: Implemented using the deduplication feature, one Set saves the IDs of tens of millions of users, and the memory consumed by more pages is too large. In Redis, eachHyperLogLogkey needs only 12 KB of memory to calculate the cardinality of nearly2^64different elements. BecauseHyperLogLogonly calculates the cardinality from the input elements, and does not store the input elements themselves, soHyperLogLogcannot return the individual elements of the input like a set. -
HyperLogLogis an algorithm, not unique toRedis - The purpose is to do cardinality statistics, so it is not a collection, no metadata is saved, and only the number is recorded instead of the value.
- The space consumption is very small, and it supports the input of a very large amount of data
- The core is the cardinality estimation algorithm, which is mainly manifested in the use of memory during calculation and the processing of data merging. There is a certain error in the final value
-
RediseachHyperloglogkey occupies 12K of memory for marking cardinality (official document) -
pfaddcommand does not allocate 12k memory at one time, but gradually increases the memory allocation with the increase of the cardinality; while the pfmerge operation will merge the sourcekey and store it in a 12k key, which is set byhyperloglogThe principle of the merge operation (twoHyperloglogthe value of each bucket needs to be compared separately when merging) can be easily understood. - Error description: The result of the cardinality estimate is an approximation with
0.81%standard error. is an acceptable range -
RedisOptimize the storage ofHyperLogLog. When the count is relatively small, the storage space is stored in a sparse matrix, and the space occupation is very small. Only when the count gradually becomes larger, the space occupied by the sparse matrix gradually increases. When the threshold is exceeded, it will be converted into a dense matrix at one time, and it will take up 12k of space
Good article recommended
- Redis Actual Combat: Using Data Types to Achieve Billion-Level Data Statistics
- Hardcore | Redis Bloom Filter principle and actual combat
- Redis Actual Combat: Using Bitmap Skillfully to Achieve Billion-Level Mass Data Statistics
- Redis Actual Combat: Realizing Nearby People Meet Goddess Through Geo Type
- The evolution process of the correct implementation principle of Redis distributed lock and the summary of Redisson actual combat
References


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。