
Author: Cheng Dehao, Fluent Member, KubeSphere Member
Introduction to Fluent Operator
With the rapid development of cloud-native technologies and the continuous iteration of technologies, higher requirements are put forward for log collection, processing, and forwarding. The log scheme under the cloud native architecture is very different from the log architecture design based on the physical machine or virtual machine scenario. As a CNCF graduate project, Fluent Bit is undoubtedly one of the preferred solutions for solving logging problems in cloud environments. However, there are certain thresholds for installing, deploying and configuring Fluent Bit in Kubernetes, which increases the cost of use for users.
On January 21, 2019 , the KubeSphere community developed the Fluentbit Operator to meet the needs of managing Fluent Bit in a cloud-native way, and released the v0.1.0 version on February 17, 2020. Since then, the product has been continuously iterated, and the Fluentbit Operator will be officially donated to the Fluent community on August 4, 2021 .
Fluentbit Operator lowers the threshold for using Fluent Bit, and can process log information efficiently and quickly, but Fluent Bit's ability to process logs is slightly weaker. We have not integrated log processing tools, such as Fluentd, which has more plug-ins available. Based on the above requirements, Fluentbit Operator integrates Fluentd, aiming to integrate Fluentd as an optional log aggregation and forwarding layer, and is renamed as Fluent Operator (GitHub address: https://github.com/fluent/fluent-operator ) . Fluent Operator released v1.0.0 on March 25, 2022, and will continue to iterate Fluentd Operator. It is expected to release v1.1.0 in the second quarter of 2022, adding more features and highlights.
Fluent Operator can be used to deploy, configure and uninstall Fluent Bit and Fluentd flexibly and conveniently. At the same time, the community also provides a large number of plug-ins that support Fluentd and Fluent Bit, and users can customize the configuration according to the actual situation. The official documentation provides detailed examples, which are very easy to use and greatly reduce the threshold for using Fluent Bit and Fluentd.

Stages of the Log Pipeline
Fluent Operator can deploy Fluent Bit or Fluentd alone, and does not require the use of Fluent Bit or Fluentd. It also supports the use of Fluentd to receive log streams forwarded by Fluent Bit for multi-tenant log isolation, which greatly increases the flexibility and diversity of deployment. sex. For a more comprehensive understanding of Fluent Operator, the following figure takes a complete log pipeline as an example, and divides the pipeline into three parts: collection and forwarding, filtering, and output.
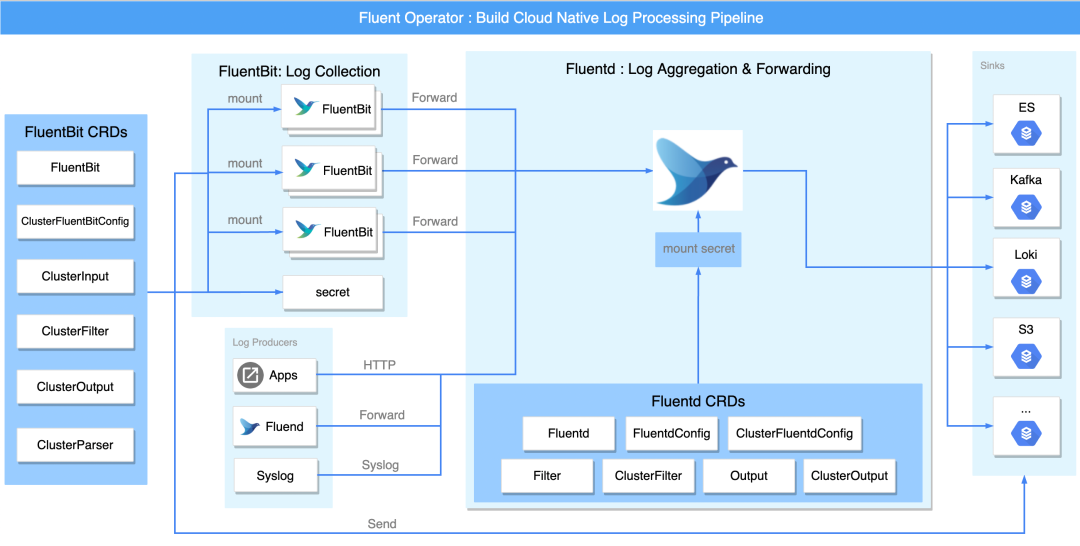
Capture and forward
Both Fluent Bit and Fluentd can collect logs.
When deployed separately, you can use Fluent Bit's intput plug-in or Fluentd's forward and http plug-ins to meet the requirements for log collection. When the two are combined, Fluentd can use forward to accept the log stream forwarding of Fluent Bit.
In terms of performance, Fluent Bit is lighter than Fluentd and consumes less memory (about 650KB), so Fluent Bit is mainly responsible for collecting and forwarding logs. Logs are collected and forwarded on each node through Fluent Bit installed as a DaemonSet.
filter
The data collected by logs is often too cluttered and redundant, which requires log processing middleware to provide the ability to filter and process log information. Both Fluent Bit or Fluentd support filter plugins, and users can integrate and customize log data according to their own needs.
output
The Fluent Bit output or Fluentd output plugin outputs the processed log information to multiple destinations, which can be third-party components such as Kafka and Elasticsearch.
Introduction to CRDs
Fluent Operator defines two groups for Fluent Bit and Fluentd respectively: fluentbit.fluent.io and fluentd.fluent.io.
fluentbit.fluent.io
The fluentbit.fluent.io group contains the following 6 CRDs:
- Fluentbit CRD defines the properties of Fluent Bit, such as image version, taint, affinity and other parameters.
- ClusterFluentbitConfig CRD defines the configuration file of Fluent Bit.
- The ClusterInput CRD defines the input plug-in of Fluent Bit, that is, the input plug-in. Through this plug-in, users can customize what kind of logs to collect.
- ClusterFilter CRD defines the filter plug-in of Fluent Bit, which is mainly responsible for filtering and processing the information collected by fluentbit.
- ClusterParser CRD defines the parser plug-in of Fluent Bit, which is mainly responsible for parsing log information and can parse log information into other formats.
- The ClusterOutput CRD defines the output plug-in of Fluent Bit, which is mainly responsible for forwarding the processed log information to the destination.
fluentd.fluent.io
The fluentd.fluent.io group contains the following 7 CRDs:
- Fluentd CRD defines properties of Fluentd, such as image version, taint, affinity and other parameters.
- The ClusterFluentdConfig CRD defines a Fluentd cluster-level configuration file.
- FluentdConfig CRD defines the configuration file of Fluentd namespace scope.
- The ClusterFilter CRD defines a Fluentd cluster-wide filter plugin, which is mainly responsible for filtering and processing the information collected by Fluentd. If Fluent Bit is installed, the log information can be further processed.
- Filter CRD This CRD defines the filter plugin of the Fluentd namespace, which is mainly responsible for filtering and processing the information collected by Fluentd. If Fluent Bit is installed, the log information can be further processed.
- ClusterOutput CRD This CRD defines Fluentd's cluster-wide output plugin, which is responsible for forwarding processed log information to the destination.
- Output CRD This CRD defines the output plugin of Fluentd's namespace scope, which is mainly responsible for forwarding the processed log information to the destination.
Introduction to the principle of orchestration (instance + mounted secret + CRD abstraction capability)
Although both Fluent Bit and Fluentd have the ability to collect, process (parse and filter) and output logs, they have different advantages. Fluent Bit is lighter and more efficient than Fluentd, and Fluentd plugins are richer.
To balance these advantages, Fluent Operator allows users to use Fluent Bit and Fluentd flexibly in several ways:
- Fluent Bit only mode: If you only need to collect logs and send them to the final destination after simple processing, you only need Fluent Bit.
- Fluentd only mode: If you need to receive logs over the network in HTTP or Syslog, etc., and then process and send the logs to the final destination, you only need Fluentd.
- Fluent Bit + Fluentd mode: If you also need to perform some advanced processing on the collected logs or send them to more sinks, you can use Fluent Bit and Fluentd in combination.
Fluent Operator allows you to configure the log processing pipeline in the above 3 modes according to your needs. Fluentd and Fluent Bit have rich plug-ins to meet various customization needs of users. Since the configuration and mounting methods of Fluentd and Fluent Bit are similar, we will briefly introduce the mounting method of Fluent Bit configuration file.
In the Fluent Bit CRD, each ClusterInput, ClusterParser, ClusterFilter,ClusterOutput represents a Fluent Bit configuration part, selected by the ClusterFluentBitConfig tag selector. The Fluent Operator monitors these objects, builds the final configuration, and finally creates a Secret to store the configuration installed into the Fluent Bit DaemonSet. The entire workflow is as follows:

Because Fluent Bit itself does not have a reload interface (see this known issue for details), in order to enable Fluent Bit to fetch and use the latest configuration when Fluent Bit configuration changes, a wrapper called fluentbit watcher is added to detect Restarts the Fluent Bit process as soon as the Fluent Bit configuration changes. This way, the new configuration can be reloaded without restarting the Fluent Bit pod.
In order to make user configuration more convenient, we extract application and configuration parameters based on the powerful abstraction capability of CRD. Users can configure Fluent Bit and Fluentd through the defined CRD. Fluent Operator monitors the changes of these objects to change the state and configuration of Fluent Bit and Fluentd. Especially the definition of the plugin, in order to make the user transition more smoothly, we basically keep the name consistent with the original fields of Fluent Bit, lowering the threshold for use.
How to implement multi-tenant log isolation
Fluent Bit can collect logs efficiently, but if complex processing of log information is required, Fluent Bit is a little out of control, while Fluentd can use its rich plug-ins to complete advanced processing of log information. Fluent-operator abstracts various plugins of Fluentd so that log information can be processed to meet user's custom needs.
As can be seen from the definition of CRD above, we divide Fluentd's config and plug-in CRDs into cluster-level and namespace-level CRDs. By defining CRD into two scopes, with the help of Fluentd's label router plug-in, the effect of multi-tenant isolation can be achieved.
We have added the watchNamespace field to clusterfluentconfig. Users can choose which namespaces to monitor according to their needs. If it is empty, it means to monitor all namespaces. The namesapce level fluentconfig can only monitor the CR and global level configuration in the namespace where it is located. Therefore, the logs at the namespace level can be output to the output in the namespace or to the output at the clsuter level, so as to achieve the purpose of multi-tenant isolation.
Fluent Operator vs logging-operator
difference
- Both can automatically deploy Fluent Bit and Fluentd. The logging-operator needs to deploy Fluent Bit and Fluentd at the same time, and Fluent Operator supports pluggable deployment of Fluent Bit and Fluentd, which is not strongly coupled. Users can choose to deploy Fluentd or Fluent Bit according to their own needs, which is more flexible.
- The logs collected by Fluent Bit in the logging-operator must pass through Fluentd to be output to the final destination, and if the amount of data is too large, Fluentd has a single point of failure hidden danger. Fluent Bit in Fluent Operator can directly send log information to the destination, thereby avoiding the hidden danger of single point of failure.
- The logging-operator defines four CRDs: loggings, outputs, flows, clusteroutputs and clusterflows, while Fluent Operator defines 13 CRDs. Compared with logging-operator, Fluent Operator has more diverse CRD definitions, and users can configure Fluentd and Fluent Bit more flexibly as needed. At the same time, when defining the CRD, select a name similar to the configuration of Fluentd and Fluent Bit, and strive to make the name clearer to conform to the native component definition.
- Both draw on Fluentd's label router plugin to achieve multi-tenant log isolation.
Outlook:
- Support HPA automatic scaling;
- Improve Helm Chart, such as collecting metrics information;
- ...
Detailed usage
With the help of Fluent Operator, logs can be processed complexly. Here we can introduce the actual functions of Fluent Operator through the example of outputting logs to elasticsearch and kafka in fluent-operator-walkthrough . To get some hands-on experience with the Fluent Operator, you need a Kind cluster. You also need to set up a Kafka cluster and an Elasticsearch cluster in this type of cluster.
# 创建一个 kind 的集群并命名为 fluent
./create-kind-cluster.sh
# 在 Kafka namespace 下创建一个 Kafka 集群
./deploy-kafka.sh
# 在 elastic namespace 下创建一个 Elasticsearch 集群
./deploy-es.shFluent Operator controls the life cycle of Fluent Bit and Fluentd. You can use the following script to start the Fluent Operator in the fluent namespace:
./deploy-fluent-operator.shBoth Fluent Bit and Fluentd have been defined as CRDs in Fluent Operator. You can create Fluent Bit DaemonSet or Fluentd StatefulSet by declaring the CR of FluentBit or Fluentd.
Fluent Bit Only mode
Fluent Bit Only will only enable the lightweight Fluent Bit to collect, process and forward logs.

Use Fluent Bit to collect kubelet logs and output to Elasticsearch
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: FluentBit
metadata:
name: fluent-bit
namespace: fluent
labels:
app.kubernetes.io/name: fluent-bit
spec:
image: kubesphere/fluent-bit:v1.8.11
positionDB:
hostPath:
path: /var/lib/fluent-bit/
resources:
requests:
cpu: 10m
memory: 25Mi
limits:
cpu: 500m
memory: 200Mi
fluentBitConfigName: fluent-bit-only-config
tolerations:
- operator: Exists
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFluentBitConfig
metadata:
name: fluent-bit-only-config
labels:
app.kubernetes.io/name: fluent-bit
spec:
service:
parsersFile: parsers.conf
inputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
filterSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
outputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: kubelet
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
systemd:
tag: service.kubelet
path: /var/log/journal
db: /fluent-bit/tail/kubelet.db
dbSync: Normal
systemdFilter:
- _SYSTEMD_UNIT=kubelet.service
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFilter
metadata:
name: systemd
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
match: service.*
filters:
- lua:
script:
key: systemd.lua
name: fluent-bit-lua
call: add_time
timeAsTable: true
---
apiVersion: v1
data:
systemd.lua: |
function add_time(tag, timestamp, record)
new_record = {}
timeStr = os.date("!*t", timestamp["sec"])
t = string.format("%4d-%02d-%02dT%02d:%02d:%02d.%sZ",
timeStr["year"], timeStr["month"], timeStr["day"],
timeStr["hour"], timeStr["min"], timeStr["sec"],
timestamp["nsec"])
kubernetes = {}
kubernetes["pod_name"] = record["_HOSTNAME"]
kubernetes["container_name"] = record["SYSLOG_IDENTIFIER"]
kubernetes["namespace_name"] = "kube-system"
new_record["time"] = t
new_record["log"] = record["MESSAGE"]
new_record["kubernetes"] = kubernetes
return 1, timestamp, new_record
end
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/component: operator
app.kubernetes.io/name: fluent-bit-lua
name: fluent-bit-lua
namespace: fluent
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: es
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
matchRegex: (?:kube|service)\.(.*)
es:
host: elasticsearch-master.elastic.svc
port: 9200
generateID: true
logstashPrefix: fluent-log-fb-only
logstashFormat: true
timeKey: "@timestamp"
EOFUse Fluent Bit to collect application logs of kubernetes and output to Kafka
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: FluentBit
metadata:
name: fluent-bit
namespace: fluent
labels:
app.kubernetes.io/name: fluent-bit
spec:
image: kubesphere/fluent-bit:v1.8.11
positionDB:
hostPath:
path: /var/lib/fluent-bit/
resources:
requests:
cpu: 10m
memory: 25Mi
limits:
cpu: 500m
memory: 200Mi
fluentBitConfigName: fluent-bit-config
tolerations:
- operator: Exists
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFluentBitConfig
metadata:
name: fluent-bit-config
labels:
app.kubernetes.io/name: fluent-bit
spec:
service:
parsersFile: parsers.conf
inputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
filterSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
outputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: tail
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
spec:
tail:
tag: kube.*
path: /var/log/containers/*.log
parser: docker
refreshIntervalSeconds: 10
memBufLimit: 5MB
skipLongLines: true
db: /fluent-bit/tail/pos.db
dbSync: Normal
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFilter
metadata:
name: kubernetes
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
spec:
match: kube.*
filters:
- kubernetes:
kubeURL: https://kubernetes.default.svc:443
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
labels: false
annotations: false
- nest:
operation: lift
nestedUnder: kubernetes
addPrefix: kubernetes_
- modify:
rules:
- remove: stream
- remove: kubernetes_pod_id
- remove: kubernetes_host
- remove: kubernetes_container_hash
- nest:
operation: nest
wildcard:
- kubernetes_*
nestUnder: kubernetes
removePrefix: kubernetes_
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: kafka
labels:
fluentbit.fluent.io/enabled: "false"
fluentbit.fluent.io/mode: "k8s"
spec:
matchRegex: (?:kube|service)\.(.*)
kafka:
brokers: my-cluster-kafka-bootstrap.kafka.svc:9091,my-cluster-kafka-bootstrap.kafka.svc:9092,my-cluster-kafka-bootstrap.kafka.svc:9093
topics: fluent-log
EOFFluent Bit + Fluentd mode
With Fluentd's rich set of plugins, Fluentd can act as a log aggregation layer to perform more advanced log processing. You can easily forward logs from Fluent Bit to Fluentd using the Fluent Operator.

Forward logs from Fluent Bit to Fluentd
To forward logs from Fluent Bit to Fluentd, you need to enable Fluent Bit's forward plugin as follows:
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: fluentd
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/component: logging
spec:
matchRegex: (?:kube|service)\.(.*)
forward:
host: fluentd.fluent.svc
port: 24224
EOFDeploy Fluentd
The Fluentd forward Input plugin is enabled by default when deploying Fluentd, so you only need to deploy the following yaml to deploy Fluentd:
apiVersion: fluentd.fluent.io/v1alpha1
kind: Fluentd
metadata:
name: fluentd
namespace: fluent
labels:
app.kubernetes.io/name: fluentd
spec:
globalInputs:
- forward:
bind: 0.0.0.0
port: 24224
replicas: 1
image: kubesphere/fluentd:v1.14.4
fluentdCfgSelector:
matchLabels:
config.fluentd.fluent.io/enabled: "true"ClusterFluentdConfig: Fluentd cluster-wide configuration
If you define ClusterFluentdConfig, then you can collect logs under any or all namespaces. We can select the namespace that needs to collect logs through the watchedNamespaces field. The following configuration is to collect logs under kube-system and default namespace:
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "cluster"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-es
labels:
output.fluentd.fluent.io/scope: "cluster"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-fd
EOFFluentdConfig: Fluentd namespace-wide configuration
If you define a FluentdConfig, then you can only send logs under the same namespace as the FluentdConfig to Output. In this way, logs under different namespaces are isolated.
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
outputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "namespace"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: namespace-fluentd-output-es
namespace: fluent
labels:
output.fluentd.fluent.io/scope: "namespace"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-namespace-fd
EOFRoute logs to different Kafka topics based on namespace
Similarly, you can use Fluentd's filter plugin to distribute logs to different topics according to different namespaces. Here we include the plug-in recordTransformer in the Fluentd core, which can add, delete, modify and check events.
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-kafka
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterFilterSelector:
matchLabels:
filter.fluentd.fluent.io/type: "k8s"
filter.fluentd.fluent.io/enabled: "true"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/type: "kafka"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFilter
metadata:
name: cluster-fluentd-filter-k8s
labels:
filter.fluentd.fluent.io/type: "k8s"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- recordTransformer:
enableRuby: true
records:
- key: kubernetes_ns
value: ${record["kubernetes"]["namespace_name"]}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-kafka
labels:
output.fluentd.fluent.io/type: "kafka"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- kafka:
brokers: my-cluster-kafka-bootstrap.default.svc:9091,my-cluster-kafka-bootstrap.default.svc:9092,my-cluster-kafka-bootstrap.default.svc:9093
useEventTime: true
topicKey: kubernetes_ns
EOFUse both cluster-wide and namespace-wide FluentdConfig
Of course, you can use both ClusterFluentdConfig and FluentdConfig as below. FluentdConfig will send the logs under the fluent namespace to ClusterOutput, and ClusterFluentdConfig will also send the namespaces under the watchedNamespaces field (that is, kube-system and default namespaces) to ClusterOutput.
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-hybrid
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config-hybrid
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-es-hybrid
labels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-hybrid-fd
EOFUsing both cluster-scoped and namespace-scoped FluentdConfig in multi-tenant scenarios
In a multi-tenant scenario, we can use both cluster-wide and namespace-wide FluentdConfig to achieve log isolation.
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config-user1
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
outputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-cluster-only
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- kubesphere-system
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/scope: "cluster-only"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: namespace-fluentd-output-user1
namespace: fluent
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-user1-fd
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-user1
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-user1-fd
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-cluster-only
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/scope: "cluster-only"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-only-fd
EOFUse buffers for Fluentd output
You can add a buffer to cache the output plugin's logs.
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-buffer
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterFilterSelector:
matchLabels:
filter.fluentd.fluent.io/type: "buffer"
filter.fluentd.fluent.io/enabled: "true"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/type: "buffer"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFilter
metadata:
name: cluster-fluentd-filter-buffer
labels:
filter.fluentd.fluent.io/type: "buffer"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- recordTransformer:
enableRuby: true
records:
- key: kubernetes_ns
value: ${record["kubernetes"]["namespace_name"]}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-buffer
labels:
output.fluentd.fluent.io/type: "buffer"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- stdout: {}
buffer:
type: file
path: /buffers/stdout.log
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-buffer-fd
buffer:
type: file
path: /buffers/es.log
EOFFluentd Only mode
You can also enable Fluentd Only mode, which will only deploy Fluentd statefulset.

Use Fluentd to receive logs from HTTP and output to standard output
If you want to enable the Fluentd plugin separately, you can receive logs via HTTP.
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: Fluentd
metadata:
name: fluentd-http
namespace: fluent
labels:
app.kubernetes.io/name: fluentd
spec:
globalInputs:
- http:
bind: 0.0.0.0
port: 9880
replicas: 1
image: kubesphere/fluentd:v1.14.4
fluentdCfgSelector:
matchLabels:
config.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: fluentd-only-config
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
filterSelector:
matchLabels:
filter.fluentd.fluent.io/mode: "fluentd-only"
filter.fluentd.fluent.io/enabled: "true"
outputSelector:
matchLabels:
output.fluentd.fluent.io/mode: "true"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Filter
metadata:
name: fluentd-only-filter
namespace: fluent
labels:
filter.fluentd.fluent.io/mode: "fluentd-only"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- stdout: {}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: fluentd-only-stdout
namespace: fluent
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- stdout: {}
EOFThis article is published by OpenWrite , a multi-post blog platform!




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。