
author
The Xingchen computing power team and the Xingchen computing power platform are based on in-depth optimization of cloud native unified access and multi-cloud scheduling, strengthening the isolation of container operation status, and mining the incremental value of technology. The platform carries Tencent's internal CPU and heterogeneous computing power services. Large-scale offline job, unified resource scheduling platform.
background
Origin of the problem
In recent years, with the continuous development of Tencent's internal self-developed cloud migration projects, more and more businesses have begun to use cloud native methods to host their own workloads, and the scale of container platforms has continued to increase. The cloud-native technology based on Kubernetes has greatly promoted the development of the cloud-native field and has become the de facto technical standard for major container platforms. In cloud-native scenarios, in order to maximize resource sharing, a single host often runs multiple computing tasks from different users. If there is no refined resource isolation in the host, multiple containers often compete fiercely for resources during peak hours of business load, which may lead to a sharp drop in program performance, mainly as follows:
- Frequent context switching times during resource scheduling
- CPU cache invalidation due to frequent process switching
Therefore, in cloud-native scenarios, it is necessary to impose fine-grained restrictions on container resource allocation to ensure that when the CPU utilization is high, there will be no fierce competition between containers, which will cause performance degradation.
Scheduling scene
The Tencent Xingchen computing power platform carries the company's CPU and GPU computing power services, and has a large number of various types of computing resources. At present, most of the key services carried by the platform deviate from the online scenarios. Under the increasing computing power demand of the business, it provides a steady stream of low-cost resources to continuously improve availability, service quality, and scheduling capabilities to cover more business scenarios. However, the native scheduling and resource binding functions of Kubernetes can no longer meet complex computing power scenarios, and more refined scheduling of resources is urgently needed, mainly as follows:
- Kubernetes native scheduler cannot perceive node resource topology information, resulting in Pod production failure
The kube-scheduler does not perceive the resource topology of the node during the scheduling process. After the kube-scheduler schedules the Pod to a node, if the kubelet finds that the node's resource topology affinity requirements cannot be met, it will refuse to produce the Pod. When a Pod is deployed through an external control loop (such as deployment), it will cause the Pod to be repeatedly created --> Scheduling --> An infinite loop of production failure.
- Changes in the actual number of CPU cores available to nodes due to the offline virtual machine-based co-location solution
Faced with the reality that the average utilization rate of cloud hosts running online services is low, in order to make full use of idle resources, offline virtual machines and online virtual machines can be mixed to meet the company's offline computing needs and improve the average utilization rate of self-developed cloud resources. In the case of ensuring that offline does not interfere with online business, Tencent Star Computing Power is based on the support of the self-developed kernel scheduler VMF, which can make full use of the idle resources on a machine to produce low-priority offline virtual machines. Due to the unfair scheduling policy of VMF, the actual number of available cores of the offline virtual machine is affected by the online virtual machine, which changes continuously with the busyness of the online business. Therefore, the number of CPU cores collected by the kubelet through the cadvisor in the offline host is not accurate, resulting in deviations in the scheduling information.
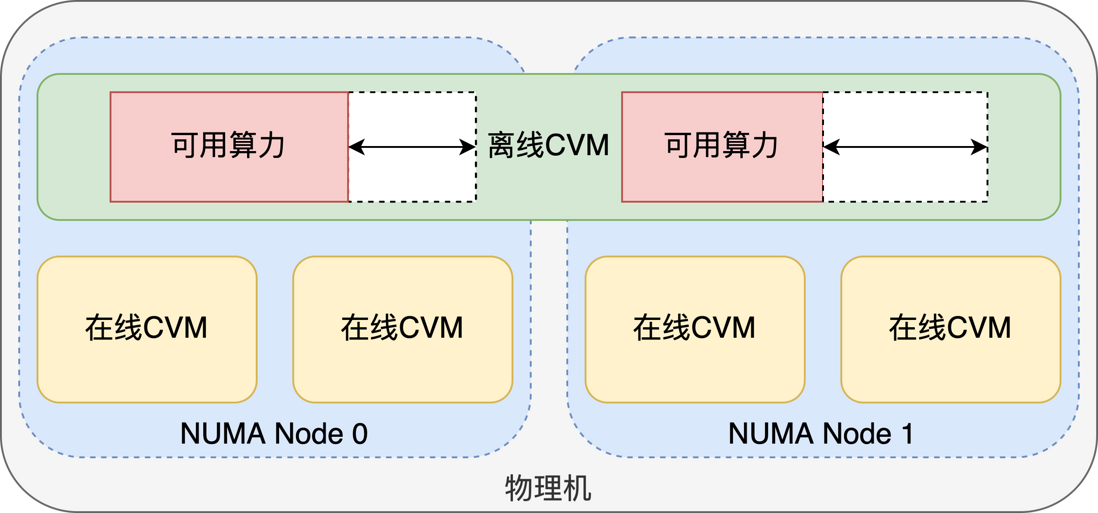
- Efficient utilization of resources requires more fine-grained scheduling granularity
The responsibility of the kube-scheduler is to select a suitable Node for the Pod to complete a scheduling. However, in order to use resources more efficiently, the functions of the native scheduler are far from enough. When scheduling, we hope that the scheduler can perform more fine-grained scheduling, such as being able to perceive the CPU core, GPU topology, network topology, etc., to make resource utilization more reasonable.
Preliminary knowledge
cpuset subsystem of cgroups
Cgroups is a mechanism provided by the Linux kernel that can limit the resources used by a single process or multiple processes, and can achieve fine-grained control over resources such as CPU and memory. Container technology under Linux mainly implements resource control through cgroups.
In cgroups, the cpuset subsystem can allocate independent CPU and memory nodes for processes in cgroups. By writing the CPU core number to the cpuset.cpus file in the cpuset subsystem or writing the memory NUMA number to the cpuset.mems file, you can restrict a process or a group of processes to use only a specific CPU or memory.
Fortunately, within the resource constraints of the container, we don't need to manually manipulate the cpuset subsystem. By connecting to the interface provided by the container runtime (CRI), it is possible to directly update the resource limits of the container.
// ContainerManager contains methods to manipulate containers managed by a
// container runtime. The methods are thread-safe.
type ContainerManager interface {
// ......
// UpdateContainerResources updates the cgroup resources for the container.
UpdateContainerResources(containerID string, resources *runtimeapi.LinuxContainerResources) error
// ......
}NUMA architecture
Non-uniform memory access architecture (NUMA) is a memory architecture designed for multiprocessor computers, where memory access time depends on the location of the memory relative to the processor. Under NUMA, a processor can access its own local memory somewhat faster than non-local memory (memory located on another processor, or memory shared between processors). Most modern multi-core servers use NUMA architecture to improve hardware scalability.
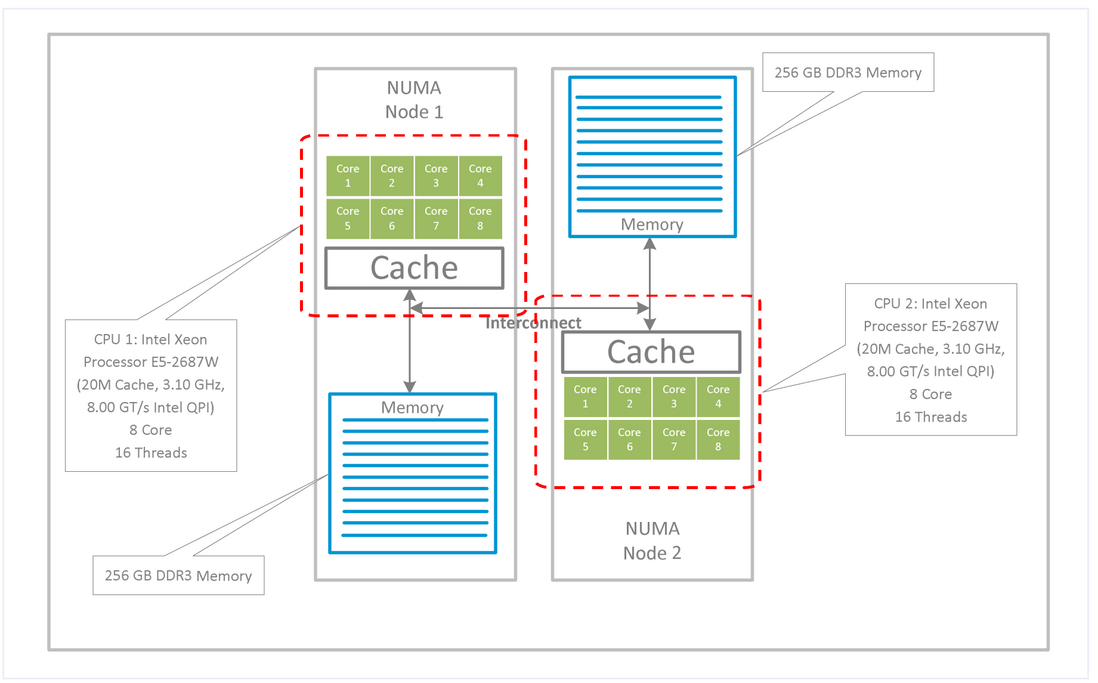
As can be seen from the figure, each NUMA Node has an independent CPU core, L3 cache and memory, and NUMA Nodes are connected to each other. CPUs on the same NUMA Node can share the L3 cache, and at the same time, accessing memory on this NUMA Node is faster, and accessing memory across NUMA Nodes is slower. Therefore, we should allocate CPU cores of the same NUMA Node for CPU-intensive applications to ensure that the local performance of the program is fully satisfied.
Kubernetes scheduling framework
Kubernetes has officially and stably supported the scheduling framework since v1.19. The scheduling framework is a plug-in architecture for the Kubernetes scheduler. It adds a new set of "plug-in" APIs to the existing scheduler, and the plug-in will be compiled into the scheduler. among. This is a boon for our custom scheduler. We can develop a custom extended scheduler without modifying the source code of kube-scheduler, by implementing different scheduling plugins and compiling the plugin code and kube-scheduler into the same executable file. Such flexible extension is convenient for us to develop and configure various scheduler plugins, and at the same time, without modifying the source code of kube-scheduler, the extended scheduler can quickly change dependencies and update to the latest community version.
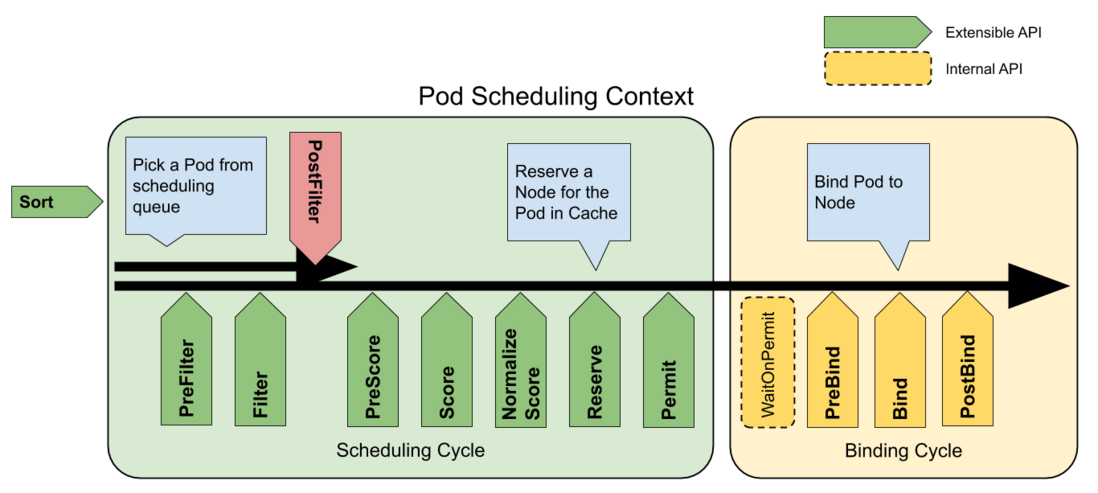
The main extension points of the scheduler are shown in the figure above. Our extended scheduler is mainly concerned with the following steps:
-
PreFilterandFilter
These two plugins are used to filter out nodes that cannot run the Pod. If any Filter plugin marks the node as infeasible, the node will not enter the candidate set and continue the subsequent scheduling process.
-
PreScore,ScoreandNormalizeScore
These three plugins are used to sort the nodes that pass the filtering phase, the scheduler will call each scoring plugin for each node, and the node with the highest score will be selected as the final scheduling result.
-
ReserveandUnreserve
This plugin is used to make some reservations for resources before the Pod is actually bound to the node to ensure the consistency of scheduling. If the binding fails, use Unreserve to release the reserved resources.
-
Bind
This plugin is used to bind Pods to nodes. The default binding plugin only specifies spec.nodeName for the node to complete the scheduling. If we need to extend the scheduler and add other scheduling result information, we need to disable the default Bind plugin and replace it with a custom Bind plugin.
Current status of technology research at home and abroad
At present, the Kubernetes community and the Volcano open source community have solutions related to topology awareness. Each solution has some similarities, but each has limitations and cannot meet the complex scenarios of star computing power.
Kubernetes community
The Kubernetes community scheduling interest group also has a solution for topology-aware scheduling. This solution is mainly led by RedHat. The scheduling method considering node topology is realized through the cooperation of scheduler-plugins and node-feature-discovery . The community method only considers whether the node can complete the screening and scoring of scheduling nodes under the condition that the kubelet configuration requirements are met, and does not perform core binding. The core binding operation is still left to kubelet to complete. The relevant proposals are here . The specific implementation scheme is as follows:
- The nfd-topology-updater on the node reports the node topology to the nfd-master through gRPC (period 60s).
- nfd-master updates node topology and assignment to CR (
NodeResourceTopology). - Extend kube-scheduler to consider NodeTopology when scheduling.
- The node kubelet completes the core binding work.
This solution has many problems and cannot solve the needs in production practice:
- The specific core allocation depends on the kubelet to complete, so the scheduler only considers the resource topology information, and does not select the topology, and the scheduler has no resource reservation. This results in that node scheduling and topology scheduling are not in the same link, which will cause data inconsistency.
- Since the specific core allocation relies on the kubelet to complete, the topology information of the scheduled Pod needs to be reported every 60s by the nfd-worker, which makes the topology discovery too slow and makes the data inconsistency problem more serious, see here .
- There is no distinction between pods that require topology affinity and common pods, which will easily lead to a waste of high-quality resources for nodes that enable topology functions.
Volcano Community
Volcano is a container batch computing engine that runs high-performance workloads on Kubernetes and is part of the CNCF incubation project. Enhanced in v1.4.0-Beta release with NUMA-aware features. Similar to the implementation of the Kubernetes community scheduling interest group, the real core binding is not implemented separately, and the functions that come with kubelet are directly used. The specific implementation scheme is as follows:
- resource-exporter is a DaemonSet deployed on each node, responsible for collecting node topology information and writing node information into CR (
Numatopology). - Volcano performs NUMA scheduling awareness when scheduling Pods according to the
Numatopologyof the node. - The node kubelet completes the core binding work.
The problems of this solution are basically similar to the implementation of the Kubernetes community scheduling interest group, and the specific core allocation relies on kubelet to complete. Although the scheduler tries its best to be consistent with the kubelet, inconsistencies still occur because of the inability to reserve resources, especially in high concurrency scenarios.
summary
Based on the analysis of the results of the research status at home and abroad, the open source community still hopes to hand over the node resource binding to kubelet, and the scheduler should try to ensure the consistency with kubelet. It can be understood that this is more in line with the direction of the community. Therefore, the typical implementation of each solution is not perfect, and cannot meet the computing power requirements of Tencent Star. In a complex production environment, we need a more robust and scalable solution. Therefore, we decided to start from the architectural advantages of each scheme, and explore a more powerful resource refinement scheduling enhancement scheme that fits the actual scene of Tencent Stars computing power.
problem analysis
Changes in the actual number of CPU cores available for offline virtual machine nodes
From Section 1.2, we can know that Tencent Star Hashpower uses a hybrid solution based on offline virtual machines, and the actual number of CPU cores available to the node will be affected by the peak value of online business and thus change. Therefore, the number of CPU cores collected by kubelet through cadvisor in the offline host is not accurate, and this value is a fixed value. Therefore, for offline resources, we need the scheduler to obtain the actual computing power of the node through other methods.

At present, neither scheduling nor core binding can reach the actual computing power of offline virtual machines, resulting in tasks being bound to NUMA nodes with severe online interference, and resource competition is very serious, which reduces the performance of tasks.
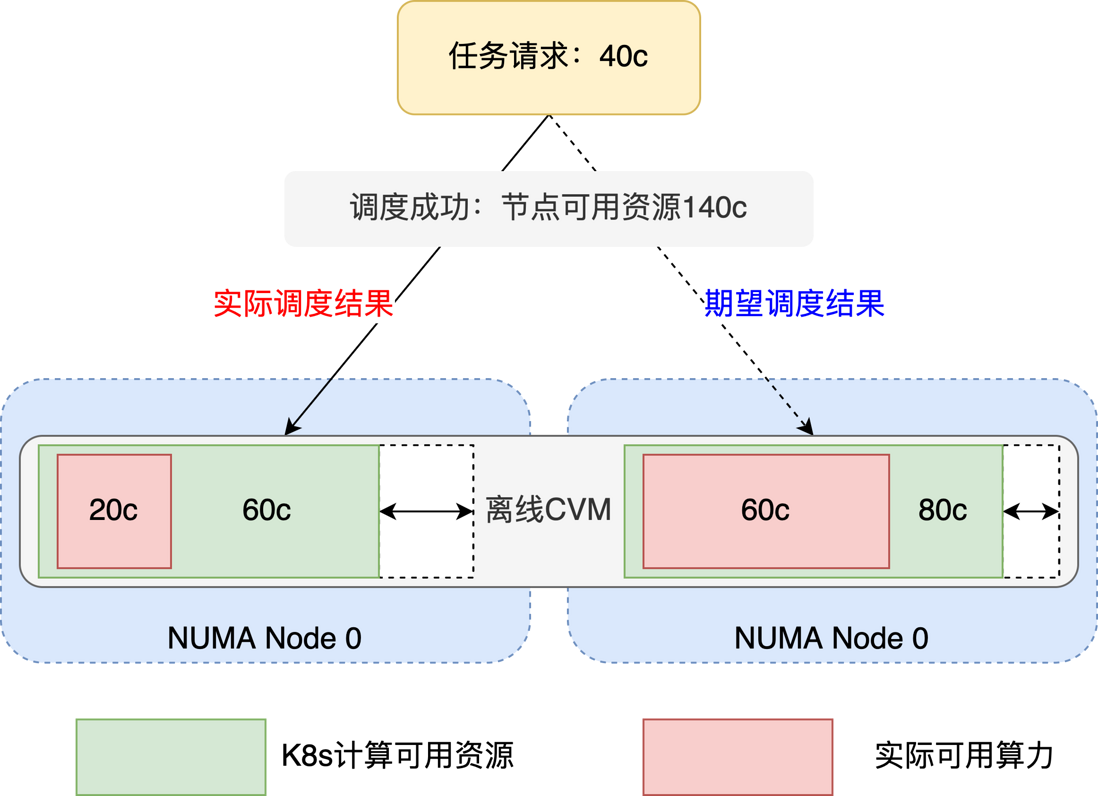
Fortunately, we can collect the actual CPU resource ratio on each NUMA node of the offline virtual machine on the physical machine, and calculate the actual computing power of the offline virtual machine through the discount formula. Next, it is only necessary for the scheduler to perceive the CPU topology and actual computing power when scheduling, so as to allocate.
Fine-grained scheduling requires greater flexibility
Core binding through kubelet cpumanager will always take effect on all Pods on the node. As long as the Pod meets the Guaranteed QoS conditions and the CPU request value is an integer, core binding will be performed. However, some Pods are not of high load type but monopolize the CPU. This method can easily lead to a waste of high-quality resources of the nodes that enable the topology function.
At the same time, for nodes of different resource types, the requirements for topology awareness are also different. For example, the resource pool of Xingchen Hashpower also contains many fragmented virtual machines. These nodes are not produced by co-location. In comparison, the resources are stable, but the specifications are small (such as 8-core CVM, each NUMA Node has 4 Nuclear). Since most task specifications will exceed 4 cores, such resources can be allocated across NUMA Nodes during use, otherwise it is difficult to match.
Therefore, topology-aware scheduling requires more flexibility to adapt to various core allocation and topology-aware scenarios.
Scheduling schemes need stronger scalability
The scheduler needs to consider scalability when abstracting topology resources. For extended resources that may need to be scheduled in the future, such as the scheduling of various heterogeneous resources, it can also be easily used in this solution, not just the resources contained in the cgroups subsystem.
Avoid CPU contention problems caused by hyperthreading
Hyperthreading may result in worse performance when competition for CPU cores is high. A more ideal allocation method is to allocate one logical core to high-load applications and another logical core to less busy applications, or to allocate two applications with opposite peak and valley times to the same physical core. At the same time, we avoid assigning the same application to two logical cores of the same physical core, which is likely to cause CPU contention issues.
solution
In order to fully solve the above problems, and taking into account the future scalability, we designed a set of refined scheduling scheme, named cassini . The whole solution consists of three components and a CRD, which work together to complete the fine-grained scheduling of resources.
Note: cassini The name comes from the well-known Saturn probe Cassini-Huygens, which has carried out accurate and accurate detection of Saturn, and uses this name to symbolize more accurate topology discovery and scheduling.
Overall architecture
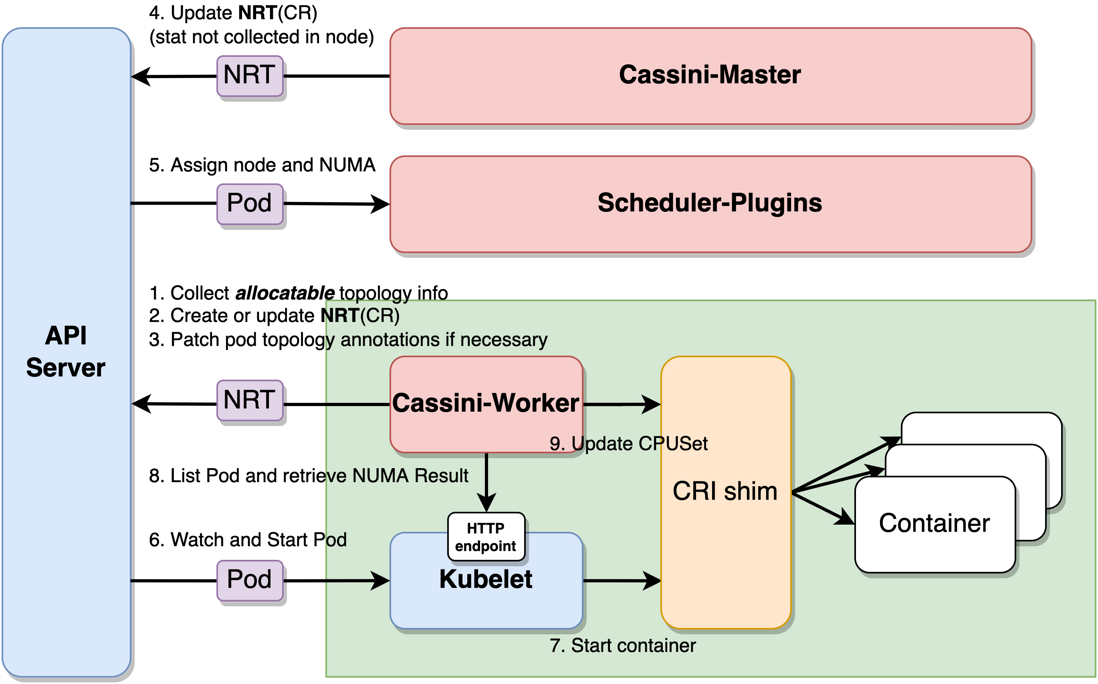
The responsibilities of each module are as follows:
-
cassini-worker: Responsible for collecting node resource topology, performing resource binding, and running on each node as DaemonSet. -
cassini-master: Responsible for collecting node characteristics (such as nodeoffline_capacity, node power status) from external systems, and running as a controller in Deployment mode. -
scheduler-plugins: The extended scheduler of the new scheduling plug-in replaces the native scheduler, and the topology scheduling results are also assigned when the nodes are bound, and run on each master node as a static Pod.
The overall scheduling process is as follows:
-
cassini-workerStart, collect topology resource information on the node. - Create or update a CR resource of type NodeResourceTopology (NRT) to record node topology information.
- Read the
cpu_manager_statefile of the kubelet, and patch the kubelet binding result of the existing container to the Pod annotations. -
cassini-masterUpdate the NRT object of the corresponding node according to the information obtained by the external system. - The extended scheduler
scheduler-pluginsexecutes Pod scheduling, perceives the node topology information according to the NRT object, and writes the topology scheduling structure to Pod annotations when scheduling Pods. - The node kubelet is listening and ready to start the Pod.
- The node kubelet calls the container runtime interface to start the container.
-
cassini-workerPeriodically visit port 10250 of the kubelet to list the Pods on the node and obtain the scheduler's topology scheduling results from the Pod annotations. -
cassini-workerCall the container runtime interface to change the core binding result of the container.
As a whole, it can be seen that cassini-worker collects more detailed resource topology information on the node, and ---19845b02cbb157bc4c06786b6dbdce32 cassini-master collects additional information about node resources from external systems. scheduler-plugins Extended the native scheduler to use these additional information as a decision basis for more refined scheduling, and write the results to Pod annotations. Finally, cassini-worker assumes the responsibility of the executor and is responsible for implementing the scheduler's resource topology scheduling result.
API Design
NodeResourceTopology (NRT) is a Kubernetes CRD used to abstractly describe node resource topology information. Here, we mainly refer to the design of the Kubernetes community scheduling interest group. Each Zone is used to describe an abstract topological area, ZoneType to describe its type, ResourceInfo to describe the total amount of resources in the Zone.
// Zone represents a resource topology zone, e.g. socket, node, die or core.
type Zone struct {
// Name represents the zone name.
// +required
Name string `json:"name" protobuf:"bytes,1,opt,name=name"`
// Type represents the zone type.
// +kubebuilder:validation:Enum=Node;Socket;Core
// +required
Type ZoneType `json:"type" protobuf:"bytes,2,opt,name=type"`
// Parent represents the name of parent zone.
// +optional
Parent string `json:"parent,omitempty" protobuf:"bytes,3,opt,name=parent"`
// Costs represents the cost between different zones.
// +optional
Costs CostList `json:"costs,omitempty" protobuf:"bytes,4,rep,name=costs"`
// Attributes represents zone attributes if any.
// +optional
Attributes map[string]string `json:"attributes,omitempty" protobuf:"bytes,5,rep,name=attributes"`
// Resources represents the resource info of the zone.
// +optional
Resources *ResourceInfo `json:"resources,omitempty" protobuf:"bytes,6,rep,name=resources"`
} Note that for stronger scalability, a Attributes is added to each Zone to describe the custom attributes on the Zone. As shown in Section 4.1, we write the collected actual computing power of offline virtual machines into the Attributes field to describe the actual computing power available to each NUMA Node.
Scheduler Design
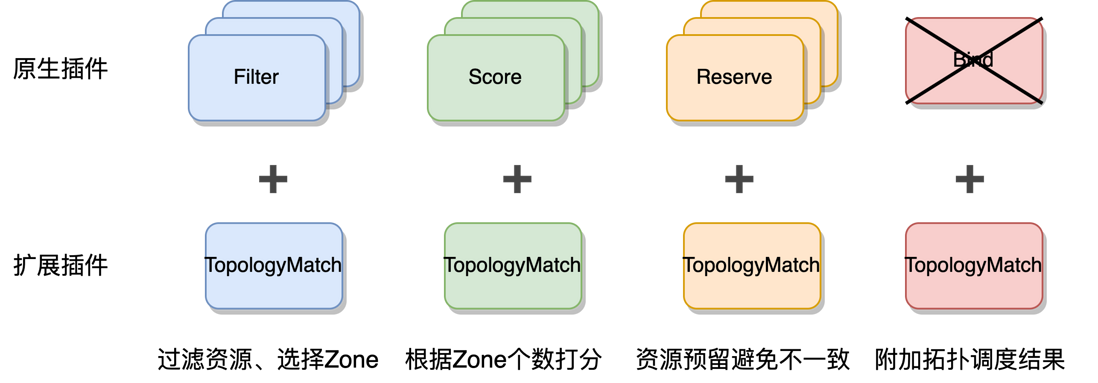
The extended scheduler extends new plugins based on the native scheduler, as follows:
-
Filter: Read NRT resources, filter nodes and select topology according to the actual available computing power in each topology and Pod topology awareness requirements. -
Score: Score according to the number of zones. The more zones, the lower the score (cross-zone will bring performance loss). -
Reserve: Make resource reservation before the actual binding to avoid data inconsistency. There is a similar assert function in the cache of kube-scheduler. -
Bind: Disable the default Bind plug-in, add the selection result of Zone when Bind, and add it to annotations.
The TopologyMatch plugin enables the scheduler to consider node topology information and perform topology assignment during scheduling, and attach the result to annotations through the Bind plugin.
It is worth mentioning that the scheduler plug-in for more dimension scheduling such as node power scheduling is additionally implemented here.
master design
cassini-master is the central control component, which collects resource information that cannot be collected on some nodes from outside. We physically collect the actual available computing power of offline virtual machines, and cassini-master is responsible for appending such results to the NRT resources of the corresponding nodes. This component strips the function of unified resource collection for easy updating and expansion.
worker design
cassini-worker is a more complex component that runs on each node as a DaemonSet. Its responsibilities are divided into two parts:
- Collect topology resources on nodes.
- Execute the topology scheduling result of the scheduler.
Resource collection
Resource topology collection mainly collects system-related hardware information from /sys/devices and creates or updates it to NRT resources. This component will watch the node kubelet configuration information and report it, so that the scheduler can perceive the node's kubelet core binding strategy, reserved resources and other information.
Since hardware information hardly changes, it will be collected and updated for a long time by default. However, the events configured by watch are real-time. Once the kubelet is configured, it will be sensed immediately, which is convenient for the scheduler to make different decisions according to the configuration of the node.
Topology scheduling result execution
The execution of topology scheduling results is to complete the topology allocation of the specified containers by periodically reconcile.
- Get Pod Information
In order to prevent cassini-worker of each node from causing pressure on kube-apiserver by watching kube-apiserver, cassini-worker use periodic access to port 10250 of kubelet to list the Pods on the node And get the scheduler's topology scheduling result from Pod annotations. At the same time, the ID and status of each container can also be obtained from the status, which creates conditions for the allocation of topology resources.
- Record CPU binding information for kubelet
When the kubelet enables CPU core binding, the extended scheduler will skip all TopologyMatch plugins. At this time, the topology scheduling results will not be included in the Pod annotations. After the kubelet completes the CPU core binding for the Pod, it will record the result in the cpu_manager_state file, cassini-worker read the file, and patch the kubelet binding result to the Pod annotations , for subsequent scheduling to make judgments.
- Record CPU binding information
According to the cpu_manager_state file and the Pod topology scheduling results obtained from annotations, generate its own cassini_cpu_manager_state file, which records the core binding results of all Pods on the node.
- Perform topology assignment
According to the cassini_cpu_manager_state file, call the container runtime interface to complete the final container core binding work.
Optimization Results
According to the above refined scheduling scheme, we have tested some online tasks. Previously, users reported that the computing performance of tasks scheduled to some nodes was poor, and they were frequently expelled due to the increase of steal_time . After replacing the solution with topology-aware scheduling, since topology-aware scheduling can fine-grainly perceive the offline actual computing power of each NUMA node ( offline_capacity ), the task will be scheduled to the appropriate NUMA node. , the training speed of the test task can be increased to 3 times of the original, which is equivalent to the time-consuming of the business in the high-quality CVM, and the training speed is relatively stable, and the resources are used more rationally.
At the same time, in the case of using the native scheduler, the scheduler cannot perceive the actual computing power of the offline virtual machine. When the task is scheduled to a node, the node steal_time will rise accordingly, and the task can't stand such a busy node, and the evictor will initiate pod eviction by the evictor. In this case, if the native scheduler is used, it will cause repeated eviction and then repeated scheduling, which will greatly affect the SLA. After the solution described in this article, the eviction rate of CPU preemption can be greatly reduced to the level of the physical machine.
Summary and Outlook
Starting from the actual business pain points, this paper first briefly introduces various background knowledge related to the business scenarios and refined scheduling of Tencent Star Computing Power, and then fully investigates the current research status at home and abroad, and finds that the various existing solutions have limitations. . Finally, the corresponding solutions are given after analyzing the pain points. After optimization, resources are used more reasonably, the training speed of the original test task can be increased to three times the original, and the eviction rate of CPU preemption is greatly reduced to the level of physical machines.
In the future, fine-grained scheduling will cover more scenarios, including the scheduling of GPU whole cards and fragmented cards under the GPU virtualization technology, the scheduling of high-performance network architectures, the scheduling of power resources, the support of overbooking scenarios, and the coordination of kernels. Scheduling is done together and so on.
about us
For more cases and knowledge about cloud native, you can pay attention to the public account of the same name [Tencent Cloud Native]~
Welfare:
① Reply to the [Manual] in the background of the official account, you can get the "Tencent Cloud Native Roadmap Manual" & "Tencent Cloud Native Best Practices"~
②The official account will reply to [series] in the background, and you can get "15 series of 100+ super practical cloud native original dry goods collection", including Kubernetes cost reduction and efficiency enhancement, K8s performance optimization practices, best practices and other series.
③If you reply to the [White Paper] in the background of the official account, you can get the "Tencent Cloud Container Security White Paper" & "The Source of Cost Reduction - Cloud Native Cost Management White Paper v1.0"
④ Reply to [Introduction to the Speed of Light] in the background of the official account, you can get a 50,000-word essence tutorial of Tencent Cloud experts, Prometheus and Grafana of the speed of light.
[Tencent Cloud Native] New products of Yunshuo, new techniques of Yunyan, new activities of Yunyou, and information of cloud appreciation, scan the code to follow the public account of the same name, and get more dry goods in time! !






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。