
Kubernetes 1.19.3
OS: CentOS 7.9.2009
Kernel: 5.4.94-1.el7.elrepo.x86_64
Docker: 20.10.6
Let's talk about the conclusion first, runc v1.0.0-rc93 has a bug, which will cause the docker hang to live.
problem found
Online alarms indicate that there are 2-3 K8s nodes in the cluster in the NotReady state, and the NotReady state persists.
- kubectl describe node, there are NotReady related events.

- After logging in to the problem machine, check the node load, everything is normal.
- Looking at the kubelet log, it is found that the PLEG time is too long, causing the node to be marked as NotReady.

- docker ps works fine.
- Execute ps to view the process and find that there are several runc init processes. runc is the OCI Runtime program called when containerd starts the container. The initial suspicion is that the docker hang has lived.

There are two ways to solve this problem, first look at the A scheme.
Solution A
In response to the phenomenon of docker hang living, after searching for information, I found that the following two articles also encountered similar problems:
- Troubleshooting docker hang [ https://www.likakuli.com/posts/docker-hang/ ]
- Docker hung problem analysis series (1): insufficient pipe capacity [ https://juejin.cn/post/6891559762320703495 ]
Both articles mentioned that the runc init is stuck in writing to the pipe due to insufficient pipe capacity, and the problem can be solved by releasing the restrictions of /proc/sys/fs/pipe-user-pages-soft.
Therefore, check that the /proc/sys/fs/pipe-user-pages-soft setting on the problem host is 16384. So magnify it 10 times and echo 163840 > /proc/sys/fs/pipe-user-pages-soft, but the kubelet still does not return to normal, the pleg error log continues, and the runc init program does not exit.
Considering that runc init is created by the kubelet calling the CRI interface, it may be necessary to exit runc init to make the kubelet exit. According to the instructions in the article, just read the contents of the corresponding pipe, and runc init can exit. Because reading the content of the pipe can use the principle of "UNIX/Linux everything is a file", check the handle information opened by runc init through lsof -p, get the number corresponding to the pipe of the write type (there may be more than one), and execute cat in sequence /proc/$pid/fd/$id, read the contents of the pipe. After a few tries, runc init really quit.
Check again, the node status is switched to Ready, the pleg error log has disappeared, and the node NotReady has not been observed for a day, and the problem is (temporarily) solved.
Questions about solution A
Although the problem is solved, but carefully read the documentation of the /proc/sys/fs/pipe-user-pages-soft parameter, it is not difficult to find that this parameter does not match the root cause of this problem.

pipe-user-pages-soft means that users who do not have CAP_SYS_RESOURCE CAP_SYS_ADMIN privileges limit the capacity of pipes to be used. By default, only 1024 pipes can be used at most, and the capacity of one pipe is 16k.
So here is the question:
- Components such as dockerd/containerd/kubelet are all run by the root user, and runc init is in the container initialization stage, theoretically, 1024 pipes will not be consumed. Therefore, pipe-user-pages-soft will not affect the problem of docker hang, but the problem disappears after the actual parameters are enlarged, and the explanation is inexplicable.
- The pipe capacity is fixed, and the user cannot declare the capacity when creating a pipe. From the online point of view, the pipe has indeed been built. If the capacity is fixed, it should not cause the problem of inability to write because the total amount of pipe used by users exceeds the limit of pipe-user-pages-soft. Is it because the capacity of the newly created pipe has become smaller, so that the data that can be written before cannot be written this time?
- At present, the pipe-user-pages-soft is enlarged by 10 times. Is it enough to enlarge 2 times? Which value is the most suitable value?
explore
The most direct way to locate the problem is to read the source code.
First look at the code related to the Linux kernel and pipe-user-pages-soft. The online kernel version is 5.4.94-1, switch to the corresponding version for retrieval.
static bool too_many_pipe_buffers_soft(unsigned long user_bufs)
{
unsigned long soft_limit = READ_ONCE(pipe_user_pages_soft);
return soft_limit && user_bufs > soft_limit;
}
struct pipe_inode_info *alloc_pipe_info(void)
{
...
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; // #define PIPE_DEF_BUFFERS 16
...
if (too_many_pipe_buffers_soft(user_bufs) && is_unprivileged_user()) {
user_bufs = account_pipe_buffers(user, pipe_bufs, 2);
pipe_bufs = 2;
}
if (too_many_pipe_buffers_hard(user_bufs) && is_unprivileged_user())
goto out_revert_acct;
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
...
}When creating a pipe, the kernel checks whether the current user-available pipe capacity is exceeded through too_many_pipe_buffers_soft. If it is found to be exceeded, the capacity size is adjusted from 16 PAGE_SIZE to 2 PAGE_SIZE. By executing getconf PAGESIZE on the machine, it can be obtained that PAGESIZE is 4096 bytes, that is to say, the pipe size is 164096 bytes under normal circumstances, but due to exceeding the limit, the pipe size is adjusted to 24096 bytes, which may cause the data to fail once The problem of writing into the pipe can basically verify the conjecture of problem 2.
So far, the logic related to pipe-user-pages-soft has been straightened out, which is relatively easy to understand.
Then, the question goes back to "why the pipe capacity of the root user of the container exceeds the limit".
100% recurrence
The first step in finding the root cause of a problem is often to reproduce the problem in an offline environment.
Since the online environment has been urgently repaired through scheme A, it is no longer possible to analyze the problem online, and it is necessary to find a must-have means.
The hard work paid off, the same problem was found in the issue, and it can be reproduced by the following methods.
https://github.com/containerd/containerd/issues/5261

echo 1 > /proc/sys/fs/pipe-user-pages-soft
while true; do docker run -itd --security-opt=no-new-privileges nginx; doneAfter executing the above command, runc init stuck immediately, which is consistent with the online phenomenon. Use lsof -p to view the file handles opened by runc init:

It can be seen that fd4, fd5, and fd6 are all pipe types, and the numbers of fd4 and fd6 are both 415841, which are the same pipe. So, how to get the pipe size to actually verify the conjecture in "Question 2"? There is no ready-made tool under Linux to obtain the pipe size, but the kernel has opened the system call fcntl (fd, F_GETPIPE_SZ) to obtain it. The code is as follows:
#include <unistd.h>
#include <errno.h>
#include <stdio.h>
// Must use Linux specific fcntl header.
#include </usr/include/linux/fcntl.h>
int main(int argc, char *argv[]) {
int fd = open(argv[1], O_RDONLY);
if (fd < 0) {
perror("open failed");
return 1;
}
long pipe_size = (long)fcntl(fd, F_GETPIPE_SZ);
if (pipe_size == -1) {
perror("get pipe size failed.");
}
printf("pipe size: %ld\\n", pipe_size);
close(fd);
}After compiling, check the pipe size as follows:
Focus on fd4 and fd6, the two handles correspond to the same pipe, and the obtained capacity size is 8192 = 2 PAGESIZE. So it is indeed because the pipe exceeds the soft limit that the pipe capacity is adjusted to 2 PAGESIZE.
After using solution A to solve the problem, let's look at solution B.
Solution B
https://github.com/opencontainers/runc/pull/2871

The bug was introduced in runc v1.0.0-rc93 and fixed in v1.0.0-rc94 with the PR above. So, how to fix it online? Do I need to upgrade all docker components?
If dockerd/containerd/runc and other components are upgraded, the business needs to be cut off before upgrading. The whole process is relatively complicated and the risk is high. And in this problem, only runc is in trouble, and only newly created containers are affected. Therefore, it is logical to consider whether it is possible to upgrade runc separately?

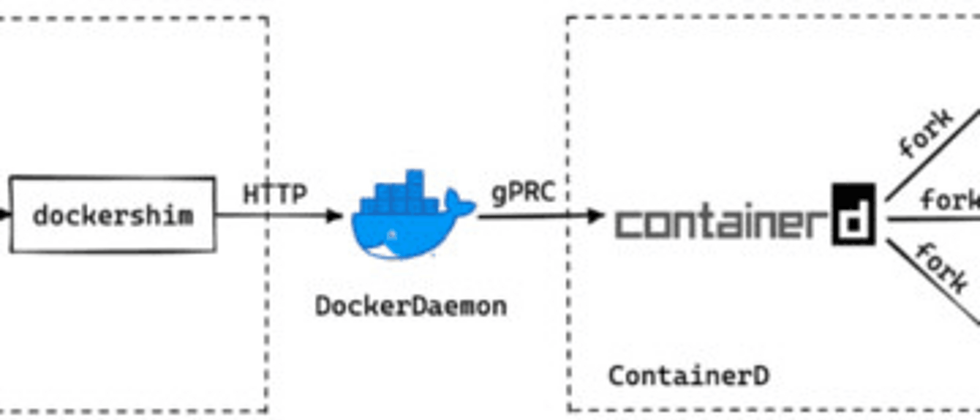
Because dockershim has not been deprecated in Kubernetes v1.19, the entire call chain for running a container is: kubelet → dockerd → containerd → containerd-shim → runc → container. Unlike dockerd/containerd, which is a server running in the background, containerd-shim calls runc, which actually calls the runc binary to start the container. Therefore, we just need to upgrade runc, and for newly created containers, the new version of runc will be used to run the container.
In the test environment, it is true that runc init does not get stuck. Finally, gradually upgrade the online runc to v1.1.1, and adjust /proc/sys/fs/pipe-user-pages-soft back to the original default value. The problem of runc hang living has been solved successfully.
analysis Summary
What did the PR fix?
The reason for the bug. When the container opens no-new-privileges, runc will need to unload a piece of bpf code that has been loaded, and then reload the patched bpf code. In the design of bpf, it is necessary to obtain the loaded bpf code first, and then use this code to call the unloading interface. When obtaining the bpf code, the kernel opens the seccomp_export_bpf function, and runc uses the pipe as the fd handle parameter to obtain the code. Since the seccomp_export_bpf function is synchronously blocked, the kernel will write the code into the fd handle. Therefore, if the pipe size is too small If the pipe data is full, the bpf code cannot be written and the situation will be stuck.
Solution in PR. Start a goroutine to read the contents of the pipe in time instead of waiting for the data to be written.
Why exceed the limit?
The container's root user UID is 0, and the host's root user UID is also 0. When the kernel counts pipe usage, it is considered to be the same user, and no distinction is made. Therefore, when runc init applies for a pipe, the kernel judges that the current user has no privileges, and queries the pipe usage of the user whose UID is 0. Since the kernel counts the sum of the pipe usage of all users with a UID of 0 (including those in the container), it has been Exceeded limit in /proc/sys/fs/pipe-user-pages-soft. The actual container root user pipe usage does not exceed the limit. This explains question 2 mentioned earlier.
So let's make a final summary. The reason for this failure is that the operating system has a soft limit on pipe-user-pages-soft, but since the UID of the container root user and the host are the same as 0, the kernel does not count pipe usage. To distinguish, the newly allocated pipe capacity will become smaller when the pipe usage of the user whose UID is 0 exceeds the soft limit. And runc 1.0.0-rc93 just because the pipe capacity is too small, the data cannot be completely written, the writing is blocked, and it has been waiting synchronously, and then runc init is stuck, the kubelet pleg status is abnormal, and the node is NotReady.
The repair solution, runc reads the pipe content in time through the goroutine to prevent write blocking.
References
https://iximiuz.com/en/posts/container-learning-path/
https://medium.com/@mccode/understanding-how-uid-and-gid-work-in-docker-containers-c37a01d01cf
https://man7.org/linux/man-pages/man7/pipe.7.html
https://gist.github.com/cyfdecyf/1ee981611050202d670c
https://github.com/containerd/containerd/issues/5261
https://github.com/opencontainers/runc/pull/2871
Recommended reading
The interviewer asked me whether Redis is single-threaded or multi-threaded.







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。