
Author: burness
Machine Learning Platform Infrastructure
Inside NetEase Cloud Music, the machine learning platform was mainly responsible for core business including music recommendation, main site search, and innovative algorithm business in the early days, and gradually covered content understanding business including audio and video, NLP, etc. The basic architecture of the machine learning platform is as follows. At present, I abstract it into four layers by function. This article will also describe in detail our specific work in each abstraction layer from these four aspects.

Resource Layer: Platform Core Capability Guarantee
It mainly provides the platform with resource guarantee and cost optimization capabilities. Resource guarantee covers various aspects including computing power, storage, communication, and tenants. For cost optimization, we currently use virtualization to provide dynamic allocation of resource pools. In addition, considering some For the sudden large computing power demand of the business, the resource layer can quickly and effectively obtain sufficient resources from other teams and the platform resource layer for business use. This chapter takes VK and Alibaba Cloud ECI as examples to briefly describe the work of the cloud music machine learning platform in the resource area:
Visual Kubelet Resources
At present, there are many resources within NetEase that belong to different clusters to be managed, and there are many k8s clusters. The Hangzhou Research Cloud Computing Team developed the kubeMiner NetEase unified scheduling system across kubernetes clusters, which can dynamically access the resources of other idle clusters. In the past period of time, the cloud music machine learning platform cooperated with cloud computing to flexibly schedule most of the CPU distributed related graph calculations, large-scale discrete and distributed training to vk resources, which can greatly increase the vk resources while ensuring vk resources. Simultaneously iterate the parallelism of the model to improve the efficiency of business iteration;
The platform's use of VK resources can be simply understood as the external cluster is virtualized as a virtual node in the k8s cluster, and the status of the virtual node is updated when the external cluster changes, so that it can directly use k8s' own scheduling capabilities to support Pod scheduling to external clusters. Scheduling across clusters.

The CPU computing tasks of the cloud music platform mainly include graph computing, large-scale discrete and distributed training, involving tfjob, mpijob, paddlepaddle several task types, and network communication is required between task copies, including cross-cluster execution of Pod Exec , the size of a single copy is about (4c~8c, 12G~20G); but due to insufficient computing resources, the number of copies of tasks and the parallelism of tasks that can be run at the same time are very low, so each training business needs to endure a long time of training and task execution wait. After accessing the VK, it can make full use of the idle computing power of some clusters, and complete the iteration of the training model in parallel with multiple copies and multiple tasks.
Alibaba Cloud ECI
CPU resources can be scheduled across clusters through kubeMiner, but basically the entire group is relatively nervous about GPU. In order to prevent certain GPU resources from being met at some point in the future. The machine learning platform supports the scheduling of Alibaba Cloud ECI, and schedules the corresponding GPU resources on our own machine learning platform in a similar way to VK. Users only need to select the corresponding Alibaba Cloud ECI resources to complete the elastic scheduling of Alibaba Cloud ECI. Currently, emergent services are used in related capabilities:


Bottom base layer: basic capabilities empower users
The underlying base layer is based on the ability to convert the resource layer, such as supporting big data basic capabilities through spark and hadoop, supporting real-time data processing capabilities through flink, and supporting resource scheduling capabilities for massive tasks through k8s+docker. Among them, we mainly talk about The use of ceph throughout the platform and some of our work in practical optimization.
Ceph
As a set of distributed storage referred to in the industry, Ceph is widely used in the business of machine learning platforms. For example, it provides the same set of file systems for development tasks and scheduling tasks, which is convenient for opening up the development and scheduling environment. The same file system is used in distributed tasks. Of course, access from 0 to 1 is often a functional requirement, and the existence of open source Ceph satisfies the goal. However, when more and more users start to use it, covering a variety of scenarios, there will be different needs. Here we summarize some points to be optimized by Ceph on the machine learning platform:
- Data security is the most important function of the machine learning platform. Although CephFS supports multi-copy storage, CephFS is powerless when there are behaviors such as accidental deletion; in order to prevent such accidents, CephFS is required to have a recycle bin function;
- The cluster has a large number of storage servers. If these servers use pure mechanical disks, the performance may not be sufficient. If they use pure SSDs, the cost may be relatively high. Therefore, it is expected to use SSDs as log disks and mechanical disks as data disks. Mixing logic, and make corresponding performance optimization based on this;
- As a unified development environment, with a large number of code compilation, log reading and writing, and sample download, CephFS requires both high throughput and fast processing of a large number of small files.
In response to these related problems, we, together with the group's Shufan storage team, have made more optimizations on Ceph:
Improvement 1: Design and implement an anti-missing system based on CephFS
The current CephFS native system does not have a recycle bin function, which means that once a user deletes a file, the file cannot be retrieved. As we all know, data is the most valuable intangible core asset of an enterprise and team. Once valuable data is damaged, it may be a disaster for an enterprise and team. In 2020, the data of a listed company was deleted by employees, causing its stock price to plummet and its market value to evaporate billions of Hong Kong dollars. What’s more, the trust of its partners dropped to freezing point, and its follow-up performance also suffered a huge blow.
Therefore, how to ensure the reliability of data is a key issue. However, CephFS, an open source star storage product, just lacks this link. The function of preventing accidental deletion has been put on the agenda as the focus of the joint construction project between Shufan storage team and cloud music. After the team's hard work, the anti-misdeletion function of the recycle bin was finally realized.
The newly developed recycling station initializes the trashbin directory in CephFS, and converts the user's unlink/rmdir request into a rename request through the backend, and the destination of the rename is the trashbin directory. It ensures the consistency and insensitivity of business usage habits. The Recycle Bin maintains a mechanism for regularly cleaning up overdue. For recovery, restore by building a directory tree of related files in the recycle bin, and then rename the files in the recycle bin to the target location.
Improvement 2: Performance optimization of hybrid storage systems
By observing and analyzing the io status of the machine learning platform for a long time, it is found that there are frequent short-term pressure surges. For users, the most important concerns are cost and AI task training time (storage IO delay is sensitive). At present: For users inside and outside the company, if they are users who pursue performance, the Shufan storage team provides a storage system based on all-flash disks; if they are users who pursue cost, the Shufan storage team provides a storage system based on all-mechanical disks. . Here we provide a storage system solution with both cost and performance,

This architecture is also one of the more commonly used architectures in the industry, but there is a problem that restricts the development of this co-located architecture, that is, using this architecture directly based on the native code of the Ceph community, the performance is only less than twice as good as that of a cluster with pure mechanical disks. Therefore, the Shufan storage team conducted in-depth analysis and transformation of the Ceph code, and finally overcome two key bottlenecks affecting performance: the heavy and time-consuming modules affecting the context and the heavy and time-consuming modules in the IO core path, as shown in the red icon below:
After the performance optimization of Shufan storage team, the performance of this co-located system has been significantly improved compared to the native version of the community. With sufficient resources, performance indicators such as IO latency and IOPS have been improved by seven or eight times. When it is insufficient and reaches the current limit, the performance is more than doubled.

Improvement 3: Design and implement all-round performance optimization based on CephFS
As a basic distributed storage, CephFS is simple and easy to use, but there are performance problems in many scenarios: for example, business code, data management, and source code compilation cause lag and high latency; for example, it takes time for users to delete massive data directories Very long, sometimes even several days; for example, the shared stuttering problem caused by the multi-user distributed writing model. These problems seriously affect the user experience. Therefore, the Shufan storage team has conducted in-depth research and improvement on performance issues. In addition to the performance optimization in the mixed disk scenario mentioned above, we have carried out performance optimization in CephFS metadata access and large file deletion.
- In terms of deletion of large directories: We have developed the function of asynchronous deletion of large directories: users often encounter situations in which large directories need to be deleted in their daily business. These directories typically contain tens of millions of files with a total capacity of several terabytes. Now the normal way for users is to use the rm -rf command under Linux. The whole process takes a long time, sometimes even more than 24 hours, which seriously affects the user experience. Therefore, users hope to provide a function to quickly delete the specified directory, and can accept the use of customized interfaces. Based on this, we have developed the function of asynchronous deletion of large directories, so that the deletion of large directories can be completed in seconds for users;
- In terms of large file IO: we have optimized the write performance of large files, so that the write bandwidth can be more than doubled, and the write latency can be more than doubled. The specific performance indicators are as follows;
- In terms of optimizing the user development environment git and make compilation, etc. are very slow: it is very slow for users to use git status in the container source directory, which takes more than tens of seconds. At the same time, the use of make compilation and other operations is also extremely slow. Based on this problem, Hangzhou The storage team has conducted a detailed analysis of the problem: through strace tracking the simple git status command, it is found that the process contains a large number of metadata operations such as stat, lstat, fstat, getdents, etc. The request delay of a single syscall is generally at the level of 100 us. However, after thousands of (for Ceph source code projects, about 4K) requests are superimposed, a delay of seconds is caused, which is obvious to users. Compared with the local file system (xfs, ext4) horizontally, the request delay of each syscall is usually an order of magnitude lower (ten us level), so the overall speed is much faster. Further analysis found that the delay is mainly consumed in the interaction between FUSE's kernel module and user mode. Even when the metadata is fully cached, the time consumption of each syscall is still an order of magnitude higher than that of the kernel-mode file system. Next, after the Shufan storage team converted user-mode services into kernel services, the performance was improved dozens of times, which solved the user's stuck experience;
- In terms of metadata request delay: The analysis found that the reason for the high delay of many user requests is the high delay of metadata requests such as open and stat. Therefore, based on this problem, we adopted the scheme of multiple data nodes, and finally made the metadata request. The average access delay can be more than doubled;
Application framework layer: tool capabilities covering most machine learning businesses
The application framework layer is mainly responsible for the framework capabilities used when the business is implemented, such as the well-known TensorFlow framework, distributed training task capabilities, large-scale graph neural network capabilities, etc. This chapter will focus on TensorFlow resource migration and large-scale graph neural networks. The job describes the work of the team:
TensorFlow and resource migration
Considering the lack of computing power resources, in 2021, we purchased a batch of new computing power, A100 machines, and encountered some problems:
Resources and Communities:
- New graphics cards such as A100 only support CUDA11, but official CUDA10 is not supported, while official TensorFlow only supports CUDA11 in the latest version 2.4 and above, and now TF1.X is used more for music, source code compilation cannot solve the cross-version problem, the Nvidia community only contributes to Nvidia -TensorFlow supports CUDA11;
- There is a big difference between TensorFlow versions, TF1.X and TF2.X, TF2.4.0 and below and TF2.4.0 above are very different;
- Community-related issues of TensorFlow1.X, such as environment and performance, are not officially supported by Google;
Music internal machine learning infrastructure:
- RTRS currently only supports TF1.14, currently for TF1.X, Google does not support CUDA11, Nvidia officially released Nvidia-TensorFlow1.15 to support, but this is not an official version, the internal code changes too much, the risk is high;
- For the current situation of Java jni model inference maintained in each business group, if you need to use new hardware for model training, you need to support at least the corresponding TF version of CUDA11 (above 2.4);
- Model training side code, the current version is between TF1.12-TF1.14;
Based on this background, we have completed the full-process support of the TF2.6 version of the machine learning platform, from sample reading and writing, model training, model online inference, and fully support TF2.6. The specific items include:
- The machine learning platform supports TF2.6 and Nvidia TF1.15 frameworks to adapt to Cuda11;
- Considering that the performance of a single A100 is extremely strong, its performance cannot be fully utilized in the model training of most businesses. Therefore, we choose to divide an A100 into smaller computing power units. If you need to know more about it, you can pay attention to the introduction of nvidia mig , which can greatly improve the overall throughput rate of the platform;
- The benefits of mig can greatly improve the overall throughput of the platform, but after the A100 is virtualized, the scheduling of graphics card instances and related monitoring are also more complicated tasks for the platform;
- After offline training is upgraded to a higher version, the inference framework also needs to be upgraded to ensure that the models generated by the frameworks compatible with TF1.x and TF2.x are compatible;
After completing the above matters, after completing the support of the A100 MIG capability, the overall training speed and the data after the inference transformation have greatly exceeded expectations. For offline tasks, we use 1/3 of the computing power of the new graphics card to be able to perform conventional tasks in the old version. In terms of computing power, the training speed has been improved by more than 40% on average, and the highest is improved by more than 170%. The online inference performance, by adapting to the 2.6 TensorFlow version, ensures that it is fully compatible with the online version of TF1. More than 20% inference performance improvement. On the A100 split instance, we currently provide three types of graphics card instances, 2g-10gb, 3g-20gb, and 4g-40gb, covering the daily task types of the platform. Other indicators such as stability greatly exceed the computing power of the old version.
Large Scale Graph Neural Networks
With the transformation from traditional music tool software to music content community, Cloud Music relies on the music master station business to derive a large number of innovative businesses, such as live broadcast, podcast, K-song, etc. Innovative business is both an opportunity and a challenge for recommendation algorithm students: users’ behavior in innovative business is sparse, and the phenomenon of cold start is obvious; even old business faces the following problems:
- How to effectively distribute content for new users;
- Effectively distribute new content to users;
Based on the Paddle Graph learning framework PGL, we use the site-wide user behavior data to construct the user's latent vector representation, describe the implicit relationship between users, and provide functions such as personalized recall, similarity mining, and lookalike; in practice, we have encountered Various difficult challenges:
- Difficulty 1: There are a variety of behavior objects and behavior types, and the amount of user behavior data is large, with nearly 500 million nodes (including users, songs, mlogs, podcasts, etc.), and the data scale of tens of billions of edges;
- Difficulty 2: Model training is difficult, and the model itself has a huge amount of parameters, which requires a lot of computing resources to ensure the training of the model;
- Difficulty 3: In the enterprise world, when implementing technologies such as graph neural networks, it is necessary to comprehensively consider costs and benefits. The costs mainly include two aspects: the cost of architectural transformation and the cost of computing resources;
In order to solve these difficulties, we have implemented the following specific technical solutions based on the NetEase Cloud Music machine learning platform:
- GraphService provides services similar to graph databases, based on massive weak terminal resources, provides giant graph storage and sampling services, and loads optimization strategies through giant graph data to meet different scale models and different sampling methods;
- Ultra-large-scale image storage and sampling is realized through k8s MPI-Operator, which is a necessary basic component to realize the usability and ease of use of general composition schemes;
- Integrate k8s TF-Operator and MPI-Operator to solve the problems of graph storage, sampling and distributed model calculation in distributed model training;
- The elastic expansion of computing and storage resources through k8s VK resources and cephfs The training process will consume a lot of computing and storage resources. After training, these resources will be idle. Dynamic expansion and shrinkage of storage resources can be realized through cephfs; idle computing resources such as virtual-kubelet are introduced into the machine. Learning platform to achieve elastic expansion, on-demand billing, and greatly reduce the training cost of large-scale distributed tasks;
Functional layer: the art of turning parts into wholes and parts into parts
The functional layer is mainly the machine learning platform as a machine learning infrastructure to support the entire life cycle of the entire machine learning process. In cloud music, a standard machine learning flow mainly includes four parts:
- data sample service;
- Feature operator development and configuration development;
- Model training and offline evaluation;
- Model service development and deployment, continuous update;
By integrating different systems of various parts covered in the machine learning flow, the end-to-end machine learning platform aims to provide support for various capabilities for algorithm development and related users more efficiently and conveniently. In addition to the core tasks, the machine learning platform will also abstract the capabilities of some stages to provide support for some components, including through model service, model sharing and other related work; the next step will be from the end-to-end machine learning platform and ModelZoo projects to share our work in this area:
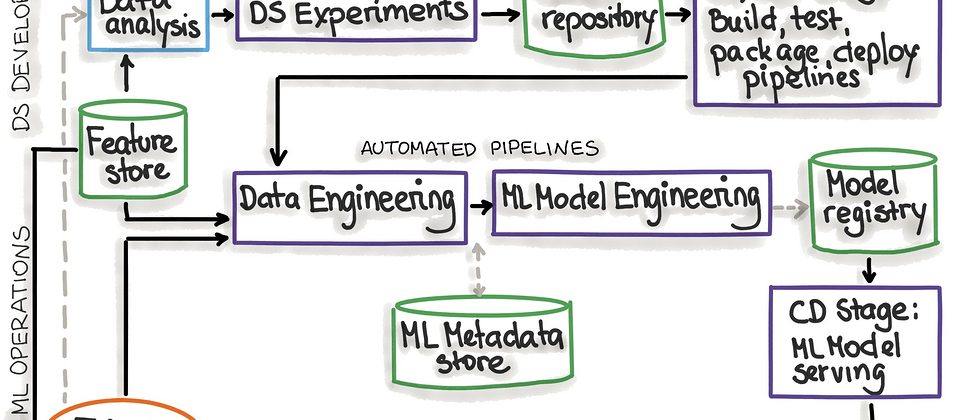
An end-to-end machine learning platform: turning parts into whole
The end-to-end machine learning platform abstracts a set of processes that can open up sample processing, feature access, online service development, code/data version control system, online service system push, and abtest system standardization processes through the machine learning platform. Correspondingly, it integrates each machine learning subsystem into the machine learning platform, and reuses core capabilities including containerization, system interconnection, elastic resources, and monitoring. The vision of the end-to-end machine learning platform is to provide a model-centric machine learning development paradigm. Through the metadata center, the relevant metadata of the entire life cycle is associated with the model tasks, and the entire machine learning is connected from the perspective of the model. stages of the life cycle. In order to achieve this goal, we have completed the corresponding work in the following aspects:

Sample service
Data sample collection and preprocessing mainly involve the connection of big data systems. In the early stage, there was no relevant system support for the development of data samples. Business students wrote Spark and Flink tasks themselves to perform sample collection, cleaning, and preprocessing. Therefore, the Unicom system only needs the machine learning platform itself to support the Unicom of user development sample tasks. The upstream of the music business mainly uses two parts of the data development platform: Mammoth and the self-developed Pandora and Magina. On the machine learning platform, it supports the task level In addition, considering the diversity of other tasks, we provide access to big data frameworks in each container and support basic frameworks such as Spark, Flink, and Hadoop.
After a period of iterations, we provided a standard FeatureStore by restricting the standard feature usage method, based on the NetEase Cloud Music-based storage suite Datahub. On this basis, the sample generation logic of the standardized business, users only need to modify a small part of the logic in the sample generation template to complete a standardized business sample service, providing users with real-time, offline sample generation capabilities.
Feature operator development and configuration development
Feature operator development and configuration development is a necessary process for a standard machine learning process, and it is also a relatively complex process. It is the pre-logic of the sample service. In Cloud Music, the online reasoning framework, or RTRS for short, abstracts a special feature processing module and provides users with the logic to develop feature operators and use feature operators to generate them.
Users configure existing operators or custom feature processing logic through feature calculation DSL voice during raw data processing, compile them into corresponding feature_extractor packages, use them in online services or sample services, and provide them for model engines and training tasks. Details You can pay attention to this article on the construction and practice of cloud music prediction system .

Model service development and deployment
At present, the core business of NetEase Cloud Music Online mainly uses the model service framework RTRS. The bottom layer of RTRS is developed based on C++, and the development of related applications in C++ has two troubles:
- Development environment: As we all know, machine learning related offline and online operating systems do not match. How to provide user model development and support service development in a more elegant way? The bottom layer of NetEase Cloud Music machine learning platform is based on K8S+docker, providing a customized operating system;
- Sharing of dependent libraries and frameworks: When developing rtrs services, some common dependencies need to be integrated in the environment, such as framework code, third-party dependent libraries, etc. The unified distributed storage provided by machine learning only needs to be mounted The specified public pvc can meet the relevant requirements;
The deployment of a model can be simply divided into two processes:
- Deployment of the first model: The part of the first model is relatively complex, involving processes such as online resource application, environment installation and configuration, and when the first model is deployed, the RTRS service framework needs to be pulled uniformly, and the business custom logic so package and Model, configuration, data files, providing basic model service capabilities;
- Model, configuration, data update: After the first model deployment, due to time drift, feature drift and various other reasons, we will collect enough training samples to retrain the model or update our configuration, dictionary and other data files. At this time, We usually do not republish model inference services, but dynamically update models, configurations, data files including dictionaries, etc.;
The machine learning platform adapts to RTRS model deployment and online service updates through standardized model push components.
Benefits of an end-to-end machine learning platform
Reduce user participation and improve efficiency <br>The end-to-end machine learning platform associates the main processes of the core business through models. Taking the model as the center perspective, it can effectively utilize the basic information of upstream and downstream, such as sample features, which can be Reuse the information of the feature schema generated in the sample service, reduce the development of the feature input part during model training and model inference, and greatly reduce the related development work. Through our experiments in some businesses, we can develop the business from zero. The process takes time from the week level to the day level.
Machine learning process visualization and lifecycle data tracking <br>The end-to-end machine learning platform manages the metadata of each stage in a unified manner through a unified metadata center, and provides machine learning process visualization capabilities: 

ModelZoo: rounded to zero
business background
The following figure is an illustration of the survey data on the time taken by the machine learning business models of various companies to go online. Most data scientists and algorithm engineers spend too much time on the model launch:

ModelZoo function layering
In line with our perception of the internal business of Cloud Music, in addition to the end-to-end standardized core business solutions we discussed earlier, some algorithm teams within Cloud Music will also have strong demand for some of these functional components. , such as our general model service, users want to build general models that can be used in actual scenarios through easy-to-use and efficient deployment. This is the origin of ModelZoo. On top of this, we hope that subsequent general models can be used in the process. Through retraining and fine-tuning, the deployed models that can be disclosed can be directly provided to business parties in need. The basic functions of the Model are layered as follows:

- Resource layer: The resource layer covers all task resources of the machine learning platform, including GPU, VK resources, and Alibaba Cloud ECI resources;
- Algorithm layer: Covers CV, NLP, and other capability modules that require general capabilities, such as faiss distributed capabilities;
- Delivery layer: It mainly includes two delivery methods: SDK and interface. The SDK module is used for the scenario use of the algorithm integration development process, and the interface is used in the scenario without algorithm integration. It provides user-defined model interface construction and interface service. and other core functions;
- Task layer: Provides core functions including reasoning, fine-tuning, and retraining, provided through SDK functions and interface functions;
ModelZoo progress
ModelZoo so far, our work is probably in the following aspects:
- Through the ability of K8S to support Serveless, you can use suitable mirrors such as TF Serving and TorchServe to provide general model services for models;
- Based on the machine learning platform, it is integrated in the model deployment component to provide the service of component deployment general model inference;
- With the components we deliver, users only need to deploy the corresponding service by specifying the model package (including some basic meta-information for deployment). If additional pre- and post-processing is required, custom pre- and post-processing logic in torchserve is also supported;
- In the image layer, by introducing the image compiled by mkl and adjusting the core parameters such as the number of session threads, rt is reduced by 30% in high qps scenarios;
- Investigating openvino and triton. Currently, there is no further investment because the business has met the needs and manpower needs. Those who have relevant experience are welcome to share;
Summarize
The above are some of the past work of the NetEase Cloud Music Machine Learning Platform. Looking back, we will share some related work and progress from the "resource layer", "underlying framework layer", "application framework layer" and "functional layer". Because the machine learning platform covers a wide range of areas, the work looks relatively messy, covering a variety of different technology stacks, and the challenges and goals of each work are different, which is still very interesting.
This article is published from the NetEase Cloud Music technical team, and any form of reprinting of the article is prohibited without authorization. We recruit all kinds of technical positions all year round. If you are ready to change jobs and happen to like cloud music, then join us at staff.musicrecruit@service.netease.com .







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。