

This year, the Meituan technical team has several papers included in KDD 2022. These papers cover many technical fields such as graph pre-training, selection algorithm, automatic intent discovery, effect modeling, policy learning, probability prediction, and reward framework. This article selects 7 papers for brief introduction (with download links), hoping to help or inspire students who are engaged in related research directions.
ACM SIGKDD International Conference (KDD for short) is the top annual conference in the field of data mining research sponsored by ACM's Data Mining and Knowledge Discovery Committee. It is a CCF A-class conference. Due to the interdisciplinary nature and wide application of KDD, its influence is also increasing, attracting research and development from statistics, machine learning, databases, the World Wide Web, bioinformatics, multimedia, natural language processing, human-computer interaction, social network computing, high-tech Practitioners and researchers in many fields such as performance computing and big data mining. The 28th KDD Conference 2022 will be held in Washington, USA from August 14th to 18th.
Paper 01: Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries
| Download : KG-Transformer
| The authors of the paper: Liu Xiao (Tsinghua University), Zhao Shiyu (Tsinghua University), Su Kai (Tsinghua University), Cen Yukuo (Meituan), Qiu Jiezhong (Tsinghua University), Dong Yuxiao (Tsinghua University), Zhang Mengdi (Meituan), Wuwei (Meituan), Tang Jie (Tsinghua University)
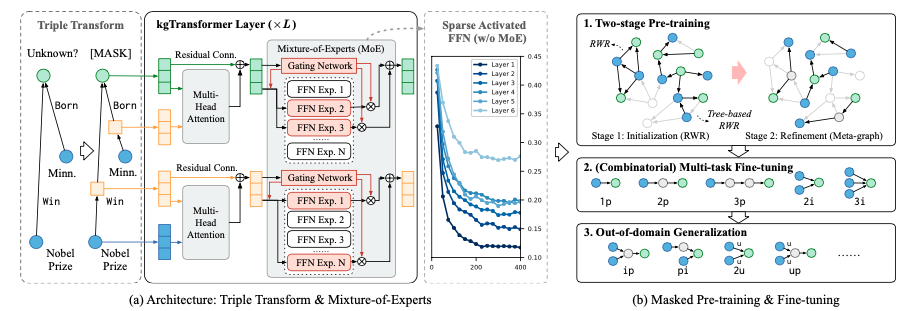
| Paper Introduction : Knowledge Graph Pre-training for Complex Logical Query. This paper studies the complex logical query problem in knowledge graph, discusses the inherent defects of mainstream reasoners based on knowledge graph embedding, and proposes a new graph neural network reasoner based on KGTransformer, and its corresponding pre-training and fine-tuning methods. KGTransformer achieves the best results on two major knowledge graph reasoning datasets, especially on out-of-domain tasks, which proves the broad prospects of this idea for knowledge graph reasoning.
Paper 02: AutoFAS: Automatic Feature and Architecture Selection for Pre-Ranking System
| Download : AutoFAS
| The authors of the paper: Li Xiang (Meituan), Zhou Xiaojiang (Meituan), Xiao Yao (Meituan), Huang Peihao (Meituan), Chen Dayao (Meituan), Chen Sheng (Meituan), Xian Yunsen (Meituan) )
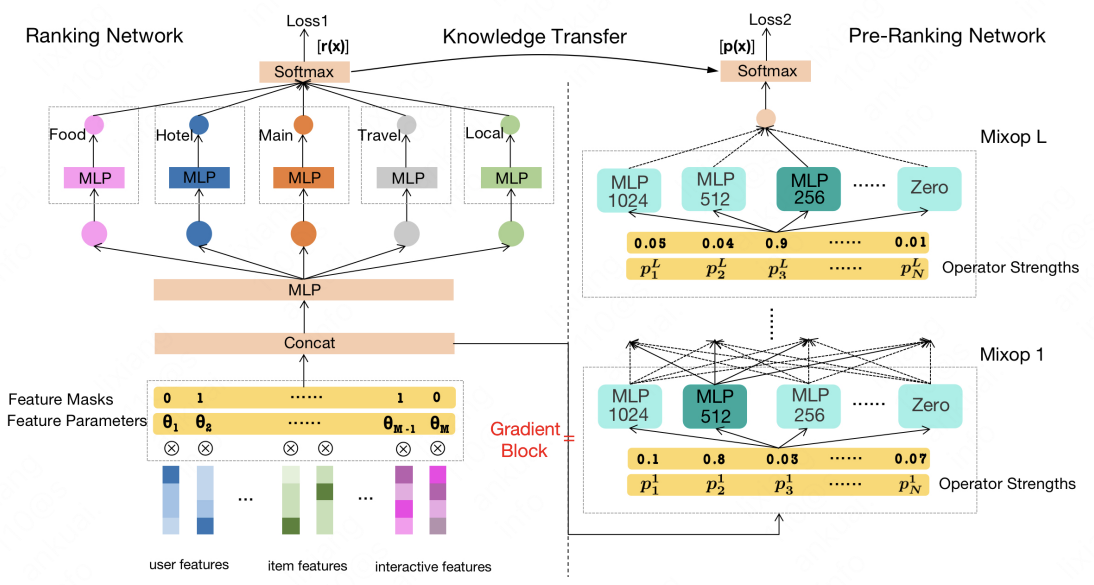
| Introduction to the paper : The industrial-level search recommendation system mainly follows the algorithm system of recall, rough sorting, fine sorting, and rearranging. In order to meet the huge scoring scale and strict delay requirements of rough row, the twin-tower model is still widely used. In order to improve the effect of the model, some schemes will additionally use the refined scoring knowledge for distillation. However, two major challenges remain to be addressed:
- If the delay is not really used as a variable in the model for joint optimization, the effect will be greatly reduced;
- If the scoring knowledge of fine ranking is distilled to a hand-designed coarse ranking structure, the performance of the model is definitely not optimal.
This paper uses the method of Neural Architecture Search, and innovatively proposes the algorithm framework of AutoFAS (Automatic Feature and Architecture Selection for Pre-Ranking System). Under the guidance of the knowledge of fine sorting and scoring, the optimal combination scheme of rough sorting features and structure is selected at the same time, which achieves the effect of SOTA. This solution has been fully used in the main search scenario of Meituan, and has achieved significant online improvement.
Paper 03: Automatically Discovering User Consumption Intents in Meituan
| Download : Automatically Discovering User Consumption Intents
| The authors of the paper: Li Yinfeng (Tsinghua University), Gao Chen (Tsinghua University), Du Xiaoyi (Meituan), Wei Huazhou (Meituan), Luo Hengliang (Meituan), Jin Depeng (Tsinghua University), Li Yong (Tsinghua University)
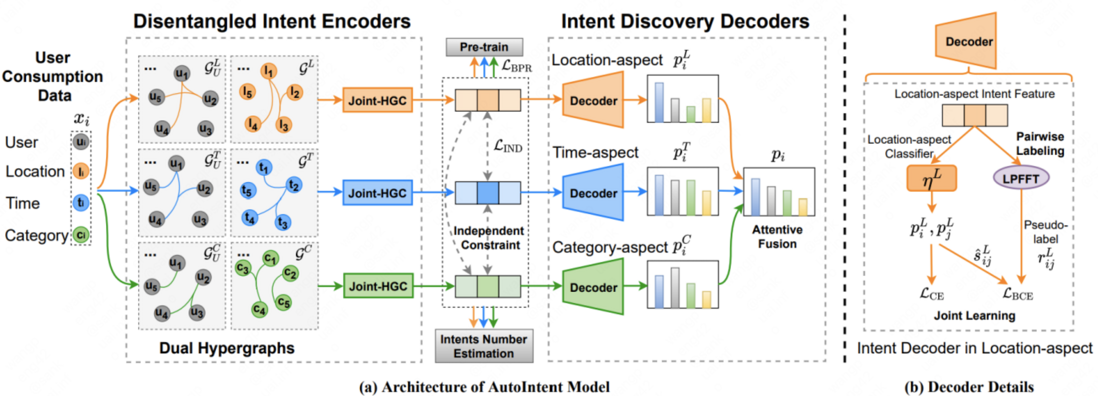
| Introduction to the paper : The consumer behavior of users in cities is often driven by specific intentions. Consumption intent, as the decision-making driving force of users' specific consumption behaviors, is crucial to improving the interpretability and accuracy of user behavior modeling in cities, and can be widely used in various business scenarios such as recommendation systems and precision marketing. However, consumption intentions are difficult to obtain, and only very limited types of intentions can be mined from user consumption data and comments. Therefore, automatically discovering new and unknown intentions from consumption data is a crucial but extremely challenging task, which mainly faces the following two key challenges: (1) How to encode consumption intentions under different types of preferences ; (2) How to realize the discovery of unknown intentions with only a small number of known intentions. In order to deal with the above challenges, this paper proposes an intent discovery model AutoIntent based on hypergraph neural network and semi-supervised learning (including a disentangled intent encoder and an intent discovery decoder) to realize automatic discovery of Meituan users' consumption intent.
Specifically, in the disentangled intent encoder, we construct three sets of dual hypergraphs to capture higher-order relationships under three different types of preferences (time-related, place-related, and intrinsic) The information dissemination mechanism on the network learns disentangled intent representations for users. In the intent discovery decoder, this paper constructs the pseudo-labels of paired samples based on the similarity of denoised intent representations, and realizes the knowledge transfer from known intents to unknown intents through semi-supervised learning to complete intent discovery. This paper compares with a variety of advanced benchmark algorithms on the large-scale industrial data set of Meituan. The experimental results show that the proposed AutoIntent method can achieve a significant performance improvement of more than 15% compared with the existing best solutions. Overall, this paper provides a new research idea for understanding and modeling user consumption behavior in cities.
Paper 04: Modeling Persuasion Factor of User Decision for Recommendation
| Download : Modeling the Effect of Persuasion Factor
| The authors of the paper: Liu Chang (Tsinghua University), Yuan Yuan (Tsinghua University), Gao Chen (Tsinghua University), Bai Chen (Meituan), Luo Lingrui (Meituan), Du Xiaoyi (Meituan), Shi Xinlei (Meituan), Luo Hengliang (Meituan), Jin Depeng (Tsinghua University), Li Yong (Tsinghua University)

| Introduction to the paper : In real urban life, for actual needs such as catering and travel, users will make decisions based on factors such as brand and price. Existing recommender systems often model these factors in a "black box" form, failing to answer the scientific question of how specific decision factors affect users' decision-making behavior, resulting in limited recommendation performance. Based on real-world catering consumption and travel data, this paper uses user interaction behavior data and persuasive copy data corresponding to different factors to explicitly model the impact of various factors on user decision-making to improve the accuracy and interpretability of the recommendation system.
Specifically, a user-item interaction graph is first constructed, and different categories of persuasive copy are used as heterogeneous edges in the graph, and a multi-layer graph convolutional network is used to generate the representation of users, items and copy; The sensitivity of copywriting is different. In the process of interactive probability prediction, adaptive modeling is carried out for each user's sensitivity to improve the prediction confidence. Furthermore, in order to solve the ubiquitous problem of sparseness of user interaction records, a data enhancement method based on counterfactual inference is proposed, which reasonably generates a large amount of high-quality data, which effectively assists the process of representation learning and achieves accurate recommendation. Compared with various advanced benchmark algorithms on the large-scale business data set of Meituan, this paper has achieved significant performance improvement; further analysis shows that the proposed model can effectively express users' preferences for different factors, and at the same time accurately model different users behavioral differences. Overall, this paper provides a basis for studying the interpretable mechanisms of user decision-making behavior in cities.
Paper 05: Practical Counterfactual Policy Learning for Top-K Recommendations
| Download : Counterfactual_Top-K/xcf
| The authors of the paper: Liu Yaxu (National Taiwan University & Meituan intern), Yan Ruinan (National Taiwan University), Yuan Bowen (National Taiwan University & Meituan intern), Shi Rundong (Meituan), Yan Peng (Meituan), Lin Zhiren (Taiwan the University)
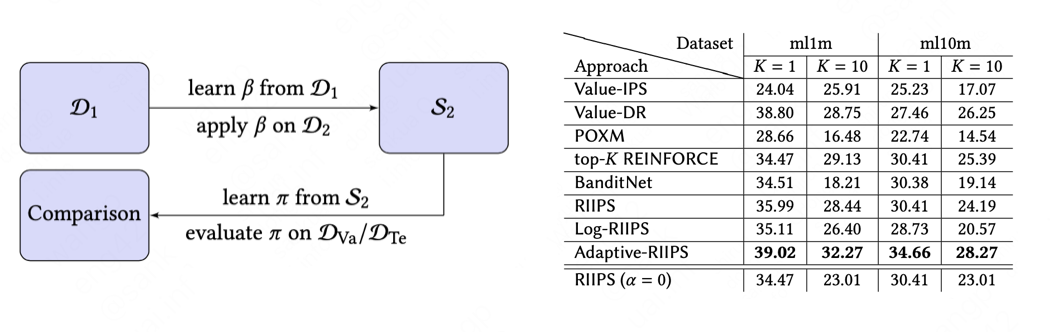
| Paper Introduction : For training a machine learning model, a key task is to construct training data from the feedback collected (e.g., ratings, clicks). However, it can be found from theoretical and practical experience that the selection bias in the collected feedback can lead to a biased model obtained by training, resulting in the training result being not the optimal policy. To solve this problem, counterfactual learning has received a lot of attention, and existing counterfactual learning methods can be divided into Value Learning methods and Policy Learning methods.
This paper studies the Policy Learning method of the Top-𝐾 ranking model with a larger decision space, and proposes a practical learning framework to solve the Importance Weight explosion in the learning of a larger decision space, less samples lead to larger variance, and training low efficiency, etc. Experiments on open source data verify the effectiveness and efficiency of the proposed framework.
Paper 06: Applying Deep Learning Based Probabilistic Forecasting to Food Preparation Time for On-Demand Delivery Service
| Download : Applying Deep Learning
| The authors of the paper: Gao Chengliang (Meituan), Zhang Fan (Meituan), Zhou Yue (Meituan), Feng Ronggen (Meituan), Ru Qiang (Meituan), Bian Kaigui (Peking University), He Renqing (Meituan) Mission), Sun Zhizhao (Meituan)

| Introduction to the paper : In the instant delivery system, the accurate estimation of the order time for the merchant to deliver the meal is very valuable to both the user and the rider experience. There are two main technical challenges in this problem, namely, incomplete sample labels (some orders only have the approximate range of meal time) and large data uncertainty, which are difficult to deal with by conventional point estimation regression methods.
In this work, probability estimation is used for the first time to characterize the uncertainty of order meal time, and a non-parametric method based on deep learning is proposed, and the data samples of range labels are fully utilized in feature construction and model design. In probability estimation, this paper proposes the S-QL loss function and proves its mathematical relationship with S-CRPS, based on which the quantile discretization of S-CRPS is performed to optimize the model parameters. Based on real delivery data evaluation and online A/B experiments, the advantages and effectiveness of this method have been proved.
Paper 07: A Framework for Multi-stage Bonus Allocation in Meal Delivery Platform
| Download : A Framework for Multi-stage Bonus Allocation
| The authors of the paper: Wu Zhuolin (Meituan), Huang Fangsheng (Meituan), Zhou Linjun (Meituan), Song Yu (Meituan), Ye Chengpeng (Meituan), Nie Pengyu (Meituan), Ren Hao (Meituan), Hao Jinghua (Meituan) Meituan), He Renqing (Meituan), Sun Zhizhao (Meituan)
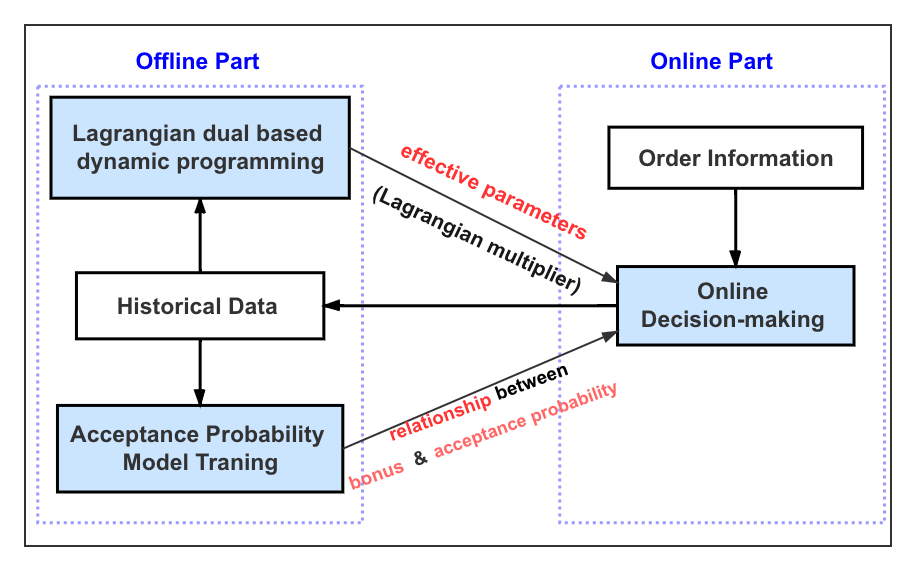
| Introduction to the paper : Meituan delivery aims to provide customers and restaurants with high-quality and stable services, but hundreds of thousands of orders are still cancelled every day because no one takes the order. The cancellation of orders has caused great damage to the user experience and the reputation of Meituan damage. To solve this problem, Meituan provided a special fund to improve the user experience of tail orders. Orders that have not been picked up will continue to be exposed to riders, so we need to continuously decide on the amount of additional rewards for orders until the order is cancelled or taken. Since the incentive scheme at the last moment of the order will significantly affect the probability of the existence and cancellation of the order in the subsequent stages, this problem is a complex multi-stage sequential decision-making problem. In order to better enhance the user experience, we propose a new framework to solve this problem. This framework consists of three parts:
- Semi-parameterized order completion probability and cancellation probability model;
- A dynamic programming algorithm based on Lagrangian duality;
- Online real-time allocation algorithm.
The semi-parameterized order completion (cancellation) probability model is used to predict the relationship between the reward amount allocated to the order and the probability of the order being picked up and finally completed (cancelled) at this moment. The Lagrangian dual dynamic programming algorithm mainly uses The historical order data calculates the Lagrangian multiplier solution for each allocation sequence, and the online allocation algorithm uses the results obtained in the offline part to calculate the corresponding incentive scheme for each order. We conducted A/B experiments on real delivery scenarios. The experimental results show that the new algorithm reduces the number of cancelled orders by 25% compared with the baseline algorithm, which significantly improves the user experience.
write on the back
The above papers are the results of the joint cooperation between the technical team of Meituan and various universities and scientific research institutions. This paper mainly introduces some scientific research work of Meituan in the technical fields of graph pre-training, selection algorithm, automatic intention discovery, effect modeling, policy learning, probability prediction, and reward framework. I hope it can be helpful or enlightening to you, and you are also welcome to communicate with us.
Read more collections of technical articles from the Meituan technical team
Frontend | Algorithm | Backend | Data | Security | O&M | iOS | Android | Testing
| Reply keywords such as [2021 stock], [2020 stock], [2019 stock], [2018 stock], [2017 stock] in the public account menu bar dialog box, you can view the collection of technical articles by the Meituan technical team over the years.

| This article is produced by Meituan technical team, and the copyright belongs to Meituan. Welcome to reprint or use the content of this article for non-commercial purposes such as sharing and communication, please indicate "The content is reproduced from the Meituan technical team". This article may not be reproduced or used commercially without permission. For any commercial activities, please send an email to tech@meituan.com to apply for authorization.





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。