

关注「Shopee技术团队」公众号👆,探索更多Shopee技术实践
目录
1. Shopee 数据系统建设中面临的典型问题
2. 为什么选择 Hudi
3. Shopee 在 Hudi 落地过程中的实践
4. 社区贡献
5. 总结与展望LakeHouse, as an important development direction in the field of big data, provides a new scenario of stream-batch integration and lake-warehouse integration. At present, problems such as data timeliness, accuracy, and storage costs that enterprises will encounter in many businesses can be solved through the integrated lake and warehouse solution.
At present, several mainstream lake and warehouse integrated open source solutions are under continuous iterative development, and applications in the industry are also moving forward in exploration. In actual use, it is inevitable to encounter some imperfections and unsupported features. Shopee has customized its own version based on the open source Apache Hudi in the process of use to realize enterprise-level applications and some new features for internal business needs.
Through the introduction of Hudi's Data lake solution, the data processing process of Shopee's Data Mart, Recommendation, ShopeeVideo and other products has realized the features of stream-batch integration and incremental processing, which greatly simplifies this process and improves performance.
1. Typical problems faced in the construction of Shopee data system
1.1 Introduction to Shopee Data System

The picture above is an overall solution provided by the Shopee Data Infrastructure team for the company's internal business side.
- The first step is data integration. At present, we provide data integration methods based on log data, databases and business event streams;
- Then, it is loaded into the data warehouse of the business through the ETL (Extract Transform Load) service of the platform, and the business students process the data through the development platform and computing services provided by us;
- The final result data is displayed through the Dashboard, the real-time query engine is used for data exploration, or it is fed back to the business system through the data service.
Let's first analyze three typical problems encountered in the construction of Shopee data system.
1.2 Stream-Batch Integrated Data Integration
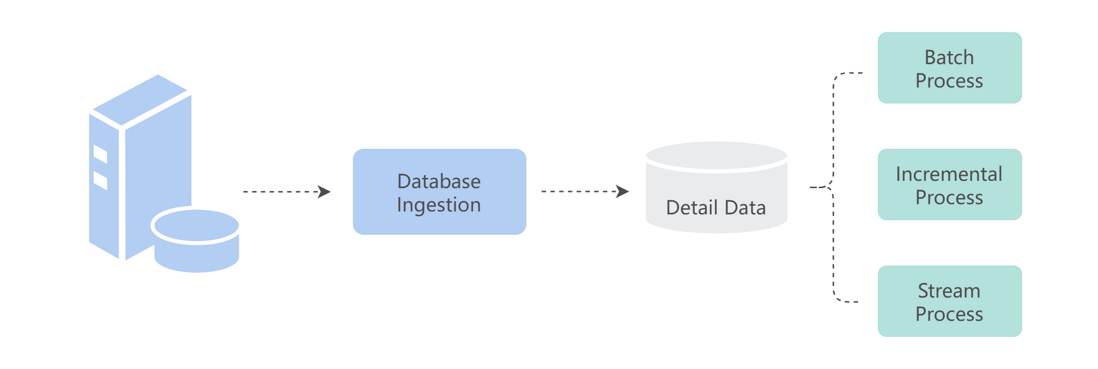
The first problem : In the process of database-based data integration, there is a need for both stream processing and batch processing for the same piece of data. The traditional approach is to implement two links of full export and CDC. The full export link meets the needs of batch processing, and the CDC link is used for real-time processing and incremental processing scenarios.
However, one problem with this approach is the low efficiency of full export, resulting in high database load . In addition, data consistency is also difficult to guarantee .
At the same time, there is a certain storage efficiency optimization in the construction of batch data sets, so we hope to build batch data sets based on CDC data to meet the needs of three processing scenarios at the same time and improve data timeliness.
1.3 Status indicates fine storage
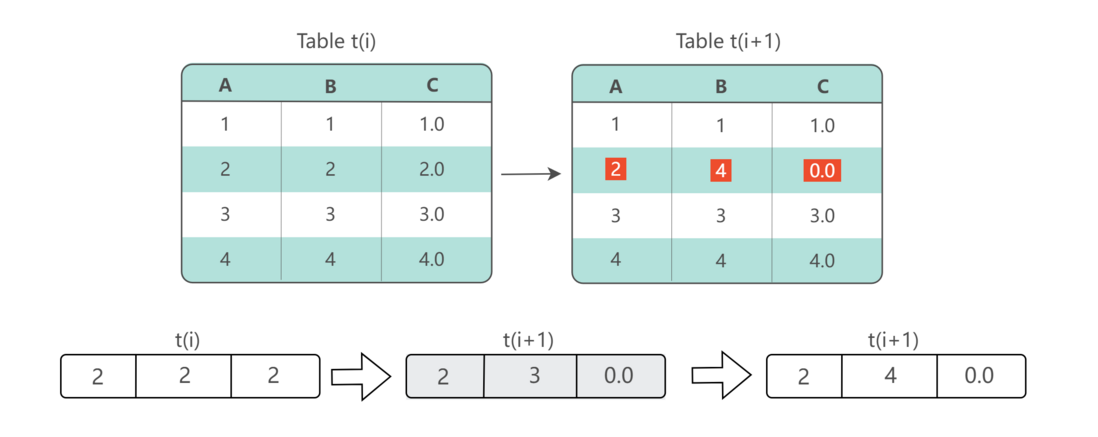
The second problem is that the state indicates fine storage . We can think that the traditional batch data set is a snapshot of the overall state of the business data at a certain point in time, and the snapshot compressed to a point will merge the process information in the business process. These change processes reflect the process of users using our services and are very important objects of analysis. Once merged, it cannot be expanded.
In addition, in many scenarios, the part of business data that changes every day only accounts for a small part of the full amount of data, and storing the full amount of each batch will bring about a great waste of resources.
1.4 Create a large wide table
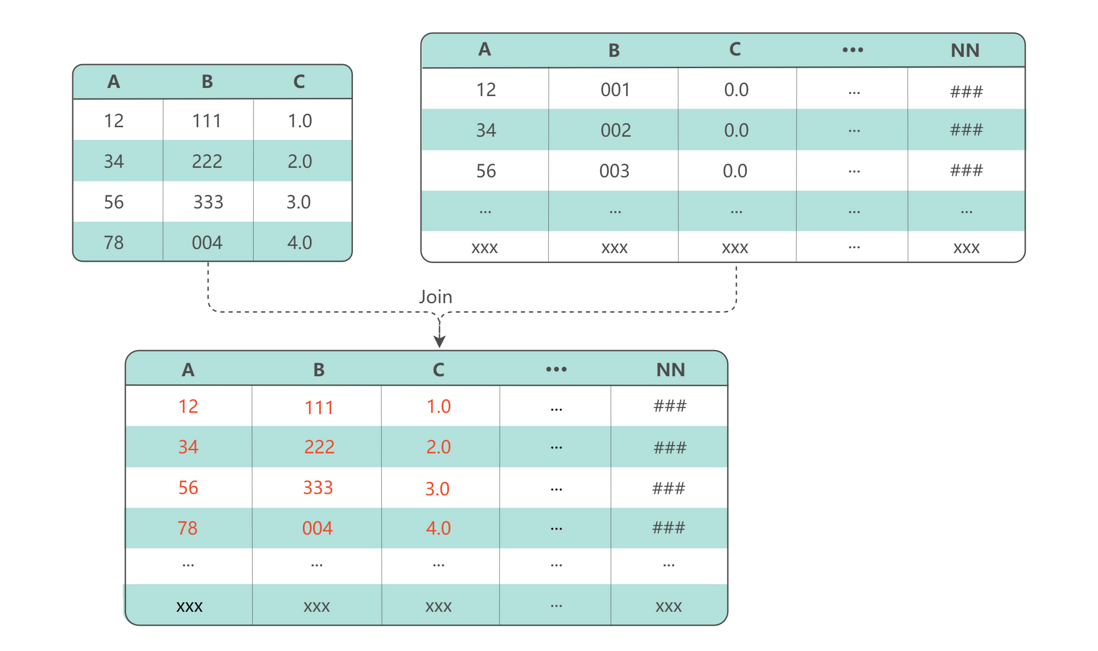
The third problem is the creation of large wide tables . Near real-time wide table construction is a common scenario in data processing. The problem is that the traditional batch processing delay is too high, and the use of streaming computing engines is a serious waste of resources. Therefore, we built a business wide table based on multiple data sets to support ad hoc-like OLAP queries.
2. Why choose Hudi
In view of the problems encountered in the above business, based on the following three considerations, we finally chose Apache Hudi as the solution.
2.1 Rich ecological support
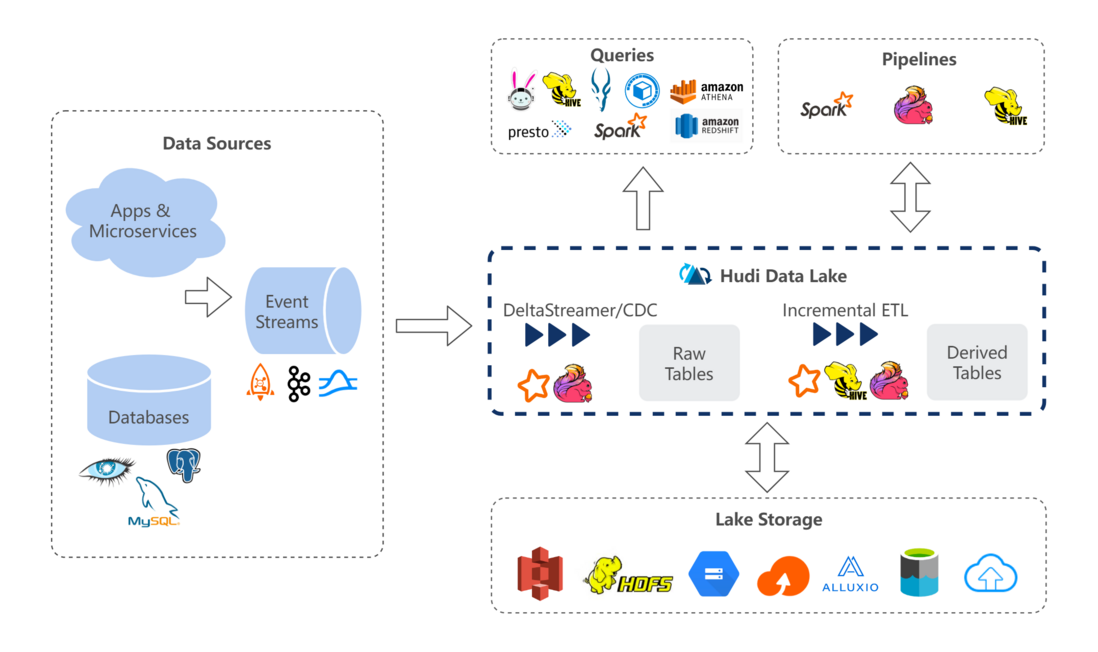
We expect to use a pure streaming approach to build a data integration environment, and Hudi has good support for streaming scenarios.
The second point is compatibility with various big data ecosystems. The datasets we build will have loads of batch processing, stream processing, incremental processing, and dynamic exploration at the same time. These workloads are currently running on various compute engines, so support for multiple compute engines is also under consideration.
Another consideration is the fit with Shopee's business needs. At present, most of the data sets we need to deal with come from business systems and have unique identification information, so the design of Hudi is more in line with our data characteristics.
2.2 The ability to plug in

At present, our platform provides Flink and Spark as general computing engines, as the bearer of data integration and data warehouse construction load, and also uses Presto to carry the function of data exploration. Hudi supports all three.
In actual use, we will also provide users with different data indexing methods according to the importance of business data.
2.3 Matching business characteristics

In the process of data integration, the schema change of users is a very common need. Data changes in ODS may cause errors in downstream computing tasks. At the same time, when processing incrementally, we need the semantics of time processing. Supporting the storage of primary key data is of great significance to the data of our business database.
3. The practice of Shopee in the implementation of Hudi
3.1 Real-time data integration
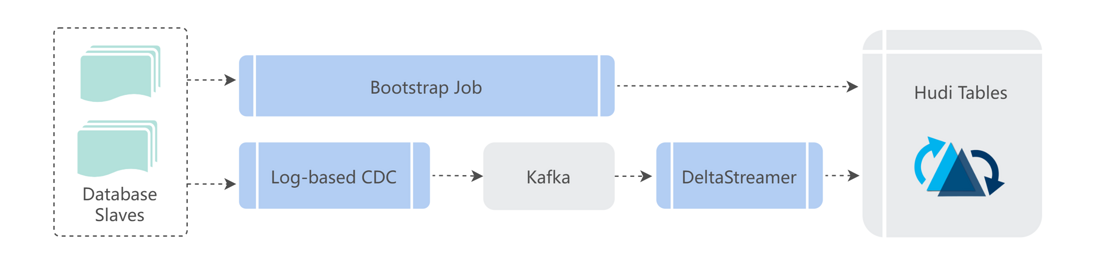
At present, a large amount of business data in Shopee comes from the business database. We use a technology similar to CDC to obtain the change data in the database, and build the ODS layer data for the business side that supports batch processing and near real-time incremental processing.
When the data of a business party needs to be accessed, we will do a full bootstrap before incremental real-time integration, build the basic table, and then build it in real time based on the newly accessed CDC data.
During the construction process, we generally choose to build a COW table or a MOR table according to user needs.
1) Problem building and solution

In the process of real-time construction, there are the following two more common problems:
One is that the user configures the type of data set with a large number of changes as a COW table, resulting in data write amplification . All we need to do at this point is to set up the appropriate monitoring to identify this configuration. At the same time, our configuration data merge logic based on MOR table supports synchronous or asynchronous update of data files.
The second problem is that the default Bloom filter causes the problem of data existence judgment . A better way here is to use HBase Index to solve the problem of writing large data sets.
2) The effect of problem solving
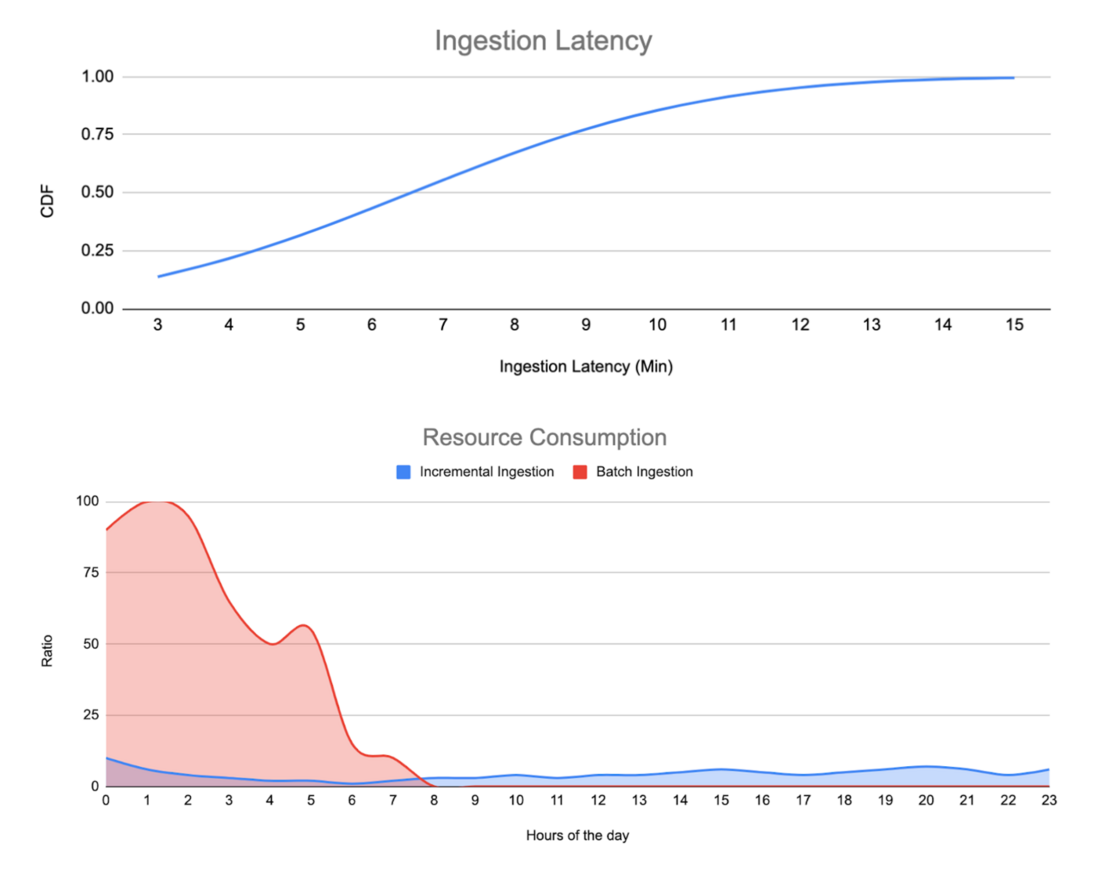
This is the effect of swapping some of our data integration links for Hudi-based real-time integrations. The above figure shows the relationship between the proportion of data visibility and the delay. At present, we can guarantee that 80% of the data is visible and available within 10 minutes, and all data is visible and available within 15 minutes.
The figure below shows the proportion of resource consumption that we have calculated. The blue part is the resource consumption of the real-time link, and the red part is the resource consumption of historical batch data integration.
Because of switching to a real-time link, repetitive processing is reduced for some data with a low repetition rate of large tables, and resource consumption caused by the reduction of centralized processing efficiency is also reduced. Therefore, our resource consumption is much lower than batch mode.
3.2 Incremental view

For scenarios where users need state details, we provide a service based on the Hudi Savepoint function, and regularly build snapshots according to the time period required by users. These snapshots are stored in the metadata management system in the form of partitions.
Users can easily use SQL in Flink, Spark, or Presto to use these data. Because the data storage is complete and has no merged details, the data itself supports full calculation and incremental processing.

When using incremental view storage, better storage savings will be achieved for some scenarios where the proportion of changed data is not large.
Here is a simple formula for calculating space usage: (1 + (t - 1) * p ) / t .
Among them, P represents the proportion of changed data, and t represents the number of time periods to be saved. The lower the percentage of changed data, the better the storage savings. For long-period data, there will also be a better saving effect.
At the same time, this method has a better effect on resource saving of incremental computing. The disadvantage is that there will be a certain read amplification problem in the full batch calculation.
3.3 Incremental calculation
When our datasets are built on Hudi MOR tables, batch, incremental, and near real-time processing workloads can be supported simultaneously.

Taking the figure as an example, Table A is an incremental MOR table. When we build subsequent Table B and Table C based on Table A, if the calculation logic supports incremental construction, then in the calculation process, only Need to get new data and changed data. In this way, the amount of data involved in the calculation is significantly reduced in the calculation process.
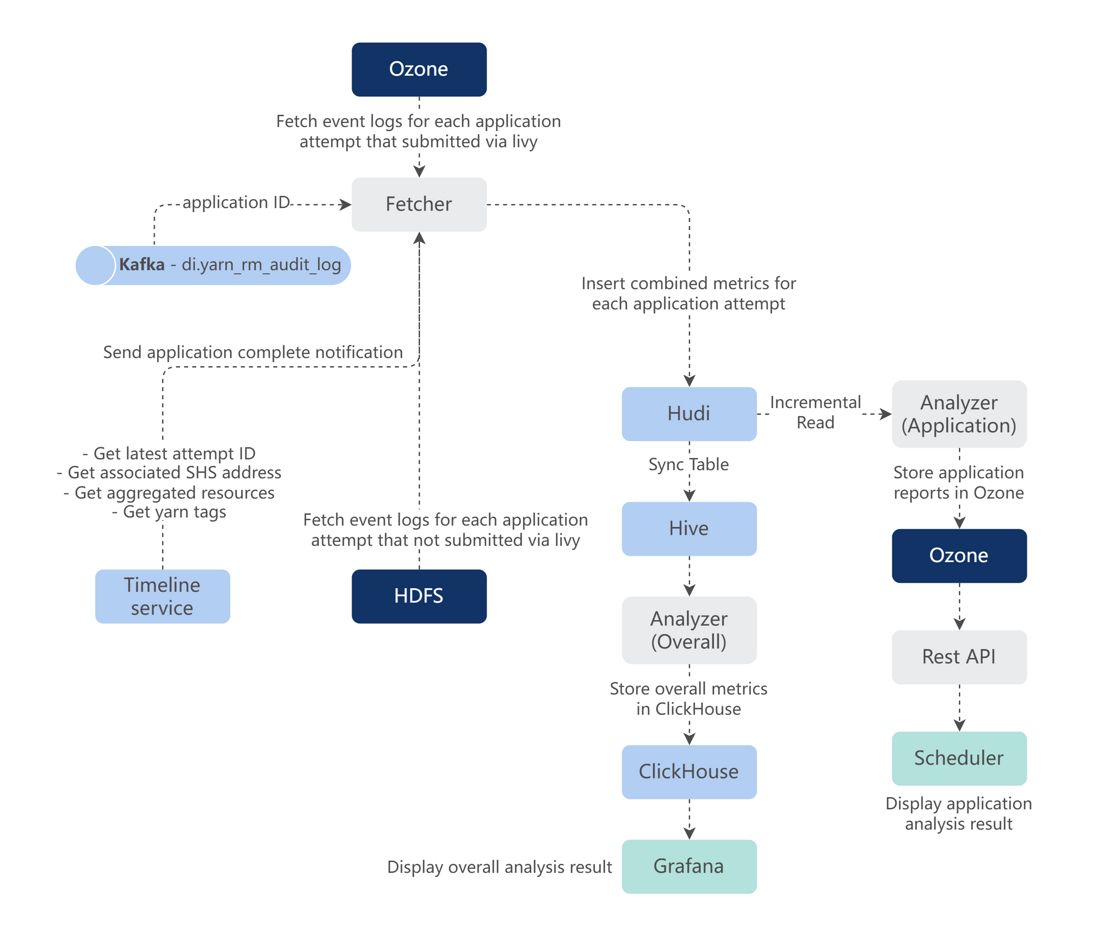
Here is a near real-time user job analysis built on the offline computing platform based on Hudi's incremental computing. When a user submits a Spark task to the cluster to run, the user's logs will be automatically collected after the task, and relevant metrics and key logs will be extracted and written to the Hudi table. Then a processing task incrementally reads these logs and analyzes the optimization items of the task for the user's reference.
When a user job is finished, the user's job situation can be analyzed within one minute, and an analysis report can be formed to provide the user.
Incremental Join

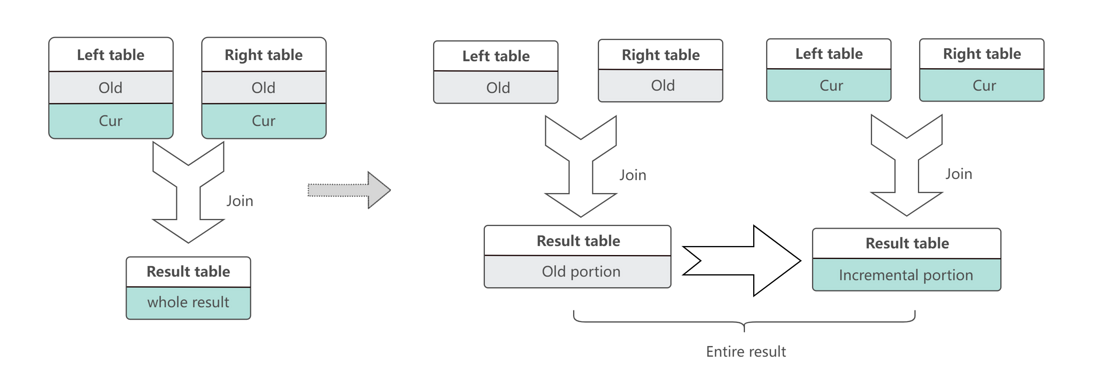
In addition to incremental computing, incremental Join is also a very important application scenario.
Compared with traditional Join, incremental computing only needs to find the data file to be read according to the incremental data, read it, analyze the partition that needs to be rewritten, and rewrite it.
Compared with the full amount, incremental computing significantly reduces the amount of data involved in computing.
Merge Into
Merge Into is a very practical technology in Hudi for building real-time wide tables. It is mainly based on Partial update.
MERGE INTO target_table t0
USING SOURCE TABLE s0
ON t0.id = s0.id
WHEN matched THEN UPDATE SET
t0.price = s0.price+5,
_ts = s0.ts; MERGE INTO target_table_name [target_alias]
USING source_table_reference [source_alias]
ON merge_condition
[ WHEN MATCHED [ AND condition ] THEN matched_action ] [...]
[ WHEN NOT MATCHED [ AND condition ] THEN not_matched_action ] [...]
matched_action
{ DELETE |
UPDATE SET * |
UPDATE SET { column1 = value1 } [, ...] }
not_matched_action
{ INSERT * |
INSERT (column1 [, ...] ) VALUES (value1 [, ...])The Merge Into syntax based on Spark SQL is shown here, which makes it very easy for users to develop jobs for building wide tables.
Incremental Join implementation based on Merge Into
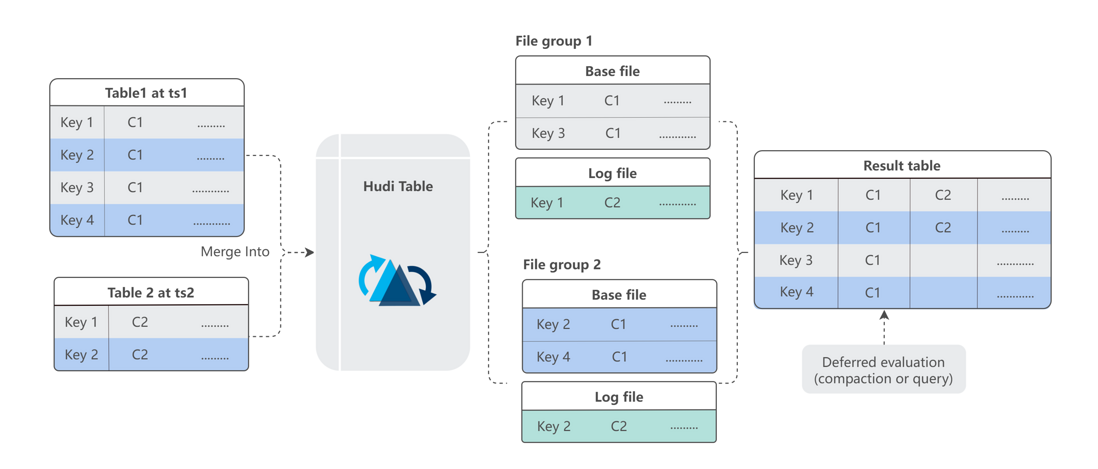
The implementation of Hudi is in the way of Payload. In a Payload, only some columns of a table can exist.
The payload of incremental data is written to the log file, and then the wide table used by the user is generated in subsequent merges. Because of the time delay in subsequent merges, we optimized the merge write logic.
After the data merge is completed, we will write a merged data time and related DML in the metadata management, and then analyze the DML and time in the process of reading this MOR table to provide guarantee for data visibility.

The benefits of using Partial Update are:
- Significantly reduces the resource usage of streaming construction of large wide tables;
- The processing efficiency is increased when data is modified at the file level.
4. Community Contribution
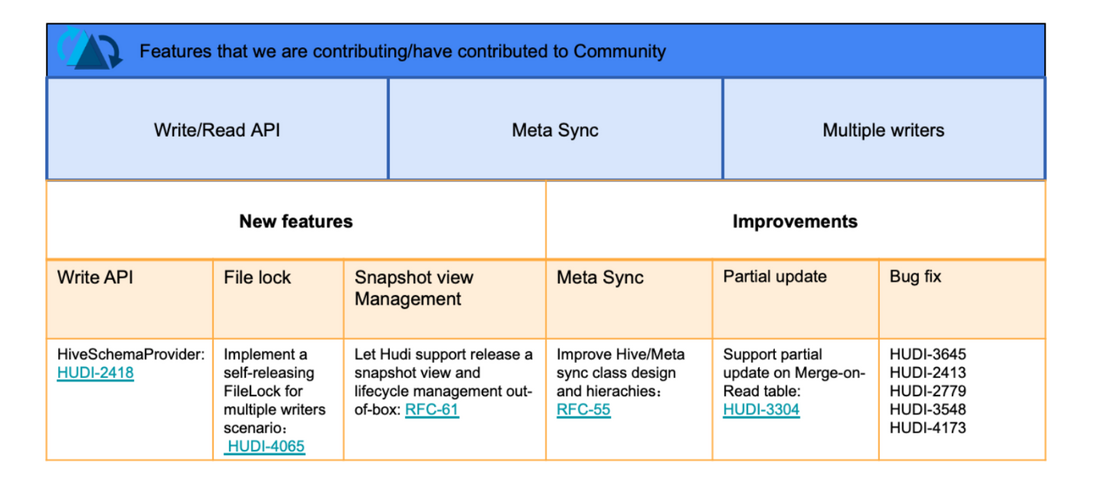
While solving the internal business problems of Shopee, we also contributed a batch of codes to the community to share internal optimizations and new features. The larger features include meta sync(RFC-55 已完成) , snapshot view(RFC-61) , partial update(HUDI-3304) , FileSystemLocker(HUDI-4065 已完成) and so on; also help the community to fix many bugs. In the future, we also hope to use this method to better meet business needs and participate in community building.
4.1 Snapshot View
Incremental view (snapshot view) has the following typical application scenarios:
- A snapshot named
compacted-YYYYMMDDis generated on the base table every day, and the user uses the snapshot table to generate a daily derived data table and calculate the report data. When the computing logic downstream of the user changes, the corresponding snapshot can be selected for recalculation. You can also set the retention period to X days and clear out expired data every day. In fact, SCD-2 can be naturally implemented on multi-snapshot data. - An archive branch named
yyyy-archivedcan be generated every year after the data is compressed and optimized. If our preservation strategy changes (for example, to delete sensitive information), then after the relevant operations, in this Generate a new snapshot on the branch. - A snapshot named
preprod-xxcan be officially released to users after the necessary quality checks have been carried out to avoid coupling of external tools to the pipeline itself.
For the needs of snapshot view, Hudi can already support it to a certain extent through two key features:
- Time travel : Users can provide a time point to query the snapshot data of the Hudi table at the corresponding time.
- Savepoint : It is guaranteed that the snapshot data at a certain commit time point will not be cleaned up, and the intermediate data outside the savepoint can still be cleaned up.
A simple implementation is shown below:

However, in actual business scenarios, in order to meet the user's snapshot view needs, it is necessary to consider more ease of use and usability .
For example, how does the user know that a snapshot has been published correctly? One of the problems involved in this is visibility, that is, users should be able to get the snapshot table explicitly throughout the pipeline. Here, a Git-like tag function needs to be provided to enhance ease of use.
In addition, in the scene of taking snapshots, a common requirement is the accurate segmentation of data. An example is that the user does not want the event time data on No. 1 to drift to the snapshot on No. 2, but prefers to do fine instant segmentation combined with watermark under each FileGroup.
To better meet the needs in production environments, we implemented the following optimizations:
- Expand the savepoint metadata, on this basis, realize the tag, branch and lifecycle management of snapshots, and the automatic meta synchronization function;
- Implement refined ro table base file segmentation on the MergeOnRead table, and segment log files by watermark during compaction to ensure the accuracy of snapshots. That is to say, we can provide data accurate to 0 points for downstream offline processing on the basis of streaming writing.
At present, we are contributing the overall function back to the community through RFC-61. The benefits of the actual implementation process have been introduced in the previous chapters, and will not be repeated here.
4.2 Multi-source Partial update
The previous article briefly introduced the multi-source partial column update (large-width table splicing) scenario. We rely on Hudi's multi-source merging capability to implement the Join operation in the storage layer, which greatly reduces the pressure on the computing layer on state and shuffle.
At present, we mainly implement multi-source partial column update through the Payload interface inside Hudi. The following figure shows the interaction flow of Payload on Hudi's write-side and read-side.

The principle of implementation is basically to realize the logic of merging data from different sources with the same key through a custom Payload class. The write end will merge multiple sources within the batch and write to the log, and the read end will also call the same when merging during reading. logic to handle cross-batch situations.
The thing to watch out for here is the issue of out-of-order and late events. If not processed, it will often cause old data to overwrite new data in the downstream, or incomplete column updates.
For out-of-order and late data, we have enhanced the Multiple ordering value of event time (ordering value) to ensure that each source can only update the data belonging to its own part of the column. Let new data overwrite old data.
In the future, we also plan to combine lock less multiple writers to realize concurrent writing of multiple jobs and multiple sources.
5. Summary and Outlook
In response to the problems faced in the construction of the Shopee data system, we proposed an integrated solution of lake and warehouse, and selected Hudi as the core component through comparison and selection.
In the process of landing, we have met three main user demand scenarios by using the core features of Hudi and the expansion and transformation on top of it: real-time data integration, incremental view and incremental computing. And it brings benefits such as low latency (about 10 minutes), reduced computing resource consumption, and reduced storage consumption for users.
Next, we will provide more features and further improve the following two aspects to meet more user scenarios and provide better performance.
5.1 Cross-task concurrent write support
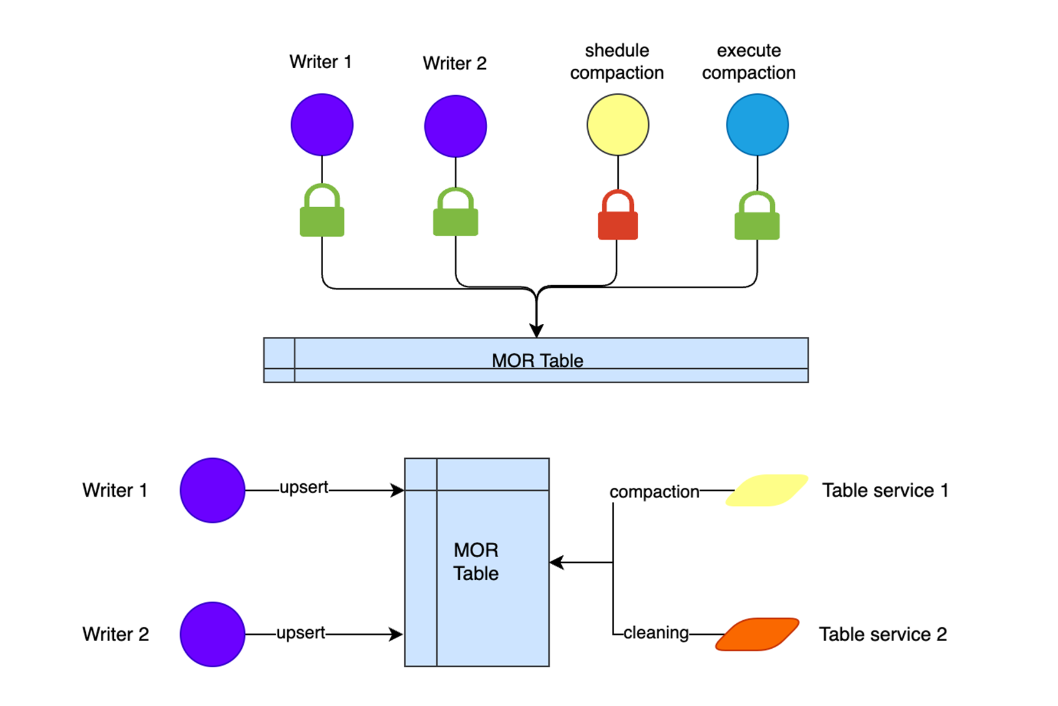
Currently Hudi supports a single-task single-writer writing method based on file locks.
However, in practice, there are some scenarios that require multiple tasks and multiple writers to write at the same time, and the write partitions are intersected. The current OCC does not support this situation well. Currently we are working with the community to solve the multi-writer scenario of Flink and Spark.
5.2 Performance optimization
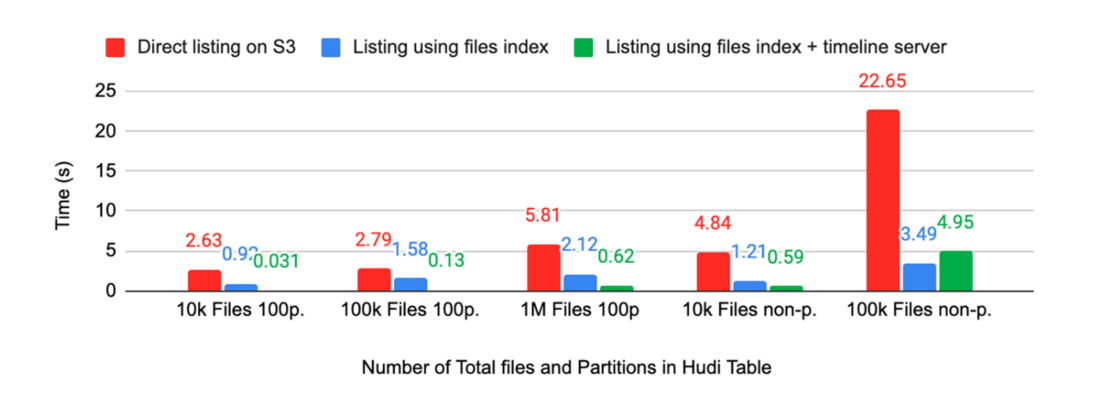
Metadata reading and file listing operations will consume a lot of performance both on the write side and on the read side. Massive partitions will also put a lot of pressure on external metadata systems (such as HMS).
In response to this problem, we plan the first step to transition information storage beyond schema from HMS to MDT; the second step is to use an independent MetaStore and Table service server in the future, no longer strongly coupled to HDFS.
In this server, we can more easily optimize read performance and flexibly adjust resources.
author of this article
Jian, big data technology expert, from the Shopee Data Infrastructure team.






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。