SF
deephub
deephub
注册登录
关注博客
注册登录
主页
关于
RSS
自回归模型PixelCNN 的盲点限制以及如何修复
deephub
2021-12-28
阅读 12 分钟
1.7k
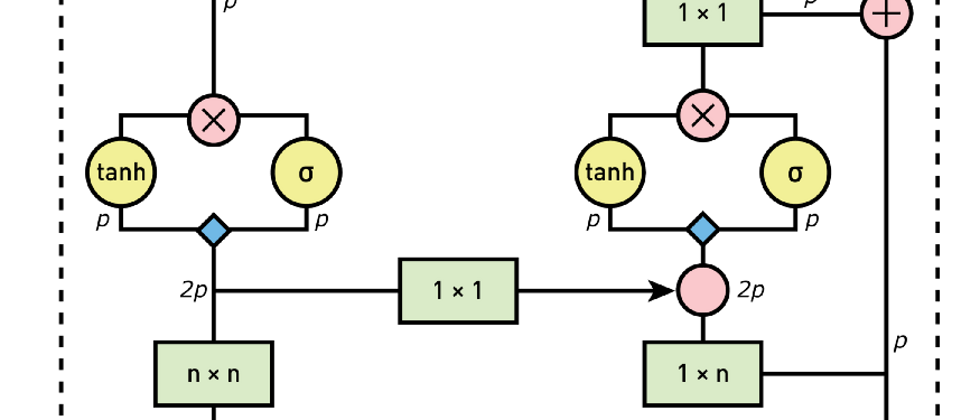
前两篇文章我们已经介绍了自回归模型PixelCNNs,以及如何处理多维输入数据,本篇文章我们将关注 PixelCNNs 的最大限制之一(即盲点)以及如何改进以修复它。
5分钟 NLP:使用 OpenNRE 进行关系提取
deephub
2021-12-27
阅读 2 分钟
2.1k
关系提取( Relation Extraction)是一项自然语言处理任务,旨在提取实体之间的关系。 例如,从句罗密欧与朱丽叶是由威廉莎士比亚写的,我们可以提取关系三元组(威廉莎士比亚,是罗密欧与朱丽叶的作者)。
5个很少被提到但能提高NLP工作效率的Python库
deephub
2021-12-27
阅读 5 分钟
962
例如:以前需要编写一长串正则表达式来扩展文本数据中的(即 don’t → do not;can’t → cannot;haven’t → have not)。Contractions就可以解决这个问题
利用关联规则实现推荐算法
deephub
2021-12-26
阅读 10 分钟
2.2k
关联规则是以规则的方式呈现项目之间的相关性:关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。
AlphaZero如何学习国际象棋的?
deephub
2021-12-25
阅读 3 分钟
1.6k
DeepMind 和 Google Brain 研究人员以及前世界国际象棋冠军Vladimir Kramnik通过概念探索、行为分析和对其激活的检查,探索了人类知识是如何获得的,以及国际象棋概念如何在 AlphaZero 神经网络中表示。
5分钟 NLP 系列: Word2Vec和Doc2Vec
deephub
2021-12-24
阅读 1 分钟
1.6k
Doc2Vec 是一种无监督算法,可从可变长度的文本片段(例如句子、段落和文档)中学习嵌入。它最初出现在 Distributed Representations of Sentences and Documents 一文中。
对抗性攻击的原理简介
deephub
2021-12-24
阅读 3 分钟
2.7k
由于机器学习算法的输入形式是一种数值型向量(numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。
使用 PyTorch Geometric 在 Cora 数据集上训练图卷积网络GCN
deephub
2021-12-23
阅读 8 分钟
2.6k
今天有很多的资源可以教我们将机器学习应用于此类数据所需的一切知识。已经有很多学习有关图机器学习的相关理论和材料,特别是图神经网络,所以本文将避免在这里解释这些内容。如果你对该方面不太熟悉,推荐先看下CS224W,这会对你的入门有很大的帮助。
从熵到交叉熵损失的直观通俗的解释
deephub
2021-12-22
阅读 2 分钟
1.6k
信息论的主要关注点之一是量化编码和传输事件所需的总比特数:罕见的事件即概率较低的事件,需要表示更多位,而频繁事件不需要很多位。因此我们可以从编码器和通信机的角度出发,将-log(p)定义为编码和传输符合p概率分布的事件所需的总比特数,即信息。小 p(罕见事件)导致大 -log(p)(更多位)。
2021 年顶级深度学习论文推荐
deephub
2021-12-21
阅读 5 分钟
2.6k
我们都讨厌对文章进行冗长而毫无意义的介绍所以我就直奔主题了。2021年还有10天就过去了, 以下是我认为 2021 年最有趣、最有前途的深度学习论文。
神经网络压缩方法:模型量化的概念简介
deephub
2021-12-20
阅读 5 分钟
3.7k
在过去的十年中,深度学习在解决许多以前被认为无法解决的问题方面发挥了重要作用,并且在某些任务上的准确性也与人类水平相当甚至超过了人类水平。如下图所示,更深的网络具有更高的准确度,这一点也被广泛接受并且证明。
阅读和实现深度学习的论文初学者指南
deephub
2021-12-19
阅读 3 分钟
1.7k
我们将讨论如何选择一篇“好”的论文作为开始,这对于初学者来说会比较容易;本文中将概述典型的论文结构以及重要信息的位置;并提供有关如何处理和实现论文的分步说明,并分享在遇到困难时可能有所帮助的链接。
计算 Python 代码的内存和模型显存消耗的小技巧
deephub
2021-12-18
阅读 5 分钟
2.9k
了解Python代码的内存消耗是每一个开发人员都必须要解决的问题,这个问题不仅在我们使用pandas读取和处理CSV文件的时候非常重要,在我们使用GPU训练的时候还需要规划GPU的显存使用。尤其是我们在白嫖使用kaggle和colab时显得更为重要。
可解释的AI (XAI):如何使用LIME 和 SHAP更好地解释模型的预测
deephub
2021-12-17
阅读 4 分钟
2.4k
作为数据科学家或机器学习从业者,将可解释性集成到机器学习模型中可以帮助决策者和其他利益相关者有更多的可见性并可以让他们理解模型输出决策的解释。
开启深度强化学习之路:Deep Q-Networks简介和代码示例
deephub
2021-12-16
阅读 6 分钟
2.3k
强化学习是机器学习领域的热门子项。由于 OpenAI 和 AlphaGo 等公司的最新突破,强化学习引起了游戏行业许多人的注意。我们今天以Hill Climb Racing这款经典的游戏来介绍DQN的整个概念,Hill Climb Racing需要玩家在不同的地形上驾驶不同的车辆,驾驶距离越长得分越高。
18 个 实用的Numpy 代码片段总结
deephub
2021-12-15
阅读 7 分钟
1k
Numpy 长期以来一直是 Python 开发人员进行数组操作的通用选择,它是基于C语言构建的这使得它成为执行数组操作的快速和可靠的选择,并且它已经成为机器学习和数据科学必备的基础库。
使用卷积神经网络进行实时面部表情检测
deephub
2021-12-14
阅读 3 分钟
1.6k
在社交互动中,面部表情在非语言交流中起着至关重要的作用。 心理学家保罗·埃克曼提出,全世界的人都有七种情绪表达方式:快乐、悲伤、惊讶、恐惧、愤怒、厌恶和蔑视。 建立更好的人机交互,例如通过图像检测人类情绪,可能是一项艰巨的任务。
BERT 模型的知识蒸馏: DistilBERT 方法的理论和机制研究
deephub
2021-12-13
阅读 5 分钟
3.8k
如果你曾经训练过像 BERT 或 RoBERTa 这样的大型 NLP 模型,你就会知道这个过程是极其漫长的。由于其庞大的规模,训练此类模型可能会持续数天。当需要在小型设备上运行它们时,就会发现正在以巨大的内存和时间成本为日益增长的性能付出代价。
带掩码的自编码器MAE详解和Pytorch代码实现
deephub
2021-12-12
阅读 10 分钟
4.4k
监督学习是训练机器学习模型的传统方法,它在训练时每一个观察到的数据都需要有标注好的标签。如果我们有一种训练机器学习模型的方法不需要收集标签,会怎么样?如果我们从收集的相同数据中提取标签呢?这种类型的学习算法被称为自监督学习。这种方法在自然语言处理中工作得很好。一个例子是BERT¹,谷歌自2019年以来一直在...
联邦学习(Federated Learning)详解以及示例代码
deephub
2021-12-11
阅读 11 分钟
6k
联邦学习也称为协同学习,它可以在产生数据的设备上进行大规模的训练,并且这些敏感数据保留在数据的所有者那里,本地收集、本地训练。在本地训练后,中央的训练协调器通过获取分布模型的更新获得每个节点的训练贡献,但是不访问实际的敏感数据。
SIMILAR:现实场景中基于子模块信息度量的主动学习
deephub
2021-12-10
阅读 3 分钟
1.5k
在过去几年中,主动学习 (AL) 策略已被证明可用于降低标签成本。但是当涉及现实世界的数据集时,当前的方法效果并不理想,现实世界的些数据集存在缺陷和许多特征,使得从中学习具有更大挑战性:
为什么 Pi 会出现在正态分布的方程中?
deephub
2021-12-09
阅读 4 分钟
1.6k
本篇文章将介绍钟形曲线是如何形成的,以及π为什么会出现在一个看似与它无关的曲线的公式中。最近在翻阅一本旧的统计教科书时我发现了一个熟悉的正态分布方程:任何在大学上过统计学课程的人都遇到过这个等式。我自己也看过很多次了,但这次重新看,立刻想到了两个问题:这东西究竟是如何形成正态分布的?π在那里做什么...
Mask R-CNN上手指南:通过对象检测和分割实现对无人机的检测
deephub
2020-04-15
阅读 8 分钟
3.2k
Mask R-CNN是目标检测的扩展,它为图像中检测到的每个目标生成边界框和分割掩模。这篇文章是关于使用Mask R-CNN训练自定义数据集的指南,希望它能帮助你们中的一些人简化这个过程。
通过 Python 代码实现时间序列数据的统计学预测模型
deephub
2020-04-10
阅读 6 分钟
5.6k
在本篇中,我们将展式使用 Python 统计学模型进行时间序列数据分析。 问题描述 目标:根据两年以上的每日广告支出历史数据,提前预测两个月的广告支出金额。
在Python中使用K-Means聚类和PCA主成分分析进行图像压缩
deephub
2020-04-09
阅读 13 分钟
3.3k
各位读者好,在这片文章中我们尝试使用sklearn库比较k-means聚类算法和主成分分析(PCA)在图像压缩上的实现和结果。 压缩图像的效果通过占用的减少比例以及和原始图像的差异大小来评估。 图像压缩的目的是在保持与原始图像的相似性的同时,使图像占用的空间尽可能地减小,这由图像的差异百分比表示。 图像压缩需要几个P...
假新闻无处不在:我创建了一个通深度学习的方法标记假新闻的开源项目
deephub
2020-04-08
阅读 9 分钟
1.4k
虚假新闻的兴起迫使拥有社交媒体帐户的每个人都成为一名侦探,负责在发布前确定帖子是否真实。但是,虚假新闻仍然会越过我们的防线,在网络上迅速扩散,由于用户的无知和粗心而加剧。正如NBC新闻报道所显示的那样,假新闻不仅会散布恐惧和虚假信息,而且还可能对公司和个人的声誉造成损害。为了减少错误信息的直接和间...
使用PyTorch Lightning构建轻量化强化学习DQN
deephub
2020-04-07
阅读 8 分钟
1.9k
本文旨在探究将PyTorch Lightning应用于激动人心的强化学习(RL)领域。在这里,我们将使用经典的倒立摆gym环境来构建一个标准的深度Q网络(DQN)模型,以说明如何开始使用Lightning来构建RL模型。
神奇的Batch Normalization 仅训练BN层会发生什么
deephub
2020-04-03
阅读 5 分钟
4.1k
最近,我阅读了arXiv平台上的Jonathan Frankle,David J. Schwab和Ari S. Morcos撰写的论文“*Training BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs*”。 这个主意立刻引起了我的注意。 到目前为止,我从未将批标准化(BN)层视为学习过程本身的一部分,仅是为了帮助深度网络实...
解决过拟合:如何在PyTorch中使用标签平滑正则化
deephub
2020-04-02
阅读 3 分钟
2.1k
在训练深度学习模型的过程中,过拟合和概率校准(**probability calibration**)是两个常见的问题。一方面,正则化技术可以解决过拟合问题,其中较为常见的方法有将权重调小,迭代提前停止以及丢弃一些权重等。另一方面,Platt标度法和isotonic regression法能够对模型进行校准。但是有没有一种方法可以同时解决过拟合和模...
精度是远远不够的:如何最好地评估一个分类器?
deephub
2020-04-01
阅读 4 分钟
4.1k
分类模型(分类器)是一种有监督的机器学习模型,其中目标变量是离散的(即类别)。评估一个机器学习模型和建立模型一样重要。我们建立模型的目的是对全新的未见过的数据进行处理,因此,要建立一个鲁棒的模型,就需要对模型进行全面而又深入的评估。当涉及到分类模型时,评估过程变得有些棘手。
上一页
1
…
More
33
34
35
(current)
36
下一页
上一页
35
(current)
下一页