SF
Python数据科学
Python数据科学
注册登录
关注博客
注册登录
主页
关于
RSS
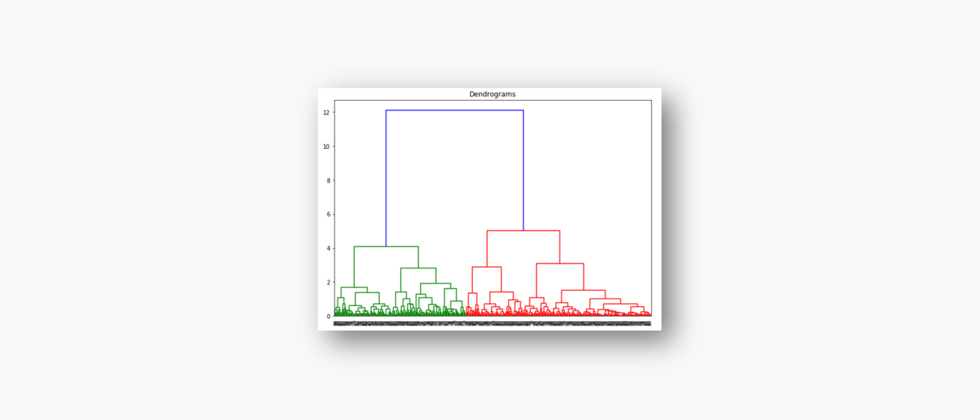
一文读懂层次聚类(Python代码)
东哥起飞
2021-11-22
阅读 5 分钟
9.8k
首先要说,聚类属于机器学习的无监督学习,而且也分很多种方法,比如大家熟知的有K-means。层次聚类也是聚类中的一种,也很常用。下面我先简单回顾一下K-means的基本原理,然后慢慢引出层次聚类的定义和分层步骤,这样更有助于大家理解。
【机器学习笔记】:大话线性回归(一)
东哥起飞
2021-01-05
阅读 6 分钟
10.3k
线性回归作为监督学习中经典的回归模型之一,是初学者入门非常好的开始。宏观上考虑理解性的概念,我想我们在初中可能就接触过,y=ax,x为自变量,y为因变量,a为系数也是斜率。如果我们知道了a系数,那么给我一个x,我就能得到一个y,由此可以很好地为未知的x值预测相应的y值。这很符合我们正常逻辑,不难理解。
再见 VBA!神器工具统一 Excel 和 Python
东哥起飞
2020-12-31
阅读 3 分钟
17.2k
Excel和Jupyter Notebok都是我每天必用的工具,而且两个工具经常协同工作,一直以来工作效率也还算不错。但说实在,毕竟是两个工具,使用的时候肯定会有一些切换的成本。
真香!Python十大常用文件操作
东哥起飞
2020-12-07
阅读 7 分钟
11.5k
日常对于批量处理文件的需求非常多,用Python写脚本可以非常方便地实现,但在这过程中难免会和文件打交道,第一次做会有很多文件的操作无从下手,只能找度娘。
太香了,墙裂推荐3个Python数据分析EDA神器!
东哥起飞
2020-11-23
阅读 4 分钟
8.3k
EDA是数据分析必须的过程,用来查看变量统计特征,可以此为基础尝试做特征工程。东哥这次分享3个EDA神器,其实之前每一个都分享过,这次把这三个工具包汇总到一起来介绍。
骚操作!嵌套 JSON 秒变 Dataframe!
东哥起飞
2020-11-09
阅读 3 分钟
6.9k
调用API和文档数据库会返回嵌套的JSON对象,当我们使用Python尝试将嵌套结构中的键转换为列时,数据加载到pandas中往往会得到如下结果:
安利一个Python大数据分析神器!
东哥起飞
2020-11-02
阅读 5 分钟
4.1k
Pandas和Numpy大家都不陌生了,代码运行后数据都加载到RAM中,如果数据集特别大,我们就会看到内存飙升。但有时要处理的数据并不适合RAM,这时候Dask来了。
Bong!5 款超牛逼的 Jupyter Notebook 插件!
东哥起飞
2020-10-29
阅读 3 分钟
7.7k
作者:东哥起飞微信公众号:Python数据科学本次东哥分享三个高效的Jupyter Notebook插件,每个都很实用。1、Scratchpad这个插件非常有用,我们做数据分析EDA或者特征工程时经常要各种尝试,而不是要真正的运行cell代码。这个时候在同一个notebook里来回运行就非常容易乱,找不到自己想要的那个对的代码了。当然,可以注...
再见,可视化!你好,Pandas!
东哥起飞
2020-10-16
阅读 4 分钟
9.1k
因此,大家在用Python做数据分析时,正常的做法是用先pandas先进行数据处理,然后再用Matplotlib、Seaborn、Plotly、Bokeh等对dataframe或者series进行可视化操作。
安利 5 个拍案叫绝的 Matplotlib 骚操作!
东哥起飞
2020-09-29
阅读 4 分钟
3.9k
大家都知道,Matplotlib是Python的可视化库,功能很强,可以绘制各种图。一些常规用法前不久分享过Matplotlib官方出品的cheatsheet:Matplotlib官方小抄手册公开,配套可视化代码已打包!
从机械转行数据科学,吐血整理了这些白嫖的学习网站
东哥起飞
2020-06-19
阅读 4 分钟
4.4k
作者:东哥起飞Python数据科学 大家好,我是东哥。 前方高能,准备开启收藏夹吃灰模式。 本篇东哥分享几个数据科学入门的学习网站,全部免费资源,且内容优质,是小白入门的不二选择。东哥当年从机械转行也从这些学习网站收获很多。 下面开始进入正题。 一、Kaggle 什么是Kaggle? kaggle是全球最先也是目前规模最大的数...
太香了!墙裂推荐6个Python数据分析神器!!
东哥起飞
2020-06-14
阅读 5 分钟
4.8k
Pandas Profiling提供数据的一个整体报告,是一个帮助我们理解数据的过程。它可以简单快速地对Pandas的数据框数据进行探索性数据分析。
太赞了!分享一个数据科学利器 PyCaret,几行代码搞定从数据处理到模型部署
东哥起飞
2020-06-07
阅读 6 分钟
4k
学习数据科学很久了,从数据探索、数据预处理、数据模型搭建和部署这些过程一直有些重复性的工作比较浪费时间,尤其当你有个新的想法想要快速尝试下效果的时候,效率很低。
深入理解 MySql 的 Explain
东哥起飞
2020-06-05
阅读 8 分钟
4.5k
相信大部分入门数据库的朋友都是从数据库的“增删改查”学起的。其实,对于很多搞业务的非专业技术人员而言,可能基本的增删改查也够用了,因为目的并不是要写的多好,只要能正确查到自己想要的分析的数据就可以了。
厉害了!每30秒学会一个Python小技巧,Github星数4600+
东哥起飞
2020-04-11
阅读 3 分钟
5.1k
很多学习Python的朋友在项目实战中会遇到不少功能实现上的问题,有些问题并不是很难的问题,或者已经有了很好的方法来解决。当然,孰能生巧,当我们代码熟练了,自然就能总结一些好用的技巧,不过对于那些还在刚熟悉Python的同学可能并不会那么轻松。
那些功能逆天,却鲜为人知的pandas骚操作
东哥起飞
2020-04-05
阅读 11 分钟
9.1k
pandas有一种功能非常强大的方法,它就是accessor,可以将它理解为一种属性接口,通过它可以获得额外的方法。其实这样说还是很笼统,下面我们通过代码和实例来理解一下。
数据探索很麻烦?推荐一款史上最强大的特征分析可视化工具:yellowbrick
东哥起飞
2019-09-03
阅读 9 分钟
9.5k
玩过建模的朋友都知道,在建立模型之前有很长的一段特征工程工作要做,而在特征工程的过程中,探索性数据分析又是必不可少的一部分,因为如果我们要对各个特征进行细致的分析,那么必然会进行一些可视化以辅助我们来做选择和判断。
Python一行代码搞定炫酷可视化,你需要了解一下Cufflinks
东哥起飞
2019-07-21
阅读 5 分钟
4k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 前言 学过Python数据分析的朋友都知道,在可视化的工具中,有很多优秀的三方库,比如matplotlib,seaborn,plotly,Boken,pyecharts等等。这些可视化库都有自己的特点,在实际应用中也广为大家使用。 plotly、Boken等都是交互式的可视化工具,结合Jupy...
还在抱怨pandas运行速度慢?这几个方法会颠覆你的看法
东哥起飞
2019-02-12
阅读 10 分钟
12.2k
作者:xiaoyu微信公众号:Python数据科学知乎:python数据分析师前言当大家谈到数据分析时,提及最多的语言就是Python和SQL。Python之所以适合数据分析,是因为它有很多第三方强大的库来协助,pandas就是其中之一。pandas的文档中是这样描述的:“快速,灵活,富有表现力的数据结构,旨在使”关系“或”标记“数据的使用既简...
【机器学习笔记】:一文让你彻底记住什么是ROC/AUC(看不懂你来找我)
东哥起飞
2018-10-15
阅读 6 分钟
22.6k
ROC/AUC作为机器学习的评估指标非常重要,也是面试中经常出现的问题(80%都会问到)。其实,理解它并不是非常难,但是好多朋友都遇到了一个相同的问题,那就是:每次看书的时候都很明白,但回过头就忘了,经常容易将概念弄混。还有的朋友面试之前背下来了,但是一紧张大脑一片空白全忘了,导致回答的很差。
99%的人都不知道的pandas骚操作(一)
东哥起飞
2018-09-11
阅读 6 分钟
11.5k
pandas有一种功能非常强大的方法,它就是accessor,可以将它理解为一种属性接口,通过它可以获得额外的方法。其实这样说还是很笼统,下面我们通过代码和实例来理解一下。
从爬虫到机器学习预测,我是如何一步一步做到的?
东哥起飞
2018-08-27
阅读 7 分钟
10.6k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 前情回顾 前一段时间与大家分享了北京二手房房价分析的实战项目,分为分析和建模两篇。文章发出后,得到了大家的肯定和支持,在此表示感谢。 数据分析实战—北京二手房房价分析 数据分析实战—北京二手房房价分析(建模篇) 除了数据分析,好多朋友也对爬...
如何用Python过一个完美的七夕节?
东哥起飞
2018-08-17
阅读 5 分钟
5.7k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 七夕礼物 一年一度的七夕节又到了,每年重复的过,花样各种有,很多男同胞又开始发愁了,该准备点什么呢?前一段时间非常火的电影 “西红市首富” 突然给了我点灵感,男主全城放烟花俘获了女主的芳心。没错!就是放烟花,而且要全城放。 可除了土豪,不是...
机器学习“特征编码”的经验分享:鱼还是熊掌?
东哥起飞
2018-08-15
阅读 3 分钟
10.3k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 1. 为什么要进行特征编码? 我们拿到的数据通常比较脏乱,可能会带有各种非数字特殊符号,比如中文。下面这个表中显示了我们最原始的数据集。而实际上机器学习模型需要的数据是数字型的,因为只有数字类型才能进行计算。因此,对于各种特殊的特征值,我...
还在为找数据而发愁吗?看完这篇应该再也不会了
东哥起飞
2018-08-11
阅读 3 分钟
13.3k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 学数据分析当然要先有数据,数据是分析的根本,不然一切都是空谈。如果是在公司里,得到数据轻而易举,因为公司有客户,有业务,必然会产生大量数据。但仅仅是个人学习的话,我们如何得到数据呢? 其实这也是好多正在学习数据分析的朋友常会遇到一个问...
【Python数据分析基础】: 异常值检测和处理
东哥起飞
2018-08-08
阅读 4 分钟
46.6k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 上一篇分享了关于数据缺失值处理的一些方法,链接如下:【Python数据分析基础】: 数据缺失值处理 本篇继续分享数据清洗中的另一个常见问题:异常值检测和处理。 1 什么是异常值? 在机器学习中,异常检测和处理是一个比较小的分支,或者说,是机器学习...
【Kaggle入门级竞赛top5%排名经验分享】— 建模篇
东哥起飞
2018-08-01
阅读 11 分钟
8.1k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 前情回顾 上一篇是数据挖掘的前戏,主要目的是认识数据特征、判断特征重要性、观察数据异常,掌握数据间联系。本篇将继续上一篇分析进行数据挖掘建模部分。 上篇数据分析的链接:【Kaggle入门级竞赛top5%排名经验分享】— 分析篇 数据预处理 数据预处理...
【Python数据分析基础】: 数据缺失值处理
东哥起飞
2018-07-28
阅读 6 分钟
17.9k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 圣人曾说过:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。 再好的模型,如果没有好的数据和特征质量,那训练出来的效果也不会有所提高。数据质量对于数据分析而言是至关重要的,有时候它的意义会在某种程度上会胜过模型算法。 ...
【Kaggle入门级竞赛top5%排名经验分享】— 分析篇
东哥起飞
2018-07-23
阅读 8 分钟
8k
作者:xiaoyu 微信公众号:Python数据科学 知乎:python数据分析师 Kaggle作为公认的数据挖掘竞赛平台,有很多公开的优秀项目,而其中作为初学者入门的一个好的项目就是:泰坦尼克号生还者预测。 可能这个项目好多朋友也听说过,可能很多朋友也做过。但是项目完成后,是否有很好的反思总结呢?很多朋友只是潦草的敷衍过...
5种方法教你用Python玩转histogram直方图
东哥起飞
2018-07-17
阅读 9 分钟
101.9k
直方图是一个可以快速展示数据概率分布的工具,直观易于理解,并深受数据爱好者的喜爱。大家平时可能见到最多就是 matplotlib,seaborn 等高级封装的库包,类似以下这样的绘图。
1
(current)
2
下一页
1
(current)
下一页