
介绍
对代码进行持续性开发和有意义的基准测试是一个复杂的任务。虽然测试工具本身(Intel® VTune™ Amplifier, SmartBear AQTime, Valgrind)与应用程序没有相关性,但是它们在某些时候对一些小团队,或者说是一些繁琐的工作来说还是很重要的。这个Celero项目,主要是要建仓一个小型的程序库,使它可以在加入 C++ 工程和对代码进行基准测试时能够非常容易地去重建,分享,并允许在独立的运行进程、开发者或者是工程间进行比较。Celero 使用一个与 GoogleTest 相似的构架,使得他的 API 很容易地使用,并融入一个工程中。当你在开发过程中进行自动测试时,自动化基准将会扮演举足轻重的作用。
背景
通常,编写基准的目的是为了测量一段代码的性能。基准有助于比较解决同一问题的不同方案并选择其中最合适的一个。其他时候,基准能以一种很有意义的方式突出设计或算法改变后的性能影响。
通过测量代码的性能,可以为性能消除那些你以为是正确方案的错误。只有通过测量,你才能确定比如用一张查找表比计算一个值更快。这种传闻(通常是重复的)可能导致糟糕的设计决策,最终生成效率更慢的代码。
编写好的基准的目的是为了消除所有噪音和开销,并且只测量被测代码。在测量中,噪音源包括时钟分辨率噪音、操作系统后台操作、测试设置/清除、框架开销以及其他不相干的系统行为。
理论上,我们想测量被测代码的执行时间“t”。实际上,我们测到的是“t”与所有噪音的和。

这些影响我们测量的“t”的不相干因素会随时间变化而波动。因此,我们想试图将“t”隔离出来。实现这样的方法是通过多次测量,但只保留最小的总时间。这个最小的总时间必然是受噪音干扰最小且最接近时间“t”的值。
一旦得到这个测量值,在进行隔离就没什么意义了。建立一个基线测试作比较很重要。基线通常应该是一个基于你正要测量出一个解决方案的问题的“经典”或“纯粹”的方案。一旦有了一个基线,你花时间去比较你的算法就有意义。简单地说,你中意的排序算法(fSort)不能在10毫秒内自动排序100万元素。然而,相对于一个经典的排序算法基线如快速排序(qSort),你可以说,fSort处理100万元素比去Sort快50%。这是个很有意义且强大的测量。
实现
Celero大量使用Visual C++和GCC4.7都支持的C++11特性。这对使代码整洁、便携大有帮助。为了使代码更容易采用,用户所需的所有定义都放在一个命名空间为celero的单一头文件:Celero.h里。
Celero.h里包含将每个用户基准用例转换为独特的、具有与之相关测试固件的类(如果有的话),然后登记测试用例到一个工厂。这些宏自动将基线测试用例与相关的测试基准关联起来,这样,在运行时基准相关的数据就可以被算出。这一关联由测试向量来维护。
测试向量利用PImpl惯语来隐藏实现并且保持包含Celero.h的开销降到最小。
Celero将结果输出到命令行。因为颜色是有用的(可能有助于主观因素/结果的可读性),所以std::cout调用了自身之外的一些东西。Console.h定义了一个简单的颜色函数,SetConsoleColor,它可以被celero::print命名空间中的函数用来格式化程序的输出。
测量基准的执行时间位于TestFixturebase类中,而且所有基准的写法都是以此为基础派生出来的。首先,测试夹具(译注:test fixture 是检测被测试系统时所需要的所有东西)的创建代码被执行。接着,测试的开始时间被获取到并以毫秒的形式用一个unsigned long保存起来。这么做是为了减少浮点指针错误。再下一步,指定次数的操作(迭代)被执行。结束时,结束时间被抓取到,测试夹具销毁,本次执行的测量时间被返回,并且这个结果会被保存下来。
无论指定多少个样本,这个循环就像这样重复。如果样本没有指定(为零),那么测试将会重复运行直到一秒钟,或者至少采集了30个样本。当写到代码的这个特定部分时,显然这里存在有一种“if-else”的关系。不管怎么说,大量的代码都是如此重复着“if”与"else"的片段。这里可以使用一个老式的函数,但是利用std::function来定义一个 匿名函数(lambda)再自然不过,这样就可以调用它并使所有的代码整洁。(c++ 11真是一个奇妙的东西)最后,结果被打印到屏幕。
使用代码
Celero 使用 CMake 去提供跨平台构件。由于它使用得是 C++ 11,因而需要请求一个现在流行的编译器(Visual C++ 2012 or GCC 4.7+)。
一旦你的项目中加入了 Celero,你能够创建专门的基准项目和源文件。为了方便,一个头文件和aCELERO_MAINmacro 能提供给 main() ,来帮助你的基准项目自动去执行所有的基准测试。
下面有一个简单的 Celero 基准的例子:
#include <celero/Celero.h>
CELERO_MAIN;
// 运行一个自动的基线。
// Celero 保证能提供足够的采样来得到一个合理的测量结果
BASELINE(CeleroBenchTest, Baseline, 0, 7100000)
{
celero::DoNotOptimizeAway(static_cast<float>(sin(3.14159265)));
}
// 运行一个自动测试。
// Celero 保证能提供足够的采样来得到一个合理的测量结果
BENCHMARK(CeleroBenchTest, Complex1, 0, 7100000)
{
celero::DoNotOptimizeAway(static_cast<float>(sin(fmod(rand(), 3.14159265))));
}
// 运行一个手动测试。这是对一个样本进行每秒 7100000 次操作。
// Celero 保证能提供足够的采样来得到一个合理的测量结果。
BENCHMARK(CeleroBenchTest, Complex2, 1, 7100000)
{
celero::DoNotOptimizeAway(static_cast<float>(sin(fmod(rand(), 3.14159265))));
}
// 运行一个手动测试。这是对 60 个样本进行每秒 7100000 次操作。
// Celero 保证能提供足够的采样来得到一个合理的测量结果。
BENCHMARK(CeleroBenchTest, Complex3, 60, 7100000)
{
celero::DoNotOptimizeAway(static_cast<float>(sin(fmod(rand(), 3.14159265))));
}
这段代码中我们做的第一件事情,就是定义一个BASELINE测试用例。这个模版有四个参数:
BASELINE(GroupName, BaselineName, Samples, Operations)
* GroupName- 基准组的名字。它是用来将运行与结果和它们相应的基线测量收集到一起。
* BaselineName- 为了报表目的的基线的名字。
* Samples- 对测试代码进行给定次数的操作,对这些操作的总的循环运行次数。
* Operations- 你希望对每个样本运行测试代码的次数。
这里的样本与操作是用来测量非常快的代码的。例如,如果你知道基准测试中的代码运行时间小于100毫秒,那么在进行一次测量之前,这个操作次数将会指定代码运行"operations"次。而Samples则定义了要做多少次测量。
Celero允许指定零样本也有助于此。零样本将告诉Celero,基于完成指定次数操作所需要的时间,采集一些具有统计学意义数量的样本。这些数字将会在运行时给出。
celero::DoNotOptimizeAway模版是用来保证优化编译器不会消除你的函数或代码。由于这个功能被用于所有的基准样本以及它们的基线,所以相比较起来其中的额外时间消耗可以忽略不计。
在基线被定义之后,接着被定义的是各种各样的基准。BENCHMARK宏的语法与普通宏的语法完全相同。
结果
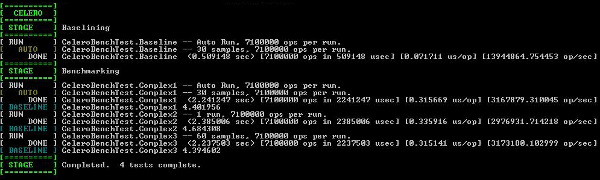
示例项目被设置为一旦成功编译就自动执行基准测试代码。在我的PC上运行这个基准测试得到的是以下的输出:
[ CELERO ]
[==========]
[ STAGE ] Baselining
[==========]
[ RUN ] CeleroBenchTest.Baseline -- Auto Run, 7100000 calls per run.
[ AUTO ] CeleroBenchTest.Baseline -- 30 samples, 7100000 calls per run.
[ DONE ] CeleroBenchTest.Baseline (0.517049 sec) [7100000 calls in 517049 usec] [0.072824 us/call] [13731773.971132 calls/sec]
[==========]
[ STAGE ] Benchmarking
[==========]
[ RUN ] CeleroBenchTest.Complex1 -- Auto Run, 7100000 calls per run.
[ AUTO ] CeleroBenchTest.Complex1 -- 30 samples, 7100000 calls per run.
[ DONE ] CeleroBenchTest.Complex1 (2.192290 sec) [7100000 calls in 2192290 usec] [0.308773 us/call] [3238622.627481 calls/sec]
[ BASELINE ] CeleroBenchTest.Complex1 4.240004
[ RUN ] CeleroBenchTest.Complex2 -- 1 run, 7100000 calls per run.
[ DONE ] CeleroBenchTest.Complex2 (2.199197 sec) [7100000 calls in 2199197 usec] [0.309746 us/call] [3228451.111929 calls/sec]
[ BASELINE ] CeleroBenchTest.Complex2 4.253363
[ RUN ] CeleroBenchTest.Complex3 -- 60 samples, 7100000 calls per run.
[ DONE ] CeleroBenchTest.Complex3 (2.192378 sec) [7100000 calls in 2192378 usec] [0.308786 us/call] [3238492.632201 calls/sec]
[ BASELINE ] CeleroBenchTest.Complex3 4.240175
[==========]
[ STAGE ] Completed. 4 tests complete.
[==========]
首次运行的测试将作为整个组测试的基线。这个基线显示出它是一个“自动测试”,暗示着由Celero来衡量并决策运行测试代码的次数。这个案例中,在我们的测试里它要运行7100000次代码迭代总共30次。(每调用7100000次测量一次,这样30次以后取最小的时间。)整个测量需要0.517049秒。基于这个结果,可以测量出每次对基准代码的调用需要0.072824毫秒。
在基线测试结束之后,将运行每个单独的测试。每个测试的运行与测量方式都是相同的,不过有一个额外的度量报告:基线。将它运行基准测试代码所需要的时间与基线进行比较。这里的数据显示,CeleroBenchTest.Complex1比基线运行需要的时间多了4.240004倍。
课外读物
- GitHub 项目点击 这里.
- 基准应该总是要在发行版本中运行。但这绝对不是要求建立一个调试工程,也不是要改变原本的结果。编译器(进行优化)将对你的代码的执行起到非常好的作用。
- Celero 在 Doxygen 中存放了 API 文档。
- Celero 对每一个基线组固定测试。
- 当监听到第三个存储槽时,执行代码使基准运行得更快。这是多么有趣的事啊!
原文:Celero - A C++ Benchmark Authoring Library
转载自:开源中国社区--super0555, 竟悟, jimmyjmh






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。