
熵
Entrophy:
sum([p*log(1/p) for each p])
p: 1次实验的, x的发生的次数的期望是 p
1/p : x发生1次, 期望要做的试验次数是 1/p
Example
- 硬币:
T: 1/2
H: 1/2
由霍夫曼编码,编码的期望长度最小是 1 bit
用熵来解释, T发生一次, 期望要做的试验次数是 2
log(2) = 1
1/2 * log(2) = 1/2
H也一样,于是就有:
1/2 + 1/2 = 1 (bit)
- 摸球
4个球 1个红球 2个绿球 1个黑球
红球的概率 1/4
绿球 2/4=1/2
黑球 1/4
1/4 * log(4) = 1/2
1/2 * 1 = 1/2
1/4 * 2 = 1/2
1/2 + 1/2 + 1/2 = 3/2 (bit)
期望的编码长度是 3/2, 同样和霍夫曼编码结果一样。
a, b 出现概率分别是 1/2, 熵是1, 所需要的比特位是1
1/p : 平均2个字符中会得到一个 a log(1/p):1个bit所代表的情况中平均能得到一个a
1/(1-p): 平均2个字符会得到一个 b log(1/(1-p)):1个bit所代表的情况中平均能得到一个b
需要bit的概率 =
出现一个a的概率 * 出现一个a的情况下需要多少bit +
出现一个b的概率 * 出现一个b的情况下需要多少bit
相对熵 (KL散度)
KL散度是两个概率分布P和Q差别的非对称性的度量。 KL散度是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的比特个数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
D(Q||P)=∑Q(x)[log(1/P(x))] - ∑Q(x)[log[1/Q(x)]]
=∑Q(x)log[Q(x)/P(x)]
∑Q(x)[log(1/P(x))] 表示使用原来的编码方式得到的比特数的期望
log(1/P(x)) 表示使用原来的编码方式,x出现1次的期望编码长度
Q(x) 表示现在x出现的概率
由于-log(u)是凸函数,因此有下面的不等式
DKL(Q||P) = -∑x∈XQ(x)log[P(x)/Q(x)] = E[-logP(x)/Q(x)] ≥ -logE[P(x)/Q(x)] = -log∑x∈XQ(x)P(x)/Q(x) = 0
即KL-divergence始终是大于等于0的。当且仅当两分布相同时,KL-divergence等于0。
举一个实际的例子吧:比如有四个类别,一个方法A得到四个类别的概率分别是0.1,0.2,0.3,0.4。另一种方法B(或者说是事实情况)是得到四个类别的概率分别是0.4,0.3,0.2,0.1,那么这两个分布的KL-Distance(A,B)=0.1*log(0.1/0.4)+0.2*log(0.2/0.3)+0.3*log(0.3/0.2)+0.4*log(0.4/0.1)
这个里面有正的,有负的,可以证明KL-Distance()>=0.
从上面可以看出, KL散度是不对称的。即KL-Distance(A,B)!=KL-Distance(B,A)
KL散度是不对称的,当然,如果希望把它变对称,
Ds(p1, p2) = [D(p1, p2) + D(p2, p1)] / 2
KL散度是两个概率分布P和Q差别的非对称性的度量。 KL散度是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的比特个数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
条件熵
条件熵是信息论中信息熵的一种度量,它表示如果已经完全知道第二个随机变量 X 的前提下,随机变量 Y 的信息熵还有多少。也就是 基于 X 的 Y 的信息熵,用 H(Y|X) 表示。同其它的信息熵一样,条件熵也用比特、奈特等信息单位表示。
具体有针对一个确定的Xj 的条件熵, 如果是针对一个随机变量而言, 条件熵是针对所有Xj的条件熵的期望

联合熵

P(x,y) 是联合概率
信息
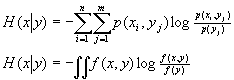
由对数性质和全概率公式
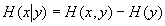
信息是通过熵与条件熵的差计量的
掷一次骰子,由于六种结局(点)的出现概率相等,所以结局的不确定程度(熵)为log6 ,如果告诉你掷骰子的结局是单数或者双数,这显然是一个信息。这个信息消除了我们的一些不确定性。把消除的不确定性称为信息显然是妥当的。
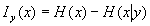
如果令公式中的y=x,H(x∣y)变成了H(x∣x),其含义当然是x已知时x的条件熵,可是x 已知时它自己当然没有不确定性了。所以H(x∣x)=0 。把它带入信息公式,得到
也就是说x 值已知时所带来的信息恰好等于原来的不确定性。或者说x。这正是在一些场合下把熵直接称为信息的原因。遗憾的是有些人没有理解这个认识过程,而引出了信息是熵或者信息是负的熵的概念混乱。
信息增益
熵降低的程度
信息是通过熵与条件熵的差计量的
互信息
http://zh.wikipedia.org/wiki/%E4%BA%92%E4%BF%A1%E6%81%AF
互信息(Mutual Information)是一有用的信息度量,它是指两个事件集合之间的相关性。两个事件X和Y的互信息定义为:
baike:
一般而言,信道中总是存在着噪声和干扰,信源发出消息x,通过信道后信宿只可能收到由于干扰作用引起的某种变形的y。信宿收到y后推测信源发出x的概率,这一过程可由后验概率p(x|y)来描述。相应地,信源发出x的概率p(x)称为先验概率。我们定义x的后验概率与先验概率比值的对数为y对x的互信息量,也称交互信息量(简称互信息)。

其意义:由于事件A发生与事件B发生相关联而提供的信息量。
该方法通过计算词条和类别的互信息,词条和类别的互信息越大,词条越能代表该种类别。其中词条和类别的互信息通过公式,
MI(T,C) = log( P(T|C)/P(T) )
MI(T,C) = H(C)-H(C|T)
熵 - 条件熵 , 这个和信息增益也有关系, 具体见 综合 部分.
其中P(T|C)是词条T在类别C中出现的概率,P(T)是词条T在整个训练集中出现的概率。
直观理解, 如果 T在整个训练集中出现的概率并不高,但是在类别C中出现的概率却很高, 那么就可以知道T可以很大程度上代表这个C, 分子类似于tf(但是包含了文档长度的考虑), 分母有点类似于IDF(但是又包含了各个文档中出现的term的个数,而不只是出没出现)。
用互信息的方法,在某个类别C中的出现概率高,而在其它类别中的出现概率低的词条T,将获得较高的词条和类别互信息,也就可能被选取为类别C的特征。
互信息是term的存在与否能给类别c的正确判断带来的信息量。
词条和类别的互信息体现了词条和类别的相关程度,互信息越大,词条和类别的相关程度也越大。得到词条和类别之间的相关程度后,选取一定比例的,排名靠前的词条作为最能代表此种类别的特征。
自信息
http://zh.wikipedia.org/wiki/%E8%87%AA%E4%BF%A1%E6%81%AF
自信息(英语:self-information),又译为信息本体,由克劳德·香农提出,用来衡量单一事件发生时所包含的信息量多寡。它的单位是bit,或是nats。

特征选择
决策树:
特征t能产生的信息增益 = 熵 - t对应的条件熵
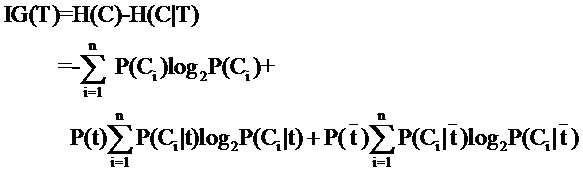
Xj -> X, 这里j只有两种取值, 有 或者 没有, 也就对应了决策树的两个分叉。
选择信息增益最大的特征。
实际中特征t可能是一个连续值,我们需要选一个阈值,大于阈值的就等同于t出现, 小于阈值的就等同于t不出现,这个阈值也需要遍历所有的样本集中t的取值来确定。 同样还是两个分叉。 假设有n个特征,m个样本(最坏在每个特征处有m个值, 这样寻找一次最大的信息增益的复杂度是 O(mn) 还是挺大的)
如果有一个样本集是这样
f1 f2 f3
c1 1 0 1
c2 0 1 0
c3 1 1 0
可以算c1 c2之间的相似度, 同样也可以算 f1, f2之间的相似度, 行和列而已, 实际中 c1 c2 c3不可能就一个样本
f1 f2 f3
c1 1 0 1
c1 1 1 1
c2 0 1 0
c2 1 1 0
c3 1 1 0
这时候直接算列的相似度就不好算了, 用互信息就可以,互信息就像是把类别作为一个doc, 特征作为term, 的tf-idf模型, 比如f3就很能代表c1, 同样, 用信息增益也可以算。
综合
Wiki : Information gain in decision trees
In information theory and machine learning, information gain is a synonym for Kullback–Leibler divergence. However, in the context of decision trees, the term is sometimes used synonymously with mutual information, which is the expectation value of the Kullback–Leibler divergence of a conditional probability distribution.
In particular, the information gain about a random variable X obtained from an observation that a random variable A takes the value A=a is the Kullback-Leibler divergence DKL(p(x | a) || p(x | I)) of the prior distribution p(x | I) for x from the posterior distribution p(x | a) for x given a.
证明:

http://www.cnblogs.com/xiedan/archive/2010/04/03/1703722.html
http://blog.sohu.com/people/f21996355!f/123258006.html
http://blog.sina.com.cn/s/blog_4d1f33470100sjuf.html
这篇文章提到互信息可以和 tf-idf 一样作为文档的关键词的权值







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。