
关于Relay与GraphQL的介绍
原文:Introducing Relay and GraphQL
视频地址(强烈建议观看):https://www.youtube.com/watch?v=9sc8Pyc51uU
React应用如何获取数据
如今,Web开发从单纯的构建界面变得更加接近应用(application)。数据获取是一个棘手的问题,特别是当应用变得复杂的时候。在React.js Conf上,Facebook公布了两个项目,用于帮助开发者简化数据层的问题,即使面对拥有众多参与者、复杂得像Facebook一样的项目。
这两个项目——Relay和GraphQL——已经在Facebook的产品中使用了一段时间了,我们很高兴将来能够把他们贡献给开源社区。现在,让我们先分享一些额外的信息。
什么是Relay
Relay是Facebook在React.js Conf(2015年1月)上首次公开的一个新框架,用于为React应用处理数据层问题。
在Relay中,每个组件都使用一种叫做GraphQL的查询语句声明对数据的依赖。组件可以使用this.props访问获取到的数据。
开发者可以自由地组合React组件,而Relay负责把不同组件的数据查询语句(原文的query)集中高效地组织并处理,向组件提供精确粒度的数据(没有多余数据),当数据变化时通知相应组件更新,并在客户端维护一份包含所有数据的数据缓存store。
什么是GraphQL
GraphQL是一种用于描述复杂、嵌套的数据依赖的查询语句。它已经在Facebook的原生APP上使用了多年。
在服务器端,我们通过配置将GraphQL与底层的数据查询代码映射起来。这层配置使得GraphQL可以访问不同的底层存储系统。Relay使用GraphQL作为数据查询语句,但并不指定GraphQL的具体实现。
理念
Relay是根据在Facebook构建大型应用的经验而诞生的。我们的首要任务是让开发者能以符合直觉的方式构建正确、高性能的WEB应用。它的设计使得即使是大型团队也能以高度隔离的方式应对功能变更。获取数据、数据变更、性能,都是让人头痛的问题。Relay则致力于简化这些问题,把复杂的部分交给框架处理,让开发者更加专注于应用本身。
将查询语句放到视图层代码中,开发者只需查看组件本身的代码就可以轻易理解组件的行为:不需要考虑和理解组件所处的上下文。组件可以在任何地方重用,而不用修改它的父组件或服务器端代码为它传递或准备数据。
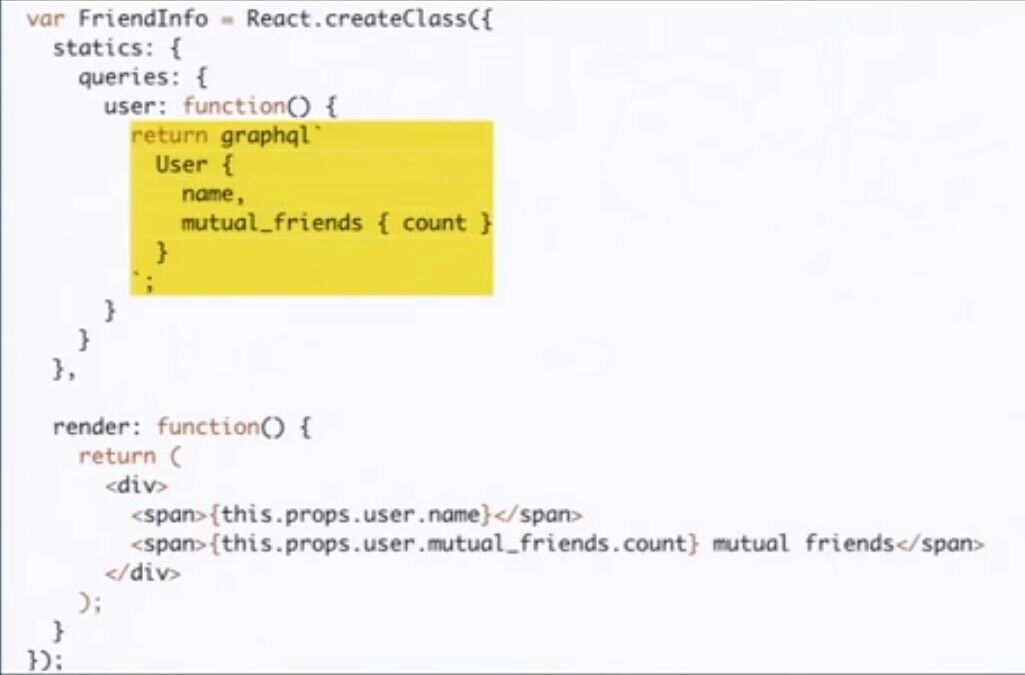
译者注:上图在原博中没有,为视频中截下来的代码截图,展示了Relay的query与展示代码混杂,图中黄色部分既为GraphQL语句。
代码混杂(原文为Co-location,意为将数据查询语句放在视图组件代码中)将开发者带入了“幸福的坑”(猜测此处的“坑”是指这种混杂看起来像是反模式),他们可以细粒度地获取需要的数据字段,而对粒度的声明就在视图层代码上。这意味着性能自然地得到了提升(更难获取冗余数据),而组件变得更加健壮(同样得益于显式的数据依赖声明,字段缺失的情况也得以避免,组件不会在运行时因为渲染缺失的字段而挂掉)。
Relay通过维护组件与数据间的依赖——在依赖的数据就绪前组件不会被渲染——为开发者提供更加可预测的开发环境。另外,数据查询语句是静态声明的(换句话说,我们可以在渲染前抽离分析整个组件树的查询语句),而GraphQL语法提供了对有效数据的准确描述,因此我们可以通过校验数据查询语句来尽早地发现开发者所犯的错误。
组件只能访问在数据查询语句中声明过的字段,即使其它字段已经被缓存在数据Store中(其它组件可能需要这些字段)。这杜绝了隐式的数据依赖导致的潜在bug。
通过统一的抽象来处理所有的数据获取工作,我们得以处理很多在应用中普遍而重复的问题:
- 性能: 所有的查询都经过框架统一处理,否则会变得非常低效。重复的查询会被自动合并并批处理成高效的、最小化的。同样地,框架知道哪些数据之前被请求过,或者哪些请求正在进行当中,因此数据查询可以自动去重至最小化。
- 监听: 所有的数据都存放在唯一的Store中,对该Store的读取也由框架管理。这意味着框架了解哪个组件关心哪些数据,数据变化时哪些组件应该重新渲染;组件不再需要自行监听数据更新。
- 公共范式: 可以更容易地构造公共范式。在大会上 Jing给出的例子是分页:如果你在初始状态有10条记录,翻页意味着声明你总共需要15条数据(注:每页5条记录,这儿的翻页类似于下拉刷新,新数据append到当前的后面),框架会分析出你需要和数据和现有数据之间的差值并构建最小查询,然后在服务器返回数据时更新视图。
- 简化服务器端: 相比于分散的响应端点(响应每个action,每个路由项),GraphQL接口可以作为底层资源对外的统一门面
- 统一处理数据变更: Relay有统一的处理数据变更(写数据)的模式,在概念上它被抽象成了数据查询模型。你可以理解成一次数据变更由两条数据查询语句组成:一条是带有副作用的——你提供描述变更的变量(例如:往一条记录中添加一条评论),另一条则指明了当变更完成后更新View视图所需要的数据(例如:评论总数),然后数据像正常的数据流一样被框架处理。我们可以乐观地立即渲染客户端,即在假设数据变更成功的前提下更新视图,在最后提交更新,如果服务器端返回异常则尝试重试或回滚视图。(注:此段翻译不是太有信心,原文的表述看得不怎么明白)
与Flux的关系
在某些方面Relay的灵感来自于Flux,但是理论模型变得更加简化。Relay用缓存所有GraphQL数据的唯一的store代替了Flux中分散的store;相对于Flux由组件自行监听数据变更,Relay用框架管理数据订阅和视图更新。 Instead of actions, modifications take the form of mutations
在Facebook,我们有完全使用Flux的项目,有完全使用Relay的项目,也有两者兼用的项目。一个我们逐渐意识到的模式是让Relay管理应用级的数据流,而让Flux管理数据之外的应用状态。
开源计划
我们正在努力让GraphQL(一个特殊的,参考级的实现)和Relay早日开源(暂时还没有明确的时间,但我们对于达成这一点非常兴奋)。
同时,我们会以博客(还有其它频道)的形式提供越来越多的信息。随着我们距离公布开源版本越来越近,你可以期待更多的细节、语法和API描述等等。
走着瞧吧
译者后记:
之前有看过Flux的相关资料,也试着自己写过基于Flux的框架和demo,但总觉得Flux更像一个半成品:对服务器端交互的问题没有很好地回答,手工订阅的action必定会面临膨胀等……
Relay像是Flux进一步成熟和发展的产物,某种程度上说甚至有了Angular的影子:更细粒度的声明式的数据依赖管理,框架监听处理数据变化。
目前的资料还比较少,很多问题需要等待更进一步的资料或代码才能弄明白,不过Relay可以说是继Flux后往前走的一大步,非常值得继续关注





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。