
在本文中,我将对 carbon 进程进行压力测试。这个涉及到在非常短的时间内发布大量指标。
增加每分钟产生的数量阈值
carbon-cache 配置文件限制了 Whisper 文件每分钟创建的数量。打开配置文件,并改变配置文件的设置。
# vi /opt/graphite/conf/carbon.conf
# Softly limits the number of whisper files that get created each minute.
# Setting this value low (like at 50) is a good way to ensure your graphite
# system will not be adversely impacted when a bunch of new metrics are
# sent to it. The trade off is that it will take much longer for those metrics'
# database files to all get created and thus longer until the data becomes usable.
# Setting this value high (like "inf" for infinity) will cause graphite to create
# the files quickly but at the risk of slowing I/O down considerably for a while.
MAX_CREATES_PER_MINUTE = 50
因为我们即将发布一堆指标,让我们修改配置文件的这部分,把值设为 1000。
MAX_CREATES_PER_MINUTE = 10000
注意:你需要重启你的 carbon cache 进程使得变更生效。
Stresser
我有一个 Stresser 应用程序可以定期地发布固定量的指标给 carbon-cache。它内部使用 Coda Hale 指标 library,更具体的说,它使用一个 Timer 对象收集数据。
Stresser 接收几个参数:
- Graphite 主机: 在我们的示例中,服务器位于我们的 carbon cache 主机上。
- Graphite 端口: 在我们的示例中,是 carbon cache 端口
- 主机数量:为了模拟发布
- 定时器数量:每个定时器生成 15 个独立的指标
- 发布间隔
- Debug 模式:true/false - 记录被发布的指标
你可以使用以下命令运行 Stresser:
java -jar stresser.jar localhost 2003 1 128 10 false
Coda Hale 指标 library 每 timer 生成 15个独立的指标。
# ls -l /opt/graphite/storage/whisper/STRESS/host/ip-0/com/graphite/stresser/feg/
total 300
-rw-r--r--. 1 root root 17308 Jun 4 11:22 count.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 m15_rate.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 m1_rate.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 m5_rate.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 max.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 mean_rate.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 mean.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 min.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 p50.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 p75.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 p95.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 p98.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 p999.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 p99.wsp
-rw-r--r--. 1 root root 17308 Jun 4 11:22 stddev.wsp
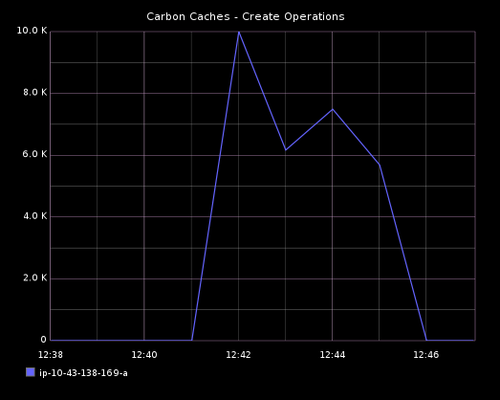
使用以上命令,指定 128 个定时器,发布到 carbon-cache 的独立指标数将是 1920 (128 * 15)。打开 dashboard,作为我们前面文章构建的一部分。你将看到被 carbon cache 执行创建操作数量的详细信息。我在 MAX_CREATES_PER_MINUTE 配置改变之前启动 Stresser。当它运行的时候,我改变这个配置文件,并重启 carbon-cache 进程。dashboard 上的创建操作图形显示发生了什么。在配置变更前,少量的创建操作以每分钟 10 个的速度执行。重启后,在一分钟之内,接近 1800 个创建操作发生了,因为阈值被设置成一个更高的值 10,000。
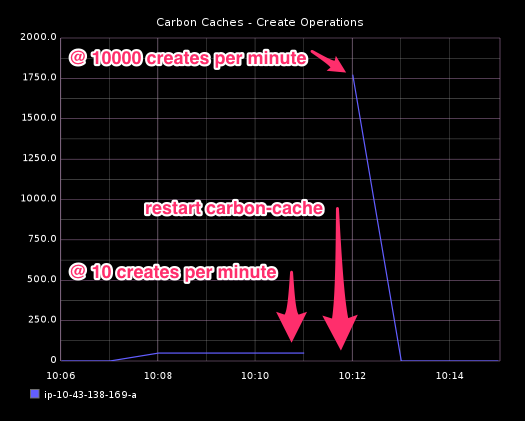
你也可以通过逐渐设置创建阈值到 10,000 并开启 Stresser 来测试行为。你将看到所有的 1920 个指标在同一分钟被创建。
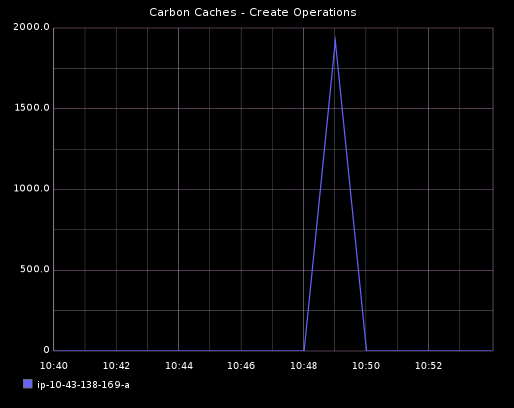
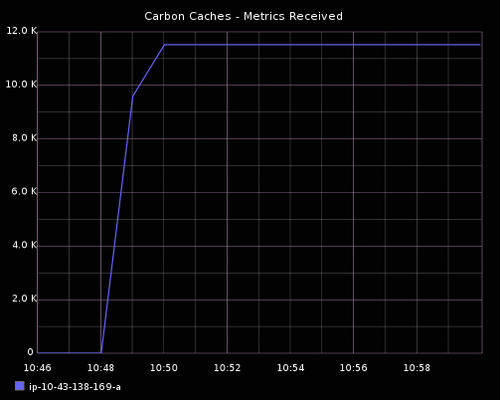
最终,每 10 秒发布的指标总数量是 1920。Carbon 进程指标每 60s 被存储一次。因此,被 carbon cache 每分钟接收到的指标数量将是 11,520 (1920 * 6)。
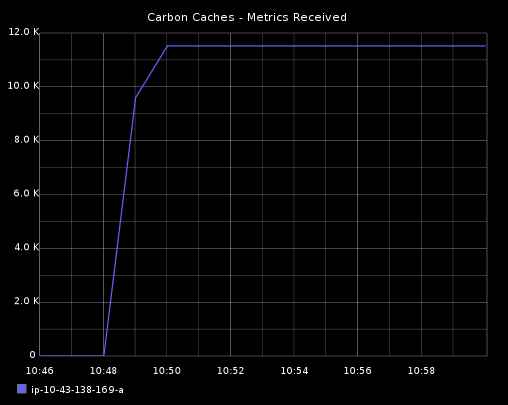
每分钟接收 11k 指标
现在我们有一种方式来发布指标到 carbon cache 并可视化它的行为,我们可以在限制值内发布它。随着指标正在被发布,运行 iostat 命令来测量 I/O 性能,因为 carbon cache 从磁盘中读写数据。
我已经配置了 Stresser 来做一下事情:
- 定时器数量: 128
- 发布间隔: 10 秒
- 每 10 秒发布的总指标: 1920 (128 * 15)
- 每分钟发布的总指标: 11,520 (1920 * 6)
java -jar stresser.jar localhost 2003 1 128 10 false
Initializing 128 timers - publishing 1920 metrics every 10 seconds from 1 host(s)
# iostat -x 10
Linux 2.6.32-431.11.2.el6.x86_64 (ip-10-43-138-169) 06/04/2014 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.50 0.00 0.38 0.35 0.00 98.77
Device: await svctm %util
xvdap1 5.28 0.32 0.26
xvdap1 6.56 0.39 0.16
xvdap1 40.25 0.33 3.62
xvdap1 37.94 0.31 3.13
xvdap1 6.39 0.54 0.44
每分钟接收 23k 指标
我们可以增加通过 Stresser 发布的指标数量,看它影响的 I/O 性能:
- 定时器数量: 256
- 发布间隔:10 秒
- 每 10 秒发布的总指标:3,840 (256 * 15)
- 每分钟发布的总指标: 23,040 (3,840 * 6)
java -jar stresser.jar localhost 2003 1 256 10 false
Initializing 256 timers - publishing 3840 metrics every 10 seconds from 1 host(s)

# iostat -x 10
Linux 2.6.32-431.11.2.el6.x86_64 (ip-10-43-138-169) 06/04/2014 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.08 0.00 0.08 0.04 0.00 99.80
Device: await svctm %util
xvdap1 51.48 0.38 6.97
xvdap1 48.06 0.38 6.96
xvdap1 21.10 0.39 1.30
xvdap1 45.21 0.58 1.48
xvdap1 60.48 0.49 13.19
注意到在这个时间点上 CPU activity 不高也是非常重要的。
每分钟 175K 指标
现在让我们大大地增加指标的发布率来看我们的设置是否可支撑。我将使用如下 Stresser 配置:
- 定时器数量: 1956
- 发布间隔:10 秒
- 每 10 秒发布的总指标:29,340 (1,956 * 15)
- 每分钟发布的总指标: 176,040 (29,340 * 6)
java -jar stresser.jar localhost 2003 1 1956 10 false
Initializing 1956 timers - publishing 29340 metrics every 10 seconds from 1 host(s)

# iostat -x 10
Linux 2.6.32-431.11.2.el6.x86_64 (ip-10-43-138-169) 06/04/2014 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.08 0.00 0.08 0.04 0.00 99.80
Device: await svctm %util
xvdap1 94.20 0.67 40.70
xvdap1 50.60 0.38 11.84
xvdap1 59.21 0.42 23.53
xvdap1 53.77 0.39 25.62
xvdap1 45.52 0.34 12.75

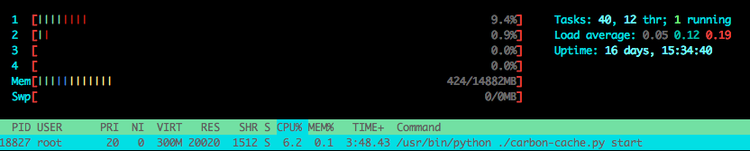
CPU 利用率和内存利用率稍稍增加了。注意 cache sizes 和 cache queues 也开始增长了在指标发率突然增加后。
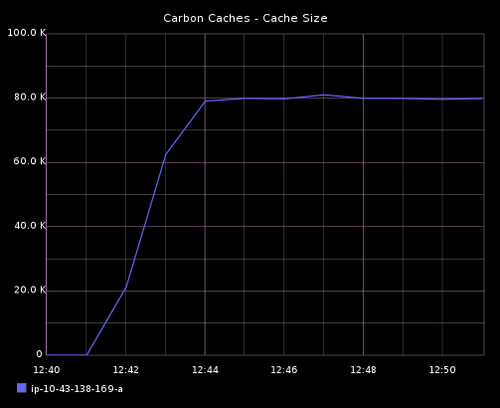
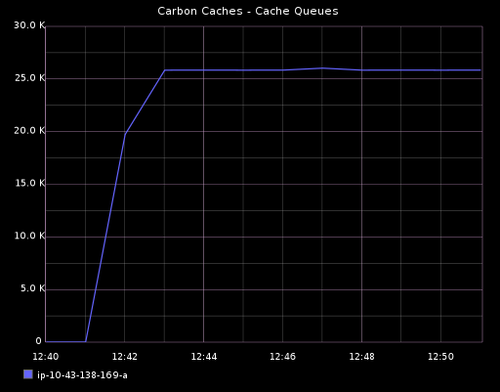
每分钟接收 440K 指标
使用以下 Stresser 配置:
- 定时器数量: 4887
- 发布间隔:10 秒
- 每 10 秒发布的总指标:73,305 (4,887 * 15)
- 每分钟发布的总指标: 439,830 (73,305 * 6)
java -jar stresser.jar localhost 2003 1 4887 10 false
Initializing 4887 timers - publishing 73305 metrics every 10 seconds from 1 host(s)
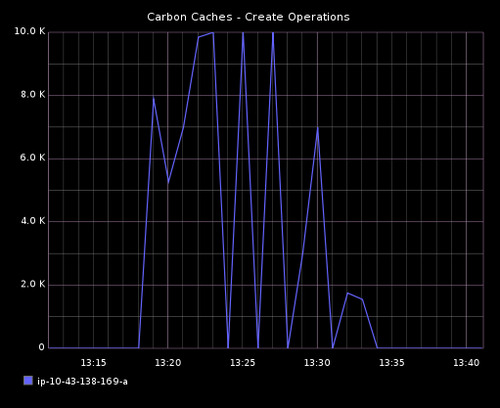

# iostat -x 10
Linux 2.6.32-431.11.2.el6.x86_64 (ip-10-43-138-169) 06/04/2014 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.08 0.00 0.08 0.04 0.00 99.80
Device: await svctm %util
xvdap1 98.76 0.74 44.29
xvdap1 83.43 0.62 22.61
xvdap1 82.47 0.62 33.51
xvdap1 123.14 0.88 52.00
xvdap1 106.97 0.75 45.58

对比前面的测试,内存消费从 500MB 增加到 900 MB,CPU activity 略有增加。如果你凝视 htop 的输出,你将每 10秒看到一个核心尖峰(指标发布频率)。
每分钟 700K 指标
使用以下 Stresser 配置:
- 定时器数量: 7824
- 发布间隔:10 秒
- 每 10 秒发布的总指标:117,360 (7,824 * 15)
- 每分钟发布的总指标: 704,160 (117,360 * 6)
java -jar stresser.jar localhost 2003 1 7824 10 false
Initializing 7824 timers - publishing 117360 metrics every 10 seconds from 1 host(s)
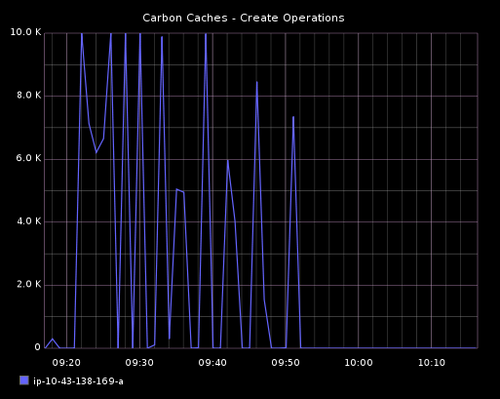

# iostat -x 10
Linux 2.6.32-431.11.2.el6.x86_64 (ip-10-43-138-169) 06/05/2014 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
12.93 0.00 5.53 6.40 0.49 74.65
Device: await svctm %util
xvdap1 241.67 1.73 58.34
xvdap1 263.33 1.83 100.00
xvdap1 256.01 1.88 54.32
xvdap1 228.32 1.63 100.00
xvdap1 474.27 3.20 100.00
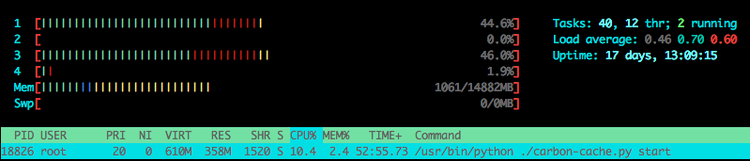
对 carbon cache 来说它花了 30 分钟来创建所有的新指标。对比前面的测试,这使用了更多的内存和 CPU 利用率。尽管如此,I/O 性能有更大的影响,因为 await 列报告值更大,在多个点百分利用率用显示 100%。cache queues 是非常高的但是仍然稳定, cache size 增加直到所有的指标被创建完成。然后直线围绕 1.5M 左右。


CARBON 做了什么?
Carbon 使用了一个动态 buffering 尽可能多的数据点的策略,因为需要维持输入数据点的速率,可能超过你的存储能跟上的 I/O 操作速率。在我们每分钟发布 11K 和 700K 指标到 Carbon cache 的以上场景中。在一个更简单的场景,比如说我们的 Stresser 应用程序被以以下方式方式:
- 每分钟发布的总指标:60,000 独立指标
让我们假设每 60,000 个不同的指标每分钟有单个数据点。因为一个指标在文件系统上是以一个 Whisper 文件呈现的,Carbon 将需要每分钟执行 60,000 次写操作 - 每个 Whisper 文件一个。为了处理指标发布率,Carbon 需要不到一毫米的时间写一个文件。在今天,这不是问题。
尽管如此,如果指标发布速率增加到一个很高的水平 - 像在我们的场景每分钟发布 700K 个指标 - 输入数据点的速率超过了可以被写入磁盘的速率。如果在 Graphite 服务器的磁盘不是 SSDs 或者有一个很低的速度时可能发生。
寻址时间
成千上万个 Whisper 文件被使用 ~12 或者每一个字节的数据频繁写入。磁盘明显会花费更多时间用于寻址。
写多个数据点
让我们假设磁盘的写速率不是太大,并且它没有大大增加,甚至如果我们买了更快的 SSDs。使得写更快的唯一方式就是少做,并且我们能做的更少如果我们 buffer 多个相关的数据点并且使用单个写操作把他们写入正确的 Whisper 文件。 Whisper 整理连贯的数据点连续写入磁盘。
update_many 函数
Chris Davis 决定修改 Whisper 和增加 update_many 函数。它需要一个列表的数据点作为单个指标并压缩相邻数据点到一个写操作。即使这使得写操作很大,它写 10个数据点 (~120 bytes) 相对于写一个数据点 (~12 bytes)花费的时间差异是可忽略的。在每个写的大小开始明显影响延迟这将需要相当多的数据点。
Buffers
为了在 Whisper 中使用 update_many 函数,在 Carbon 中实现了一个缓存机制。每个进入的数据点基于它的指标名字被映射到一个队列然后添加进队列 - 通过 Receiver 线程。另外一个线程 - Writer 线程 - 重复迭代所有的队列,对于每一个,它拉取出所有的数据点并使用 update_many 写入合适的 Whisper 文件。如果数据点进入速率超过了写速率,队列将最终持有更多的数据点。唯一花费的服务器资源是内存,这是可接受的,因为每个数据点只有几字节。
额外的福利:弹性
这种方法的优势是一定程度上的弹性来处理临时的 I/O 减速。如果系统需要做其他与 Graphite 无关的 I/O 操作,这时写速率可能减小。如果这个发生了,Carbon 队列将缓慢增长。队列越大,写越大。因为数据点的整体吞吐量等于写操作花费的每个写操作的平均大小比率。只要 queues 有足够内存 Carbon 可以持续保持。
实时图表
如果 Carbon 维护的在内存中的数据点队列等待被写回磁盘,这意味着这些数据点将不会显示在你的 graphite-webapp 图表上,对吗?错了!
一个 socket 监听器被添加到 Carbon,为访问缓存数据提供了一个查询接口。graphite-webapp 在它每次需要检索数据的时候使用这个查询接口。graphite-webapp 这时可以组合这些它从 Carbon 和 从在磁盘上 Whisper 文件检索的数据点。因此你的 graphite-webapp 图表将是实时的。一旦数据点被 Carbon 接收,就可以立即被访问。


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。