
在前面博客文章中,我们已经学到了怎样设置 Carbon (caches) 和 Whisper,发布指标和可视化信息以及 Carbon 进程的行为。在这篇博客中,我将介绍 Carbon 的另外一个特性 - 聚合器。
Carbon 聚合器
在把指标报告给 Whisper 之前,随着时间推移,Carbon 聚合器会缓冲指标。例如,让我们假设你有 10 个应用服务器报告每 10 秒接收到的请求数量。
PRODUCTION.host.ip-0.requests.m1_rate
PRODUCTION.host.ip-1.requests.m1_rate
PRODUCTION.host.ip-2.requests.m1_rate
PRODUCTION.host.ip-3.requests.m1_rate
PRODUCTION.host.ip-4.requests.m1_rate
PRODUCTION.host.ip-5.requests.m1_rate
PRODUCTION.host.ip-6.requests.m1_rate
PRODUCTION.host.ip-7.requests.m1_rate
PRODUCTION.host.ip-8.requests.m1_rate
PRODUCTION.host.ip-9.requests.m1_rate
以这种方式的数据点是非常有见地的。你或许想验证负载均衡功能实际上是否正确的以及服务器之间的负载是否是均衡的。
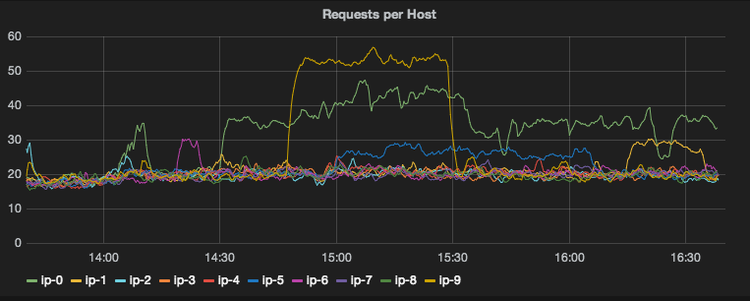
尽管如此,其他时候你可能仅仅对你服务器应用程序接收到的总请求数感兴趣。这通过一个 Graphite 函数可以非常容易在你的指标上实现。
sumSeries(PRODUCTION.host.*.requests.m1_rate)
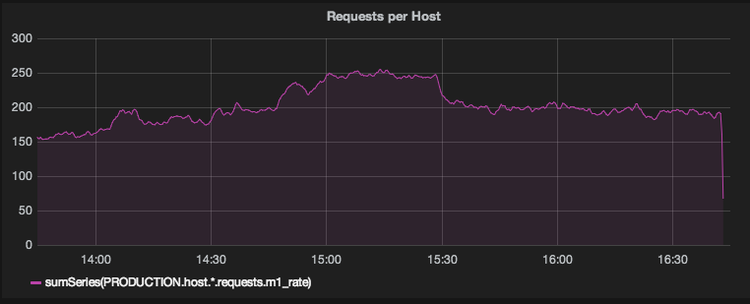
这种方法的问题就是操作是非常昂贵的。为了渲染图形我们首先需要从它们的相应 Whisper 文件中读取 10 个不同的指标,然后我们需要通过执行指定函数合并结果,最后构建图形。如果我们知道我们一直对哪些值的可视化感兴趣,我们可以通过预计算这些值来受益。
为了预计算这些值,我们可以定义一个匹配指标的正则表达式规则。在指定的时间缓冲它们,对缓冲数据执行一个函数,在一个单独的 Whisper 指标文件存储结果。在我们的示例中我们需要做以下工作:
- 指标匹配规则: PRODUCTION.host.*.requests.m1_rate
- 缓冲时间间隔: 60 秒
- 聚合函数: sum
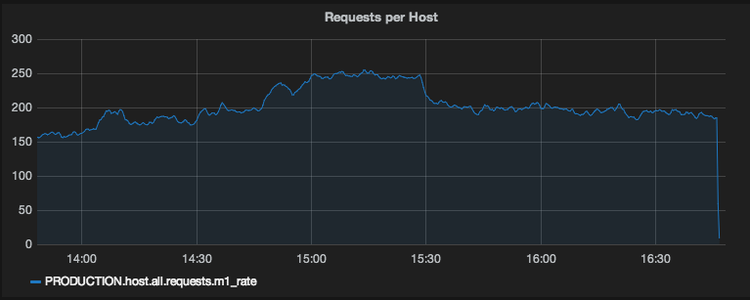
- 输出指标: PRODUCTION.host.all.requests.m1_rate
每个服务器的指标每 10秒报告到我们的环境中。结合这个配置,指标缓冲 6 个发布时间间隔,使用 sum 函数合并存储到输出的 Whisper 指标文件中。最后我们可以通过查询聚合指标数据来构建一个图形。
Carbon 进程栈

Carbon 聚合器可以被配置成运行在 Carbon caches 前面。输入的指标能被聚合器接收然后传递到 caches。
Carbon Cache
参考 Carbon & Whisper 博客中对于怎样配置和运行一个 Carbon cache 的操作指南。在我的环境中我使用以下配置 cache:
$ vi /opt/graphite/conf/carbon.conf
[cache]
LINE_RECEIVER_INTERFACE = 0.0.0.0
LINE_RECEIVER_PORT = 2003
PICKLE_RECEIVER_INTERFACE = 0.0.0.0
PICKLE_RECEIVER_PORT = 2004
CACHE_QUERY_INTERFACE = 0.0.0.0
CACHE_QUERY_PORT = 7002
我使用以下命令运行它:
$ cd /opt/graphite/bin
$ ./carbon-cache.py start
$ ps -efla | grep carbon-cache
1 S root 18826 1 4 80 0 - 156222 ep_pol Jun04 ? 02:04:31 /usr/bin/python ./carbon-cache.py start
Carbon 聚合器
对于 Carbon 聚合器,同样的 Carbon 配置文件有一个默认的设置:
$ vi /opt/graphite/conf/carbon.conf
[aggregator]
LINE_RECEIVER_INTERFACE = 0.0.0.0
LINE_RECEIVER_PORT = 2023
PICKLE_RECEIVER_INTERFACE = 0.0.0.0
PICKLE_RECEIVER_PORT = 2024
DESTINATIONS = 127.0.0.1:2004
AGGREGATION_RULES = aggregation-rules.conf
REWRITE_RULES = rewrite-rules.conf
我的 Carbon cache 进程的接收端口被设置成默认的(2004)。因此,我可以使用默认的配置启动一个聚合器进程,它可以与我的 cache 进程通信。
$ cd /opt/graphite/bin
$ ./carbon-aggregator.py start
$ ps -efla | grep carbon-aggregator
1 S root 23767 1 0 80 0 - 56981 ep_pol 13:53 ? 00:00:00 /usr/bin/python ./carbon-aggregator.py start
聚合规则
聚合规则配置文件是由多行指定的需要被聚合的指标以及它们应该怎样被组合组成。每行的格式如下:
output_template (buffering_time_interval) = function input_pattern
这将测量任何接收到的匹配 input_pattern 的指标用于计算一个聚合指标。这个计算将每 buffering_time_interval 秒发生。函数应用既可以是 sum 也可以是 avg。聚合指标的名字将从来 output_template 派生而来,填写来自 input_pattern 的任何捕获字段。使用前面博客的示例,我们可以构建如下聚合规则:
# aggregate all m1_rate metrics
<env>.host.all.<app_metric>.m1_rate (60) = sum <env>.host.*.<<app_metric>>.m1_rate
由于我发布的指标的性质,我知道所有的指标都将开始于环境,遵循主机字符串和正确的主机名。其余的指标字符串对应于实际的指标名称。以下是一个进入流量的统计分析和聚合指标的结果,通过以上的聚合规则。
Incoming: PRODUCTION.host.ip-0.requests.m1_rate
<env> = PRODUCTION
host.* = host.ip-0
<app_metric> = requests
m1_rate = m1_rate
Aggregate: PRODUCTION.host.all.requests.m1_rate
<env> = PRODUCTION
host.all = host.all
<app_metric> = requests
m1_rate = m1_rate
这时你有一个 Carbon 聚合进程运行一个单个聚合规则,发送数据点到一个 Carbon cache。我们可以开始发布数据点来观察行为。
聚合数据
在前面的文章中,我们使用了 Stresser 应用程序来发布指标到一个 Carbon cache。使用相同的参数修改,我们可以配置 Stresser 来发布指标到一个 Carbon 聚合器,以及模仿指标从多个主机发布 - 来测试聚合功能。使用以下配置:
- Publishing port: 2023 (aggregator)
- Number of timers: 2
- Number of hosts: 5
- Publishing interval: 10 seconds
- Total metrics published every 10 seconds: 150 metrics
- Total metrics published per minute: 900
- Debug mode: true
$ java -jar stresser.jar localhost 2023 5 2 10 true
Initializing 2 timers - publishing 150 metrics every 10 seconds from 5 host(s)
Publishing metric: STRESS.host.ip-0.com.graphite.stresser.a
Publishing metric: STRESS.host.ip-1.com.graphite.stresser.a
Publishing metric: STRESS.host.ip-2.com.graphite.stresser.a
Publishing metric: STRESS.host.ip-3.com.graphite.stresser.a
Publishing metric: STRESS.host.ip-4.com.graphite.stresser.a
Publishing metric: STRESS.host.ip-0.com.graphite.stresser.b
Publishing metric: STRESS.host.ip-1.com.graphite.stresser.b
Publishing metric: STRESS.host.ip-2.com.graphite.stresser.b
Publishing metric: STRESS.host.ip-3.com.graphite.stresser.b
Publishing metric: STRESS.host.ip-4.com.graphite.stresser.b
在 Stresser 开始不久之后,你可以检查正确的 Whisper 文件是否创建。明显地,每个独立指标的 Whisper 文件应该已经创建。
$ ls -l /opt/graphite/storage/whisper/STRESS/host/ip-*/com/graphite/stresser/a/
/opt/graphite/storage/whisper/STRESS/host/ip-0/com/graphite/stresser/a/:
-rw-r--r--. 1 root root 17308 Jun 6 14:27 m1_rate.wsp
/opt/graphite/storage/whisper/STRESS/host/ip-1/com/graphite/stresser/a/:
-rw-r--r--. 1 root root 17308 Jun 6 14:27 m1_rate.wsp
/opt/graphite/storage/whisper/STRESS/host/ip-2/com/graphite/stresser/a/:
-rw-r--r--. 1 root root 17308 Jun 6 14:27 m1_rate.wsp
/opt/graphite/storage/whisper/STRESS/host/ip-3/com/graphite/stresser/a/:
-rw-r--r--. 1 root root 17308 Jun 6 14:27 m1_rate.wsp
/opt/graphite/storage/whisper/STRESS/host/ip-4/com/graphite/stresser/a/:
-rw-r--r--. 1 root root 17308 Jun 6 14:27 m1_rate.wsp
但是更重要的,聚合指标应该也被创建:
$ ls -l /opt/graphite/storage/whisper/STRESS/host/all/com/graphite/stresser/a/
-rw-r--r--. 1 root root 17308 Jun 6 14:30 m1_rate.wsp
可视化聚集
我已经在 Graphite Webapp 创建了一个非常简单的仪表板来可视化我使用 Stresser 发布的指标。使用以下仪表板定义:
[
{
"target": [
"aliasByNode(STRESS.host.ip*.com.graphite.stresser.a.m1_rate,2)",
"aliasByNode(STRESS.host.all.com.graphite.stresser.a.m1_rate,2)"
],
"title": "Individual & Aggregate Rates"
}
]
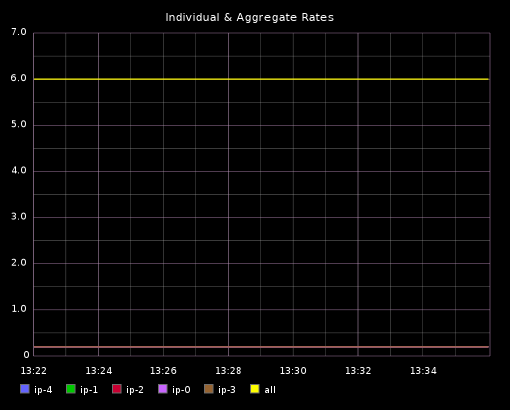
注意我们不再需要在独立的指标上应用函数来取得聚合数据,我们仅仅需要查询预先完成聚合数据的所有指标。
下一步
聚合规则可以被扩充来包含许多你需要聚合的指标。这里有些事情需要牢记:
- 随着匹配聚合规则的指标数量增长,因此聚合进程的内存使用 - 因为缓存数据点增长了。
- 确保在一个聚合规则中缓存间隔比指标发布间隔大。
原版 Graphite 系列:


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。