
看到 这篇文章,重拾计算机网络的知识,决定班门弄斧写一篇
下面的讨论基于最简单的情景:HTTP、无代理、不讨论功夫王、IPv4,并简单得从三个方面阐述。
浏览器会做些什么
- 接收 URL,并拆分成协议,网络地址,资源路径
- 与缓存进行比对,如果请求的对象在缓存中,则直接进行第九步
- 如果网络地址不是一个 IP 地址,向操作系统询问,操作系统返回一个IP地址
- 浏览器向服务器发起一个 TCP 连接
- 浏览器通过 TCP 连接向服务器发起 HTTP 请求,HTTP 三次握手,HTTPS 握手过程则复杂得多
- 浏览器接受 HTTP 响应,这时候它能关闭 TCP 连接也能为另一个连接保留。
- 检查 HTTP header 里的状态码,并做出不同的处理方式。比如:错误(
4XX、5XX),重定向(3XX),授权请求(2XX) - 如果是可以缓存的,这个响应则会被存储起来
- 浏览器进行解码响应,并决定如何处理该响应(比如HTML页面,图像,声音等等)
- 浏览器渲染响应,或者为不能识别的类型提供下载的提示框
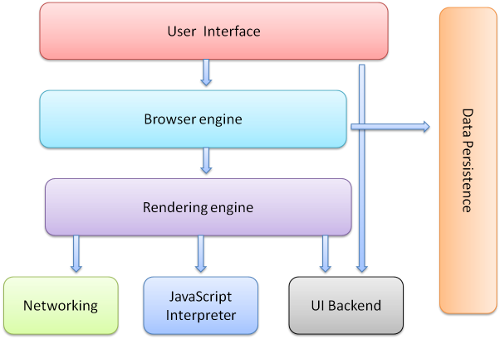
浏览器主要组件:
操作系统会做些什么
客户端
- 检查域名是否在本地的 host 的文件中,在则直接返回 IP 地址,不在则向 DNS 服务器请求
- DNS 服务器一级一级往上查询,直到查询到 IP 地址
服务器端
- 验证连接是否合法,如客户端 IP 地址是否符合防火墙的规则,端口号是否开启等
- 将请求转发到相应的端口
- 记录相应事件
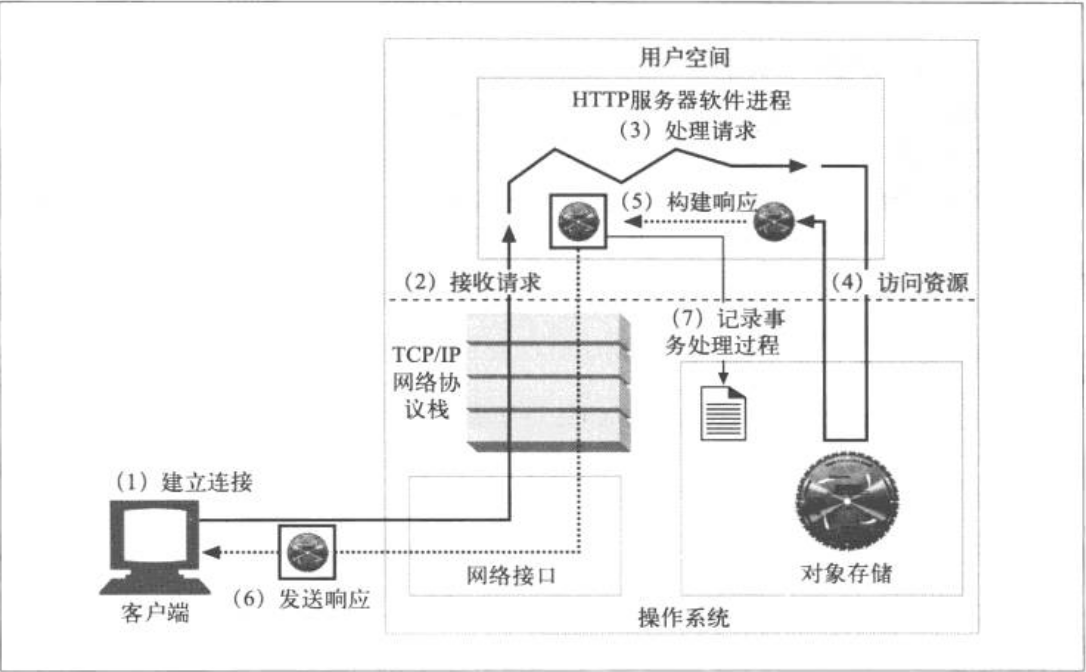
Web 服务器会做些什么
- 建立连接:接受一个客户端,或者如果不希望与这个客户端不能简历连接,就将其关闭
- 接收请求:从网络中读取一条 HTTP 请求报文
- 处理请求:对请求报文进行解释,并采取行动
- 访问资源:访问报文中指定的资源
- 构建响应:创建带有正确首部的 HTTP 响应报文
- 发送响应:将响应回送给客户端
- 记录事务处理过程:将已完成事务相关的内容记录在一个日志文件中
输入 URL 便能浏览互联网,其背后的计算机系统却要完成无数工作。上述过程中的每一步的背后都蕴含着无数人的智慧,每一步都可以展开成庞大的课题,真实的情景也要比提到的复杂很多。我想这正是科技最大的魅力,身处其中并得益于此,感谢各个领域的无数工程师为此付出的努力。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。