
docker很火很红,简直到了没有道理的地步了。docker为什么这么红?因为它是一种可以用来掀桌子的技术。在部署自动化这条产业上的工人和机床制造商们,看家护院的 cmdb,分布式脚本执行等所谓核心技术即便不会变成明日黄花,也会沦为二流技术。仅仅把 docker 当成一个轻量级 vmware 来使用,是没法看穿其实质的。要理解 docker 的意义,不能从 docker 是什么,能够干什么说起。让我们先来回忆一下集群管理模式的发展历程,以及这些落后的模式的种种弊端。
手工管理时代
IP地址是放在 excel 表里的。管理是靠登陆跳板机,用 SSH 连接服务器。手工执行命令做新的服务器部署,已有服务器的程序版本升级,以及各种配置刷新修改的工作。
弊端不言而喻,主要有这么几点:
- 缺乏一致性,因为是手工操作所以服务器之间总是有一些差异
- 效率低下,一个人可以管理的服务器数量非常有限
自动化大跃进时代
业务数量的增长,很快使得机器的数量超过手工操作维护的极限。无论再烂的团队,只要业务长到这个份上了,必然会出现大量的自动化工具用脚本自动化执行的方式快速地支撑业务。这个时代是一个黄金时代,运维真正长脸的时代。因为没有自动化的运维技术,业务就会遇到瓶颈。自动化技术的引入,切实地体现成了业务的收益。
这时代的特征是两个关键的系统
- 把本地 excel 表格里的 IP 地址用数据库的方式管理起来,称之为 CMDB
- 基于 ssh 或者 agent 的分布式脚本执行平台
效率低下了不再是主要问题,主要的弊端变为了:
- 大量的脚本,杂乱无章,内容重复,质量难以保证,最终给故障留下隐患
- 没有对现网预期状态的定义和管理,所有的现网状态都是脚本日积月累的产物,导致服务器状态漂移,产生雪花服务器(每个机器都不一样),进而给业务稳定性留下隐患
这些弊端短期对业务来说并没有立竿见影的伤害,属于内伤型的。而且很多隐患即便暴露了也会流于强调纪律,强调运维意识云云。很少会有人去追究背后的运维理念的问题。结果就是大部分公司都停留在这个阶段了。毕竟运维是一个足够用即可的支撑领域。运维搞得再高科技,特高可用,未必和创业公司的成功有多少直接联系。
开发闹革命时代
伴随 devops 同时出现的是 infrastructure as code 的提法。简单来说就是一帮开发杀到运维领域之后,看见这些运维居然是这样去管理现网状态的。于是他们把写代码的经验带过来,将现网状态建立成模型(所谓 code),把预期的状态提交到版本控制中。就像写代码一样,去管理服务器配置。
很多后台开发主导的小创业公司直接跳过了上个时代,运维自动化体系从一开始就是基于 puppet 和 chef 来搞的。平心而论,用 puppet 的更多是缺少历史包袱,而不是因为运维问题有多复杂。很多管理的机器数量不超过十台,却在如何使用 puppet/chef 上浪费大把时间的团队也是有的。相反很多大公司因为有沉重的历史包袱,和庞大的传统运维团队,这种开发闹革命的路反而走不通。
这种做法主要是解决了脚本的管理问题,而且因为直接定义了现网状态,服务器之间的一致性也会好很多。但是光鲜亮丽的模型背后本质上还是一堆脚本来驱动的。上个时代的弊端只是经过了包装和改良,并没有办法根除
- 应用预期状态到现网依靠的还是跑脚本。而且与之前不同,现在更多的是跑别人写的cookbook了,质量也是良莠不齐的
- 虽然定义了预期的现网状态,但是起点不同(比如从a=>c, b=>c)需要做的升级操作可能完全是不同的。要编写一个面面俱到的升级脚本其实非常困难。
还有哪些问题?
一致性和稳定性是最大的问题。服务器开机之后,常年是不重装系统的。无数人在上面跑过脚本,执行过命令,定位过问题。服务器实际的状态是没有办法精确管控的。infrastructure as code 是一种改良,但是仍未根除这个问题。每一次在服务器上跑脚本其实就是一种赌博,因为没有两台服务器是完全一样的。在本地测试可行的脚本,未必在另外一台上不会引起问题。这不是强调一下代码里不能 rm * ,而要 rm path/* 就可以解决的问题。
版本管理其实一直是没有的。做过开发的人,可能还会用 git/svn 来作为部署的基线,基本的版本都会提交到仓库里。更多的一线运维用的还是 rsync 的模式。rsync 的意思就是要安装一个新服务器,需要找一台“与之最像”的服务器。然后把文件拷贝到新服务器上,把配置修改一下,启动完事。携程出事了,我个人猜测应该与版本管理混乱有关系。
故障替换是非常困难的。先不说故障替换,就是故障机剔除就是一个头疼的事情。比如 zookeeper。各个客户端都硬编码三个 ip 地址。一旦其中一个 ip 挂掉了。zookeepr按照高可用协议可以保持正常,但是长期来说这个挂掉的ip还是要从各个使用方里剔除的。这个就且改了。一旦业务的高可用做得不好,需要运维来搞一些接告警之后替换故障机的事情,那就是各种脚本折腾各种配置文件的节奏了。
Docker 是如何掀桌子的
两点神论,进入到 Docker 时代之后
- CMDB 不再至关重要了。CMDB 连同IP,以及服务器资源变成底层蓝领工人关心的问题了。上层的后台开发和业务运维不再需要也无法再以 IP 为中心的 CMDB 来管理配置。
- 分布式脚本执行平台从核心作业系统退居二线。很简单,服务器不再需要变更了,常规的上新服务器,发布新版本都不再依赖脚本在一个已有的服务器上执行去修改状态。而是创建一个新的容器。
Docker的实质是一个真正的版本管理工具。在 Docker 之前版本管理是各种拼凑的解决方案。什么是版本,服务器是由三部分组成:版本、配置、数据。所谓版本就是操作系统,以及操作系统的配置。各种第三方包,开发给的可执行文件,和一部分配置文件。这些的集合是一个版本,其实就是一个完整的可执行环境。除此之外一般就是一个数据库,里面放了两部分内容,一部分是管理员可以从页面上修改的配置,一部分是业务数据。在 puppet 时代的版本,是一个申明文件。这个申明文件执行的时候,需要先从某个 ISO 安装出一个操作系统,然后用 apt-get/yum 从某个镜像源安装一堆系统的包,然后用 pip/bundle 安装一堆 python/ruby 语言层面的包,最后才是开发给你的 git/svn/某个不知名的tar.gz。你以为这些东西每次拼装出来的东西都是同样的版本么?其实未必。想当年某墙干掉 github 的时候,不知道多少人无法做发布了。Docker 打包出的连系统在一起的镜像,其实是对版本的最好阐述。
使用 Docker 之后不再需要修改现网的 container 了。一个 container 如果需要升级,那么就把它干掉,再把预先做好的新的镜像发布成一个新的 container 替换上去。分布式脚本执行,变成了分布式容器替换了。当然这种标准化的操作,用 mesos + marathon 已经完美解决了。
使用 Docker 之后,无法再基于 IP 做管理了。倒不是给每个 container 分配一个 IP 分配不过来,而是 IP 代表的静态模型无法跟上时代了。基于 IP 管理,就意味你会基于 SSH 登陆这个 IP 来管理。这种思想从骨子里就是落后的了。进程,进程组,模块,set 这些才是管理的粒度。至于进程是跑在哪个 IP 上的哪个容器里,不再重要了。一图可以说明这个问题;
上面这个扩容的按钮点完之后有让你填 IP 吗?没有!你只需要告诉marathon,我要32个进程实例。它就会去找这些资源运行这 32 个实例。业务最终需要的是 32 个进程,而不是 32 个 IP。IP只是运行进程需要的资源而已。实际运行的时候进程可能是在一个IP上启动了32个端口,也可能是随机分配了5个IP,每个各跑了一些端口。当然这些分配都是可以通过“约束”的方式表达的。而不是让你去搞32个IP来,再跑个脚本去这些IP上部署这些进程。
The Missing Piece
拼图游戏就差最后这一块了。Docker 做为一个版本工具是绝对合格的。Marathon 以 Docker 的方式托管所有进程也是靠谱的。但是还不完整:
- Docker镜像作为版本发布到现网之后是无法运行的,因为任何一个应用起码都有好几个服务要互相访问。这些硬编码在镜像里的 IP 地址换了一个环境是无法执行的。一个版本里任何配置都可以硬编码,就是 IP 地址和端口是没硬编码的。
- 扩容缩容可以很容易创建和销毁容器,但是引用了这个容器的服务器的其他容器怎么办呢?
- 发布,故障替换都是同样的问题
解决方案可以看这两张图:
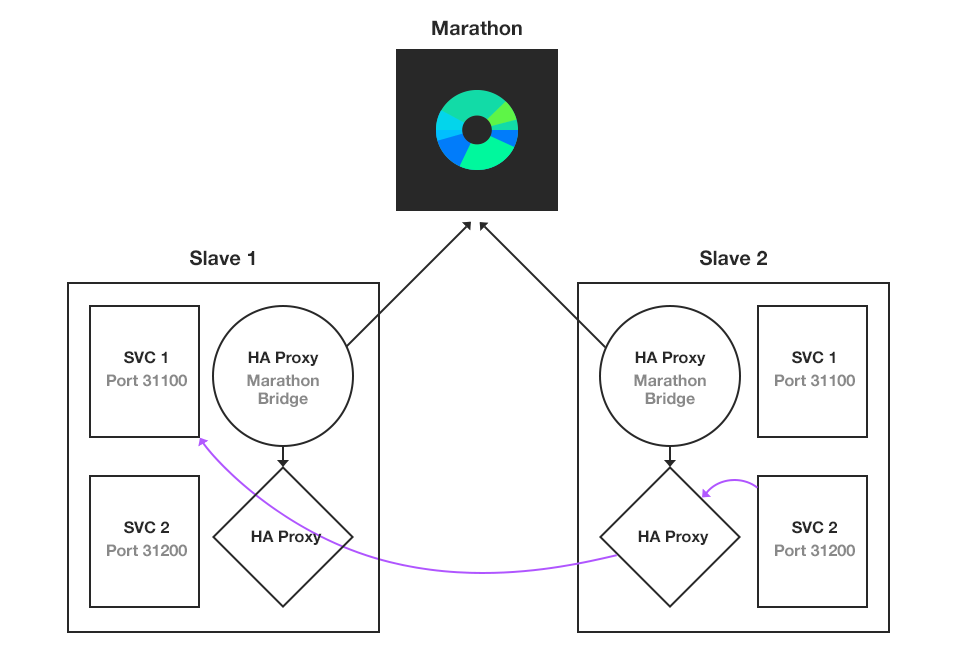
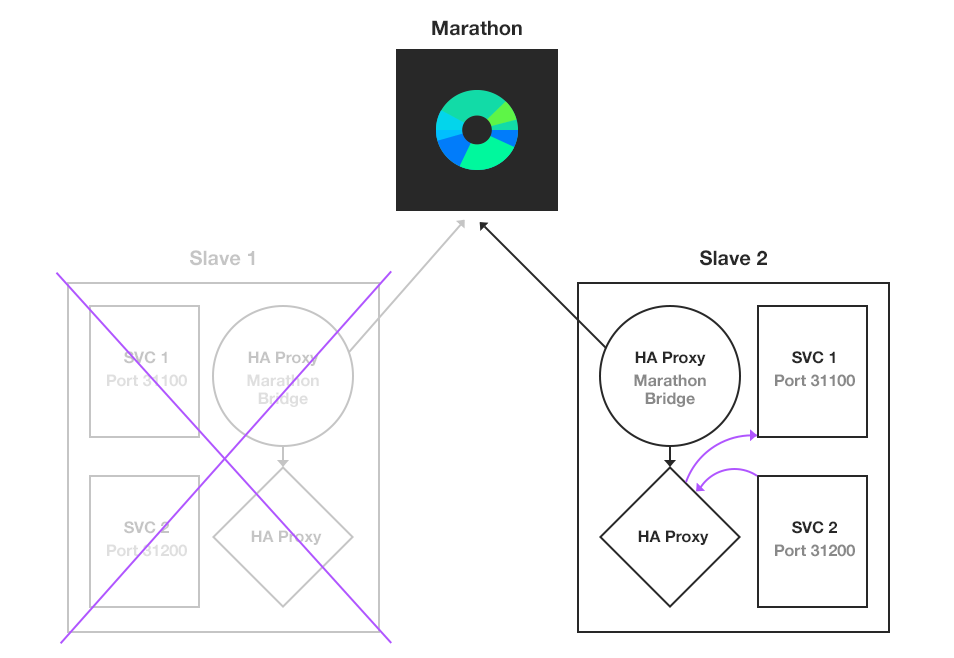
方案其实非常简单。把 app1 => app2 的网络访问关系,改成 app1 =local=> haproxy =network=> haproxy =local=> app2。通过在容器本地部署 haproxy “托管所有的端口”,也就是用 haproxy 在进程之间做联线,而不是每个进程自己去负责连接网络上的其他进程。
试想一下之前是在配置文件里硬编码 10.0.0.1:3306 是某台数据库。硬编码是不对的,是要打屁股的。所以我们把硬编码的 ip 地址改成 127.0.0.1:10010。这一次我们不再硬编码任何 IP 了,我们只硬编码一个特殊的端口号。每个进程都有一堆特殊的本地端口号用于访问自己需要的上下游服务。这个端口号背后的进程到底在哪个 IP,哪个 端口,哪个 container 里执行。做为使用方不需要修改任何代码(比如兼容什么 zookeeper/etcd 神马的),也不用关心。甚至这个端口后面是多个远程的IP构成一个基于客户端的高可用。代理甚至还可以做一些出错换一个后端再重试的事情。
有了这种神器之后,扩容所容,发布变更,故障替换都很轻松了。容器随便新增,随便删除。网络结构变化了之后,刷新各个地方的 haproxy 配置就是了。各种灰度,各种零停机替换方案都可以搞起。
名字服务与网络
类似的方案有很多。最底层的方案是 SDN/IP 漂移,以及网络的bonding。这种方案的特点是保持 IP 地址作为最传统的名字服务,妄图延续其生命。
上层一点的方案是 DNS。再上层一些的方案是 Zookeeper。
各种方案争的就是服务如何注册自己,如何彼此发现这个点。各种方案的优缺点可以自己去读:
http://nerds.airbnb.com/smartstack-service-discovery-cloud/
https://blog.docker.com/tag/smartstack/
btw,airbnb 在 13 年就把这套方案投入生产了。
最有意思的是把这种 haproxy 的方案与基于 SDN 的 IP 漂移方案做对比。haproxy 的就是替网络做应用层进程之间联线的事情,通过引入 haproxy 让这种联线更具有灵活性。 而 SDN 的方案是说,你现在的业务进程之间是通过 IP 之间静态链接的,这种连接不够灵活没关系,路由器帮你整。一个 IP 挂掉了,可以把IP漂移到另外一台机器上去继续使用。其实就是在一个场景下实现两个进程的重新联线,突破两 IP 之间静态互访的限制,给基于 IP 的部署方案续命。
两者底层的技术是相通的。所谓 IP 漂移最后靠的是现代牛逼的CPU,和软件路由技术。最后玩的都是用户态转发,dpdk神马的。所以 haproxy 慢,转发效率有问题神马的,长期来看都不会是问题。用软件来联线,是趋势。连路由器都开始这么玩了,连硬件厂商都开始卖软件了。
The Final Battle
集群管理纯粹变成进程管理,IP不再重要,状态不再重要。CMDB会变得越来越边缘化。
发布变更不再是去修改服务器,而是新建销毁容器,以及更新进程间网络联线关系。分布式作业系统会越来越少用,跳板机就更加不允许使用了。
记住“immutable servers”这个提法吧,它终将会得到历史的认可。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。