
Abstract
介绍Trie树的性质和构造方法。
最终用来统计一片文章各个单词出现的频率。
最终结果:
Trie
Trie树是一种数据结构,对于词频统计,文本检索非常有效。
Trie树的大小取决与要统计的文本的字母个数。比如只统计26个英文字母的话,单词最大长度为10的话,占用的空间最多是26^10。但实际上并没有这么恐怖。因为没有abc这样的单词。
在Trie中,将没一个字母作为一个node,其中含有几个信息
c#define R 26 typedef struct node { int value;// ASCII码 int frequecy;//c出现的频率 struct node* child[R];//有R个孩子,初始为NULL }Node;
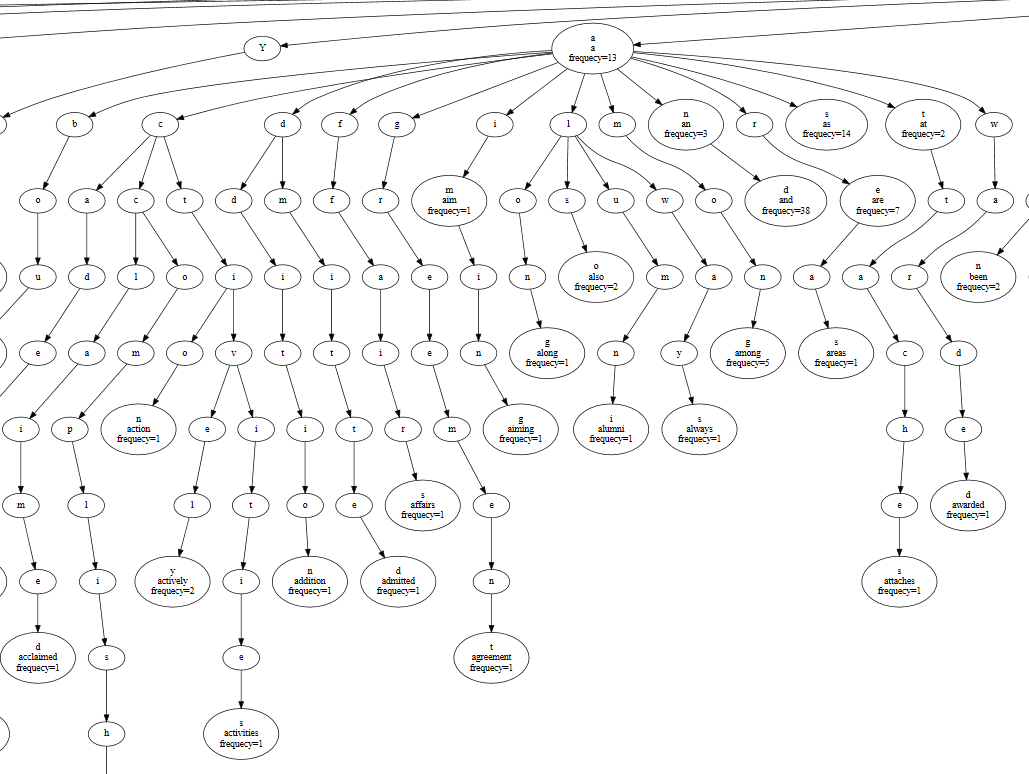
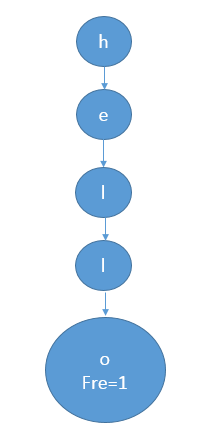
下面用hello这个单词举例子。
第一个节点是h,且h有一个孩子l。往后类似。到了最后的o,此时才是一个真正的单词,所以o的frequecy为1.
建立Trie树的时候,每次都是从Root出发,当再次遇到单词hello时,还是顺着这条路走下来,到o的时候将frequecy=2。
如果碰到的单词是helloworld,则插入后的结果为
可以看到,frequency>0的节点,说明从root到这个节点的路径上的所有字母节点构成了一个单词,且单词出现的频率就是frequecy。

所以,树的高度与文本中的单词的最大长度有关,但实际上最长的单词也没几个字母……尤其是当不同的单词具有相同前缀的时候,前缀的路径是共用的。利用这个性质,Trie在前缀搜索上变现也不错。
当拿到一个文本文档时,我们可以通过一遍扫描将trie建立,通过遍历trie得到所有词出现的频率。




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。