
概述
kubernetes中pods是平凡的,可创建可销毁而且不可再生。 ReplicationControllers可以动态的创建&销毁pods(如扩容 or 缩容 or 更新)。虽然pods有他们单独的ip,但是他们的ip并不能得到稳定的保证,这将会导致一个问题,如果在kubernetes集群中,有一些pods(backends)为另一些pods(frontend)提供一些功能,如何能保证frontend能够找到&链接到backends。
引入Services。
kubernetes services是一个抽象的概念,定义了如何和一组pods相关联—— 有时候叫做“micro-service”。一个service通过Label Selector来筛选出一组pods(下文会说明什么情况下不需要selector)。
举个栗子,设想一个拥有三个节点的图片处理backend,这三个节点都可以随时替代——frontend并不关系链接的是哪一个。即使组成backend的pods发生了变动,frontend也不必关心连接到哪个backend。services将frontend和backend的链接关系解耦。
对于kubernetes本身的应用来说,kubernetes提供了一个简单的endpoint 的api,对于非kubernetes本身的应用,kubernetes为servicet提供了一个解决方案,通过一个设定vip的bridge来链接pods。
定义一个service
在kubernetes中,services和pods一样都是一个REST对象。同其他的REST对象一样,通过POST来创建一个service。比如,有一组pods,每个pod对外暴露9376端口 他们的label为“app=MyApp”:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376
}
]
}
}
上述的json将会做以下事情:创建一个叫“my-service”的service,它映射了label为“app=MyApp”的pods端口9376,这个service将会被分配一个ip(cluster ip),service用这个ip作为代理,service的selector将会一直对pods进行筛选,并将起pods结果放入一个也焦作“my-service”的Endpoints中。
注意,一个service可能将流量引入到任何一个targetPost,默认targetPort字段和port字段是相同的。有趣的是targetPort 也可以是一个string,可以设定为是一组pods所映射port的name。在每个pod中,这个name所对应的真实port都可以不同。这为部署& 升级service带来了很大的灵活性,比如 可以在
kubernetes services支持TCP & UDP协议,默认为tcp。
Services without selectors
kubernetes service通常是链接pods的一个抽象层,但是service也可以作用在其他类型的backend。比如:
- 在生产环境中你想使用一个外部的database集群,在测试环境中使用自己的database;
- 希望将一个service指向另一个namespace中的service 或者 指向另外一个集群;
- 希望将非kubernetes的工作代码环境迁移到kubernetes中;
在以上任意一个情景中,都可以使用到不指定selector的service:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376
}
]
}
}
在这个例子中,因为没有使用到selector,因此没有一个明确的Endpoint对象被创建。 因此需要手动的将service映射到对应的endpoint:
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"subsets": [
{
"addresses": [
{ "IP": "1.2.3.4" }
],
"ports": [
{ "port": 80 }
]
}
]
}
无论有没有selector都不会影响这个service,其router指向了这个endpoint(在本例中为1.2.3.4:80)。
虚IP & service代理(Virtual IPs and service proxies)
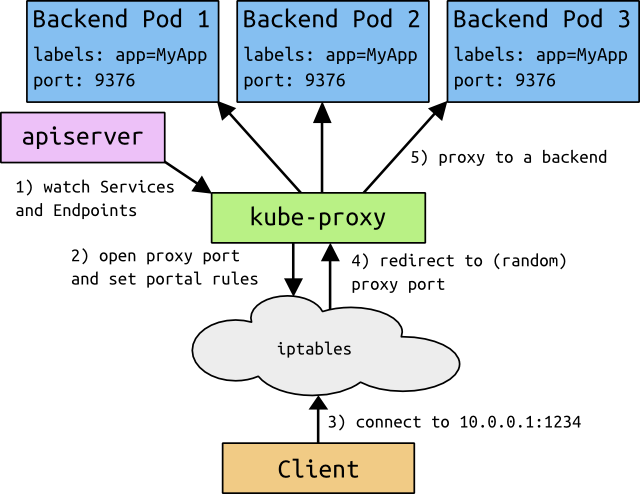
kubernetes中的每个node都会运行一个kube-proxy。他为每个service都映射一个本地port,任何连接这个本地port的请求都会转到backend后的随机一个pod,service中的字段SessionAffinity决定了使用backend的哪个pod,最后在本地建立一些iptables规则,这样访问service的cluster ip以及对应的port时,就能将请求映射到后端的pod中。
最终的结果就是,任何对service的请求都能被映射到正确的pod中,而client不需要关心kubernetes、service或pod的其他信息。
默认情况下,请求会随机选择一个backend。可以将service.spec.sessionAffinity 设置为 "ClientIP" (the default is "None"),这样可以根据client-ip来维持一个session关系来选择pod。
在kubernetes中,service是基于三层(TCP/UDP over IP)的架构,目前还没有提供专门作用于七层(http)的services。
Multi-Port Services
在很多情况下,一个service需要对多个port做映射。下面举个这样的例子,注意,使用multi-port时,必须为每个port设定name,如:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"name": "http",
"protocol": "TCP",
"port": 80,
"targetPort": 9376
},
{
"name": "https",
"protocol": "TCP",
"port": 443,
"targetPort": 9377
}
]
}
}
Choosing your own IP address
用户可以为service指定自己的cluster ip,通过字段spec.clusterIP来实现。用户设定的ip必须是一个有效的ip,必须符合service_cluster_ip_range 范围,如果ip不合符上述规定,apiserver将会返回422。
Why not use round-robin DNS?
有一个问题会时不时的出现,为什么不用一个DNS轮询来替换vip?有如下几个理由:
- 已经拥有很长历史的DNS库不会太注意DNS TTL 并且会缓存name lookup的结果;
- 许多应用只做一次name lookup并且将结果缓存;
- 即使app和dns库做了很好的解决,client对dns做一遍又一遍的轮询将会增加管理的复杂度;
我们做这些避免用户做哪些作死的行为,但是,如果真有那么多用户要求,我们会提供这样的选择。
Discovering services
对于每个运行的pod,kubelet将为其添加现有service的全局变量,支持Docker links compatible变量 以及 简单的{SVCNAME}_SERVICE_HOST and {SVCNAME}_SERVICE_PORT变量。
比如,叫做”redis-master“的service,对外映射6379端口,已经被分配一个ip,10.0.0.11,那么将会产生如下的全局变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
这意味着一个顺序依赖——service要想被pod使用,必须比pod先建立,否则这些service环境变量不会构建在pod中。DNS没有这些限制。
DNS
一个可选的扩展(强烈建议)是DNS server。DNS server通过kubernetes api server来观测是否有新service建立,并为其建立对应的dns记录。如果集群已经enable DNS,那么pod可以自动对service做name解析。
举个栗子,有个叫做”my-service“的service,他对应的kubernetes namespace为”my-ns“,那么会有他对应的dns记录,叫做”my-service.my-ns“。那么在my-ns的namespace中的pod都可以对my-service做name解析来轻松找到这个service。在其他namespace中的pod解析”my-service.my-ns“来找到他。解析出来的结果是这个service对应的cluster ip。
Headless services
有时候你不想做负载均衡 或者 在意只有一个cluster ip。这时,你可以创建一个”headless“类型的service,将spec.clusterIP字段设置为”None“。对于这样的service,不会为他们分配一个ip,也不会在pod中创建其对应的全局变量。DNS则会为service 的name添加一系列的A记录,直接指向后端映射的pod。此外,kube proxy也不会处理这类service
,没有负载均衡也没有请求映射。endpoint controller则会依然创建对应的endpoint。
这个操作目的是为了用户想减少对kubernetes系统的依赖,比如想自己实现自动发现机制等等。Application可以通过api轻松的结合其他自动发现系统。
External services
对于你应用的某些部分(比如frontend),你可能希望将service开放到公网ip,kubernetes提供两种方式来实现,NodePort and LoadBalancer。
每个service都有个type字段,值可以有以下几种:
- ClusterIP: 使用集群内的私有ip —— 这是默认值。
- NodePort: 除了使用cluster ip外,也将service的port映射到每个node的一个指定内部port上,映射的每个node的内部port都一样。
- LoadBalancer: 使用一个ClusterIP & NodePort,但是会向cloud provider申请映射到service本身的负载均衡。
注意:NodePort支持TCP/UDP,LoadBalancer只支持TCP。
Type = NodePort
如果将type字段设置为NodePort,kubernetes master将会为service的每个对外映射的port分配一个”本地port“,这个本地port作用在每个node上,且必须符合定义在配置文件中的port范围(为--service-node-port-range)。这个被分配的”本地port“定义在service配置中的spec.ports[*].nodePort字段,如果为这个字段设定了一个值,系统将会使用这个值作为分配的本地port 或者 提示你port不符合规范。
这样就方便了开发者使用自己的负载均衡方案。
Type = LoadBalancer
如果在一个cloud provider中部署使用service,将type地段设置为LoadBalancer将会使service使用人家提供的负载均衡。这样会异步的来创建service的负载均衡,在service配置的status.loadBalancer字段中,描述了所使用被提供负载均衡的详细信息,如:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376,
"nodePort": 30061
}
],
"clusterIP": "10.0.171.239",
"type": "LoadBalancer"
},
"status": {
"loadBalancer": {
"ingress": [
{
"ip": "146.148.47.155"
}
]
}
}
}
这样外部的负载均衡方案将会直接作用在后端的pod上。
Shortcomings
通过iptables和用户控件映射可以很好的为中小型规模服务,但是并不适用于拥有数千个service的集群。详情请看” the original design proposal for portals“。
使用kube-proxy不太可能看到访问的源ip,这样使得某些类型防火墙实效。
LoadBalancers 只支持TCP.
type字段被设计成嵌套的结构,每一层都被增加到了前一层。很多云方案提供商支持的并不是很好(如,gce没有必要分配一个NodePort来使LoadBalancer正常工作,但是AWS需要),但是当前的API需要。
Future work
The gory details of virtual IPs
以上的信息应该足够用户来使用service。但是还是有许多东西值得大家来深入理解。
(懒得翻了,大家自己看吧,最后贴上最后一个图)







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。