
原文地址:这里
Google 最近开源了它的第二代人工智能与数值计算库TensorFlow。TensorFlow由Google大脑团队开发,并且能够灵活地运行在多个平台上——包括GPU平台与移动设备中。

TensorFlow的核心就是使用所谓的数据流,可以参考Wikipedia上的有关于Genetic Programming 的相关知识,譬如:
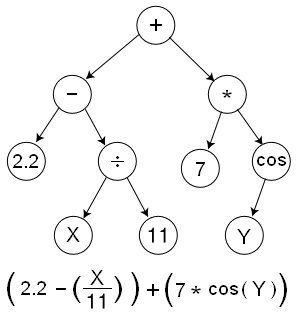
正如你理解的,整个以树状图的架构来表示整个计算流。每个节点即代表一个操作,TensorFlow称作OPS,即operations的缩写。非叶子节点还是很好理解的,一些叶子节点可以是特殊的操作类型,譬如返回一个常量值(譬如上述树中的7或者2.2)。其他的一些叶子节点,譬如X或者Y这样的,被当做placeholders,即会在运行中被动态地注入值。如果仔细观察上图中的箭头的指向,可以发现这些箭头指向就表明了不同节点之间输出的依赖关系。因此,Data(在TensorFlow中被称为Tensors),会在不同的节点之间逆向流动,这就就是他们被称为TensorFlow的原因。TensorFlow也提供了其他的基于图像抽象的组件,譬如持久化的数据存储(被称为Variables),以及在譬如神经网络这样的应用中对于Variables中的参数微调而进行的优化手段。
TensorFlow提供了非常有好的Python的接口,在看本篇文章之前建议阅读以下:
2.参阅这个例子 来对TensorFlow的代码风格有一个模糊的认识。
3.接下来这个解释 会阐述TensorFlow中的基础的组件。
4.参考详细的例子 来看看TensorFlow是怎么解决常见的ML问题的。
5.在了解上述的基本知识后,可以阅读Python docs这个接口文档来作为开发中的参考。
接下来,我会以用TensorFlow来解决常见的K-Means问题作为例子来阐述如何使用它。
import tensorflow as tf
from random import choice, shuffle
from numpy import array
def TFKMeansCluster(vectors, noofclusters):
"""
K-Means Clustering using TensorFlow.
`vertors`应该是一个n*k的二维的NumPy的数组,其中n代表着K维向量的数目
'noofclusters' 代表了待分的集群的数目,是一个整型值
"""
noofclusters = int(noofclusters)
assert noofclusters < len(vectors)
#找出每个向量的维度
dim = len(vectors[0])
#辅助随机地从可得的向量中选取中心点
vector_indices = list(range(len(vectors)))
shuffle(vector_indices)
#计算图
#我们创建了一个默认的计算流的图用于整个算法中,这样就保证了当函数被多次调用 #时,默认的图并不会被从上一次调用时留下的未使用的OPS或者Variables挤满
graph = tf.Graph()
with graph.as_default():
#计算的会话
sess = tf.Session()
##构建基本的计算的元素
##首先我们需要保证每个中心点都会存在一个Variable矩阵
##从现有的点集合中抽取出一部分作为默认的中心点
centroids = [tf.Variable((vectors[vector_indices[i]]))
for i in range(noofclusters)]
##创建一个placeholder用于存放各个中心点可能的分类的情况
centroid_value = tf.placeholder("float64", [dim])
cent_assigns = []
for centroid in centroids:
cent_assigns.append(tf.assign(centroid, centroid_value))
##对于每个独立向量的分属的类别设置为默认值0
assignments = [tf.Variable(0) for i in range(len(vectors))]
##这些节点在后续的操作中会被分配到合适的值
assignment_value = tf.placeholder("int32")
cluster_assigns = []
for assignment in assignments:
cluster_assigns.append(tf.assign(assignment,
assignment_value))
##下面创建用于计算平均值的操作节点
#输入的placeholder
mean_input = tf.placeholder("float", [None, dim])
#节点/OP接受输入,并且计算0维度的平均值,譬如输入的向量列表
mean_op = tf.reduce_mean(mean_input, 0)
##用于计算欧几里得距离的节点
v1 = tf.placeholder("float", [dim])
v2 = tf.placeholder("float", [dim])
euclid_dist = tf.sqrt(tf.reduce_sum(tf.pow(tf.sub(
v1, v2), 2)))
##这个OP会决定应该将向量归属到哪个节点
##基于向量到中心点的欧几里得距离
#Placeholder for input
centroid_distances = tf.placeholder("float", [noofclusters])
cluster_assignment = tf.argmin(centroid_distances, 0)
##初始化所有的状态值
##这会帮助初始化图中定义的所有Variables。Variable-initializer应该定 ##义在所有的Variables被构造之后,这样所有的Variables才会被纳入初始化
init_op = tf.initialize_all_variables()
#初始化所有的变量
sess.run(init_op)
##集群遍历
#接下来在K-Means聚类迭代中使用最大期望算法。为了简单起见,只让它执行固 #定的次数,而不设置一个终止条件
noofiterations = 100
for iteration_n in range(noofiterations):
##期望步骤
##基于上次迭代后算出的中心点的未知
##the _expected_ centroid assignments.
#首先遍历所有的向量
for vector_n in range(len(vectors)):
vect = vectors[vector_n]
#计算给定向量与分配的中心节点之间的欧几里得距离
distances = [sess.run(euclid_dist, feed_dict={
v1: vect, v2: sess.run(centroid)})
for centroid in centroids]
#下面可以使用集群分配操作,将上述的距离当做输入
assignment = sess.run(cluster_assignment, feed_dict = {
centroid_distances: distances})
#接下来为每个向量分配合适的值
sess.run(cluster_assigns[vector_n], feed_dict={
assignment_value: assignment})
##最大化的步骤
#基于上述的期望步骤,计算每个新的中心点的距离从而使集群内的平方和最小
for cluster_n in range(noofclusters):
#收集所有分配给该集群的向量
assigned_vects = [vectors[i] for i in range(len(vectors))
if sess.run(assignments[i]) == cluster_n]
#计算新的集群中心点
new_location = sess.run(mean_op, feed_dict={
mean_input: array(assigned_vects)})
#为每个向量分配合适的中心点
sess.run(cent_assigns[cluster_n], feed_dict={
centroid_value: new_location})
#返回中心节点和分组
centroids = sess.run(centroids)
assignments = sess.run(assignments)
return centroids, assignments需要注意的是,如果
for i in range(100):
x = sess.run(tf.assign(variable1, placeholder))像上面那样看似无害地在每次执行的时候创建一个新的OP(譬如tf.assign或者tf.zeros这样的),这样会一定的影响性能。作为替代的,你应该为每个任务定义一个特定的OP,然后在循环中调用这个OP。可以使用len(graph.get_operations())这个方法来检测是否有冗余的非必需的OPs。准确来说,sess.run应该是在迭代中唯一会与graph产生交互的方法。在上述代码的138~139行中可以看出,一系列的ops/Variables可以组合在sess.run中使用。





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。