
原文地址:stream-sql
我的Flink系列实战文章地址:Github Repo
近年来,开源的分布式流计算系统层出不穷,引起了广泛的关注与讨论。其中的先行者,譬如 Apache Storm提供了低延迟的流式处理功能,但是受限于at-least-once的投递保证,背压等不太良好的处理以及相对而言的开放API的底层化。不过Storm也起到了抛砖引玉的作用,自此之后,很多新的流计算系统在不同的维度上大放光彩。今日,Apache Flink或者 Apache Beam的使用者能够使用流式的Scala或者Java APIs来进行流处理任务,同时保证了exactly-once的投递机制以及高吞吐情况下的的低延迟响应。与此同时,流处理也在产界得到了应用,从Apache Kafka与Apache Flink在流处理的基础设施领域的大规模部署也折射除了流处理在产界的快速发展。与日俱增的实时数据流催生了开发人员或者分析人员对流数据进行分析以及实时展现的需求。不过,流数据分析也需要一些必备的技能与知识储备,譬如无限流的基本特性、窗口、时间以及状态等等,这些概念都会在利用Java或者Scala API来完成一个流分析的任务时候起到很大的作用。
大概六个月之前,Apache Flink社区着手为流数据分析系统引入一个SQL交互功能。众所周知,SQL是访问与处理数据的标准语言,基本上每个用过数据库的或者进行或数据分析的都对SQL不陌生。鉴于此,为流处理系统添加一个SQL交互接口能够有效地扩大该技术的受用面,让更多的人可以熟悉并且使用。除此之外,引入SQL的支持还能满足于一些需要实时交互地用户场景,大大简化一些需要进行流操作或者转化的应用代码。这篇文章中,我们会从现有的状态、架构的设计以及未来Apache Flink社区准备添加SQL支持的计划这几个方面进行讨论。
从何开始,先来回顾下已有的Table API
在 0.9.0-milestone1 发布之后,Apache Flink添加了所谓的Table API来提供类似于SQL的表达式用于对关系型数据进行处理。这系列API的操作对象就是抽象而言的能够进行关系型操作的结构化数据或者流。Table API一般与DataSet或者DataStream紧密关联,可以从DataSet或者DataStream来方便地创建一个Table对象,也可以用如下的操作将一个Table转化回一个DataSet或者DataStream对象:
val execEnv = ExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(execEnv)
// obtain a DataSet from somewhere
val tempData: DataSet[(String, Long, Double)] =
// convert the DataSet to a Table
val tempTable: Table = tempData.toTable(tableEnv, 'location, 'time, 'tempF)
// compute your result
val avgTempCTable: Table = tempTable
.where('location.like("room%"))
.select(
('time / (3600 * 24)) as 'day,
'Location as 'room,
(('tempF - 32) * 0.556) as 'tempC
)
.groupBy('day, 'room)
.select('day, 'room, 'tempC.avg as 'avgTempC)
// convert result Table back into a DataSet and print it
avgTempCTable.toDataSet[Row].print()
上面这坨代码是Scala的,不过你可以简单地用Java版本的Table API进行实现,下面这张图就展示了Table API的原始的结构:
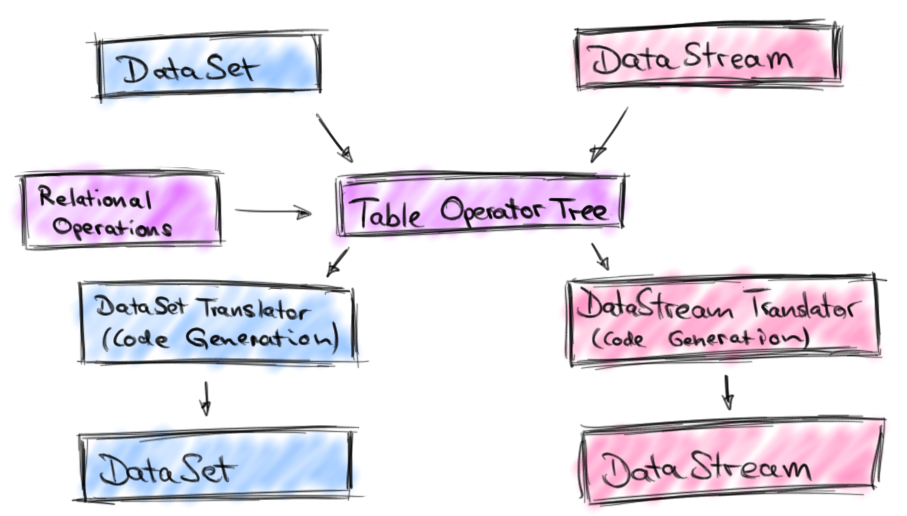
在我们从DataSet或者DataStream创建了Table之后,可以利用类似于filter, join, 或者 select关系型转化操作来转化为一个新的Table对象。而从内部实现上来说,所有应用于Table的转化操作都会变成一棵逻辑表操作树,在Table对象被转化回DataSet或者DataStream之后,专门的转化器会将这棵逻辑操作符树转化为对等的DataSet或者DataStream操作符。譬如'location.like("room%")这样的表达式会经由代码生成编译为Flink中的函数。
不过,老版本的Table API还是有很多的限制的。首先,Table API并不能单独使用,而必须嵌入到DataSet或者DataStream的程序中,对于批处理表的查询并不支持外连接、排序以及其他很多在SQL中经常使用的扩展操作。而流处理表中只支持譬如filters、union以及projections,不能支持aggregations以及joins。并且,这个转化处理过程并不能有查询优化,你要优化的话还是要去参考那些对于DataSet操作的优化。
Table API joining forces with SQL
关于是否需要添加SQL支持的讨论之前就在Flink社区中发生过几次,Flink 0.9发布之后,Table API、关系表达式的代码生成工具以及运行时的操作符等都预示着添加SQL支持的很多基础已经具备,可以考虑进行添加了。不过另一方面,在整个Hadoop生态链里已经存在了大量的所谓“SQL-on-Hadoop”的解决方案,譬如Apache Hive, Apache Drill, Apache Impala, Apache Tajo,在已经有了这么多的可选方案的情况下,我们觉得应该优先提升Flink其他方面的特性,于是就暂时搁置了SQL-on-Hadoop的开发。
不过,随着流处理系统的日渐火热以及Flink受到的越来越广泛地应用,我们发现有必要为用户提供一个更简单的可以用于数据分析的接口。大概半年前,我们决定要改造下Table API,扩展其对于流处理的能力并且最终完成在流处理上的SQL支持。不过我们也不打算重复造轮子,因此打算基于Apache Calcite这个非常流行的SQL解析器进行重构操作。Calcite在其他很多开源项目里也都应用到了,譬如Apache Hive, Apache Drill, Cascading, and many more。此外,Calcite社区本身也有将SQL on streams列入到它们的路线图中,因此我们一拍即合。Calcite 在新的架构设计中的地位大概如下所示:
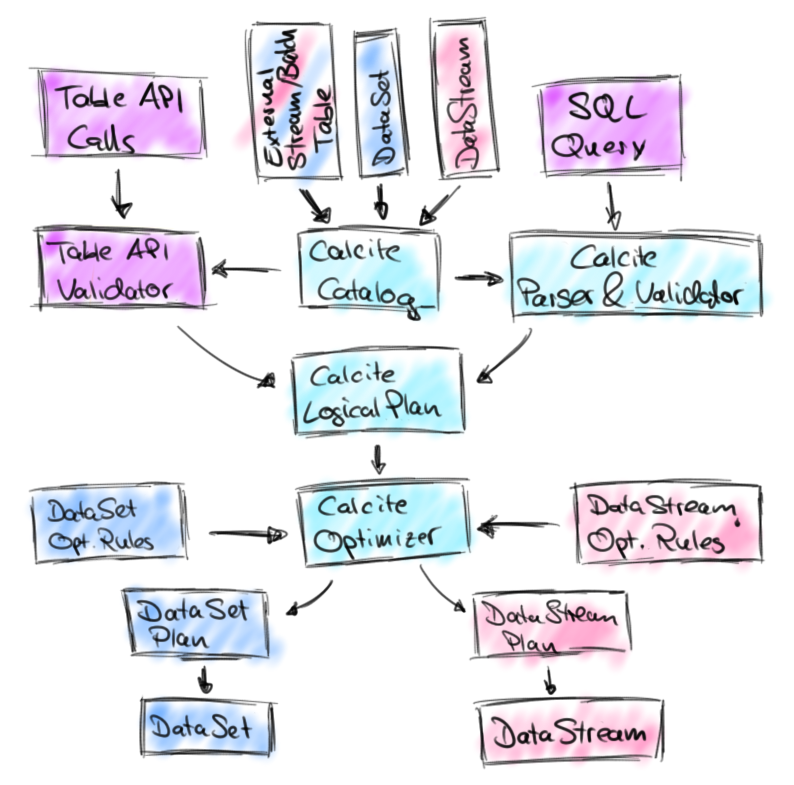
新的架构主要是将Table API与SQL集成起来,用这两货的API构建的查询最终都会转化到Calcite的所谓的logicl plans表述。转化之后的流查询与批查询基本上差不多,然后Calcite的优化器会基于转化和优化规则来优化这些logical plans,针对数据源(流还是静态数据)的不同我们会应用不同的规则。最后,经过优化的logical plan会转化为一个普通的Flink DataStream或者DataSet对象,即还是利用代码生成来将关系型表达式编译为Flink的函数。
新的架构继续提供了Table API并且在此基础上进行了很大的提升,它为流数据与关系型数据提供了统一的查询接口。另外,我们利用了Calcite的查询优化框架与SQL解释器来进行了查询优化。不过,因为这些设计都还是基于Flink的已有的API,譬如DataStream API提供的低延迟、高吞吐以及exactly-once投递的功能,以及DataSet API通过的健壮与高效的内存级别的操作器与管道式的数据交换,任何对于Flink核心API的提升都能够自动地提升Table API或者SQL查询的效率。
在这些工作之后,Flink就已经具备了同时对于流数据与静态数据的SQL支持。不过,我们并不想把这个当成一个高效的SQL-on-Hadoop的解决方案,就像Impala, Drill, 以及 Hive那样的角色,我们更愿意把它当成为流处理提供便捷的交互接口的方案。另外,这套机制还能促进同时用了Flink API与SQL的应用的性能。
How will Flink’s SQL on streams look like?
我们讨论了为啥要重构Flink的流SQL接口的原因以及大概怎么去完成这个任务,现在我们讨论下最终的API或者使用方式会是啥样的。新的SQL接口会集成到Table API中。DataStreams、DataSet以及额外的数据源都会先在TableEnvironment中注册成一个Table然后再进行SQL操作。TableEnvironment.sql()方法会允许你输入SQL查询语句然后执行返回一个新的Table,下面这个例子就展示了一个完整的从JSON编码的Kafka主题中读取数据然后利用SQL查询进行处理最终写入另一个Kafka主题的模型。注意,这下面提到的KafkaJsonSource与KafkaJsonSink都还未发布,未来的话TableSource与TableSinks都会固定提供,这样可以减少很多的模板代码。
// get environments
val execEnv = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(execEnv)
// configure Kafka connection
val kafkaProps = ...
// define a JSON encoded Kafka topic as external table
val sensorSource = new KafkaJsonSource[(String, Long, Double)](
"sensorTopic",
kafkaProps,
("location", "time", "tempF"))
// register external table
tableEnv.registerTableSource("sensorData", sensorSource)
// define query in external table
val roomSensors: Table = tableEnv.sql(
"SELECT STREAM time, location AS room, (tempF - 32) * 0.556 AS tempC " +
"FROM sensorData " +
"WHERE location LIKE 'room%'"
)
// define a JSON encoded Kafka topic as external sink
val roomSensorSink = new KafkaJsonSink(...)
// define sink for room sensor data and execute query
roomSensors.toSink(roomSensorSink)
execEnv.execute()
你可能会发现上面这个例子中没有体现流处理中两个重要的方面:基于窗口的聚合与关联。下面我就会解释下怎么在SQL中表达关于窗口的操作。 Apache Calcite社区关于这方面已经有所讨论:SQL on streams。Calcite的流SQL被认为是一个标准SQL的扩展,而不是另一个类似于SQL的语言。这会有几个方面的好处,首先,已经熟悉了标准SQL语法的同学就没必要花时间再学一波新的语法了,皆大欢喜。现在对于静态表与流数据的查询已经基本一致了,可以很方便地进行转换。Flink一直主张的是批处理只是流处理的一个特殊情况,因此用户也可以同时在静态表与流上进行查询,譬如处理有限的流。最后,未来也会有很多工具支持进行标准的SQL进行数据分析。
尽管我们还没有完全地定义好在Flink SQL表达式与Table API中如何进行窗口等设置,下面这个简单的例子会指明如何在SQL与Table API中进行滚动窗口式查询:
SQL (following the syntax proposal of Calcite’s streaming SQL document)
SELECT STREAM
TUMBLE_END(time, INTERVAL '1' DAY) AS day,
location AS room,
AVG((tempF - 32) * 0.556) AS avgTempC
FROM sensorData
WHERE location LIKE 'room%'
GROUP BY TUMBLE(time, INTERVAL '1' DAY), location
Table API
val avgRoomTemp: Table = tableEnv.ingest("sensorData")
.where('location.like("room%"))
.partitionBy('location)
.window(Tumbling every Days(1) on 'time as 'w)
.select('w.end, 'location, , (('tempF - 32) * 0.556).avg as 'avgTempCs)





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。