
2014年,Oracle发布了Java8新版本。对于Java来说,这显然是一个具有里程碑意义的版本。尤其是那函数式编程的功能,避开了Java那烦琐的语法所带来的麻烦。
这可以算是一篇Java8的学习笔记。将Java8一些常见的一些特性作了一个概要的笔记。
行为参数化(Lambda以及方法引用)
为了编写可重用的方法,比如filter,你需要为其指定一个参数,它能够精确地描述过滤条件。虽然Java专家们使用之前的版本也能达到同样的目的(将过滤条件封装成类的一个方法,传递该类的一个实例),但这种方案却很难推广,因为它通常非常臃肿,既难于编写,也不易于维护。
Java 8通过借鉴函数式编程,提供了一种新的方式——通过向方法传递代码片段来解决这一问题。这种新的方法非常方便地提供了两种变体。
- 传递一个Lambda表达式,即一段精简的代码片段,比如
apple -> apple.getWeight() > 150- 传递一个方法引用,该方法引用指向了一个现有的方法,比如这样的代码:
Apple::isHeavy这些值具有类似Function<T, R>、Predicate<T>或者BiFunction<T, U, R>这样的类型,值的接收方可以通过apply、test或其他类似的方法执行这些方法。Lambda表达式自身是一个相当酷炫的概念,不过Java 8对它们的使用方式——将它们与全新的Stream API相结合,最终把它们推向了新一代Java的核心。
闭包
你可能已经听说过闭包(closure,不要和Clojure编程语言混淆)这个词,你可能会想Lambda是否满足闭包的定义。用科学的说法来说,闭包就是一个函数的实例,且它可以无限制地访问那个函数的非本地变量。例如,闭包可以作为参数传递给另一个函数。它也可以访问和修改其作用域之外的变量。现在,Java 8的Lambda和匿名类可以做类似于闭包的事情:它们可以作为参数传递给方法,并且可以访问其作用域之外的变量。但有一个限制:它们不能修改定义Lambda的方法的局部变量的内容。这些变量必须是隐式最终的。可以认为Lambda是对值封闭,而不是对变量封闭。如前所述,这种限制存在的原因在于局部变量保存在栈上,并且隐式表示它们仅限于其所在线程。如果允许捕获可改变的局部变量,就会引发造成线程不安全的新的可能性,而这是我们不想看到的(实例变量可以,因为它们保存在堆中,而堆是在线程之间共享的)。
函数接口
Java 8之前,接口主要用于定义方法签名,现在它们还能为接口的使用者提供方法的默认实现,如果接口的设计者认为接口中声明的某个方法并不需要每一个接口的用户显式地提供实现,他就可以考虑在接口的方法声明中为其定义默认方法。
对类库的设计者而言,这是个伟大的新工具,原因很简单,它提供的能力能帮助类库的设计者们定义新的操作,增强接口的能力,类库的用户们(即那些实现该接口的程序员们)不需要花费额外的精力重新实现该方法。因此,默认方法与库的用户也有关系,它们屏蔽了将来的变化对用户的影响。
在接口上添加注解:@FunctionalInterface。即可声明该接口为函数接口。
如果你去看看新的Java API,会发现函数式接口带有@FunctionalInterface的标注。这个标注用于表示该接口会设计成一个函数式接口。如果你用@FunctionalInterface定义了一个接口,而它却不是函数式接口的话,编译器将返回一个提示原因的错误。例如,错误消息可能是“Multiple non-overriding abstract methods found in interface Foo”,表明存在多个抽象方法。请注意,@FunctionalInterface不是必需的,但对于为此设计的接口而言,使用它是比较好的做法。它就像是@Override标注表示方法被重写了。
Lambdas及函数式接口的例子:
| 使用案例 | Lambda例子 | 对应的函数式接口 |
|---|---|---|
| 布尔表达式 | (List<String> list) -> list.isEmpty() |
Predicate<List<String>> |
| 创建对象 | () -> new Apple(10) |
Supplier<Apple> |
| 消费一个对象 | (Apple a) ->System.out.println(a.getWeight()) |
Consumer<Apple> |
| 从一个对象中选择/提取 | (String s) -> s.length() |
Function<String, Integer>或ToIntFunction<String> |
| 合并两个值 | (int a, int b) -> a * b |
IntBinaryOperator |
| 比较两个对象 | (Apple a1, Apple a2) ->a1.getWeight().compareTo(a2.getWeight()) |
Comparator<Apple>或BiFunction<Apple, Apple, Integer>或ToIntBiFunction<Apple, Apple> |
流
简介
要讨论流,我们先来谈谈集合,这是最容易上手的方式了。Java 8中的集合支持一个新的stream方法,它会返回一个流(接口定义在java.util.stream.Stream里)。你在后面会看到,还有很多其他的方法可以得到流,比如利用数值范围或从I/O资源生成流元素。
那么,流到底是什么呢?简短的定义就是“从支持数据处理操作的源生成的元素序列”。让我们一步步剖析这个定义。
- 元素序列——就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如ArrayList 与 LinkedList)。但流的目的在于表达计算,比如你前面见到的filter、sorted和map。集合讲的是数据,流讲的是计算。我们会在后面几节中详细解释这个思想。
- 源——流会使用一个提供数据的源,如集合、数组或输入/输出资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
- 数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如filter、map、reduce、find、match、sort等。流操作可以顺序执行,也可并行执行。
此外,流操作有两个重要的特点。
- 流水线——很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。这让我们下一章中的一些优化成为可能,如延迟和短路。流水线的操作可以看作对数据源进行数据库式查询。
- 内部迭代——与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
流与集合
Java现有的集合概念和新的流概念都提供了接口,来配合代表元素型有序值的数据接口。所谓有序,就是说我们一般是按顺序取用值,而不是随机取用的。那这两者有什么区别呢?
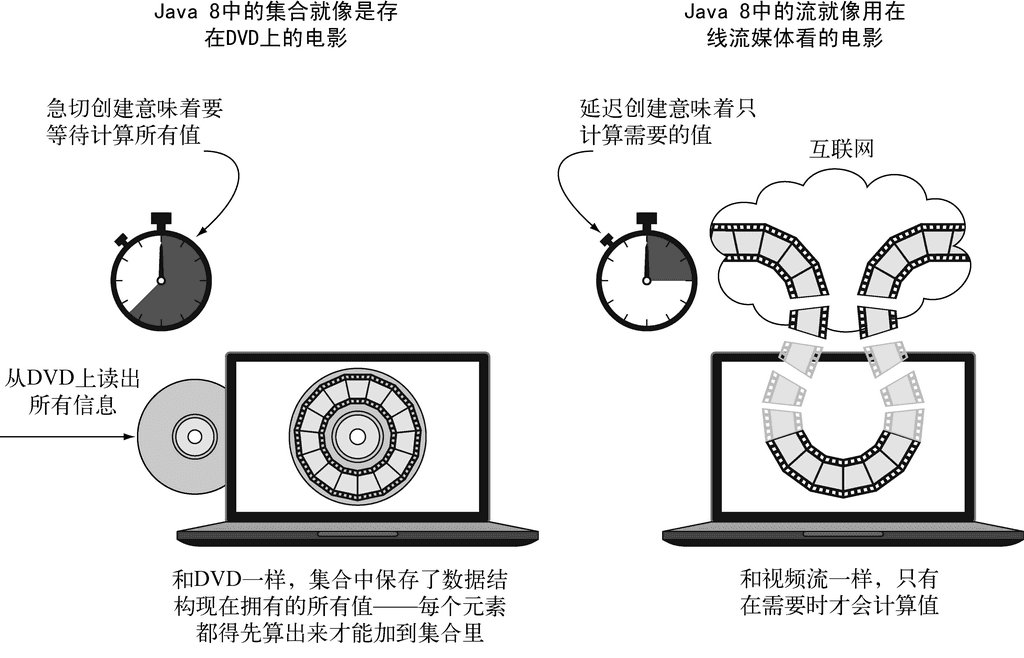
我们先来打个直观的比方吧。比如说存在DVD里的电影,这就是一个集合(也许是字节,也许是帧,这个无所谓),因为它包含了整个数据结构。现在再来想想在互联网上通过视频流看同样的电影。现在这是一个流(字节流或帧流)。流媒体视频播放器只要提前下载用户观看位置的那几帧就可以了,这样不用等到流中大部分值计算出来,你就可以显示流的开始部分了(想想观看直播足球赛)。特别要注意,视频播放器可能没有将整个流作为集合,保存所需要的内存缓冲区——而且要是非得等到最后一帧出现才能开始看,那等待的时间就太长了。出于实现的考虑,你也可以让视频播放器把流的一部分缓存在集合里,但和概念上的差异不是一回事。
粗略地说,集合与流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。(你可以往集合里加东西或者删东西,但是不管什么时候,集合中的每个元素都是放在内存里的,元素都得先算出来才能成为集合的一部分。)
相比之下,流则是在概念上固定的数据结构(你不能添加或删除元素),其元素则是按需计算的。 这对编程有很大的好处。在第6章中,我们将展示构建一个质数流(2, 3, 5, 7, 11, …)有多简单,尽管质数有无穷多个。这个思想就是用户仅仅从流中提取需要的值,而这些值——在用户看不见的地方——只会按需生成。这是一种生产者-消费者的关系。从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值(用管理学的话说这就是需求驱动,甚至是实时制造)。
与此相反,集合则是急切创建的(供应商驱动:先把仓库装满,再开始卖,就像那些昙花一现的圣诞新玩意儿一样)。以质数为例,要是想创建一个包含所有质数的集合,那这个程序算起来就没完没了了,因为总有新的质数要算,然后把它加到集合里面。当然这个集合是永远也创建不完的,消费者这辈子都见不着了。

流的操作
| 操作 | 类型 | 返回类型 | 使用的类型、函数式接口 | 函数描述符 |
|---|---|---|---|---|
filter |
中间 | Stream<T> |
Predicate<T> |
T -> boolean |
distinct |
中间(有状态-无界) | Stream<T> |
`` | `` |
skip |
中间(有状态-有界) | Stream<T> |
long |
`` |
limit |
中间(有状态-有界) | Stream<T> |
long |
`` |
map |
中间 | Stream<R> |
Function<T, R> |
T -> R |
flatMap |
中间 | Stream<R> |
Function<T, Stream<R>> |
T -> Stream<R> |
sorted |
中间(有状态-无界) | Stream<T> |
Comparator<T> |
(T, T) -> int |
anyMatch |
终端 | boolean |
Predicate<T> |
T -> boolean |
noneMatch |
终端 | boolean |
Predicate<T> |
T -> boolean |
allMatch |
终端 | boolean |
Predicate<T> |
T -> boolean |
findAny |
终端 | Optional<T> |
`` | `` |
findFirst |
终端 | Optional<T> |
`` | `` |
forEach |
终端 | void |
Consumer<T> |
T -> void |
collect |
终端 | R |
Collector<T, A, R> |
`` |
| reduce`` | 终端(有状态-有界) | Optional<T> |
BinaryOperator<T> |
(T, T)-> T |
count |
终端 | long |
`` | `` |
预定义收集器
即Collectors类提供的工厂方法(例如groupingBy)创建的收集器。它们主要提供了三大功能:
- 将流元素归约和汇总为一个值
- 元素分组
- 元素分区
Collectors类的静态工厂方法
| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| toList | List<T> | 把流中所有项目收集到一个List |
使用示例:
List<Dish> dishes = menuStream.collect(toList());| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| toSet | Set<T> | 把流中所有项目收集到一个Set,删除重复项 |
使用示例:
Set<Dish> dishes = menuStream.collect(toSet());| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| toCollection | Collection<T> | 把流中所有项目收集到给定的供应源创建的集合 |
使用示例:
Collection<Dish> dishes = menuStream.collect(toCollection(),ArrayList::new);| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| counting | Long | 计算流中元素的个数 |
使用示例:
long howManyDishes = menuStream.collect(counting());| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| summingInt | Integer | 对流中项目的一个整数属性求和 |
使用示例:
int totalCalories =
menuStream.collect(summingInt(Dish::getCalories));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| averagingInt | Double | 计算流中项目Integer属性的平均值 |
使用示例:
double avgCalories =
menuStream.collect(averagingInt(Dish::getCalories));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| summarizingInt | IntSummaryStatistics | 收集关于流中项目Integer属性的统计值,例如最大、最小、总和与平均值 |
使用示例:
IntSummaryStatistics menuStatistics =
menuStream.collect(summarizingInt(Dish::getCalories));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| joining` | String | 连接对流中每个项目调用toString方法所生成的字符串 |
使用示例:
String shortMenu =
menuStream.map(Dish::getName).collect(joining(", "));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| maxBy | Optional<T> | 一个包裹了流中按照给定比较器选出的最大元素的Optional,或如果流为空则为Optional.empty() |
使用示例:
Optional<Dish> fattest =
menuStream.collect(maxBy(comparingInt(Dish::getCalories)));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| minBy | Optional<T> | 一个包裹了流中按照给定比较器选出的最小元素的Optional,或如果流为空则为Optional.empty() |
使用示例:
Optional<Dish> lightest =
menuStream.collect(minBy(comparingInt(Dish::getCalories)));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| reducing | 归约操作产生的类型 | 从一个作为累加器的初始值开始,利用BinaryOperator与流中的元素逐个结合,从而将流归约为单个值 |
使用示例:
int totalCalories =
menuStream.collect(reducing(0, Dish::getCalories, Integer::sum));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结果应用转换函数 |
使用示例:
int howManyDishes =
menuStream.collect(collectingAndThen(toList(), List::size));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| groupingBy | Map<K, List<T>> | 根据项目的一个属性的值对流中的项目作问组,并将属性值作为结果Map的键 |
使用示例:
Map<Dish.Type,List<Dish>> dishesByType =
menuStream.collect(groupingBy(Dish::getType));| 工厂方法 | 返回类型 | 用于 |
|---|---|---|
| partitioningBy | Map<Boolean,List<T>> | 根据对流中每个项目应用谓词的结果来对项目进行分区 |
使用示例:
Map<Boolean,List<Dish>> vegetarianDishes =
menuStream.collect(partitioningBy(Dish::isVegetarian));并行流
在Java 7之前,并行处理数据集合非常麻烦。第一,你得明确地把包含数据的数据结构分成若干子部分。第二,你要给每个子部分分配一个独立的线程。第三,你需要在恰当的时候对它们进行同步来避免不希望出现的竞争条件,等待所有线程完成,最后把这些部分结果合并起来。Java 7引入了一个叫作分支/合并的框架,让这些操作更稳定、更不易出错。
我们简要地提到了Stream接口可以让你非常方便地处理它的元素:可以通过对收集源调用parallelStream方法来把集合转换为并行流。并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。
高效使用并行流
一般而言,想给出任何关于什么时候该用并行流的定量建议都是不可能也毫无意义的,因为任何类似于“仅当至少有一千个(或一百万个或随便什么数字)元素的时候才用并行流)”的建议对于某台特定机器上的某个特定操作可能是对的,但在略有差异的另一种情况下可能就是大错特错。尽管如此,我们至少可以提出一些定性意见,帮你决定某个特定情况下是否有必要使用并行流。
- 如果有疑问,测量。把顺序流转成并行流轻而易举,但却不一定是好事。我们在本节中已经指出,并行流并不总是比顺序流快。此外,并行流有时候会和你的直觉不一致,所以在考虑选择顺序流还是并行流时,第一个也是最重要的建议就是用适当的基准来检查其性能。
- 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8中有原始类型流(IntStream、LongStream、DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
- 有些操作本身在并行流上的性能就比顺序流差。特别是limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。例如,findAny会比findFirst性能好,因为它不一定要按顺序来执行。你总是可以调用unordered方法来把有序流变成无序流。那么,如果你需要流中的n 个元素而不是专门要前n 个的话,对无序并行流调用limit可能会比单个有序流(比如数据源是一个List)更高效。
- 还要考虑流的操作流水线的总计算成本。设 N 是要处理的元素的总数,Q 是一个元素通过流水线的大致处理成本,则 N*Q 就是这个对成本的一个粗略的定性估计。Q 值较高就意味着使用并行流时性能好的可能性比较大。
- 对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。
- 要考虑流背后的数据结构是否易于分解。例如,ArrayList的拆分效率比LinkedList高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。另外,用range工厂方法创建的原始类型流也可以快速分解。
- 流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如,一个SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。
- 还要考虑终端操作中合并步骤的代价是大是小(例如Collector中的combiner方法)。如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
流的数据源和可分解性
| 源 | 可分解性 |
|---|---|
| ArrayList | 极佳 |
| LinkedList | 差 |
| IntStream.range | 极佳 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
Optional
Java 8的库提供了Optional<T>类,这个类允许你在代码中指定哪一个变量的值既可能是类型T的值,也可能是由静态方法Optional.empty表示的缺失值。无论是对于理解程序逻辑,抑或是对于编写产品文档而言,这都是一个重大的好消息,你现在可以通过一种数据类型表示显式缺失的值——使用空指针的问题在于你无法确切了解出现空指针的原因,它是预期的情况,还是说由于之前的某一次计算出错导致的一个偶然性的空值,有了Optional之后你就不需要再使用之前容易出错的空指针来表示缺失的值了。
Optional类的方法
| 方法 | 描述 |
|---|---|
| empty | 返回一个空的Optional实例 |
| filter | 如果值存在并且满足提供的谓词,就返回包含该值的Optional对象;否则返回一个空的Optional对象 |
| flatMap | 如果值存在,就对该值执行提供的mapping函数调用,返回一个Optional类型的值,否则就返回一个空的Optional对象 |
| get | 如果该值存在,将该值用Optional封装返回,否则抛出一个NoSuchElementException异常 |
| ifPresent | 如果值存在,就执行使用该值的方法调用,否则什么也不做 |
| isPresent | 如果值存在就返回true,否则返回false |
| map | 如果值存在,就对该值执行提供的mapping函数调用 |
| of | 将指定值用Optional封装之后返回,如果该值为null,则抛出一个NullPointerException异常 |
| ofNullable | 将指定值用Optional封装之后返回,如果该值为null,则返回一个空的Optional对象 |
| orElse | 如果有值则将其返回,否则返回一个默认值 |
| orElseGet | 如果有值则将其返回,否则返回一个由指定的Supplier接口生成的值 |
| orElseThrow | 如果有值则将其返回,否则抛出一个由指定的Supplier接口生成的异常 |
小结
- null引用在历史上被引入到程序设计语言中,目的是为了表示变量值的缺失。
- Java 8中引入了一个新的类java.util.Optional<T>,对存在或缺失的变量值进行建模。
- 你可以使用静态工厂方法Optional.empty、Optional.of以及Optional.ofNullable创建Optional对象。
- Optional类支持多种方法,比如map、flatMap、filter,它们在概念上与Stream类中对应的方法十分相似。
- 使用Optional会迫使你更积极地解引用Optional对象,以应对变量值缺失的问题,最终,你能更有效地防止代码中出现不期而至的空指针异常。
- 使用Optional能帮助你设计更好的API,用户只需要阅读方法签名,就能了解该方法是否接受一个Optional类型的值。
CompletableFuture
Java从Java 5版本就提供了Future接口。Future对于充分利用多核处理能力是非常有益的,因为它允许一个任务在一个新的核上生成一个新的子线程,新生成的任务可以和原来的任务同时运行。原来的任务需要结果时,它可以通过get方法等待Future运行结束(生成其计算的结果值)。
Future接口的局限性
我们知道Future接口提供了方法来检测异步计算是否已经结束(使用isDone方法),等待异步操作结束,以及获取计算的结果。但是这些特性还不足以让你编写简洁的并发代码。比如,我们很难表述Future结果之间的依赖性;从文字描述上这很简单,“当长时间计算任务完成时,请将该计算的结果通知到另一个长时间运行的计算任务,这两个计算任务都完成后,将计算的结果与另一个查询操作结果合并”。但是,使用Future中提供的方法完成这样的操作又是另外一回事。这也是我们需要更具描述能力的特性的原因,比如下面这些。
- 将两个异步计算合并为一个——这两个异步计算之间相互独立,同时第二个又依赖于第一个的结果。
- 等待Future集合中的所有任务都完成。
- 仅等待Future集合中最快结束的任务完成(有可能因为它们试图通过不同的方式计算同一个值),并返回它的结果。
- 通过编程方式完成一个Future任务的执行(即以手工设定异步操作结果的方式)。
- 应对Future的完成事件(即当Future的完成事件发生时会收到通知,并能使用Future计算的结果进行下一步的操作,不只是简单地阻塞等待操作的结果)。
CompletableFuture 详解
一个非常有用,不过不那么精确的格言这么说:“Completable-Future对于Future的意义就像Stream之于Collection。”让我们比较一下这二者。
- 通过Stream你可以对一系列的操作进行流水线,通过map、filter或者其他类似的方法提供行为参数化,它可有效避免使用迭代器时总是出现模板代码。
- 类似地,CompletableFuture提供了像thenCompose、thenCombine、allOf这样的操作,对Future涉及的通用设计模式提供了函数式编程的细粒度控制,有助于避免使用命令式编程的模板代码。
新的日期和时间API
Java的API提供了很多有用的组件,能帮助你构建复杂的应用。不过,Java API也不总是完美的。我们相信大多数有经验的程序员都会赞同Java 8之前的库对日期和时间的支持就非常不理想。然而,你也不用太担心:Java 8中引入全新的日期和时间API就是要解决这一问题。
- LocalDate
- LocalTime
- LocalDateTime
- Instant
- Duration
- Period
使用LocalDate和LocalTime还有LocalDateTime
开始使用新的日期和时间API时,你最先碰到的可能是LocalDate类。该类的实例是一个不可变对象,它只提供了简单的日期,并不含当天的时间信息。另外,它也不附带任何与时区相关的信息。
你可以通过静态工厂方法of创建一个LocalDate实例。LocalDate实例提供了多种方法来读取常用的值,比如年份、月份、星期几等,如下所示。
LocalDate date = LocalDate.of(2014, 3, 18); ←─2014-03-18
int year = date.getYear(); ←─2014
Month month = date.getMonth(); ←─MARCH
int day = date.getDayOfMonth(); ←─18
DayOfWeek dow = date.getDayOfWeek(); ←─TUESDAY
int len = date.lengthOfMonth(); ←─31 (days in March)
boolean leap = date.isLeapYear(); ←─false (not a leap year)
//你还可以使用工厂方法从系统时钟中获取当前的日期:
LocalDate today = LocalDate.now();LocalTime和LocalDateTime都提供了类似的方法。
机器的日期和时间格式
作为人,我们习惯于以星期几、几号、几点、几分这样的方式理解日期和时间。毫无疑问,这种方式对于计算机而言并不容易理解。从计算机的角度来看,建模时间最自然的格式是表示一个持续时间段上某个点的单一大整型数。这也是新的java.time.Instant类对时间建模的方式,基本上它是以Unix元年时间(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的秒数进行计算。
你可以通过向静态工厂方法ofEpochSecond传递一个代表秒数的值创建一个该类的实例。静态工厂方法ofEpochSecond还有一个增强的重载版本,它接收第二个以纳秒为单位的参数值,对传入作为秒数的参数进行调整。重载的版本会调整纳秒参数,确保保存的纳秒分片在0到999 999 999之间。这意味着下面这些对ofEpochSecond工厂方法的调用会返回几乎同样的Instant对象:
Instant.ofEpochSecond(3);
Instant.ofEpochSecond(3, 0);
Instant.ofEpochSecond(2, 1_000_000_000); ←─2 秒之后再加上100万纳秒(1秒)
Instant.ofEpochSecond(4, -1_000_000_000); ←─4秒之前的100万纳秒(1秒)正如你已经在LocalDate及其他为便于阅读而设计的日期-时间类中所看到的那样,Instant类也支持静态工厂方法now,它能够帮你获取当前时刻的时间戳。我们想要特别强调一点,Instant的设计初衷是为了便于机器使用。它包含的是由秒及纳秒所构成的数字。所以,它无法处理那些我们非常容易理解的时间单位。比如下面这段语句:
int day = Instant.now().get(ChronoField.DAY_OF_MONTH);
它会抛出下面这样的异常:
java.time.temporal.UnsupportedTemporalTypeException: Unsupported field:
DayOfMonth但是你可以通过Duration和Period类使用Instant,接下来我们会对这部分内容进行介绍。
定义Duration或Period
目前为止,你看到的所有类都实现了Temporal接口,Temporal接口定义了如何读取和操纵为时间建模的对象的值。之前的介绍中,我们已经了解了创建Temporal实例的几种方法。很自然地你会想到,我们需要创建两个Temporal对象之间的duration。Duration类的静态工厂方法between就是为这个目的而设计的。你可以创建两个LocalTimes对象、两个LocalDateTimes对象,或者两个Instant对象之间的duration,如下所示:
Duration d1 = Duration.between(time1, time2);
Duration d1 = Duration.between(dateTime1, dateTime2);
Duration d2 = Duration.between(instant1, instant2);由于LocalDateTime和Instant是为不同的目的而设计的,一个是为了便于人阅读使用,另一个是为了便于机器处理,所以你不能将二者混用。如果你试图在这两类对象之间创建duration,会触发一个DateTimeException异常。此外,由于Duration类主要用于以秒和纳秒衡量时间的长短,你不能仅向between方法传递一个LocalDate对象做参数。
如果你需要以年、月或者日的方式对多个时间单位建模,可以使用Period类。使用该类的工厂方法between,你可以使用得到两个LocalDate之间的时长,如下所示:
Period tenDays = Period.between(LocalDate.of(2014, 3, 8),
LocalDate.of(2014, 3, 18));最后,Duration和Period类都提供了很多非常方便的工厂类,直接创建对应的实例;换句话说,就像下面这段代码那样,不再是只能以两个temporal对象的差值的方式来定义它们的对象。
创建Duration和Period对象
Duration threeMinutes = Duration.ofMinutes(3);
Duration threeMinutes = Duration.of(3, ChronoUnit.MINUTES);
Period tenDays = Period.ofDays(10);
Period threeWeeks = Period.ofWeeks(3);
Period twoYearsSixMonthsOneDay = Period.of(2, 6, 1);Duration类和Period类共享了很多相似的方法:
| 方法名 | 是否是静态方法 | 方法描述 |
|---|---|---|
| between | 是 | 创建两个时间点之间的interval |
| from | 是 | 由一个临时时间点创建interval |
| of | 是 | 由它的组成部分创建interval的实例 |
| parse | 是 | 由字符串创建interval的实例 |
| addTo | 否 | 创建该interval的副本,并将其叠加到某个指定的temporal对象 |
| get | 否 | 读取该interval的状态 |
| isNegative | 否 | 检查该interval是否为负值,不包含零 |
| isZero | 否 | 检查该interval的时长是否为零 |
| minus | 否 | 通过减去一定的时间创建该interval的副本 |
| multipliedBy | 否 | 将interval的值乘以某个标量创建该interval的副本 |
| negated | 否 | 以忽略某个时长的方式创建该interval的副本 |
| plus | 否 | 以增加某个指定的时长的方式创建该interval的副本 |
| subtractFrom | 否 | 从指定的temporal对象中减去该interval |



**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。