
Word2Vec
基于 Gensim 的 Word2Vec 实践,从属于笔者的程序猿的数据科学与机器学习实战手册,代码参考gensim.ipynb。推荐前置阅读Python语法速览与机器学习开发环境搭建,Scikit-Learn 备忘录。
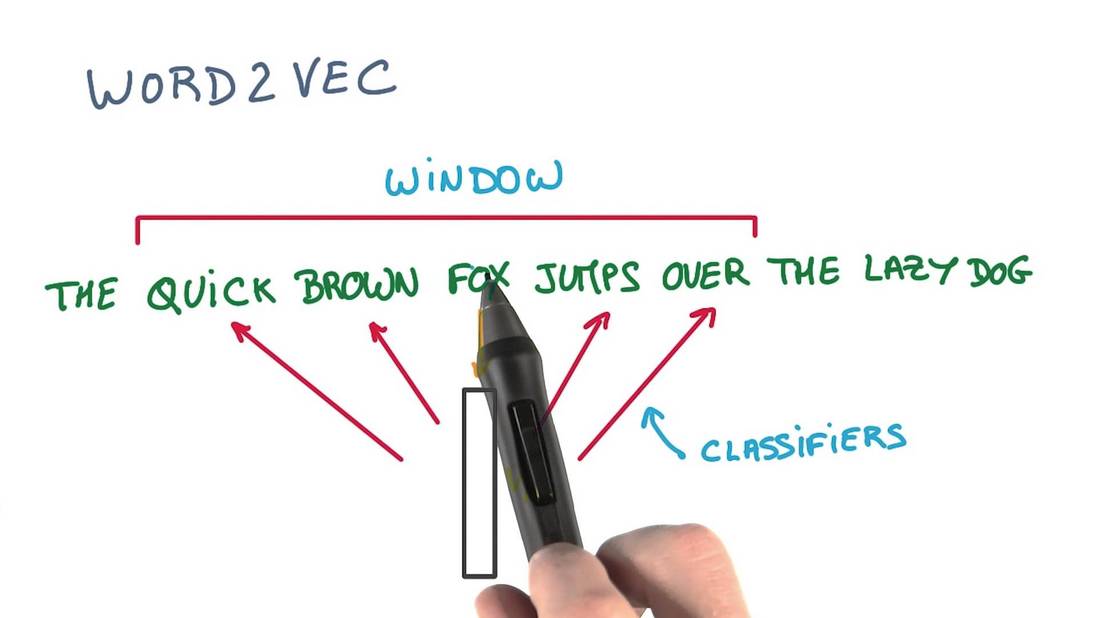
模型创建
Gensim中 Word2Vec 模型的期望输入是进过分词的句子列表,即是某个二维数组。这里我们暂时使用 Python 内置的数组,不过其在输入数据集较大的情况下会占用大量的 RAM。Gensim 本身只是要求能够迭代的有序句子列表,因此在工程实践中我们可以使用自定义的生成器,只在内存中保存单条语句。
# 引入 word2vec
from gensim.models import word2vec
# 引入日志配置
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 引入数据集
raw_sentences = ["the quick brown fox jumps over the lazy dogs","yoyoyo you go home now to sleep"]
# 切分词汇
sentences= [s.encode('utf-8').split() for s in sentences]
# 构建模型
model = word2vec.Word2Vec(sentences, min_count=1)
# 进行相关性比较
model.similarity('dogs','you')这里我们调用Word2Vec创建模型实际上会对数据执行两次迭代操作,第一轮操作会统计词频来构建内部的词典数结构,第二轮操作会进行神经网络训练,而这两个步骤是可以分步进行的,这样对于某些不可重复的流(譬如 Kafka 等流式数据中)可以手动控制:
model = gensim.models.Word2Vec(iter=1) # an empty model, no training yet
model.build_vocab(some_sentences) # can be a non-repeatable, 1-pass generator
model.train(other_sentences) # can be a non-repeatable, 1-pass generatorWord2Vec 参数
min_count
model = Word2Vec(sentences, min_count=10) # default value is 5在不同大小的语料集中,我们对于基准词频的需求也是不一样的。譬如在较大的语料集中,我们希望忽略那些只出现过一两次的单词,这里我们就可以通过设置min_count参数进行控制。一般而言,合理的参数值会设置在0~100之间。
size
size参数主要是用来设置神经网络的层数,Word2Vec 中的默认值是设置为100层。更大的层次设置意味着更多的输入数据,不过也能提升整体的准确度,合理的设置范围为 10~数百。
model = Word2Vec(sentences, size=200) # default value is 100workers
workers参数用于设置并发训练时候的线程数,不过仅当Cython安装的情况下才会起作用:
model = Word2Vec(sentences, workers=4) # default = 1 worker = no parallelization外部语料集
在真实的训练场景中我们往往会使用较大的语料集进行训练,譬如这里以 Word2Vec 官方的text8为例,只要改变模型中的语料集开源即可:
sentences = word2vec.Text8Corpus('text8')
model = word2vec.Word2Vec(sentences, size=200)这里语料集中的语句是经过分词的,因此可以直接使用。笔者在第一次使用该类时报错了,因此把 Gensim 中的源代码贴一下,也方便以后自定义处理其他语料集:
class Text8Corpus(object):
"""Iterate over sentences from the "text8" corpus, unzipped from http://mattmahoney.net/dc/text8.zip ."""
def __init__(self, fname, max_sentence_length=MAX_WORDS_IN_BATCH):
self.fname = fname
self.max_sentence_length = max_sentence_length
def __iter__(self):
# the entire corpus is one gigantic line -- there are no sentence marks at all
# so just split the sequence of tokens arbitrarily: 1 sentence = 1000 tokens
sentence, rest = [], b''
with utils.smart_open(self.fname) as fin:
while True:
text = rest + fin.read(8192) # avoid loading the entire file (=1 line) into RAM
if text == rest: # EOF
words = utils.to_unicode(text).split()
sentence.extend(words) # return the last chunk of words, too (may be shorter/longer)
if sentence:
yield sentence
break
last_token = text.rfind(b' ') # last token may have been split in two... keep for next iteration
words, rest = (utils.to_unicode(text[:last_token]).split(),
text[last_token:].strip()) if last_token >= 0 else ([], text)
sentence.extend(words)
while len(sentence) >= self.max_sentence_length:
yield sentence[:self.max_sentence_length]
sentence = sentence[self.max_sentence_length:]我们在上文中也提及,如果是对于大量的输入语料集或者需要整合磁盘上多个文件夹下的数据,我们可以以迭代器的方式而不是一次性将全部内容读取到内存中来节省 RAM 空间:
class MySentences(object):
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
for fname in os.listdir(self.dirname):
for line in open(os.path.join(self.dirname, fname)):
yield line.split()
sentences = MySentences('/some/directory') # a memory-friendly iterator
model = gensim.models.Word2Vec(sentences)模型保存与读取
model.save('text8.model')
2015-02-24 11:19:26,059 : INFO : saving Word2Vec object under text8.model, separately None
2015-02-24 11:19:26,060 : INFO : not storing attribute syn0norm
2015-02-24 11:19:26,060 : INFO : storing numpy array 'syn0' to text8.model.syn0.npy
2015-02-24 11:19:26,742 : INFO : storing numpy array 'syn1' to text8.model.syn1.npy
model1 = Word2Vec.load('text8.model')
model.save_word2vec_format('text.model.bin', binary=True)
2015-02-24 11:19:52,341 : INFO : storing 71290x200 projection weights into text.model.bin
model1 = word2vec.Word2Vec.load_word2vec_format('text.model.bin', binary=True)
2015-02-24 11:22:08,185 : INFO : loading projection weights from text.model.bin
2015-02-24 11:22:10,322 : INFO : loaded (71290, 200) matrix from text.model.bin
2015-02-24 11:22:10,322 : INFO : precomputing L2-norms of word weight vectors模型预测
Word2Vec 最著名的效果即是以语义化的方式推断出相似词汇:
model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)
[('queen', 0.50882536)]
model.doesnt_match("breakfast cereal dinner lunch";.split())
'cereal'
model.similarity('woman', 'man')
0.73723527
model.most_similar(['man'])
[(u'woman', 0.5686948895454407),
(u'girl', 0.4957364797592163),
(u'young', 0.4457539916038513),
(u'luckiest', 0.4420626759529114),
(u'serpent', 0.42716869711875916),
(u'girls', 0.42680859565734863),
(u'smokes', 0.4265017509460449),
(u'creature', 0.4227582812309265),
(u'robot', 0.417464017868042),
(u'mortal', 0.41728296875953674)]如果我们希望直接获取某个单词的向量表示,直接以下标方式访问即可:
model['computer'] # raw NumPy vector of a word
array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)模型评估
Word2Vec 的训练属于无监督模型,并没有太多的类似于监督学习里面的客观评判方式,更多的依赖于端应用。Google 之前公开了20000条左右的语法与语义化训练样本,每一条遵循A is to B as C is to D这个格式,地址在这里:
model.accuracy('/tmp/questions-words.txt')
2014-02-01 22:14:28,387 : INFO : family: 88.9% (304/342)
2014-02-01 22:29:24,006 : INFO : gram1-adjective-to-adverb: 32.4% (263/812)
2014-02-01 22:36:26,528 : INFO : gram2-opposite: 50.3% (191/380)
2014-02-01 23:00:52,406 : INFO : gram3-comparative: 91.7% (1222/1332)
2014-02-01 23:13:48,243 : INFO : gram4-superlative: 87.9% (617/702)
2014-02-01 23:29:52,268 : INFO : gram5-present-participle: 79.4% (691/870)
2014-02-01 23:57:04,965 : INFO : gram7-past-tense: 67.1% (995/1482)
2014-02-02 00:15:18,525 : INFO : gram8-plural: 89.6% (889/992)
2014-02-02 00:28:18,140 : INFO : gram9-plural-verbs: 68.7% (482/702)
2014-02-02 00:28:18,140 : INFO : total: 74.3% (5654/7614)还是需要强调下,训练集上表现的好也不意味着 Word2Vec 在真实应用中就会表现的很好,还是需要因地制宜。)
模型创建
Gensim中 Word2Vec 模型的期望输入是进过分词的句子列表,即是某个二维数组。这里我们暂时使用 Python 内置的数组,不过其在输入数据集较大的情况下会占用大量的 RAM。Gensim 本身只是要求能够迭代的有序句子列表,因此在工程实践中我们可以使用自定义的生成器,只在内存中保存单条语句。
# 引入 word2vec
from gensim.models import word2vec
# 引入日志配置
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 引入数据集
raw_sentences = ["the quick brown fox jumps over the lazy dogs","yoyoyo you go home now to sleep"]
# 切分词汇
sentences= [s.encode('utf-8').split() for s in sentences]
# 构建模型
model = word2vec.Word2Vec(sentences, min_count=1)
# 进行相关性比较
model.similarity('dogs','you')这里我们调用Word2Vec创建模型实际上会对数据执行两次迭代操作,第一轮操作会统计词频来构建内部的词典数结构,第二轮操作会进行神经网络训练,而这两个步骤是可以分步进行的,这样对于某些不可重复的流(譬如 Kafka 等流式数据中)可以手动控制:
model = gensim.models.Word2Vec(iter=1) # an empty model, no training yet
model.build_vocab(some_sentences) # can be a non-repeatable, 1-pass generator
model.train(other_sentences) # can be a non-repeatable, 1-pass generatorWord2Vec 参数
min_count
model = Word2Vec(sentences, min_count=10) # default value is 5在不同大小的语料集中,我们对于基准词频的需求也是不一样的。譬如在较大的语料集中,我们希望忽略那些只出现过一两次的单词,这里我们就可以通过设置min_count参数进行控制。一般而言,合理的参数值会设置在0~100之间。
size
size参数主要是用来设置神经网络的层数,Word2Vec 中的默认值是设置为100层。更大的层次设置意味着更多的输入数据,不过也能提升整体的准确度,合理的设置范围为 10~数百。
model = Word2Vec(sentences, size=200) # default value is 100workers
workers参数用于设置并发训练时候的线程数,不过仅当Cython安装的情况下才会起作用:
model = Word2Vec(sentences, workers=4) # default = 1 worker = no parallelization外部语料集
在真实的训练场景中我们往往会使用较大的语料集进行训练,譬如这里以 Word2Vec 官方的text8为例,只要改变模型中的语料集开源即可:
sentences = word2vec.Text8Corpus('text8')
model = word2vec.Word2Vec(sentences, size=200)这里语料集中的语句是经过分词的,因此可以直接使用。笔者在第一次使用该类时报错了,因此把 Gensim 中的源代码贴一下,也方便以后自定义处理其他语料集:
class Text8Corpus(object):
"""Iterate over sentences from the "text8" corpus, unzipped from http://mattmahoney.net/dc/text8.zip ."""
def __init__(self, fname, max_sentence_length=MAX_WORDS_IN_BATCH):
self.fname = fname
self.max_sentence_length = max_sentence_length
def __iter__(self):
# the entire corpus is one gigantic line -- there are no sentence marks at all
# so just split the sequence of tokens arbitrarily: 1 sentence = 1000 tokens
sentence, rest = [], b''
with utils.smart_open(self.fname) as fin:
while True:
text = rest + fin.read(8192) # avoid loading the entire file (=1 line) into RAM
if text == rest: # EOF
words = utils.to_unicode(text).split()
sentence.extend(words) # return the last chunk of words, too (may be shorter/longer)
if sentence:
yield sentence
break
last_token = text.rfind(b' ') # last token may have been split in two... keep for next iteration
words, rest = (utils.to_unicode(text[:last_token]).split(),
text[last_token:].strip()) if last_token >= 0 else ([], text)
sentence.extend(words)
while len(sentence) >= self.max_sentence_length:
yield sentence[:self.max_sentence_length]
sentence = sentence[self.max_sentence_length:]我们在上文中也提及,如果是对于大量的输入语料集或者需要整合磁盘上多个文件夹下的数据,我们可以以迭代器的方式而不是一次性将全部内容读取到内存中来节省 RAM 空间:
class MySentences(object):
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
for fname in os.listdir(self.dirname):
for line in open(os.path.join(self.dirname, fname)):
yield line.split()
sentences = MySentences('/some/directory') # a memory-friendly iterator
model = gensim.models.Word2Vec(sentences)模型保存与读取
model.save('text8.model')
2015-02-24 11:19:26,059 : INFO : saving Word2Vec object under text8.model, separately None
2015-02-24 11:19:26,060 : INFO : not storing attribute syn0norm
2015-02-24 11:19:26,060 : INFO : storing numpy array 'syn0' to text8.model.syn0.npy
2015-02-24 11:19:26,742 : INFO : storing numpy array 'syn1' to text8.model.syn1.npy
model1 = Word2Vec.load('text8.model')
model.save_word2vec_format('text.model.bin', binary=True)
2015-02-24 11:19:52,341 : INFO : storing 71290x200 projection weights into text.model.bin
model1 = word2vec.Word2Vec.load_word2vec_format('text.model.bin', binary=True)
2015-02-24 11:22:08,185 : INFO : loading projection weights from text.model.bin
2015-02-24 11:22:10,322 : INFO : loaded (71290, 200) matrix from text.model.bin
2015-02-24 11:22:10,322 : INFO : precomputing L2-norms of word weight vectors模型预测
Word2Vec 最著名的效果即是以语义化的方式推断出相似词汇:
model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)
[('queen', 0.50882536)]
model.doesnt_match("breakfast cereal dinner lunch";.split())
'cereal'
model.similarity('woman', 'man')
0.73723527
model.most_similar(['man'])
[(u'woman', 0.5686948895454407),
(u'girl', 0.4957364797592163),
(u'young', 0.4457539916038513),
(u'luckiest', 0.4420626759529114),
(u'serpent', 0.42716869711875916),
(u'girls', 0.42680859565734863),
(u'smokes', 0.4265017509460449),
(u'creature', 0.4227582812309265),
(u'robot', 0.417464017868042),
(u'mortal', 0.41728296875953674)]如果我们希望直接获取某个单词的向量表示,直接以下标方式访问即可:
model['computer'] # raw NumPy vector of a word
array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)模型评估
Word2Vec 的训练属于无监督模型,并没有太多的类似于监督学习里面的客观评判方式,更多的依赖于端应用。Google 之前公开了20000条左右的语法与语义化训练样本,每一条遵循A is to B as C is to D这个格式,地址在这里:
model.accuracy('/tmp/questions-words.txt')
2014-02-01 22:14:28,387 : INFO : family: 88.9% (304/342)
2014-02-01 22:29:24,006 : INFO : gram1-adjective-to-adverb: 32.4% (263/812)
2014-02-01 22:36:26,528 : INFO : gram2-opposite: 50.3% (191/380)
2014-02-01 23:00:52,406 : INFO : gram3-comparative: 91.7% (1222/1332)
2014-02-01 23:13:48,243 : INFO : gram4-superlative: 87.9% (617/702)
2014-02-01 23:29:52,268 : INFO : gram5-present-participle: 79.4% (691/870)
2014-02-01 23:57:04,965 : INFO : gram7-past-tense: 67.1% (995/1482)
2014-02-02 00:15:18,525 : INFO : gram8-plural: 89.6% (889/992)
2014-02-02 00:28:18,140 : INFO : gram9-plural-verbs: 68.7% (482/702)
2014-02-02 00:28:18,140 : INFO : total: 74.3% (5654/7614)还是需要强调下,训练集上表现的好也不意味着 Word2Vec 在真实应用中就会表现的很好,还是需要因地制宜。


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。