
用了Vue很久了,最近决定系统性的看看Vue的源码,相信看源码的同学不在少数,但是看的时候却发现挺有难度,Vue虽然足够精简,但是怎么说现在也有10k行的代码量了,深入进去逐行查看的时候感觉内容庞杂并且搞不懂代码的目的,同时网上的深入去仔细阐述Vue的compile/link/ expression parse/依赖订阅和收集/batcher的文章却不多,我自己读源码时,深感在这些环节可供参考的资料稀缺。网上较多的文章都在讲getter/setter、Mutation Observer和LRU缓存。所以我趁着寒假详细的阅读了Vue构建整个响应式过程的代码,基本包括数据observe到模板解析、transclude、compile、link、指令的bind、update、dom批处理更新、数组diff等等环节,并用这篇文章详细的介绍出来,希望能帮到想学习Vue源码或者想参与Vue维护、提交pr的同学。
Vue源码详解系列文章和配套的我整理的Vue源码注释版已经在git上开项:Vue源码注释版及详解,欢迎大家在git上查看,并配合注释版源码使用。订阅文章更新请watch。
注释版源码主要注释了本文中涉及的部分,依然有很多没有涉及,我个人精力有限,欢迎大家提pr,如果您喜欢,多谢您的star~
本文介绍的源码版本是当前(17年2月23日)1.x版本的最新版v1.0.26,2.x版本的源码我先学学虚拟dom之后再进行。
源码整体概览
Vue源码构造实例的过程就一行this._init(options),用你的参数对象去执行init初始化函数。init函数中先进行了大量的参数初始化操作this.xxx = blabla,然后剩下这么几行代码(后文所有的英文注释是尤雨溪所写,中文是我添加的,英文注释极其精确、简洁,请勿忽略)
this._data = {}
// call init hook
this._callHook('init')
// initialize data observation and scope inheritance.
this._initState()
// setup event system and option events.
this._initEvents()
// call created hook
this._callHook('created')
// if `el` option is passed, start compilation.
if (options.el) {
this.$mount(options.el)
}基本就是触发init钩子,初始化一些状态,初始化event,然后触发created钩子,最后挂载到具体的元素上面去。_initState()方法中包含了数据的初始化操作,也就是让数据变成响应式的,让Vue能够监听到数据的变动。而this.$mount()方法则承载了绝大部分的代码量,负责模板的嵌入、编译、link、指令和watcher的生成、批处理的执行等等。
从数据的响应化说起
嗯,是的,虽然这个observe数据的部分已经被很多文章说烂了,但是我并不只是讲getter/setter,这里应该会有你没看过的部分,比如Vue是如何解决"getter/setter无法监听属性的添加和删除"的。
熟悉Vue的同学都了解Vue的响应式特性,对于data对象的几乎任何更改我们都能够监听到。这是MVVM的基础,基本思路就是遍历每一个属性,然后使用Object.defineProperty将这个属性设置为响应式的(即我能监听到他的改动)。
先说遍历,很简单,如下10行左右代码就足够遍历一个对象了:
function touch (obj) {
if (typeof obj === 'object')
if (Array.isArray(obj)) {
for (let i = 0,l = obj.length; i < l; i++) {
touch(obj[i])
}
} else {
let keys = Object.keys(obj)
for (let key of keys) touch(obj[key])
}
console.log(obj)
}遇到普通数据属性,直接处理,遇到对象,遍历属性之后递归进去处理属性,遇到数组,递归进去处理数组元素(console.log)。
遍历完就到处理了,也就是Object.defineProperty部分了,对于一个对象,我们可以用这个来改写它属性的getter/setter,这样,当你改属性的值我就有办法监听到。但是对于数组就有问题了。
你也许想到可以遍历当前存在的下标,然后执行Object.defineProperty。这种处理方法先不说性能问题,很多时候我们操作数组是采用push、pop、splice、unshift等方法来操作的,光是push你就没办法监听,更不要说pop后你设置的getter/setter就直接没了。
所以,Vue的方法是,改写数组的push、pop等8个方法,让他们在执行之后通知我数组更新了(这种方法带来的后果就是你不能直接修改数组的长度或者通过下标去修改数组。参见官网)。这样改进之后我就不需要对数组元素进行响应式处理,只是遇到数组的时候把数组的方法变异即可。于是在用户使用数组的push、pop等方法会改变数组本身的方法时,可以监听到数组变动。
此外,当数组内部元素是对象时,设置getter/setter是可以监听对象的,所以对于数组元素还是要遍历一下的。如果不是对象,比如a[0]是字符串、数字?那就没办法了,但是vue为数组提供了$set和$remove,方便我们可以通过下标去响应式的改动数组元素,这里后文再说。
我们先说说怎么“变异”数组的push等方法,并且找出数组元素中的对象,让对象响应式。我们结合我的注释版源码来看一下。
Vue.prototype._initData = function () {
// 初始化数据,其实一方面把data的内容代理到vm实例上,
// 另一方面改造data,变成reactive的
// 即get时触发依赖收集(将订阅者加入Dep实例的subs数组中),set时notify订阅者
var dataFn = this.$options.data
var data = this._data = dataFn ? dataFn() : {}
var props = this._props
// proxy data on instance
var keys = Object.keys(data)
var i, key
i = keys.length
while (i--) {
key = keys[i]
// 将data属性的内容代理到vm上面去,使得vm访问指定属性即可拿到_data内的同名属性
// 实现vm.prop === vm._data.prop,
// 这样当前vm的后代实例就能直接通过原型链查找到父代的属性
// 比如v-for指令会为数组的每一个元素创建一个scope,这个scope就继承自vm或上级数组元素的scope,
// 这样就可以在v-for的作用域中访问父级的数据
this._proxy(key)
}
// observe data
//重点来了
observe(data, this)
}<p class="tip">(注释里的依赖收集、Dep什么的大家看不懂没关系,请跳过,后面会细说)
</p>
代码中间做了_proxy操作,注释里我已经写明原因。_proxy操作也很简单想了解的话大家自己查看源码即可。
代理完了之后就开始observe这个data:
export function observe (value, vm) {
if (!value || typeof value !== 'object') {
// 保证只有对象会进入到这个函数
return
}
var ob
if (
//如果这个数据身上已经有ob实例了,那observe过了,就直接返回那个ob实例
hasOwn(value, '__ob__') &&
value.__ob__ instanceof Observer
) {
ob = value.__ob__
} else if (
shouldConvert &&
(isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue
) {
// 是对象(包括数组)的话就深入进去遍历属性,observe每个属性
ob = new Observer(value)
}
if (ob && vm) {
// 把vm加入到ob的vms数组当中,因为有的时候我们会对数据手动执行$set/$delete操作,
// 那么就要提示vm实例这个行为的发生(让vm代理这个新$set的数据,和更新界面)
ob.addVm(vm)
}
return ob
}代码的执行过程一般都是进入到那个else if里,执行new Observer(value),至于shouldConvert和后续的几个判断则是为了防止value不是单纯的对象而是Regexp或者函数之类的,或者是vm实例再或者是不可扩展的,shouldConvert则是某些特殊情况下为false,它的解释参见源码里尤雨溪的注释。
那好,现在就进入到拿当前的data对象去new Observer(value),现在你可能会疑惑,递归遍历的过程不是应该是纯命令式的、面向过程的吗?怎么代码跑着跑着跑出来一句new一个对象了,嗯先不用管,我们先理清代码执行过程,先带着这个疑问。同时,我们注意到代码最后return了ob,结合代码,我们可以理解为如果return的是undifned,那么说明传进来的value不是对象,反之return除了一个ob,则说明这个value是对象或数组,他可以添加或删除属性,这一点我们先记着,这个东西后面有用。
我们先看看Observer构造函数:
/**
* Observer class that are attached to each observed
* object. Once attached, the observer converts target
* object's property keys into getter/setters that
* collect dependencies and dispatches updates.
*
* @param {Array|Object} value
* @constructor
*/
function Observer (value) {
this.value = value
this.dep = new Dep()
def(value, '__ob__', this) //value的__ob__属性指向这个Ob实例
if (isArray(value)) {
var augment = hasProto
? protoAugment
: copyAugment
augment(value, arrayMethods, arrayKeys)
this.observeArray(value)
} else {
// 如果是对象则使用walk遍历每个属性
this.walk(value)
}
}observe一个数组
上述代码中,如果遇到数组data中的数组实例增加了一些“变异”的push、pop等方法,这些方法会在数组原本的push、pop方法执行后发出消息,表明发生了改动。听起来这好像可以用继承的方式实现: 继承数组然后在这个子类的原型上附加上变异的方法。
但是你需要知道的是在es5及更低版本的js里,无法完美继承数组,主要原因是Array.call(this)时,Array根本不是像一般的构造函数那样对你传进去this进行改造,而是直接返回一个新的数组。所以一般的继承方式就没法实现了。参见这篇文章,所以出现了新建一个iframe,然后直接拿那个iframe里的数组的原型进行修改,添加自定义方法,诸如此类的hack方法,在此按下不表。
但是如果当前浏览器里存在__proto__这个非标准属性的话(大部分都有),那又可以有方法继承,就是创建一个继承自Array.prototype的Object: Object.create(Array.prototype),在这个继承了数组原生方法的对象上添加方法或者覆盖原有方法,然后创建一个数组,把这个数组的__proto__指向这个对象,这样这个数组的响应式的length属性又得以保留,又获得了新的方法,而且无侵入,不会改变本来的数组原型。
Vue就是基于这个思想,先判断__proto__能不能用(hasProto),如果能用,则把那个一个继承自Array.prototype的并且添加了变异方法的Object (arrayMethods),设置为当前数组的__proto__,完成改造,如果__proto__不能用,那么就只能遍历arrayMethods就一个个的把变异方法def到数组实例上面去,这种方法效率不高,所以优先使用改造__proto__的那个方法。
源码里后面那句this.observeArray非常简单,for遍历传进去的value,然后对每个元素执行observe,处理之前说的数组的元素为对象或者数组的情况。好了,对于数组的讨论先打住,至于数组的变异方法怎么通知我他进行了更改之类的我们不说了,我们先说清楚对象的情况,对象说清楚了,再去看源码就一目了然了。
observe 对象
对于对象,上面的代码执行this.walk(value),他“游走”对象的每个属性,对属性和属性值执行defineReactive函数。
function Dep () {
this.id = uid++
this.subs = []
}
Dep.prototype.depend = function () {
Dep.target.addDep(this)
}
Dep.prototype.notify = function () {
// stablize the subscriber list first
var subs = toArray(this.subs)
for (var i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
function defineReactive (obj, key, val) {
// 生成一个新的Dep实例,这个实例会被闭包到getter和setter中
var dep = new Dep()
var property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
var getter = property && property.get
var setter = property && property.set
// 对属性的值继续执行observe,如果属性的值是一个对象,那么则又递归进去对他的属性执行defineReactive
// 保证遍历到所有层次的属性
var childOb = observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
var value = getter ? getter.call(obj) : val
// 只有在有Dep.target时才说明是Vue内部依赖收集过程触发的getter
// 那么这个时候就需要执行dep.depend(),将watcher(Dep.target的实际值)添加到dep的subs数组中
// 对于其他时候,比如dom事件回调函数中访问这个变量导致触发的getter并不需要执行依赖收集,直接返回value即可
if (Dep.target) {
dep.depend()
if (childOb) {
//如果value是对象,那就让生成的Observer实例当中的dep也收集依赖
childOb.dep.depend()
}
if (isArray(value)) {
for (var e, i = 0, l = value.length; i < l; i++) {
e = value[i]
//如果数组元素也是对象,那么他们observe过程也生成了ob实例,那么就让ob的dep也收集依赖
e && e.__ob__ && e.__ob__.dep.depend()
}
}
}
return value
},
set: function reactiveSetter (newVal) {
var value = getter ? getter.call(obj) : val
if (newVal === value) {
return
}
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
// observe这个新set的值
childOb = observe(newVal)
// 通知订阅我这个dep的watcher们:我更新了
dep.notify()
}
})
}
我们来说说这个Dep,Dep类的定义极其简单,一个id,一个数组,他就是一个很基本的发布者-观察者模式的实现,作为一个发布者,他的subs属性用来存放了订阅他的观察者,也就是后面我们会说到的watcher。
defineProperty是用来将对象的属性转化为响应式的getter/setter的,defineProperty函数执行过程中新建了一个Dep,闭包在了属性的getter和setter中,因此每个属性都有一个唯一的Dep与其对应,我们暂且可以把属性和他对应的Dep理解为一体的。
Dep其实是dependence依赖的缩写,我之前一直没能理解依赖、依赖收集是什么,其实对于我们的一个模板{{a+b}},我们会说他的依赖有a和b,其实就是依赖了data的a和b属性,更精确的说是依赖了a属性中闭包的dep实例和b属性中闭包的那个dep实例。
详细来说:我们的这个{{a+b}}在dom里最终会被"a+b"表达式的真实值所取代,所以存在一个求出这个“a+b”的表达式的过程,求值的过程就会自然的分别触发a和b的getter,而在getter中,我们看到执行了dep.depend(),这个函数实际上回做dep.addSub(Dep.target),即在dep的订阅者数组中存放了Dep.target,让Dep.target订阅dep。
那Dep.target是什么?他就是我们后面介绍的Watcher实例,为什么要放在Dep.target里呢?是因为getter函数并不能传参,dep可以通过闭包的形式放进去,那watcher可就不行了,watcher内部存放了a+b这个表达式,也是由watcher计算a+b的值,在计算前他会把自己放在一个公开的地方(Dep.target),然后计算a+b,从而触发表达式中所有遇到的依赖的getter,这些getter执行过程中会把Dep.target加到自己的订阅列表中。等整个表达式计算成功,Dep.target又恢复为null.这样就成功的让watcher分发到了对应的依赖的订阅者列表中,订阅到了自己的所有依赖。
我们可以看到这是极其精妙的一笔!在一个表达式的求值过程中隐式的完成依赖订阅。
上面完成的是订阅的过程,而上面setter代码里的dep.notify就负责完成数据变动时通知订阅者的功能。而且数据变化时,后文会说明只有依赖他的那些dom会精确更新,不会出现一些介绍mvvm的文章里虽然实现了订阅更新但是重新计算整个视图的情况。
于是一整个对象订阅、notify的过程就结束了。
Observer类?
现在我们明白了Dep的作用和收集订阅依赖的过程,但是对于watcher是什么肯定还是云里雾里的,先别急。我们先解决之前的疑问:为什么命令式的监听过程中出现了个new Observer()?而且构造函数第一行就创建了一个dep(这个dep不是defineReactive里的那个闭包dep,注意区分),在defineReactive函数的getter中还执行了childOb.dep.depend(),去完成了这个dep的watcher添加?
我们考虑一下这样的情况,比如我的data:{a:{b:true}},这个时候,如果页面有dom上有个指令:class="a",而我想响应式的删除data.a的b属性,此时我就没有办法了,因为defineReactive中的getter/setter都不会执行(他们甚至还会在delete a.b时被清空),闭包里的那个dep就无法通知对应的watcher。
这就是getter和setter存在的缺陷:只能监听到属性的更改,不能监听到属性的删除与添加。
Vue的解决办法是提供了响应式的api: vm.$set/vm.$delete/ Vue.set/ Vue.delete /数组的$set/数组的$remove。
具体方法是为所有的对象和数组(只有这俩哥们才可能delete和新建属性),也创建一个dep,也完成收集依赖的过程。我们回到源码defineReactive再看一遍,在执行defineReactive(data,'a',{b:true})时,他首先创造了那个闭包在getter/setter中的dep,然后var childOb = observe(val),val是{b:true},那就会为这个对象new Observer(val),并放在val.__ob__上,而这个ob实例上存放了一个Dep实例。现在我们看到,有两个Dep实例,一个是闭包里的dep,一个是为{b:true}创建的ob上的这个dep。而:class="a"生成的watcher的求值过程中会触发到a的getter,那就会执行:
dep.depend()
if (childOb) {
//如果value是对象,那就让生成的Observer实例当中的dep也收集依赖
childOb.dep.depend()
}这一步,:class="a"的watcher既会订阅闭包dep,也会订阅ob的dep。
当我们执行Vue.delete(this.a,'b'),内部会执行del函数,他会找到要删除属性的那个对象,也是{b:true},它的__ob__属性存放了ob,现在先删除属性,然后执行ob.dep.notify,通知所有依赖这个对象的watcher重新计算,这个时候属性已经删除了,重新计算的值(为空)就会刷新到页面上,完成dom响应式更新。参见此处源码。
不仅对于属性的删除这样,属性的的添加也是类似的,都是为了弥补getter和setter存在的缺陷,都会找到这个dep执行notify。不过data的顶级属性略有不同,涉及到digest,此处不表。
同时我们再回到之前遍历数组的代码,我们数组的响应化代码甚至都里没有getter/setter,他连那个闭包的dep都没有,代码只是变异了一下push/pop方法。他有的只是那个childOb上的dep,所以数组的响应式过程都是notify的这个dep,不管是数组的变异方法),还是数组的$set/$remove里我们都会看到是在这个dep上触发notify,通知订阅了整个数组的watcher进行更新。所以你知道这个dep的重要性了把。当然这也就有问题了,我一个watcher订阅整个数组,当数组的元素有改动我就会收到消息,但我不知道变动的是哪个,难道我要用整个数组重新构造一下dom?所以这就是数组diff算法的使用场景了。
至于Observer,这个额外的实例上存放了一个dep,这个dep配合Observer的addVm、removeVm、vms等属性来一起搞定data的顶级属性的新增或者删除,至于为什么不直接在数据上存放dep,而是搞个Observer,并把dep定义在上面,我觉得是Observer的那些方法和vms等属性,并不是所有的dep都应该具有的,作为dep的实例属性是不应该的,所以就抽象了个Observer这么个东东吧,顺便把walk、convert之类的函数变成方法挂在Observer上了,抽象出个专门用来observe的类而已,这部分纯属个人臆测。
_compile
介绍完响应式的部分,算是开了个头了,后面的内容很多,但是层层递进,最终完成响应式精确订阅和批处理更新的整个过程,过程比较流程,内容耦合度也高,所以我们先来给后文的概览,介绍一下大体过程。
我们最开始的代码里提到了Vue处理完数据和event之后就到了$mount,而$mount就是在this._compile后触发编译完成的钩子而已,所以核心就是Vue.prototype._compile。
_compile包含了Vue构建的三个阶段,transclude,compile,link。而link阶段其实是放在linkAndCapture里执行的,这里又包含了watcher的生成,指令的bind、update等操作。
我先简单讲讲什么是指令,虽然Vue文档里说的指令是v-if,v-for等这种HTML的attribute,其实在Vue内部,只要是被Vue处理的dom上的东西都是指令,比如dom内容里的{{a}},最终会转换成一个v-text的指令和一个textNode,而一个子组件<component><component>也会生成指令,还有slot,或者是你自己在元素上写的attribute比如hello={{you}}也会被编译为一个v-bind指令。我们看到,基本只要是涉及dom的(不是响应式的也包含在内,只要是vue提供的功能),不管是dom标签,还是dom属性、内容,都会被处理为指令。所以不要有指令就是attribute的惯性思维。
回过头来,_compile部分大致分为如下几个部分
-
transclude
transclude的意思是内嵌,这个步骤会把你template里给出的模板转换成一段dom,然后抽取出你el选项指定的dom里的内容(即子元素,因为模板里可能有slot),把这段模板dom嵌入到el里面去,当然,如果replace为true,那他就是直接替换el,而不是内嵌。我们大概明白transclude这个名字的意义了,但其实更关键的是把template转换为dom的过程(如`<p>{{a}}<p>`字符串转为真正的段落元素),这里为后面的编译准备好了dom。 -
compile
compile的的过程具体就是**遍历模板解析出模板里的指令**。更精确的说是解析后生成了指令描述对象。 同时,compile函数是一个高阶函数,他执行完成之后的返回值是另一个函数:link,所以compile函数的第一个阶段是编译,返回出去的这个函数完成另一个阶段:link。 -
link
compile阶段将指令解析成为指令描述对象(descriptor),闭包在了link函数里,link函数会把descriptor传入Directive构造函数,创建出真正的指令实例。此外link函数是作为参数传入linkAndCaptrue中的,后者负责执行link,同时取出这些新生成的指令,先按照指令的预置的优先级从高到低排好顺序,然后遍历指令执行指令的_bind方法,这个方法会为指令创建watcher,并计算表达式的值,完成前面描述的依赖收集。并最后执行对应指令的bind和update方法,使指令生效、界面更新。 此外link函数最终的返回值是unlink函数,负责在vm卸载时取消对应的dom到数据的绑定。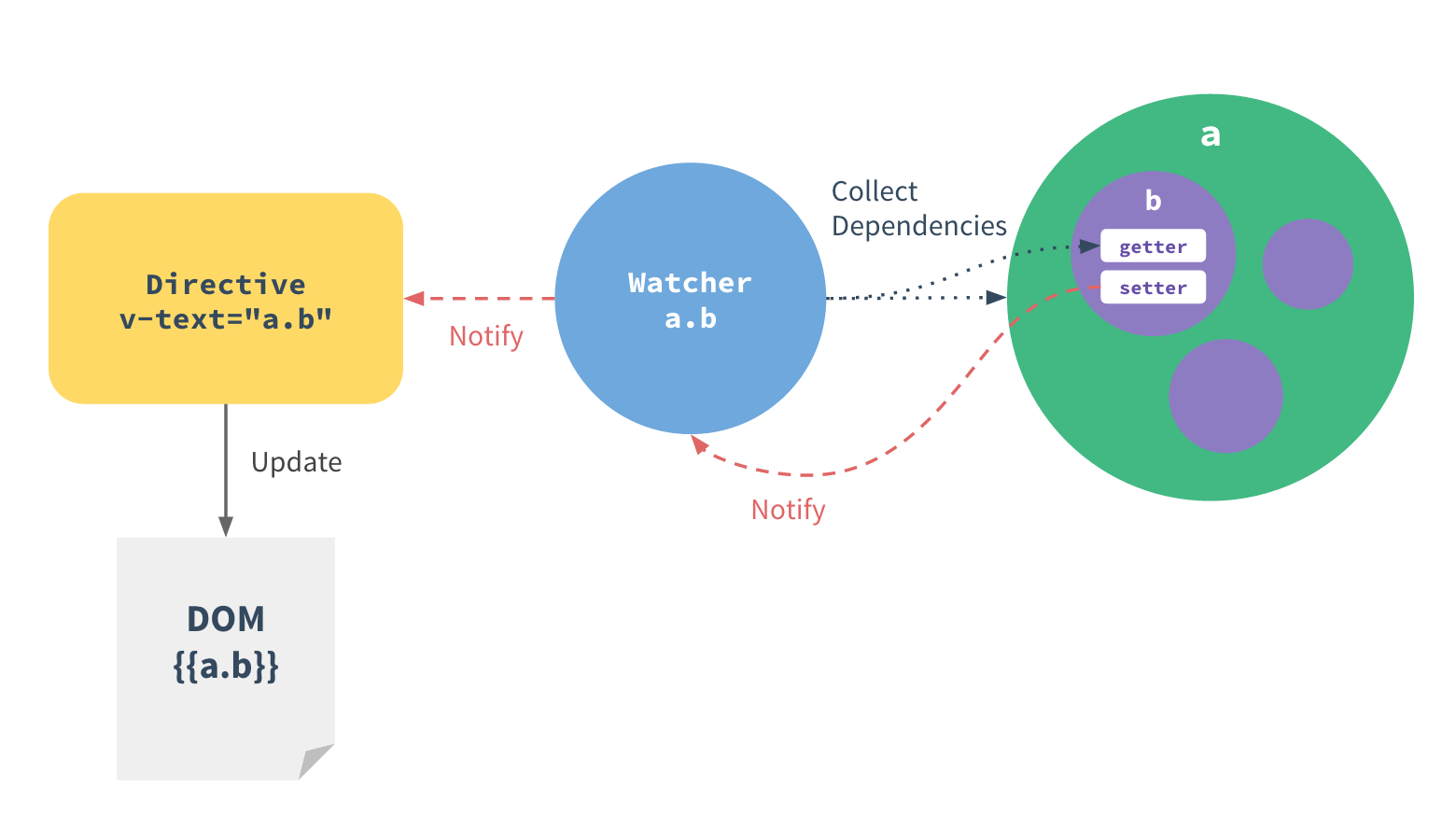
是时候回过头来看看Vue官网这张经典的图了,以前我刚学Vue时也是对于Watcher,Directive之类的概念云里雾里。但是现在大家看这图是不是很清晰明了?
模板中每个指令/数据绑定都有一个对应的 watcher 对象,在计算过程中它把属性记录为依赖。之后当依赖的 setter 被调用时,会触发 watcher 重新计算 ,也就会导致它的关联指令更新 DOM。 --Vue官网
上代码:
Vue.prototype._compile = function (el) {
var options = this.$options
// transclude and init element
// transclude can potentially replace original
// so we need to keep reference; this step also injects
// the template and caches the original attributes
// on the container node and replacer node.
var original = el
el = transclude(el, options)
// 在el这个dom上挂一些参数,并触发'beforeCompile'钩子,为compile做准备
this._initElement(el)
// handle v-pre on root node (#2026)
// v-pre指令的话就什么都不用做了。
if (el.nodeType === 1 && getAttr(el, 'v-pre') !== null) {
return
}
// root is always compiled per-instance, because
// container attrs and props can be different every time.
var contextOptions = this._context && this._context.$options
var rootLinker = compileRoot(el, options, contextOptions)
// resolve slot distribution
// 具体是将各个slot存储到vm._slotContents的对应属性里面去,
// 然后后面的compile阶段会把slot解析为指令然后进行处理
resolveSlots(this, options._content)
// compile and link the rest
var contentLinkFn
var ctor = this.constructor
// component compilation can be cached
// as long as it's not using inline-template
// 这里是组件的情况才进入的,大家先忽略此段代码
if (options._linkerCachable) {
contentLinkFn = ctor.linker
if (!contentLinkFn) {
contentLinkFn = ctor.linker = compile(el, options)
}
}
// link phase
// make sure to link root with prop scope!
var rootUnlinkFn = rootLinker(this, el, this._scope)
// compile和link一并做了
var contentUnlinkFn = contentLinkFn
? contentLinkFn(this, el)
: compile(el, options)(this, el)
// register composite unlink function
// to be called during instance destruction
this._unlinkFn = function () {
rootUnlinkFn()
// passing destroying: true to avoid searching and
// splicing the directives
contentUnlinkFn(true)
}
// finally replace original
if (options.replace) {
replace(original, el)
}
this._isCompiled = true
this._callHook('compiled')
}
尤雨溪的注释已经极尽详细,上面的代码很清晰(如果你用过angular,那你会感觉很熟悉,angular里也是有transclude,compile和link的,虽然实际差别很大)。我们在具体进入各部分代码前先说说为什么dom的编译要分成compile和link两个phase。
在组件的多个实例、v-for数组等场合,我们会出现同一个段模板要绑定不同的数据然后分发到dom里面去的需求。这也是mvvm性能考量的主要场景:大数据量的重复渲染生成。而重复渲染的模板是一致的,不一致的是他们需要绑定的数据,因此compile阶段找出指令的过程是不用重复计算的,只需要link函数(和里面闭包的指令),而模板生成的dom使用原生的cloneNode方法即可复制出一份新的dom。现在,复制出的新dom+ link+具体的数据即可完成渲染,所以分离compile、并缓存link使得Vue在渲染时避免大量重复的性能消耗。
transclude函数
这里大家可以考虑一下,我给你一个空的documentFragment和一段html字符串,让你把html生成dom放进fragment里,你应该怎么做?innerHTML?documentFragment可是没有innerHtml的哦。那先建个div再innerHTML?那万一我的html字符串的是tr元素呢?tr并不能直接放进div里哦,那直接用outerHTML?没有parent Node的元素是不能设置outerHTML的哈(parent是fragment也不行),那我先用正则提取第一个标签,先createElement这个标签然后在写他的innerHTML总可以了吧?并不行,我没告诉你我给你的这段HTML最外层就一个元素啊,万一是个片段实例呢(也就是包含多个顶级元素,如<p>1<p><p>2<p>),所以我才说给你一个fragment当容器,让你把dom装进去。
上面这个例子说明了实际转换dom过程中,可能遇到的一个小坑,只是想说明字符串转dom并不是看起来那么一行innerHTML的事。
/**
* Process an element or a DocumentFragment based on a
* instance option object. This allows us to transclude
* a template node/fragment before the instance is created,
* so the processed fragment can then be cloned and reused
* in v-for.
*
* @param {Element} el
* @param {Object} options
* @return {Element|DocumentFragment}
*/
export function transclude (el, options) {
// extract container attributes to pass them down
// to compiler, because they need to be compiled in
// parent scope. we are mutating the options object here
// assuming the same object will be used for compile
// right after this.
if (options) {
options._containerAttrs = extractAttrs(el)
}
// for template tags, what we want is its content as
// a documentFragment (for fragment instances)
if (isTemplate(el)) {
el = parseTemplate(el)
}
if (options) {
// 如果当前是component,并且没有模板,只有一个壳
// 那么只需要处理内容的嵌入
if (options._asComponent && !options.template) {
options.template = '<slot></slot>'
}
if (options.template) {
//基本都会进入到这里
options._content = extractContent(el)
el = transcludeTemplate(el, options)
}
}
if (isFragment(el)) {
// anchors for fragment instance
// passing in `persist: true` to avoid them being
// discarded by IE during template cloning
prepend(createAnchor('v-start', true), el)
el.appendChild(createAnchor('v-end', true))
}
return el
}我们看上面的代码,先options._containerAttrs = extractAttrs(el),这样就把el元素上的所有attributes抽取出来存放在了选项对象的_containerAttrs属性上。因为我们前面说过,这些属性是vm实际挂载的根元素上的,如果vm是一个组件之类的,那么他们应该是在父组件的作用于编译/link的,所以需要预先提取出来,因为如果replace为true,el元素会被模板元素替换,但是他上面的属性是会编译link后merge到模板元素上面去。
然后进入到那个两层的if里, extractContent(el),将el的内容(子元素和文本节点)抽取出来,因为如果模板里有slot,那么他们要分发到对应的slot里。
然后就到el = transcludeTemplate(el, options):
/**
* Process the template option.
* If the replace option is true this will swap the $el.
*
* @param {Element} el
* @param {Object} options
* @return {Element|DocumentFragment}
*/
function transcludeTemplate (el, options) {
var template = options.template
var frag = parseTemplate(template, true)
if (frag) {
// 对于非片段实例情况且replace为true的情况下,frag的第一个子节点就是最终el元素的替代者
var replacer = frag.firstChild
var tag = replacer.tagName && replacer.tagName.toLowerCase()
if (options.replace) {
/* istanbul ignore if */
if (el === document.body) {
process.env.NODE_ENV !== 'production' && warn(
'You are mounting an instance with a template to ' +
'<body>. This will replace <body> entirely. You ' +
'should probably use `replace: false` here.'
)
}
// there are many cases where the instance must
// become a fragment instance: basically anything that
// can create more than 1 root nodes.
if (
// multi-children template
frag.childNodes.length > 1 ||
// non-element template
replacer.nodeType !== 1 ||
// single nested component
tag === 'component' ||
resolveAsset(options, 'components', tag) ||
hasBindAttr(replacer, 'is') ||
// element directive
resolveAsset(options, 'elementDirectives', tag) ||
// for block
replacer.hasAttribute('v-for') ||
// if block
replacer.hasAttribute('v-if')
) {
return frag
} else {
// 抽取replacer自带的属性,他们将在自身作用域下编译
options._replacerAttrs = extractAttrs(replacer)
// 把el的所有属性都转移到replace上面去,因为我们后面将不会再处理el直至他最后被replacer替换
mergeAttrs(el, replacer)
return replacer
}
} else {
el.appendChild(frag)
return el
}
} else {
process.env.NODE_ENV !== 'production' && warn(
'Invalid template option: ' + template
)
}
}首先执行解析parseTemplate(template, true),得到一段存放在documentFragment里的真实dom,然后就判断是否需要replace。(若replace为false)之后判断是否是片段实例,官网已经讲述哪几种情况对应片段实例,而代码里那几个判断就是对应的处理。若不是,那就进入后续的情况,我已经注释代码作用,就不再赘述。我们来说说parseTemplate,因为vue支持template选项写#app这样的HTML选择符,也支持直接存放模板字符串、document fragment、dom元素等等,所以针对各种情况作了区分,如果是一个已经好的dom那几乎不用处理,否则大部分情况下都是执行stringToFragment:
function stringToFragment (templateString, raw) {
// 缓存机制
// try a cache hit first
var cacheKey = raw
? templateString
: templateString.trim()
var hit = templateCache.get(cacheKey)
if (hit) {
return hit
}
//这三个正则分别是/<([\w:-]+)/ 和/&#?\w+?;/和/<!--/
var frag = document.createDocumentFragment()
var tagMatch = templateString.match(tagRE)
var entityMatch = entityRE.test(templateString)
var commentMatch = commentRE.test(templateString)
if (!tagMatch && !entityMatch && !commentMatch) {
// 如果没有tag 或者没有html字符实体(如 ) 或者 没有注释
// text only, return a single text node.
frag.appendChild(
document.createTextNode(templateString)
)
} else {
// 这里如前面的函数签名所说,使用了jQuery 和 component/domify中所使用的生成元素的策略
// 我们要将模板变成实际的dom元素,一个简单的方法的是创建一个div document.createElement('div')
// 然后再设置这个div的innerHtml为我们的模板,
// (不直接创建一个模板的根元素是因为模板可能是片段实例,也就会生成多个dom元素)
// (而设置这个div的outerHtml也不行哈,不能设置没有父元素的outerHtml)
// 但是许多特殊元素只能再固定的父元素下存在,不能直接存在于div下,比如tbody,tr,th,td,legend等等等等
// 那么怎么办? 所以就有了下面这个先获取第一个标签,然后按照map的里预先设置的内容,给模板设置设置好父元素,
// 把模板嵌入到合适的父元素下,然后再层层进入父元素获取真正的模板元素.
var tag = tagMatch && tagMatch[1]
var wrap = map[tag] || map.efault
var depth = wrap[0]
var prefix = wrap[1]
var suffix = wrap[2]
var node = document.createElement('div')
node.innerHTML = prefix + templateString + suffix
// 这里是不断深入,进入正确的dom,
// 比如你标签是tr,那么我会为包上table和tbody元素
// 那么我拿到你的时候应该剥开外层的两个元素,让node指到tr
while (depth--) {
node = node.lastChild
}
var child
/* eslint-disable no-cond-assign */
// 用while循环把所有的子节点都提取了,因为可能是片段实例
while (child = node.firstChild) {
/* eslint-enable no-cond-assign */
frag.appendChild(child)
}
}
if (!raw) {
trimNode(frag)
}
templateCache.put(cacheKey, frag)
return frag
}这个部分的代码就是用来处理我一开始介绍transclude提到的那个把html字符串转换为真正dom的问题。原理在代码的注释里已经说得很清楚了,比如<tr>a</tr>这段dom,那么代码里的tag就匹配上了'tr',map对象是预先写好的一个对象,map['tr']存放的内容就是这么个数组[2, '<table><tbody>', '</tbody></table>'],2表示真正的元素在2层dom里。剩下的两段字符串是用于添加在你的HTML字符串两端(prefix + templateString + suffix),现在innerHTML就设置为了'<table><tbody><tr>a</tr></tbody></table>',不会出现问题了。
现在transclude之后,字符串已经变成了dom。后续的就依据此dom,遍历dom树,提取其中的指令,那如果Vue一开始就没有把字符串转成dom,而是直接解析字符串,提取其中的指令的话,其实工程量是非常大的。一方面要自己构建dom结构,一方面还要解析dom的attribute和内容,而这三者在Vue允许实现自定义组件、自定义指令、自定义prop的情况下给直接分析纯字符串带来了很大难度。所以,实先构造为dom是很有必要的。
compile
compile阶段执行的compileRoot函数就是编译我们在transclude阶段说过的,我们分别提取到了el顶级元素的属性和模板的顶级元素的属性,如果是component,那就需要把两者分开编译生成两个link。主要就是对属性编译,后续内容会细说属性编译,所以在此处不细说了,注释版源码在此。后面的resolveSlots出于篇幅考虑,也不再介绍,如有需求,请查看注释版源码。
我们来说说compile函数,他对元素执行compileNode,对其childNodes执行compileNodeList:
export function compile (el, options, partial) {
// link function for the node itself.
var nodeLinkFn = partial || !options._asComponent
? compileNode(el, options)
: null
// link function for the childNodes
// 如果nodeLinkFn.terminal为true,说明nodeLinkFn接管了整个元素和其子元素的编译过程,那也就不用编译el.childNodes
var childLinkFn =
!(nodeLinkFn && nodeLinkFn.terminal) &&
!isScript(el) &&
el.hasChildNodes()
? compileNodeList(el.childNodes, options)
: null
return function compositeLinkFn (vm, el, host, scope, frag) {
// cache childNodes before linking parent, fix #657
var childNodes = toArray(el.childNodes)
// link
// 任何link都是包裹在linkAndCapture中执行的,详见linkAndCapture函数
var dirs = linkAndCapture(function compositeLinkCapturer () {
if (nodeLinkFn) nodeLinkFn(vm, el, host, scope, frag)
if (childLinkFn) childLinkFn(vm, childNodes, host, scope, frag)
}, vm)
return makeUnlinkFn(vm, dirs)
}
}上面的代码中,我们看到了一个terminal属性,详见官网说明,其实就是终端指令这么个东东,比如v-if 因为元素是否存在和是否需要编译得视v-if的值而定(这个元素最终都不存在那就肯定不用浪费时间去编译他...- -),所以这个terminal指令接管了他和他的子元素的编译过程,由他来控制何时进行自己和后代的编译和link。
compile函数就是执行了compileNode和compileNodeList两个编译操作,他们分别编译了元素本身和元素的childNodes,然后将返回的两个link放在一个“组合link”函数里返回出去,link函数的内容我下节再说。
我们回头看看compileNode具体是怎么做的。至于compileNodeList其实是对应于多个元素情况下,对每个元素执行compileNode、对其childNodes递归执行compileNodeList,本质上就是遍历元素递归对每个元素执行compileNode。
function compileNode (node, options) {
var type = node.nodeType
if (type === 1 && !isScript(node)) {
return compileElement(node, options)
} else if (type === 3 && node.data.trim()) {
return compileTextNode(node, options)
} else {
return null
}
}可以看到很简单,compileNode就是判断了下node是元素节点还是文本节点,那我们分别看一下元素和文本节点是怎么编译的。
compileElement
function compileElement (el, options) {
if (el.tagName === 'TEXTAREA') {
// textarea元素是把tag中间的内容当做了他的value,这和input什么的不太一样
// 因此大家写模板的时候通常是这样写: <textarea>{{hello}}</textarea>
// 但是template转换成dom之后,这个内容跑到了textarea元素的value属性上,tag中间的内容是空的,
// 因此遇到textarea的时候需要单独编译一下它的value
var tokens = parseText(el.value)
if (tokens) {
el.setAttribute(':value', tokensToExp(tokens))
el.value = ''
}
}
var linkFn
var hasAttrs = el.hasAttributes()
var attrs = hasAttrs && toArray(el.attributes)
// check terminal directives (for & if)
if (hasAttrs) {
linkFn = checkTerminalDirectives(el, attrs, options)
}
// check element directives
if (!linkFn) {
linkFn = checkElementDirectives(el, options)
}
// check component
if (!linkFn) {
linkFn = checkComponent(el, options)
}
// normal directives
if (!linkFn && hasAttrs) {
// 一般会进入到这里
linkFn = compileDirectives(attrs, options)
}
return linkFn
}代码过程中检测该元素是否有Terminal指令、是否是元素指令和component,这些情况下他们会接管元素及后代元素的编译过程。而一般情况下会执行compileDirectives,也就是编译元素上的属性。
我先说一下哪些属性需要处理的:
一种是有插值的,插值其实就是我们很熟悉的
{{a}}这样的形式比如id="item-{{ id }}",另外vue还支持html插值:{{{a}}}和单次插值{{* a}}。在属性里的插值,比如test="{{a}}"其实等价于v-bind:test="a"。另一种则是
v-model="a"这样的vue指令,其不需要在value里写插值。
compileDirectives代码较长,不便贴出。代码主要是首先对属性的value执行parseText,检测value中是否有插值的情况,若有则返回插值的处理结果:token数组。如果没返回token,那么在检测属性的name是否是Vue的提供的指令比如v-if、transition或者@xxxx、:xxxx之类。
总之上述两种情况不管是那种出现了,就会对属性做进一步处理,比如拿属性的name执行parseModifiers,提取出属性中可能存在的修饰符,诸如此类,这些过程主要是使用正则表达式进行所需值的提取。
最终会生成这么一个指令描述对象,以v-bind:href.literal="mylink"为例:
{
arg:"href",
attr:"v-bind:href.literal",
def:Object,// v-bind指令的定义
expression:"mylink", // 表达式,如果是插值的话,那主要用到的是下面的interp字段
filters:undefined
hasOneTime:undefined
interp:undefined,// 存放插值token
modifiers:Object, // literal修饰符的定义
name:"bind" //指令类型
raw:"mylink" //未处理前的原始属性值
}这就是指令描述对象,他包含了指令构造过程和执行过程的所有信息。对象中的def属性存放了指令定义对象。因为vue提供了大量的指令,并且也允许自定义指令,写过自定义指令的同学肯定清楚要定义的指令bind、updaate等方法。指令大运行过程都是一致的,不同就在于这些bind、update、优先级等细节,因此如果为这二三十个指令实现一个单独的类并根据指令描述对象手动调用对应的构造函数是不可取的。Vue是定义了一个统一的指令类Directive,在创建时Directive实例时,会把上述def属性存放的具体指令的定义对象拷贝到this上,从而完成具体的指令的创建过程。
回过头来说一说解析插值的parseText的具体执行过程,其核心过程就是这么几句代码(为方便理解,改了一下原版的),代码的注释已经解释清楚代码执行过程。
// 仅用于匹配html插值
var htmlRE = /{{{.+?}}}/
// 用于匹配插值模板,可能是两个花括号,也可能是三个花括号
var tagRE = /{{(.+?)}}|{{{(.+?)}}}/
var lastIndex = 0
var match, index, html, value, first, oneTime
/* eslint-disable no-cond-assign */
// 反复执行匹配操作,直至所有的插值都匹配完
while (match = tagRE.exec(text)) {
// 当前匹配的起始位置
index = match.index
// push text token
if (index > lastIndex) {
// 如果index比lastIndex要大,说明当前匹配的起始位置和上次的结束位置中间存在空隙,
// 比如'{{a}} to {{b}}',这个空隙就是中间的纯字符串部分' to '
tokens.push({
value: text.slice(lastIndex, index)
})
}
// tag token
html = htmlRE.test(match[0])
// 如果用于匹配{{{xxx}}}的htmlRE匹配上了,则应该从第一个捕获结果中取出value,反之则为match[2]
value = html ? match[1] : match[2]
first = value.charCodeAt(0)
// 有value的第一个字符是否为* 判断是否是单次插值
oneTime = first === 42 // *
value = oneTime
? value.slice(1)
: value
tokens.push({
tag: true, // 是插值还是普通字符串
value: value.trim(), // 普通字符串或者插值表达式
html: html, // 是否为html插值
oneTime: oneTime // 是否为单次插值
})
// lastIndex记录为本次匹配结束位置的后一位.
// 注意index + match[0].length到达的是后一位
lastIndex = index + match[0].length
}
if (lastIndex < text.length) {
// 如果上次匹配结束位置的后一位之后还存在空间,则应该是还有纯字符串
tokens.push({
value: text.slice(lastIndex)
})
}代码的执行结果就是把插值字符串转换成了一个token数组,每个token其实就是一个简单对象,里面的四个属性记录了对应的插值信息。这些token最终会存放在前述指令描述对象的interp字段里(interp为Interpolation简写)。
compileTextNode
说完了怎么处理element,那就看看另一种情况:textNode。
function compileTextNode (node, options) {
// skip marked text nodes
if (node._skip) {
return removeText
}
var tokens = parseText(node.wholeText)
// 没有token就意味着没有插值,
// 没有插值那么内容不需要任何更改,也不会是响应式的数据
if (!tokens) {
return null
}
// mark adjacent text nodes as skipped,
// because we are using node.wholeText to compile
// all adjacent text nodes together. This fixes
// issues in IE where sometimes it splits up a single
// text node into multiple ones.
var next = node.nextSibling
while (next && next.nodeType === 3) {
next._skip = true
next = next.nextSibling
}
var frag = document.createDocumentFragment()
var el, token
for (var i = 0, l = tokens.length; i < l; i++) {
token = tokens[i]
// '{{a}} vue {{b}}'这样一段插值得到的token中
// token[1]就是' vue ',tag为false,
// 直接用' vue ' createTextNode即可
el = token.tag
? processTextToken(token, options)
: document.createTextNode(token.value)
frag.appendChild(el)
}
return makeTextNodeLinkFn(tokens, frag, options)
}
/**
* Process a single text token.
*
* @param {Object} token
* @param {Object} options
* @return {Node}
*/
function processTextToken (token, options) {
var el
if (token.oneTime) {
el = document.createTextNode(token.value)
} else {
if (token.html) {
// 这个comment元素形成一个锚点的作用,告诉vue哪个地方应该插入v-html生成的内容
el = document.createComment('v-html')
setTokenType('html')
} else {
// IE will clean up empty textNodes during
// frag.cloneNode(true), so we have to give it
// something here...
el = document.createTextNode(' ')
setTokenType('text')
}
}
function setTokenType (type) {
if (token.descriptor) return
// parseDirective其实是解析出filters,
// 比如 'msg | uppercase'
// 就会生成{expression:'msg',filters:[过滤器名称和参数]}
var parsed = parseDirective(token.value)
token.descriptor = {
name: type,
def: publicDirectives[type],
expression: parsed.expression,
filters: parsed.filters
}
}
return el
}对于文本节点,我们只需要处理他的wholeText里面出现插值的情况,所以需要parseText解析他的value,如果没有插值,那就原样保持不动。接着新建一个fragment,最后对生成的tokens进行处理,处理过程遇到tag为false的就说明不是插值是纯字符串,那就直接document.createTextNode(token.value)(这种情况不会生成指令描述符,使得产生指令描述符并生成指令的情况只有纯插值的情况)。遇到插值token则创建对应元素,并在token的descriptor属性存放对应的指令描述符。这个指令描述符相比之前的指令描述符简单了很多,那是因为textNode只会对应v-bind、v-text和v-html三种指令,他们基本只需要expression即可。最终处理token过程中生成的元素都会添加到fragment里。这个fragment在link阶段link完毕后会替换掉模板dom里的对应节点,完成界面更新。
link
compile结束后就到了link阶段。前文说了所有的link函数都是被linkAndCapture包裹着执行的。那就先看看linkAndCapture:
// link函数的执行过程会生成新的Directive实例,push到_directives数组中
// 而这些_directives并没有建立对应的watcher,watcher也没有收集依赖,
// 一切都还处于初始阶段,因此capture阶段需要找到这些新添加的directive,
// 依次执行_bind,在_bind里会进行watcher生成,执行指令的bind和update,完成响应式构建
function linkAndCapture (linker, vm) {
// 先记录下数组里原先有多少元素,他们都是已经执行过_bind的,我们只_bind新添加的directive
var originalDirCount = vm._directives.length
linker()
// slice出新添加的指令们
var dirs = vm._directives.slice(originalDirCount)
// 对指令进行优先级排序,使得后面指令的bind过程是按优先级从高到低进行的
dirs.sort(directiveComparator)
for (var i = 0, l = dirs.length; i < l; i++) {
dirs[i]._bind()
}
return dirs
}linkAndCapture的作用很清晰:排序然后遍历执行_bind()。注释很清楚了。我们直接看link阶段。我们之前说了几种complie方法,但是他们的link都很相近,基本就是使用指令描述对象创建指令就完毕了。为了缓解你的好奇心,我们还是举个例子:看看compileDirective生成的link长啥样:
// makeNodeLinkFn就是compileDirective最后执行并且return出去返回值的函数
// 它让link函数闭包住编译阶段生成好的指令描述对象(他们还不是Directive实例,虽然变量名叫做directives)
function makeNodeLinkFn (directives) {
return function nodeLinkFn (vm, el, host, scope, frag) {
// reverse apply because it's sorted low to high
var i = directives.length
while (i--) {
vm._bindDir(directives[i], el, host, scope, frag)
}
}
}
// 这就是vm._bindDir
Vue.prototype._bindDir = function (descriptor, node, host, scope, frag) {
this._directives.push(
new Directive(descriptor, this, node, host, scope, frag)
)
}我们可以看到,这么一段link函数是很灵活的,他的5个参数(vm, el, host, scope, frag) 对应着vm实例、dom分发的宿主环境(slot中的相关内容,大家先忽略)、v-for情况下的数组作用域scope、document fragment(包含el的那个fragment)。只要你传给我合适的参数,我就可以还给你一段响应式的dom。我们之前说的大数据量的v-for情况下,新dom(el)+ link+具体的数据(scope)实现就是基于此。
回到link函数本身,其功能就是将指令描述符new为Directive实例,存放至this._directives数组。而Directive构造函数就是把传入的参数、指令构造函数的属性赋值到this上而已,整个构造函数就是this.xxx = xxx的模式,所以我们就不说它了。
关键在于linkAndCapture函数中在指令生成、排序之后执行了指令的_bind函数。
Directive.prototype._bind = function () {
var name = this.name
var descriptor = this.descriptor
// remove attribute
if (
// 只要不是cloak指令那就从dom的attribute里移除
// 是cloak指令但是已经编译和link完成了的话,那也还是可以移除的
(name !== 'cloak' || this.vm._isCompiled) &&
this.el && this.el.removeAttribute
) {
var attr = descriptor.attr || ('v-' + name)
this.el.removeAttribute(attr)
}
// copy def properties
// 不采用原型链继承,而是直接extend定义对象到this上,来扩展Directive实例
var def = descriptor.def
if (typeof def === 'function') {
this.update = def
} else {
extend(this, def)
}
// setup directive params
// 获取指令的参数, 对于一些指令, 指令的元素上可能存在其他的attr来作为指令运行的参数
// 比如v-for指令,那么元素上的attr: track-by="..." 就是参数
// 比如组件指令,那么元素上可能写了transition-mode="out-in", 诸如此类
this._setupParams()
// initial bind
if (this.bind) {
this.bind()
}
this._bound = true
if (this.literal) {
this.update && this.update(descriptor.raw)
} else if (
// 下面这些判断是因为许多指令比如slot component之类的并不是响应式的,
// 他们只需要在bind里处理好dom的分发和编译/link即可然后他们的使命就结束了,生成watcher和收集依赖等步骤根本没有
// 所以根本不用执行下面的处理
(this.expression || this.modifiers) &&
(this.update || this.twoWay) &&
!this._checkStatement()
) {
// wrapped updater for context
var dir = this
if (this.update) {
// 处理一下原本的update函数,加入lock判断
this._update = function (val, oldVal) {
if (!dir._locked) {
dir.update(val, oldVal)
}
}
} else {
this._update = noop
}
// 绑定好 预处理 和 后处理 函数的this,因为他们即将作为属性放入一个参数对象当中,不绑定的话this会变
var preProcess = this._preProcess
? bind(this._preProcess, this)
: null
var postProcess = this._postProcess
? bind(this._postProcess, this)
: null
var watcher = this._watcher = new Watcher(
this.vm,
this.expression,
this._update, // callback
{
filters: this.filters,
twoWay: this.twoWay,//twoWay指令和deep指令请参见官网自定义指令章节
deep: this.deep, //twoWay指令和deep指令请参见官网自定义指令章节
preProcess: preProcess,
postProcess: postProcess,
scope: this._scope
}
)
// v-model with inital inline value need to sync back to
// model instead of update to DOM on init. They would
// set the afterBind hook to indicate that.
if (this.afterBind) {
this.afterBind()
} else if (this.update) {
this.update(watcher.value)
}
}
}这个函数其实也很简单,主要先执行指令的bind方法(注意和_bind区分)。每个指令的bind和update方法都不相同,他们都是定义在各个指令自己的定义对象(def)上的,在_bind代码的开头将他们拷贝到实例上:extend(this, def)。然后就是new了watcher,然后将watcher计算得到的value update到界面上(this.update(wtacher.value)),此处用到的update即刚刚说的指令构造对象上的update。
那我们先看看bind做了什么,每个指令的bind都是不一样的,大家可以随便找一个指令定义对象看看他的bind方法。如Vue官网所说:只调用一次,在指令第一次绑定到元素上时调用,bind方法大都很简单,例如v-on的bind阶段几乎什么都不做。我们此处随便举两个简单的例子吧:v-bind和v-text:
// v-bind指令的指令定义对象 [有删节]
export default {
...
bind () {
var attr = this.arg
var tag = this.el.tagName
// handle interpolation bindings
const descriptor = this.descriptor
const tokens = descriptor.interp
if (tokens) {
// handle interpolations with one-time tokens
if (descriptor.hasOneTime) {
// 对于单次插值的情况
// 在tokensToExp内部使用$eval将表达式'a '+val+' c'转换为'"a " + "text" + " c"',以此结果为新表达式
// $eval过程中未设置Dep.target,因而不会订阅任何依赖,
// 而后续Watcher.get在计算这个新的纯字符串表达式过程中虽然设置了target但必然不会触发任何getter,也不会订阅任何依赖
// 单次插值由此完成
this.expression = tokensToExp(tokens, this._scope || this.vm)
}
}
},
....
}
// v-text指令的执行定义对象
export default {
bind () {
this.attr = this.el.nodeType === 3
? 'data'
: 'textContent'
},
update (value) {
this.el[this.attr] = _toString(value)
}
}两个指令的bind函数都足够简单,v-text甚至只是根据当前是文本节点还是元素节点预先为update阶段设置好修改data还是textContent。
指令的bind阶段完成后_bind方法继续执行到创建Watcher。那我们又再去看看Watcher构造函数:
export default function Watcher (vm, expOrFn, cb, options) {
// mix in options
if (options) {
extend(this, options)
}
var isFn = typeof expOrFn === 'function'
this.vm = vm
vm._watchers.push(this)
this.expression = expOrFn
// 把回调放在this上, 在完成了一轮的数据变动之后,在批处理最后阶段执行cb, cb一般是dom操作
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
// lazy watcher主要应用在计算属性里,我在注释版源码里进行了解释,这里大家先跳过
this.dirty = this.lazy // for lazy watchers
// 用deps存储当前的依赖,而新一轮的依赖收集过程中收集到的依赖则会放到newDeps中
// 之所以要用一个新的数组存放新的依赖是因为当依赖变动之后,
// 比如由依赖a和b变成依赖a和c
// 那么需要把原先的依赖订阅清除掉,也就是从b的subs数组中移除当前watcher,因为我已经不想监听b的变动
// 所以我需要比对deps和newDeps,找出那些不再依赖的dep,然后dep.removeSub(当前watcher),这一步在afterGet中完成
this.deps = []
this.newDeps = []
// 这两个set是用来提升比对过程的效率,不用set的话,判断deps中的一个dep是否在newDeps中的复杂度是O(n)
// 改用set来判断的话,就是O(1)
this.depIds = new Set()
this.newDepIds = new Set()
this.prevError = null // for async error stacks
// parse expression for getter/setter
if (isFn) {
// 对于计算属性而言就会进入这里,我们先忽略
this.getter = expOrFn
this.setter = undefined
} else {
// 把expression解析为一个对象,对象的get/set属性存放了获取/设置的函数
// 比如hello解析的get函数为function(scope) {return scope.hello;}
var res = parseExpression(expOrFn, this.twoWay)
this.getter = res.get
// 比如scope.a = {b: {c: 0}} 而expression为a.b.c
// 执行res.set(scope, 123)能使scope.a变成{b: {c: 123}}
this.setter = res.set
}
// 执行get(),既拿到表达式的值,又完成第一轮的依赖收集,使得watcher订阅到相关的依赖
// 如果是lazy则不在此处计算初值
this.value = this.lazy
? undefined
: this.get()
// state for avoiding false triggers for deep and Array
// watchers during vm._digest()
this.queued = this.shallow = false
}
代码不难,首先我们又看到了熟悉的dep相关的属性,他们就是用来存放我们一开始在observe章节讲到的dep。在此处存放dep主要是依赖的属性值变动之后,我们需要清除原来的依赖,不再监听他的变化。
接下来代码对表达式执行parseExpression(expOrFn, this.twoWay),twoWay一般为false,我们先忽略他去看看parseExpression做了什么:
export function parseExpression (exp, needSet) {
exp = exp.trim()
// try cache
// 缓存机制
var hit = expressionCache.get(exp)
if (hit) {
if (needSet && !hit.set) {
hit.set = compileSetter(hit.exp)
}
return hit
}
var res = { exp: exp }
res.get = isSimplePath(exp) && exp.indexOf('[') < 0
// optimized super simple getter
? makeGetterFn('scope.' + exp)
// dynamic getter
// 如果不是简单Path, 也就是语句了,那么就要对这个字符串做一些额外的处理了,
// 主要是在变量前加上'scope.'
: compileGetter(exp)
if (needSet) {
res.set = compileSetter(exp)
}
expressionCache.put(exp, res)
return res
}
const pathTestRE = // pathTestRE太长了,其就是就是检测是否是a或者a['xxx']或者a.xx.xx.xx这种表达式
const literalValueRE = /^(?:true|false|null|undefined|Infinity|NaN)$/
function isSimplePath (exp) {
// 检查是否是 a['b'] 或者 a.b.c 这样的
// 或者是true false null 这种字面量
// 再或者就是Math.max这样,
// 对于a=true和a/=2和hello()这种就不是simple path
return pathTestRE.test(exp) &&
// don't treat literal values as paths
!literalValueRE.test(exp) &&
// Math constants e.g. Math.PI, Math.E etc.
exp.slice(0, 5) !== 'Math.'
}
function makeGetterFn (body) {
return new Function('scope', 'return ' + body + ';')
}先计算你传入的表达式的get函数,isSimplePath(exp)用于判断你传入的表达式是否是“简单表达式”(见代码注释),因为Vue支持你在v-on等指令里写v-on:click="a/=2" 等等这样的指令,也就是写一个statement,这样就明显不是"简单表达式"了。如果是简单表达式那很简单,直接makeGetterFn('scope.' + exp),比如v-bind:id="myId",就会得到function(scope){return scope.myId},这就是表达式的getter了。如果是非简单表达式比如a && b() || c() 那就会得到function(scope){return scope.a && scope.b() || scope.c()},相比上述结果就是在每个变量前增加了一个“scope.”,这个操作是用正则表达式提取变量部分加上“scope.”后完成的。后续的setter对应于twoWay指令中要将数据写回vm的情况,在此不表(此处分析path的过程就是@勾三股四大神那篇非常出名的博客里path解析状态机涉及的部分)。
现在我们明白vue是怎么把一个表达式字符串变成一个可以计算的函数了。回到之前的Watcher构造函数代码,这个get函数存放在了this.getter属性上,然后进行了this.get(),开始进行我们期待已久的依赖收集部分和表达式求值部分!
Watcher.prototype.beforeGet = function () {
Dep.target = this
}
Watcher.prototype.get = function () {
this.beforeGet()
// v-for情况下,this.scope有值,是对应的数组元素,其继承自this.vm
var scope = this.scope || this.vm
var value
try {
// 执行getter,这一步很精妙,表面上看是求出指令的初始值,
// 其实也完成了初始的依赖收集操作,即:让当前的Watcher订阅到对应的依赖(Dep)
// 比如a+b这样的expression实际是依赖两个a和b变量,this.getter的求值过程中
// 会依次触发a 和 b的getter,在observer/index.js:defineReactive函数中,我们定义好了他们的getter
// 他们的getter会将Dep.target也就是当前Watcher加入到自己的subs(订阅者数组)里
value = this.getter.call(scope, scope)
} catch (e) {
// 输出相关warn信息
}
// "touch" every property so they are all tracked as
// dependencies for deep watching
// deep指令的处理,类似于我在文章开头写的那个遍历所有属性的touch函数,大家请跳过此处
if (this.deep) {
traverse(value)
}
if (this.preProcess) {
value = this.preProcess(value)
}
if (this.filters) {
// 若有过滤器则对value执行过滤器,请跳过
value = scope._applyFilters(value, null, this.filters, false)
}
if (this.postProcess) {
value = this.postProcess(value)
}
this.afterGet()
return value
}
// 新一轮的依赖收集后,依赖被收集到this.newDepIds和this.newDeps里
// this.deps存储的上一轮的的依赖此时将会被遍历, 找出其中不再依赖的dep,将自己从dep的subs列表中清除
// 不再订阅那些不依赖的dep
Watcher.prototype.afterGet = function () {
Dep.target = null
var i = this.deps.length
while (i--) {
var dep = this.deps[i]
if (!this.newDepIds.has(dep.id)) {
dep.removeSub(this)
}
}
// 清除订阅完成,this.depIds和this.newDepIds交换后清空this.newDepIds
var tmp = this.depIds
this.depIds = this.newDepIds
this.newDepIds = tmp
this.newDepIds.clear()
// 同上,清空数组
tmp = this.deps
this.deps = this.newDeps
this.newDeps = tmp
this.newDeps.length = 0
}
这部分代码的原理,我在observe数据部分其实就已经完整的剧透了,watcher在计算getter之前先把自己公开放置到Dep.target上,然后执行getter,getter会依次触发各个响应式数据的getter,大家把这个watcher加入到自己的dep.subs数组中。完成依赖订阅,同时getter计算结束,也得到了表达式的值。
wait,watcher加入到dep.subs数组的过程中好像还有其他操作。我们回过头看看:响应式数据的getter被触发的函数里写了用dep.depend()来收集依赖:
Dep.prototype.depend = function () {
Dep.target.addDep(this)
}
// 实际执行的是watcher.addDep
Watcher.prototype.addDep = function (dep) {
var id = dep.id
// 如果newDepIds里已经有了这个Dep的id, 说明这一轮的依赖收集过程已经完成过这个依赖的处理了
// 比如a + b + a这样的表达式,第二个a在get时就没必要在收集一次了
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
// 如果连depIds里都没有,说明之前就没有收集过这个依赖,依赖的订阅者里面没有我这个Watcher,
// 所以加进去
// 一般发生在有新依赖时,第一次依赖收集时当然会总是进入这里
dep.addSub(this)
}
}
}依赖收集的过程中,首先是判断是否已经处理过这个依赖:newDepIds中是否有这个dep的id了。然后再在depIds里判断。如果连depIds里都没有,说明之前就没有收集过这个依赖,依赖的订阅者里面也没有我这个Watcher。那么赶紧订阅这个依赖dep.addSub(this)。这个过程保证了这一轮的依赖都会被newDepIds准确记录,并且如果有此前没有订阅过的依赖,那么我需要订阅他。
因为并不只是这样的初始状态会用watcher.get去计算表达式的值。每一次我这个watcher被notify有数据变动时,也会去get一次,订阅新的依赖,依赖也会被收集到this.newDepIds里,收集完成后,我需要对比哪些旧依赖没有在this.newDepIds里,这些不再需要订阅的依赖,我需要把我从它的subs数组中移除,避免他更新后错误的notify我。
watcher构造完毕,成功收集依赖,并计算得到表达式的值。回到指令的_bind函数,最后一步:this.update(watcher.value)。
这里执行的是指令构造对象的update方法。我们举个例子,看看v-bind函数的update[为便于理解,有改动]:
// bind指令的指令构造对象
export default {
...
update (value) {
var attr = this.arg
const el = this.el
const interp = this.descriptor.interp
if (this.modifiers.camel) {
// 将绑定的attribute名字转回驼峰命名,svg的属性绑定时可能会用到
attr = camelize(attr)
}
// 对于value|checked|selected等attribute,不仅仅要setAttribute把dom上的attribute值修改了
// 还要在el上修改el['value']/el['checked']等值为对应的值
if (
!interp &&
attrWithPropsRE.test(attr) && //attrWithPropsRE为/^(?:value|checked|selected|muted)$/
attr in el
) {
var attrValue = attr === 'value'
? value == null // IE9 will set input.value to "null" for null...
? ''
: value
: value
if (el[attr] !== attrValue) {
el[attr] = attrValue
}
}
// set model props
// vue支持设置checkbox/radio/option等的true-value,false-value,value等设置,
// 如<input type="radio" v-model="pick" v-bind:value="a">
// 如果bind的是此类属性,那么则把value放到元素的对应的指定属性上,供v-model提取
var modelProp = modelProps[attr]
if (!interp && modelProp) {
el[modelProp] = value
// update v-model if present
var model = el.__v_model
if (model) {
// 如果这个元素绑定了一个model,那么就提示model,这个input组件value有更新
model.listener()
}
}
// do not set value attribute for textarea
if (attr === 'value' && el.tagName === 'TEXTAREA') {
el.removeAttribute(attr)
return
}
// update attribute
// 如果是只接受true false 的"枚举型"的属性
if (enumeratedAttrRE.test(attr)) { // enumeratedAttrRE为/^(?:draggable|contenteditable|spellcheck)$/
el.setAttribute(attr, value ? 'true' : 'false')
} else if (value != null && value !== false) {
if (attr === 'class') {
// handle edge case #1960:
// class interpolation should not overwrite Vue transition class
if (el.__v_trans) {
value += ' ' + el.__v_trans.id + '-transition'
}
setClass(el, value)
} else if (xlinkRE.test(attr)) { // /^xlink:/
el.setAttributeNS(xlinkNS, attr, value === true ? '' : value)
} else {
//核心就是这里了
el.setAttribute(attr, value === true ? '' : value)
}
} else {
el.removeAttribute(attr)
}
}
}update中要处理的边界情况较多,但是核心还是比较简单的:el.setAttribute(attr, value === true ? '' : value),就是这么一句。
好了,现在整个link过程就完毕了,所有的指令都已建立了对应的watcher,而watcher也已订阅了数据变动。在_compile函数最后replace(original, el)后,就直接append到页面里了。将我们预定设计的内容呈现到dom里了。
那最后我们来讲一讲如果数据有更新的话,是如何更新到dom里的。虽然具体的dom操作是执行指令的update函数,刚刚的这个例子也已经举例介绍了v-bind指令的update过程。但是在update前,Vue引入了批处理机制,来提升dom操作性能。所以我们来看看数据变动,依赖触发notify之后发生的事情。
依赖变动后的dom更新
Dep.prototype.notify = function () {
// stablize the subscriber list first
var subs = toArray(this.subs)
for (var i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}数据变动时触发的notify遍历了所有的watcher,执行器update方法。(删节了shallow update的内容,想了解请看注释)
Watcher.prototype.update = function (shallow) {
if (this.lazy) {
// lazy模式下,标记下当前是脏的就可以了,这是计算属性相关的东西,大家先跳过
this.dirty = true
} else if (this.sync || !config.async) {
// 如果你关闭async模式,即关闭批处理机制,那么所有的数据变动会立即更新到dom上
this.run()
} else {
// 标记这个watcher已经加入批处理队列
this.queued = true
pushWatcher(this)
}
}我们先忽略lazy和同步模式,真正执行的就是将这个被notify的watcher加入到队列里:
export function pushWatcher (watcher) {
const id = watcher.id
// 如果已经有这个watcher了,就不用加入队列了,这样不管一个数据更新多少次,Vue都只更新一次dom
if (has[id] == null) {
// push watcher into appropriate queue
// 选择合适的队列,对于用户使用$watch方法或者watch选项观察数据的watcher,则要放到userQueue中
// 因为他们的回调在执行过程中可能又触发了其他watcher的更新,所以要分两个队列存放
const q = watcher.user
? userQueue
: queue
// has[id]记录这个watcher在队列中的下标
// 主要是判断是否出现了循环更新:你更新我后我更新你,没完没了了
has[id] = q.length
q.push(watcher)
// queue the flush
if (!waiting) {
//waiting这个flag用于标记是否已经把flushBatcherQueue加入到nextTick任务队列当中了
waiting = true
nextTick(flushBatcherQueue)
}
}
}pushWatcher把watcher放入队列里之后,又把负责清空队列的flushBatcherQueue放到本轮事件循环结束后执行,nextTick就是vm.$nextTick,利用了MutationObserver,注释里讲述了原理,这里跳过:
function flushBatcherQueue () {
runBatcherQueue(queue)
runBatcherQueue(userQueue)
// user watchers triggered more watchers,
// keep flushing until it depletes
// userQueue在执行时可能又会往指令queue里加入新任务(用户可能又更改了数据使得dom需要更新)
if (queue.length) {
return flushBatcherQueue()
}
// 重设batcher状态,手动重置has,队列等等
resetBatcherState()
}runBatcherQueue就是对传入的watcher队列进行遍历,对每个watcher执行其run方法。
Watcher.prototype.run = function () {
if (this.active) {
var value = this.get()
// 如果两次数据不相同,则不仅要执行上面的 求值、订阅依赖 ,还要执行下面的 指令update、更新dom
// 如果是相同的,那么则要考虑是否为Deep watchers and watchers on Object/Arrays
// 因为虽然对象引用相同,但是可能内层属性有变动,
// 但是又存在一种特殊情况,如果是对象引用相同,但为浅层更新(this.shallow为true),
// 则一定不可能是内层属性变动的这种情况(因为他们只是_digest引起的watcher"无辜"update),所以不用执行后续操作
if (
value !== this.value ||
// Deep watchers and watchers on Object/Arrays should fire even
// when the value is the same, because the value may
// have mutated; but only do so if this is a
// non-shallow update (caused by a vm digest).
((isObject(value) || this.deep) && !this.shallow)
) {
// set new value
var oldValue = this.value
this.value = value
} else {
// this.cb就是watcher构造过程中传入的那个参数,其基本就是指令的update方法
this.cb.call(this.vm, value, oldValue)
}
}
this.queued = this.shallow = false
}
}可以看到run其实就是先执行了一次this.get(),求出了表达式的最新值,并订阅了可能出现的新依赖,然后执行了this.cb。this.cb是watcher构造函数中传入的第三个形参。
我们回忆一下指令的_bind函数中在用watcher构造函数创造新的watcher的时候传入的参数:
//指令的_bind方法
// 处理一下原本的update函数,加入lock判断
this._update = function (val, oldVal) {
if (!dir._locked) {
dir.update(val, oldVal)
}
}
var watcher = this._watcher = new Watcher(
this.vm,
this.expression,
this._update, // callback
{
filters: this.filters,
twoWay: this.twoWay,
deep: this.deep,
preProcess: preProcess,
postProcess: postProcess,
scope: this._scope
}
)很简单了,其实就是加入了_locked判断后的指令的update方法(一般指令都是未锁住的)。而我们之前就已经举例讲述过指令的update方法。他完成的就是dom更新的具体操作。
好了,其实批处理就是个很好理解的东西,我把收到notify的watcher存放到一个数组里,在本轮事件循环结束后遍历数组,取出来一个个执行run方法,也即求出新值,订阅新依赖,然后执行对应指令的update的方法,将新值更新作用到dom里。
最后
我已经介绍完了Vue的大体流程,Vue为所有需要绑定到数据的指令都建立了一个watcher,watcher跟指令一一对应,watcher最终又精确的依赖到数据上,即使是数组内嵌对象这样的复杂情况。所以在小量数据更新时,可以做到极其精确、微量的dom更新。
但是这种方式也有其弊端,在大量数组渲染时,一方面需要遍历数据defineReactive,一方面需要将数组元素转为scope(一个既装载了数组元素的内容,又继承了其父级vm实例的对象),另一方面所有需要响应式订阅的dom也肯定是O(n)规模,因此必须要建立O(n)个watcher,执行每个watcher的依赖订阅和求值过程。
上述3个O(n)步骤决定了Vue在启动阶段的性能开销不小,同时,在大数据量的数组替换情况下,新数组的defineReactive,依赖的退订、重订过程,和watcher的对应dom更新也都是O(n)级别。虽然最重的肯定是dom更新部分,但其实前两者也依然会有一定的性能开销。而基于脏检查的Angular而言,其不会有那么多的watcher产生变动,也不会有上述前两个过程,因此会有一定的性能优势。
为了满足大量数组变动的性能需求,track-by的提出就显得很有必要,最大可能的重用原来的数据和依赖,只执行O(data change)级别的defineReactive、依赖的退订、重订、dom更新,所以合理优化和复用情况,Vue就具有了很高的性能。我们熟悉了源码之后可以从内部层面进行分析,而不是对于各个框架的性能了解停留在他们的宣传层面。
后续应该还有3篇左右的文章用来介绍网上资料较少的内容:
计算属性部分,即lazy watcher相关内容
Vue.set和delele中用到的vm._digest(), 即shallow update相关东西
v-for指令的实现,涉及diff算法
这篇文章非常长(比我本科的毕业论文都长?),非常感谢你能看完。Vue源码较长,因为作者提供的功能非常多,所以要处理的edge case就很多,而要想深入了解Vue,源码阅读是绕不开的一座大山。源码阅读过程中很多时候不是看不懂js,而是搞不懂作者这么写的目的,我自己模拟多种情况,调试、分析了很多次,消耗较多精力,希望能帮到同样在阅读源码的你。
原发于我的个人博客:Chuck Liu的个人博客






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。