
深度学习知识点总结
目录
[1] CNN 的原理和应用
[2] RNN LSTM, Seq2Seq, Attention 的原理和应用
CNN 的原理和算法实现
CNN 的全称是卷积神经网络,它的思路是模拟人识别物体时的顺序,先看一个图片大致的轮廓,知道了是个什么东西,然后再扣细节,比如一个人的照片,我们先意识到这是一个人,然后再看性别,肤色,眼睛鼻子嘴等等。
卷积
卷积的意思是把一个图片划分为一个个小格子,检查每个小格子里的物体

图中 convolution kernel 就是卷积核,卷积核会在原始图片上移动,每次移动算出一个点积(dot product),它的大小是 3 3,假设原始图像的大小是 N N,那么新的图像大小为 (N-2) * (N-2)
当然,新图像的大小可以根据是否 padding 和移动的步长来设定。注意新图像 -8 的位置,这个位置不在最左上角,说明算法是 padding 过的
通过卷积,我们找到很多的 Point of interest,每个 POI 都包含了一块数据的信息量,它代表了一个轮廓,通过很多 POI 的组合,配合他们之间的权值,我们就能找到描述
这个物体的 POI 组合。举一个汽车的例子,车子的轮子,玻璃,车架等等通过多次卷积都成了 POI,这些 POI 的组合就是车子本身。
以后机器看到类似的 POI 组合,就可以说,哦,这是一辆车

虽然大体的意思是这样,但是机器看到的东西和我们人看到的东西还是不一样,上图是机器进行卷积
以后看到的图像,卷积以后的图像,人都识别不了它是什么东西了。左上那张图其实看上去更像一个兔子,不知道兔子和一朵花在一起分类,分类器会不会误分类。
下面这张图是卷积的实现过程
最左边是三张图,分别是一张图的 RGB 描述,中间两列是卷积核,这里是两个卷积核。右边是卷积之后的图像,为了更快的展示整个过程,GIF 图没有使用 padding, 步长也设置的比较大。

下面是一个 CNN 的实现,使用 CNN 来分类 MINIST 数据集,理解思路以后,只需要再弄明白每个参数的意思就好了
'''
Trains a simple convnet on the MNIST dataset.
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
# 每次喂给模型 128 张图片
batch_size = 128
num_classes = 10
# 训练集迭代 128 次
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, shuffled and split between train and test_api sets
# 默认加载 minist 数据,数据保存在 ~/.keras/dataset 中
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_test.shape)
# (10000, 28, 28)
print(y_test.shape)
# (10000,)
print(y_test[0:10])
# [7 2 1 0 4 1 4 9 5 9]
# 根据不同 backend 的特性来重新组织图像
# reshape, shape 函数需要解释一下
# 对于维度 (10000, 28, 28) 的图像, shape[0] 返回 10000, shape[1], shape[2] 都返回 28
# reshape 是重新构造图像的维度,这里把 10000 * 28 * 28 -> 10000 * 1 * 28 * 28
# channel 是图层,灰度图片,图层是 1,RGB 的话,应该是 3,后面等于 Filters 的值,比如 32 或者 64
# channel 的个数只和 filter 的数目有关,不和上一层的数目有关,这是因为我们取的是所有图片的对应位置
# 如果能够看懂上面的 GIF 图就能理解了
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
# tensor flow 会使用这个模型
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# 简单的正则化,把 0 ~ 255 的灰度图变成 0.0 ~ 1.0 之间
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test_api samples')
# convert class vectors to binary class matrices
# y_train 变形 (3, 1, 2) -> [[0, 0, 1, 0 ...], [0, 1, ...], ..] 的矩阵形式
# 因为神经网络的输出本来就是一个数组,而不是一个值,对于 digit 就是返回一个数组
# 一般我们取最大的那个值作为返回值
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
# 接下来是比较难啃的骨头,Conv 的参数
# 第一个参数最复杂,它表示核函数的个数为 32,也就是上一层的所有图片,变成了 32 张图片
# kernel size 很好理解,就是上图中卷积核的 row * col
# 激活函数就用 relu, 类似的还有 sigmoid, tant 等等
# input_shape 就是一个图片 (1, row, col)
# 步长没有写,使用默认值,(1,1),在 tensorflow 中有四个参数,额外的两个参数分别是数据集
# 和 channel 的步长
# kernel 矩阵的内容我们没有定义,因为这是系统帮忙定义的
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
# 经过上面的运算,返回的图像是 26 * 26 * 32 * 10000, 乘以 32 倍, 28 -> 26
# 然后再来一次卷积,这样应该得到的大小是 24 * 24 * 64 * 10000
# channel 的意思就是,卷积的时候是很多图片在一起卷积,而不是一张,再回去看看 GIF 那张图
# 的意思就明白了
model.add(Conv2D(64, (3, 3), activation='relu'))
# 接下来是 pool, 返回的大小变成 12 * 12 * 64
# strides 没设置的话,就等于 pool_size, (2,2) 相当于图片长宽各少了一半, 这和 conv2d
# 是不一样的
model.add(MaxPooling2D(pool_size=(2, 2)))
# 解决 overfitting 问题,每次都有 25% 的权值不工作
model.add(Dropout(0.25))
# 接下来,就转变结构,开始 Dense 输出了
model.add(Flatten())
# Dense 是全连接层,就是一个最简单的 BP 神经网络,权值矩阵维度是 (12*12*64) * (128)
# 返回值是 128 维的,输入是 12 * 12 * 64,相当于减少了很多维信息
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
# 再来一把 Dense 层,返回维度就和 class 类型相同
# softmax 需要注意,它是把 float 变成 0 ~ 1 之间的期望值,且特点是越大的越大,越小的越小
# [0, 4, 10, 1] -> [0, 0.11, 0.88, 0.01] 然后我们选择第三类为期望的结果
model.add(Dense(num_classes, activation='softmax'))
# loss 定义预测值和期望之间差距的计算方式,就像 SVM 的 L1, L2 penalty
# optimizer 是更新权值的方式吧,这个不太确定
# 在 BP 神经网络中,loss 和 optimizer 好像是一个东西,就是最小二乘推导出来的递归下降
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# epochs 表示同一份训练数据训练的次数,研究表明,同一份数据训练多次也能提高准确率
# batch size 是一次推进去的数据量
# verbose 的意义位置
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])这就是一个完成的 CNN 识别手写数字的全部文档加注释
RNN 的原理
CNN 比较适合图片的分类任务,但是对于语言翻译,问答系统等场景不是很适用,假设有一个句子,最后一个单词为空,人是怎么填这个空的:
He is american, he speak _
这个空的值出现是基于前面出现过的 american 来填写的,即 american -> english。因此我们需要一个模型,不仅能挖掘语料之间的关系,还能挖掘语料之中的关系,这就是 RNN 的思路,因此这个模型要从把 american -> english 作为一个 feature 从一条语料中进行挖掘。
RNN 是循环神经网络,它的特点是拥有记忆能力,这个能力的实现也很简单,就是神经网络的输入不再是一整个大向量了,而是把这个大向量拆成小的向量,每个小向量喂给神经网络后返回的值 input1 和下一个小向量 input2 作为输入再喂给神经网络

上面就是 RNN 的工作模式,hidden 状态的值可以作为输入进入下一次迭代中。
RNN 的问题在于梯度爆炸和梯度消息,意义是这个模型对很长的句子学习效果不好,所以它又两个演化版本,LSTM (long short term memory) 和 GRU ()
其实,LSTM 的记忆能力也没有很高,好像也就 100 来个单词的样子。
下图是 LSTM 的模型图

LSTM 的结构和 RNN 相同,只是计算返回值的方式有所不同,在中间的框内, 有多种门,包括遗忘门,残差门(不计算,直接留到下一个 input)等等。背后的原理就是留出很多门,供数据流动,需要的数据从残差门通过,不需要的走到遗忘门,有组合关系的还可以从其他门走
此外,LSTM 需要一个 EOF 标志表示输入结束,它还可以有多个输出。
Seq2Seq 模型
LSTM 应用非常成功的领域是机器翻译,它的模型是两个 RNN, 一个叫做 encoder, 一个叫做 decoder, encoder 返回一个固定向量的编码,这个编码作为输入放到 encoder 中
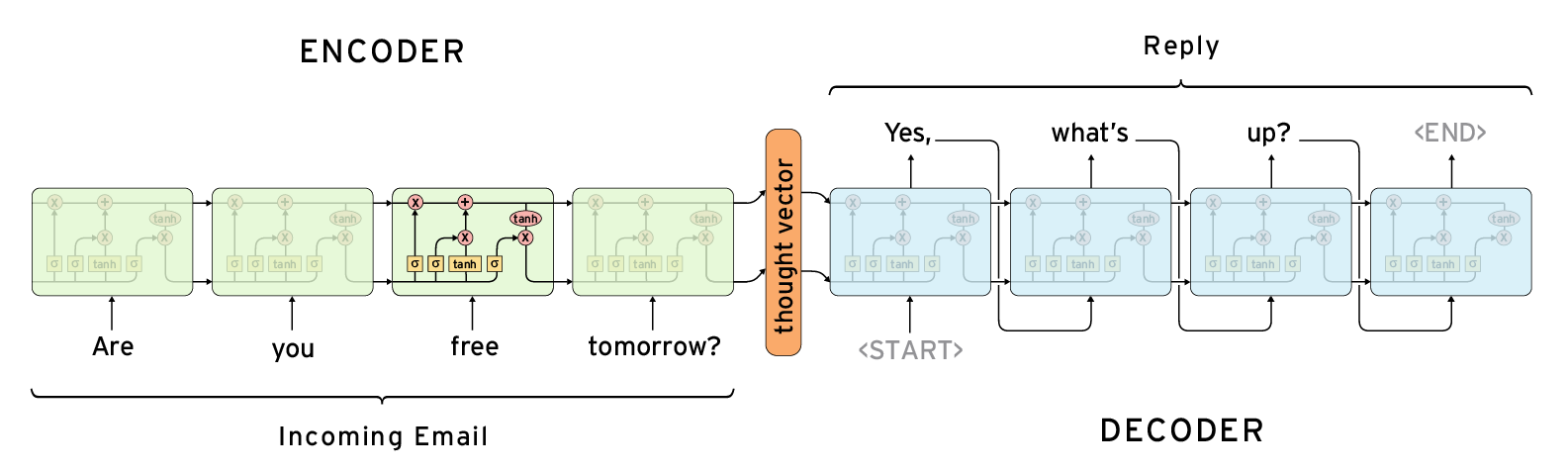
twitter bot 就用了这个模型来进行问答处理,
但是问答系统的问题在于经常两个回答没有任何关系,比如你问他来自哪里,和它讲什么语言,这两个问题他可能会给出不同的解法,因为他的语料库是一个很大且杂的系统,另外一个问题是两个机器人之间对话,会进去死循环
attention 机制
一个潜在的问题是,采用编码器-解码器结构的神经网络模型需要将输入序列中的必要信息表示为一个固定长度的向量,而当输入序列很长时则难以保留全部的必要信息(因为太多),尤其是当输入序列的长度比训练数据集中的更长时。
Attention机制的基本思想是,打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。
在文本翻译任务上,使用attention机制的模型每生成一个词时都会在输入序列中找出一个与之最相关的词集合。之后模型根据当前的上下文向量 (context vectors) 和所有之前生成出的词来预测下一个目标词。
它将输入序列转化为一堆向量的序列并自适应地从中选择一个子集来解码出目标翻译文本。这感觉上像是用于文本翻译的神经网络模型需要“压缩”输入文本中的所有信息为一个固定长度的向量,不论输入文本的长短。
虽然模型使用attention机制之后会增加计算量,但是性能水平能够得到提升。另外,使用attention机制便于理解在模型输出过程中输入序列中的信息是如何影响最后生成序列的。
这有助于我们更好地理解模型的内部运作机制以及对一些特定的输入-输出进行debug。
论文提出的方法能够直观地观察到生成序列中的每个词与输入序列中一些词的对齐关系,这可以通过对标注 (annotations) 权重参数可视化来实现…每个图中矩阵的每一行表示与标注相关联的权重。
由此我们可以看出在生成目标词时,源句子中的位置信息会被认为更重要。
attention 机制在图片上的应用
给定一张图片作为输入,输出对应的英文文本描述。Attention机制被用在输出输出序列的每个词时会专注考虑图片中不同的局部信息。

更多的 attention 应用可以参考这里
LSTM 的应用
'''
Trains an LSTM model on the IMDB sentiment classification task.
The dataset is actually too small for LSTM to be of any advantage
compared to simpler, much faster methods such as TF-IDF + LogReg.
Notes:
- RNNs are tricky. Choice of batch size is important,
choice of loss and optimizer is critical, etc.
Some configurations won't converge.
- LSTM loss decrease patterns during training can be quite different
from what you see with CNNs/MLPs/etc.
大概就是说这个东西需要仔细调参数
似乎可以无限拟合数据,结果能达到 90% +,不可思议
'''
from __future__ import print_function
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb
# 最多 2w 个单词
max_features = 20000
# cut texts after this number of words (among top max_features most common words)
maxlen = 80
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('y train example: ', y_train[0:10])
# y train example: [1 0 0 1 0 0 1 0 1 0]
print('Build model...')
model = Sequential()
# Embedding 层,只能作为神经网络的第一层,是把输入的单词变成向量 eg. [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
model.add(Embedding(max_features, 128))
# 第一个参数是 Unit, 需要等于上层的返回值么
# dropout Fraction of the units to drop for the linear transformation of the inputs
# recurrent_dropout: fraction of the units to drop for the linear transformation of the recurrent state
# 如果有多个输出该怎么办呢?
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
# dense 的个数一般和类别相同,这里 y_train 只有 0,1 就能简化成 1 个输出了
model.add(Dense(1, activation='sigmoid'))
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=2,
validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test,
batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。