
Softmax classifier
在线性分类和SVM中已经介绍过了线性分类和Multiclass SVM的基本概念,这篇文章主要讨论Softmax分类器。
Softmax分类器是除了SVM以外,另一种常见的线性分类器,它是Logistic回归推广到多类分类的形式。
既然Softmax分类器是一种线性分类器,那么我们同样可以从这两个方面来研究它:score function和loss function。
score function
$$f(x_i; W) = W x_i$$
可以看出,它的score function与Multiclass SVM是相同的,毕竟它们都属于“线性分类器”,计算score的公式必定是这种线性的公式。
注意,这个score function形式是将b合并进W后的形式,具体见上一篇文章。
Softmax对score的解释:转化为概率分布
虽然SVM和Softmax分类器的score function相同,但是两者看待score的方式是完全不同的:
- Multiclass SVM将score看作每类的“得分”,单单看得分的数值大小是没有意义的,得分只有在进行比较的时候才有意义。
- Softmax classifier将score向量看作是一种未归一化的对数概率分布(unnormalized log probabilities)。经过适当的转化以后可以得到各个类的概率。
将unnormalized log probabilities转化为normalized probabilities
这个回答对unnormalized log probabilities做出了解释:
log probabilities的意思就是概率的对数(注意这里的概率不一定是归一化以后的,也就是说所有概率加起来可以不等于一),比如已知3个类的概率(未归一化):$$[e^{-1}, e^{1}, e^{2}]$$,那么这3个概率对应的unnormalized log probabilities就是$$[-1, 1, 2]$$。
因此将unnormalized log probabilities转化回normalized probabilities的方式是:先将每个log probabilities以e为底数做幂运算,转化为普通概率,再把所有类的普通概率做归一化,让它们加起来等于1。比如,第j个类的normalized probability是:
$$p_j(z) = \frac{e^{z_j}}{\sum_k e^{z_k}}$$
其中$z$是各个类的unnormalized log probabilities组成的向量。$p_j(z)$就是第j个类的normalized probability。
函数$\sigma (\boldsymbol z)_j \equiv \frac{e^{\boldsymbol z_j}}{\sum_k e^{\boldsymbol z_k}}$又称为softmax function,它输入一组实数(也就是向量),然后输出其中一个实数的对应的概率(所有实数对应的概率加和为1)。
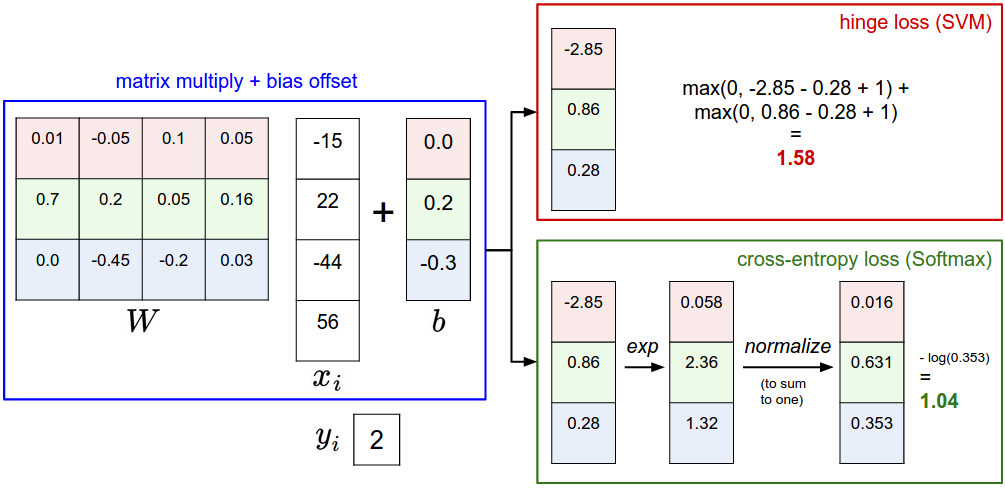
总结一下,Softmax分类器会对线性运算输出的score向量进行进一步转化:通过Softmax函数将【当前样本对于各个类的分数】转化为【当前样本属于各个类的概率分布】,后者才是模型的真正输出。这也是Softmax分类器名字的由来。
hypothesis 与 score function 的关系
由于线性运算的结果(score)往往不具备很好的可解释性,因此在输出之前“对score进行进一步转化”(比如将score转化为概率)是一种很常见的做法。
将输入映射为预测结果的函数,就是机器学习算法中的hypothesis(假设函数)。对于线性分类来说,假说函数包括了【通过线性运算计算score】+【将score转化为具有解释意义的预测结果】两个部分。
比如,softmax分类器的hypothesis是:
$$ \begin{align} h_\theta(x) = \begin{bmatrix} P(y = 1 | x; \theta) \\ P(y = 2 | x; \theta) \\ \vdots \\ P(y = K | x; \theta) \end{bmatrix} = \frac{1}{ \sum_{j=1}^{K}{\exp(\theta^{(j)\top} x) }} \begin{bmatrix} \exp(\theta^{(1)\top} x ) \\ \exp(\theta^{(2)\top} x ) \\ \vdots \\ \exp(\theta^{(K)\top} x ) \\ \end{bmatrix} \end{align} $$
参考资料:cs229-notes1, Softmax Regression
loss function
Softmax classifier通过以下公式来计算模型在样本$x_i$上的loss:
$$L_i = -\log\left(\frac{e^{f_{y_i}}}{ \sum_j e^{f_j} }\right) \hspace{0.5in} \text{or equivalently} \hspace{0.5in} L_i = -f_{y_i} + \log\sum_j e^{f_j}$$
这种计算loss的方式叫做交叉熵(cross-entropy loss),与Multiclass SVM的折叶损失(hinge loss)计算方式不一样,这是因为两者对score的解释不一样。前面已经说了Softmax分类器是如何将score向量转化为概率分布的,现在你应该可以理解,Softmax classifier loss实际是在希望正确类的概率$\frac{e^{f_{y_i}}}{ \sum_j e^{f_j} }$越大越好。
从信息论的角度来理解cross-entropy loss
除了从概率的角度来理解,还可以从信息论的角度来理解cross-entropy loss:Softmax函数与交叉熵。对交叉熵的解释。交叉熵解释2。对softmax的解释。softmax解释2。
简单来说,信息论中有这样一个公式$H(p,q) = H(p) + D_{KL}(p||q)$,其中:
- p是实际分布,q是近似分布。p分布在分类问题中已经给出,即实际分类的概率分布。比如[0,0,1,0]表示样本实际是第3类。真实分布仅仅在真实类上概率为1,其他概率为0。
- 第一项就是p和q两个概率分布的交叉熵。在信息论中完整的交叉熵公式是:$H(p,q) = - \sum_x p(x) \log q(x)$。可以看出cross-entropy loss其实就是将p和q分布带入这个公式得到的。
- 第二项是p概率分布的熵。由于p分布是已知的,因此p分布的熵$H(p)$是定值(计算一个分布的熵的公式:$H(X) = \sum_{i} P(x_i)\log_b \frac{1}{P(x_i)} = -\sum_{i} P(x_i)\log_b P(x_i)$)。
- 第三项是pq分布之间的KL散度。表示两个分布之间的“距离”。
由于$H(p)$是定值,因此最小化交叉熵实际上就是最小化pq分布之间的KL散度,也就是最小化预测分布与实际分布之间的“距离”。
模型在整个数据集上的loss
模型在整个数据集的loss的计算公式与Multiclass SVM相同:
$$L = \underbrace{ \frac{1}{N} \sum_i L_i } + \underbrace{ \lambda R(W) } = -\frac{1}{N} \sum_i \log\left(\frac{e^{f_{y_i}}}{ \sum_j e^{f_j} }\right) + \lambda R(W)$$
将上面的$L_i$公式带入这个公式即可。这个公式左边的部分是data loss,右边的部分是regularization loss(正则化惩罚):$R(W) = \sum_k\sum_l W_{k,l}^2$。
与 Logistic Regression 的关系
Sigmoid 和 Softmax 都用来对线性运算结果进行处理,将实数映射到(0, 1)区间,输出的数值具有更好的可解释性(可以看成概率)。
Sigmoid用于Logistic回归(二分类),它将单个实数映射到(0, 1)区间。这是Logistic回归的hypothesis:
$$\Pr(Y_i=0) = 1 - \Pr(Y_i=0) = \frac{e^{-\boldsymbol\beta \mathbf{X}_i}} {1 +e^{-\boldsymbol\beta \mathbf{X}_i}}$$
$$\Pr(Y_i=1) = S(\boldsymbol\beta \mathbf{X}_i) = \frac{1} {1 +e^{-\boldsymbol\beta \mathbf{X}_i}} $$
其中使用了Sigmoid函数:$$S(\boldsymbol x) \equiv \frac{e^\boldsymbol x}{e^\boldsymbol x + 1} \equiv \frac{1}{1 + e^{-x}}$$,$\boldsymbol\beta$是我们要训练的参数向量。
损失函数:
$$J(\theta) = - \sum_i \left(y^{(i)} \log( h_\theta(x^{(i)}) ) + (1 - y^{(i)}) \log( 1 - h_\theta(x^{(i)}) ) \right)$$
以下为Softmax分类的hypothesis:
$$\Pr(Y_i=j) = \frac{e^{\boldsymbol\beta_j \mathbf{X}_i}} {~\sum_k{e^{\boldsymbol\beta_k \cdot \mathbf{X}_i}}}$$
其中使用了Softmax函数:$$\sigma (\boldsymbol z)_j \equiv \frac{e^{\boldsymbol z_j}}{\sum_k e^{\boldsymbol z_k}}$$,$\boldsymbol\beta_k \cdot \mathbf{X}_i$就是第k个分类器的输出,$\boldsymbol\beta_k$是$W$的第$k$行,$W$是我们要训练的参数矩阵。
特别地,如果将Softmax分类用于二分类问题($k \in \lbrace 0, 1 \rbrace$):
$$\Pr(Y_i=0) = \frac{e^{\boldsymbol\beta_0 \cdot \mathbf{X}_i}} {~\sum_{0 \leq c \leq K}^{}{e^{\boldsymbol\beta_c \cdot \mathbf{X}_i}}} = \frac{e^{\boldsymbol\beta_0 \cdot \mathbf{X}_i}}{e^{\boldsymbol\beta_0 \cdot \mathbf{X}_i} + e^{\boldsymbol\beta_1 \cdot \mathbf{X}_i}} = \frac{e^{(\boldsymbol\beta_0 - \boldsymbol\beta_1) \cdot \mathbf{X}_i}}{e^{(\boldsymbol\beta_0 - \boldsymbol\beta_1) \cdot \mathbf{X}_i} + 1} = \frac{e^{-\boldsymbol\beta \cdot \mathbf{X}_i}} {1 +e^{-\boldsymbol\beta \cdot \mathbf{X}_i}}$$
$$\Pr(Y_i=1) = \frac{e^{\boldsymbol\beta_1 \cdot \mathbf{X}_i}} {~\sum_{0 \leq c \leq K}^{}{e^{\boldsymbol\beta_c \cdot \mathbf{X}_i}}} = \frac{e^{\boldsymbol\beta_1 \cdot \mathbf{X}_i}}{e^{\boldsymbol\beta_0 \cdot \mathbf{X}_i} + e^{\boldsymbol\beta_1 \cdot \mathbf{X}_i}} = \frac{1}{e^{(\boldsymbol\beta_0-\boldsymbol\beta_1) \cdot \mathbf{X}_i} + 1} = \frac{1} {1 +e^{-\boldsymbol\beta \cdot \mathbf{X}_i}}$$
因此,只要设$$\boldsymbol\beta = \boldsymbol\beta_1 - \boldsymbol\beta_0$$,就能把Softmax二分类写成Logistic回归。这就是为什么我们说Logistic回归是Softmax分类用于二分类问题的特例。
同理,Sigmoid函数只是Softmax函数的特例,你同样可以将两者写成相同的形式。
参考资料:Softmax vs Sigmoid
上面的式子还告诉我们,Softmax分类训练的参数是冗余的:Softmax二分类让我们训练出两个向量$\boldsymbol\beta_0$和$\boldsymbol\beta_1$,但是实际上只要$\boldsymbol\beta_0 - \boldsymbol\beta_0$相同,二分类的模型就是等价的。
Logistic回归就直截了当,不训练冗余的参数,直接训练$\boldsymbol\beta_0 - \boldsymbol\beta_0$向量。
损失函数的一致性:
无论是Softmax分类还是Logistic回归,损失函数是一致的。对单个样本$x_i$的loss的形式都是$$-\log(模型预测真实类概率)$$,都可以解释为期望“最大化正确类的概率”或者期望“最小化交叉熵”。
Multiclass SVM与Softmax的对比
loss function的差异
可以看出,两者的score function是相同的,通过score和ground truth label计算loss的方式是不同的。
Multiclass SVM只需要满足margin,Softmax永不满足
假设对某个样本输出的score为$$ [10, -2, 3]$$,真实类是第一个类,且$\Delta = 1$,那么SVM认为模型在这个样本上的loss为0,因为真实类的分数已经比其他所有类的分数都大1以上。也就是说,输出是$$[10, -2, 3]$$还是$$[1000, -2, 3]$$都无所谓,只要margin被满足,SVM loss都为0。在训练时遇到这种样本时不会去优化模型参数,因为loss已经为0。
但Softmax classifier的cross-entropy loss不同,真实类得到的分数相对其他类分数越高,cross-entropy loss越小,但是cross-entropy loss永远不可能为0。也就是说,Softmax永不满足,对于任何训练样本,它都会尝试去优化模型参数。
比如,一个车辆类型的SVM分类器,输入轿车图片和货车图片会产生相近的score(差值小于margin$\Delta = 1$),它就会学习轿车与货车之间的区别。如果输入一只青蛙的图片(青蛙的类别属于“其他”),“其他”类的分数已经比车辆类大1以上,那么模型不会学到什么新东西。也就是说,SVM只会从“有分类难度”(错误类的score接近正确类的score)的样本中学习。
但是如果是Softmax分类器,即使“其他”类的分数已经高于车辆类很多,Softmax分类器仍然会尝试增加这种差距。这种行为有时候是我们希望的,但有时候我们更希望分类器“专注于”学习轿车与货车之间的区别(有分类难度),对于杂七杂八的输入,只要保证分数之间的差距达到margin就行,不必为这种输入做优化。
欢迎提出建议或者指出错误!




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。