
在上一篇文章我们学习了包含全连接层的神经网络。这一篇文章我们将总结卷积神经网络(CNN)的知识。
这是一个交互式的在线DEMO,它是一个训练好的手写数字识别网络,很好地展示了这篇文章覆盖的重要知识点。(访问它可能需要科学上网)
全连接神经网络的局限性
全连接神经网络不太适合图像识别、语音识别这种任务,这种任务的特征是:输入大量数值,且需要识别的事物相对于输入数值来说,非常高层次和抽象。比如人脸(需要识别的事物)相对于像素灰度值(输入数值)来说,非常高层次和抽象;完整语句(需要识别的事物)相对于音调和音量(输入数值)来说,非常高层次和抽象。
全连接神经网络在这种任务中具有以下问题:
- 参数数量剧增。全连接层的每个神经元都与上一层的每个神经元建立连接,因此$总连接数=上一层神经元数 \times 全连接层神经元数$。随着输入数据量、每层神经元数量、网络层数的增加,总连接数剧增,因此参数数量也剧增(每个连接对应一个参数)。参数过多不仅会使网络难以训练,而且容易出现过拟合的问题。
- 没有利用输入的空间信息。对于图像识别、语音识别这种任务,每个输入值在输入整体中的位置是很重要的。比如对于图像识别任务来说,每个像素和其周围像素的联系是比较紧密的(它们可能共同构成一个局部特征,比如眼睛)。而对于距离很远的像素,则关系薄弱很多(在像素这种低层次,眼睛的像素和嘴巴的像素没有什么联系)。然而全连接层认为“每个输入值都是平等的”,它将输入视为一维向量,它并不关心这个像素是第几行、第几列的。
卷积神经网络
卷积神经网络与全连接神经网络非常相似。它们都由若干层构成,每一层包含很多神经元,每个神经元都是做$a=f(wx+b)$的运算,其中w和b是可以学习的参数。用在分类问题时,整个网络将输入数据映射为各个类的评分。
不同的地方在于:卷积神经网络不仅包含全连接层,它还具有其他的一些特殊结构,这些特有属性使得前向传播函数实现起来更高效,并且解决了全连接神经网络的上述问题。
层的结构:三维长方体
卷积神经网络的各层神经元排列为三维长方体,具有宽度、高度、深度。由于神经元是三维排列的,因此它们的输出也是三维排列的(每个神经元有1个输出),称为数据体(volume)。
这种排列方式能够保留输入像素的位置关系,从而在后面可以通过局部连接来利用这种位置关系。举个例子,CIFAR-10中的图像作为卷积神经网络的输入时,输入层数据体大小是32x32x3(32x32像素,每个像素有RGB三个通道),像素的位置信息被保留了下来。

如上图,如果红色长方体是接受CIFAR-10图片的输入层,那么它的三维排列与原始图片相同:32x32x3。
对比全连接层
全连接层的神经元是一维排列的,它的输入、输出是一维向量,全连接层通过$a=f(Wx)$函数将输入向量映射为输出向量,详见二层全连接神经网络示例。
而卷积神经网络的各层神经元是按照三维排列的,它的输入、输出是三维向量。CNN的每一层神经元将三维数据体(输入)映射为三维数据体(输出)。这个映射关系可能包含参数,可能不需要参数(见下文)。
层的种类:卷积层,全连接层,RELU层,汇聚层
目前在CNN中,最流行的层有卷积层(Convolutional Layer),全连接层,RELU层,汇聚层(Pooling Layer)。
其中,卷积层和全连接层包含可以训练的参数,而RELU层和汇聚层则不包含参数,也就是说它们在训练和使用的过程中固定不变。

如上图,一个简单的CNN由多个层构成,整个网络将原始图像像素映射为各个分类的评分。箭头指向的列是这一层的输出数据体。为了在图片中展示三维数据体,将每个数据体沿着深度的方向进行切片,然后铺成一列。
卷积层
输入和输出
和CNN中的其他层一样,卷积层接收上一层输出的三维数据体。
每个卷积层包含若干个filter(或kernel),每个filter的输入都是上一层的输出数据体,每个filter产生一个二维输出(width x height),因此包含n个filter的卷积层产生(width x height x n)的三维数据体。
卷积层输出的数据体的深度等于filter的数量。
filter和卷积操作
每个filter是三维的,它的宽度和高度都比较小,深度总是与输入数据体的深度相同。比如,第一个卷积层的其中一个filter可能为5x5x3,深度为3是因为输入的图片包含3个通道。
"Every filter is small spatially (along width and height), but extends through the full depth of the input volume."
filter的深度总是等于输入数据体的深度。
在前向传播的时候,让每个滤波器都在输入数据体的宽度和高度上滑动(更精确地说是卷积),每次滑动到一个新的位置,就计算【filter的权重】与【输入数据体与filter重叠的部分】的内积,输出一个实数。filter的深度总是和输入数据体的深度一致,因此filter只会沿着宽度或高度滑动,因此filter的输出也是按照二维来排列的。输入数据体被一个filter卷积以后,产生的二维图像称为特征图(feature map)。卷积层有n个filter,就会产生n个特征图,也就是说输出数据体的深度为n。
滑动的过程需要两个超参数来决定:
- 步长(stride)。当步长为n,滤波器每次移动时,就沿着宽度或高度移动n个像素。
- 零填充(zero-padding)。在输入数据体的边缘用0填充,增加宽度和高度。通过适当的零填充,可以使得输入和输出的宽高都相等。
filter执行的运算是$a = W \cdot X + b$(点积以后加偏置),其中W和b都是需要学习参数。

在上图中,步长为1,不使用0填充。
注意,为了展示方便,输入深度是1(因此filter深度是1),并且只使用1个filter(因此输出深度是1),但是现实中这些深度可以不为1:

在上图中,步长为2,零填充为1(边缘增加一层0)。
输入深度是3(因此每个filter深度是3),并且使用2个filter(因此输出深度是2)。
输出尺寸(filter滑动多少次)计算公式:
$$width = (width_{in} - F + 2P)/S + 1$$
$$height = (height_{in} - F + 2P)/S + 1$$
其中,F是filter的边长,P是零填充的层数,S是步长。$width_{in}$和$hieght_{in}$一般是相同的。
你可以通过上面两幅图来验证这个公式。作为额外的例子,如果输入是7x7,滤波器是3x3,步长为1,填充为0,那么就能得到一个5x5的输出。如果步长为2,输出就是3x3。

上图是一个卷积层的一维视角。左边的$width_{in}$=5, F=3, P = 1, S = 1;中间$width_{in}$=5, F=3, P = 1, S = 2。右上角的三个数是filter的权重(权重是共享的,后文会讨论)。
卷积层的神经元实现
通过上面对卷积操作的解释,我们已经初步了解了卷积层是在做什么事情,以及它的输入输出是怎样的。那么如何用神经网络来实现卷积层呢?
filter每次滑动到的区域,都对应1个神经元,这个神经元的权重就是filter的权重,接受输入数据体的一个局部区域(也就是说与上一层的部分神经元进行连接),输出内积的结果。因此,每个filter对应二维排列的神经元(width x height),n个filter就对应三维排列的神经元(width x height x n)。每个filter产生一个输出实数,因此卷积层的输出数据体也是width x height x n。
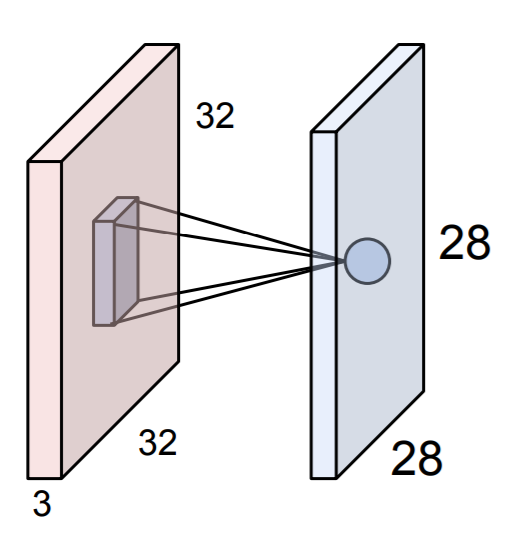
如上图,红色是输入层,蓝色是卷积层。这张图展示了只有一个filter的卷积层。每个神经元与输入层的一个局部区域进行连接。这里的“局部区域”指的是filter在输入数据体上滑动的过程中,两者重叠的部分。再次强调:filter的深度总是和输入数据体的深度一致,因此filter只会沿着宽度或高度滑动。
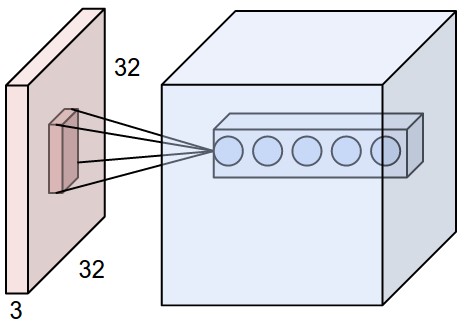
上图中没有画出卷积层的所有神经元,只画出了其中一个深度列,为每个filter画了一个代表性的神经元。
我们将卷积层中沿着深度方向排列、感受野相同的神经元集合称为深度列(depth column),也有人使用纤维(fibre)来称呼它们。
在上图中,因为有3个filter,所以每个“合法感知野”都有3个神经元同时在感知。这3个神经元是一个深度列。这里的“合法感知野”表示:根据超参数(filter尺寸、步长、零填充),filter在滑动的过程中,会经过并停下的地方。
从上面的说明中,我们能够总结出卷积层神经元的特点:
-
局部连接
我们让每个神经元只与输入数据的一个局部区域连接。该连接的空间大小叫做神经元的感受野(receptive field),它的尺寸就是filter的尺寸,是一个超参数。局部连接基于这样一种假设,每个输入只与它的“相邻”输入有较紧密的联系,与距离较远的输入关联不大。 -
参数共享
在滑动的过程中,filter的权值不变。也就是说,在卷积层中,处于同一个深度切片的神经元共享同一组参数。参数共享基于这样一种假设,如果一个filter能够提取出(x1, y1)附近的某种特征(比如说横向边缘),那么这个filter也能够提取出(x2, y2)附近的相同特征,也就是说特征具有平移不变性。
深度切片就是对数据体沿着深度坐标轴的切片。比如一个 width x height x depth 的数据体能够切出depth个width x height的切片。
如果我们希望训练出的filter,在任何位置都“期望”相同特征,这时才应该使用参数共享机制。如果我们希望训练出的filter,在不同的位置“期望”不同的特征,这时应该放弃参数共享机制,这种只使用局部连接而不使用参数共享的层叫做局部连接层(Locally-Connected Layer)。
卷积层总结
- 输入数据体的尺寸为$W_1 \times H_1 \times D_1$
-
需要4个超参数:
- filter(kernel)的数量$K$
- filter的空间尺寸$F \times F$(一般宽度和高度相等)
- 步长$S$
- 零填充数量$P$
-
输出数据体的尺寸$W_2 \times H_2 \times D_2$,其中
- $W_2 = (W_1 - F + 2P)/S + 1$
- $H_2 = (H_1 - F + 2P)/S + 1$
- $D_2 = K$
- 由于参数共享,每个filter包含$F \cdot F \cdot D_1$个权重,$K$个filter就有$(F \cdot F \cdot D_1) \cdot K$个权重和$K$个bias。这些都是需要训练的参数。
- 在输出数据体中,第$d$个深度切片($W_2 \times H_2$),通过第$d$个filter与输入数据体进行卷积得到(步长为$S$)。
用矩阵乘法实现卷积层计算
详见cs231n notes的"Implementation as Matrix Multiplication"小结。
大致的思路是,将每个合法的感知野变为一个列向量,得到一个b x c矩阵X_col,其中b是每个感知野的输入数据量,c是合法感知野的数量。
然后,将卷积层的filter权重实现为一个a x b矩阵W_row,其中a是filter的数量,b是每个filter的权重数量。
然后,使用矩阵乘法np.dot(W_row, X_col)就能同时完成所有神经元的点积运算,结果是一个a x c矩阵。其中的第i行第j列表示第i个filter在第j个合法感知野的输出。
最后还要记得加上bias,并转化为三维的输出数据体。
RELU层(RELU Layer)
RELU层会对输入数据体中的每个值依次使用激活函数进行映射,比如$max(0, x)$。RELU层不改变数据体的尺寸。
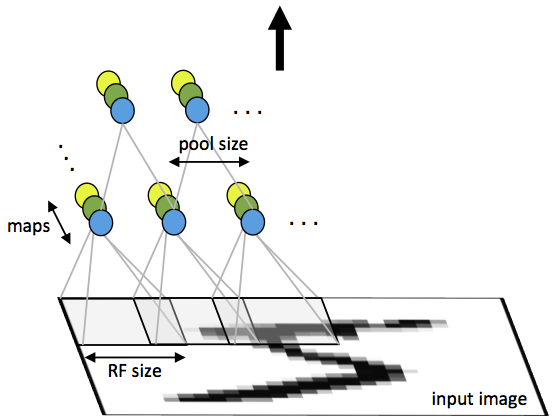
汇聚层(Pooling Layer)
汇聚层的作用是逐渐降低数据体的空间尺寸(深度不变),减少网络中参数的数量,并且减少过拟合。
Pooling分别应用于每个深度切片,输出尺寸更小的深度切片。因此Pooling不改变数据体的深度,只会减小宽度和高度。
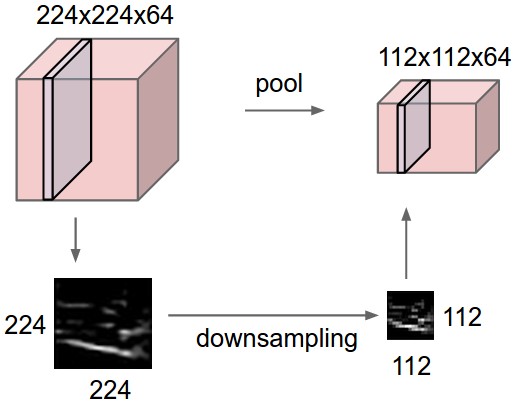
上图表示汇聚层对输入数据体的每个深度切片分别进行降采样(downsample)。
Pooling的方法很多,最常见的汇聚层是使用2 x 2的filter,以2为步长,对输入数据体的每个深度切片进行降采样。filter每次输入2 x 2个值,输出其中的最大值(称为max pooling)。因此每个深度切片的宽度和高度都减半,75%的激活信息(输入)被丢弃。

上图是max pooling对其中一个深度切片应用的效果。
汇聚层小结
- 输入数据体的尺寸$W_1 \times H_1 \times D_1$
-
需要2个超参数:
- Pooling filter的尺寸:$F \times F$
- 步长$S$
-
输出数据体的尺寸$W_2 \times H_2 \times D_2$,其中
- $W_2 = (W_1 - F)/S + 1$
- $H_2 = (H_1 - F)/S + 1$
- $D_2 = D_1$
- 不引入参数
- 很少使用零填充
全连接层(Fully-connected layer)
全连接层已经在【机器学习】3. 神经网络基础讨论过。全连接层的处理可以用公式$a = f(Wx)$来表示。
注意,这里的$Wx$是将bias合并进W后的形式,将b当做了一个常数1的权重,具体见【机器学习】1. 线性分类和SVM。
在CNN中,全连接层将输入数据看作是$1 \times 1 \times D_1$的数据体(丢弃输入的三维结构,将输入视为一维向量),输出的是$1 \times 1 \times D_2$的数据体(输出一维向量)。
全连接层与卷积层之间转化
详见cs231n notes的"Converting FC layers to CONV layers"小结。
层的排列
CNN的层常常具有如下排列规律:INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
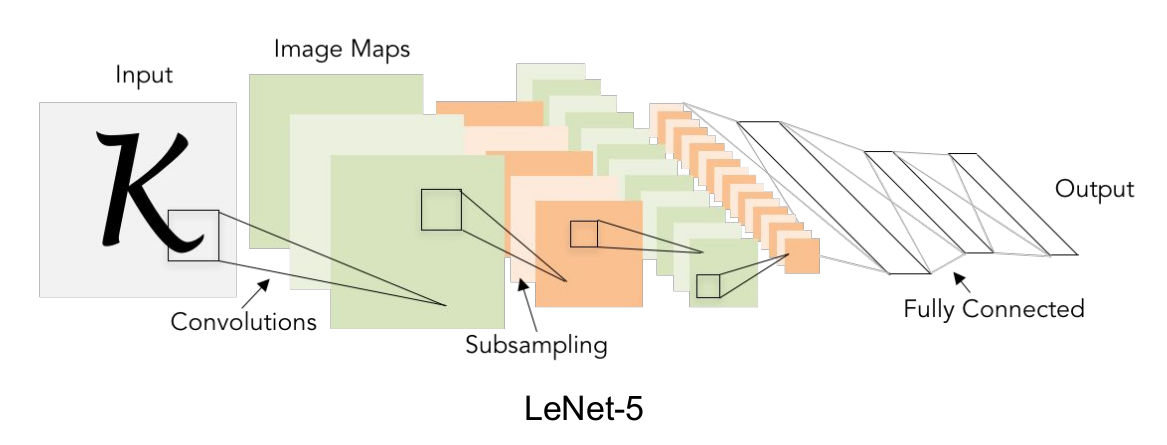
上图展示了一个非常基本的卷积神经网络LeNet-5。文章开头提供的在线DEMO实现的就是这个网络。
更详细的关于层次组织的讨论请看cs231n notes。
参考资料
cs231n notes
CS231n课程笔记翻译:卷积神经网络笔记
ufldl tutorial
零基础入门深度学习(4) - 卷积神经网络






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。