
基于Heapster的HPA
概述
Horizontal Pod Autoscaling,简称HPA,是Kubernetes中实现POD水平自动伸缩的功能。自动扩展主要分为两种:
- 水平扩展(scale out),针对于实例数目的增减
- 垂直扩展(scal up),即单个实例可以使用的资源的增减, 比如增加cpu和增大内存
HPA属于前者。它可以根据CPU使用率或应用自定义metrics自动扩展Pod数量(支持 replication controller、deployment 和 replica set)
节点扩缩容层面,k8s集群的Cluster Autoscaler持续监控Pods,一旦发现Pods无法被schedule,则基于PodConditoin进行扩展,即node节点的自动扩缩容,具体内容在后续文章中介绍。
监控数据获取
- Heapster: heapster收集Node节点上的cAdvisor数据,并按照kubernetes的资源类型来集合资源。但是在v1.11中已经被废弃(heapster监控数据可用,但HPA不再从heapster拿数据)
- metric-server: 在v1.8版本中引入,官方将其作为heapster的替代者。metric-server依赖于kube-aggregator,因此需要在apiserver中开启相关参数。v1.11中HPA从metric-server获取监控数据
工作流程
- 1.创建HPA资源,设定目标CPU使用率限额,以及最大、最小实例数, 一定要设置Pod的资源限制参数: request, 否则HPA不会工作。
- 2.控制管理器每隔30s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况
- 3.然后与创建时设定的值和指标做对比(平均值之和/限额),求出目标调整的实例个数
- 4.目标调整的实例数不能超过1中设定的最大、最小实例数,如果没有超过,则扩容;超过,则扩容至最大的实例个数
如何部署:
- 1.6-1.8版本默认使用heapster
- 1.11版本及以上默认使用metric-server(需单独安装,并开启参数)
1.部署和运行php-apache并将其暴露成为服务

2.创建HPA
如果为1.8及以下的k8s集群,指标正常,如果为1.11集群,需要执行如下操作。
4.向php-apache服务增加负载,验证自动扩缩容
启动一个容器,并通过一个循环向php-apache服务器发送无限的查询请求(请在另一个终端中运行以下命令)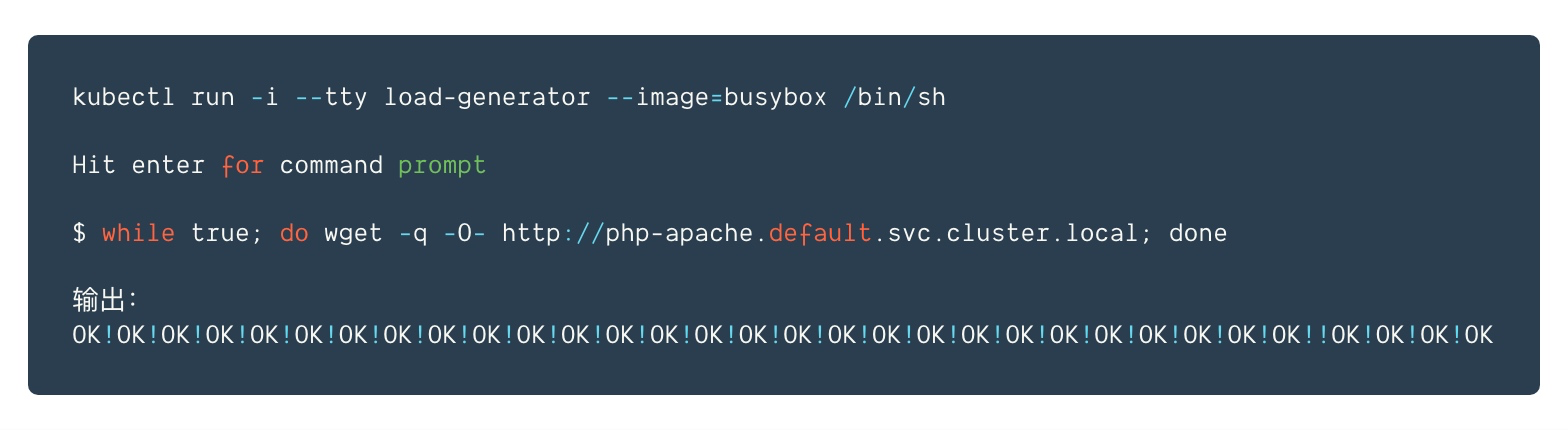
5.观察HPA是否生效
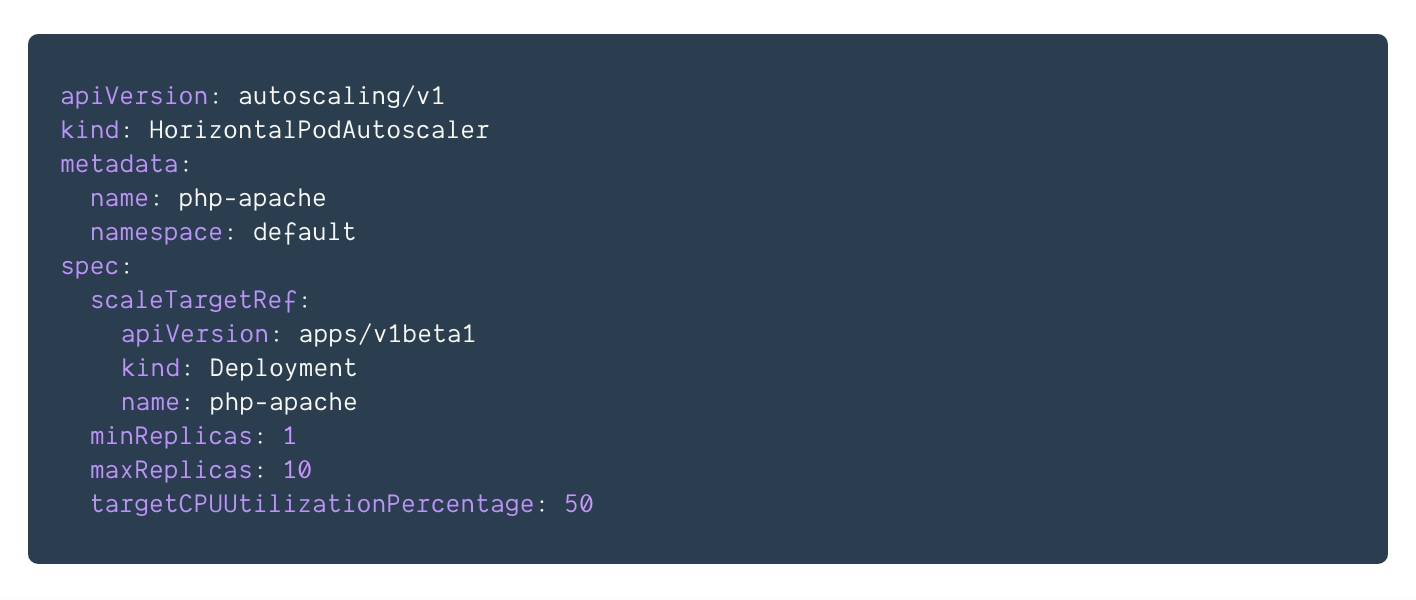
用yaml创建HPA的方式为:
实现细节
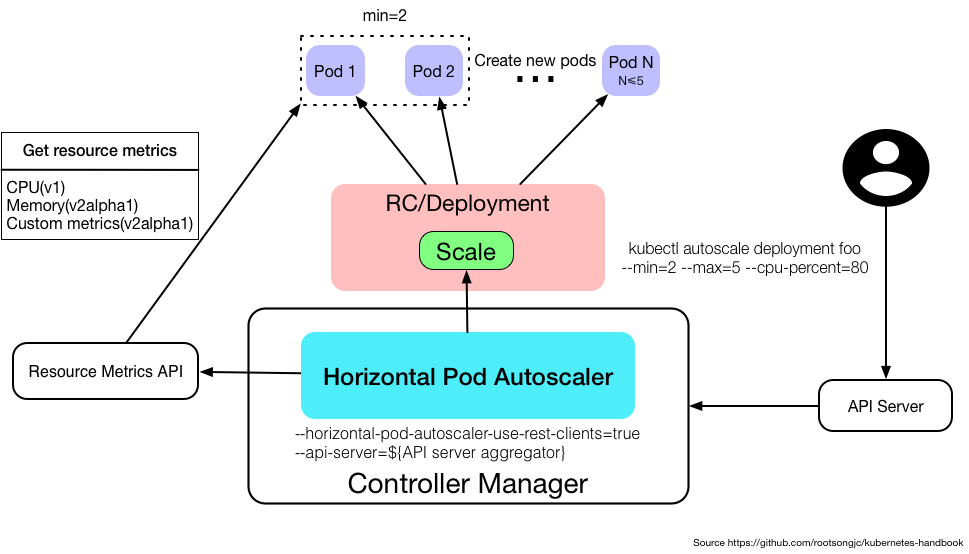
HPA由一个控制循环实现,循环周期由--horizontal-pod-autoscaler-sync-period 标志指定,默认是30秒,每个周期内,controller-manager会查询HPA中定义的metric的资源利用率。
如上例子,pod的request定义为200M,而HPA定义的target为50%,即HPA将通过增加或者减少Pod副本的数量(通过Deployment)以保持所有Pod的平均CPU利用率在50%以内(即200*0.5=100M以内),循环周期到达时,获取pod的1分钟内的平均cpu利用率(从heaspter),发现超过了100M,为332M,于是通过下面的公式,决定最终的pod数量
TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)即 332/50 =6.xxx ceil为向上取整,得到7。如果得到的结果大于10,则为10
因为每次HPA生效都会创建或者删除pod,而这些操作其实会影响到metric监控值,如创建pod会暂时性的升高cpu,因此每次扩容都要间隔3分钟,缩容需要间隔5分钟。且需要满足:avg(CurrentPodsConsumption)/ Target下降9%,进行缩容,增加至10%才进行扩容
这样做好处是:
1、判断的精度高,不会频繁的扩缩pod,造成集群压力大。
2、避免频繁的扩缩pod,防止应用访问不稳定
实现hpa的条件:
1、hpa不能autoscale daemonset类型control
2、要实现autoscale,pod必须设置request
参考:https://github.com/kubernetes...
本文为容器监控实践系列文章,完整内容见:container-monitor-book







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。