
博文:https://chanjarster.github.io...
原文:What every programmer should know about memory, Part 1, RAM
1 Introduction
如今的计算机架构中CPU和main memory的访问速度的差异是很大的,解决这一瓶颈有这么几种形式:
- RAM硬件设计的改善(速度和并行)
- Memory controller设计
- CPU caches
- 给设备用的Direct memory access(DMA)
2 Commodity Hardware Today
大众架构
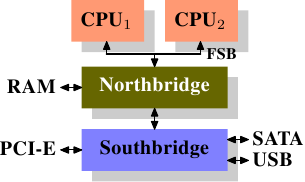
Figure 2.1: Structure with Northbridge and Southbridge
- 所有CPU通过FSB连接到北桥,北桥包含内存控制器(memory controller),连接到RAM。不同的内存类型如SRAM、DRAM有不同的内存控制器。
- 南桥又称I/O桥,如果要访问其他系统设备,北桥必须和南桥通信。南桥连接着各种不同的bus
这个架构要注意:
- CPU之间的所有数据通信必须经过FSB,而这个FSB也是CPU和北桥通信的bus。
- 所有和RAM的通信都必须经过北桥
- RAM只有一个端口(port)
- CPU和挂接到南桥设备的通信则有北桥路由
可以发现瓶颈:
- 为设备去访问RAM的瓶颈。解决办法是DMA,让设备直接通过北桥访问RAM,而不需要CPU的介入。如今挂到任一bus的所有高性能设备都能利用DMA。虽然DMA减少了CPU的工作量,但是争用了北桥的带宽
- 北桥到RAM的瓶颈。老的系统里只有一条通往所有RAM芯片的bus。现在的RAM类型要求有两条独立的bus,所以倍增了带宽(DDR2里称为channel)。北桥通过多个channel交替访问内存。
多内存控制器
比较贵的系统北桥自己不包含内存控制器,而是外接内存控制器:
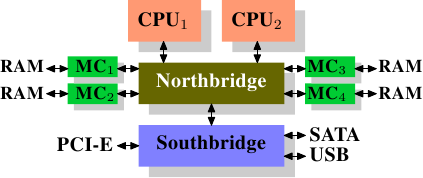
Figure 2.2: Northbridge with External Controllers
在这种架构里有多个内存bus,大大增加了带宽。在并发内存访问的时候,可以同时访问不同的memory bank(我理解为就是内存条)。而这个架构的瓶颈则是北桥内部的带宽。
NUMA
除了使用多个内存控制器,还可以采用下面的架构增加内存带宽。做法就是把内存控制器内置在CPU里。每个CPU访问自己的本地RAM。
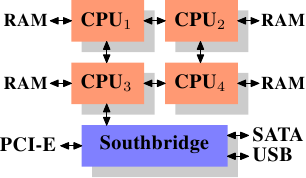
Figure 2.3: Integrated Memory Controller
这个架构同样也有缺点:因为这种系统里的所有CPU还是要能够访问所有的RAM,所以the memory is not uniform anymore (hence the name NUMA - Non-Uniform Memory Architecture - for such an architecture)。访问本地内存速度是正常的,访问别的CPU的内存就不一样了,CPU之间必须interconnect才行。在上图中CPU1访问CPU4的时候就要用到两条interconnect。
2.1 RAM Types
2.1.1 Static RAM
- 访问SRAM没有延迟,但SRAM贵,容量小。
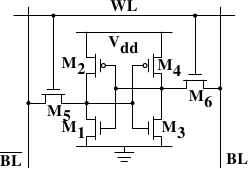
Figure 2.4: 6-T Static RAM
电路图就不解释了。
2.2.1 Dynamic RAM
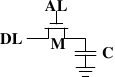
Figure 2.5: 1-T Dynamic RAM
电路图就不解释了。
- DRAM物理结构:若干RAM chip,RAM chip下有若干RAM cell,每个RAM cell的状态代表1 bit。
- 访问DRAM有延迟(等待电容充放电),但DRAM便宜,容量大。商业机器普遍使用DRAM,DDR之类的就是DRAM。
2.1.3 DRAM Access
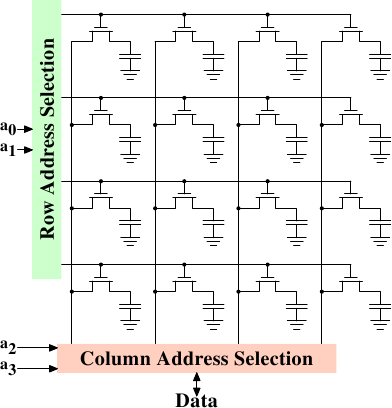
Figure 2.7: Dynamic RAM Schematic
访问DRAM的步骤:
- RAS(Row address selection)
- CAS(Column address selection)
- 传输数据
RAS和CAS都需要消耗时钟频率,如果每次都需要重新RAS-CAS则性能会低。如果一次性把一行的数据都传输,则速度很快。
2.1.4 Conclusions
- 不是所有内存都是SRAM是有原因的(成本原因)
- memory cell必须被单独选择才能够使用
- address line的数目直接影响到内存控制器、主板、DRAM module、DRAM chip的成本
- 需要等待一段时间才能得到读、写操作的结果
2.2 DRAM Access Technical Details
略。
2.2.4 Memory Types
- 现代DRAM内置I/O buffer增加每次传输的数据量。
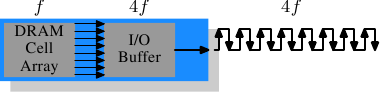
Figure 2.14: DDR3 SDRAM Operation
2.2.5 Conclusions
- 假如DRAM的时钟频率为200MHz,I/O buffer每次传送4份数据(商业宣传其FSB为800MHz),你的CPU是2GHz,那么两者时钟频率则是1:10,意味着内存延迟1个时钟频率,那么CPU就要等待10个时钟频率。
2.3 Other Main Memory Users
- 网络控制器、大存储控制器,使用DMA访问内存。
- PCI-E卡也能通过南桥-北桥访问内存。
- USB也用到FSB。
- 高DMA流量会占用FSB,导致CPU访问内存的时候等待时间变长。
- 在NUMA架构中,可以CPU使用的内存不被DMA影响。在Section 6会详细讨论。
- 没有独立显存的系统(会使用内存作为显寸),这种系统对于RAM的访问会很频繁,造成占用FSB带宽,影响系统性能。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。