
背景
随着前端技术日新月异地快速发展,web应用功能和体验也逐渐发展到可以和原生应用媲美的程度,前端缓存技术的应用对这起到了不可磨灭的贡献,因此想一探前端的缓存技术,这篇文章主要会介绍在日常开发中比较少接触的IndexedDB
IndexedDB
什么是IndexedDB
IndexedDB简单理解就是前端数据库,提供了一种在用户浏览器中持久存储数据的方法,但是和前端关系型数据不同的是,IndexedDB采用的key-value键值对存储,这种存储形式的数据库查询更简单快速,IndexedDB分别为同步和异步访问提供了单独的API,但是同步API仅提供在web worker内部使用,因此绝大多数情况,我们使用的都是异步API,同时IndexedDB也无法突破同源策略的限制,只能访问在同域下的数据
为什么要用IndexedDB
提到为什么要用IndexedDB就不得不提到我们经常用的缓存API localStorage和sessionStorage,这两个缓存API能满足我们开发时的绝大多数需求,简单的键值存储,但是它们有它们的限制:
- 存储空间限制,只有5M
- 只能存储字符串,存储对象类型的数据要用JSON.stringify和parse两个方法转换
- 存储的字段一多就很难管理,存储的字段也无法产生关联
IndexedDB的存储空间是没有限制,但是不同浏览器可能会对IndexedDB中单个库的大小进行一定的限制,IndexedDB本质上还是一个数据库,可以存储大量结构化数据(包括文件/blobs),同时IndexedDB API通过索引的方式实现了数据的高性能搜索
怎么用IndexedDB
前面介绍一堆IndexedDB相关的内容,接下来就来看看具体IndexedDB具体怎么使用,以一个简单的例子来切入,下面直接上具体代码:
var data = [{
id: 1,
name: 'Tom',
age: '18'
}, {
id: 2,
name: 'Tommy',
age: '16'
}]
// 打开数据库,两个参数(数据库名字,版本号),如果数据库不存在则创建一个新的库
var request = window.indexedDB.open('myDatabase', '1')
// 数据库操作过程中出错,则错误回调被触发
request.onerror = (event) => {
console.log(event)
}
// 数据库操作一切正常,所有操作后触发
request.onsuccess = (event) => {
var db = event.target.result
// 数据读取
var usersObjectStore = db.transaction('users').objectStore('users')
var userRequest = usersObjectStore.get(1)
userRequest.onsuccess = function (event) {
console.log(event.target.result)
}
}
// 创建一个新的数据库或者修改数据库版本号时触发
request.onupgradeneeded = (event) => {
var db = event.target.result
// 创建对象仓库用来存储数据,把id作为keyPath,keyPath必须保证不重复,相当于数据库的主键
var objectStore = db.createObjectStore('users', { keyPath: 'id'})
// 建立索引,name和age可能重复,因此unique设置为false
objectStore.createIndex('name', 'name', {unique: false})
objectStore.createIndex('age', 'age', {unique: false})
// 确保在插入数据前对象仓库已经建立
objectStore.transaction.oncomplete = () => {
// 将数据保存到数据仓库
var usersObjectStore = db.transaction('users', 'readwrite').objectStore('users')
data.forEach(data => {
usersObjectStore.add(data)
})
}
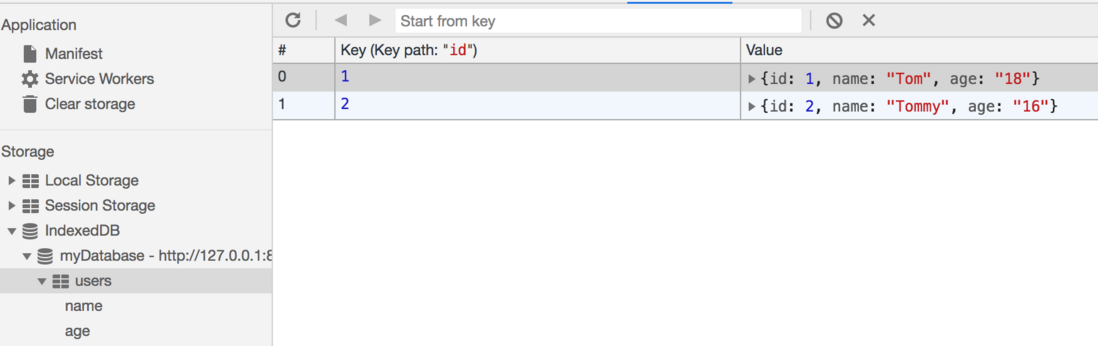
}上面的例子介绍了IndexedDB的简单用法,当执行完上面的代码后可以在浏览器中看到自己新建的IndexedDB:
考虑到不是所有人都会将IndexedDB应用于实际工作,因此上面只是介绍了简单API的调用,更多关于IndexedDB的用法可以去MDN学习,真正需要使用的时候,对于其异步API调用如果不做一定的封装,一定会陷入深深的回调地狱,因此这里推荐两个IndexedDB API的封装库:
应用场景
相信这个话题应该是大部分人最感兴趣的,IndexedDB到底应用在什么地方?前面介绍了这么多,IndexedDB使用比localStorage、sessionStorage复杂得多,如果没有特定的使用场景,开发者一定不会自己给自己找麻烦选择IndexedDB做缓存,结下就来看看IndexedDB适用的场景:
- 不需要网络连接的纯离线应用,比如Todolist这类的用来记录待办任务类型的应用,
在不考虑需要联网的登录、分享功能下,待办事项、收件箱、任务核心功能完全可以用IndexedDB做数据库存储,配合Electron做一个桌面应用

- 需要存储大量数据的应用,比如图书管理系统这类的需要存储大量数据的应用,完全可以将图书信息存储在IndexedDB中
- 配和service worker构建pwa应用,用来缓存网络请求
总结
这篇文章简单介绍了IndexedDB的相关内容,总的来说,IndexedDB的应用频率并不高,这是由于IndexedDB适用复杂度和不多的适用场景决定的,因此这里也只是对它做了简单介绍,希望看了这篇文章后,能对IndexedDB有个简单的了解,在需要使用的时候能有个印象。如果有错误或不严谨的地方,欢迎批评指正,如果喜欢,欢迎点赞






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。