
据统计,全球数据总量预计2020年达到44ZB,中国数据量将达到8060EB,占全球数据总量的18%。现阶段我们所讨论的人工智能,很大程度上都是在谈“人工智能”这个大概念下机器学习领域中的深度学习技术。它的底层原理相对简单,对数据有很大的依赖性,本质上是一种基于大数据的统计分析技术。
推荐系统作为人工智能的落地场景之一,对数据的依赖性不言而喻。企业通过前期的数据收集,全面了解自身的产品和目标用户;之后,通过一系列的数据挖掘技术,对目标用户进行分类,刻画用户画像;最后,再通过数据决策,制定产品运营方案,并不断迭代、优化产品细节。可以说,没有前期的数据,之后的一系列操作无从谈起。
那么,推荐系统是如何处理数据的呢?
一个典型的推荐系统,处理数据通常会经历以下四步:即数据收集、数据存储、数据分析和数据过滤。
数据收集
实现推荐系统的第一步便是收集数据。这些数据可以是显性数据,也可以是隐性数据。显性数据就是指用户主动输入的数据,例如对内容的评论、点赞、转发、下载等,隐性数据是指用户的浏览历史、阅读时长、观看记录、搜索日志等。后台会为每一个使用该产品/访问该站点的用户创建一个数据集。
用户的行为数据很容易收集,通过站点上的用户行为日志就能获取。如果用户已经在使用APP,获取用户的行为数据就不需要用户的额外操作。但这种方法有一个缺点,获取的数据分析起来很麻烦。比如说,从用户的大量行为日志中过滤出真正需要的日志非常麻烦。
由于每个用户对产品的喜好不一,因此收集到的每位用户的数据集也截然不同。随着时间的推移,收集到的用户数据也越来越多,通过一系列数据分析,推荐的结果也会越来越精准。
数据存储
我们为推荐算法提供的数据越多,推荐的效果就会越精准。这也就意味着,任何推荐问题都可以转变为大数据分析问题来解决。
用于创建推荐结果的数据类型可帮助我们确定应使用的数据存储类型。我们可以选择使用NoSQL(Not Only SQL)数据库、标准SQL数据库,甚至是某种对象存储。根据不同的存储目的如获取用户输入/行为,以及操作的难易程度、存储的数量级、与其他环境的集成以及数据的可移植性等因素,选择合适的数据存储类型。
在保存用户评级或评论时,可扩展和可托管的数据库能够最大限度地减少所需的任务量,将注意力聚焦在推荐结果上。 Cloud SQL可以满足这两种需求,还可以直接从Spark上加载数据。
数据分析
为了获取类似用户参与度之类的数据,我们需要使用不同的分析方法过滤数据。如果想在用户浏览产品时即时给出推荐结果,那么需要更加灵活的数据分析方法。以下是分析数据的一些方法:
•实时分析
可以在创建数据的同时对其进行处理。这种类型的系统通常包含可以处理和分析事件流的工具。要想给出用户实时的推荐结果,就要创建实时的数据分析系统。
•批量分析
要求定期处理数据。采用这种方法,意味着要有足够的数据才能分析数据之间的相关性,例如每日阅读量、关注量等。推荐结果可能会通过邮件形式发送给用户。
•近实时分析
每隔几分钟或几秒钟刷新一次后可以快速收集数据,进行分析。近实时系统最适合在一次浏览会话期间给出推荐结果。
数据过滤
下一步便是过滤数据,获取为用户提供推荐所需的相关数据。我们得先从上面的算法中选择一种更合适的算法。比如说:
基于内容的过滤:推荐的产品具有与目标用户喜欢的产品类似的特征;
聚类:对目标用户进行分类,处于某一个簇中的用户会被当成一个整体来对待;
协同过滤:目标用户喜欢其他用户喜欢的某一产品,那他也可能喜欢其他用户喜欢的其他产品。
协同过滤能够使产品属性理论化,并根据用户的口味进行预测。协同过滤的假设基础是:如果一位用户喜欢另一位用户喜欢的某一个产品,那么现在或将来他也有可能喜欢这位用户喜欢的另一个产品。
我们将产品和用户作为两个不同维度,把有关评级或互动的数据表示为一组矩阵。假设以下两个矩阵相似,如果用数字1代替现有的评级,用0补上缺少的评级,就能得到第二个矩阵。生成的矩阵为真值表,其中数字表示用户与产品之间的交互。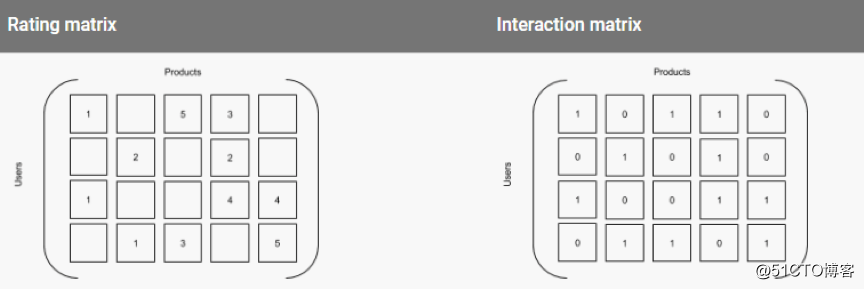
我们可以使用K-Nearest算法、Jaccard系数、Dijkstra算法、余弦相似性来更好地关联用户数据集,以便根据评级或产品特征进行推荐。
最后,根据推荐类型的及时性,用户就会得到相应的算法推荐结果。

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。