
相信好多人的面经中都写到过这道题了。可以说是一道网络方向的上古经典面试题,久盛不衰!有的人足够了解,这个问题能回答10分钟。不是很了解的童鞋,可能只能用寥寥数字来进行简单不完全的描述。写下这篇博客的目的就是——对这个问题做一个很好的总结。相信在接下来的面试中还很有可能被问到。希望到时候能用这个回答征服面试官哈哈哈。不过更加希望的是自己能思考明白这其中各个环节发生了什么,并能够利用这个知识真正变现成为生产力去解决问题。
这篇可能会很臭很长。我只想写的足够详细。
让我们先从按下键盘的电流回路开始讲起吧
开个玩笑,不过我看到有人真的这么分析了。也真是个狼人🐺
<!--浏览器会做什么-->
<!--首先,浏览器会分析我输入的内容。-->
<!--通常,如果输入的内容中包含了字段".com",那么浏览器不会认为我输入的是一个关键字。在确定用户输入的是一个URL而不是一个搜索关键字之后。浏览器就会检查,我所输入的URL是否指明了某种协议。如果没有,就会在开头加上"https://"。因为我没有指定具体的HTTP协议选项,所以浏览器就会使用默认值来填充:端口 80、GET方法、不使用基本的身份验证。-->
<!--关于自动补全时使用HTTP还是HTTPS?-->
<!--比如我输入的是"baidu.com",输入之后回车浏览器就会自动补全成" https://www.baidu.com"为什么会补全成https而不是http呢?-->
<!--关于这个问题,我尝试在网上搜索了一下,不过没有完整清晰的答案。主要是取决于各个厂商的考量。chrome亲测是补全成HTTPS的-->
会输入什么
访问或者搜索的时候。我们第一步需要做的,就是输入,那么我们可能的输入场景都有哪些呢?
-
搜索关键字。比如:
- baidu
- 百度
- www.baidu,com (注意这里使用的是逗号)
输入文本后回车,如果浏览器判定所输入的内容不是一个URL。那么浏览器就会调用默认的搜索引擎对输入的内容进行搜索。其过程只比直接输入URL多了一步。
如图。我输入了一个文本,并按下了回车
浏览器进行判定。判定结果是非URL链接,接下来浏览器自动生成一个带有我们搜索关键字的URL,向默认的搜索引擎发起连接请求。接下来的步骤就和输入一个URL链接一样啦。

-
URL
- baidu.com
- www.baidu.com
- http://www.baidu.com
- https://www.baidu.com
在我们输入并回车之后。首先,浏览器会对我们输入的内容进行解析。判断我们的输入是一个文本还是一个URL。如果是一个文本,那么浏览器就会对调用默认的搜索引擎对文本内容进行搜索。如果是一个URL,那么浏览器就会跳转到用户所请求访问的这个页面中去。
输入URL会怎么样
如上边所分析的那样。如果浏览器判定我们输入的是一个URL,那么浏览器就会查找这个域名锁对应的IP,这其中涉及到DNS的问题。我在另一篇Blog中详细写了DNS查找的过程——《网络——DNS处理顺序》。接下来浏览器就会检查这些请求是HTTP还是HTTPS的。有些情况下,第一个请求不是HTTPS的,但是当浏览器向网站发出第一个HTTP请求之后,网站会返回一个请求,让浏览器使用HTTPS发送请求。HTTP改HTTPS这个转变的时间是浏览器自动完成的。
我们可以以百度为例——我尝试在浏览器输入www.baidu.com回车之后,网页就会自动转到https://www.baidu.com。接下来,我输入http://www.baidu.com,回车之后,也会自动转到https://www.baidu.com。说明
输入URL之后的流程
- URL的解析&合法性判断
- HSTS检查
- 安全检查&访问限制
- 缓存检查
- DNS查询
- TCP连接
- 发起HTTP/HTTPS连接请求
- 服务器响应请求,浏览器得到HTML代码
- 浏览器解析HTML代码,并请求HTML代码中的资源(js、css、图片等)
- 浏览器对页面进行渲染,并向用户呈现我们最终看到的网页
所用到的协议
想了一段时间,但是还是有点理不清思绪,所以列举一下各层所用到的协议。在之后的文章会都写到的。
应用层:发起请求的逻辑
表示层:HTTP/HTTPS
会话层:TLS
传输层:TCP
网络层:IP
数据链路层:帧
物理层:比特流
域名解析
字符转换
如果输入的是非a-z、A-Z、0-9、-、.的非ASCII的Unicode字符字符,浏览器会对主机名部分使用Punycode编码
HSTS
在上边所举例的三种输入样例中,按下回车其实都会转到https://www.baidu.com。但是其中的原理却不尽相同。在我们输入https://www.baidu.com的时候,说明我们是使用https协议来访问,这个并不是很难理解。
在输入baidu.com和www.baidu.com之后,这其中涉及到的是"预加载HSTS"的问题。详细内容在我单独写的一个博客《HSTS简单探究》中。简而言之就是现代浏览器会内置一个列表,记录了一些域名。如果我们访问的域名在这个列表中,浏览器就会自动将网络协议补全成为HTTPS。另外提一点,假如baidu.com不在浏览器的HSTS列表中,那么也会被自动补全成HTTPS。
只要网站支持,用https总是好的,安全的! ——一位不愿透漏姓名的网友
在输入http://www.baidu.com也会使用301自动重定向到https://www.baidu.com这是因为浏览器和服务器在其中做了很多。在我们使用HTTP去向网站发起连接请求,这时会得到服务器的响应。但是不是常规响应,而是一个重定向的301响应,而后浏览器收到响应,会重新发起HTTPS请求和网站进行通信。这其实是一次有风险的操作,因为我们可能会因此受到downgrade attack的攻击。还有一点就是在服务器和浏览器之间会发生TLS握手。这个马上就说。
TLS
Transport Layer Security:传输层安全协议。有SSL1.0、SSL 2.0、SSL3.0三个版本。作为初学者,我的理解就是HTTPS = HTTP + TLS(其实是我在google到的)。我看了关于TLS的介绍,有点头大。。。
所以我就不多讲了,不过可以写写关于OpenSSL和SSL的关系。倒是蛮有意思的。
之前看罗永浩的发布会。罗说卖门票就是用来做一个观众的筛选,不是为挣钱,就是交个朋友。所以他把门票收入都捐了。捐给了谁呢?那就是OpenSSL组织。界面新闻曾经写过一篇名叫《隐形战友》的文章,文中的OpenSSL一副惨兮兮的样子,开源组织在作者笔下仿佛没有锤子的捐款明天就要倒闭的样子。我真的不是很赞同文章的立场。OpenSSL作为一个开源组织,最大的贡献当然是OpenSSL工具集。并没有什么精确的办法来判断HTTPS是否是使用OpenSSL的,不过在apache和nginx上肯定是使用了OpenSSL的。这么来推理的话,保守估计全球70%以上的网站都是使用了OpenSSL的。也对!要不然HeartBleeding也不会引起那么大的关注了。扯的有点远了。言归正传~
解析域名
前面一堆吧啦吧啦之后,域名解析才真正开始。解析过程为
- 搜索浏览器自身DNS缓存
- 操作系统DNS缓存
- 本地HOSTS文件
- 使用DNS服务器查询
详细的解析过程请看我的另一篇关于DNS解析顺序的Blog《网络——DNS解析顺序》。
使用套接字
现在我们已经拿到目的服务器的IP地址了。现在,我们的浏览器就会以一个随机的端口(1024<端口<65535)向服务器的Web程序(常用的有tomcat,nginx)的80端口(如果是https协议的话,默认就是443端口)调用系统的socket,请求一个TCP流套接字。这个请求首先交给传输层,请求在传输层被封装成TCP segment。TCP segment又被送往网络层,加入IP头部,封装成IP packet。然后IP packet进入了链路层,加入了本机MAC和网关MAC,最终成为了一个完整的TCP封包。如果内核不知道网关的MAC,那么它就必须进行ARP广播来进行查询。
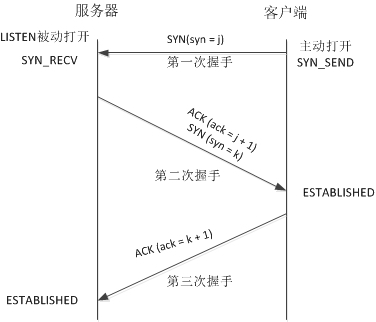
我们现在已经可以发起TCP连接请求了。请求发送,服务器的WEB程序收到了我们的连接请求最终建立了TCP/IP连接。以下是TCP的三次握手过程。
如果是https的话,那么在这个时候就会进行TLS握手,握手过程如下:
- 客户端发送一个
Clienthellof到服务器端,消息中也包含了TLS版本,可用的加密算法和压缩算法。- 服务器收到消息之后返回
Serverhello消息。其中也包含了服务器的TLS版本。所选择的压缩算法和加密算法,CA签发的服务器证书。证书中包含了公钥。- 客户端验证CA证书的可靠性、若可信就生成一个对称主密钥。
- 服务器生成对称主密钥。
- 客户端发送
Finished消息给服务端。- 服务器生成Hash,解密客户端消息。
- 接下来,TLS密钥都会被用来加密和解密传输层(http)的内容。
http层
客户端发送http请求
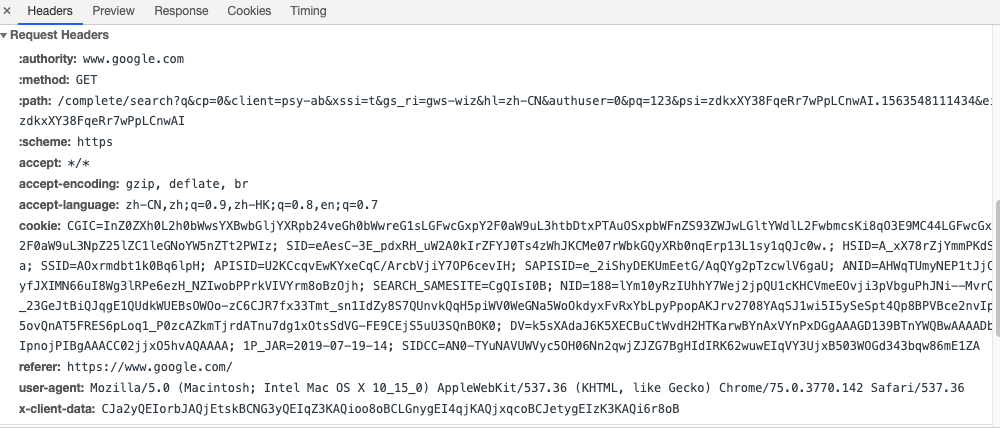
低层协议的连接建立了,现在是高层协议的showtime了。TCP的连接已经建立了,报文也准备好了。准备发送。这是我们的请求报头:
服务器响应http请求
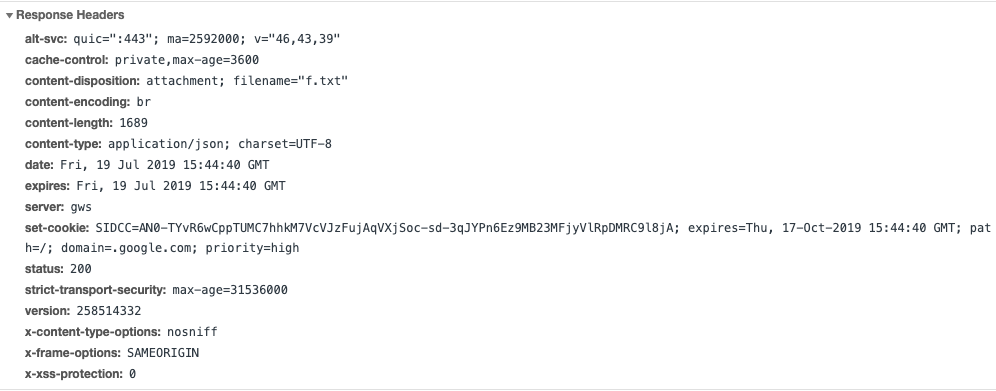
服务器端的Web程序收到了http请求以后,就会处理客户端的请求。处理完了之后返回给浏览器请求的资源文件(HTML,CSS,JS,图片等等)。服务器的响应头:
浏览器
浏览器拿到了index.html文件了,就要开始解析其中的html代码了,遇到js/css/image这些静态资源就向服务器端去请求下载。这个时候就需要用到keep-alive特性了。建立一次HTTP连接,可以请求多个资源。
浏览器在请求静态资源的时候,向服务器端发送一个http请求来询问自从上次请求之后,静态文件有没有被修改。如果服务器返回304状态码,那么就是没有改变的意思,浏览器就直接从本地的缓存中直接读取文件了。
之后就是GPU渲染,并且把最终的网页呈现出来。
我们就看到网页了。
完。
本文参考:




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。