
携程度假每个旅游线路在每期、每天的价格均有变化,而价格变化又受到多个因素影响。为尽快捕捉到价格变化,需要不断优化调整架构,使得价格调整灵敏度更高更准。这对被调服务及硬件产生了极大的压力,也带来了新的瓶颈。那么,携程是如何解决这一难题的呢?本文是携程高级研发经理陈少伟在「云加社区沙龙online」的分享整理,着重介绍了携程度假起价引擎架构不断演进的过程。
一、背景介绍
1. 什么是度假起价引擎?
首先,解释一下什么是度假起价引擎。度假每个旅游线路涉及到不同的出发地,不同的出发地下有不同可出发班期,每个班期都有对应的这一天的价格。旅游产品的价格由多个资源组成的,任何一个资源价格发生变化,都会影响到产品的价格。 为了尽快捕捉到价格变化,需要有一个专门的价格系统去监测不同资源的价格变化,这就是起价引擎。
2. 旅游电商和普通电商的区别是什么?
普通电商的商品基本都是标品,价格和库存都针对的是单个SKU(StockKeeping Unit 库存单元),而旅游打包类商品都是由多个SKU组成(静态和实时匹配),任意一个SKU的价格、库存发生变化,都会直接影响到它所关联的所有产品。正是由于变量太多,这也给定价带来了极大的挑战。
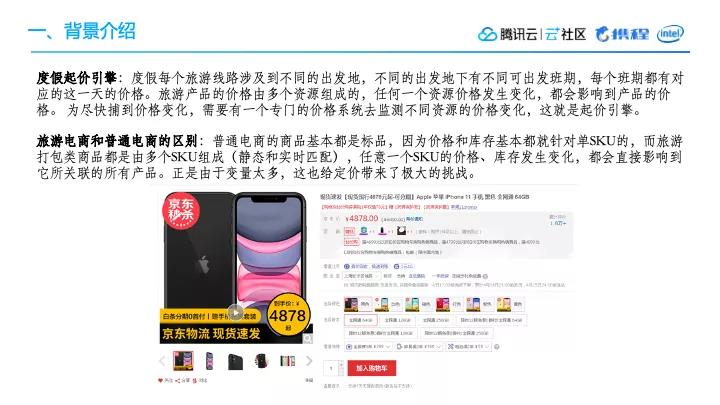
上图展示的是京东上一个商品截图,我们可以看到它涉及到两个SKU,基本上像这种情况,每个SKU的价格都是比较确定的。
3. 度假起价面临的挑战有哪些?

旅游产品由于它的关联复杂性,给我们的度假起价造成了很大的挑战,总结如下:
(1)价格组成复杂
旅游产品不像单品售卖,产品价格是由多种资源组成(机、酒、火、X等),任意一项资源价格、库存发生变化,都会导致整包价改变,变量太多。
(2)计算规则复杂
资源除了可以和产品行程绑定,同时,可以设置规则,由产品行程配置去动态匹配。资源和资源间存在关联关系。
(3)计算量较大
总任务单元(产品ID+出发地+出发班期)8亿+,并且在不断增加,其中国际机票任务量8700W+,国际航线路由(出发+到达+日期)1500W。总任务峰值QPS10W,Redis QPS 65W。
(4)可控性差
除了部门采购的资源外,活包产品大量依赖外部的资源。外部资源的变化对系统是黑盒,只能依赖API离线计算,API的调用量也会有限制等。
(5)售卖风险高
任意一个资源价格设置错误,直接影响到一批产品,对于异常价格需要实时预警,通知相应的业务介入处理。
(6)活包的概念
这里需要解释一下活包的概念,活包的意思是就是说,整个的价格库存不是控制在自己部门内的,主要依赖外部资源,只能是通过API去调用,包含这类型资源的产品,就叫活包。
4. 业务范围及指标
引擎计算的价格,包含“产品起价”和“班期起价”,这一部分是离线计算的衡量。
起价一致性的核心指标,是产品起价准确率。表示产品从搜索到详情页,某个出发班期与用户实时查询时产生价格的差异到底有多大。
为了更好衡量差异性,我们将准确率分为三个区间:比例区间、价格区间和完全相等。
二、引擎1.0简介
下面介绍一下第1个版本,引擎1.0存在的几个问题。
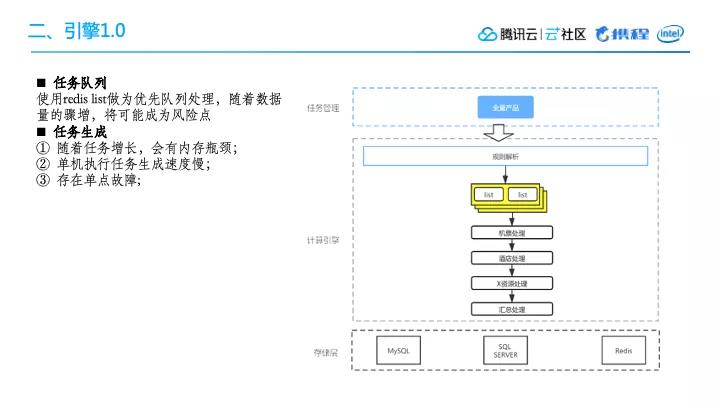
1. 任务队列
在最早的引擎1.0版本,用MySQL做任务队列,并且针对每个任务队列做了一个同步处理。比如说,在算完机票资源之后,再算酒店,算完酒店后进行单选项资源处理,最终汇总出价格。这里同时还涉及到数据库的同步问题,比如说从MySQL同步到SqlServer。
其实这个版本存在为数不少的问题,后来,我们为了加速一些任务上的流转,把MySQL的队列拆成了多个队列,并且使用Redis的队列去替换MySQL队列,整体的处理的速度快了一些,但是它同样也存在一些问题。
2. 任务队列
使用Redis list做为优先队列处理,随着数据量的增长,将来可能成为风险点,因为Redis list在队列数据量越来越多的时候,包括qps等整体各方面都达不到我们的性能要求。
3. 任务生成
当数据量越来越大时,任务生成会比较慢。并且在之前的模式下,任务生成由某一台机器去承载这个功能,也就是说这台机器承担着一个比较重的任务。如果数据量不增长,可能还可以承受,但是当数据量急剧增长的时候,就会出现瓶颈。
另外这样还容易产生单点故障。比如说,这台机器挂了该怎么办?或者当前只生成了一半结果出现问题,整个结果又得推倒重来?这样一来,失败的成本会很高。
三、引擎2.0简介
针对引擎1.0的问题,我们在引擎2.0中采取了相应的改善措施。
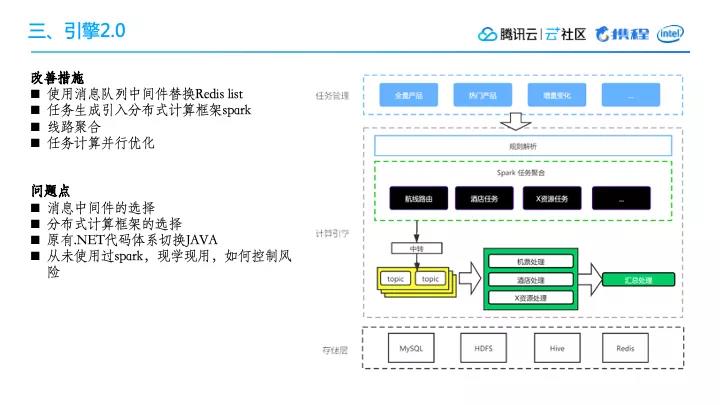
首先,我们用消息队列中间件去替换Redis list,这样一来,系统的整体抗堆积能力就会强很多,并且可以达到非常高的水平扩展性能。
当然,对于选哪一种消息中间件,我们自己也做过一些衡量。比如说像是RabbitMQ或者是携程内部的消息中间件的产品,最终我们选择了一个内部的基于Kafka的消息队列,因为有专门的团队去维护它,使用风险也降低了很多。
在任务生成方面,我们引入了分布式计算框架Spark,可以调用较多的计算资源进行数据的聚合计算处理,并且有很好的容错性,即便有个别机器失败,会有重试机制,对整体影响有限,没有单点故障风险,生成的效率较高。
当时如果要采用Spark的话,会涉及到之前没有遇到过的问题。比如,在整个公司从原有的.net代码体系切换到Java、团队中从来没有使用Spark,现学现用如何控制风险等。
当然我们也做了非常多的调研,包括全流程的环境搭建。比如,从本地环境的搭建,再到测试环境的搭建,每一步的搭建,每个环节都要去进行测试,甚至涉及到Spark的调用时,还需要很多安全认证。比如,在Windows下面就很难去处理安全验证问题,需要切换到Linux。整个过程当中,都需要一步一步去学,然后去解决问题,最终也学到了不少东西。
1. 线路聚合
在引入了分布式计算框架之后,我们又做过一些优化工作。比如航线聚合。
例如,北京->上海,这算是一条航线。不同的产品可能都会配这个航线,比如说产品1配置了上海->北京->上海,然后产品5也配置了上海->北京->上海。按原来的调用方式,这是两个请求。但是,将这个航线作为一个聚合的话,北京->上海这一个请求可以复用到产品1跟产品5。
这样一来,一个机票的调用量就减少了很多。拿之前的国际机票来举例,总的用量有8700万架,但其实只有1500万的航线。这样一来,调用的请求量就只有原来的几分之一。
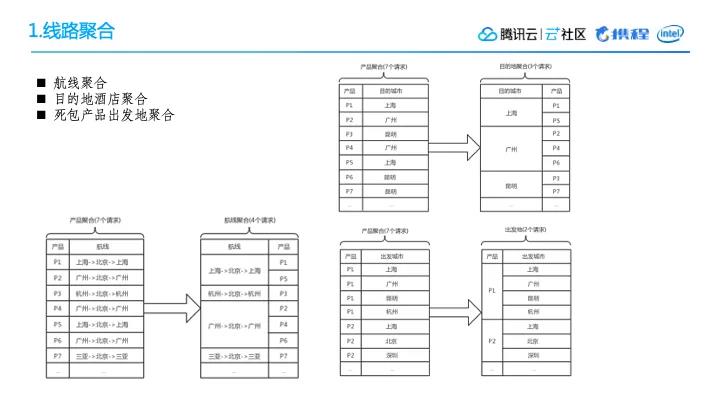
类似的,例如目的地酒店\VBK资源产品计算也可以做这样的聚合。这样的话,基本上每一种类型资源都有可能得到几倍,甚至上百倍的性能优化。
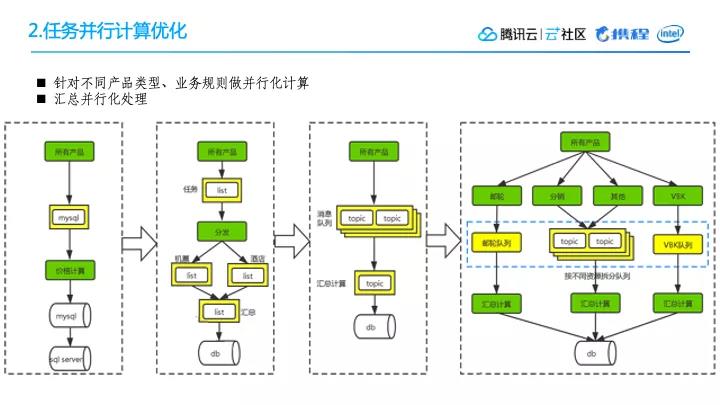
2. 任务并行计算优化
下图是任务并行计算优化演化的一个过程。
第一,使用MySQL做为任务队列,接下来同步计算机票、酒店、单选项资源价格,然后汇总出最终价格,写入MySQL同时把数据同步到SqlServer;
第二,使用Redis队列替换MySQL队列,把Redis按资源拆成不同的队列,去除SqlServer数据同步;
第三、把Redis队列替换成消息队列中间件,把分发节点去除,加快任务流转的过程;
第四、把计算结构打平,不同的产品可以并行任务生成并计算,不同产品的计算频率可以不一样,原来各个资源队列处理完成之后都会放到汇总队列处理,这里汇总队列容易成为瓶颈,因此把汇总队列去除,把它放到各个资源队列里直接计算,加快整个的计算效率。
3. 优化结果
最终的优化结果是,任务生成的速度从5个小时降低到了1.5小时,任务的整个技术周期从两周缩短到1.5天。
但是,这个版本依旧存在一些问题。随着任务量增加,班期数从6000万增加到8亿家,系统面临着新的瓶颈:
(1)MySQL数据库存在IO瓶颈
(2)任务生成后消息分发不及时
- 消发送慢
- 发布会中断消息的发送
四、引擎3.0简介
针对引擎2.0的两个主要问题,我们启动了3.0的改造计划。
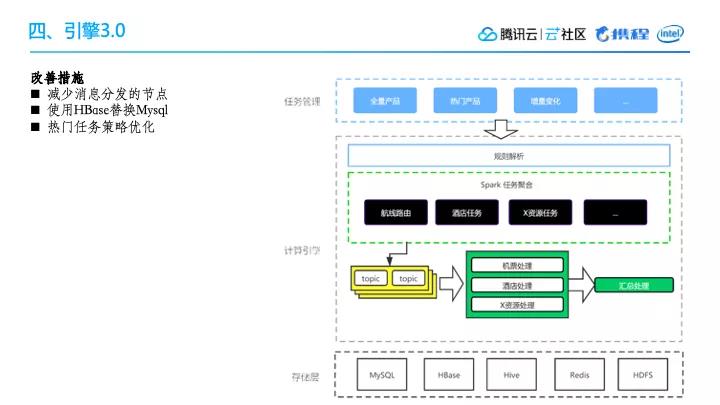
主要做了以下三点改善措施:
- 减少消息分发的节点
- 使用HBase替换MySQL
- 热门任务策略优化
1. 减少消息分发的节点
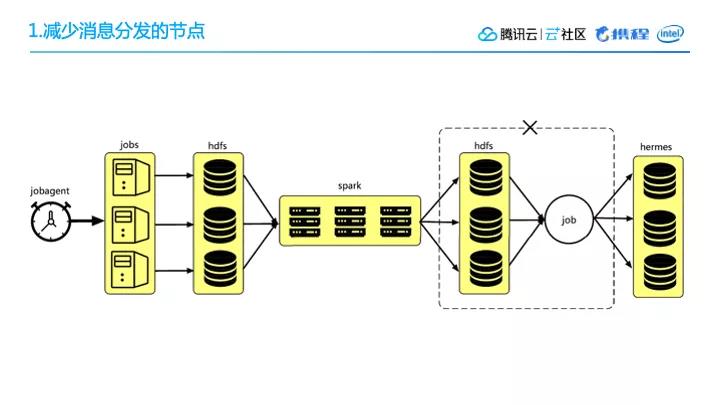
我们怎么减少消息分发节点的呢?
整个任务生成的过程,首先是消息对产品进行解析,拿到产品的出发地、出发日期,再结合其他的信息,把这些相关的信息写到分布式文件系统里面,再通过Spark进行不同资源的聚合排序,然后再把它写回到分布式文件系统里面,接着通过某一个job去把这些信息取出来,然后把消息发送出去。
这种处理方式当然是可以的,但是整体处理的步骤稍微有点多。之所以这样做,是因为之前所用的不同环境下的不同组件,它们的结合容易有各种各样的冲突以及环境本身还不足够完备,我们一开始也没时间去做这块的优化等等,所以暂定的这样的临时处理方式。
后来我们把通过HDFS分布式文件系统把任务信息分发到下一步的这一个步骤简化了,在消息发送的时候,直接通过Spark进行消息发送,比如它里面可能有几百个节点,我们这几百个节点同时发送这个消息,所以整体发消息的效率就提升了特别多,同时消息发送同业务计算逻辑分发,业务上的调整发布不会影响消息发送的进程。
2. 使用HBase替换MySQL
随着计算量的增加,MySQL数据写入存在IO瓶颈,更换SSD、分库分表后依然未彻底解决问题,考虑到引擎使用DB如下场景:写入多、查询少,查询条件简单,再加上我们是离线计算方式计算价格,比较适合NOSQL数据库的适用场景,在综合评估HBase的各项指标、开发成本、运维成熟度之后,基本符合我们的预期。
3. 热门任务策略优化
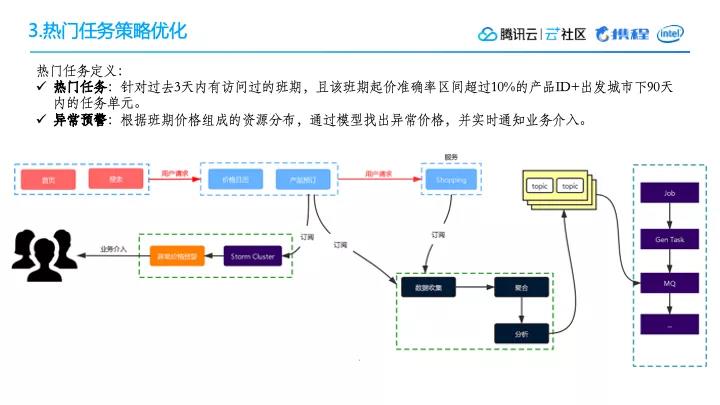
然后同时我们也做了一个热门任务的策略优化。热门任务整个的价格,需要访问的资源很多。如果能够针对这部分的产品做一些优化,对于整个准确率的提升是有帮助的。
什么是热门任务呢?我们对热门任务的定义是针对过去3天内有访问过的班期,且该班期起价准确率区间超过10%的产品ID+出发城市下90天内的任务单元。
同时,我们还做了异常预警。根据班期价格组成的资源分布,通过模型找出异常价格,并实时通知业务介入。
五、优化结果
各版本及现在优化效果如下图所示,其中价格完全一致60%。
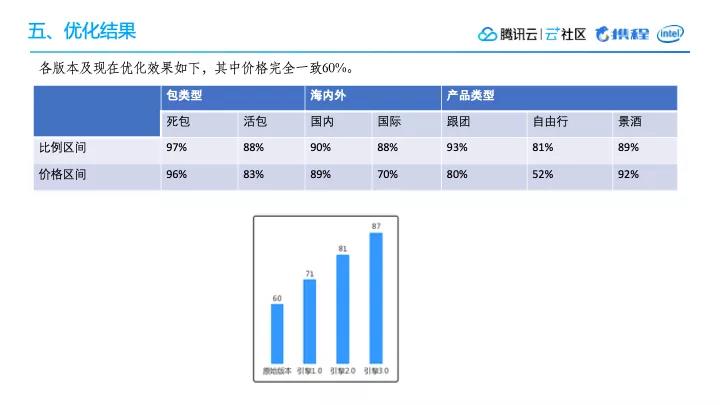
在最开始的版本,整体准确率只能达到60%,到了引擎1.0达到了71%,引擎2.0准确率达到了是81%,引擎3.0突破了87%,事实上现在的平均准确率能达到90%多。
其中价格完全一致差不多占了60%,基本上比例区间数值都要比价格区间要高一点,但是景酒类型会比较特殊,因为它的单价比较低,景酒单价平均在450元左右,所以如果景酒按价格区间来计算的话,可能正负差价在45元,而我们定的价格区间大概是±100了,所以它的比例区间的的范围明显比价格区间更窄,因此它的价格区间值其实是要比比例期间是要好的,但其他产品因为单价都比较高,所以通常来讲是比例区间会更好一点,然后有些场景下例如像自由行,因为它主要包含了活包资源,因此准确率还不是特别高,我们后面可能也会针对这类的场景做一些优化。
六、总结
最后做一下总结:以上的很多优化并不是孤立的,有很多优化都是并行着进行的,一个优化做完之后,计算效率、准确率提升的同时,也带来了计算速度的增加,计算速度的增加同样会增加被调服务的调用次数,不管是对自身系统还是对被调服务各方面压力都在增加,整个架构是在不断优化调整中演化出来的,而并不是事先设计好的。架构是为业务服务的,业务上的需求决定了架构演化的方向。
另外分享一下离线计算的解决思路或者经验:通过数据的沉淀,以提供一种启发式、自驱动的方式去寻找问题,可以对数据做深入分析,查看数据的分布,深入分析产生此种分布的深层原因,找到原因并思考可能的侯选解决方案,通过相关公开的benchmark/试验/demo等论证方案的可行性,确定方案后制定合理的切换方案,在保证线上业务正常运行的同时进行灰度切换,验证无问题后切换到新方案,下线旧方案。
七、Q&A
Q:为什么原有的.Net体系要换成Java?
A:这是公司整体的架构方向,属于公司层面的一个切换,我个人觉得Java的生态环境要好很多。
Q:发送任务的MQ出问题了怎么办?
A:通常来讲,基本不太会有这种情况出现。因为我们的发送有n个节点,并且就算发送失败了,也会检查失败的原因到底是什么?因为MQ有专门的团队去维护,所以通常不太会有这种问题,其实可能性更大的是发送的JOB失败了,像这种情况我们是可以重试的。
Q:这个系统是分区域,高可用部署方案怎么实施的?
A:我们主要是离线计算任务,计算结果我们也会分发到不同的数据中心去进行处理,如果某个数据中心有问题,我们完全可以切换到另外一个数据中心去。
Q:替换MySQL时是怎么进行的?是双写吗?如果是双写的话,如何保证数据一致性?
A:是双写的,要么同时成功,要么同时失败。
Q:MySQL是直接安装在物理机上么 还是虚拟机上?
A:我们的MySQL是安装在物理机上的。
Q:双写性能能保证吗?
A:双线的性能会差一点,但是在灰度的过程中,双写其实是必要的,等到后面新的方案成熟之后,就可以把双写下掉。然后我们是有分库分表的。
Q:怎么保证HBase和MySQL同时写入成功?
A:我们会有一些处理,比如说如果写失败的话,我们的整个过程都会失败。
Q:MySQL 大概分了多少库,遇到性能瓶颈了吗?
A:我们分了大概有64张表,但其实在我们在分了两个库之后,基本上就不再考虑MySQL的方案了,因为当我们分库的时候,基本没有撑到很长的时间,也就是说我们的系统瓶颈基本是在DB上,在这种情况下,我们希望能够找到一个方案能够一步到位能够提升特别多,虽然我们还是可以通过分库再让MySQL再支撑一段时间,但其实后续的维护成本,包括性能的提升,对我们来说都是相对比较有限的。所以我们最终考察下来,选择了HBase。
Q:离线计算进行数据统计测试,有没有什么比较好的方向和体系?
A:关于离线计算,其实当时使用Spark,会有一些数据统计方面的考虑,因为Spark可以进行一些大数据的计算,它有很多数据分析的包,通过这些包我们能够分析出整个数据的分布情况,并且整个Spark体系跟Python生态结合得比较好,整体的数据分析体系会比较好,结合这些数据进行分析,我们可以挖掘出很多数据本身的价值。
Q:HBase数据量大的话,节点故障恢复会比较慢吧,线上有出过问题吗?
A:我们有出现HBase响应越来越慢的情况,在这种情况下,我们基本上会去找HBase运维团队去帮我们做分析。比如之前碰到像访问句柄过多导致处理较慢,我们会对HBase做一些针对性的优化,把对HBase的写入打得更加平稳,以及减少了很多不必要的查询,同时也对整个查询做了一些优化,使得查询也也更加的一个平稳,改造完后现在整体运行都相当的平稳。
Q:业务中选冷热分离,还是及时建好数据中心?
A:其实我们这种场景不太会有冷热数据这种情况,我们的离线计算基本上是全量计算的,也就是说7×24小时不间断的一直在计算,当然对于外网的价格日历访问是存在热点的,但是我们的整个查询结合了缓存等去做,查询性能还可以。
Q:有用到缓存吗?缓存预热是怎么做的?
A:我们对外的价格日历班期查询是有用到缓存的,整个缓存我们相当于是7×24小时不间断一直在写入,所以其实也不怎么存在预热的问题。
Q:引擎3.0的价格调整灵敏度多高?实现实时了吗?
A:其实还达不到实时,其实我们最开始做这个引擎的时候,想的是如果有一个消息通知机制,整个计算会简单很多,但因为当时并不足够了解旅游相关产品特性,它的价格复杂度比普通商品高很多,因为它的价格涉及到很多其他库存资源,而且这些资源不在本部门控制中,所以很难做到实时的消息更新,所以我们现在基本上都还是通过轮询的方式去调用别部门的接口,而对外调用接口,他们会对你限流,包括机票自身去查询相关的一些接口,也是要付费的,在这种情况下,我们只能去充分利用好每一个流量资源。
死包我们基本上能做到准实时的情况,因为我们有消息通知机制,当我们收到这个消息之后,会立马进行计算。基本上酒店的价格更新,我们可以做到一天一次,但是像机票的话,因为机票的任务量太多,外面对我们的限流也比较厉害,所以现在基本上只能做到两天跑一次。
Q:你们目前系统的瓶颈是什么?
A:其实我们目前的系统瓶颈还是受限于外部接口的限流,因为接口的限流导致我们计算受限较大,并且这部分资源价格库存不是控制在我们自己手中,假如是抓在自己手里的话,这些其实都不是问题,我们自己可以控制的资源,我们都可以做得很好。
讲师简介
陈少伟,携程高级研发经理。携程度假起价引擎研发负责人,主要负责度假起价引擎、搜索的研发工作,拥有11年研发经验的资深技术控,携程公司级杰出技术贡献者,对新技术有浓厚的兴趣。





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。